

Deconstructing Early NVIDIA Investor Gavin Baker’s Investment Philosophy: Going Long on AI Infrastructure Bottlenecks, Going Short on Overall Market Risk
TechFlow Selected TechFlow Selected
Deconstructing Early NVIDIA Investor Gavin Baker’s Investment Philosophy: Going Long on AI Infrastructure Bottlenecks, Going Short on Overall Market Risk
“AI is not in a bubble; on the contrary, it is in a supercycle.”
Compiled & Edited by TechFlow

Hosts: Ejaaz Ahamadeen (EJ), Josh Kale (Josh)
Original Title: What The Best AI Investors Are Buying Right Now
Podcast Source: Limitless Podcast
Air Date: May 28, 2026
Editor’s Introduction
This episode centers on Gavin Baker, founder of Atreides Management and a long-term investor in Nvidia and Cerebras. His core thesis is that AI is not a bubble—but rather a supercycle driven by electricity, wafers, and compute infrastructure. Real alpha does not lie in large language models or chatbots, but in “picks-and-shovels” enablers: GPU interconnects, memory, inference chips, advanced process nodes, and power supply.
Gavin Baker hedges broad market risk using QQQ puts while concentrating positions in AI physical-bottleneck assets such as Astera Labs, Unity, Micron, Nvidia, Cerebras, and Positron. He reframes the “AI bubble” debate away from sentiment and toward hard supply constraints—arguing that as long as TSMC, ASML, high-bandwidth memory, and grid capacity cannot scale rapidly into oversupply, AI capital expenditures are unlikely to replay the 2000 dot-com crash.
Key Quotes
AI Bubble or Supercycle?
- “AI is not in a bubble; quite the contrary—it’s in a supercycle.”
- “The biggest returns aren’t in SaaS, nor in chatbots like OpenAI or Anthropic—they’re in electricity, compute, and silicon manufacturing.”
- “This isn’t the dot-com bubble, because buyers are the world’s smartest, highest-cash-flow companies—not leveraged speculators buying compute on debt.”
- “If the entire market can’t be oversupplied, it’s hard for it to collapse suddenly like a traditional bubble.”
The Real Bottlenecks: Power, Wafers, Tokens
- “Gavin’s theory is simple: focus only on bottlenecks at the AI infrastructure layer—who delivers higher performance per watt and lower token cost wins.”
- “AI labs now care intensely about one metric: how many tokens per watt of electricity.”
- “Power and wafers are two brick walls—the two key constraints limiting AI’s acceleration.”
From Pre-training to Inference and Post-training
- “Once a model is pre-trained, it doesn’t stay brilliant forever—it must absorb new information during post-training.”
- “Inference is inherently compute-intensive—which is why inference chips and inference infrastructure will be the next focal point.”
- “The cost or revenue opportunity from inference alone could be 5–10x that of pre-training compute investment.”
Vertical Small Models, On-Device Models, and Sovereign Infrastructure
- “You may not interact with Claude daily—you may instead need a personalized AI agent trained on your own data.”
- “Speed of infrastructure deployment itself is a moat: digital iteration moves far faster than physical infrastructure construction.”
“Whoever compresses months—or years—of physical deployment into weeks commands premium pricing in AI infrastructure.”
Gavin’s Investment Approach: Long Bottlenecks, Short Market Risk
- “He strongly believes AI winners will emerge—but that doesn’t mean he’s bullish on the broader market; the QQQ put is his hedge against systemic downside.”
- “TSMC effectively throttles bubble acceleration; as long as chip capacity can’t expand instantly, capex won’t spiral out of control.”
- “Gavin is like an older, steadier, more battle-tested Leopold: the former’s success is measured in decades; the latter’s, so far, in quarters.”
Assets Worth Betting On in the AI Supercycle
EJ: Gavin Baker is an extraordinarily prolific yet largely unknown AI investor. Over the past 20 years, he invested early in several AI companies before they became household names. He backed Nvidia (the leading AI GPU and accelerated computing supplier) and Cerebras (an AI chip company) early—and holds a clear, compelling view: AI is not a bubble; rather, it’s a supercycle.
