

Vana: Let your data freely circulate and create value like tokens in the AI era
TechFlow Selected TechFlow Selected
Vana: Let your data freely circulate and create value like tokens in the AI era
How does Vana reconstruct the data value chain in the AI era using "Data DAO" and "Proof of Contribution"?
By Siwei Guaiguai
Have you ever wondered why social media platforms like Reddit and X (formerly Twitter) are free to use? The answer lies in your daily posts, likes, and even the time you spend scrolling.
In the past, these platforms sold your attention to advertisers. Today, they’ve found an even bigger buyer—AI companies. Reports indicate that Reddit’s data licensing deal with Google alone could generate $60 million annually for the platform. Yet, none of this massive wealth flows back to you and me—the actual creators of the data.
Even more troubling is the fact that AI models trained on our data may one day replace our jobs. While AI might also create new employment opportunities, the concentration of wealth driven by data monopolies undoubtedly exacerbates social inequality. We appear to be sliding toward a cyberpunk world controlled by a handful of tech giants.
So, as ordinary individuals, how can we protect our interests in this age of AI? In the wake of AI’s rise, many have begun viewing blockchain as humanity’s last line of defense. Inspired by this vision, innovators are now exploring solutions: first, reclaim ownership and control over our personal data; second, leverage that data to collaboratively train an AI model that truly serves the public.
This idea may seem idealistic, but history shows that every technological revolution begins with a “crazy” idea. Today, a new public blockchain project called "Vana" is turning this vision into reality. As the first decentralized data liquidity network, Vana aims to transform your data into freely tradable tokens, paving the way for a truly user-controlled, decentralized artificial intelligence.

The Founders and Origins of Vana
Vana’s story traces back to a classroom at the MIT Media Lab, where two young visionaries—Anna Kazlauskas and Art Abal—met and shared a dream of changing the world.

Left: Anna Kazlauskas; Right: Art Abal
Anna Kazlauskas majored in computer science and economics at MIT. Her interest in data and cryptocurrency dates back to 2015, when she participated in early Ethereum mining—an experience that revealed to her the transformative potential of decentralization. Later, through data research roles at institutions such as the Federal Reserve, European Central Bank, and World Bank, she came to believe that data would become a new form of currency in the future.
Meanwhile, Art Abal earned a master's degree in public policy from Harvard and conducted in-depth research on data impact assessment at the Belfer Center for Science and International Affairs. Before joining Vana, Art led innovative data collection initiatives at Appen, a provider of AI training data, contributing significantly to the development of many modern generative AI tools. His insights into data ethics and AI responsibility have infused Vana with a strong sense of social mission.
When Anna and Art met during a course at the MIT Media Lab, they quickly discovered their shared passion for data democratization and user data rights. They realized that solving the problems of data ownership and AI fairness required a new paradigm—one that empowers users to truly own and control their data.
This shared vision led them to co-found Vana. Their goal was to build a revolutionary platform that not only secures data sovereignty for users but also ensures they receive economic benefits from their own data. Through innovations like the Data Liquidity Pool (DLP) mechanism and Proof of Contribution system, Vana enables users to securely contribute private data, collectively own AI models trained on that data, and share in the resulting value—driving user-led AI development.
Vana’s vision has already gained strong industry recognition. To date, the project has raised a total of $25 million in funding, including a $5 million strategic round led by Coinbase Ventures, an $18 million Series A round led by Paradigm, and a $2 million seed round led by Polychain. Other notable investors include Casey Caruso, Packy McCormick, Manifold, GSR, and DeFiance Capital.

In a world where data is the new oil, Vana presents a critical opportunity to reclaim data sovereignty. But how exactly does this promising project work? Let’s dive deeper into Vana’s technical architecture and innovative philosophy.
Technical Architecture and Core Innovations of Vana
Vana’s technical framework is a carefully designed ecosystem aimed at democratizing data and maximizing its value. Its core components include Data Liquidity Pools (DLP), Proof of Contribution, Nagoya Consensus, self-custodied data storage, and a decentralized application layer. Together, these elements form an innovative platform that protects user privacy while unlocking the full potential of data.
1. Data Liquidity Pools (DLP): The Foundation of Data Valuation
Data Liquidity Pools are the fundamental units of the Vana network, analogous to “liquidity mining” but for data. Each DLP is essentially a smart contract designed to aggregate specific types of data assets. For example, the Reddit Data DAO (r/datadao) is a successful DLP case that has attracted over 140,000 Reddit users, aggregating their posts, comments, and voting histories.
When users contribute data to a DLP, they earn DLP-specific tokens—such as RDAT for the Reddit Data DAO. These tokens represent both their contribution and grant governance rights and entitlements to future revenue shares from the pool. Notably, Vana allows each DLP to issue its own token, enabling flexible value capture across diverse data assets.
Among all DLPs, the top 16 ranked pools receive additional emissions of VANA tokens, further incentivizing high-quality data aggregation and competition. In this way, Vana transforms fragmented personal data into liquid digital assets, laying the groundwork for data monetization and liquidity.
