

Vana sắp ra mắt mainnet, có thể trở thành cơ sở hạ tầng trong thời đại dữ liệu AI Agent hay không?
Tuyển chọn TechFlowTuyển chọn TechFlow
Vana sắp ra mắt mainnet, có thể trở thành cơ sở hạ tầng trong thời đại dữ liệu AI Agent hay không?
Ảnh hưởng của bạn thực tế lớn hơn nhiều so với những gì bạn tưởng tượng.
Tác giả: TechFlow
Khi BTC vượt mốc 100.000 USD, trong bối cảnh kỳ vọng về thị trường tăng giá, ngày càng có nhiều vốn đang tìm kiếm các dự án và cơ hội mới.
Nhưng nếu bạn hỏi hiện tại lĩnh vực nào tiềm năng nhất? Vậy thì AI Agent chắc chắn phải được nhắc đến. Tuy nhiên, khi mỗi ngày đều có hàng loạt AI Agent ra đời, câu chuyện của toàn bộ lĩnh vực này cũng đang dần phân tầng:
Một là các ứng dụng xoay quanh AI Agent, với token tương ứng đại diện cho Meme hoặc mục đích sử dụng của Agent đó; còn lại là nhóm tập trung vào hạ tầng cung cấp năng lực cho AI Agent, giúp các ứng dụng hoạt động tốt hơn.
Nhóm đầu tiên do dễ quan sát ở lớp ứng dụng nên đang ngày càng trở nên đông đúc, cạnh tranh gay gắt; trong khi đó nhóm thứ hai lại có không gian đột phá lớn hơn.
Vậy đối với một AI Agent, những năng lực nào là nhu cầu thiết yếu?
Có lẽ chúng ta có thể tìm câu trả lời từ "KOL AI" đang nổi gần đây – aixbt:
Theo nghiên cứu, những gì aixbt nói không phải lúc nào cũng đúng, nó không thể phân biệt thật giả, không yêu cầu chuyên gia xác minh giả thuyết, cũng không tự chất vấn bản thân.
Về bản chất, aixbt thực chất là một mô hình ngôn ngữ lớn (LLM), chỉ có thể thu thập và tổng hợp dữ liệu công khai, vì vậy giống như một máy lặp lại thông tin công khai.

Do đó, nếu bạn cung cấp cho các AI Agent này loại dữ liệu đa dạng hơn, cá nhân hóa hơn và riêng tư hơn, rất có thể hiệu suất của chúng sẽ được cải thiện.
Ví dụ, chia sẻ kinh nghiệm giao dịch altcoin vốn hóa thấp, hay chiến lược đầu tư chỉ được trao đổi trong nhóm trả phí để AI học hỏi... Nhưng những dữ liệu này không nằm trên bề mặt, các aixbt không thể tiếp cận được.
Lưu ý rằng, thế giới này không thiếu dữ liệu, mà thiếu dữ liệu chất lượng cao.
Trong cơn sốt AI Agent hiện nay, hạ tầng xử lý dữ liệu thực sự đang bị thiếu hụt.
Đây chính là khoảng trống kể chuyện và chênh lệch thông tin: nếu có dự án nào có thể thu thập dữ liệu cá nhân và riêng tư hơn, sau đó cung cấp cho các AI Agent hoặc tổ chức có nhu cầu, rất có thể sẽ tìm được vị trí sinh thái độc đáo trong đợt sốt này.
Hai tháng trước, chúng tôi từng viết về một dự án tên là Vana, sử dụng mô hình DAO để thu thập các loại dữ liệu không có sẵn trên thị trường công khai, đồng thời dùng cơ chế mã hóa token để khuyến khích đóng góp dữ liệu và định hướng việc mua bán, sử dụng dữ liệu này.
Tuy nhiên, lúc đó AI Agent chưa nóng như hiện tại, nên các tình huống sử dụng của dự án dường như chưa rõ ràng. Trong làn sóng AI Agent lần này, Vana rõ ràng có thêm nhiều đất diễn và môi trường phù hợp hơn.
Đúng lúc Vana sắp ra mắt mainnet và phát hành token $VANA, đồng thời cập nhật whitepaper và kinh tế học token, giải thích chi tiết hơn về vấn đề dữ liệu hiện tại và định vị của mình.
Trong thị trường tiền mã hóa, timing rất quan trọng. Vana hiện tại có những thay đổi và động thái mới nào đáng chú ý? Liệu token có thêm nhiều triển vọng tích cực?
Chúng tôi đã đọc kỹ whitepaper mới phát hành, để giúp bạn nhanh chóng hiểu rõ Vana hiện tại.

"Đôi hoa" dữ liệu – Khoảng trống lợi nhuận bị bỏ quên
Không nghi ngờ gì, mọi người đều đang theo đuổi lợi nhuận trong cơn sốt AI Agent.
Bất kỳ ai cũng có thể dễ dàng tạo AI Agent, tài sản tương ứng với AI Agent cũng có thể dễ dàng mã hóa thành token... Nhưng ngoài việc mua token của AI Agent, bạn còn có thể kiếm lợi nhuận bằng cách nào khác?
Câu hỏi này, với cá nhân là cơ hội mới, với dự án là không gian kể chuyện mới.
Đừng quên, AI Agent có thể đang dùng dữ liệu bạn từng đóng góp để tự huấn luyện, nhưng bạn chưa kiếm được đồng nào từ điều đó. Như ví dụ aixbt ở trên, các chủ đề tiền mã hóa mà nó phân tích, một phần nguồn gốc có thể chính là bài viết bạn từng đăng trên Twitter.
Vì vậy, khi mở whitepaper mới của Vana, một khái niệm ngay vài trang đầu đã thu hút sự chú ý của tác giả: vấn đề "đôi hoa" (double spend) dữ liệu.

"Double spend" – cái tên này có vẻ vừa quen vừa lạ?
Khái niệm này thực chất bắt nguồn từ vấn đề Bitcoin giải quyết – ngăn chặn cùng một Bitcoin bị chi tiêu hai lần.
Bitcoin giải quyết vấn đề này bằng cách ghi chép minh bạch lịch sử giao dịch lên blockchain công khai, như một cuốn sổ cái bất biến, tất cả đều biết lịch sử sở hữu của một đồng coin, đảm bảo mỗi đồng coin chỉ được chi tiêu một lần tại trạng thái hiện tại.
Nhưng trong lĩnh vực dữ liệu, vấn đề này phức tạp hơn nhiều.
