

X releases new open-source algorithm: What content should we really create to be more engaging?
TechFlow Selected TechFlow Selected
X releases new open-source algorithm: What content should we really create to be more engaging?
Likes are nearly worthless; conversational engagement is the real currency.
Author: David, TechFlow
On the afternoon of January 20, X open-sourced its new recommendation algorithm.
Musk’s accompanying reply was interesting: "We know this algorithm is dumb and needs major improvements, but at least you can see us struggling in real time to make it better. No other social platform would dare do this."
This statement carries two meanings. One, admitting the algorithm has flaws; two, using “transparency” as a selling point.
This marks the second time X has open-sourced its algorithm. The 2023 version hadn’t been updated in three years and had long since diverged from the actual system. This time, it's a complete rewrite—the core model has shifted from traditional machine learning to Grok’s transformer architecture, with the official claim being a “complete elimination of manual feature engineering.”
In plain terms: the old algorithm relied on engineers manually tuning parameters; now, AI directly analyzes your interaction history to decide whether to promote your content.
For content creators, this means that previous “best practices”—like “posting at optimal times” or “using specific tags to gain followers”—may no longer work.
We also took a look at the open-source GitHub repository, and with AI assistance, uncovered some hard-coded logic worth dissecting.
Algorithm Logic Shift: From Manual Rules to AI-Driven Judgment
First, let’s clarify the differences between the old and new versions—otherwise, the rest might get confusing.
In 2023, Twitter open-sourced a version called Heavy Ranker, which was essentially traditional machine learning. Engineers manually defined hundreds of “features”: whether a post contained images, how many followers the author had, how long ago it was posted, whether it included links, etc.
Then they assigned weights to each feature, tweaking endlessly to find the best-performing combinations.
The newly open-sourced version is called Phoenix—a completely different architecture. Think of it as an algorithm far more reliant on large AI models. Its core is Grok’s transformer model, the same type of technology used by ChatGPT and Claude.
The official README states bluntly: “We have eliminated every single hand-engineered feature.”
All the traditional rules based on manually extracted content features have been scrapped—entirely.
So, what does the algorithm now use to judge whether content is “good”?
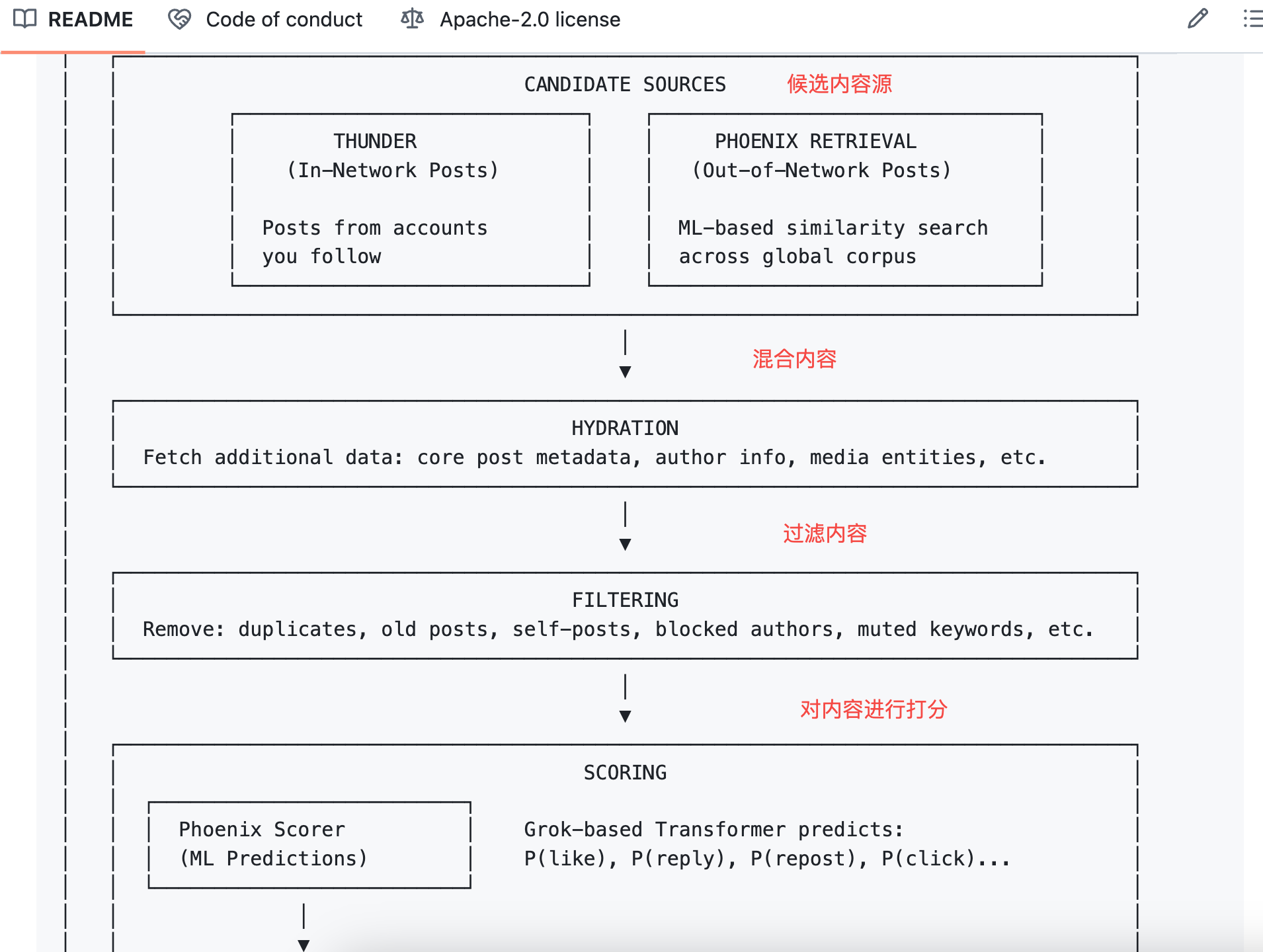
The answer lies in your behavior sequence. What you’ve liked in the past, who you’ve replied to, which posts you’ve spent over two minutes on, which accounts you’ve blocked. Phoenix feeds all these behaviors into the transformer model, letting it learn patterns and draw conclusions on its own.