He argues that by observing watts (power), wafers (silicon), and tokens (model output and computation units)—i.e., AI’s foundational infrastructure—you can identify critical bottlenecks and constraints. His conclusion is straightforward: the largest returns in AI come from power, energy, and silicon manufacturing—not SaaS, and not chatbots like Anthropic or OpenAI. Ultimately, the entire industry cascades downstream to semiconductors—the “picks-and-shovels” assets underpinning AI.
While many call AI a bubble, he sees this precisely as a generational buying opportunity—especially in AI infrastructure. He expresses this conviction with roughly $4.1 billion in assets under management (AUM).
If you hear him speak about these constraints—particularly AI infrastructure—the framework will feel familiar. We’ve previously discussed investor Leopold Aschenbrenner on this show, who has made similar allocations. The difference? Leopold has been at it for about three years; Gavin, for over two decades.
Leopold manages roughly three times Gavin’s AUM—but as show producer Luke wisely noted: You might beat Warren Buffett in a single year, but can you do it consistently for decades? Gavin Baker’s track record suggests he brings a distinct, time-tested perspective to this investment thesis.
For those unfamiliar with Gavin Baker: he’s the founder of Atreides Management (a hedge fund), and has invested in Nvidia continuously for 20 years. If you held Nvidia for two decades and remained employed, you’d already be astonishingly well-compensated—given the extraordinary returns generated.
His recent wins include Cerebras and Astera Labs (an AI data center interconnect chip company). Cerebras is an AI chip firm—the show notes its IPO valuation was staggering. There are also lesser-known companies we’ll explore in this episode, following his portfolio and reasoning to see where he believes AI investment opportunities truly lie.
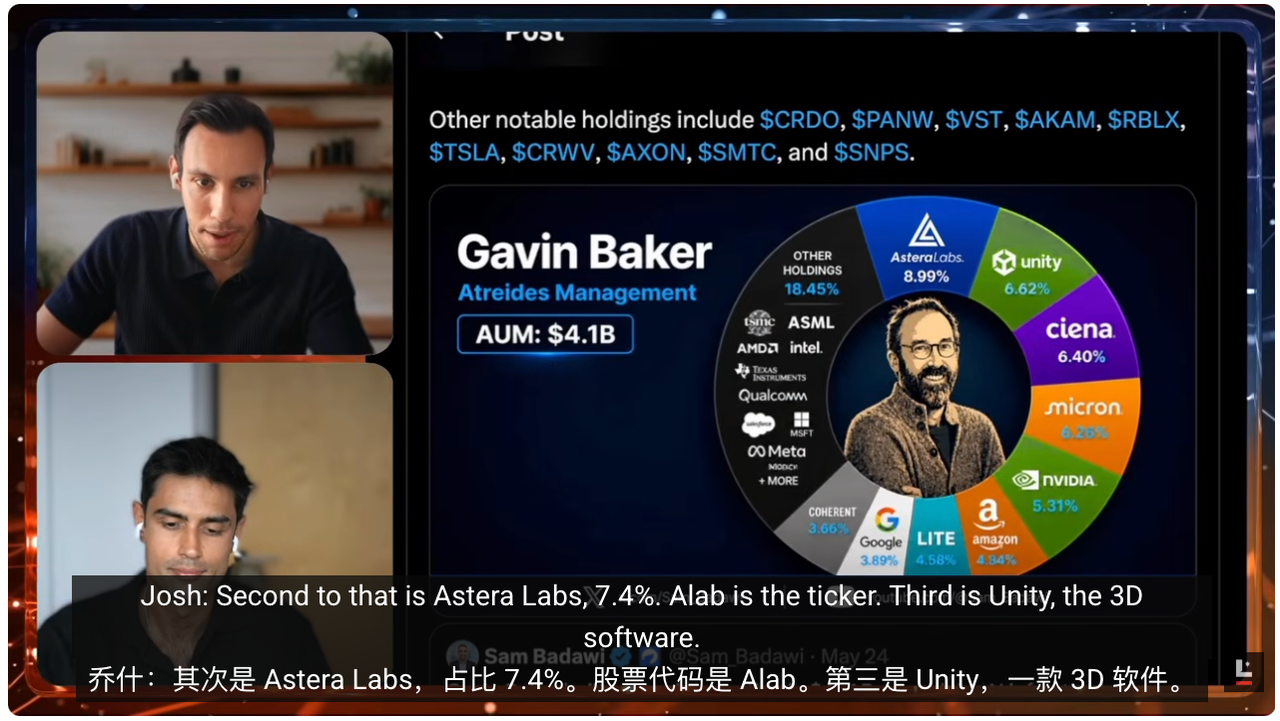
So the question becomes: what exactly has he invested in—and why? Looking at Atreides Management’s most recent 13F filing (the U.S. institutional quarterly holdings disclosure), the fund manages ~$4 billion in AUM. Breaking down its top holdings reveals firms directly tied to the AI bottlenecks Gavin repeatedly highlights.
