

Another Perspective on "AI + Blockchain": How Can AI Innovate Ethereum?
TechFlow Selected TechFlow Selected
Another Perspective on "AI + Blockchain": How Can AI Innovate Ethereum?
As on-chain computing power gradually increases, we can expect more sophisticated models to be developed for network management, transaction monitoring, security auditing, and various other aspects, enhancing the efficiency and security of the Ethereum network.
Author: Mirror Tang, Salus;
Yixin Ren, Hongshan Capital;
Lingzhi Shi, Salus;
Jiangyue Wang, Salus
Over the past year, as generative AI has repeatedly exceeded public expectations, the wave of an AI productivity revolution has swept through the cryptocurrency community. We've seen numerous AI-themed projects create a wave of wealth creation in secondary markets, while more and more developers are beginning to build their own "AI + Crypto" projects.
However, upon closer inspection, these projects suffer from severe homogenization, with most merely attempting to improve "production relationships"—for example, organizing computing power via decentralized networks or creating a "decentralized Hugging Face." Few projects attempt genuine technical integration and innovation at the foundational level. We believe this stems from a "domain bias" between the AI and blockchain fields. Despite broad overlap, few people deeply understand both domains. For instance, AI developers often struggle to grasp Ethereum’s technical implementation and historical infrastructure state, making it difficult for them to propose meaningful optimizations.
Take machine learning (ML), one of the most fundamental branches of AI: it enables machines to make decisions based on data without explicit programming instructions. ML shows immense potential in data analysis and pattern recognition and is already widely adopted in Web2. However, due to limitations of its era of origin, even in cutting-edge blockchain innovation hubs like Ethereum, architectural designs, network protocols, and governance mechanisms have yet to adopt machine learning as an effective tool for solving complex problems.
"Great innovations often emerge at interdisciplinary intersections." Our motivation for writing this article is to help AI developers better understand the blockchain world, while also offering new perspectives to Ethereum developers. In this piece, we first introduce Ethereum's technical architecture, then propose applying basic AI algorithms—specifically machine learning—to enhance Ethereum’s security, efficiency, and scalability. We hope this case study offers a fresh perspective distinct from current market trends, inspiring more innovative "AI + Blockchain" combinations within the developer ecosystem.
Ethereum's Technical Implementation
-
Basic Data Structures
A blockchain is essentially a chain of linked blocks, where key distinctions between chains are defined by chain configurations—an essential component established at genesis. For Ethereum, chain configurations differentiate various Ethereum-based chains and mark significant protocol upgrades or landmark events. For example, DAOForkBlock indicates the block height of the hard fork following the DAO attack, while ConstantinopleBlock marks the activation block of the Constantinople upgrade. Major upgrades involving multiple improvement proposals include special fields indicating corresponding block heights. Additionally, Ethereum includes various testnets and mainnets, each uniquely identified by ChainID.
The genesis block serves as the zeroth block of the entire blockchain, with all other blocks directly or indirectly referencing it. Therefore, nodes must load the correct genesis block information upon startup, which cannot be arbitrarily modified. The configuration of the genesis block includes the aforementioned chain parameters, along with additional fields such as mining rewards, timestamps, difficulty, and gas limits. Note that Ethereum has transitioned its consensus mechanism from Proof-of-Work (PoW) to Proof-of-Stake (PoS).
Ethereum accounts are divided into externally owned accounts (EOAs) and contract accounts. EOAs are controlled solely by private keys, whereas contract accounts lack private key control and can only be operated when external accounts invoke functions to execute contract code. Both types possess unique addresses. The Ethereum world state is represented as an account trie (tree), where each account corresponds to a leaf node storing its state (including balance, storage, and code).
Transactions: As a decentralized platform, Ethereum fundamentally exists to facilitate transactions and smart contracts. Blocks contain batches of transactions and supplementary metadata. Each block consists of two parts: the block header and the block body. The block header contains cryptographic evidence linking all blocks into a chain—such as the previous block hash—and roots verifying the global state: the state root, transaction root, receipt root, and additional data including difficulty and nonce. The block body stores lists of transactions and uncle block headers (though uncle references no longer exist since Ethereum's transition to PoS).
Transaction receipts provide execution results and auxiliary information not derivable from the transaction itself. These include consensus-related content, transaction details, and block context, such as whether the transaction succeeded, associated logs, and gas consumption. Analyzing receipt data helps debug smart contract code, optimize gas usage, and verify that a transaction has been processed by the network, allowing users to inspect outcomes and impacts.
In Ethereum, gas fees function similarly to transaction fees. When sending tokens, executing contracts, transferring ether, or performing any operation on the blockchain, computational work consumes network resources, requiring users to pay gas fees to incentivize validators. Ultimately, these fees compensate validators for processing transactions. The fee formula is Fee = Gas Used × Gas Price—actual consumption multiplied by unit price. Users set the gas price themselves, influencing how quickly their transaction is included; setting it too low may result in non-execution. Users must also specify a gas limit—the maximum amount of gas they're willing to spend—to prevent unexpected infinite loops or errors from consuming excessive resources.
