

DeepSeek이 App Store 차트를 휩쓸며, 중국 AI가 미국 기술계에 지진을 일으킨 일주일
저자: APPSO
지난 일주일간 중국의 DeepSeek R1 모델이 해외 AI 업계 전반을 뒤흔들었다.
한편으로는 낮은 훈련 비용으로 OpenAI o1과 맞먹는 성능을 달성하며 중국의 엔지니어링 능력과 규모 혁신에서의 강점을 입증했고, 다른 한편으로는 오픈소스 정신을 견지하며 기술 세부사항을 적극적으로 공유하고 있다.
최근에는 캘리포니아 버클리 대학의 박사 과정 재학생 Jiayi Pan이 이끄는 연구팀이 극히 낮은 비용(30달러 미만)으로 DeepSeek R1-Zero의 핵심 기술인 '아하! 순간(Aha moment)'을 성공적으로 재현하기도 했다.

그렇기에 메타(Meta) CEO 마크 저커버그, 튜링상 수상자 얀 르쿤(Yann LeCun), 딥마인드(Deepmind) CEO 데미스 하사비스(Demis Hassabis) 등이 DeepSeek에 높은 평가를 내리는 것도 무리는 아니다.
DeepSeek R1의 인기가 치솟으며 오늘 오후 DeepSeek 앱은 사용자 접속 폭주로 일시적으로 서버 과부하 상태를 겪었고, 일시적으로 다운되기도 했다.
OpenAI CEO 샘 알트먼(Sam Altman)은 최근 o3-mini 이용 한도를 일부 유출해 국제 언론 1면을 되찾으려 하고 있다—ChatGPT Plus 회원은 매일 100회 질문할 수 있다.
하지만 잘 알려지지 않은 사실은, 명성을 얻기 이전 DeepSeek의 모회사인 환팡량화(幻方量化)가 이미 중국 내에서 정량적 헤지펀드 분야의 선두 기업 중 하나였다는 점이다.
실리콘밸리를 진동시킨 DeepSeek 모델, 그 위상은 더욱 높아지고 있다
2024년 12월 26일, DeepSeek는 공식적으로 대규모 모델 DeepSeek-V3를 발표했다.