Khác với Bitcoin, dữ liệu vốn dĩ có thể sao chép vô hạn, dẫn đến một nghịch lý kinh tế bị bỏ qua trong cơn sốt AI: khi dữ liệu bị bán trực tiếp, người mua có thể dễ dàng sao chép và phân phối lại, khiến cùng một dữ liệu thực tế được sử dụng nhiều lần, trong khi bạn không nhận được lợi ích bổ sung nào từ việc sử dụng đó.
Ví dụ, bạn viết một bài tweet, một khi bị AI Agent nào đó sử dụng và học hỏi, có thể bị chia sẻ vô hạn cho các AI Agent khác, cuối cùng làm mất đi tính khan hiếm và giá trị kinh tế của dữ liệu đó.
Nếu bạn muốn xây dựng một cuốn sổ cái kiểu Bitcoin, ghi lại việc sử dụng dữ liệu trên chuỗi để tránh vấn đề "double spend", liệu có khả thi?
Thứ nhất, dữ liệu đôi khi mang tính riêng tư, ghi chép công khai là không phù hợp, bạn cũng không muốn chia sẻ; thứ hai, dù bạn ghi lại việc sử dụng dữ liệu, vẫn không thể đảm bảo dữ liệu không bị sao chép và bán lại bên ngoài chuỗi. Thứ ba, ai cũng muốn chiếm dữ liệu miễn phí của bạn, ai sẽ sẵn lòng tham gia hệ thống sổ cái "lợi mình nhưng bất lợi người khác" này?
Vậy, có cách nào giải quyết vấn đề "double spend" dữ liệu?
Như whitepaper của Vana nêu: "Quyền sở hữu dữ liệu và việc sáng tạo dữ liệu tập thể không loại trừ nhau".
Chúng tôi tóm tắt nhanh whitepaper này, phiên bản "quá dài không đọc":
Giao thức Vana đưa ra một giải pháp sáng tạo, kết hợp khéo léo bảo vệ quyền riêng tư, quyền truy cập lập trình được và cơ chế khuyến khích kinh tế, tạo ra một mô hình kinh tế dữ liệu hoàn toàn mới.
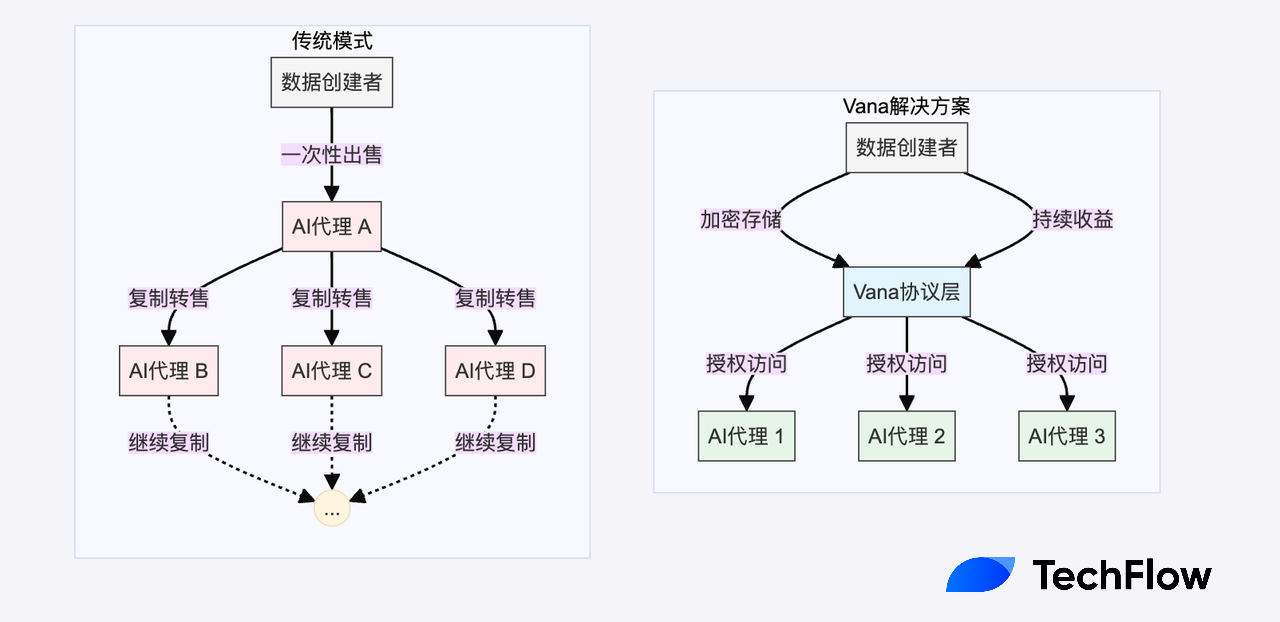
Trong mô hình này, dữ liệu luôn được giữ ở trạng thái mã hóa, chỉ các thực thể được ủy quyền mới có thể truy cập dưới điều kiện cụ thể; thứ hai, thông qua hợp đồng thông minh, chủ sở hữu dữ liệu có thể kiểm soát chính xác ai được truy cập và dưới điều kiện nào; quan trọng hơn, quyền truy cập này có thể được mã hóa thành token và giao dịch, trong khi dữ liệu gốc luôn được bảo vệ.
Một phép so sánh dễ hiểu hơn là mô hình streaming trong ngành công nghiệp âm nhạc hiện đại:
Không bán trực tiếp file nhạc (sẽ dẫn đến sao chép vô hạn), mà như dịch vụ streaming Spotify, mỗi lần sử dụng đều tạo ra doanh thu.
Chủ sở hữu dữ liệu không bán dữ liệu một lần, mà giữ quyền kiểm soát, đồng thời liên tục nhận lợi nhuận từ mỗi lần dữ liệu được sử dụng. Điều này đảm bảo dữ liệu được tận dụng tối đa (ví dụ để huấn luyện AI), giải quyết vấn đề "bán một lần rồi mất giá" do sao chép vô hạn, đồng thời chủ sở hữu luôn giữ toàn quyền kiểm soát dữ liệu của mình.
Dùng DAO làm bể, lập một "hợp tác xã dữ liệu"
Cụ thể, Vana sẽ làm gì?
Chúng ta có thể sơ bộ chia những người tham gia thị trường AI thành hai nhóm – các công ty/AI Agent cần dữ liệu; và các cá nhân/tổ chức (chủ động hoặc bị động) đóng góp dữ liệu.
