

L'essor de ChatGPT : de GPT-1 à GPT-3, l'ère de la génération de contenu par intelligence artificielle (AIGC) arrive bientôt
TechFlow SélectionTechFlow Sélection
L'essor de ChatGPT : de GPT-1 à GPT-3, l'ère de la génération de contenu par intelligence artificielle (AIGC) arrive bientôt
L'historique du développement de ChatGPT, les principes technologiques sous-jacents et ses limites.

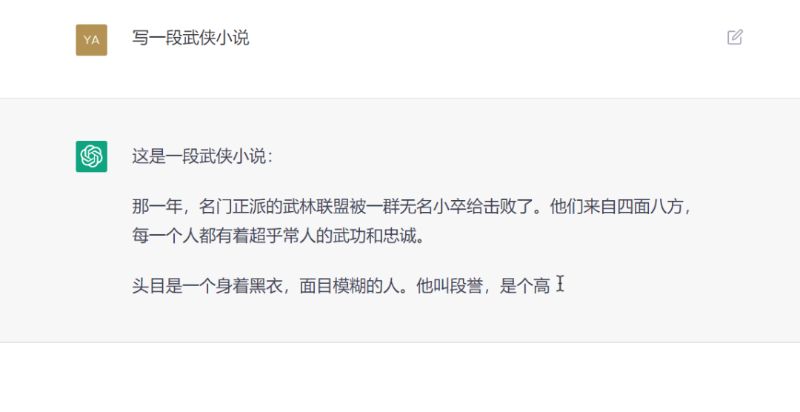
Qu'est-ce que ChatGPT ?
Récemment, OpenAI a lancé ChatGPT, un modèle pouvant interagir via un système de conversation. Grâce à son haut niveau d'intelligence, il a été très bien accueilli par les utilisateurs.
ChatGPT est également apparenté à InstructGPT, publié précédemment par OpenAI. Le modèle ChatGPT a été entraîné en utilisant la méthode RLHF (Reinforcement Learning with Human Feedback). Peut-être que l'arrivée de ChatGPT marque le prélude au lancement officiel de GPT-4 par OpenAI.
Qu'est-ce que GPT ? De GPT-1 à GPT-3
Generative Pre-trained Transformer (GPT) est un modèle de génération de texte basé sur l'apprentissage profond, entraîné à partir de données disponibles sur Internet. Il est utilisé pour des tâches telles que la réponse aux questions, la synthèse de textes, la traduction automatique, la classification, la génération de code et les systèmes de dialogue IA.
En 2018, GPT-1 est apparu, marquant ainsi l'année inaugurale des modèles pré-entraînés dans le traitement du langage naturel (NLP).
Sur le plan des performances, GPT-1 possède une certaine capacité de généralisation, ce qui lui permet d'être utilisé dans des tâches NLP indépendantes des tâches supervisées.
Ses tâches courantes incluent :
-
Inférence en langage naturel : déterminer la relation entre deux phrases (implication, contradiction, neutralité) ;
-
Questions-réponses et raisonnement commun : à partir d'un texte et de plusieurs réponses proposées, évaluer la précision de la réponse fournie ;
-
Détection de similarité sémantique : juger si deux phrases ont un sens similaire ;
-
Classification : déterminer à quelle catégorie donnée appartient un texte d'entrée ;
Bien que GPT-1 obtienne quelques résultats sur des tâches non affinées, sa capacité de généralisation reste bien inférieure à celle des tâches supervisées affinées. Ainsi, GPT-1 ne peut être considéré que comme un bon outil de compréhension linguistique, mais pas comme un assistant conversationnel.
GPT-2 est arrivé comme prévu en 2019. Toutefois, GPT-2 n'a apporté aucune innovation majeure dans la structure du réseau existant, se contentant d'utiliser davantage de paramètres et un jeu de données plus volumineux : le modèle maximal comporte 48 couches et 1,5 milliard de paramètres. L'objectif d'apprentissage repose sur un modèle pré-entraîné non supervisé appliqué à des tâches supervisées. Sur le plan des performances, outre la compréhension, GPT-2 a montré pour la première fois une puissance remarquable en matière de génération : résumé de lecture, discussion, continuation de texte, création d'histoires, voire fabrication de fausses nouvelles, d'e-mails frauduleux ou d'usurpation d'identité en ligne, tout cela devient possible. En devenant « plus grand », GPT-2 a effectivement démontré des capacités universelles et puissantes, atteignant les meilleures performances de l'époque sur plusieurs tâches spécifiques de modélisation linguistique.
