Phỏng vấn người sáng lập Grass: Tại sao bạn nên tham gia cung cấp dữ liệu AI phi tập trung?
Tuyển chọn TechFlowTuyển chọn TechFlow
Phỏng vấn người sáng lập Grass: Tại sao bạn nên tham gia cung cấp dữ liệu AI phi tập trung?
Grass kết hợp nhiều câu chuyện tăng giá khác nhau: DePin + AI + Solana.
Bài viết: AYLO
Biên dịch: TechFlow
Grass là một dự án cực kỳ đáng chú ý, dự kiến sẽ ra mắt mainnet vào quý I hoặc quý II. Hiện tại Grass đã có hơn 500.000 người dùng. Khi mạng lưới Grass chính thức đi vào hoạt động, chỉ xét về số lượng người dùng, nó sẽ trở thành một trong những giao thức tiền mã hóa lớn nhất trên thị trường, đồng thời mở ra một nguồn thu nhập mới cho mọi người dùng Internet.
Grass kết hợp nhiều yếu tố tích cực khác nhau: DePin + AI + Solana. Trong bài viết này, bạn sẽ được lắng nghe chia sẻ từ 0xdrej – nhà sáng lập Grass, người đã tiết lộ rất nhiều thông tin quan trọng. Đây là một bài viết dài nhưng vô cùng đáng để đọc, chúng tôi sẽ cùng thảo luận về Grass là gì, cách thức hoạt động, lý do chọn Solana và nhiều nội dung khác.
Điều gì đã thu hút ông đến với lĩnh vực tiền mã hóa?
0xdrej: Vâng, có lẽ tôi đã bỏ lỡ khá nhiều cơ hội khi mới bước chân vào thế giới tiền mã hóa. Tôi nghĩ điều này cũng xảy ra với nhiều người khác. Lần đầu tiên tôi nghe về tiền mã hóa là khi còn học trung học, vì một người bạn cùng lớp đã đào Bitcoin trên chiếc laptop của anh ấy. Từ đó tôi không còn nghe tin gì về anh ấy nữa, nhưng chắc chắn giờ đây anh ấy đang làm rất tốt. Ngoài ra, thực tế tôi từng tham gia một faucet Doge vào năm 2014, khi Doge vừa mới ra đời, nhưng sau đó tôi đã mất quyền truy cập vào tài khoản đó. Vì vậy, tôi nghĩ đây là hai trải nghiệm quan trọng đầu tiên của tôi với tiền mã hóa, tuy nhiên mãi đến vài năm gần đây khi bắt đầu tiếp xúc với DeFi, tôi mới thực sự đắm mình vào công việc nghiên cứu và phát triển.
Tôi từng làm việc trong lĩnh vực tài chính, nên rất hiểu rõ cách vận hành của ngành tài chính truyền thống. Việc chứng kiến một nhóm người bình thường xây dựng lại toàn bộ hạ tầng trên blockchain thật sự rất hấp dẫn. Bạn biết đấy, có rất nhiều điểm tương đồng giữa tài chính truyền thống và những gì đang diễn ra trên chuỗi, điều này thật điên rồ, chủ yếu vì đây là một sổ cái bất biến khổng lồ. Vì vậy, vài năm trước tôi đã bắt đầu tham gia vào một số giao thức DeFi.
Elevator pitch của Grass là gì? Ông giải thích nó ở cấp độ cao như thế nào?