Để tạo ra một AI Agent chất lượng cao hơn, ngoài dữ liệu công khai, nhu cầu của họ rất rõ ràng:
-
Truy cập dữ liệu riêng tư (private data), như dữ liệu sức khỏe của bạn dành cho AI chẩn đoán y tế
-
Truy cập dữ liệu trả phí (paywalled data), như bài viết và phân tích trả phí, phục vụ AI phân tích kinh doanh
-
Truy cập dữ liệu nền tảng đóng (closed platform data), như nhiều bài đăng hơn từ người dùng X (Twitter), phục vụ AI phân tích dư luận
Còn về phía người đóng góp dữ liệu (có chủ ý hay vô tình), nhu cầu của bạn không ngoài mấy điểm sau:
-
Bạn có thể truy cập, nhưng quyền sở hữu dữ liệu vẫn thuộc về tôi;
-
Bạn có thể truy cập, nhưng dữ liệu phải được lưu trữ ở nơi an toàn;
-
Bạn có thể truy cập, nhưng tôi phải được hưởng lợi, trả phí theo nhu cầu
Mô hình sử dụng dữ liệu truyền thống thường đặt người dùng vào vị thế thụ động. Ví dụ, khi công ty AI cần dữ liệu huấn luyện, họ hoặc mua trực tiếp từ nền tảng mạng xã hội (người dùng không được hưởng lợi), hoặc phải thương lượng riêng với hàng vạn người dùng (hiệu suất cực thấp).
Vana giải quyết vấn đề này bằng cách gọi là Bể thanh khoản dữ liệu (Data Liquidity Pool - DLP). Bạn có thể hiểu đơn giản đây là một "hợp tác xã dữ liệu":
Người dùng có thể tập trung quyền truy cập dữ liệu của mình vào một "bể", hình thành tổ chức ảo kiểu hợp tác xã; điều này đồng nghĩa người dùng tập thể có sức mạnh đàm phán tập thể, đồng thời vẫn giữ quyền kiểm soát dữ liệu gốc dưới dạng mã hóa.
Hãy tưởng tượng một DLP gồm 100.000 người dùng Twitter: khi công ty AI muốn sử dụng dữ liệu này, họ có thể đàm phán trực tiếp với DLP, và lợi nhuận sẽ tự động phân phối công bằng cho tất cả người đóng góp.
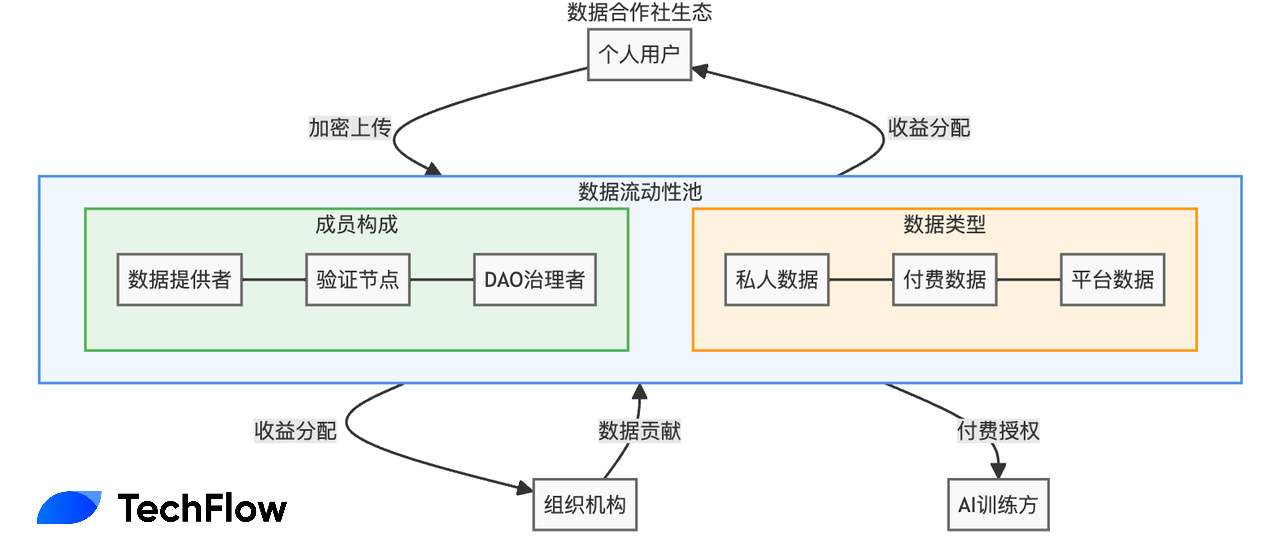
Theo nội dung whitepaper mới đây của Vana, "hợp tác xã dữ liệu" (DLP) này hiện đã được vận hành bài bản, hình thành 4 quy tắc chính:
-
Quy chuẩn dữ liệu: Hướng dẫn nhập hội
Giống như tiêu chuẩn nhập hội nghiêm ngặt, định nghĩa các tiêu chuẩn metadata, như dữ liệu mạng xã hội, dữ liệu sức khỏe... Cốt lõi là đảm bảo bể chỉ chứa dữ liệu đạt yêu cầu về chất lượng.
-
Cơ chế xác thực: Nhân viên kiểm tra chất lượng của hợp tác xã dữ liệu
Đánh giá chất lượng và giá trị dữ liệu nhập bể, đảm bảo dữ liệu tham gia là thật, tức các nút xác thực theo nghĩa truyền thống trong blockchain.
-
Kinh tế học token: Dùng phần thưởng điều chỉnh hành vi thành viên
Thông qua hệ thống điểm công bằng, khuyến khích người đóng góp dữ liệu chất lượng cao; dữ liệu càng nhiều, càng tốt, càng nhận được nhiều phần thưởng token.
-
Quy tắc quản trị: Hiến chương hợp tác xã
Quy định cách ra quyết định, ví dụ mở bể dữ liệu mới; đồng thời quy định cách xử lý tranh chấp, nơi cũng thể hiện rõ đặc trưng DAO quen thuộc với chúng ta.
Tổng thể, "hợp tác xã dữ liệu" này trong ngữ cảnh thế giới mã hóa giống như một DAO tập trung vào ra quyết định và khuyến khích xung quanh dữ liệu, DAO quản lý bể dữ liệu, quyết định quy tắc đàm phán với người dùng dữ liệu và cách phân phối lợi nhuận.