He holds large positions in unglamorous, often obscure companies—for instance, Astera Labs, which accounts for ~9–10% of the fund. Think of Astera Labs as the interconnect layer between GPUs. Imagine a data center as a system: GPUs are the engines powering pre-training, post-training, and inference. But for GPUs to function, they must shuttle massive volumes of data among themselves—and access memory chips storing that data.
To enable this, you need a “pipeline system.” I’m speaking at a high level here—I don’t pretend to understand every technical detail. Astera Labs solves precisely this problem. When AI clusters scale to hundreds of thousands of chips, the bottleneck shifts from GPUs themselves to data-transfer bandwidth: delivering the right data, to the right place, at the right time. Astera Labs builds that pipeline.
I hadn’t heard of Astera Labs before researching this episode. But I recall Cerebras was similarly obscure when Gavin first discussed it—about six months ago. Given AI’s timescales, six months is already a long horizon. Soon after, Cerebras went public, valued at ~$60 billion, then rose another 40%. This suggests Astera Labs may be on a similar trajectory.
Josh: Cerebras was one of his earliest investments—he entered very early in the company’s lifecycle, meaning he’s bet on this thesis for many years. Other long-held positions include, most prominently, Nvidia.
Holding Nvidia for over two decades—and maintaining unwavering conviction throughout—is remarkable. I recently listened to two podcasts featuring Gavin, where he articulated clearly his view on Nvidia: he expects the company to sustain current margins and demand. That implies a potential path to a ~$10 trillion market cap—currently, it’s only halfway there.
Another notable holding is Micron (a global leader in memory chips). In our last episode, we walked through the AI investment stack and where each company fits—highly recommended for context. Micron is one of the world’s largest memory makers. The episode cites a staggering figure: its market cap was under $100 billion a year ago; at recording, it had crossed $1 trillion—a 10x increase in one year. That underscores just how critical the memory problem is.
There are also less visible but intriguing names. EJ, let me highlight one especially for you: Unity Software. Gamers know Unity as a game engine—many hit games are built with this 3D rendering software.
So why would an AI investor back Unity—the “video game company”? Answer: 3D game engines. Unity is a world model builder with deep understanding of physics, material properties, lighting, and how the real world operates. When AI labs build AGI (Artificial General Intelligence) or humanoid robots, a crucial step is simulating virtual environments and synthetic datasets for robot training. Unity happens to be one of the strongest tools for this. So if you’re a world model maxi, you’ll love this example: a company famous for game engines has a clear pathway to becoming a pivotal player in the AI world.
Gavin’s Investment Thesis and Strategy
EJ: The world model thesis is simple: today’s AI models or LLMs understand the world primarily through text and books—like a student sitting in a library—but lack real-world experience. World models unlock this: placing a video game character in a simulated environment to learn how physical reality works. For instance: what happens if I drop my phone—or kick a ball? What’s the sequence of events? How should I respond? World models solve exactly that.
