

La voie de la survie pour les ZKVM : un article détaillé sur la lutte entre factions
TechFlow SélectionTechFlow Sélection
La voie de la survie pour les ZKVM : un article détaillé sur la lutte entre factions
L'année écoulée 2022 a principalement concentré les débats autour du ZkEVM, mais il ne faut pas oublier que le ZkVM constitue également un autre moyen de mise à l'échelle.
Auteur : Bryan, IOSG Ventures
Merci à Xin Gao, Boyuan de p0xeidon, Daniel de Taiko et Sin7Y pour leur soutien et leurs suggestions de révision sur cet article !
Sommaire
Implémentation du système de preuve ZKP – Basé sur circuit (circuit-based) vs basé sur machine virtuelle (vm-based)
Principes de conception d’un ZKVM
Comparaison entre les machines virtuelles fondées sur STARK
Pourquoi Risc0 suscite-t-il tant d’enthousiasme ?
Introduction :
En 2022, la majorité des discussions autour du rollup se sont concentrées sur le ZkEVM. Cependant, il ne faut pas oublier que le ZkVM constitue également une autre méthode de mise à l’échelle. Bien que le ZkEVM ne soit pas l’objectif principal de cet article, il est utile de rappeler quelques différences clés entre ZkVM et ZkEVM :
1. Compatibilité : Bien que tous deux visent la mise à l’échelle, leurs priorités diffèrent. Le ZkEVM met l’accent sur la compatibilité directe avec l’EVM existante, tandis que le ZkVM vise une scalabilité complète en optimisant au maximum la logique et les performances des dapps. La compatibilité n’est pas son objectif premier. Une fois la base construite, la compatibilité EVM peut être ajoutée ultérieurement.
2. Performance : Les deux approches présentent des goulots d’étranglement prévisibles. Pour le ZkEVM, le principal frein provient du coût supplémentaire induit par la compatibilité avec l’EVM, une architecture peu adaptée à l’intégration dans un système de preuve ZK. Pour le ZkVM, le goulot d’étranglement vient de l’introduction d’un jeu d’instructions (ISA), ce qui rend les contraintes résultantes plus complexes.
3. Expérience développeur : Les ZkEVM de type II (comme Scroll ou Taiko) misent sur la compatibilité au niveau du bytecode EVM, c’est-à-dire que tout code EVM au niveau du bytecode ou supérieur peut générer une preuve à connaissances nulles via le ZkEVM. Concernant le ZkVM, deux orientations s’offrent : concevoir son propre langage spécifique (DSL), comme Cairo, ou chercher à être compatible avec des langages matures existants tels que C++/Rust (comme Risc0). À l’avenir, nous anticipons que les développeurs Solidity d’Ethereum pourront migrer vers le ZkEVM sans coût, tandis que les applications plus puissantes et innovantes s’exécuteront sur le ZkVM.

Beaucoup se souviennent de cette image. La raison fondamentale pour laquelle CairoVM reste en marge des luttes entre factions ZkEVM est une différence de philosophie de conception.
Avant d’aborder le sujet du ZkVM, commençons par réfléchir à la manière dont implémenter un système de preuve ZK dans la blockchain. De manière générale, deux méthodes permettent d’implémenter un circuit : les systèmes basés sur circuit (circuit-based) et les systèmes basés sur machine virtuelle (vm-based).
Premièrement, un système basé sur circuit transforme directement un programme en contraintes, puis transmet ces contraintes au système de preuve. Un système basé sur machine virtuelle exécute le programme via un jeu d’instructions (ISA), générant ainsi une trajectoire d’exécution (execution trace). Cette trajectoire est ensuite convertie en contraintes avant d’être envoyée au système de preuve.
Dans un système basé sur circuit, le calcul du programme est contraint par chaque machine exécutant le programme. Dans un système basé sur machine virtuelle, le jeu d’instructions (ISA) est intégré au générateur de circuits, produisant ainsi les contraintes du programme. Le générateur de circuits impose des limites concernant le jeu d’instructions, les cycles d’exécution, la mémoire, etc. La machine virtuelle offre une universalité : toute machine peut exécuter un programme tant que ses conditions d’exécution restent dans les limites définies.
Dans une machine virtuelle, un programme ZKP suit approximativement le flux suivant :

Source : Bryan, IOSG Ventures
Avantages et inconvénients :
- Du point de vue du développeur, développer dans un système basé sur circuit nécessite généralement une compréhension approfondie du coût de chaque contrainte. En revanche, pour les programmes destinés à une machine virtuelle, le circuit étant statique, le développeur doit surtout se préoccuper des instructions.