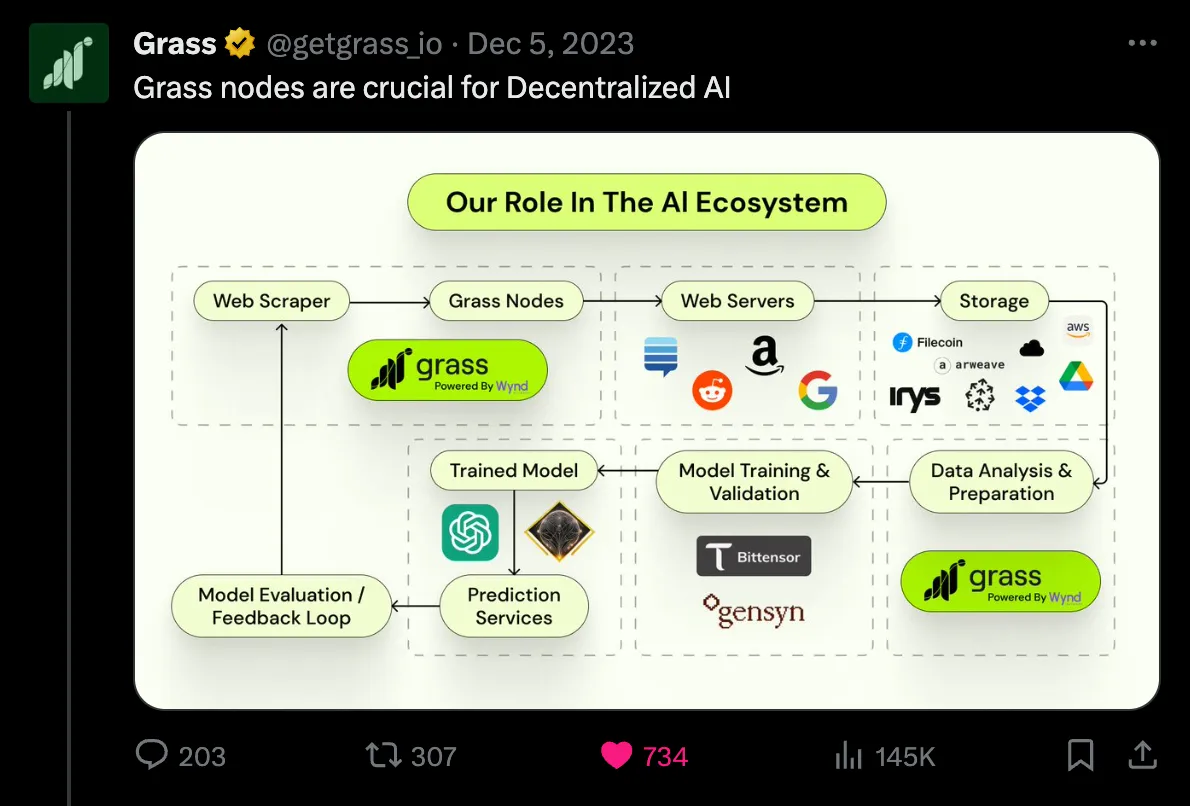
0xdrej: Chúng tôi thích gọi nó là tầng cung cấp dữ liệu phi tập trung cho trí tuệ nhân tạo (AI). Điều này thực chất nghĩa là chúng tôi sở hữu một mạng lưới gồm hơn 500.000 tiện ích mở rộng trình duyệt, đang thu thập dữ liệu từ Internet công cộng, chụp ảnh các trang web và tải chúng lên cơ sở dữ liệu.
Ý tưởng ở đây là, bởi vì chúng tôi có thể xử lý song song và phân phối tất cả năng lực tính toán này, cũng như thu thập dữ liệu từ các địa chỉ IP dân cư (điều này rất quan trọng, vì các trang web thường hiển thị những thứ họ muốn công chúng thấy, chứ không phải những gì hiện ra từ trung tâm dữ liệu hay sản phẩm truyền thống), nên chúng tôi thực sự có thể tạo ra các bộ dữ liệu mà không thể hình thành từ các kho lưu trữ khác.
Vì vậy, đã xuất hiện một số so sánh. Một trong số đó giống như một oracle phi tập trung dành cho AI, và những cái khác là phiên bản phi tập trung của việc thu thập dữ liệu thông thường. Nhưng đúng vậy, cuối cùng thì nó là một giao thức dữ liệu khổng lồ tập trung vào dữ liệu từ mạng công cộng.
Vì vậy, bằng cách cho phép bất kỳ ai tham gia vào mạng lưới này và tích hợp blockchain, ông nhận thấy rằng bạn có thể cạnh tranh với các giải pháp hiện có, đúng không?
0xdrej: Chúng tôi đã thử nghiệm một vài mô hình kinh doanh khác nhau. Rõ ràng, khi xây dựng một giao thức như vậy, bạn có thể chỉ trả cho người dùng một khoản phí nhỏ cho phần băng thông chưa sử dụng. Ví dụ, bạn có thể trả cho họ một mức cố định mỗi gigabyte, sau đó sử dụng băng thông đó để thu thập các bộ dữ liệu lớn, rút ra thông tin và kiếm lợi nhuận từ các thông tin đó. Bạn có thể thu lợi nhuận nhỏ ở mỗi bước từ tầng thu thập, đến tầng bộ dữ liệu, rồi đến tầng thông tin.