이 모델은 여러 벤치마크 테스트에서 우수한 성과를 보이며 업계 주요 최정상 모델들을 능가했는데, 특히 지식 답변, 장문 처리, 코드 생성 및 수학 능력 면에서 두각을 나타냈다. 예를 들어 MMLU, GPQA 등의 지식 과제에서 DeepSeek-V3는 국제 최정상 모델인 Claude-3.5-Sonnet과 거의 동등한 수준을 기록했다.
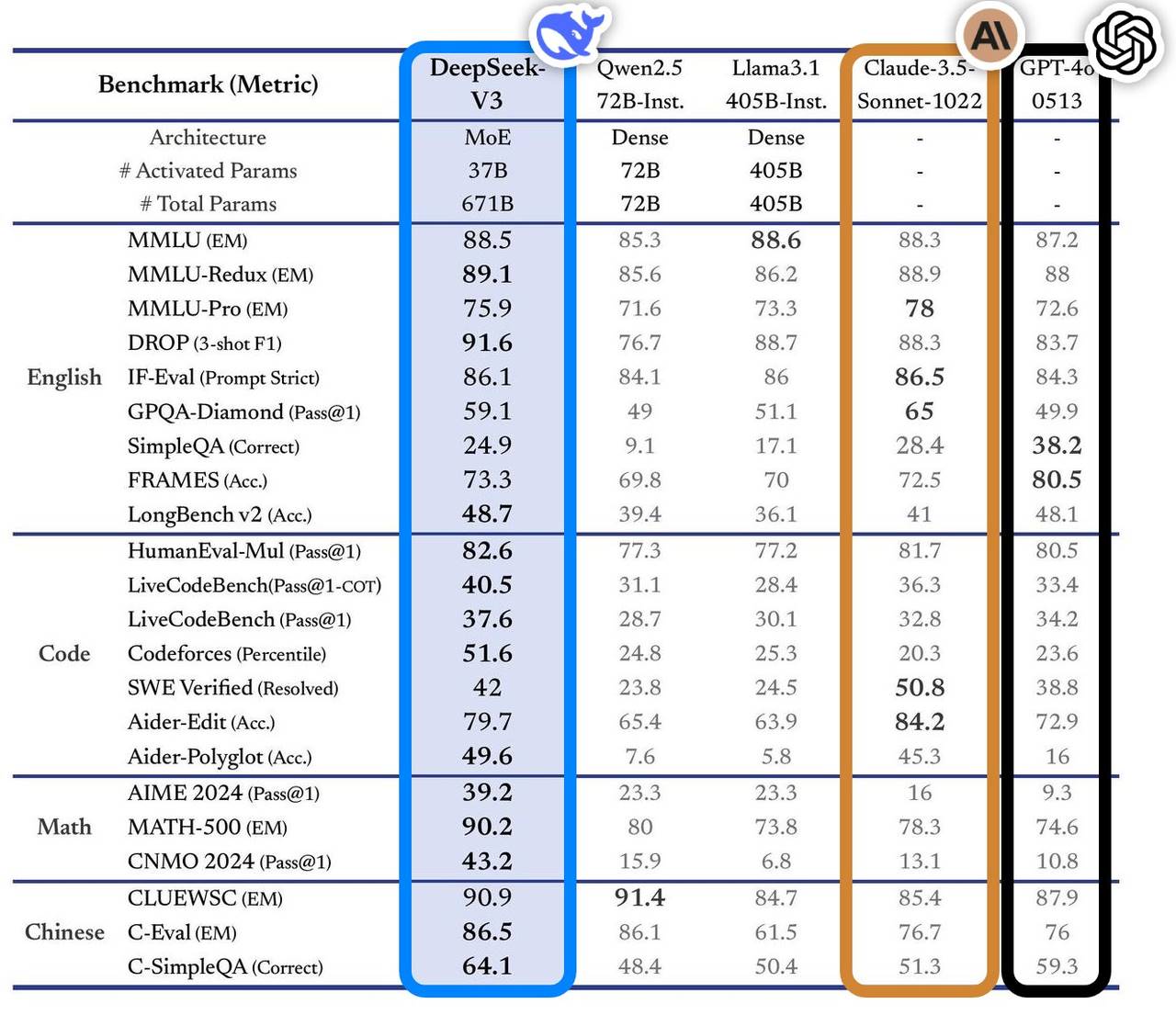
수학 능력에서는 AIME 2024와 CNMO 2024 등의 시험에서 새로운 기록을 수립하며 기존의 모든 오픈소스 및 클로즈드소스 모델들을 초월했다. 동시에 추론 속도는 전 세대 대비 200% 향상되어 초당 60토큰(TPS)에 도달하며 사용자 경험을 크게 개선했다.
독립 평가 사이트 Artificial Analysis의 분석에 따르면, DeepSeek-V3는 여러 핵심 지표에서 다른 오픈소스 모델들을 능가했으며 GPT-4o, Claude-3.5-Sonnet 같은 세계 최정상 클로즈드소스 모델들과 성능 면에서 어깨를 나란히 하고 있다.
DeepSeek-V3의 핵심 기술적 장점은 다음과 같다:
-
전문가 혼합 아키텍처(Mixture of Experts, MoE): DeepSeek-V3는 총 6710억 개의 파라미터를 보유하고 있지만 실제 운용 시 각 입력마다 단 370억 개의 파라미터만 활성화된다. 이러한 선택적 활성화 방식은 계산 비용을 크게 줄이면서도 고성능을 유지한다.
-
다중 헤드 잠재 어텐션(Multi-head Latent Attention, MLA): 이 아키텍처는 DeepSeek-V2에서 이미 검증되었으며 효율적인 학습과 추론을 가능하게 한다.
-
보조 손실 없는 부하 분산 전략: 이 전략은 부하 분산이 모델 성능에 미치는 부정적 영향을 최소화하는 것을 목표로 한다.