To illustrate: the old algorithm was like a manually created scoring sheet where each item gets checked and scored;
The new algorithm is like an AI that has seen your entire browsing history and directly guesses what you’ll want to see next.
For creators, this implies two things:
First, tactics like “best posting times” or “golden hashtags” are now less valuable. Because the model no longer looks at fixed features—it focuses instead on individual user preferences.
Second, whether your content gets promoted increasingly depends on “how people react when they see it.” These reactions are quantified into 15 behavioral predictions—we’ll break them down in the next section.
The Algorithm Predicts Your 15 Possible Reactions
When Phoenix receives a post for recommendation, it predicts 15 possible user reactions:
- Positive actions: such as liking, replying, retweeting, quote-retweeting, clicking the post, visiting the author’s profile, watching over half of a video, expanding an image, sharing, spending significant time on the post, following the author
- Negative actions: marking “not interested,” blocking the author, muting the author, reporting
Each action is assigned a predicted probability. For example, the model might estimate a 60% chance you’ll like the post, a 5% chance you’ll block the author, etc.
Then the algorithm performs a simple calculation: multiply each probability by its weight and sum them up to produce a final score.
The formula looks like this:
Final Score = Σ (weight × P(action))
Positive actions have positive weights; negative actions have negative weights.
Posts with higher total scores appear higher in feeds; lower-scoring ones sink.
Beyond the math, here’s the essence:
Now, a post’s quality isn’t determined by how well it’s written (though readability and value remain foundational for virality), but more by “what reaction it triggers in you.” The algorithm doesn’t care about the post itself—it cares only about your behavior.
Under this logic, in extreme cases, a low-quality post that provokes strong reactions (e.g., outrage-driven replies) could score higher than a high-quality post that receives no engagement. That may indeed be the system’s underlying principle.
However, the newly open-sourced version does not disclose the exact numerical values of these behavior weights—though the 2023 version did.
Reference from the Old Version: One Report = 738 Likes
Let’s examine the 2023 dataset. Though outdated, it reveals just how differently various actions are valued by the algorithm.
On April 5, 2023, X did publish a set of weight values on GitHub.
Here are the numbers:
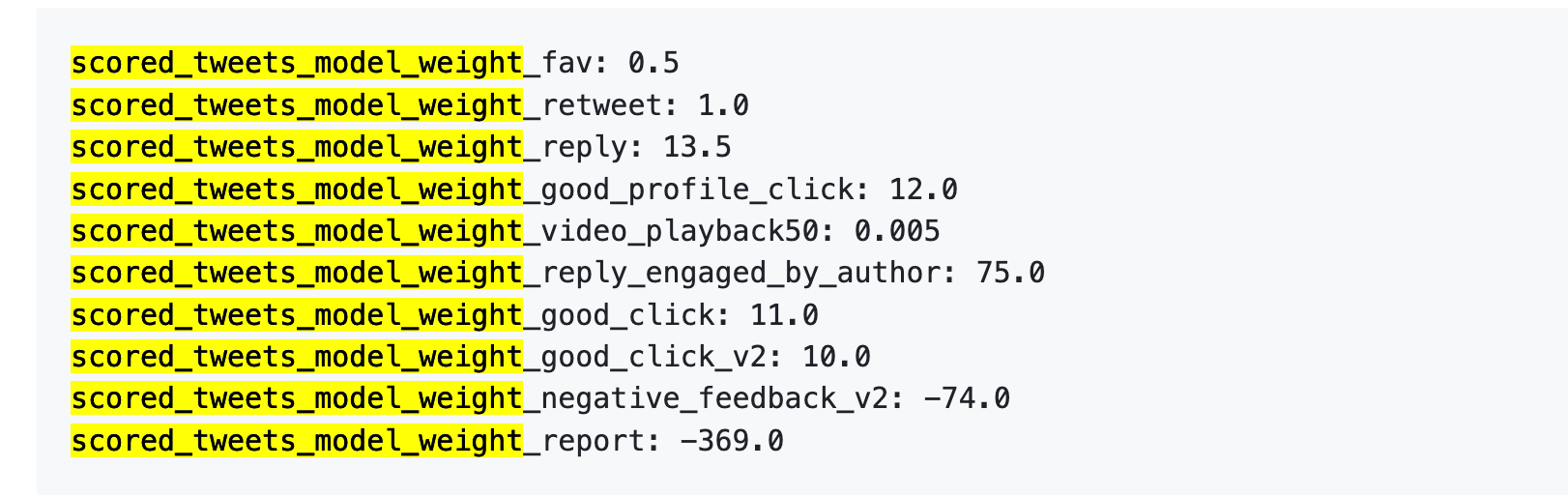
Even more plainly:

Data source: old version GitHub twitter/the-algorithm-ml repository, click to view original algorithm
A few figures stand out:
First, likes are nearly worthless. With a weight of just 0.5, it’s the lowest among all positive actions. In the algorithm’s eyes, one like is practically negligible.