2. Proof of Contribution: Precise Measurement of Data Value
Proof of Contribution is Vana’s key mechanism for ensuring data quality. Each DLP can customize its own contribution function, which verifies not only the authenticity and integrity of submitted data but also measures its impact on improving AI model performance.
Take the ChatGPT Data DAO as an example: its Proof of Contribution evaluates four dimensions—authenticity, ownership, quality, and uniqueness. Authenticity is verified via OpenAI’s data export link; ownership is confirmed through email verification; quality is assessed using LLMs to score randomly sampled conversations; and uniqueness is determined by computing feature vectors and comparing them against existing datasets.
This multi-dimensional evaluation ensures only high-quality, valuable data is accepted and rewarded. Proof of Contribution forms the basis for data valuation and is crucial for maintaining the overall health of the ecosystem.
3. Nagoya Consensus: Decentralized Data Quality Assurance
The Nagoya Consensus is the heart of the Vana network—a refined version of Bittensor’s Yuma Consensus. It employs a group of validator nodes to collectively assess data quality, calculating final scores through a weighted average.
More innovatively, validators don’t just evaluate data—they also rate each other’s scoring behavior. This “two-layer evaluation” greatly enhances fairness and accuracy. For instance, if a validator assigns a high score to clearly low-quality data, other validators will penalize that behavior with lower trust ratings.
Every 1,800 blocks (approximately every three hours), the system distributes rewards to validators based on their performance during the cycle. This mechanism incentivizes honest participation and swiftly identifies or removes malicious actors, ensuring the network remains robust and reliable.
4. Non-Custodial Data Storage: The Final Line of Privacy Defense
One of Vana’s most significant innovations is its unique data management approach. In the Vana network, raw user data never actually goes “on-chain.” Instead, users retain full control by storing their encrypted data wherever they choose—be it Google Drive, Dropbox, or even a personal server running on their MacBook.
When submitting data to a DLP, users only provide a URL pointing to the encrypted file and an optional content integrity hash. This information is recorded in Vana’s data registry contract. Validators request decryption keys when needed, then download and decrypt the data for verification purposes.
This design elegantly resolves the tension between privacy and utility. Users maintain complete control over their data while still participating in the data economy. This not only safeguards security but also opens doors for broader data applications in the future.
5. Decentralized Application Layer: Diversified Realization of Data Value
At the top of Vana’s stack lies an open application ecosystem. Developers can leverage the accumulated data liquidity from DLPs to build innovative apps, while data contributors earn real economic returns from these applications.
For example, a development team might train a specialized AI model using data from the Reddit Data DAO. Contributors not only gain access to use the trained model but also receive a proportional share of its generated revenue. In fact, such AI models have already been developed—see “Comeback Kid: Why Has r/datadao, an Old AI Token, Resurrected?”.
This model encourages higher-quality data contributions and fosters a truly user-driven AI development ecosystem. Users evolve from passive data providers into co-owners and beneficiaries of AI products.
Through this model, Vana is reshaping the landscape of the data economy. In this new paradigm, users transition from passive participants to active builders who share in the ecosystem’s success. This creates new value channels for individuals and injects fresh innovation and momentum into the entire AI industry.
Vana’s architecture addresses core challenges in today’s data economy—data ownership, privacy protection, and fair value distribution—while paving the way for future data-driven innovation. As more data DAOs join the network and more applications are built on the platform, Vana has the potential to become foundational infrastructure for the next generation of decentralized AI and data economies.
Satori Testnet: Vana’s Public Testing Ground
With the launch of the Satori testnet on June 11, Vana unveiled a prototype of its ecosystem. This is not just a technical trial—it’s a preview of how the mainnet will operate. Currently, Vana offers three primary ways for participants to engage: running DLP validator nodes, creating new DLPs, or contributing data to existing DLPs through “data mining.”
Running DLP Validator Nodes
Validator nodes act as gatekeepers of the Vana network, responsible for verifying the quality of data submitted to DLPs. Running a validator requires technical expertise and sufficient computational resources. According to Vana’s documentation, the minimum hardware requirements are 1 CPU core, 8GB RAM, and 10GB of high-speed SSD storage.
Interested users must first select a DLP and register as a validator through its smart contract. Once approved, they can run the validator node specific to that DLP. Notably, validators can support multiple DLPs simultaneously, though each has its own minimum staking requirement.
Creating New DLPs
For users with unique data sources or creative ideas, launching a new DLP is an appealing option. Creating a DLP requires deep understanding of Vana’s architecture, particularly the Proof of Contribution and Nagoya Consensus mechanisms.
New DLP creators must define data contribution goals, validation methods, and reward parameters. They must also implement a precise Proof of Contribution function to evaluate data value. Though complex, Vana provides detailed templates and documentation to support this process.
