

Khi tiếng Quảng Đông của ChatGPT "nói không đúng": Trong thời đại AI, liệu các ngôn ngữ ít tài nguyên có bị định đoạt số phận bị đẩy ra ngoài lề?
Tuyển chọn TechFlowTuyển chọn TechFlow
Khi tiếng Quảng Đông của ChatGPT "nói không đúng": Trong thời đại AI, liệu các ngôn ngữ ít tài nguyên có bị định đoạt số phận bị đẩy ra ngoài lề?
Phía sau tiếng Quảng Đông "nửa vời" do AI tạo ra là cuộc đấu tranh giữa việc bảo tồn ngôn ngữ và phân bổ nguồn lực xã hội.
Tác giả: Anita Zhang
Bạn đã từng nghe ChatGPT nói tiếng Quảng Đông chưa?
Nếu bạn là người nói tiếng Quan thoại bản xứ, xin chúc mừng – bạn vừa lập tức đạt được thành tựu "thành thạo tiếng Quảng Đông". Nhưng ngược lại, những người thực sự nói được tiếng Quảng Đông có lẽ lúc này đang bối rối. Giọng nói của ChatGPT mang một âm điệu kỳ lạ, giống như một người từ nơi khác đang cố gắng nói tiếng Quảng Đông.
Vào lần cập nhật tháng 9 năm 2023, ChatGPT lần đầu tiên sở hữu khả năng "nói". Ngày 13 tháng 5 năm 2024, thế hệ mô hình mới nhất GPT-4o được ra mắt. Mặc dù chức năng giọng nói phiên bản mới vẫn chưa chính thức ra mắt và chỉ tồn tại trong các bản demo, nhưng từ bản cập nhật năm ngoái, ta đã có thể phần nào nhìn thấy khả năng hội thoại đa ngôn ngữ bằng giọng nói của ChatGPT.
Rất nhiều người cũng nhận ra rằng giọng nói tiếng Quảng Đông của ChatGPT rất đặc trưng, tuy ngữ điệu tự nhiên, giống con người thật, nhưng "con người thật" đó chắc chắn không phải là người bản xứ nói tiếng Quảng Đông.

Để xác minh điều này và tìm hiểu nguyên nhân đằng sau, chúng tôi đã tiến hành thử nghiệm so sánh các phần mềm phát âm tiếng Quảng Đông: các đối tượng thử nghiệm gồm ChatGPT Voice, Siri của Apple, Văn Tâm Nhất Ngôn (ERNIE Bot) của Baidu, và suno.ai. Ba đối tượng đầu là trợ lý giọng nói, trong khi suno.ai là nền tảng tạo nhạc trí tuệ nhân tạo cực kỳ nổi bật gần đây. Tất cả đều có khả năng tạo phản hồi bằng tiếng Quảng Đông hoặc dạng tương tự theo gợi ý.
Xét về cách phát âm từ vựng, Siri và Văn Tâm Nhất Ngôn đều phát âm đúng, nhưng câu trả lời khá máy móc và cứng nhắc. Hai đối tượng còn lại mắc lỗi phát âm ở mức độ khác nhau. Thường thì sai lầm nằm ở việc dùng cách phát âm theo kiểu thiên về tiếng Quan thoại, ví dụ như từ "ảnh" (影) trong tiếng Quảng Đông phải đọc là "jing2", nhưng lại biến thành "ying" kiểu tiếng Quan thoại; từ "lóng lánh" (亮晶晶) phải là "zing1", nhưng lại đọc thành "jing".
Từ "cao" (高) trong cụm "cao lâu đại sảnh" (高楼大厦) bị ChatGPT phát âm thành "gao", trong khi thực tế phải là âm Quảng Đông "gou1". Frank – người sinh ra và lớn lên ở Quảng Đông – cũng chỉ ra rằng đây là lỗi phát âm phổ biến ở người không bản xứ, thường bị người địa phương chế giễu vì "gao" là từ lóng thô tục ám chỉ bộ phận sinh dục trong tiếng Quảng Đông. Mỗi lần phát âm của ChatGPT có chút khác biệt: chữ "hạ" (厦) trong "cao lâu đại sảnh" đôi khi phát âm đúng là "haa6", nhưng đôi khi lại sai thành "xia" – một âm không tồn tại trong tiếng Quảng Đông, gần giống với cách đọc tiếng Quan thoại.