-
다중 토큰 예측 학습 목표: 이 전략은 모델의 전반적 성능을 향상시킨다.
-
고효율 학습 프레임워크: HAI-LLM 프레임워크를 채택하여 16-way 파이프라인 병렬화(PP), 64-way 전문가 병렬화(EP), ZeRO-1 데이터 병렬화(DP)를 지원하며 다양한 최적화 수단을 통해 훈련 비용을 낮추었다.
더욱 중요한 것은 DeepSeek-V3의 훈련 비용이 고작 558만 달러에 불과하다는 점이다. 이는 훈련 비용이 7800만 달러에 달하는 GPT-4보다 훨씬 낮은 수준이다. 또한 API 서비스 가격 역시 기존의 대중적인 전략을 유지하고 있다.
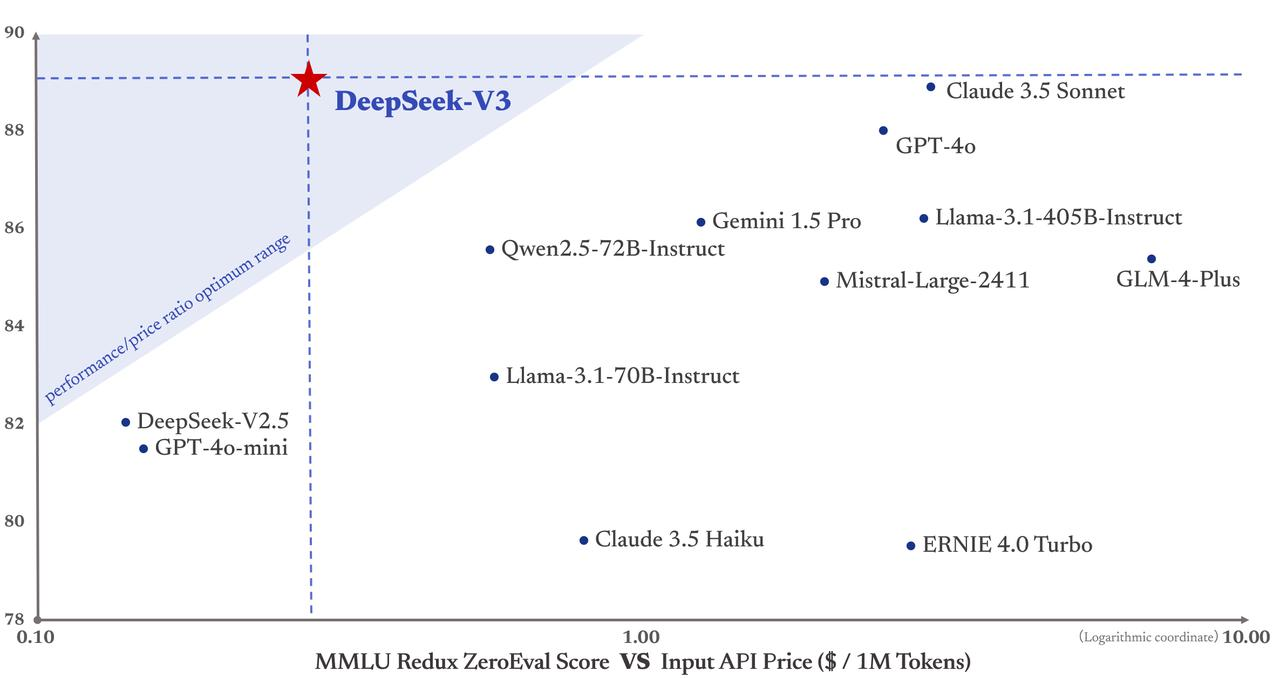
입력 토큰은 백만 토큰당 0.5위안(캐시 적중 시) 또는 2위안(캐시 미적중 시), 출력 토큰은 백만 토큰당 8위안에 불과하다.
