

Google's latest "banana" AI image model has sparked a frenzy among netizens for "Vibe Photoshopping"
TechFlow Selected TechFlow Selected
Google's latest "banana" AI image model has sparked a frenzy among netizens for "Vibe Photoshopping"
High character consistency brings an unprecedented "Vibe Photoshoping" experience.

Remember the mysterious AI image editing model "nano-banana" that everyone was buzzing about? Back then, it sparked intense discussions on LMArena's large language model leaderboard due to its outstanding performance. Even Google Gemini's top engineers took turns hyping it up on social media, leading many to speculate it might be the rumored Gemini 3.0 Pro.
Now, Google has finally unveiled its true identity.
In the early hours of August 27, Beijing time, Google AI Studio officially launched Gemini 2.5 Flash Image (codename nano banana) 🍌.
Gemini 2.5 Flash Image, long-anticipated and now here | Image source: Geek Park
This is Google’s most advanced image generation and editing model to date—ridiculously fast, offering a near-instantaneous, “lightning-fast” experience, while achieving SOTA results across multiple benchmarks and leading far ahead on LMArena.
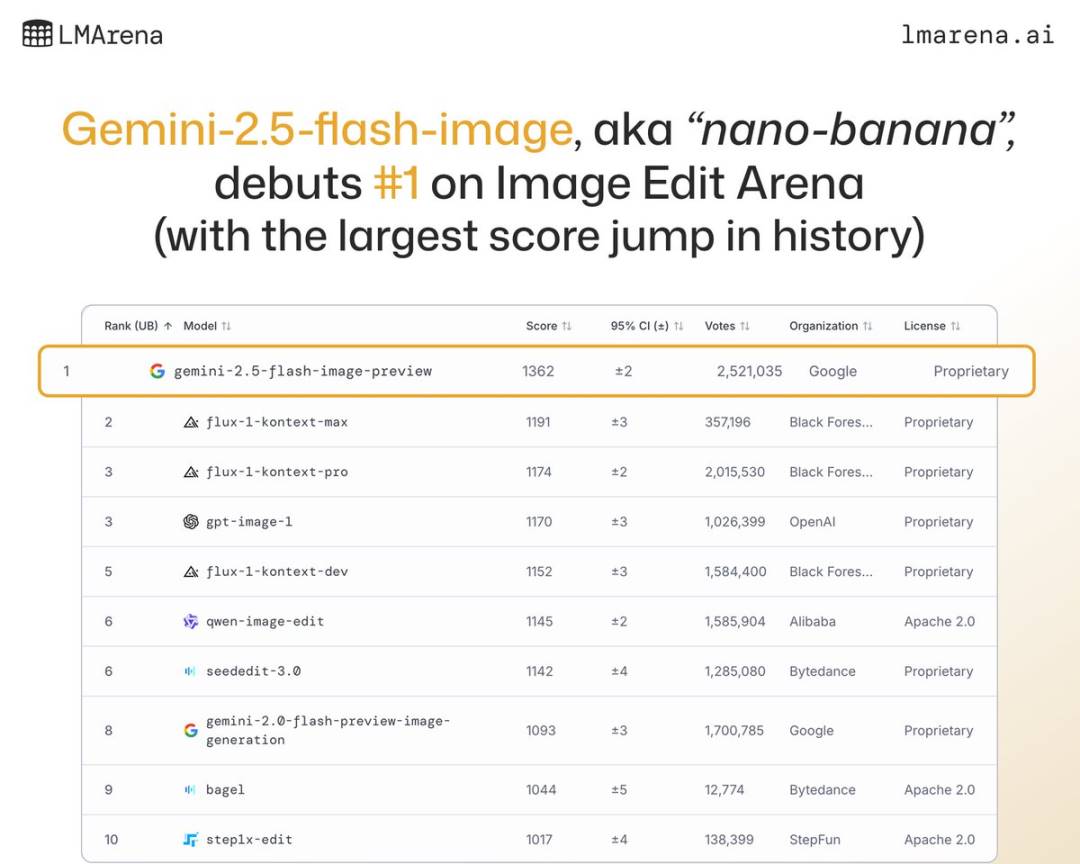
Gemini 2.5 Flash Image hits SOTA-level capabilities right out of the gate | Image source: LMarena.ai
In its technical blog, Google noted that Gemini 2.0 Flash had already won developer favor with low latency and high cost-efficiency, but users continued to demand higher image quality and stronger creative control. Gemini 2.5 Flash Image delivers these major upgrades: consistent character representation is now fully maintained, prompt-based image editing is more accurate, multi-image blending appears natural and smooth, and enhanced understanding of real-world knowledge transforms it from just another model into a foundational “origin point” for next-generation hit applications.
Geek Park tested it immediately upon release. Surprisingly, this wasn't just another model update—it gave us our first real glimpse of what AI photo editing will look like in the future.
Available for hands-on testing now within Google AI Studio | Image source: Geek Park
At first, I approached it with typical expectations—just checking how much faster the new model might be. But within just a few hours, I felt as if I’d caught an early glimpse of the next big hit application.
We’re used to tools like Meitu, where tapping buttons or applying filters quickly beautifies photos. But Gemini 2.5 Flash Image feels entirely different. It’s astonishingly fast and intelligent—like a designer who intuitively understands your intent. Just describe the desired outcome, and it renders the scene in seconds.