Few players currently deliver this capability at scale. Google may lead—e.g., with Genie 3 (its generative interactive world model project). The episode also mentions Google’s recent Gemini Omni release—but such models haven’t yet had their “ChatGPT moment” (breakout mainstream adoption).
What I admire about Gavin is his barbell-like portfolio. One end is traditional: everyone needs GPUs and memory, so he invests in dominant players Micron and Nvidia. The other end is forward-looking: he anticipates where the puck is heading—so he bets on Cerebras, believing inference will be critical; and on Unity, believing world models will become the foundation for training robots and next-gen LLMs.
His portfolio also includes Positron, which makes inference chips. If this sounds similar to Cerebras—it is; both target inference. Gavin has repeatedly emphasized in recent interviews a key trend: the AI model infrastructure stack—especially the training stack—is shifting from pre-training toward greater emphasis on post-training.
If you’re in the AI space, you know this shift is already underway—and Gavin is laser-focused on it. A model still needs to absorb new information and update itself. It doesn’t remain brilliant for life just because it completed pre-training on a dataset. It must keep learning—and that occurs in the post-training layer, requiring massive compute.
Second, if you want an AI model to truly reason—like humans do when processing new information (“Does this interpretation hold up? Is there an alternative explanation?”)—that too demands heavy compute. Current estimates suggest inference alone generates 5–10x the cost or revenue opportunity of pre-training compute investment.
Thus, AI labs and chipmakers are undergoing major strategic pivots. You’ve seen Nvidia launch many inference-optimized GPUs to support agentic applications—and Gavin expresses his inference thesis through targeted investments.
One final fascinating point: Gavin’s take on China. In the AI race, the narrative is often “China vs. US.” China possesses a unique advantage: relatively abundant energy and expanding chip-manufacturing capacity. The U.S. struggles here—which is why much of the supply chain relies on Taiwan’s TSMC (the world’s most important advanced wafer foundry).
His view: China has a unique opportunity to build AI infrastructure—or chips—distinct from the U.S., heavily optimized for inference. You could say Gavin is spearheading U.S.-based investment in inference infrastructure. I believe this represents a massive future opportunity.
Josh: Notably, this bet isn’t purely directional. He also holds a large position in QQQ puts (put options on the Nasdaq-100 ETF). QQQ tracks the Nasdaq-100 index—a basket of 100 top stocks—and is the second-most-traded ETF in the U.S. Its performance has been exceptional: +55% in 2023, +25% in 2024, +20% in 2025, and +17% YTD in 2026.
In other words, QQQ has performed brilliantly—easy to buy, a basket of the world’s elite 100 stocks. Yet Gavin takes the opposite position. He’s not saying AI won’t win—he’s saying he wants exposure to the critical manufacturers solving real bottlenecks, while remaining cautious about overall market sentiment. The QQQ put serves as downside protection: even if AI wins long-term, he’s hedged if the broader market collapses adversely.
Four Key Investment Themes
Josh: We can break down his most critical investment bottlenecks into four categories. First: verticalized small language models (SLMs). General-purpose LLMs—like Claude or ChatGPT—are broad-spectrum models capable of answering diverse questions. But training models specifically for narrow domains or enterprise use cases is different.
These specific problems live inside enterprises—especially those deeply entrenched in a particular domain or occupying a niche. Verticalized SLMs address precisely this: they’re frontier models, highly optimized to run efficiently on proprietary enterprise data—or locally on devices.
We’ve previously discussed on-device or locally-run models. Why? Your phone or device holds vast amounts of highly personal data you may not wish to share—and companies may not be permitted to access. Examples: medical records, financial details. I saw OpenAI announce a financial AI agent that accesses your bank account—but can’t execute transactions, due to sensitive personally identifiable information (PII) like Social Security numbers and banking credentials.