Về mặt ngữ pháp, văn bản tạo ra rõ ràng nghiêng về văn viết, thỉnh thoảng pha chút khẩu ngữ. Việc chọn từ và cấu trúc câu thường đột ngột chuyển sang mô hình tiếng Quan thoại, chẳng hạn như nói "mua đồ" (买东西 - tiếng Quảng Đông là "mua dã"), hay "dùng tiếng Quảng Đông để giới thiệu Hong Kong cho bạn" (用粤语来给你介绍一下香港啦 – đúng phải là "dùng tiếng Quảng Đồng đồng bạn giới thiệu hạ Hong Kong la").
Khi sáng tác lời rap tiếng Quảng Đông, suno.ai cũng viết những câu như "giới phường biên cá仿 đáo, Hương Cảng đích đặc sắc chân chính lương diệu", một câu vô nghĩa; khi chúng tôi đưa câu này cho ChatGPT đánh giá, nó nhận xét rằng "câu này dường như là bản dịch trực tiếp từ tiếng Quan thoại, hoặc là cấu trúc câu pháp (syntax) trộn lẫn giữa tiếng Quan thoại và tiếng Quảng Đông".

Ngược lại, khi thử dùng tiếng Quan thoại, những lỗi sai này hầu như không xuất hiện. Dĩ nhiên, cùng là tiếng Quảng Đông, nhưng có sự khác biệt về giọng và từ vựng giữa Quảng Châu, Hồng Kông và Ma Cao. Âm chuẩn của tiếng Quảng Đông được gọi là âm Tây Quan, rất khác biệt so với tiếng bạch thoại Quảng Đông thông dụng ở Hồng Kông. Tuy nhiên, giọng tiếng Quảng Đông của ChatGPT nhiều nhất cũng chỉ có thể gọi là "không mặn không nhạt" – tức là giọng nói của người bản xứ tiếng Quan thoại nói tiếng Quảng Đông nửa vời.
Chuyện gì đang xảy ra vậy? Liệu ChatGPT có thực sự không biết tiếng Quảng Đông? Nó không tuyên bố trực tiếp là không hỗ trợ, mà lại triển khai một sự tưởng tượng, và sự tưởng tượng này rõ ràng được xây dựng dựa trên một ngôn ngữ mạnh hơn, có sự hậu thuẫn chính thống. Điều này liệu có trở thành vấn đề?
Nhà ngôn ngữ học và nhân chủng học Sapir (Edward Sapir) cho rằng: khẩu ngữ ảnh hưởng đến cách con người tương tác với thế giới. Khi một ngôn ngữ không thể cất lên tiếng nói của mình trong thời đại trí tuệ nhân tạo, điều đó hàm ý điều gì? Liệu hình ảnh về tiếng Quảng Đông của chúng ta sẽ dần dần đồng nhất với hình ảnh do AI tạo ra?
Những ngôn ngữ không có "nguồn lực"
Khi tra cứu thông tin công khai từ OpenAI, ta thấy rằng khả năng hội thoại của chế độ giọng nói ChatGPT ra mắt năm ngoái thực chất gồm ba phần chính: đầu tiên là hệ thống nhận dạng giọng nói mã nguồn mở Whisper chuyển khẩu ngữ thành văn bản – sau đó mô hình hội thoại văn bản ChatGPT tạo phản hồi dạng văn bản – cuối cùng là một mô hình chuyển văn bản thành giọng nói (Text-To-Speech, gọi tắt là TTS) tạo âm thanh và tinh chỉnh cách phát âm.
Nói cách khác, nội dung hội thoại vẫn do bản thể ChatGPT3.5 tạo ra, mô hình này được huấn luyện trên lượng lớn văn bản sẵn có trên mạng, chứ không phải dữ liệu giọng nói.
Ở điểm này, tiếng Quảng Đông có bất lợi rõ rệt, bởi nó chủ yếu tồn tại dưới dạng khẩu ngữ hơn là văn viết. Về mặt chính thức, văn viết được dùng trong khu vực nói tiếng Quảng Đông là văn viết Trung Quốc tiêu chuẩn bắt nguồn từ tiếng Hán phương Bắc, gần với tiếng Quan thoại hơn là tiếng Quảng Đông. Trong khi đó, văn viết tiếng Quảng Đông – tức là hệ thống chữ viết phù hợp với ngữ pháp và thói quen từ vựng khẩu ngữ tiếng Quảng Đông, còn gọi là "Quảng văn" – chủ yếu xuất hiện trong các bối cảnh phi chính thức như diễn đàn mạng.