- Du point de vue du vérificateur, en supposant l’utilisation du même SNARK pur comme backend, les systèmes basés sur circuit et les machines virtuelles diffèrent fortement en termes de généralité du circuit. Un système basé sur circuit produit un circuit différent pour chaque programme, tandis qu’une machine virtuelle utilise le même circuit pour différents programmes. Cela signifie qu’un rollup utilisant un système basé sur circuit devrait déployer plusieurs contrats de vérification (verifier contract) sur L1.
- Du point de vue applicatif, la machine virtuelle intègre un modèle mémoire dans sa conception, permettant ainsi une logique applicative plus complexe, tandis que l’objectif d’un système basé sur circuit est d’optimiser la performance du programme.
- Du point de vue de la complexité du système, la machine virtuelle introduit davantage de complexité, notamment en matière de modèle mémoire ou de communication entre hôte (host) et invité (guest), alors que le système basé sur circuit est plus simple.
Voici un aperçu des projets actuels sur L1/L2 basés sur circuit ou sur machine virtuelle :
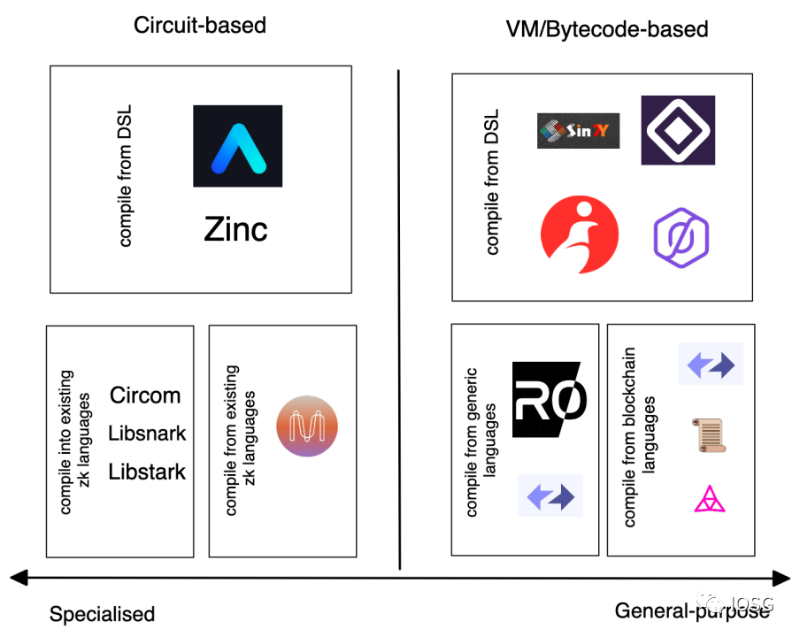
Source : Bryan, IOSG Ventures
Principes de conception de la machine virtuelle
Deux principes clés régissent la conception d’une machine virtuelle :
Premièrement, garantir que le programme soit correctement exécuté. Autrement dit, la sortie (output) — c’est-à-dire les contraintes — doit correspondre fidèlement à l’entrée (input) — le programme. Cela est généralement assuré par le jeu d’instructions ISA.
Deuxièmement, garantir que le compilateur fonctionne correctement lorsqu’il traduit un langage de haut niveau vers un format de contraintes approprié.
1. Jeu d’instructions ISA
Il définit le fonctionnement du générateur de circuits. Son rôle principal consiste à mapper correctement les instructions aux contraintes, qui seront ensuite transmises au système de preuve. Les systèmes ZK utilisent exclusivement des architectures RISC (Reduced Instruction Set Computing). Deux choix s’offrent :
La première option consiste à concevoir un ISA personnalisé (custom ISA), comme on le voit dans la conception de Cairo. Généralement, cela implique quatre types de logique de contrainte.

L’objectif principal d’un ISA personnalisé est de minimiser autant que possible le nombre de contraintes, afin que l’exécution et la vérification du programme soient rapides.
La deuxième option consiste à utiliser un ISA existant, comme adopté par Risc0. Outre un temps d’exécution concis, les ISA existants (comme RISC-V) offrent des avantages supplémentaires, notamment une meilleure compatibilité avec les langages frontaux et le matériel backend. Une question ouverte demeure : les ISA existants risquent-ils d’être moins performants en termes de temps de vérification (car ce dernier n’était pas un objectif principal de conception de RISC-V) ?
2. Compilateur (Compiler)
Globalement, un compilateur traduit progressivement un langage de programmation en code machine. Dans un contexte ZK, cela signifie convertir des langages de haut niveau comme C, C++, Rust en une représentation bas niveau compatible avec les systèmes de contraintes (R1CS, QAP, AIR, etc.). Deux approches principales existent :
Concevoir un compilateur fondé sur des représentations de circuits ZK existantes — par exemple, dans le monde ZK, les circuits peuvent être exprimés via des bibliothèques directement appelables comme Bellman, ou via des langages bas niveau comme Circom. Afin d’unifier ces formats, des outils comme Zokrates (qui agit aussi comme un DSL) visent à fournir une couche d’abstraction pouvant compiler vers différentes formes bas niveau.