Local models or SLMs solve this. Gavin strongly bets they’ll grow increasingly vital. One company he particularly favors: Apple. Though he hasn’t explicitly signaled investment interest, he views Apple as a leading device maker likely to deploy local models on hardware.
If this future unfolds, we may no longer assume Claude is your daily AI companion. Instead, you’ll want a personalized AI agent trained exclusively on your data—that’s the ultimate form of an SLM. A general version runs on your phone; enterprises likewise run highly optimized, specialized models on their proprietary data to better sell or market products.
EJ: Apple is perfectly positioned for this. I’m eagerly awaiting WWDC (Apple’s Worldwide Developers Conference)—it’s coming soon.
Josh: Yes.
EJ: Just weeks away, Apple will unveil new AI software and how it integrates with hardware. This will be hugely consequential—we’ll continue covering it, and I’m excited to discuss it.
Josh: Second pillar: sovereign infrastructure. We often say bits move faster than atoms. AI infrastructure illustrates this starkly: model quality improves near-exponentially; intelligence-per-watt and intelligence-per-token rise relentlessly.
But physical deployment speed hasn’t kept pace—and that slowness itself is a moat. Hardware is extremely complex; transistor precision approaches atomic scale. Deploying at scale in an already-strained physical world is difficult. With EVs accelerating grid strain—many regions nearing full capacity—AI now adds energy and chip constraints.
Gavin strongly bets on the fact that infrastructure is hard: building takes days, months, even years. He targets those who compress that timeline to weeks. Thus, physical deployment speed is itself a moat—and he narrows his focus to companies achieving rapid deployment.
My first example: SpaceX—and its rapid construction of Colossus (xAI’s massive AI supercluster), leased to Anthropic and potentially others. This infrastructure pillar is central to Gavin’s attention.
If you examine Leopold’s portfolio, this is equally core. Reality is simple: building things is hard—and those who build them command premium pricing. The episode notes SpaceX’s largest current revenue stream is renting data centers—not rockets. That underscores this pillar’s importance.
EJ: He cares about speed—but also cost. He repeatedly emphasizes one metric: performance per watt. What he really means is AI labs increasingly care about tokens per watt.
Consider that only ~five companies this year will spend tens—or even hundreds—of billions of dollars on GPUs, compute, and the electricity powering them. You absolutely need high bang-for-buck—especially as hyperscalers expand at this scale, making cost paramount.
Hypothetically: asking Claude costs 2¢; asking ChatGPT costs $1. Even if Claude is only 95% as intelligent, you’ll likely choose it—you get more answers for less money.
So cost-of-accessing intelligence matters enormously. This week, Microsoft and Uber announced they’re actually reducing usage of Claude Code (Anthropic’s AI coding tool) because their annual budget ran out in ~four months.
You see this reflected in Gavin’s portfolio: Cerebras, Positron, Astera Labs. He identifies highly granular infrastructure bottlenecks—and places simple, direct bets: if this company solves that bottleneck, achieves certain performance-per-watt thresholds, and drives token costs down, AI labs will buy more GPUs, more products, more of these components.
So his thesis is fundamentally simple—even if the underlying tech is complex: I focus solely on AI infrastructure bottlenecks. If a company boosts performance-per-watt and lowers token cost, it will become valuable—either via IPO or acquisition.
Josh: Within this theme, investors seeking to replicate Gavin’s trade should note four names: Astera Labs, Cerebras, SiFive (a RISC-V chip design company), and Positron. These four are pivotal in this segment.
Fourth and final theme: energy and space convergence. As noted earlier, terrestrial grids severely constrain energy supply—and building new generation capacity is extremely difficult. The episode cites a statistic: ~40% of new data centers face intense opposition—protests, lobbying—to block their siting.
Solutions fall into two buckets. First: “out-of-the-box” energy—portable, modular power. Bring the data center to the power source, powered by compact energy systems. Blue Marble—highly favored by Leopold—is in this category.
Second: orbital compute—Gavin’s current focus. The dominant, central player here is unquestionably SpaceX. It’s the only company capable of serving as the “highway to space”—launching payloads into orbit, deploying racks and data centers into low Earth orbit (LEO), and generating sufficient intelligence and power to transmit back to Earth.