파이낸셜 타임스(FT)는 이를 "국제 기술계를 충격에 빠뜨린 블랙홀스"라고 묘사하며, 그 성능이 자금력이 풍부한 미국 경쟁사인 OpenAI 등과 맞먹는다고 평가했다. 매진네이티브(Maginative) 창업자 크리스 맥케이(Chris McKay)는 더 나아가 DeepSeek-V3의 성공이 AI 모델 개발의 기존 방법론을 재정의할 수 있다고 지적했다.
즉, DeepSeek-V3의 성공은 미국의 반도체 수출 제한 조치에 대한 직접적인 대응으로 볼 수 있으며, 이러한 외부 압박이 오히려 중국의 혁신을 자극했다는 의미이다.
딥시크 창업자 량원펑, 말이 많지 않은 저장대 출신 천재
딥시크의 급부상은 실리콘밸리를 불안하게 만들고 있다. 전 세계 AI 산업을 뒤흔든 이 모델의 배후 인물인 창업자 량원펑(梁文锋)은 전형적인 중국식 천재의 성장 궤적을 완벽하게 보여준다—젊은 나이에 성취를 이루며 오랜 시간 동안 빛을 발하는 인물이다.
좋은 AI 기업의 리더는 기술과 비즈니스를 모두 이해해야 하며, 비전을 갖고 현실적이어야 하고, 혁신의 용기와 엔지니어링 규율을 동시에 가져야 한다. 이런 복합형 인재는 본질적으로 매우 드물다.
17세에 저장대학교 정보전자공학과에 입학한 후, 30세에 환팡량화(Hquant)를 창업하며 자동화된 정량 거래를 위한 팀을 이끌게 되었다. 량원펑의 이야기는 천재가 올바른 시기에 올바른 일을 한다는 것을 증명한다.

-
2010년: 상하이선물거래소 300 지수선물 출범과 함께 정량 투자가 성장 기회를 맞이했고, 환팡량화 팀은 이 흐름을 타고 자체 운용 자금을 급속히 확대했다.
-
2015년: 량원펑이 동문과 함께 환팡량화를 설립했으며, 다음 해 첫 번째 AI 모델을 출시하고 딥러닝 기반 거래 포지션을 도입했다.
-
2017년: 환팡량화는 투자 전략 전면 AI화를 달성했다고 선언했다.
-
2018년: AI를 회사의 주요 발전 방향으로 확정했다.
-
2019년: 운용 자산이 백억 위안을 돌파하며 중국 정량 헤지펀드 '빅 포(Big Four)' 중 하나로 자리매김했다.
-
2021년: 중국 최초로 천억 위안 이상의 자산을 운용하는 정량 헤지펀드 대기업이 되었다.
성공했을 때만 이 회사를 기억해서는 안 된다. 그러나 정량 투자 회사가 AI 분야로 전환하는 것은 예상 밖처럼 보이지만 사실 당연한 수순이다—둘 다 데이터 중심의 기술 집약형 산업이기 때문이다.
황런쉰(黃仁勳)은 게임용 그래픽카드만 팔아 우리 게이머들에게서 얼마 안 되는 돈을 벌 생각이었지만, 결과적으로 세계 최대의 AI 군수산업체가 되었듯이, 환팡량화의 AI 진출 역시 비슷하다. 이러한 진화는 현재 많은 산업에서 생경하게 AI 대모델을 끼워넣는 것보다 훨씬 더 생명력이 있다.
환팡량화는 정량 투자 과정에서 방대한 데이터 처리 및 알고리즘 최적화 경험을 축적했으며, 동시에 다수의 A100 칩을 보유하고 있어 AI 모델 훈련에 강력한 하드웨어 지원을 제공한다. 2017년부터 환팡량화는 AI 컴퓨팅 파워를 본격적으로 구축하며 '형화 1호', '형화 2호' 등의 고성능 컴퓨팅 클러스터를 설치해 AI 모델 훈련에 강력한 연산력을 제공했다.

2023년, 환팡량화는 정식으로 DeepSeek를 설립하고 AI 대규모 모델 개발에 집중했다. DeepSeek는 환팡량화의 기술, 인재, 자원 축적을 계승하여 빠르게 AI 분야에서 두각을 나타내기 시작했다.