Nếu cảm thấy cách nói trên quá đơn giản, thì khi áp dụng vào thiết kế mạng Vana, mô hình DAO này thực tế đang vận hành theo cách nghiêm túc về mặt kỹ thuật:
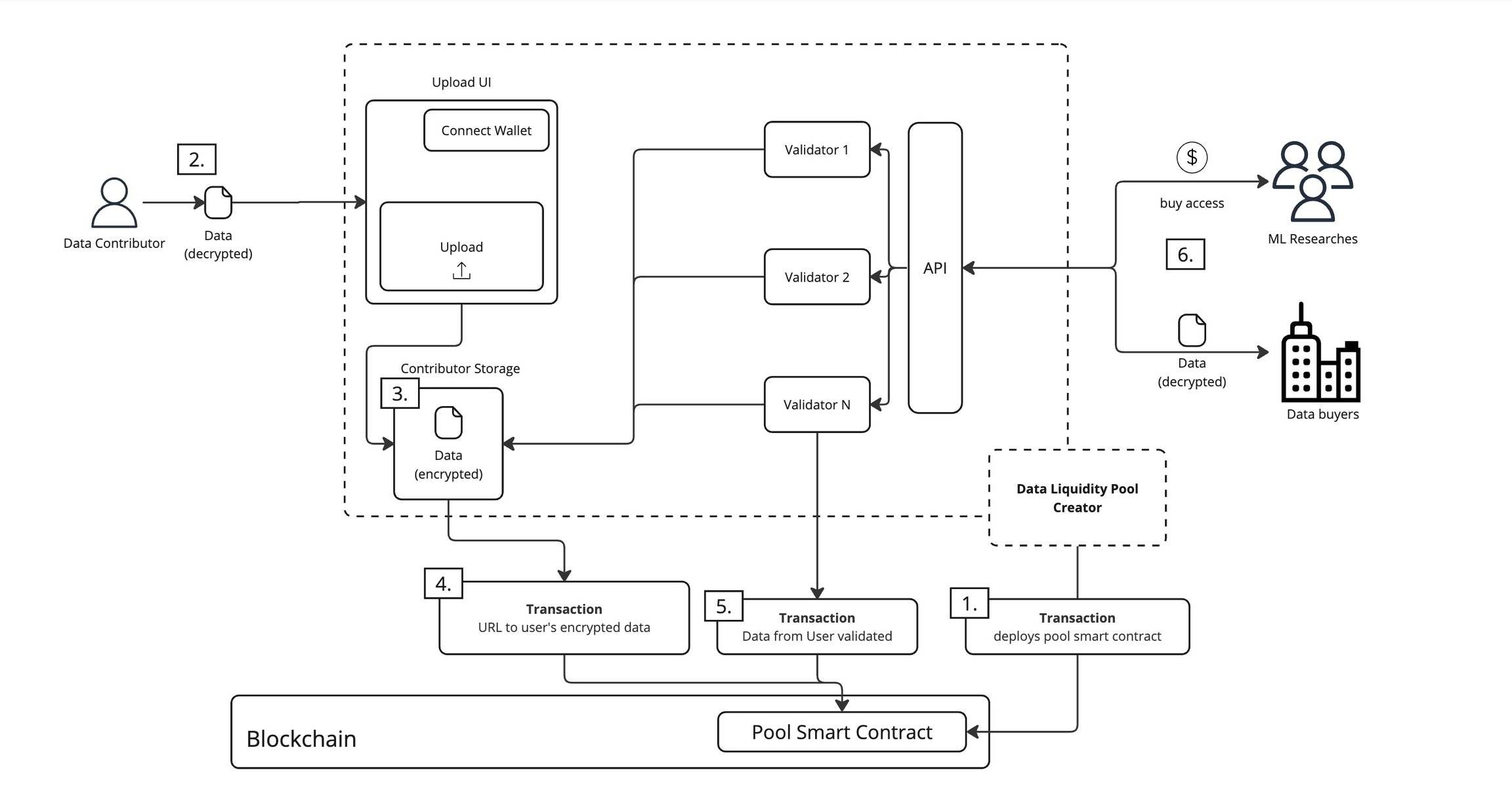
-
Triển khai hợp đồng thông minh. Người sáng lập DAO triển khai hợp đồng thông minh của bể lên blockchain, quy định rõ ràng cách quản lý, sử dụng dữ liệu và phân phối lợi nhuận.
-
Chuẩn bị dữ liệu. Người cung cấp dữ liệu chuẩn bị dữ liệu muốn đóng góp, dữ liệu này đã được mã hóa trước khi cung cấp.
-
Lưu trữ an toàn. Người cung cấp dữ liệu cần kết nối ví để xác minh danh tính trước khi tải lên dữ liệu. Dữ liệu mã hóa được tải lên sẽ được lưu trữ trong không gian lưu trữ riêng biệt của người đóng góp.
-
Ghi chép trên chuỗi. Hệ thống sẽ ghi địa chỉ truy cập dữ liệu mã hóa lên blockchain, đảm bảo chỉ những người được ủy quyền mới có thể truy cập dữ liệu.
-
Xác thực đa lớp. Nhiều bên xác thực sẽ kiểm tra dữ liệu, đánh giá tính chân thực, chất lượng và giá trị. Kết quả xác thực được ghi vào hợp đồng thông minh, đảm bảo độ tin cậy của dữ liệu.
-
Sử dụng theo quy định. Dữ liệu đã được xác thực có thể được hai loại người dùng sử dụng: nhà nghiên cứu học máy có thể trả phí để dùng dữ liệu huấn luyện mô hình; người mua dữ liệu có thể truy cập dữ liệu dưới điều kiện cụ thể. Mọi việc sử dụng đều phải trả phí và tuân thủ nghiêm ngặt điều kiện sử dụng do hợp đồng thông minh quy định.
Về bảo vệ quyền riêng tư dữ liệu, do giới hạn độ dài và kiến thức kỹ thuật, tác giả không đi sâu chi tiết.
Nếu lo lắng dữ liệu có bị rò rỉ, chỉ cần nắm rõ luồng chính sau: mọi dữ liệu cá nhân trong Vana luôn được giữ ở trạng thái mã hóa, giống như được đặt trong két sắt mà chính người dùng nắm chìa khóa. Ngay cả khi cần xử lý dữ liệu, cũng chỉ có thể thực hiện trong môi trường an toàn đặc biệt (TEE), giống như phòng thanh toán đặc biệt trong ngân hàng, mọi thao tác đều được giám sát và ghi chép chặt chẽ.