-
Transaction Pool
Ethereum processes vast numbers of transactions. Compared to centralized systems, decentralized platforms clearly lag in transactions per second. Due to the high volume of incoming transactions, nodes maintain a transaction pool to manage them effectively. Transactions are broadcast peer-to-peer: a node relays executable transactions to neighboring nodes, who further propagate them across the network. This allows a single transaction to spread throughout the Ethereum network within approximately six seconds.
Transactions in the pool are categorized as executable or non-executable. Executable transactions have higher priority and are eventually included in blocks. All newly arrived transactions start as non-executable and become executable once certain conditions are met. These are stored separately in the pending queue (executable) and queue container (non-executable).
Additionally, the transaction pool maintains a local transaction list. Local transactions enjoy advantages such as higher priority, immunity to volume caps, and automatic reloading into the pool after node restarts. This persistence is achieved via journal files, ensuring unprocessed local transactions aren't lost and are periodically updated.
Before entering the queue, transactions undergo validity checks—including anti-DOS safeguards, negative value prevention, and gas limit validation. The transaction pool structure primarily comprises two components: queue and pending (together forming all known transactions). After passing initial checks, further validations occur—such as checking if the pool has reached capacity, or determining whether remote (non-local) transactions offer higher fees than existing ones. By default, only transactions increasing the fee by at least 10% can replace already queued transactions, and replaced transactions revert to the non-executable state. Invalid or expired transactions are removed during maintenance, and eligible replacements are applied accordingly.
-
Consensus Mechanism
Ethereum originally relied on PoW, where miners compute hashes to meet target difficulty thresholds before a block is considered valid. Since Ethereum has now transitioned to PoS, we will not elaborate on mining mechanics. Instead, we summarize the current PoS algorithm. In September 2022, Ethereum completed "The Merge," integrating the Beacon Chain to implement PoS. Under PoS, block intervals are consistently fixed at 12 seconds. Users stake ETH to qualify as validators. A random selection process chooses validator sets, and during each epoch (comprising 32 slots), one validator per slot is selected as the proposer responsible for producing a block. Other validators in that slot form a committee to attest to the proposer’s block validity and confirm the legitimacy of prior blocks. PoS significantly improves block production stability and drastically reduces energy waste compared to PoW.
-
Signature Algorithm
Ethereum inherits Bitcoin’s signature standard, using the secp256k1 elliptic curve and ECDSA (Elliptic Curve Digital Signature Algorithm). Signatures are derived from hashing the original message. A signature consists of three components: R, S, and V. Randomness is introduced during signing; R and S represent the core ECDSA output, while V is the recovery identifier, indicating how many attempts are needed to recover the public key from the signature and message, since multiple points on the curve might satisfy the R value.
The overall process works as follows: transaction data and signer-related information are RLP-encoded and hashed, then signed using the private key via ECDSA to produce the final signature. The underlying curve used in ECDSA is secp256k1. Finally, combining the signature with the transaction data yields a signed transaction ready for broadcasting.
Ethereum’s data structures go beyond traditional blockchain designs by incorporating Merkle Patricia Tries (MPT), also known as Merkle compressed prefix trees, enabling efficient storage and verification of large datasets. MPT combines the cryptographic hashing of Merkle Trees with the path compression features of Patricia Tries, providing a solution that ensures data integrity while supporting fast lookups.
-
Merkle Patricia Trie (MPT)
In Ethereum, MPT stores all state and transaction data, ensuring any change reflects in the root hash. This means verifying the root hash alone proves data integrity without needing to audit the full database. MPT consists of four node types: leaf nodes, extension nodes, branch nodes, and null nodes, collectively forming a dynamic tree adaptable to changing data. During updates, nodes are added, deleted, or modified, triggering corresponding changes to the root hash. Because every node is cryptographically hashed, even minor alterations cause dramatic shifts in the root hash, guaranteeing data security and consistency. Moreover, MPT supports “light client” verification—nodes need only store the root hash and relevant path nodes to validate specific data existence or status, greatly reducing storage and processing overhead.
Through MPT, Ethereum achieves efficient data management and rapid access, reinforcing network security and decentralization, underpinning the entire system’s operation and evolution.
-
State Machine
Ethereum’s core architecture integrates the concept of a state machine, where the Ethereum Virtual Machine (EVM) executes all smart contract code, and Ethereum itself functions as a globally shared state transition system. Each block execution represents a state transition—from one global state to another. This design ensures consistency and decentralization while making smart contract outcomes predictable and tamper-proof.
In Ethereum, "state" refers to the current information of all accounts—balances, stored data, and contract code. Whenever a transaction occurs, the EVM computes and transitions the state accordingly. This process is securely and efficiently recorded using MPT. Each state transition modifies account data and triggers MPT updates, reflected in changes to the root hash.