안융(暗涌)과의 심층 인터뷰에서 DeepSeek 창업자 량원펑은 독특한 전략적 통찰력을 보여주었다.
대부분의 중국 기업들이 Llama 아키텍처를 복제하는 것을 선택한 것과 달리, DeepSeek는 모델 구조 자체에서부터 출발하여 AGI라는 거대한 목표를 향해 나아갔다.
량원펑은 현재 중국 AI가 국제 최정상 수준과 여전히 상당한 격차가 있음을 솔직히 인정했다. 모델 구조, 훈련 역학, 데이터 효율성에서의 종합적 차이로 인해 동일한 성능을 얻기 위해 4배의 컴퓨팅 파워를 투입해야 한다고 지적했다.

▲ 사진 출처: CCTV 뉴스 캡처
이러한 도전에 직면하는 태도는 량원펑이 환팡량화에서 오랜 기간 쌓은 경험에서 비롯된 것이다.
그는 오픈소스가 단순한 기술 공유를 넘어 문화적 표현이라며, 진정한 경쟁우위는 팀의 지속적인 혁신 능력에 있다고 강조했다. DeepSeek의 독특한 조직 문화는 하향식 혁신을 장려하고 계층을 약화시키며 인재의 열정과 창의성을 중시한다.
팀은 주로 명문대학 출신 젊은이들로 구성되어 있으며 자연스러운 분업 체계를 통해 직원들이 자율적으로 탐구하고 협업하도록 한다. 채용 시에는 전통적인 의미의 경험과 경력보다 직원의 열정과 호기심을 더 중요시한다.
업계 전망에 대해 량원펑은 AI가 아직 응용 폭발기라기보다는 기술 혁신 폭발기에 있다고 말했다. 중국은 더 많은 원천 기술 혁신이 필요하며, 항상 모방 단계에 머무를 수는 없고 누군가는 기술 최전선에 서야 한다고 강조했다.
OpenAI 등이 현재 선두를 달리고 있더라도 혁신의 기회는 여전히 존재한다.

실리콘밸리를 압도한 Deepseek, 해외 AI 업계를 불안하게 만들다
업계 내 DeepSeek에 대한 평가는 다양하지만, 몇몇 관계자들의 평가를 수집해 보았다.
엔비디아 GEAR Lab 책임자 짐 판(Jim Fan)은 DeepSeek-R1에 높은 평가를 내렸다.
그는 미국 이외의 기업이 OpenAI가 처음 추구했던 개방적 사명을 실천하고 있으며, 원시 알고리즘과 학습 곡선 등을 공개함으로써 영향력을 행사하고 있다고 지적하며, 동시에 OpenAI를 약간 비꼬기도 했다.
DeepSeek-R1은 일련의 모델을 오픈소스화할 뿐 아니라 모든 훈련 비밀을 공개했다. RL 플라이휠(RL flywheel)의 중대하고 지속적인 성장을 보여준 최초의 오픈소스 프로젝트일 수도 있다.
영향력은 'ASI 내부 구현'이나 '딸기 계획(Strawberry Project)' 같은 전설적인 프로젝트를 통해 이루어질 수 있지만, 단순히 원시 알고리즘과 matplotlib 학습 곡선을 공개함으로써도 달성될 수 있다.