Thông thường, điều này được thực hiện bởi các thực thể khác nhau, trong khi người dùng cung cấp băng thông (những người thúc đẩy tất cả điều này) chỉ nhận được mức phí cố định rất nhỏ mỗi gigabyte, hoặc thậm chí không nhận được gì, vì họ đã cài đặt một SDK vào một ứng dụng miễn phí, và ứng dụng đó chỉ đơn giản tái sử dụng băng thông. Chúng tôi cho rằng điều này là không công bằng.
Chúng tôi suy nghĩ, vậy chúng ta sẽ tạo ra một cơ chế bể giá trị như thế nào để bồi thường cho người dùng qua toàn bộ chiều dọc? Vì vậy, nếu ai đó sử dụng dữ liệu được thu thập từ nút Grass của bạn để huấn luyện một mô hình AI, thì nút Grass của bạn nên được bồi thường, chứ không chỉ là dữ liệu gốc. Mong rằng điều này có ý nghĩa. Đây là một trong những vấn đề lớn mà chúng tôi muốn giải quyết trên chuỗi.
Một vấn đề khác ngày càng nổi bật là vấn đề dữ liệu bị ô nhiễm. Đây là một vấn đề mới nổi, nhưng đã tồn tại nhiều năm trong lĩnh vực thương mại điện tử.
Ví dụ, nếu bạn đang thu thập dữ liệu từ các trang web thương mại điện tử như eBay, và bạn muốn lấy giá của tất cả hàng tồn kho mỗi ngày, bạn cần thu thập khoảng 30 triệu SKU mỗi ngày. eBay nhận ra rằng nếu họ chặn địa chỉ IP của bạn, bạn sẽ thay đổi IP. Vì vậy, họ thiết lập các bẫy giá. Nếu họ phát hiện bạn đang cố gắng thu thập dữ liệu và ép giá họ, họ sẽ cung cấp cho bạn những mức giá giả. Chúng tôi đã trải qua điều này khi mới bắt đầu dùng Grass, và so sánh với việc dùng trung tâm dữ liệu.
Các chiến lược thương mại điện tử này đã dần lan sang lĩnh vực công nghệ quảng cáo. Và kể từ khi HoloLens bùng nổ trong khoảng một năm rưỡi qua, nó thực sự đã tràn vào lĩnh vực bộ dữ liệu NLP (xử lý ngôn ngữ tự nhiên).
Vì vậy, nếu bạn là một chính trị gia và biết rằng một bộ dữ liệu cụ thể sẽ được dùng để huấn luyện một mô hình, bạn có thể liên hệ với người quản lý bộ dữ liệu đó và yêu cầu họ chèn vào, ví dụ, một nghìn câu ủng hộ một ứng cử viên cụ thể. Tương tự, các công ty tài trợ để chèn các đánh giá giả vào các bộ dữ liệu đã được thu thập từ Internet.
Hiện nay, việc giải quyết vấn đề này rất khó khăn, đúng không? Bởi vì, như bạn có thể biết, bộ dữ liệu huấn luyện LLM không chỉ đơn thuần là GB hay TB, mà là PB dữ liệu, thực tế là hàng triệu GB.
Do đó, mong đợi bất kỳ ai huấn luyện LLM xác minh xem dữ liệu thực sự có đến từ đúng trang web được tuyên bố hay không là hoàn toàn không thực tế. Ví dụ, nếu tôi tuyên bố rằng tôi đã thu thập toàn bộ nội dung từ Medium, có thể đó là khoảng 50 triệu bài viết, nhưng không có gì đảm bảo rằng nội dung đó thực sự là những bài viết từ Medium.
Để giải quyết vấn đề này, zk-TLS (zero-knowledge Transport Layer Security) cung cấp một giải pháp tuyệt vời. Thành thật mà nói, điều này chỉ khả thi trên một blockchain có thông lượng cao.
Ý tưởng là, một khi chúng tôi phi tập trung hóa, các nút khi thu thập dữ liệu từ Internet sẽ gửi bằng chứng yêu cầu. Họ gửi bằng chứng yêu cầu, sau đó bộ sắp xếp (sequencer) của chúng tôi (hiện tại vẫn tập trung, nhưng chúng tôi có kế hoạch phi tập trung hóa) sẽ ủy thác một lượng token nhất định vào hợp đồng thông minh.