The relationship between EVM and MPT is crucial because MPT guarantees data integrity during state transitions. When the EVM executes a transaction and alters account states, corresponding MPT nodes are updated. Since MPT nodes are linked via cryptographic hashes, any state modification alters the root hash, which is then included in the next block, preserving the integrity and security of Ethereum’s global state. Next, we discuss the EVM.
-
EVM
The EVM is the foundation enabling smart contract execution and state transitions on Ethereum. Thanks to the EVM, Ethereum can truly be envisioned as a "world computer." The EVM is Turing-complete, meaning it can execute arbitrarily complex logic. However, the gas mechanism prevents infinite loops, maintaining network stability and security. Technically, the EVM is a stack-based virtual machine that runs Ethereum-specific bytecode. Developers typically write smart contracts in high-level languages like Solidity, which are compiled into bytecode interpretable by the EVM. The EVM is central to Ethereum’s innovation, powering smart contracts and providing a robust foundation for decentralized applications (DApps). Through the EVM, Ethereum is shaping a decentralized, secure, and open digital future.
Historical Overview
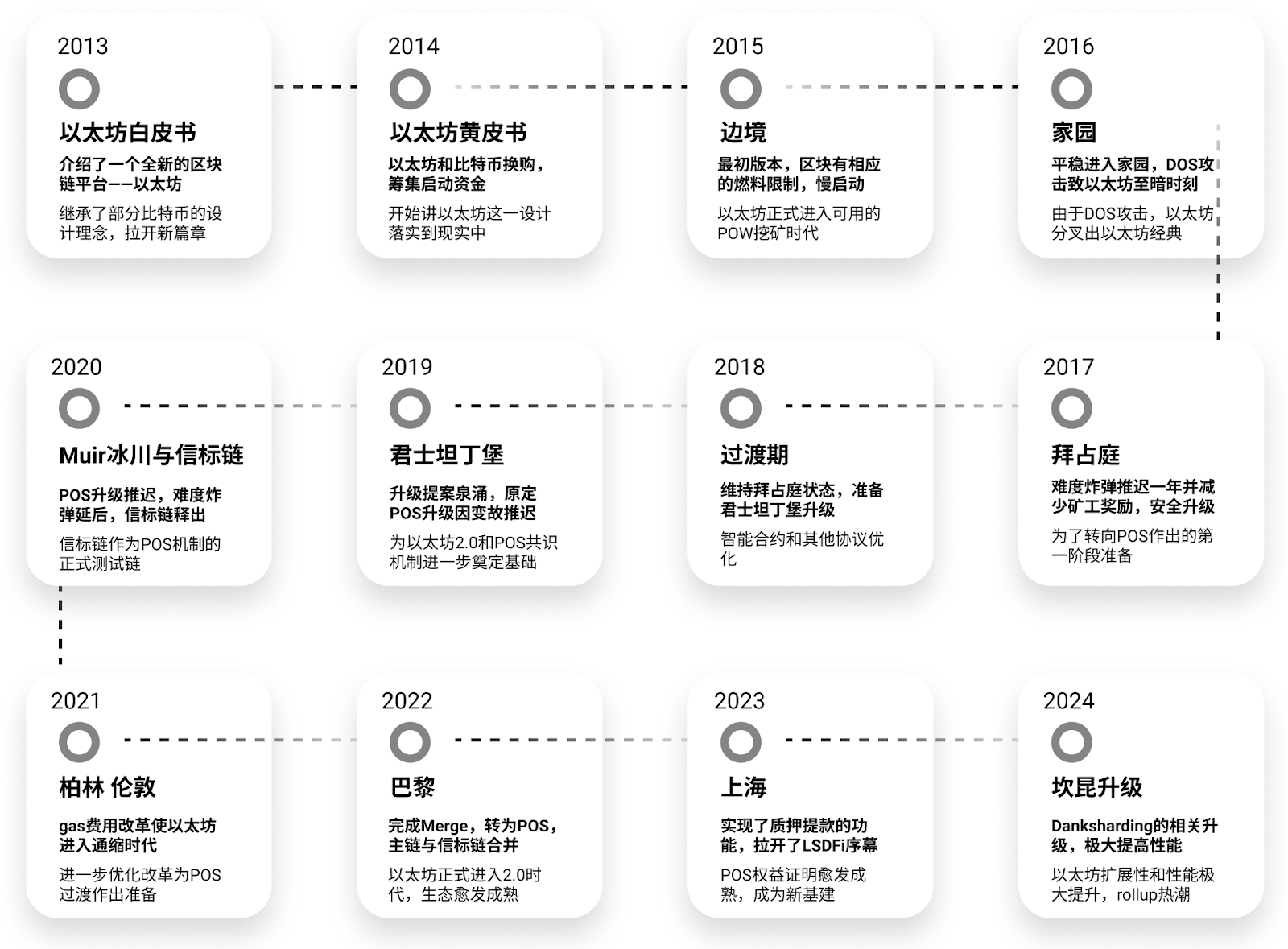
Figure 1: Ethereum Historical Overview
Challenges Facing Ethereum
Security
Smart contracts are computer programs running on the Ethereum blockchain. They allow developers to build and deploy diverse applications—including lending platforms, decentralized exchanges, insurance, crowdfunding, social networks, and NFTs. Smart contract security is critical, as these apps directly manage and control cryptocurrencies. Any vulnerability or malicious exploit poses direct financial risk, potentially causing massive losses. For example, on February 26, 2024, the DeFi lending protocol Blueberry Protocol was attacked due to a logic flaw, resulting in a loss of approximately $1,400,000.