Beyond quality, speed is another defining aspect of Gemini 2.5 Flash Image that sets it apart from earlier image-generation models | Image source: Geek Park
01 Lightning-Fast Generation, Results in Seconds
The most immediate impression from nano banana is its speed. When using certain open-source models—even with a powerful computer—it often takes tens of seconds or longer to generate a decent image after inputting a prompt. For mobile users, this wait can be especially frustrating.
Gemini 2.5 Flash Image reduces this delay to mere seconds. Marketed by Google as the “newest, fastest, and most efficient” natively multimodal model, it clearly reflects significant optimization efforts. During my testing, entering a single prompt yielded results in about three to four seconds, with impressive resolution and detail clarity.
This experience resembles everyday photo editing in Meitu: tap the “beautify” button and see instant results. The difference? While Meitu applies pre-built algorithmic filters, Gemini 2.5 Flash Image constructs images from scratch or dramatically transforms existing photos based on your needs. This “point-and-shoot” responsiveness is unimaginable compared to traditional, tedious photo editing workflows.

Requests like “remove bystanders from background” can now be fulfilled with a single prompt | Image source: Geek Park
If speed improves the user experience for traditional photo editors, native multimodality expands the boundaries of AI image capabilities.
Gemini 2.5 Flash Image doesn’t just generate images—it simultaneously understands both text and visual inputs. This means I can provide a photo alongside a text prompt, and the model combines both to understand my intent.
For example, I uploaded a street photo and instructed it to “change the background to Tokyo Shinjuku at night.” It not only identified the main subject but also accurately extracted the person and replaced the background with a neon-lit Shinjuku streetscape. Impressively, it preserved consistent lighting and shadows on the person—avoiding the harsh, pasted-on look common in manual cutouts.
This level of understanding reminds me of a feature frequently promoted by smartphone makers in their native photo albums—“one-click background replacement.” But unlike earlier versions, which often suffered from blurry edges and mismatched lighting, Gemini 2.5 Flash Image leverages world knowledge and visual comprehension to fill in details naturally, preserving far more accurate image details than conventional text-to-image or image-to-image tools.

Original image & result generated by Gemini 2.5 Flash Image | Image source: Geek Park
This is why I believe it redefines photo editing: no longer reliant on manual adjustments, but powered by natural semantic understanding to achieve “brute-force creativity,” particularly in portrait retouching where fine details matter.

For such portrait editing tasks, Gemini 2.5 Flash Image offers an unprecedented “Vibe Photoshoping” experience through superior character consistency.

One second to save a programmer’s dignity | Image source: Geek Park
This experience breaks many people’s prior assumptions about AI image generation being “black magic”—where great prompts yield stunning results, while average ones produce wildly off-target outputs.
With Gemini 2.5 Flash Image, I found this “black magic” effect greatly reduced. Its understanding of prompts is more precise and closely aligned with human intuition—which explains why so many users instantly find it significantly more usable.
For instance, when I told it to “blur the background and highlight the foreground figure,” the output matched exactly what I wanted. When I asked to “change the person’s expression to a smile,” it not only lifted the corners of the mouth slightly but also adjusted the eyes—details were spot-on. I even tried “colorize a black-and-white photo,” and the resulting color image didn’t look randomly painted, but rather reflected authentic historical color tones.
This “say it, get it” capability contrasts sharply with past experiences in Meitu, where trying to apply subtle skin smoothing often resulted in an over-processed, “level-10 beauty filter” face. Now, Gemini 2.5 Flash Image operates precisely and subtly—it truly understands your intent and faithfully realizes it.
02 Enhanced Capabilities, Once Used, Hard to Go Back
To make the difference clearer, I directly compared it with my go-to mobile photo editing tools.
In Snapseed, blurring the background typically requires manually selecting the foreground area for one to two minutes, followed by repeated adjustments even with熟练操作.
Meitu offers a one-click background blur, but it often inadvertently blurs the edges of the person, resulting in unnatural outcomes.
With Gemini 2.5 Flash Image, all I needed was a single sentence. It automatically detected the boundary between person and background, applied a natural blur, and required zero additional touch-ups.