Hợp đồng này sẽ được mở khóa khi nhận được yêu cầu phê duyệt. Bây giờ, bạn thực sự có thể liên kết bằng chứng yêu cầu đó với phản hồi mạng từ công việc thu thập, và sau đó trực tiếp với bộ dữ liệu. Đột nhiên, bạn có một bằng chứng mật mã cho thấy những dòng dữ liệu này trong bộ dữ liệu thực sự đến từ những trang web đó, và được thu thập vào một ngày và giờ cụ thể.
Điều này rất mạnh mẽ, bởi vì cơ chế như vậy thậm chí không tồn tại trong Web 2.0, và chỉ có thể thực hiện được nhờ blockchain.
Ông có thể nói rõ thêm về "cuộc chiến dữ liệu" là gì và Grass tham gia vào đó như thế nào không?

0xdrej: Như tôi đã ám chỉ trước đó, ngành đầu tiên bắt đầu chặn dữ liệu thực ra là thương mại điện tử, vì đó là những bộ dữ liệu có thể dễ dàng chuyển hóa thành tiền nhất lúc bấy giờ. Khi công nghệ phát triển, khi chúng ta hiểu sâu hơn về dữ liệu ngôn ngữ, loại dữ liệu này cũng trở nên cực kỳ quý giá. Tuy nhiên, cho đến bây giờ, dữ liệu ngôn ngữ mới bắt đầu mang lại nhiều giá trị như hiện nay. Vì vậy, nhiều trang web chỉ mới gần đây thực sự tìm ra cách kiếm tiền từ dữ liệu ngôn ngữ này. Sau đó, họ bắt đầu nhận ra sức mạnh to lớn của dữ liệu này và bắt đầu khóa dữ liệu trên Internet.
Ví dụ, khoảng nửa năm trước, Elon Musk bắt đầu giới hạn tốc độ truy cập Twitter đối với mọi người vì dữ liệu Twitter đang bị thu thập. Trước đây, Twitter không thực sự ngăn chặn bot thu thập dữ liệu, nhưng Elon Musk nhận ra giá trị của dữ liệu Twitter và muốn dùng nó để huấn luyện AI của riêng mình. Chính xác là điều chúng tôi đã dự đoán, và thực tế đúng như vậy.

Một ví dụ khác là Reddit, họ đã áp dụng nhiều hạn chế lên API của mình. Bạn có thể không biết, nhưng hai phần ba trong bộ dữ liệu tổng quát được GPT sử dụng để huấn luyện thực chất được thu thập từ Reddit.

Reddit không thực sự hiểu rõ dữ liệu của họ quý giá đến mức nào. Nó đặc biệt quý giá vì cách hoạt động của hệ thống Reddit: ai đó đặt câu hỏi, người khác trả lời, câu trả lời tốt nhất được đẩy lên trên, còn câu trả lời tệ bị đẩy xuống dưới. Reddit có một nhóm người đang vô tình huấn luyện dữ liệu có thể đưa vào mô hình.
Chúng tôi dự đoán hiện đang diễn ra một cuộc chiến dữ liệu, tất cả các trang web này đều cố gắng khóa dữ liệu của họ. Họ thậm chí còn mở cửa hậu cho một vài công ty công nghệ lớn, khiến AI trở nên không thể tiếp cận với các nhà phát triển mã nguồn mở thông thường, điều này hơi đáng sợ và mang lại nhiều rủi ro tập trung.
Một ví dụ điển hình khác là Medium. Cách đây vài tháng, CEO của Medium đã viết một bài blog về việc các bot thu thập dữ liệu đang đưa bài viết Medium vào các mô hình AI. Ông ấy nói về việc làm thế nào để làm ô nhiễm các bộ dữ liệu này, ngăn chặn bot thu thập và khiến dữ liệu trở nên khó tiếp cận nhất có thể. Đó là lý do tại sao việc duyệt Medium mà không đăng ký tài khoản lại rất khó.
Điều này khiến người bình thường không thể sử dụng Internet một cách đầy đủ, vì các công ty đang cố gắng cô lập dữ liệu của họ.
CEO của Medium cũng đề cập rằng họ cho phép Google truy cập dữ liệu của họ. Người bình thường không thể duyệt đúng cách trang web của họ, nhưng Google có thể thu thập dữ liệu để huấn luyện miễn phí mô hình AI của mình. Ông ấy giải thích lý do: Google sẽ ưu tiên Medium trên kết quả tìm kiếm Google để đổi lấy quyền truy cập. Điều này cho thấy giá trị to lớn của việc sở hữu một công cụ tìm kiếm, bạn có thể thanh toán chi phí dữ liệu ngôn ngữ bằng cách ưu tiên SEO. Đây là làn sóng lớn tiếp theo trong cuộc chiến dữ liệu.