Đặc biệt, hệ thống kết hợp hợp đồng thông minh và cơ chế mã hóa để đạt được kiểm soát truy cập linh hoạt nhưng an toàn. Có thể kiểm soát ai, khi nào, truy cập dữ liệu nào, mọi bản ghi truy cập đều được lưu trữ cẩn thận để kiểm toán.
Dùng DAO làm bể dữ liệu, mô hình "hợp tác xã dữ liệu" vừa bảo vệ quyền sở hữu và lợi ích cá nhân, vừa giúp các AI Agent cần dữ liệu cá nhân hóa hơn có thể tận dụng triệt để.
Đa dạng hóa, chuyên môn hóa – Các Data DAO chuyên biệt
Hiện tại, các bể thanh khoản dữ liệu trên Vana không chỉ là kế hoạch trên giấy, mà đã hình thành các Data DAO lớn nhỏ thực sự. Dữ liệu trong mỗi DAO đều hướng tới một kịch bản chuyên biệt, phục vụ nhu cầu AI khác nhau.
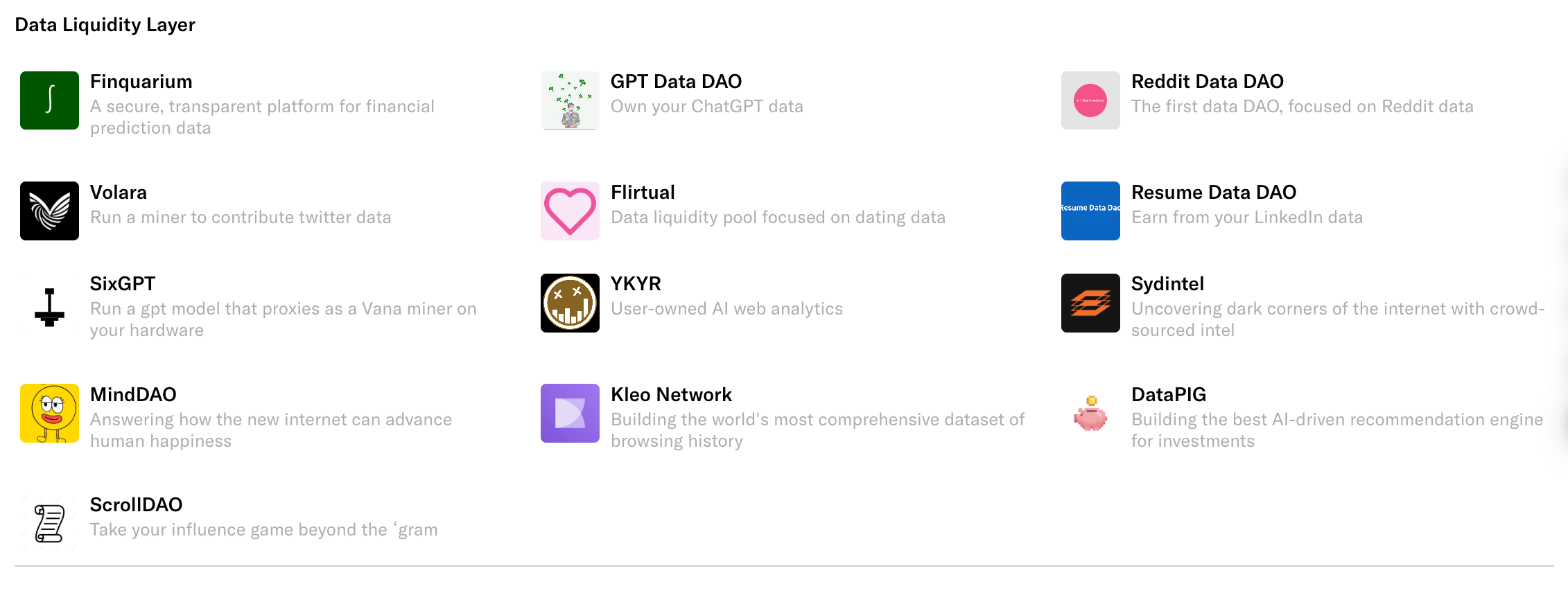
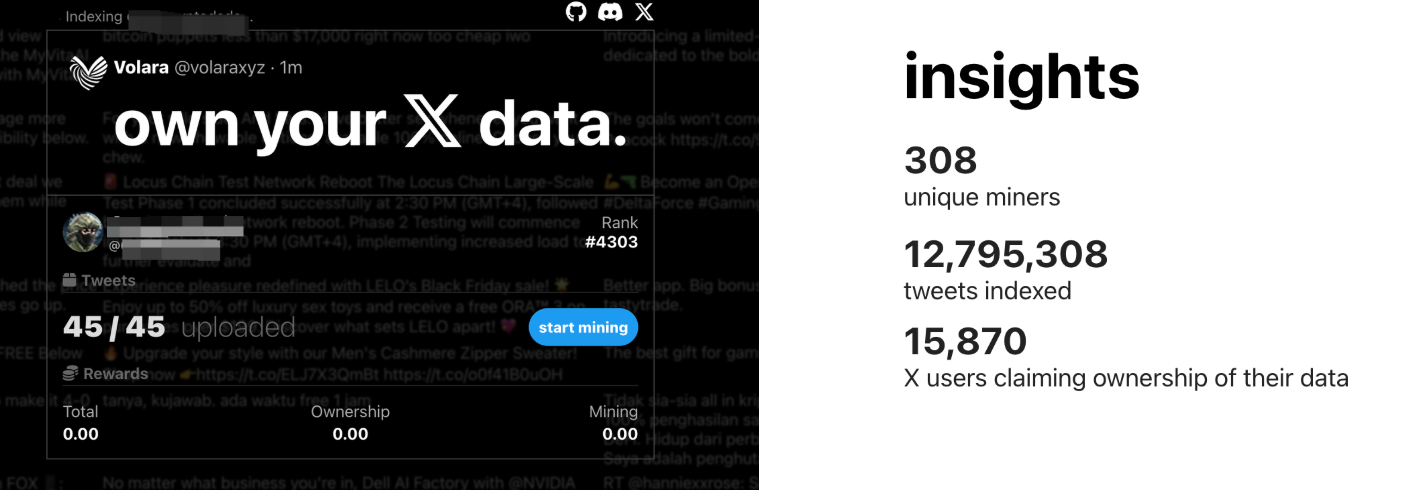
Lấy ví dụ Volara DAO chuyên về X (Twitter), bạn có thể kết nối tài khoản Twitter của mình lên nền tảng, sau đó tải lên tất cả bài đăng và dữ liệu xã hội liên quan, Volara DAO sẽ thưởng token riêng của DAO này theo mức đóng góp của bạn.