Construire sur des infrastructures de compilation existantes. La logique de base repose sur l’utilisation d’une représentation intermédiaire (intermediate representation) compatible avec plusieurs frontaux et backends.
Le compilateur de Risc0 s’appuie sur une représentation intermédiaire multi-niveaux (MLIR), capable de générer plusieurs IR (similaire à LLVM). Ces différentes IR offrent de la flexibilité aux développeurs, car chacune a des objectifs spécifiques — certaines étant optimisées pour le matériel, par exemple. Cette idée est également présente dans vnTinyRAM et TinyRAM utilisant GCC. zkSync constitue un autre exemple utilisant une infrastructure de compilation.
On observe également des infrastructures de compilation dédiées au ZK, telles que CirC, qui s’inspirent de certains concepts de LLVM.
Outre ces deux étapes essentielles, d’autres facteurs doivent être pris en compte :
1. Équilibre entre sécurité du système et coût de vérification
Plus le nombre de bits utilisé par le système est élevé (donc plus la sécurité est grande), plus le coût de vérification augmente. La sécurité se reflète dans le générateur de clés (par exemple, les courbes elliptiques dans SNARK).
2. Compatibilité avec les frontaux et backends
La compatibilité dépend de l’efficacité de la représentation intermédiaire (IR) du circuit. L’IR doit trouver un équilibre entre justesse (correspondance entre entrée et sortie + conformité au système de preuve) et flexibilité (support de multiples frontaux et backends). Si l’IR a été initialement conçu pour des systèmes à faible degré (low-degree) comme R1CS, il sera difficile de l’adapter à des systèmes plus avancés comme AIR.
3. Circuits façonnés manuellement (hand-crafted) pour améliorer l’efficacité
L’inconvénient des modèles généralistes est leur inefficacité pour des opérations simples ne nécessitant pas d’instructions complexes.
Un bref rappel des théories antérieures :
Avant Pinocchio : Calcul vérifiable réalisé, mais temps de vérification très lent.
Protocole Pinocchio : Offre une faisabilité théorique en termes de vérifiabilité et de taux de succès (le temps de vérification est inférieur au temps d’exécution), basé sur circuit.
Protocole TinyRAM : Par rapport à Pinocchio, TinyRAM ressemble davantage à une machine virtuelle, introduisant un ISA, ce qui permet de contourner certaines limitations comme l’accès mémoire (RAM) ou le flux de contrôle (control flow).
Protocole vnTinyRAM : Le générateur de clés ne dépend plus du programme individuel, apportant une universalité accrue. Extension du générateur de circuits pour traiter des programmes plus volumineux.
Tous ces modèles utilisent SNARK comme backend de preuve, mais en particulier pour les machines virtuelles, STARK et Plonk semblent être des backends plus adaptés, car leurs systèmes de contraintes conviennent mieux à une logique de type processeur.
À présent, nous allons présenter trois machines virtuelles fondées sur STARK : Risc0, MidenVM, CairoVM. En résumé, bien qu’elles partagent toutes STARK comme système de preuve, elles présentent des différences notables :
Risc0 exploite RISC-V pour la simplicité de son jeu d’instructions. Il compile via MLIR, une variante de LLVM-IR, supportant plusieurs langages de programmation généralistes comme Rust et C++. RISC-V offre également des avantages matériels.
Miden vise la compatibilité avec la machine virtuelle Ethereum (EVM), étant essentiellement un rollup EVM. Miden possède actuellement son propre langage, mais ambitionne de supporter Move à l’avenir.
Cairo VM est développé par Starkware. Le système de preuve STARK utilisé par ces trois plateformes a été inventé par Eli Ben-Sasson, actuel président de Starkware.
Approfondissons leurs différences :
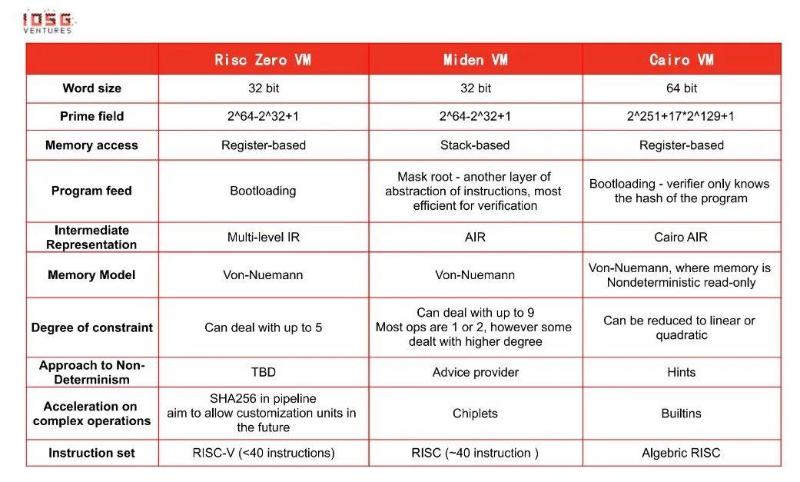
*Comment lire ce tableau ? Quelques notes...