Tất cả các công ty này đang chiến đấu vì dữ liệu, cố gắng khóa dữ liệu, cố gắng định giá đúng cho những thứ chưa từng được định giá trong lịch sử loài người. Người bình thường trở thành nạn nhân phụ, và dữ liệu này chỉ có thể tiếp cận bởi một vài tổ chức, điều này là không công bằng.
Điều điên rồ là, hiện nay có những công ty lâu đời đang thu thập dữ liệu từ các trang như Reddit bằng cách cài SDK vào các ứng dụng được hàng triệu người tải xuống miễn phí. Giả sử bạn tải về màn hình chờ Roku TV hoặc một trò chơi điện thoại miễn phí nào đó. Các nhà phát triển được trả tiền để đặt SDK vào đó, SDK này cho phép các công ty lớn sử dụng băng thông của bạn để thu thập dữ liệu từ địa chỉ IP nhà bạn, vì IP của họ đã bị chặn. Mỉa mai thay, chúng ta luôn đồng ý với các điều khoản và điều kiện này, và lý do họ đưa ra là: “Này, bạn được trải nghiệm sản phẩm không quảng cáo.” Họ tuyên bố đó là cách bạn được bồi thường. Nhưng chúng ta đều rất rõ ràng rằng giá trị của quảng cáo thấp hơn rất nhiều so với giá trị của dữ liệu bị sử dụng.
Triết lý của chúng tôi với Grass là, nếu cuộc chiến dữ liệu xảy ra, chúng tôi có thể không ngăn được nó, nhưng ít nhất chúng tôi nên có cơ hội tham gia. Chúng tôi nên có lựa chọn, hoặc bán vũ khí trong cuộc chiến dữ liệu, hoặc tạo ra một bộ dữ liệu mở khổng lồ cho Internet, nơi bất kỳ ai cũng có thể dùng để huấn luyện mô hình AI của riêng họ.
Việc tham gia Grass và nhận được một số lợi ích có dễ dàng đối với mọi người không?

0xdrej: Hiện tại mạng lưới đang trong giai đoạn kiểm thử beta, rất đơn giản. Bởi vì phần cứng bạn cần đã có sẵn trên thiết bị của bạn. Tất cả những gì bạn cần là một mã mời. Sau đó, bạn chỉ cần tạo một tài khoản hoặc ứng dụng Saga, và bạn đã sẵn sàng, quy trình bắt đầu rất mượt mà.
Một vấn đề chúng tôi gặp phải gần đây là số lượng người dùng tăng trưởng nhanh hơn dự kiến. Do đó, khi chúng tôi đang mở rộng hạ tầng, người dùng có thể gặp một vài sự cố nhỏ.
Ông nghĩ quy mô thị trường này lớn đến mức nào?
0xdrej: Hiện tại, chúng tôi thực tế đang nhắm tới hai lĩnh vực chuyên biệt, hoặc ba lĩnh vực, mỗi lĩnh vực có quy mô thị trường khác nhau.
Thứ nhất là ngành dữ liệu thay thế, tôi tin rằng đây là một thị trường trị giá 20 tỷ đô la Mỹ. Khi tôi nói dữ liệu thay thế, chủ yếu là dữ liệu được các quỹ phòng hộ sử dụng. Ví dụ, nếu bạn tìm kiếm giá cả và hàng tồn kho của một số cửa hàng nhất định, bạn có thể ước tính lợi nhuận hàng quý của một công ty. Các quỹ phòng hộ sẵn sàng trả tiền cho loại thông tin này.

Bản thân thị trường thu thập dữ liệu qua web, mặc dù vẫn còn non trẻ, hiện đang có giá trị hàng tỷ đô la và đang tăng trưởng mạnh mẽ. Lý do tăng trưởng quy mô lớn như vậy nằm ở thị trường thứ ba, đó là trí tuệ nhân tạo (AI).
Quy mô thị trường dữ liệu AI hiện tại rất khó định lượng. Quy mô của nó có thể đang tăng theo cấp số nhân mỗi ngày, và chúng tôi khó có thể định giá chính xác. Nhưng khi bạn thấy có người đang bàn về việc bán dữ liệu cho các bộ dữ liệu AI, bạn sẽ hiểu rằng đây là một cơ hội khổng lồ.