Participating in Data Mining
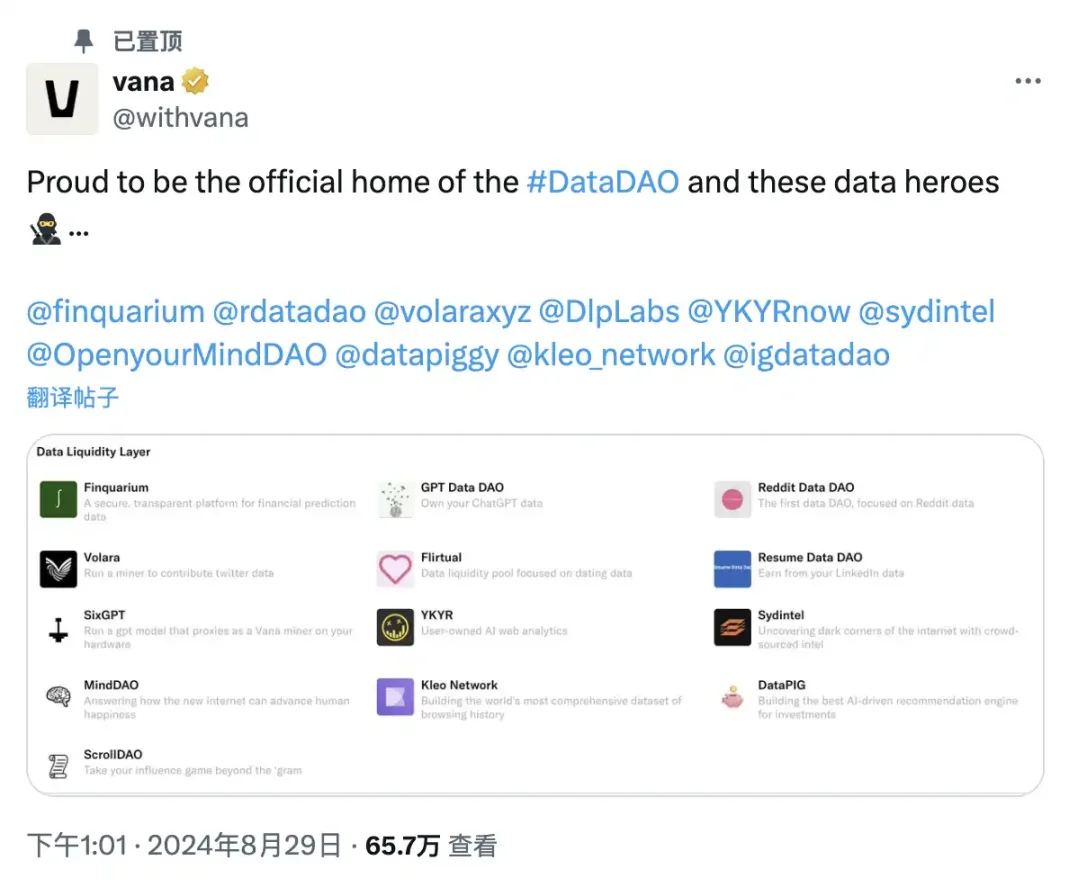
For most users, contributing data to existing DLPs via “data mining” is the most accessible entry point. Currently, 13 DLPs are officially recommended, spanning domains from social media to financial forecasting data.
-
Finquarium: Aggregates financial prediction data.
-
GPT Data DAO: Focuses on exported ChatGPT chat data.
-
Reddit Data DAO: Concentrates on Reddit user data, now officially launched.
-
Volara: Dedicated to collecting and utilizing Twitter data.
-
Flirtual: Gathers dating app data.
-
ResumeDataDAO: Focuses on LinkedIn profile exports.
-
SixGPT: Collects and manages LLM chat data.
-
YKYR: Collects Google Analytics data.
-
Sydintel: Uses crowdsourced intelligence to expose hidden corners of the internet.
-
MindDAO: Collects time-series data related to user well-being.
-
Kleo: Building the most comprehensive global browsing history dataset.
-
DataPIG: Tracks token investment preference data.
-
ScrollDAO: Collects and leverages Instagram data.
Some of these DLPs are still under development, others are live—but all remain in pre-mining phase. Formal data submission and mining will only begin after the mainnet launch. However, users can now secure early participation through various means, such as completing challenges in the Vana Telegram App or pre-registering on individual DLP websites.
Conclusion
Vana’s emergence signals a paradigm shift in the data economy. In today’s AI wave, data has become the new “oil,” and Vana seeks to reinvent how this resource is extracted, refined, and distributed.
At its core, Vana offers a solution to the “tragedy of the commons” in data. Through ingenious incentive design and technical innovation, it transforms personal data—once seen as abundant yet hard-to-monetize—into a manageable, priceable, and tradable digital asset. This not only opens new pathways for ordinary users to share in AI-generated wealth but also offers a possible blueprint for decentralized AI development.
However, Vana’s success remains uncertain. Technically, it must balance openness with security; economically, it must prove its model can generate sustained value; socially, it must navigate complex data ethics and regulatory landscapes.
On a deeper level, Vana represents a challenge to current data monopolies and dominant AI development models. It raises a critical question: in the age of AI, do we continue reinforcing existing data oligopolies, or do we strive to build a more open, fair, and pluralistic data ecosystem?
Regardless of whether Vana ultimately succeeds, its existence offers us a vital window to rethink data value, AI ethics, and technological innovation. In the future, projects like Vana may serve as crucial bridges connecting Web3 ideals with AI realities, charting a new course for the next stage of the digital economy.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News