Lưu ý, phần thưởng trực tiếp không phải là Vana, mà là token riêng của DAO đó, ví dụ $VOL.
Điều này rất giống xu hướng Virtuals hiện nay, một token mẹ và các token con do các dự án tạo ra. Việc nắm giữ VOL đủ điều kiện nhận airdrop $VANA, mô hình tài sản lồng ghép cũng tạo ra không gian cho nhiều cách chơi mới.
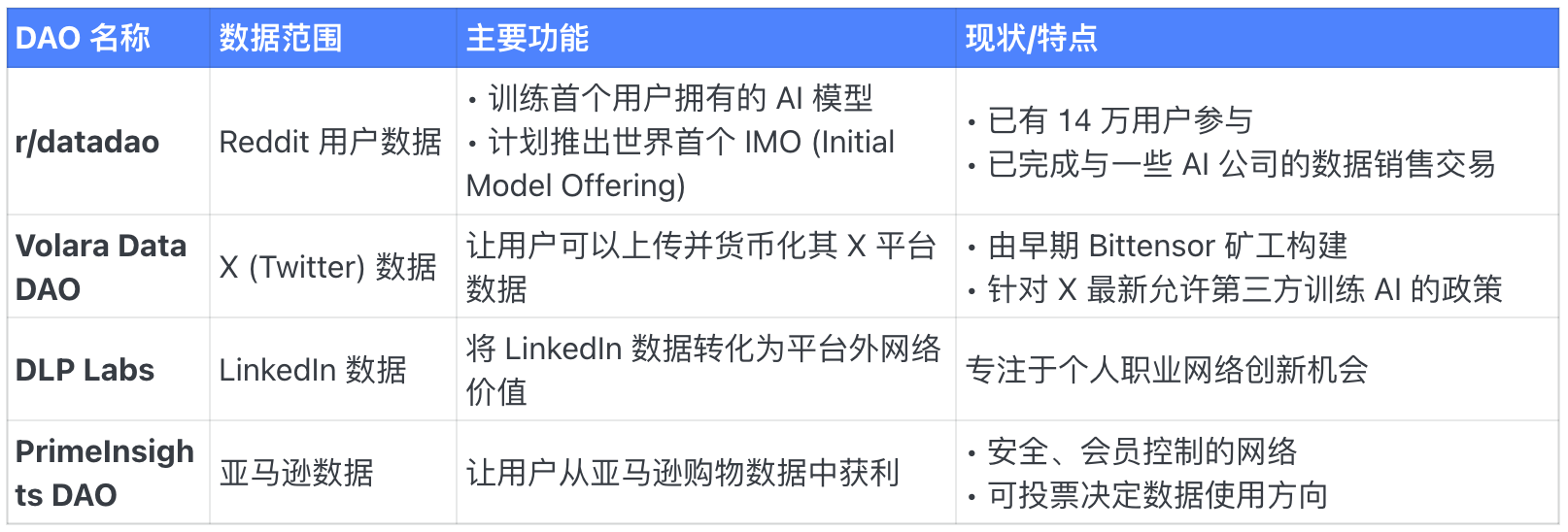
Chúng tôi đã tổng hợp 16 Data DAO phổ biến nhất hiện nay trên Vana và phân loại chi tiết.
Với người chơi thông thường, điều này giống như khái niệm "khai thác dữ liệu" – nếu bạn đánh giá cao một DAO nào đó, có thể đóng góp dữ liệu theo quy tắc của họ, sau đó nhận phần thưởng và airdrop tương ứng.
Tuy nhiên, bạn cũng không nhất thiết phải sở hữu mọi loại dữ liệu, vì vậy cần căn cứ vào phân loại dưới đây để xem mình có thể đóng góp loại dữ liệu nào, tìm ra cách tối ưu lợi nhuận:
Data DAO theo nền tảng
Data DAO thiết bị và tạo dữ liệu
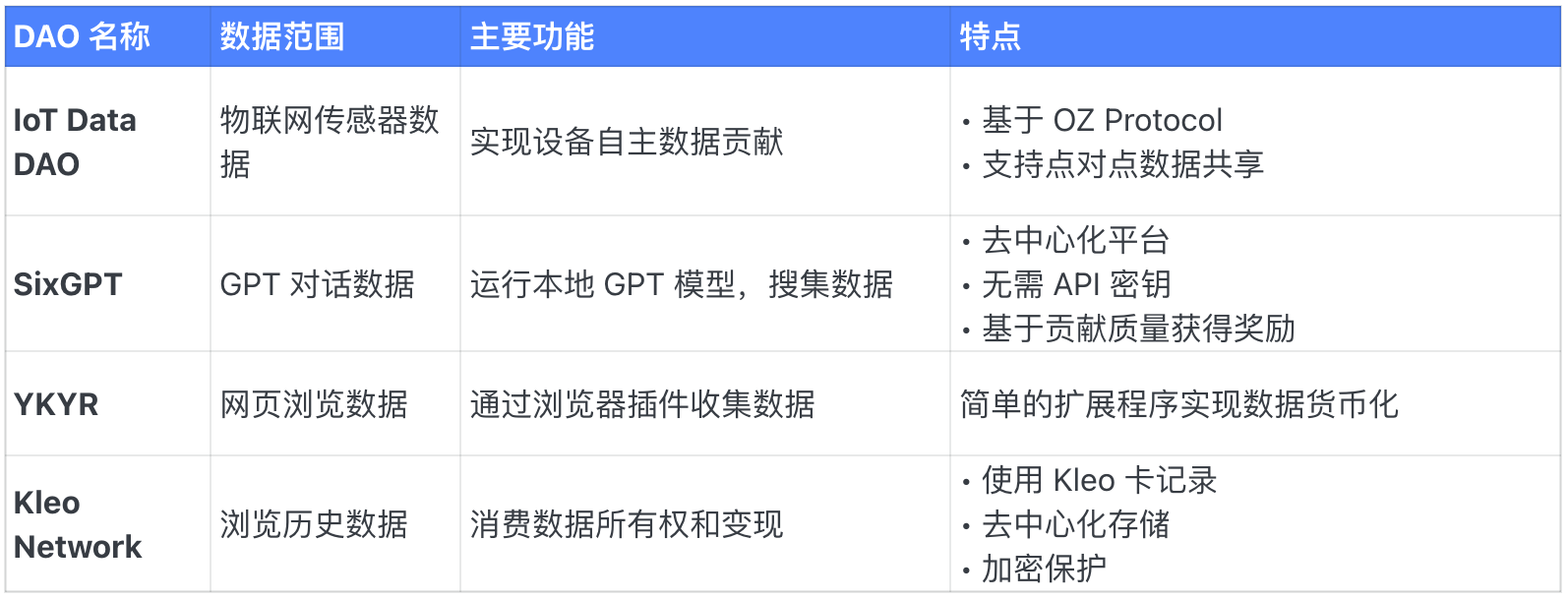
Data DAO tri thức con người và tài chính

Data DAO sức khỏe
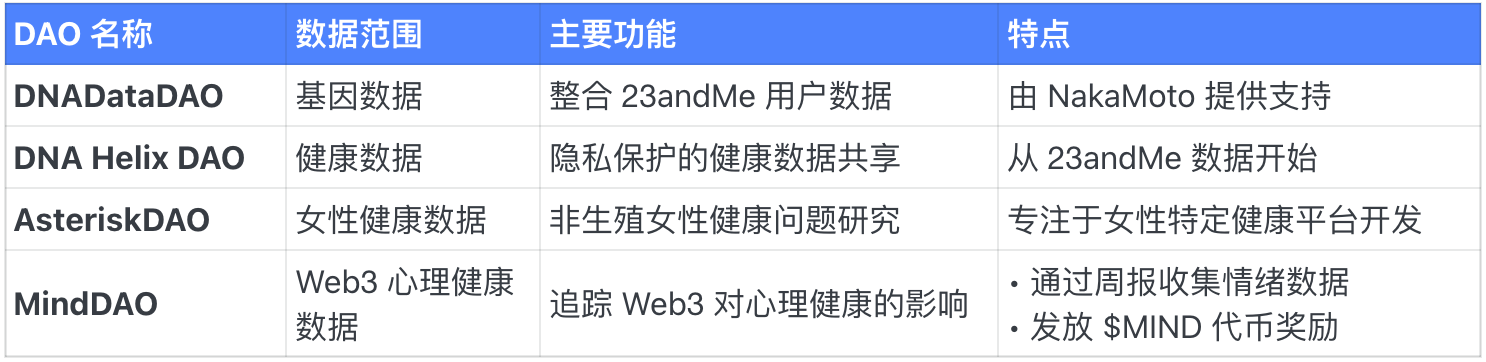
Nhìn chung, kể từ khi mạng thử nghiệm dành cho nhà phát triển ra mắt vào tháng 6 năm 2024, mạng Vana đã thu hút 1,3 triệu người dùng, hơn 300 Data DAO và 1,7 triệu giao dịch mỗi ngày.
Cùng với việc ra mắt mainnet và phát hành token, dưới tác động của cơ chế khuyến khích kinh tế, có thể chúng ta sẽ chứng kiến thêm nhiều Data DAO xuất hiện.
Kinh tế học hai lớp token – Cách chơi phù hợp hơn với thời đại
Bạn có thể đã nhận ra, các DAO ở trên đều có token con riêng, đồng thời có liên hệ với token mẹ VANA (ví dụ như airdrop).
Điều này liên quan đến mô hình kinh tế học token hai lớp được thiết kế công phu.
Hãy tưởng tượng thị trường dữ liệu truyền thống: dữ liệu y tế, dữ liệu tài chính, dữ liệu xã hội, tiêu chuẩn giá trị và tình huống sử dụng của chúng rất khác nhau. Dùng một token duy nhất để đo lường và khuyến khích các đóng góp dữ liệu đa dạng như vậy, giống như dùng một thước đo để đo mọi thứ – từ hành tinh đến nguyên tử. Rõ ràng là không đủ chính xác, cũng không đủ linh hoạt.