Vậy thì, khi số lượng người dùng tăng lên, Grass có trở nên có giá trị và cạnh tranh hơn không?
0xdrej: Vâng, đây là một câu hỏi rất hay. Mạng lưới càng lớn thì khả thi càng cao.
Tôi có thể lấy một ví dụ, đó là hivemapper, tôi nghĩ đây là một sản phẩm và ý tưởng rất thú vị. Nếu bạn muốn lập bản đồ toàn bộ thế giới, nhưng chỉ có 10 chiếc xe đang chạy, bạn chỉ nhận được một phần rất nhỏ của bản đồ. Nó có thể hữu ích cho một vài ứng dụng nhỏ và cụ thể, nhưng không thực sự phổ biến.
Tuy nhiên, nếu bạn có hàng triệu tài xế đang lập bản đồ mọi con đường trên thế giới, bạn có thể tạo ra một bức tranh toàn diện hơn. Sau đó, bạn có thể bán sản phẩm tốt hơn với mức giá cao hơn, và hiệu quả kinh tế trên mỗi đơn vị sẽ tăng lên đáng kể đối với mỗi người tham gia.
Hãy suy nghĩ kỹ, Grass về cơ bản là đang lập bản đồ toàn bộ Internet.
Vì vậy, hãy để tôi đưa thêm một ví dụ nữa, ứng dụng này không liên quan đến AI, nhưng thuộc về một ngành công nghiệp khổng lồ — vé máy bay, du lịch và khách sạn. Nếu bạn là một trang web tổng hợp du lịch, bạn muốn lấy được mức giá tốt nhất từ mọi nhà cung cấp ở mỗi địa điểm. Ví dụ, giá vé bay từ Berlin đến Singapore có thể khác nhau khi xem từ New York và từ Berlin. Trang web tổng hợp du lịch cần biết giá vé của mỗi chuyến bay tại càng nhiều địa chỉ IP càng tốt để có được sản phẩm tốt nhất. Bây giờ, nếu họ chỉ có một vài địa điểm ở Singapore, Trung Quốc và Mỹ, và ai đó đang cố gắng bay giữa hai địa điểm ở châu Âu, thì việc thu thập đúng giá sẽ rất khó khăn với họ. Mạng lưới mở rộng quy mô sẽ mở khóa thêm nhiều trường hợp sử dụng, điều này thật sự hấp dẫn.
Khi mạng lưới phát triển, ông có nghĩ rằng phần thưởng của người dùng sẽ bị pha loãng không? Hay sẽ đạt được sự cân bằng do mạng lưới trở nên sinh lời hơn?
0xdrej: Tôi sẽ cố gắng tránh đưa ra bất kỳ tuyên bố dự báo nào để trả lời câu hỏi này. Biến số đầu tiên là mạng lưới hiện tại rất gần với trạng thái sử dụng được, đó là lý do tại sao trong giai đoạn beta này, chúng tôi chọn bồi thường thời gian hoạt động. Chúng tôi không có ý định thưởng mãi mãi cho thời gian trực tuyến của người dùng.
Vì vậy, hiện tại là thời điểm duy nhất bạn có thể kiếm điểm chỉ bằng cách giữ thiết bị trực tuyến. Trong tương lai, các nút sẽ chỉ được bồi thường khi sử dụng băng thông thực tế. Về sự cân bằng, tôi đã nhắc đến lĩnh vực du lịch trước đó là một ví dụ rất tốt.
Trong lĩnh vực đó, bạn sẽ không bao giờ có đủ nút. Đối với trang web tổng hợp du lịch, để duy trì tính cạnh tranh, trang tổng hợp cạnh tranh nhất thực ra là trang có nhiều nút nhất. Vì vậy, nếu bạn có thể mở khóa điều này, họ sẽ chỉ đổ thêm nội dung và tăng thông lượng qua mạng lưới.
Lý do gì khiến ông quyết định phát triển trên Solana?
0xdrej: Đối với những gì chúng tôi đang cố gắng thực hiện, việc sở hữu một chuỗi có thông lượng cao là rõ ràng rất quan trọng. Khi mạng lưới Grass ra mắt, nó sẽ trở thành một trong những giao thức tiền mã hóa có số lượng người dùng đông nhất. Điều này đòi hỏi phí Gas phải cực kỳ thấp để khuyến khích người dùng. Solana hiện tại là chuỗi tiết kiệm Gas nhất, và có lẽ cũng là nhanh nhất. Một số cập nhật sắp tới (ví dụ như FireDancer) rất đáng mong đợi, vì xử lý giao dịch song song chính là thứ chúng tôi cần.