Smart contract vulnerabilities arise from multiple sources: flawed business logic, inadequate access control, insufficient data validation, reentrancy attacks, and Denial-of-Service (DoS) attacks. These flaws can disrupt contract execution and compromise reliability. Take DoS attacks: attackers flood the network with numerous transactions to consume resources, delaying legitimate user transactions and degrading user experience. It also drives up gas prices, as users compete by bidding higher fees to prioritize their transactions under resource-constrained conditions.
Moreover, Ethereum users face investment risks threatening fund security. "Shitcoins" refer to cryptocurrencies perceived as nearly worthless or lacking long-term growth potential. Often exploited for scams or price manipulation schemes (e.g., pump-and-dump), shitcoins carry extremely high investment risk, potentially leading to substantial financial losses. Due to their low price and market cap, they are highly susceptible to manipulation and volatility. Such tokens are frequently used in rug pulls—where creators abruptly remove liquidity, collapsing the token’s value—or honeypot scams that lure investors with fake projects and steal funds. These fraudulent campaigns often use fabricated partnerships and endorsements for marketing. Once the token price rises, scammers sell off their holdings and vanish, leaving investors with worthless assets. Furthermore, investing in shitcoins diverts attention and capital away from legitimate cryptocurrencies with real utility and growth potential.
Beyond shitcoins, vaporware coins and pyramid-scheme tokens also serve as quick profit vehicles. For inexperienced users lacking expertise, distinguishing them from legitimate cryptocurrencies becomes particularly challenging.
Efficiency
Two direct metrics for evaluating Ethereum’s efficiency are transaction speed and gas fees. Transaction speed measures how many transactions Ethereum can process per unit time, reflecting network throughput—higher speeds indicate greater efficiency. Every Ethereum transaction requires a gas fee to compensate validators. Lower gas fees imply higher efficiency.
Slower transaction processing leads to higher gas fees. With limited block space, slower confirmation times increase competition among pending transactions. To stand out, users often raise their gas prices, as validators prioritize higher-paying transactions. Higher fees degrade user experience.
Transactions are just basic activities on Ethereum. Within its ecosystem, users engage in borrowing, staking, investing, insurance, and more—all facilitated by specific DApps. However, given the wide variety of DApps and the absence of personalized recommendation services akin to traditional industries, users often feel overwhelmed when choosing suitable applications. This confusion lowers satisfaction and negatively impacts the overall efficiency of the Ethereum ecosystem.
Take lending as an example. Some DeFi lending platforms enforce over-collateralization to ensure platform safety and stability. Borrowers must deposit more assets than the loan value, which remain locked during the loan period and cannot be used elsewhere. This reduces capital efficiency and dampens market liquidity.
Machine Learning Applications in Ethereum
Machine learning models such as RFM, Generative Adversarial Networks (GANs), decision trees, K-Nearest Neighbors (KNN), and DBSCAN clustering are increasingly playing important roles in Ethereum. These models can help optimize transaction processing efficiency, enhance smart contract security, enable user segmentation for personalized services, and support stable network operations.
Algorithm Introduction
Machine learning algorithms are sets of rules or instructions designed to parse data, learn patterns, and make predictions or decisions autonomously, without explicit human programming. Models like RFM, GANs, decision trees, KNN, and DBSCAN are proving valuable in Ethereum contexts—helping optimize transaction efficiency, strengthen smart contract security, enable user segmentation, and maintain network stability.
-
Naive Bayes Classifier
The Naive Bayes classifier is a statistical classification method aimed at minimizing classification error probability or average risk under specific cost frameworks. Rooted in Bayes’ Theorem, it calculates the posterior probability that an object belongs to a certain class given observed features, then assigns the object to the class with the highest posterior probability. It begins with prior probabilities, applies Bayes’ formula to incorporate observed data, and updates classification beliefs accordingly. Its key strength lies in naturally handling uncertainty and incomplete information, making it powerful and flexible across diverse applications.
As shown in Figure 2, supervised machine learning uses data and probabilistic models based on Bayes’ Theorem for classification. Using likelihoods and priors of classes and features, the classifier computes posterior probabilities for each category and assigns data points to the class with the maximum posterior. In the scatter plot on the right, the classifier seeks a boundary curve that best separates differently colored points, minimizing misclassification.