Việc sử dụng này thường không tuân theo quy tắc thống nhất. "Khoảng 30% chữ tiếng Quảng Đông, tôi cũng không biết phải viết thế nào," Frank nói. Khi trò chuyện mạng gặp chữ không biết viết, mọi người thường chỉ gõ đại một chữ gần âm trên bàn phím pinyin tiếng Trung. Ví dụ như thành ngữ "loạn up nhị thập tứ" (乱噏廿四; nghĩa là nói nhảm), thường được viết thành "loạn up nhị thập tứ". Mặc dù phần lớn mọi người vẫn hiểu được, điều này khiến văn bản tiếng Quảng Đông hiện có thêm phần lộn xộn và thiếu chuẩn mực.
Sự ra đời của mô hình ngôn ngữ lớn giúp con người nhận thức được tầm quan trọng của tập huấn luyện đối với trí tuệ nhân tạo, cũng như các định kiến tiềm tàng. Tuy nhiên, thực tế là trước khi AI tạo sinh xuất hiện, khoảng cách tài nguyên dữ liệu giữa các ngôn ngữ đã tạo nên một hố sâu. Hầu hết các hệ thống xử lý ngôn ngữ tự nhiên đều được thiết kế và kiểm thử bằng các ngôn ngữ có nguồn lực cao. Trong số tất cả các ngôn ngữ đang hoạt động trên toàn cầu, chỉ có khoảng 20 ngôn ngữ được coi là "có nguồn lực cao", như tiếng Anh, tiếng Tây Ban Nha, tiếng Quan thoại, tiếng Pháp, tiếng Đức, tiếng Ả Rập, tiếng Nhật, tiếng Hàn.
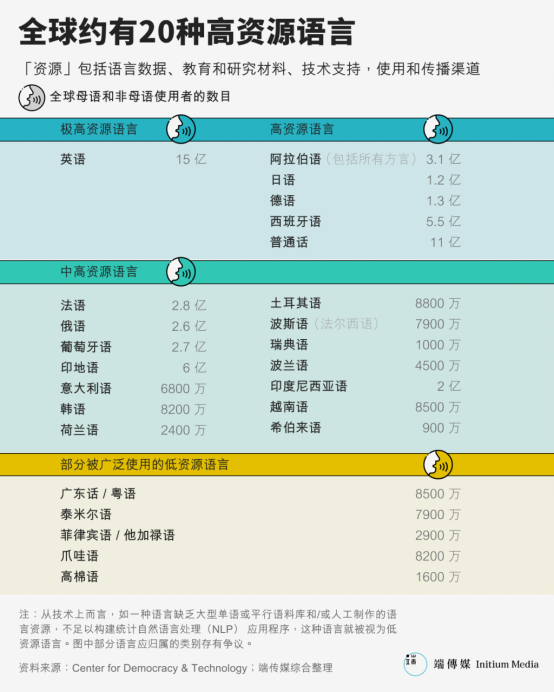
Trong khi đó, tiếng Quảng Đông – với 85 triệu người sử dụng – trong xử lý ngôn ngữ tự nhiên (NLP) lại thường bị coi là một ngôn ngữ ít nguồn lực. Là điểm khởi đầu cho học sâu, Wikipedia tiếng Anh nén lại có dung lượng 15,6GB, bản tiếng Trung giản thể/phồn thể kết hợp là 1,7GB, trong khi bản tiếng Quảng Đông chỉ có 52MB – chênh lệch gần 33 lần.
Tương tự, trong bộ dữ liệu giọng nói công khai lớn nhất hiện nay Common Voice, dữ liệu giọng nói Chinese (China) dài 1232 giờ, Chinese (Hong Kong) là 141 giờ, Cantonese là 198 giờ.
Thiếu hụt ngữ liệu ảnh hưởng sâu sắc đến hiệu suất xử lý ngôn ngữ tự nhiên của máy. Một nghiên cứu năm 2018 phát hiện nếu kho ngữ liệu có ít hơn 13.000 câu song song, máy dịch không thể đạt được kết quả dịch hợp lý. Điều này cũng ảnh hưởng đến khả năng "nghe – viết" của máy. Mô hình nhận dạng giọng nói Whisper mã nguồn mở (phiên bản V2) mà ChatGPT Voice sử dụng cho thấy tỷ lệ lỗi ký tự tiếng Quảng Đông rõ ràng cao hơn tiếng Quan thoại.
Hiệu suất văn bản của mô hình cho thấy sự thiếu hụt tài nguyên của Quảng văn, nhưng nguyên nhân nào khiến cách phát âm và ngữ điệu – thứ quyết định cảm giác nghe của chúng ta – lại sai lệch?
Máy học nói như thế nào?