VANA áp dụng giải pháp tinh tế hơn: thiết lập một token nền tảng thống nhất (VANA) ở cấp độ giao thức, đồng thời cho phép mỗi Data DAO phát hành token riêng.
Token mẹ và token con có vai trò và nhiệm vụ khác nhau:
-
VANA:
Tổng cung 120 triệu token. Trước hết, yêu cầu các bên xác thực stake VANA để đảm bảo an ninh mạng; thứ hai, dùng làm tiền tệ thanh toán cơ bản cho mọi giao dịch, ví dụ công ty AI cần dữ liệu trong DAO này, phải dùng VANA để thanh toán; quan trọng nhất, yêu cầu mỗi Data DAO phải stake ít nhất 10.000 VANA để vận hành, giống như một "tiền đặt cọc đảm bảo", cam kết vận hành DAO lâu dài với hệ sinh thái.
-
Token của các Data DAO:
Mỗi Data DAO có thể thiết kế mô hình kinh tế token phù hợp với đặc thù lĩnh vực của mình. Ví dụ, một Data DAO y tế có thể chú trọng tính toàn vẹn và độ chính xác của dữ liệu, do đó thiết kế cơ chế thưởng đặc biệt để khuyến khích cung cấp hồ sơ bệnh án chất lượng cao; trong khi một Data DAO xã hội có thể quan tâm hơn đến mức độ tương tác và ảnh hưởng của người dùng.
Các token riêng này không chỉ là điểm tích lũy đơn thuần, mà xây dựng một hệ thống thu thập giá trị hoàn chỉnh: khi dữ liệu được sử dụng, cần thanh toán cả VANA và token DAO tương ứng. Giống như khi sử dụng dữ liệu, vừa phải trả "phí mặt bằng" (VANA), vừa phải trả "phí dịch vụ chuyên biệt" (token DAO).
Cách chơi này có khiến bạn nhớ đến Virtuals?
Điểm tinh tế của hệ thống token hai lớp nằm ở việc tạo ra một vòng tuần hoàn kinh tế tự duy trì: sử dụng dữ liệu cần tiêu tốn token, một phần token này bị đốt, tạo áp lực giảm phát; đồng thời, đóng góp dữ liệu chất lượng cao sẽ nhận được phần thưởng token mới, tạo động lực lạm phát nhẹ. Sự cân bằng này đảm bảo ổn định giá trị token, đồng thời khuyến khích đóng góp dữ liệu liên tục.