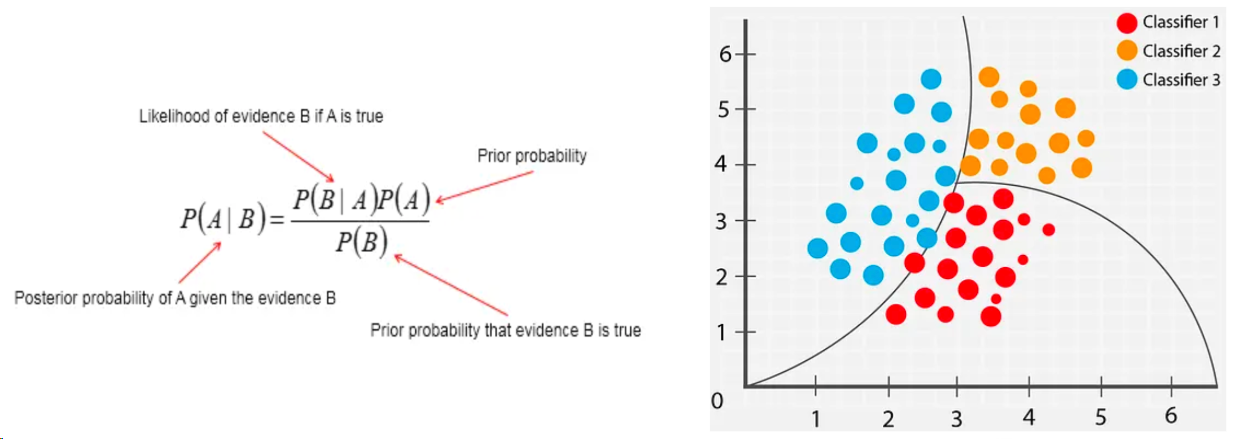
Figure 2: Naive Bayes Classifier
-
Decision Tree
Decision trees are commonly used for classification and regression tasks. They follow a hierarchical decision-making approach, splitting data based on features with high information gain ratios to train a tree-like model. Essentially, the algorithm learns decision rules from data to predict variable values. Complex decisions are broken down into simpler sub-decisions, each branching from parent criteria, forming a tree structure.
As illustrated in Figure 3, each node represents a decision criterion based on a feature, branches denote outcomes, and leaf nodes represent final predictions or classifications. Decision tree models are intuitive, easy to interpret, and highly explainable.
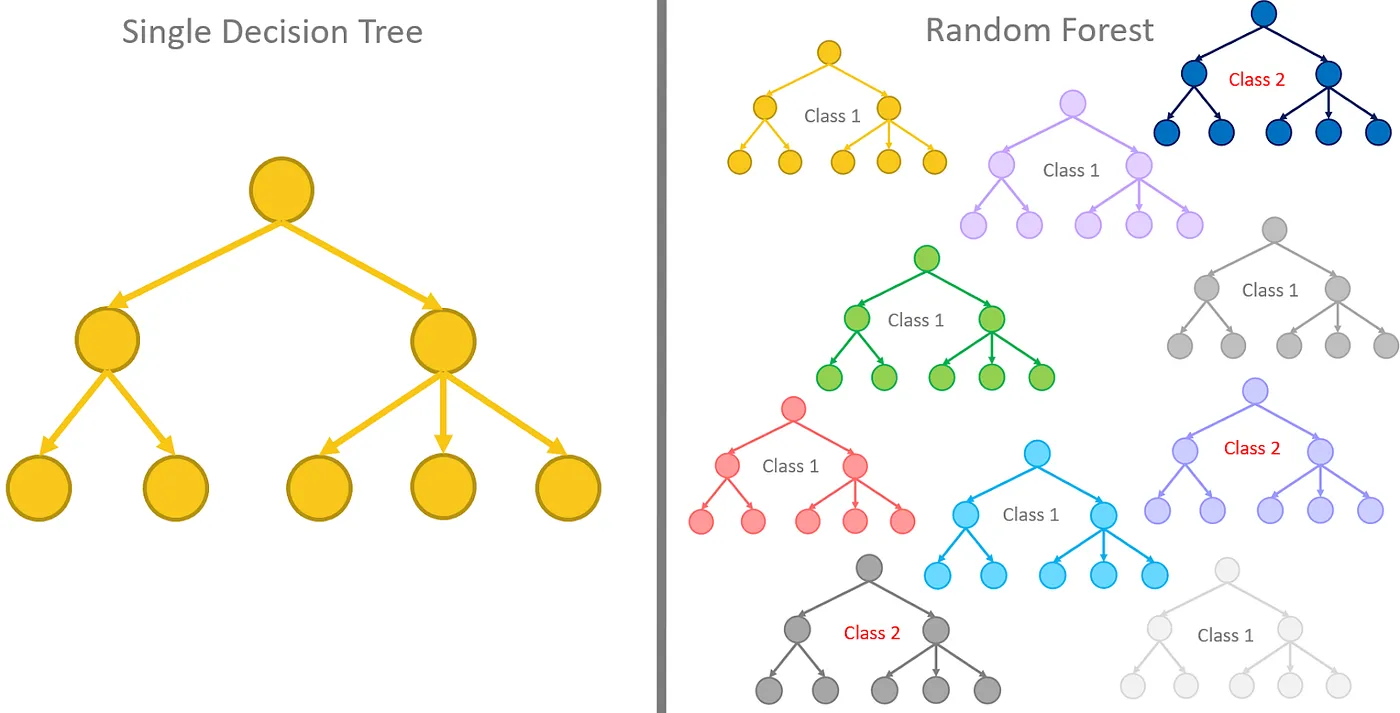
Figure 3: Decision Tree Model
-
DBSCAN Algorithm
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) identifies clusters based on density, excelling with disconnected or irregularly shaped datasets. It discovers arbitrary cluster shapes without predefining the number of clusters and demonstrates strong robustness against outliers. DBSCAN effectively detects anomalies in noisy datasets—points in low-density regions are labeled as noise, as shown in Figure 4.