Con người từ lâu đã nảy sinh ý định làm cho máy móc biết nói, sớm nhất có thể truy nguyên đến thế kỷ 17, những nỗ lực ban đầu bao gồm việc dùng ống organ hoặc bơm gió để bơm không khí vào các thiết bị mô phỏng cấu trúc ngực, dây thanh và khoang miệng phức tạp. Ý tưởng này sau đó được nhà phát minh Faber (Joseph Faber) áp dụng, tạo ra một con rối mặc trang phục Thổ Nhĩ Kỳ biết nói – nhưng lúc đó người ta đều không hiểu điều này có ý nghĩa gì.
Chỉ đến khi các thiết bị gia dụng ngày càng phổ biến, ý tưởng làm cho máy biết nói mới thu hút sự quan tâm của đông đảo.
Bởi vì đối với đa số người, giao tiếp bằng mã hóa là không tự nhiên, và một bộ phận đáng kể người khuyết tật do đó bị loại trừ khỏi công nghệ.

Năm 1939 tại Hội chợ Thế giới, kỹ sư Dudley (Homer Dudley) của Phòng thí nghiệm Bell đã phát minh ra bộ tổng hợp giọng nói Voder, phát ra "tiếng nói máy móc" đầu tiên hướng tới con người. So với tính "bí ẩn" của học máy hiện nay, nguyên lý Voder đơn giản và rõ ràng, khán giả đều có thể thấy: một nữ điều khiển viên ngồi trước một cái máy giống như đàn piano đồ chơi,熟练 vận hành 10 phím để tạo hiệu ứng phát âm gần giống ma sát dây thanh. Người điều khiển còn có thể đạp bàn đạp để thay đổi cao độ, mô phỏng ngữ điệu vui vẻ hoặc u ám hơn. Bên cạnh, một người dẫn chương trình liên tục mời khán giả đưa ra từ mới để chứng minh âm thanh của Voder không phải được ghi âm sẵn.
Thông qua bản ghi âm thời đó, tờ New York Times nhận xét giọng Voder giống như "lời chào hỏi của người ngoài hành tinh vọng từ đáy biển sâu", hoặc như một người say rượu lè nhè, khó hiểu. Nhưng vào thời điểm đó, công nghệ này đủ để gây kinh ngạc, trong suốt hội chợ, Voder đã thu hút hơn 5 triệu lượt khách tham quan trên toàn thế giới.
Các hình ảnh robot thông minh và sinh vật ngoài hành tinh thời kỳ đầu lấy cảm hứng rất nhiều từ các thiết bị này. Năm 1961, các nhà khoa học Phòng thí nghiệm Bell để máy IBM 7094 hát bản dân ca Anh thế kỷ 18 "Daisy Bell". Đây là bài hát do máy tính tổng hợp âm thanh đầu tiên được biết đến. Nhà văn Clarke – tác giả cuốn "2001: Không gian Odyssey" – từng đến Phòng thí nghiệm Bell nghe IBM 7094 hát Daisy Bell, và siêu máy tính HAL 9000 trong tiểu thuyết của ông học bài hát này đầu tiên. Trong phiên bản điện ảnh, khi HAL 9000 bị khởi động lại và ý thức rối loạn, nó bắt đầu ngân nga "Daisy Bell", giọng nói linh hoạt, giống con người dần trở về thành tiếng gầm rú cơ khí.
Từ đó, tổng hợp giọng nói trải qua hàng chục năm phát triển. Trước khi công nghệ mạng thần kinh AI trưởng thành, hai phương pháp phổ biến nhất là tổng hợp nối chuỗi (concatenative synthesis) và tổng hợp cộng hưởng (formant synthesis) – thực tế nhiều chức năng giọng nói phổ biến ngày nay vẫn dùng hai phương pháp này, ví dụ như phần mềm đọc màn hình. Trong đó, tổng hợp cộng hưởng chiếm ưu thế giai đoạn đầu. Nguyên lý phát âm tương tự tư duy của Voder, dùng sự kết hợp kiểm soát các tham số như tần số cơ bản, âm xát, âm mũi... để tạo ra vô hạn âm thanh. Điều này mang lại lợi thế lớn: bạn có thể dùng nó để sản xuất bất kỳ ngôn ngữ nào. Ngay từ năm 1939, Voder đã có thể nói tiếng Pháp.