I think SpaceX’s significance extends beyond SpaceX itself. I’m somewhat surprised Gavin’s portfolio doesn’t hold more space stocks—given his belief in its massive potential. Perhaps reality is it’s still too early—and SpaceX remains the linchpin unlocking the sector.
Next, watch Starship V3’s launch closely. We just saw a successful Starship flight last week. If Starship fails to operate reliably, there’s no orbital energy—and no racks-to-orbit. It’s a necessary condition, given the enormous payload requirements. So SpaceX is essential to monitor—though many second-order companies will inevitably be impacted.
Why Isn’t This Just Another Dot-Com Bubble?
Josh: Naturally, the next question is: Why isn’t this simply another dot-com bubble? Gavin has fielded this countless times—and gives a forceful, persuasive answer. I largely agree with his reasoning.
His logic: The 2000 dot-com bubble was debt-fueled. Many borrowed heavily to fund unproven theories and products nobody used or cared about.
Contrast that with Gavin’s AI supercycle: OpenAI and Anthropic alone are projected to reach $200 billion in ARR (Annual Recurring Revenue) this year—not speculative fantasy, but contracted revenue, with 40–60% reportedly prepaid by enterprise and retail customers. Real money is flowing.
Look at GPU compute demand—not from model labs, but from buyers. Google, Microsoft, Amazon, and Meta all pay Nvidia in cash—not debt. Amazon has only recently tapped the edge of its free cash flow; if they start borrowing, we’d worry. But for now, leverage remains absent.
These are five of the world’s most elite—and arguably smartest—companies, by virtue of their market cap, scale, and stature. Contrast that with the dot-com era, when countless nameless startups raised huge sums and burned cash irrationally. Here, the world’s smartest companies deploy unlevered capital.
Recent earnings reports covered on this show further confirm profits are optimizing around these investments—and models continue improving, growing smarter. So Gavin’s core argument stands: This isn’t a dot-com bubble, because it’s not leveraged capital driving it—and the bottlenecks we discuss are constrained by physical atoms.
Buying memory chips and GPUs is one thing—but Nvidia can’t oversell GPUs, and Micron can’t oversell AI memory chips, because they lack sufficient fabrication capacity. So his simple thesis is: If you can’t oversupply the entire market, it’s not a bubble. We’re limited by insufficient picks-and-shovels—and he invests precisely in those.
Another strong point: Gavin notes that if TSMC could supply demand, Nvidia could have sold $2–3 trillion worth of GPUs this year and next. In other words, TSMC sits at a critical boundary of the bubble.
Why? Because if TSMC met demand, supplying chips at that scale would consume immense capital. Currently, CapEx and operating cash flow show no major divergence—cash generation still supports construction.
But if TSMC told Nvidia tomorrow, “We can triple capacity overnight,” Nvidia wouldn’t refuse—it would spend massively on chips. Others would follow, forced to borrow—triggering a CapEx bubble widening the gap between capex and operating cash flow.
Yet constraints exist across the board: memory, chip manufacturing, energy—and especially TSMC’s lead in advanced nodes. So we simply can’t accelerate build-out that fast. Thus, TSMC acts as a brake on bubble acceleration.
As long as TSMC’s advanced-node capacity remains constrained—and Samsung and others fail to surpass its market share—growth remains relatively sustainable. It feels fast, yet vast unmet demand persists because we simply can’t build fast enough. As long as this dynamic holds, I believe the near-term outlook is sound.
EJ: Also, don’t assume demand stays static—it won’t. AI-related demand is growing exponentially—and outpacing chip production.
I can think of only two ways to falsify this thesis. First: someone miraculously replicates ASML (the sole global supplier of EUV lithography machines), spawning numerous ASML competitors overnight. For those unfamiliar: ASML builds machines costing ~$400 million—essential for TSMC and all major fabs. The episode states ASML has only one team in Norway building them, with extremely long lead times—and a backlog extending ~5 years.