While modifying specific elements in the scene, it avoids the common AI tool pitfall of “random scribbling” elsewhere in the background | Image source: Twitter
This comparison highlights a key point: Gemini 2.5 Flash Image liberates users from complex operations, shifting the workload to the model itself. For average users, it lowers the barrier to photo editing; for professionals, it saves substantial time.
After extensive use, my biggest takeaway is that Gemini 2.5 Flash Image has evolved beyond a mere editing tool—it’s becoming more like an “intelligent assistant.”
In the past, using Meitu meant working with a preset collection of functions: filters, beautification, mosaics—each button mapped to a fixed action. You had to select and adjust step-by-step until satisfied.
Now, Gemini 2.5 Flash Image operates on a completely different logic. It no longer demands that you learn the tool’s interface—instead, it directly interprets your intent. You speak, and it executes.
This shift may seem subtle, but it fundamentally changes the relationship in the photo editing process. Previously, we adapted to the tool; now, the tool adapts to us. This interaction pattern is itself a prototype of next-generation applications.
From today’s vantage point, Gemini 2.5 Flash Image remains in its early stages, with functional limitations. Yet its demonstrated speed, comprehension, and fidelity are enough to spark boundless imagination for the future.
What if it were integrated into Meitu? You might open the app and say, “Touch up this photo to make my skin look more natural,” and seconds later receive a perfect result. While traveling, you could say, “Change the weather to sunny,” and instantly see a bright, sunlit version. Even video editing could allow changing an entire clip’s mood with a single sentence.

This kind of interaction could soon become standard in smartphone operating systems | Image source: Twitter
This is why I believe it will rapidly revolutionize current photo editing workflows and define the next “Meitu”: not just about retouching photos, but reshaping how we interact with image processing, turning AI into your post-production photography partner.
Still, Gemini 2.5 Flash Image isn’t yet a plug-and-play mass-market P tool. Partly because its primary focus remains image generation rather than fine-tuning existing content, and partly because every image created or edited via Gemini 2.5 Flash Image includes a SynthID digital watermark to help social platforms identify AI-generated content.
03 The Tipping Point for a Hit
Looking back, Meitu became a nationwide sensation by solving a universal desire—making photos look better—in the simplest way possible.
Gemini 2.5 Flash Image builds on that foundation, refining complex AI capabilities into a “generate-in-seconds” experience accessible to everyone.
When I first said, “Blur the background a bit,” and saw the perfectly processed result appear seconds later, I knew instantly: this is the ignition point for a breakout hit. It’s not just a model—it’s the foundational capability behind countless future products.
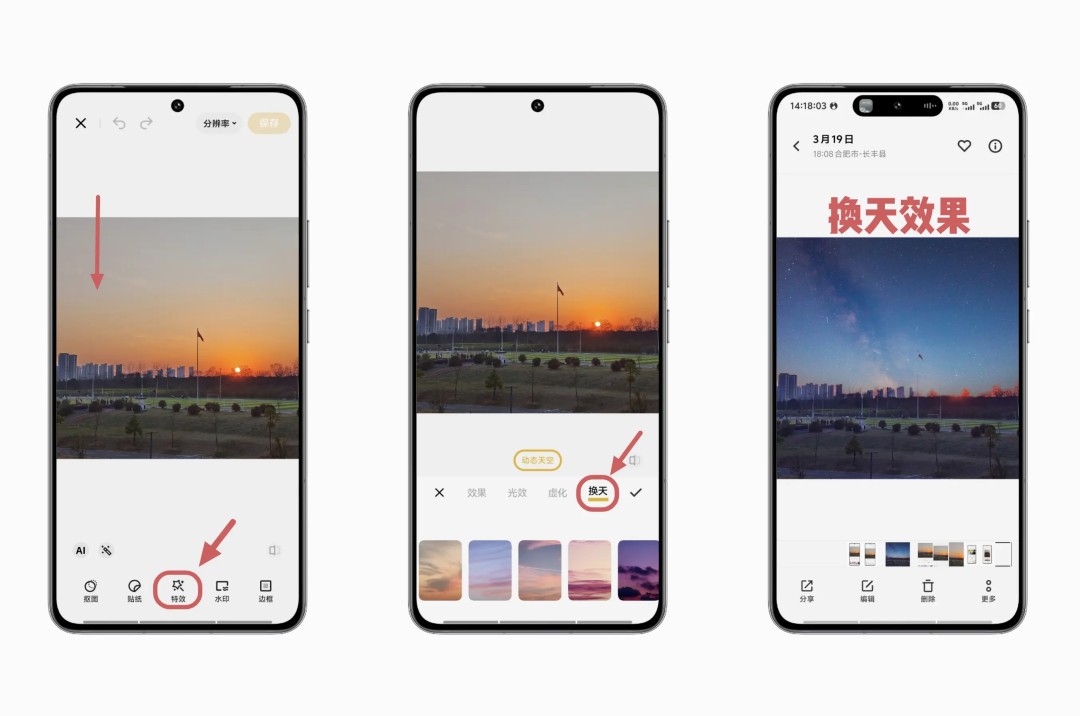
The AI-powered “sky replacement” feature that went viral among mobile users in recent years | Image source: vivo Community
In a few years, we may forget the codename “Banana,” but we’ll see more and more image editing tools delivering this “say what you want, get it instantly” experience—tools that, like Meitu before them, could become shared memories for a generation of users.
Only this time, AI will push imagination even further.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