Vậy dĩ nhiên nó cũng có thể nói tiếng Quảng Đông. Tháng 11 năm 2006, khi còn là nghiên cứu sinh thạc sĩ chuyên ngành phần mềm máy tính tại Đại học Trung Sơn, Huang Guanneng – người Quảng Châu – khi đang lên kế hoạch luận văn tốt nghiệp, nghĩ đến việc làm một trình duyệt Linux dành cho người khiếm thị. Trong quá trình này anh tiếp xúc với eSpeak, một bộ tổng hợp giọng nói mã nguồn mở sử dụng phương pháp tổng hợp cộng hưởng. Vì lợi thế về ngôn ngữ, eSpeak nhanh chóng được ứng dụng thực tế sau khi ra đời; năm 2010 Google Dịch bắt đầu bổ sung chức năng đọc to cho hàng loạt ngôn ngữ, bao gồm tiếng Quan thoại, tiếng Phần Lan, tiếng Indonesia..., đều thông qua eSpeak.

Ngày 24 tháng 11 năm 2015, Bắc Kinh, Trung Quốc, một cánh tay robot đang viết chữ Hán bằng bút lông.
Huang Guanneng quyết định bổ sung hỗ trợ tiếng Quảng Đông – tiếng mẹ đẻ của anh – cho eSpeak. Tuy nhiên do giới hạn nguyên lý, âm thanh tổng hợp bởi eSpeak có cảm giác ghép nối rõ rệt. "Giống như bạn học tiếng Trung không phải qua bảng pinyin, mà qua bảng phiên âm tiếng Anh để đọc, hiệu quả sẽ giống như một người nước ngoài học nói tiếng Trung," Huang Guanneng nói.
Vì vậy anh tiếp tục làm Ekho TTS. Hiện nay, bộ tổng hợp giọng nói này hỗ trợ tiếng Quảng Đông, tiếng Quan thoại, thậm chí cả những ngôn ngữ nhỏ hơn như tiếng Khách gia Triệu An, tiếng Tây Tạng, Nghiêm ngữ, tiếng Đài Sơn Quảng Đông. Ekho sử dụng phương pháp nối chuỗi, nói đơn giản là cắt dán – ghi âm trước phát âm của con người, rồi "nói" bằng cách ráp chúng lại. Như vậy, phát âm từng chữ sẽ chuẩn hơn, và một số từ thông dụng nếu được ghi âm đầy đủ sẽ tạo cảm giác tự nhiên hơn. Huang Guanneng đã tổng hợp bảng phát âm tiếng Quảng Đông gồm 5005 âm, ghi âm toàn bộ mất từ 2 đến 3 tiếng.
Sự xuất hiện của học sâu đã mang lại cuộc cách mạng cho lĩnh vực này. Tổng hợp giọng nói dựa trên thuật toán học sâu học ánh xạ giữa đặc trưng văn bản và đặc trưng giọng nói từ kho dữ liệu giọng nói quy mô lớn, không cần phụ thuộc vào các quy tắc ngôn ngữ học đã định sẵn hay đơn vị giọng nói được ghi âm trước. Công nghệ này giúp giọng máy tiến một bước lớn về độ tự nhiên, nhiều lúc hiệu quả không khác gì người thật, và có thể sao chép âm sắc cùng thói quen nói của một người chỉ với vài chục giây giọng nói – mô-đun TTS của ChatGPT sử dụng chính công nghệ này.
So với tổng hợp cộng hưởng và kỹ thuật nối chuỗi, các hệ thống này tiết kiệm rất nhiều chi phí nhân lực ban đầu, nhưng lại đòi hỏi cao hơn về tài nguyên cặp đôi văn bản-giọng nói. Ví dụ như mô hình Tacotron đầu cuối do Google ra mắt năm 2017, cần hơn 10 giờ dữ liệu huấn luyện mới đạt được chất lượng giọng nói tốt.
Để giải quyết tình trạng thiếu hụt tài nguyên ở nhiều ngôn ngữ, trong những năm gần đây, các nhà nghiên cứu đề xuất phương pháp học chuyển giao (transfer learning): trước tiên dùng tập dữ liệu ngôn ngữ có nguồn lực cao để huấn luyện một mô hình chung, sau đó chuyển các quy luật này sang tổng hợp cho ngôn ngữ ít nguồn lực. Đến một mức độ nào đó, các quy luật chuyển giao này vẫn mang theo đặc trưng của tập dữ liệu gốc – giống như người nói tiếng mẹ đẻ học một ngôn ngữ mới, sẽ mang theo kiến thức ngôn ngữ mẹ đẻ của họ. Năm 2019, nhóm Tacotron từng đề xuất một mô hình có thể sao chép giọng nói của cùng một người nói giữa các ngôn ngữ khác nhau. Trong bản demo, người nói tiếng Anh "nói" tiếng Quan thoại, dù phát âm chuẩn, nhưng mang rõ ràng "giọng người nước ngoài".