Second: we invent a radically different LLM architecture requiring far fewer GPUs and memory. But we see zero evidence of this yet.
Today I saw news about SK Hynix (a leading global HBM supplier and Nvidia’s top memory partner)—the undisputed top dog in AI memory. It’s reportedly receiving $50–100 billion offers from Google and Microsoft to pre-pay for three years’ worth of future production, funding its expansion equipment.
This shows how desperate big tech is for memory—and this is just one subsegment of AI hardware. SK Hynix retorts: “I won’t guarantee supply—I’ll just raise prices.” Its operating margin sits at ~70%—unprecedented in semiconductors.
So Gavin’s all-in stance is rational. It doesn’t look like a bubble—though markets may react emotionally in the short term. Before recording, we checked the stock portfolio—nearly everything was down—but that’s mostly reactionary. The directional thesis remains clear: we’ll need ever more GPUs and semiconductors, yet supply lags—and manufacturers lag further.
Gavin’s Portfolio
Josh: The bottom line: power and wafers. Just those two. They’re the two brick walls—the dual constraints preventing runaway acceleration. As long as power and wafers retain value, demand stays strong, and supply remains tight, the runway ahead remains long.
If you want a TLDR (Too Long; Didn’t Read) of Gavin’s portfolio, here are his top holdings. Again—this is not investment advice. This reflects what Gavin holds—not what we hold. I have no idea whether these stocks will rise, fall, or stagnate.
His largest position is counterintuitive: the QQQ put. Overall, he’s bearish on the broad market—a noteworthy stance. His second-largest holding is Astera Labs (~7.4%, ticker ALAB). Third is Unity—the 3D software company.
Others follow: Ciena (optical networking), Micron, Nvidia, Amazon, Lumentum (optical communications & lasers), Alphabet (Google’s parent), Coherent (photonics & materials), Roblox (gaming platform), EchoStar (satellite comms), Twilio (cloud comms), Wayfair (furniture e-commerce). He invests across the board.
If interested, check his 13F—we’ll link it in the description. But this is Gavin’s view: bottlenecks are power and wafers. As long as those constraints persist, the trend is overwhelmingly upward. EJ, how do you digest this? How would you act on it?
EJ: Since Leopold’s 13F dropped, markets have been turbulent. Recording this episode, I’ve increasingly realized Gavin resembles an older, wiser Leopold—deeply entrenched in this space for decades. He may not manage $13 billion in AUM—but I suspect he’ll still be here in 10 years.
If you’re listening thinking, “I don’t want to chase every AI development minute-by-minute—I just want to allocate capital and let it compound over months or years,” then Gavin’s portfolio may offer meaningful reference. Of course, this is not investment advice.
His approach is more cautious, longer-term, and future-oriented. If his trend thesis materializes—as it did with early Nvidia and Cerebras bets—exponential returns could follow in the coming years. But it all rests on his core premise: We are not in a bubble.
I’m curious whether listeners agree. Clearly, most won’t engage with AI as technically or deeply as Gavin does. But after this episode—do you think we’re in a bubble? Or not? What are the strongest arguments for and against? Did we miss anything? Josh, before we wrap—do you think we’re in a bubble now?
Josh: I think we’re certainly in a bubble. The question is: what stage are we in—and that’s debatable. Right now, it looks more like an early-stage bubble, so hopefully it continues. Per Gavin, as long as TSMC keeps constraining chip capacity, we’re okay.
That’s the overall outlook. We’ve covered Leopold—his success is measured in quarters. Now we’ve covered Gavin—his success is measured in decades. Most people’s own answers probably land somewhere in between.
If you enjoyed this episode, please share it with friends. And tell us which asset class you find most compelling—not necessarily a theory, but perhaps a ticker worth watching. I find this exciting because everything is moving rapidly—both up and down—with plenty of volatility and engagement. See you tomorrow—and good morning.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News