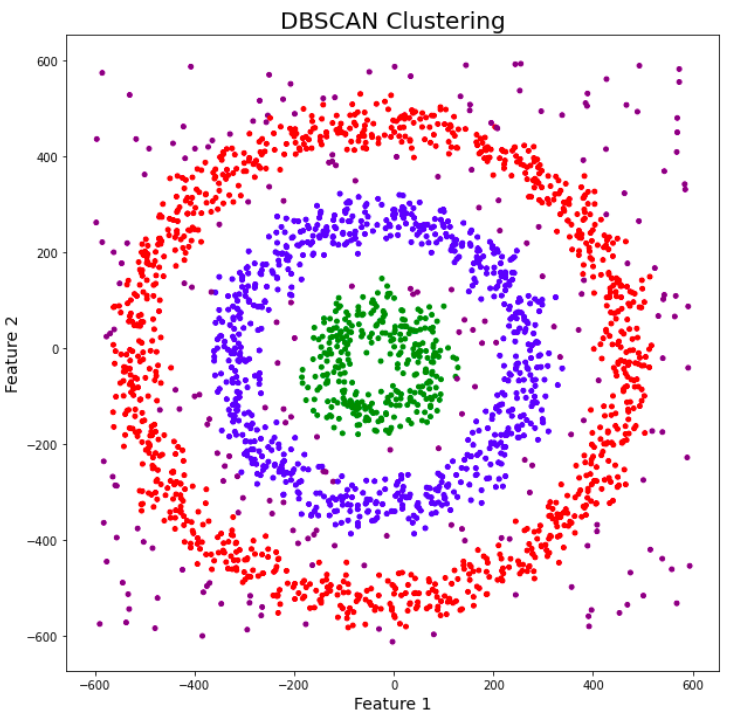
Figure 4: DBSCAN Identifying Noise
-
KNN Algorithm
K-Nearest Neighbors (KNN) applies to both classification and regression. In classification, it uses voting among the K nearest neighbors to determine the class. In regression, it predicts using the average or weighted average of the K nearest samples.
As shown in Figure 5, KNN finds the K closest neighbors to a new data point and predicts its class based on neighbor labels. If K=1, the point adopts the class of its nearest neighbor. For K>1, majority voting determines the predicted class. In regression, the prediction is the mean (or weighted mean) of the K nearest outputs.
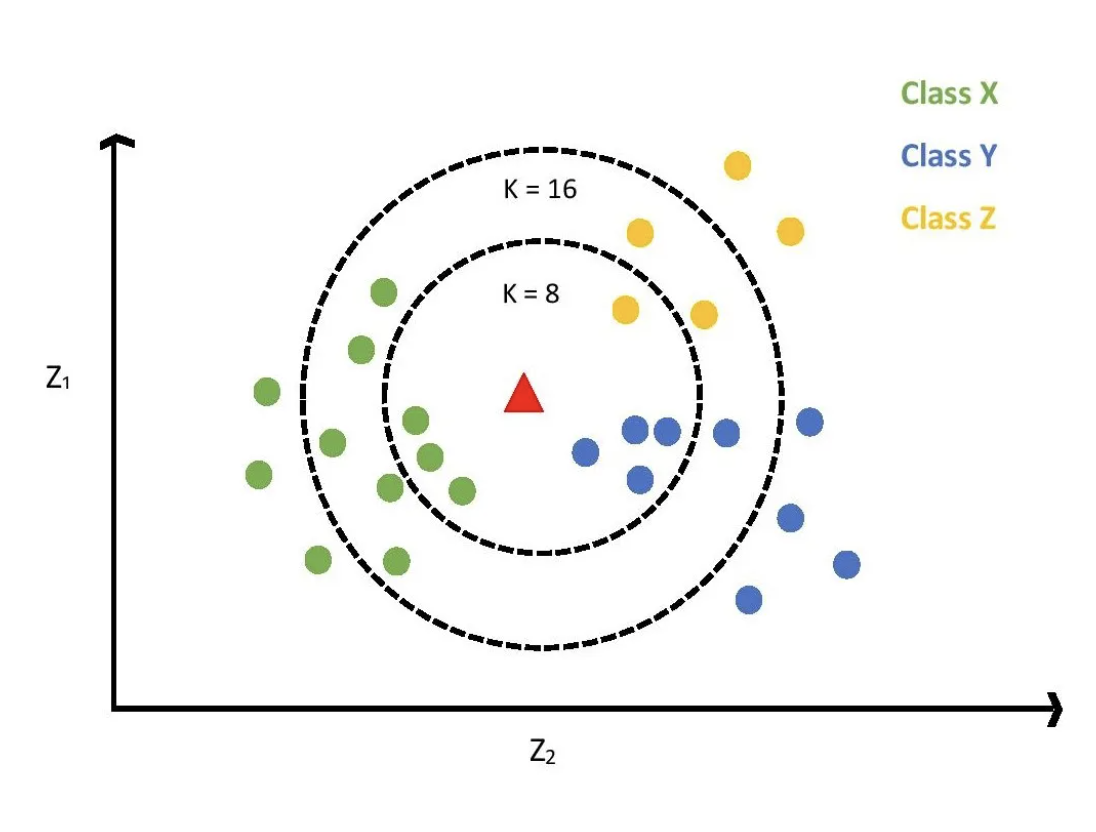
Figure 5: KNN for Classification
-
Generative AI
Generative AI is an AI technology capable of generating new content—such as text, images, music—based on input prompts. Built on advances in machine learning and deep learning, especially in natural language processing and image recognition, generative AI learns patterns and relationships from vast datasets and uses this knowledge to produce novel outputs. The key lies in model training, which requires high-quality data. During training, models analyze dataset structures, patterns, and correlations, progressively enhancing their ability to generate realistic content.
-
Transformer