Một bình luận trên tờ Nam Hoa Tảo Báo chỉ ra rằng người Hồng Kông viết bằng tiếng Hán chuẩn, để tất cả người nói tiếng Trung đều hiểu được ý của mình, họ buộc phải dùng từ "họ" (他们) trong tiếng Hán chuẩn hiện đại – "taa1 mun4" theo âm Quảng Đông – một từ gần như không bao giờ xuất hiện trong khẩu ngữ tiếng Quảng Đông; trong tiếng Quảng Đông, từ chỉ "họ" là "kẻi5 đới6" (佢哋), hoàn toàn khác biệt về phát âm và cách viết.
Trong việc dùng một giải pháp để xử lý vấn đề phổ quát, mô hình GPT-4o mới nhất làm điều này cực đoan hơn, OpenAI giới thiệu rằng họ huấn luyện đầu cuối một mô hình xuyên suốt văn bản, hình ảnh và âm thanh, tất cả đầu vào và đầu ra đều do mạng thần kinh chung này xử lý. Cách mô hình này xử lý các ngôn ngữ khác nhau vẫn chưa rõ ràng, nhưng dường như tính phổ quát giữa các nhiệm vụ của nó mạnh hơn trước đây.
Nhưng sự tương đồng giữa tiếng Quảng Đông và tiếng Quan thoại đôi khi khiến vấn đề trở nên phức tạp hơn.
Trong ngôn ngữ học có khái niệm "phân tầng ngôn ngữ" hay "song ngữ" (diglossia), chỉ hiện tượng tồn tại hai ngôn ngữ liên hệ chặt chẽ trong một xã hội nhất định, một ngôn ngữ có uy tín cao hơn, thường được chính phủ sử dụng, còn ngôn ngữ kia thường được dùng như phương ngữ khẩu ngữ, hay gọi là bạch thoại.
Trong bối cảnh Trung Quốc, tiếng Quan thoại là ngôn ngữ cấp cao nhất, dùng trong viết chính thức, phát thanh tin tức, giáo dục trường học và công vụ chính phủ. Trong khi đó, các phương ngữ địa phương như tiếng Quảng Đông, tiếng Mân Nam (Đài ngữ), tiếng Thượng Hải... là ngôn ngữ cấp thấp, chủ yếu dùng trong giao tiếp khẩu ngữ hàng ngày tại gia đình và cộng đồng địa phương.
Do đó, tại Quảng Đông, Hồng Kông và Ma Cao đã hình thành hiện tượng này: tiếng Quảng Đông là tiếng mẹ đẻ của đa số người, dùng trong giao tiếp khẩu ngữ hàng ngày, trong khi ngôn ngữ viết chính thức thường là tiếng Hán chuẩn tiếng Quan thoại.
Giữa hai ngôn ngữ này có nhiều điểm tương đồng nhưng thực tế khác biệt, nhiều cặp "không hòa hợp" như "họ" và "kẻi đới", khiến việc chuyển giao từ tiếng Quan thoại sang tiếng Quảng Đông trở nên khó khăn hơn và dễ gây hiểu lầm.
Tiếng Quảng Đông ngày càng bị đẩy ra ngoài lề
"Nỗi lo ngại về tương lai tiếng Quảng Đông hoàn toàn không phải là vô căn cứ. Sự suy tàn của một ngôn ngữ diễn ra rất nhanh, có thể suy giảm trong một hoặc hai thế hệ, và một khi ngôn ngữ bắt đầu suy tàn, sẽ rất khó cứu vãn." – James Griffiths, "Please Speak Mandarin"
Tới đây, dường như có thể cho rằng biểu hiện kém của tổng hợp giọng nói trên tiếng Quảng Đông là do khả năng xử lý ngôn ngữ ít nguồn lực. Các mô hình dùng thuật toán học sâu khi gặp từ chưa quen sẽ tạo ra ảo ảnh âm thanh. Tuy nhiên, Giáo sư Tan Lee, Khoa Kỹ thuật Điện tử, Đại học Trung Văn Hồng Kông, sau khi nghe biểu hiện giọng nói của ChatGPT, đã đưa ra một quan điểm khác.