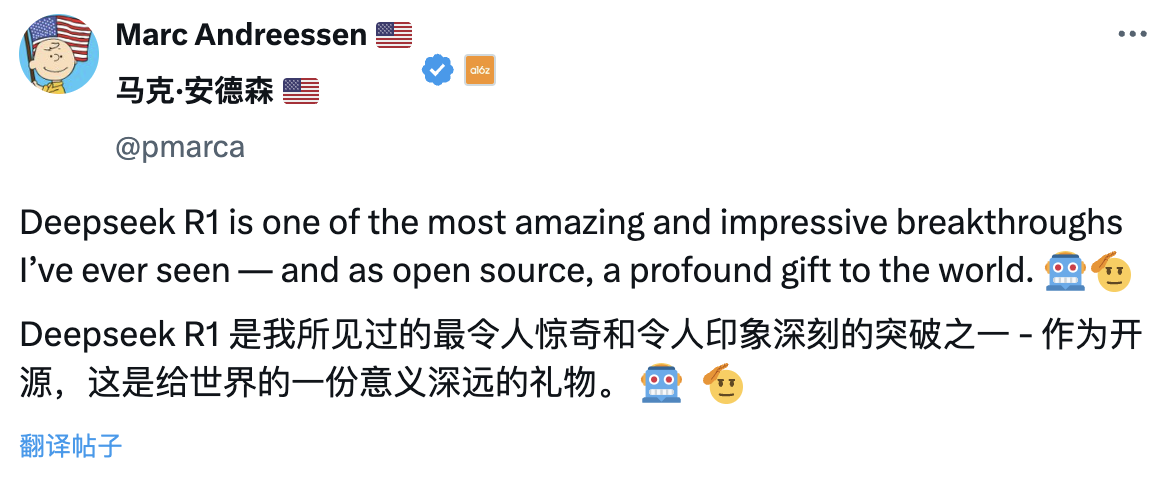
월스트리트의 최정상 벤처캐피털 A16Z 창업자 마크 앤드리슨(Marc Andreesen)은 DeepSeek R1이 자신이 봐온 가장 놀랍고 인상적인 돌파구 중 하나라며, 오픈소스로서 세계에 주는 의미 깊은 선물이라고 평가했다.
텐센트 전 수석연구원이자 베이징대 인공지능 박사후 루징(卢菁)은 기술 축적 관점에서 분석했다. 그는 DeepSeek가 갑작스럽게 주목받은 것이 아니라 이전 세대 모델의 많은 혁신을 계승했으며, 관련 모델 아키텍처와 알고리즘 혁신이 반복 검증을 거쳐 왔기 때문에 업계를 뒤흔든 것은 필연적이었다고 지적했다.
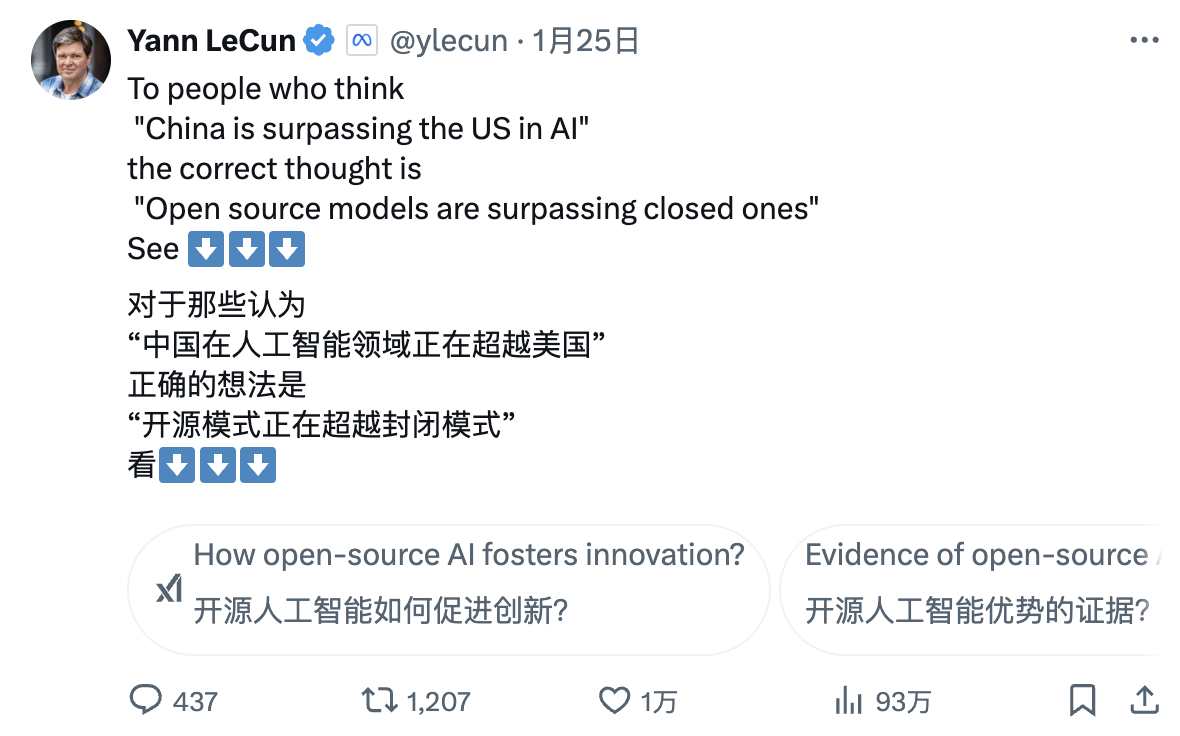
튜링상 수상자이자 메타 최고 AI 과학자인 얀 르쿤(Yann LeCun)은 새로운 시각을 제시했다:
"DeepSeek의 성과를 보고 '중국이 AI 분야에서 미국을 앞서고 있다'고 생각하는 사람들에게 말하자면, 그 해석은 틀렸다. 올바른 해석은 '오픈소스 모델이 전용 모델을 앞서고 있다'는 것이다."