Có rất nhiều giao thức DePin trên Solana, về mặt phát triển kinh doanh, chúng tôi rất vui khi được hợp tác với một số giao thức DePin khác. Một điều rất thú vị mà chúng tôi nhận thấy là Solana có điện thoại riêng của mình, và chúng tôi tin rằng tỷ lệ sử dụng điện thoại Solana sẽ chỉ tăng lên. Đây là điều mà không chuỗi nào khác có thể cung cấp. Đối với chúng tôi, việc cài đặt một ứng dụng trên điện thoại Solana là lựa chọn hiển nhiên.
Ông có tìm cảm hứng từ các dự án khác trong lĩnh vực DePin, ví dụ như Helium không?
0xdrej: Tất nhiên rồi, toàn bộ tư tưởng đứng sau DePin thực chất là về bản thân bạn. Không chỉ bạn đang trả quá nhiều cho rất nhiều thứ trong cuộc sống, mà bạn còn bị tước đoạt những thứ vốn có thể giúp bạn kiếm tiền.
Gần đây, làn sóng thúc đẩy phi tập trung hóa từ DePin, và những gì Helium Mobile và điện thoại Saga đang làm, đã khiến mọi người mở mang tầm mắt. Nó giống như, tôi nắm giữ rất nhiều tài nguyên, nhưng trong nhiều trường hợp, những tài nguyên này lại bị lấy đi khỏi tôi. Nhưng giờ đây, mọi người nhìn thấy một con đường khác, nơi bạn có quyền lựa chọn không chấp nhận điều này xảy ra. Điều này rất mạnh mẽ, và tôi không muốn bỏ lỡ. Vì vậy, chúng tôi đã lấy cảm hứng rất nhiều từ đó.
Nhìn về tương lai, Grass sẽ như thế nào vào năm 2024? Ông có thể chia sẻ một chút về lộ trình của mình không?
0xdrej: Chúng tôi dự kiến sẽ khởi động toàn bộ mạng lưới vào một thời điểm nào đó trong năm 2024, tôi nghĩ điều này sẽ không khiến ai ngạc nhiên.
Ngoài ra, trong lộ trình, chúng tôi muốn hiện thực hóa bằng chứng yêu cầu sử dụng zk-TLS, liên kết yêu cầu mạng với bộ dữ liệu, điều này có thể xảy ra vào nửa cuối năm. Chúng tôi cũng có kế hoạch phi tập trung hóa nhiều bộ sắp xếp (sequencer) của mình. Cách thức triển khai vẫn đang được xác định, nhưng chúng tôi có rất nhiều ý tưởng thú vị, cho phép mọi người dễ dàng vận hành hạ tầng Grass hơn.

Chúng tôi cũng đang xem xét vấn đề phần cứng. Hiện tại, chi phí sử dụng Grass là bằng không, chúng tôi rất thích điều này và dự định sẽ giữ như vậy mãi mãi. Nhưng giả sử bạn không muốn thiết bị của mình luôn bật, hoặc vì lý do nào đó bạn không muốn chạy nút trên thiết bị của mình. Chúng tôi muốn cho mọi người một lựa chọn: chỉ cần mua một hộp thiết bị, kết nối nó với Internet và để nó chạy nền. Ngoài sở thích cá nhân, một khía cạnh thú vị của việc sở hữu phần cứng là chúng tôi thực sự có thể đặt các tác nhân AI (AI agents) bên trong và cho phép chúng chạy. Chúng có thể thực hiện rất nhiều công việc thu thập và duyệt web thay bạn. Tất cả những gì bạn cần làm là ngồi yên và để các tác nhân AI đó thực hiện công việc, giống như sở hữu một chiếc xe tự lái có thể vẽ bản đồ vậy.
Nếu bạn muốn đóng góp nhiều hơn cho mạng lưới, thì chúng tôi hy vọng sẽ có một thiết bị như vậy để bạn sử dụng.