The Transformer, foundational to modern generative AI, innovatively introduced the attention mechanism, enabling models to focus on key information while maintaining global context awareness. This capability has made Transformers excel in text generation. Leveraging advanced natural language models like GPT (Generative Pre-trained Transformer), user requirements expressed in natural language can be understood and automatically converted into executable code—lowering development barriers and significantly boosting efficiency.
As shown in Figure 6, the introduction of multi-head attention and self-attention mechanisms, combined with residual connections and fully connected neural networks, alongside prior word embedding techniques, has dramatically elevated the performance of generative models in natural language processing.
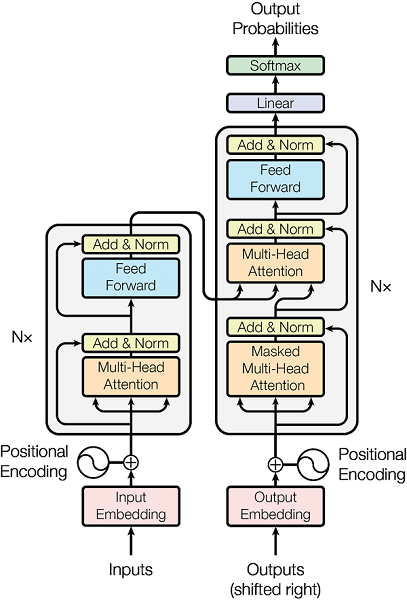
Figure 6: Transformer Model
-
RFM Model
The RFM model analyzes user purchasing behavior by segmenting users based on three dimensions: Recency (R)—how recently a user transacted; Frequency (F)—how often they transact; and Monetary value (M)—how much they spend. Together, these metrics form the core of the RFM framework.
As shown in Figure 7, the model scores users across these three dimensions, ranks them, and identifies high-value customer segments. This enables effective user segmentation and targeted engagement strategies.