Puis GPT-3 est apparu. En tant que modèle non supervisé (souvent appelé aujourd'hui auto-supervisé), il peut accomplir presque toutes les tâches de traitement du langage naturel, telles que la recherche ciblée, la compréhension de lecture, l'inférence sémantique, la traduction automatique, la génération d'articles et les systèmes de réponse automatique. Ce modèle excelle dans de nombreuses tâches : il atteint des niveaux record dans la traduction anglais-français et anglais-allemand, produit des articles quasi indiscernables de ceux écrits par des humains (avec seulement 52 % de taux de reconnaissance correcte, proche du hasard), et réalise même près de 100 % de précision dans des calculs simples d'addition et de soustraction. Il peut même générer du code automatiquement selon une description de tâche. Un modèle non supervisé aussi performant et polyvalent semble raviver l'espoir d'une intelligence artificielle générale, ce qui expliquerait probablement l'énorme impact de GPT-3.
Qu'est-ce que le modèle GPT-3 ?
En réalité, GPT-3 est simplement un modèle statistique de langage. Du point de vue de l'apprentissage automatique, un modèle de langage consiste à modéliser la distribution de probabilité des séquences de mots, c’est-à-dire à prédire, à partir d’un fragment déjà connu, la probabilité d’apparition de chaque mot suivant. Un modèle de langage permet d’une part d’évaluer dans quelle mesure une phrase respecte les règles grammaticales (par exemple, vérifier si une réponse générée automatiquement par un système de dialogue homme-machine paraît naturelle), et d’autre part de prédire et générer de nouvelles phrases. Par exemple, pour le fragment « Il est midi, allons ensemble au restaurant », un modèle de langage peut prédire quels mots pourraient suivre « restaurant ». Un modèle classique pourrait prédire « manger », tandis qu’un modèle plus avancé, capable de capter l’information temporelle, pourrait produire le mot contextuellement approprié « déjeuner ».
La puissance d’un modèle de langage dépend généralement de deux facteurs :
-
Tout d’abord, il faut examiner si le modèle peut exploiter toute l’information contextuelle historique. Dans l'exemple ci-dessus, sans capter l'information distante « midi », le modèle aurait du mal à prédire le mot « déjeuner ».
-
Ensuite, il est crucial que le contexte historique disponible soit suffisamment riche, autrement dit que les données d’entraînement soient assez variées. Comme les modèles de langage relèvent de l’apprentissage auto-supervisé, leur objectif d’optimisation est de maximiser la probabilité du texte observé, ce qui signifie que tout texte, sans besoin d’étiquetage, peut servir de données d’entraînement.
Grâce à ses performances supérieures et à son nombre nettement plus élevé de paramètres, GPT-3 couvre une plus grande diversité de sujets et surpasse clairement GPT-2.
Actuellement le plus grand réseau neuronal dense, GPT-3 peut convertir une description web en code correspondant, imiter la narration humaine, composer des poèmes personnalisés, générer des scénarios de jeux, voire imiter des philosophes disparus en tentant de prédire le sens de la vie. De plus, GPT-3 ne nécessite aucun ajustement fin : pour résoudre des problèmes grammaticaux, il lui suffit de quelques exemples du type de sortie attendue (apprentissage par quelques exemples).
On peut dire que GPT-3 semble répondre à toutes nos attentes vis-à-vis d’un expert en langage.
Quels sont les problèmes de GPT-3 ?
Toutefois, GPT-3 n’est pas parfait. L’un des principaux problèmes liés à l’intelligence artificielle aujourd’hui concerne les chatbots et outils de génération de texte, qui risquent d’apprendre aveuglément tous les textes présents sur internet, indépendamment de leur qualité, produisant ainsi des sorties erronées, offensantes ou même agressives, ce qui compromettrait sérieusement leurs applications futures.
OpenAI a également annoncé qu’il publiera bientôt un modèle encore plus puissant, GPT-4 :

Comparaison entre GPT-3, GPT-4 et le cerveau humain (Source image : Lex Fridman @youtube)
On dit que GPT-4 sera publié l’année prochaine, qu’il réussira le test de Turing et sera si avancé qu’il sera indiscernable d’un être humain. De plus, le coût d’intégration de GPT-4 par les entreprises devrait chuter massivement.
ChatGPT et InstructGPT
Évoquer ChatGPT implique de parler de son « prédécesseur », InstructGPT.
Au début de l’année 2022, OpenAI a publié InstructGPT. Dans cette étude, OpenAI a mis en œuvre une recherche d’alignement (alignment research), formant un modèle de langage plus véridique, plus inoffensif et mieux aligné avec les intentions des utilisateurs, comparé à GPT-3.
InstructGPT est une version affinée de GPT-3, capable de minimiser les sorties nuisibles, fausses ou biaisées.
Comment fonctionne InstructGPT ?