Chúng tôi đang phát triển một số tính năng nhỏ, như thêm yếu tố game hóa vào bảng điều khiển. Chúng tôi cũng muốn thêm một số tính năng trứng phục sinh (easter egg) đặc biệt dành riêng cho người dùng Saga, hiện đang khám phá các ý tưởng này. Ngoài ra, chúng tôi cũng đang nghiên cứu các phiên bản cho các thiết bị khác. Bây giờ, chúng tôi không chỉ nghĩ đến tiện ích mở rộng trình duyệt, mà còn nghĩ đến việc cho phép mọi người tải về nếu họ cần. Có rất nhiều người không thích cài tiện ích mở rộng, điều đó hoàn toàn ổn. Vì vậy, chúng tôi dự định mở rộng sang các nền tảng khác như Android, iOS, Raspberry Pi, Linux, v.v.
Tổng thể, chúng tôi muốn mang đến cho mọi người nhiều lựa chọn hơn, để họ có thể dễ dàng tham gia vào mạng lưới Grass.
Ông nhìn nhận cấu trúc quản trị của Grass như thế nào? Liệu nó sẽ trở thành một mạng lưới phi tập trung hoàn toàn do cộng đồng sở hữu?
0xdrej: Chúng tôi có nhiều giai đoạn hướng tới sự phi tập trung. Giai đoạn đầu tiên là cơ chế xác thực, nơi chúng tôi có thể thưởng cho đóng góp của người dùng trên chuỗi.
Giai đoạn thứ hai liên quan đến việc phi tập trung hóa bộ sắp xếp (sequencer) và một số nội dung phê duyệt yêu cầu thu thập. Quản trị đóng vai trò then chốt ở đây. Về cơ bản, chúng tôi muốn trở thành một mạng lưới cung cấp dữ liệu khổng lồ, nơi các thành viên cộng đồng có thể nói: “Này, tôi đang huấn luyện mô hình AI này, tôi cần những bộ dữ liệu kiểu này, tôi muốn đề xuất chuyển công việc thu thập sang thu thập những dữ liệu này.” Sau đó, bộ sắp xếp có thể kiêm luôn vai trò trình xác thực để đảm bảo việc thu thập đúng dữ liệu.
Một trong số ít tính năng quản trị mà chúng tôi muốn bao gồm là bảo vệ mạng lưới. Trong một mạng lưới phi tập trung, nếu được thực hiện đúng, thường sẽ đạt được hiệu quả thị trường theo thời gian. Có rất nhiều ứng dụng có thể tận dụng CPU, GPU chưa dùng đến để tạo thu nhập, thường dưới dạng tiền pháp định. Ban đầu họ có thể trả một mức nhất định cho người tham gia, sau đó giảm dần theo thời gian, và cuối cùng lợi nhuận trở nên rất nhỏ.
Thông qua cấu trúc quản trị, bạn có thể bảo vệ cộng đồng, bởi vì những người đóng góp cho mạng lưới thực sự sở hữu một phần mạng lưới. Đây là trạng thái mà chúng tôi muốn đạt được, tức là mỗi người chạy nút trong mạng lưới Grass đều sở hữu một phần của chính mạng lưới đó.
Ông có nghĩ rằng hiện tại về lý thuyết ông đã có quy mô đủ lớn để khởi động mạng lưới chưa? Hay ông vẫn muốn tăng thêm số lượng nút trước khi ra mắt?
0xdrej: Về tổng số lượng nút, chúng tôi rất gần với mục tiêu. Tuy nhiên, ở một số khu vực địa lý cụ thể, chúng tôi thực sự chưa đạt được. Có những khu vực địa lý mà mọi người muốn thu thập một loại nội dung nhất định, và nhu cầu ở đó thực tế cao hơn nguồn cung. Chúng tôi muốn đảm bảo rằng chúng tôi có khả năng đáp ứng mọi nhu cầu, đây là mục tiêu khi chúng tôi khởi động mạng lưới.
Như bạn biết, chúng tôi đang trong giai đoạn kiểm thử, vì vậy chúng tôi đang cố gắng hết sức để đảm bảo mạng lưới có thể mở rộng. Do tốc độ tăng trưởng nhanh hơn dự kiến, người dùng gặp một số vấn đề khi kết nối vào mạng và hiển thị trên bảng điều khiển. Những vấn đề này đều nằm trong kế hoạch giải quyết trước khi khởi động toàn bộ mạng lưới. Đó là lý do vì sao chúng tôi vẫn đang trong giai đoạn kiểm thử. Vì vậy, về số lượng nút, chúng tôi đang xem xét rất nhiều yếu tố. Nhìn chung, chúng tôi khá hài lòng với tình hình hiện tại.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News