Một vở kịch Quảng Đông đang diễn tại rạp hát Cửu Long
Tan Lee bắt đầu nghiên cứu về ngôn ngữ và giọng nói từ đầu những năm 1990, lãnh đạo phát triển hàng loạt công nghệ khẩu ngữ lấy tiếng Quảng Đông làm trung tâm, và được ứng dụng rộng rãi. Năm 2002, anh cùng nhóm phát triển kho ngữ liệu giọng nói tiếng Quảng Đông CU Corpora, lúc đó là cơ sở dữ liệu lớn nhất thế giới cùng loại, chứa dữ liệu ghi âm của hơn 2.000 người. Từ thế hệ đầu tiên nhận dạng giọng nói của Apple trở đi, nhiều công ty và tổ chức nghiên cứu muốn phát triển chức năng tiếng Quảng Đông từng mua bộ tài nguyên này từ họ.
Theo anh, biểu hiện giọng nói tiếng Quảng Đông của ChatGPT "chất lượng không tốt, chủ yếu là không ổn định, chất lượng âm thanh, độ chính xác phát âm tổng thể đều không làm hài lòng". Nhưng biểu hiện kém này không phải do giới hạn kỹ thuật. Thực tế, nhiều sản phẩm tạo giọng nói tiếng Quảng Đông hiện có trên thị trường có chất lượng cao hơn hẳn. Đến mức anh cảm thấy khó tin khi xem video mạng về biểu hiện của ChatGPT, từng nghĩ đó là sản phẩm giả mạo bằng deepfake, "nếu làm mô hình tạo giọng nói mà ra thành thế này thì cơ bản không dám ra mắt, chẳng khác nào tự sát".
Lấy hệ thống do Đại học Trung Văn Hồng Kông tự phát triển làm ví dụ, những mẫu tiên tiến nhất hiện nay về hiệu ứng giọng nói gần như không thể phân biệt được giữa người thật và giọng tổng hợp. So với các ngôn ngữ mạnh hơn như tiếng Quan thoại và tiếng Anh, tiếng Quảng Đông trong AI chỉ hơi yếu kém hơn về biểu hiện cảm xúc trong một số tình huống cá nhân và đời sống, ví dụ như đối thoại giữa cha mẹ và con cái, tư vấn tâm lý, phỏng vấn xin việc, khi đó giọng Quảng Đông có vẻ lạnh lùng hơn.
"Nhưng nghiêm túc mà nói, về mặt kỹ thuật điều này không có gì khó, vấn đề then chốt nằm ở lựa chọn nguồn lực xã hội," Tan Lee nói.
So với 20 năm trước, lĩnh vực tổng hợp giọng nói đã thay đổi hoàn toàn, lượng dữ liệu CU Corpora so với các cơ sở dữ liệu hiện nay "có thể chưa đến một phần vạn". Thương mại hóa công nghệ giọng nói khiến dữ liệu trở thành một nguồn lực thị trường, chỉ cần sẵn sàng, các công ty dữ liệu luôn có thể cung cấp lượng lớn dữ liệu tùy chỉnh. Và với tư cách là một ngôn ngữ khẩu ngữ, vấn đề thiếu dữ liệu song song văn bản-giọng nói của tiếng Quảng Đông, trong những năm gần đây cùng với sự phát triển công nghệ nhận dạng giọng nói, đã không còn là vấn đề. Theo Tan Lee, việc gọi tiếng Quảng Đông là "ngôn ngữ ít nguồn lực" hiện nay đã không còn chính xác.
Chính vì vậy, theo anh, biểu hiện tiếng Quảng Đông của máy móc trên thị trường phản ánh không phải năng lực kỹ thuật, mà là cân nhắc thị trường và thương mại. "Giả sử toàn Trung Quốc cùng học tiếng Quảng Đông, chắc chắn có thể làm được; hoặc giả sử bây giờ Hồng Kông và đại lục ngày càng hội nhập, một ngày nào đó chính sách giáo dục thay đổi, các trường tiểu học và trung học ở Hồng Kông không được dùng tiếng Quảng Đông mà chỉ được dùng tiếng Quan thoại, thì lại là một câu chuyện khác."
Giọng nói thể hiện bởi học sâu – "ăn gì nôn ra nấy" – thực chất là sự bóp méo tiếng Quảng Đông trong không gian thực tế.
Con gái Huang Guanneng mới vào lớp mẫu giáo giữa ở Quảng Châu, đứa trẻ từ nhỏ chỉ nói tiếng Quảng Đông, sau một tháng đi học đã thành thạo tiếng Quan thoại. Hiện nay, ngay cả trong giao tiếp hàng ngày với gia đình và hàng xóm, cô bé cũng quen dùng tiếng Quan thoại, chỉ khi nói chuyện với Huang Guanneng mới chịu nói tiếng Quảng Đông, "vì cô bé thích chơi với ba nhất, nên phải theo sở thích của ba". Trong mắt anh, biểu hiện của ChatGPT giống hệt cách con gái anh nói tiếng Quảng Đông bây giờ, nhiều từ không nhớ cách nói, liền dùng tiếng Quan thoại thay thế, hoặc đoán phát âm qua tiếng Quan thoại.