Second, conversational engagement is king. “You reply, and the author replies back” carries a weight of 75—150 times that of a like. The algorithm prioritizes dialogue over one-way approval.
Third, negative feedback is extremely costly. One Block or Mute (-74) requires 148 likes to offset. One report (-369) requires 738 likes. And these penalties accumulate in your account’s reputation score, affecting distribution of all future posts.
Fourth, video completion rate has absurdly low weight. Only 0.005—effectively negligible. This sharply contrasts platforms like Douyin or TikTok, where completion rate is a core metric.
The official document also notes: “The exact weights in the file can be adjusted at any time... Since then, we have periodically adjusted the weights to optimize for platform metrics.”
Weights can change anytime—and they have.
The new version doesn’t reveal exact numbers, but the README confirms the same logic framework: positive actions add points, negative ones subtract, then sum up.
The specific values may have changed, but the relative scale likely remains. Replying to someone still matters far more than receiving 100 likes. Getting blocked is worse than receiving zero engagement.
What Can Creators Do With This Knowledge?
After analyzing both old and new algorithm code, here are several actionable takeaways:
1. Reply to commenters. “Author replies to commenter” is the highest-scoring item (+75)—150x more valuable than a like. You don’t need to solicit comments—just respond when someone engages. Even a simple “thanks” counts.
2. Avoid making users want to block you. One block costs the equivalent of 148 likes to recover. Controversial content may drive engagement, but if the response is “this person is annoying—block,” your account reputation will suffer, hurting visibility of all future posts. Controversial traffic is a double-edged sword—it cuts you first.
3. Put external links in comments. The algorithm penalizes in-post links because it doesn’t want to send users off-platform. Musk himself has publicly stated this. To share links, keep content in the main post and place the link in the first comment.
4. Don’t spam-feed. The new code includes an “Author Diversity Scorer” that downweights consecutive posts from the same creator. The goal is to diversify user feeds—but the side effect is that ten rushed posts perform worse than one well-crafted one.
6. There’s no “best posting time” anymore. The old algorithm used “post time” as a manual feature—now it’s gone. Phoenix only considers user behavior sequences, not when a post was published. Guides claiming “best results at 3 PM on Tuesdays” are becoming increasingly irrelevant.
The above insights come directly from code analysis.
Other factors affecting scores come from X’s public documentation—not included in this open-source release: Blue checkmarks provide boosts, all-caps text gets downgraded, sensitive content triggers an 80% reach reduction. These aren’t open-sourced, so we won’t elaborate.
Overall, the open-sourced material is quite substantial.
It includes full system architecture, candidate retrieval logic, ranking pipelines, and filter implementations. The codebase is primarily Rust and Python, well-structured, with a README more detailed than many commercial projects.
But several critical components remain undisclosed:
1. Weight parameters not revealed. The code states “positive actions add, negative subtract,” but doesn’t specify how many points a like is worth or how much a block deducts. At least in 2023, they published the numbers—this time, only the formulaic framework is shared.
2. Model weights not released. Phoenix uses Grok’s transformer, but the model’s internal parameters aren’t open-sourced. You can see how it’s called, but not how it computes internally.
3. Training data not disclosed. We don’t know what data trained the model, how user behaviors were sampled, or how positive/negative examples were constructed.
To put it simply: this open-source release tells you “we calculate a weighted sum,” but not the weights; it says “we use transformers to predict behavior probabilities,” but hides what’s inside the transformer.
Compared horizontally, TikTok and Instagram haven’t even released this much. X’s transparency level exceeds other major platforms—though it’s still short of “full transparency.”
That said, this doesn’t diminish the value of the release. For creators and researchers, seeing the code is always better than seeing nothing.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