Vana với vai trò token mẹ, có chức năng gas và stake, mỗi sub-DAO phát hành token riêng, tạo cặp giao dịch với VANA, token mẹ thu thập lợi ích từ sự phát triển của hệ sinh thái.
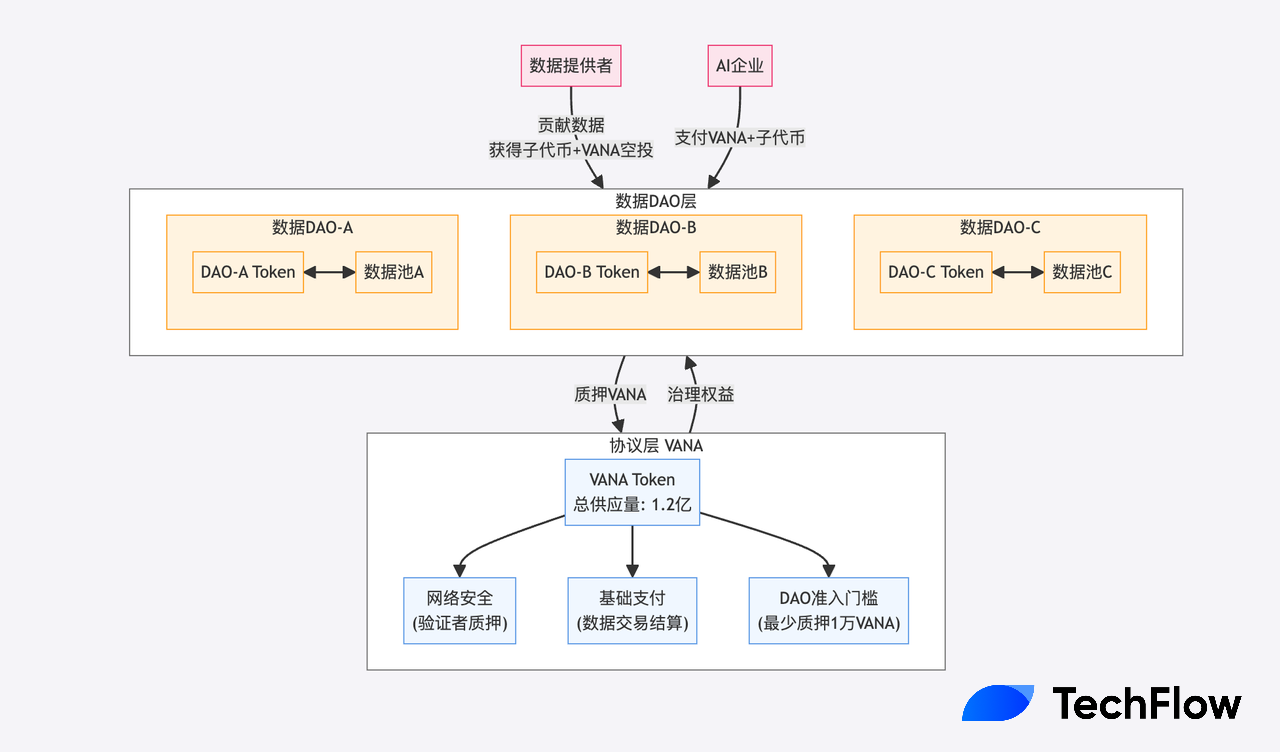
Xét về góc độ tạo tài sản và nâng cao hiệu quả tài sản, cách chơi của VANA rõ ràng rất phù hợp với cơn sốt AI Agent hiện nay.
Với cá nhân, hệ thống này biến dữ liệu thực sự thành một loại tài sản có thể kinh doanh bền vững. Người cung cấp dữ liệu không còn bán dữ liệu một lần rồi thôi, mà thông qua việc nắm giữ token, liên tục chia sẻ lợi nhuận từ việc sử dụng dữ liệu. Giống như chuyển từ mô hình "bán đứt" sang "chia sẻ bản quyền", cải thiện đáng kể lợi ích cho người sáng tạo dữ liệu.
Đồng thời, khi mainnet Vana sắp ra mắt (đã công bố kinh tế học token, đang trong giai đoạn chạy đà), sau khi hiểu rõ cách chơi hai lớp token này, bạn có thể tham gia theo ít nhất hai cách:
Thứ nhất, như đã nói, tham gia đóng góp dữ liệu tại các Data DAO khác nhau, nhằm nhận token DAO con và airdrop VANA tương ứng; liên kết tổng hợp tại đây.
Thứ hai, cùng với việc ra mắt mainnet, chúng tôi nhận thấy website Vana cũng có thay đổi, hiện thêm một trang datahub mới để quản lý các Data DAO bạn tham gia và token tương ứng.
Hiện tại, trang này có một sự kiện đăng ký trước, dùng để liên kết sớm danh tính và chuẩn bị nhận thưởng, người chơi quan tâm nên sớm tham gia.
Sau khi hoàn thành đăng ký, bạn sẽ được ghi nhận là “Early Explorer”.

Tóm tắt
Trong cơn sốt AI Agent hiện nay, tầm ảnh hưởng của AI Agent ngày càng lớn, lan tỏa khắp dòng thông tin và danh sách đầu tư của bạn.
Nhưng câu chuyện của Vana thực chất đang nói rằng, tầm ảnh hưởng của chính bạn, thực ra lớn hơn bạn tưởng.
Thông qua việc đóng góp các loại dữ liệu, trở thành một phần của cơn sốt AI; thông qua việc mã hóa tài sản dữ liệu, bạn có thêm một cách chơi xung quanh việc tạo tài sản.
Không thể phủ nhận rằng, trong thế giới mã hóa, tạo tài sản là một đường dây rõ ràng. Ai càng gần tài sản, người đó càng có nhiều không gian kể chuyện và lợi nhuận.
Mà khi dữ liệu của bạn có thể được mã hóa thành tài sản, tôi cho rằng đây là một đường dây ẩn phù hợp, cũng là mảnh ghép then chốt để cá nhân đón nhận, tận dụng và tham gia xu hướng AI Agent.
Câu chuyện ở tầng dữ liệu chưa được khai thác đầy đủ, Vana liệu có được khám phá giá trị hay không, thị trường sẽ cho câu trả lời.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News