●Word size (taille de mot) - Puisque ces machines virtuelles reposent sur un système de contraintes AIR, similaire à une architecture CPU, choisir une taille de mot standard (32/64 bits) est pertinent.
●Memory access (accès mémoire) - Risc0 utilise des registres car le jeu d’instructions RISC-V est basé sur registres. Miden utilise principalement la pile (stack), car AIR fonctionne de manière similaire à une pile. CairoVM n’utilise pas de registres généralistes car l’accès à la mémoire principale y est peu coûteux.
●Program feed (exécution du programme) - Chaque méthode comporte des compromis. Par exemple, la méthode « mast root » nécessite un décodage pendant l’exécution, augmentant ainsi le coût pour le prouveur sur des programmes longs. La méthode « bootloading » cherche à équilibrer coût du prouveur et coût du vérificateur tout en préservant la confidentialité.
●Non-déterminisme (non-determinism) - Propriété clé des problèmes NP-complets. Utiliser le non-déterminisme permet de valider rapidement des exécutions passées, mais ajoute des contraintes, entraînant un compromis sur la vérification.
●Accélération des opérations complexes - Certaines opérations sont lentes sur CPU : opérations binaires (XOR, AND), fonctions de hachage (ECDSA), vérifications d’intervalle (range-check)... Ce sont souvent des opérations natives pour la blockchain/chiffrement, mais non natives pour le CPU (sauf les opérations binaires). Les implémenter directement via un DSL peut facilement saturer les cycles de preuve.
●Permutation/multiset (permutation / multi-ensemble) - Fréquemment utilisée dans les zkVM, elle a deux buts : 1. Réduire le coût du vérificateur en évitant de stocker toute la trajectoire d’exécution 2. Prouver que le vérificateur connaît l’intégralité de la trajectoire.
Pour conclure, je souhaite aborder l’état actuel du développement de Risc0 et expliquer pourquoi il suscite mon enthousiasme.
État actuel de Risc0 :
a. L’infrastructure du compilateur propriétaire « Zirgen » est en cours de développement. Comparer ses performances à celles d’autres compilateurs ZK existants serait intéressant.
b. Des innovations prometteuses comme l’extension de corps (field extension), permettant des paramètres de sécurité renforcés et des opérations sur des entiers plus grands.
c. Face aux défis liés à l’intégration entre entreprises matérielles et logicielles ZK, Risc0 a mis en place une couche d’abstraction matérielle pour faciliter le développement côté hardware.
d. Encore en développement !
- Support de circuits sur mesure (hand-crafted circuits), prise en charge de divers algorithmes de hachage. Actuellement, un circuit spécialisé SHA256 est implémenté, mais cela ne suffit pas encore. L’auteur pense que le choix des circuits à optimiser dépendra des cas d’usage de Risc0. SHA256 est un excellent point de départ. D’autre part, le ZKVM offre de la flexibilité : par exemple, ils n’ont pas besoin de supporter Keccak s’ils ne le souhaitent pas :)
- Récursion : sujet vaste, que l’auteur préfère ne pas approfondir ici. Sachez que, avec des cas d’usage plus complexes, la récursion devient cruciale. Pour la soutenir davantage, ils travaillent actuellement sur une accélération GPU côté matériel.
- Gestion du non-déterminisme : attribut que tout ZKVM doit gérer, contrairement aux machines virtuelles traditionnelles. Le non-déterminisme peut accélérer l’exécution. MLIR excelle sur les problèmes classiques de VM ; il sera intéressant de voir comment Risc0 intègrera cette notion dans son design.
CE QUI ME PASSIONNE :
a. Simple et vérifiable !
Dans les systèmes distribués, le PoW nécessite une redondance élevée car la confiance fait défaut : on répète les mêmes calculs pour atteindre un consensus. Grâce aux preuves à zéro connaissance, atteindre un état devrait être aussi simple que convenir que 1+1=2.
b. Plus d’applications concrètes :
Au-delà de la mise à l’échelle, de nouveaux cas d’usage deviennent envisageables : apprentissage automatique à zéro connaissance, analyse de données, etc. Comparé à un langage ZK spécifique comme Cairo, Rust/C++ sont plus universels et puissants, permettant à davantage d’applications web2 de s’exécuter sur la machine virtuelle Risc0.
c. Communauté développeur plus inclusive et mature :
Les développeurs intéressés par STARK et la blockchain n’auront plus besoin d’apprendre un nouveau DSL — ils peuvent utiliser Rust/C++ directement.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