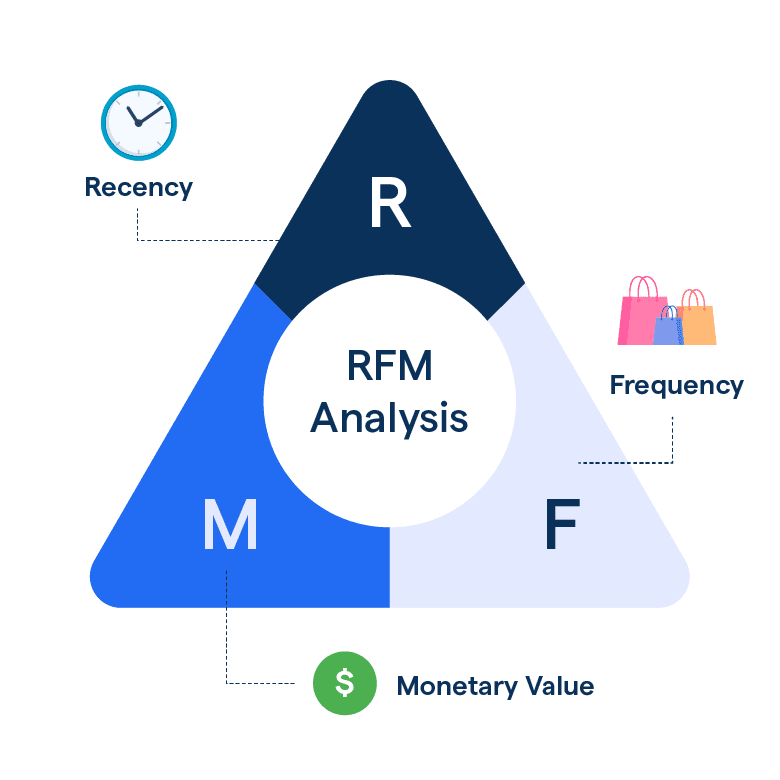
Figure 7: RFM Segmentation Model
Potential Applications
When applying machine learning to address Ethereum’s security challenges, we explored four primary approaches:
-
Using Naive Bayes Classifier to Identify and Filter Malicious Transactions
By constructing a Naive Bayes classifier, potentially harmful transactions—such as those involved in DoS attacks characterized by high frequency, small amounts, and repeated submissions—can be detected and filtered. This method analyzes transaction features like gas price and frequency to effectively maintain network health and ensure stable operation.
-
Generating Secure Smart Contract Code That Meets Specific Requirements
Both Generative Adversarial Networks (GANs) and Transformer-based generative models can generate secure, requirement-compliant smart contract code. However, they differ in training data: GANs primarily learn from insecure code samples, while Transformer models train on large corpora of secure, well-written contracts.
Training a GAN involves learning patterns from existing secure contracts, building a self-adversarial model to generate potentially vulnerable code, and refining detection capabilities—ultimately enabling automated generation of high-quality, secure smart contracts. Alternatively, Transformer-based models trained on extensive secure contract examples can generate purpose-built, gas-optimized code, significantly improving development efficiency and security.
-
Risk Analysis of Smart Contracts Using Decision Trees
Using decision trees to analyze smart contract characteristics—such as function call frequency, transaction values, and source code complexity—can effectively identify potential risk levels. By examining runtime behavior and code structure, possible vulnerabilities and risk points can be predicted, offering developers and users a safety assessment. This approach could significantly enhance smart contract security within the Ethereum ecosystem, reducing losses from bugs or malicious code.
-
Building Cryptocurrency Evaluation Models to Reduce Investment Risk
By applying machine learning algorithms to analyze multidimensional data—including trading activity, social media sentiment, and market performance—a predictive evaluation model can be built to assess the likelihood of a cryptocurrency being a "shitcoin." Such models can provide investors with valuable insights, helping them avoid risky investments and promoting healthier market development.
Beyond security, machine learning also holds promise for enhancing Ethereum’s efficiency. We explore three key dimensions:
-
Applying Decision Trees to Optimize Transaction Pool Queuing
Decision trees can effectively optimize Ethereum’s transaction pool queuing mechanism. By analyzing transaction attributes such as gas price and size, decision trees can improve transaction selection and prioritization. This approach significantly enhances processing efficiency, reduces network congestion, and shortens user wait times.
-
User Segmentation for Personalized Services
The RFM model (Recency, Frequency, Monetary value), widely used in CRM, evaluates users based on their last transaction time, transaction frequency, and spending amount to enable effective segmentation. Applying RFM on Ethereum helps identify high-value user groups, optimize resource allocation, and deliver personalized services—improving user satisfaction and overall platform efficiency.
DBSCAN can also analyze user transaction behaviors to identify distinct user clusters, enabling customized financial services. This segmentation strategy optimizes marketing efforts and enhances customer satisfaction and service efficiency.
-
Credit Scoring Using KNN
The K-Nearest Neighbors (KNN) algorithm can analyze Ethereum users’ transaction histories and behavioral patterns to generate credit scores—crucial for financial activities like lending. Credit scoring helps institutions evaluate borrowers’ repayment capacity and credit risk, enabling more accurate lending decisions. This mitigates over-lending and improves market liquidity.
Future Directions
From a macro-level resource allocation perspective, Ethereum—as the world’s largest decentralized computer—can never invest too heavily in infrastructure. Attracting developers from diverse backgrounds to co-build is essential. In this article, we reviewed Ethereum’s technical architecture and existing challenges, proposing several intuitive applications of machine learning. We eagerly anticipate AI developers in the community turning these visions into tangible, impactful solutions.
As on-chain computational power grows, we foresee increasingly sophisticated models emerging for network management, transaction monitoring, security auditing, and more—enhancing Ethereum’s efficiency and security.
Looking further ahead, AI- or agent-driven governance mechanisms could become a major innovation in the Ethereum ecosystem. Such systems could enable faster, more transparent, and automated decision-making, leading to more flexible and reliable governance structures. These future directions will not only drive technological innovation on Ethereum but also deliver superior on-chain experiences for users.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News