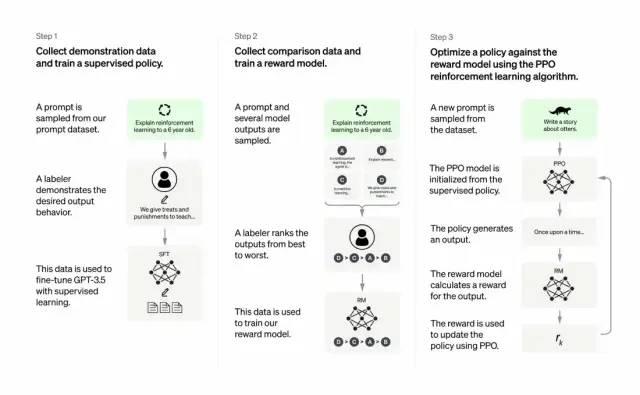
Les développeurs améliorent la qualité de sortie de GPT-3 en combinant apprentissage supervisé et apprentissage par renforcement à partir de retours humains. Dans ce processus, des humains hiérarchisent les sorties potentielles du modèle ; l'algorithme d'apprentissage par renforcement récompense ensuite les sorties similaires aux meilleures productions humaines.
Le jeu de données d'entraînement commence par des prompts, certains étant basés sur les entrées des utilisateurs de GPT-3, comme « Raconte-moi une histoire sur une grenouille » ou « Explique en quelques phrases l'atterrissage lunaire à un enfant de 6 ans ».
Les développeurs divisent les prompts en trois groupes et créent des réponses différemment pour chacun :
-
Des auteurs humains répondent au premier groupe de prompts. Les développeurs affinent alors un modèle GPT-3 pré-entraîné pour reproduire ces réponses, le transformant ainsi en InstructGPT.
-
L'étape suivante consiste à former un modèle capable de récompenser les meilleures réponses. Pour le deuxième groupe de prompts, le modèle optimisé génère plusieurs réponses. Des évaluateurs humains les classent. À partir d'un prompt et de deux réponses, un modèle de récompense (un autre GPT-3 pré-entraîné) apprend à attribuer une récompense plus élevée aux réponses bien notées et une récompense plus faible aux autres.
-
Les développeurs utilisent un troisième groupe de prompts et la méthode d'apprentissage par renforcement appelée Proximal Policy Optimization (PPO) pour affiner davantage le modèle de langage. Après avoir reçu un prompt, le modèle génère une réponse, puis le modèle de récompense attribue une récompense. PPO utilise cette récompense pour mettre à jour le modèle de langage.
Pourquoi est-ce important ?
L’enjeu central est que l’intelligence artificielle doit être une IA responsable.
Les modèles linguistiques d’OpenAI peuvent aider dans l’éducation, la thérapie virtuelle, l’assistance à l’écriture ou les jeux de rôle. Dans ces domaines, les biais sociaux, la désinformation et les contenus toxiques posent problème. Seuls les systèmes capables d’éviter ces défauts seront véritablement utiles.
Quelles sont les différences entre les processus d'entraînement de ChatGPT et InstructGPT ?
Globalement, ChatGPT, tout comme InstructGPT décrit ci-dessus, est entraîné à l’aide de RLHF (apprentissage par renforcement à partir de retours humains).
La différence réside dans la manière dont les données sont configurées pour l'entraînement (et collectées). (Explication : dans le cas précédent du modèle InstructGPT, une entrée donnait une sortie unique, comparée aux données d’entraînement, avec récompense si correcte, pénalité sinon ; actuellement, ChatGPT prend une entrée et génère plusieurs sorties, que des humains classent de « parlant comme un humain » à « absurde », afin que le modèle apprenne à reproduire ce classement humain. Cette stratégie s'appelle l'apprentissage supervisé. Remerciements au Dr. Zhang Zijian.)
Quelles sont les limites de ChatGPT ?
Les voici :
a) Durant la phase d'apprentissage par renforcement (RL), il n'existe aucune source de vérité ou de réponse standard pour répondre à vos questions.
b) Le modèle entraîné est plus prudent et peut refuser de répondre (afin d'éviter les faux positifs).
c) L'apprentissage supervisé peut induire en erreur ou biaiser le modèle vers la connaissance de la réponse idéale, plutôt que de générer un ensemble de réponses aléatoires parmi lesquelles seuls les commentateurs humains choisissent celles qui sont bonnes ou bien classées.
Remarque : ChatGPT est sensible à la formulation. Parfois, le modèle ne répond pas à une phrase, mais avec une légère reformulation de la question ou de la phrase, il finit par donner la bonne réponse. Les annotateurs ayant tendance à préférer les réponses plus longues — car elles semblent plus complètes —, cela pousse le modèle à être plus verbeux. Certains termes sont ainsi excessivement utilisés. Si l'indication initiale ou la question est floue, le modèle ne demandera pas correctement des clarifications.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