Đây là kết quả của việc tiếng Quảng Đông bị coi nhẹ kéo dài tại Quảng Đông, thậm chí bị loại bỏ hoàn toàn khỏi ngữ cảnh chính thức. Một tài liệu chính phủ năm 1981 của Chính quyền Nhân dân tỉnh Quảng Đông viết: "Phổ cập tiếng Quan thoại là một nhiệm vụ chính trị", đặc biệt với Quảng Đông – nơi phương ngữ phức tạp, giao lưu trong và ngoài nước thường xuyên – "cố gắng trong ba đến năm năm tới, mọi nơi công cộng ở các thành phố lớn và vừa đều dùng tiếng Quan thoại; trong sáu năm tới, các trường học cơ bản phổ cập tiếng Quan thoại".
Frank – người lớn lên ở Quảng Châu – cũng có ký ức sâu sắc về điều này. Thời thơ ấu, các bộ phim chiếu trên kênh truyền hình công cộng, phim ngoại ngữ đều không có phụ đề tiếng Trung mà chỉ dùng chữ, duy chỉ có phim tiếng Quảng Đông nhất thiết phải có phụ đề tiếng Quan thoại mới được phát sóng. Trong bối cảnh này, tiếng Quảng Đông ngày càng suy yếu, số người sử dụng giảm mạnh, các trường học dẫn đầu "cấm tiếng Quảng Đông", cũng gây ra tranh luận gay gắt về sự tồn vong của tiếng Quảng Đông và bản sắc liên quan. Năm 2010, mạng internet và bên ngoài ở Quảng Châu bùng nổ phong trào lớn "ủng hộ tiếng Quảng Đông". Các báo cáo thời đó so sánh cuộc tranh luận này với cảnh trong tiểu thuyết Pháp "Bài học cuối cùng", cho rằng chủ nghĩa cực đoan văn hóa suốt nửa thế kỷ khiến cành cây ngôn ngữ phong phú ngày càng teo tóp. Với Hồng Kông, tiếng Quảng Đông còn là phương tiện văn hóa địa phương then chốt, phim Hồng Kông, nhạc Hồng Kông định hình diện mạo đời sống xã hội nơi đây.
Năm 2014, trang web Cục Giáo dục từng đăng một bài viết gọi tiếng Quảng Đông là "phương ngữ Trung Quốc không phải ngôn ngữ pháp định", gây tranh cãi dữ dội, cuối cùng buộc nhân viên Cục Giáo dục phải xin lỗi. Tháng 8 năm 2023, tổ chức bảo vệ tiếng Quảng Đông ở Hồng Kông "Hương Ngữ Học" tuyên bố giải tán, người sáng lập Trần Lạc Hành trong phỏng vấn sau đó nhắc đến thực trạng tiếng Quảng Đông ở Hồng Kông: chính quyền tích cực thúc đẩy "Phổ giáo trung" (dùng tiếng Quan thoại dạy môn tiếng Trung), nhưng do người dân quan tâm, khiến chính quyền "chậm lại một bước".
Tất cả điều này đủ thấy tầm quan trọng của tiếng Quảng Đông trong lòng người Hồng Kông, nhưng cũng cho thấy áp lực lâu dài mà ngôn ngữ này đang đối mặt tại địa phương: sự mong manh do không có thân phận chính thức, và cuộc đấu tranh liên tục giữa chính quyền và dân chúng.
Từ điển tiếng Quảng Đông trực tuyến – Yue Dian
Những tiếng nói không được đại diện
Ảo ảnh ngôn ngữ không chỉ tồn tại trong tiếng Quảng Đông. Trên diễn đàn Reddit và khu thảo luận của OpenAI, người dùng khắp nơi trên thế giới đều phản ánh ChatGPT có biểu hiện tương tự khi nói các ngôn ngữ không phải tiếng Anh:
"Khả năng nhận dạng giọng nói tiếng Ý của nó rất tốt, luôn hiểu và diễn đạt trôi chảy, như một người thật. Nhưng lạ là, nó có giọng Anh, giống như một người Anh đang nói tiếng Ý."
"Tôi là người Anh, tôi thấy nó có giọng Mỹ. Tôi rất ghét điều này, nên chọn không dùng."
"Tiếng Hà Lan cũng vậy, rất khó chịu, cứ như
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News