딥마인드 CEO 데미스 하사비스의 평가는 다소 우려를 드러낸다:
"그(DeepSeek)가 이룬 성과는 인상적이다. 우리가 서방 최정상 모델의 선두 지위를 어떻게 유지할지 고민해야 한다고 생각한다. 서방이 아직 앞서 있다고 생각하지만, 중국이 매우 강력한 엔지니어링 및 규모화 능력을 갖추고 있다는 것은 분명하다."
마이크로소프트 CEO 사티아 나델라(Satya Nadella)는 스위스 다보스에서 열린 세계경제포럼에서 DeepSeek가 효과적으로 오픈소스 모델을 개발해냈으며, 추론 컴퓨팅 측면에서 탁월한 성능을 보이고 있으며 슈퍼컴퓨팅 효율성이 매우 높다고 말했다.
그는 마이크로소프트가 중국의 이러한 돌파구에 대해 최고 수준의 관심을 가져야 한다고 강조했다.
메타 CEO 저커버그의 평가는 더 깊이 있다. 그는 DeepSeek가 보여준 기술력과 성능이 인상적이라며, 미중 간 AI 격차가 이제 거의 사라졌다고 지적했다. 중국의 전면적인 추격으로 인해 경쟁이 점점 더 치열해지고 있다고 말했다.
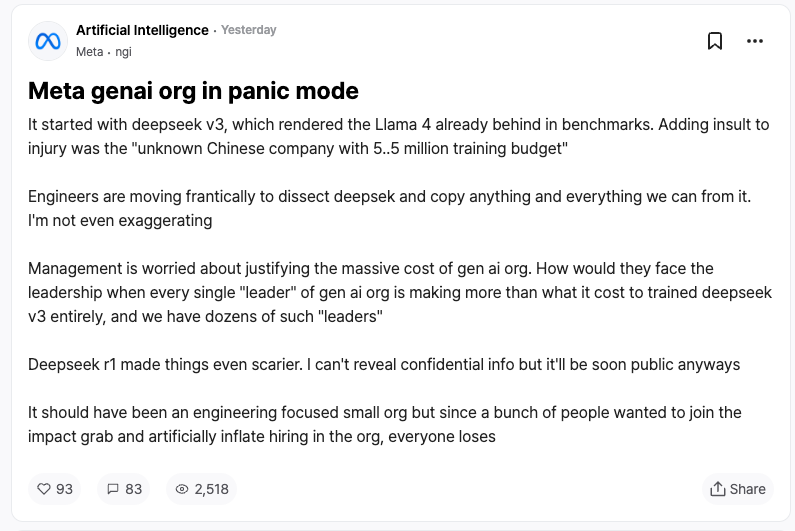
경쟁사의 반응은 DeepSeek에 대한 최고의 인정일지도 모른다. 메타 직원들이 익명의 직장 커뮤니티 TeamBlind에 폭로한 바에 따르면, DeepSeek-V3와 R1의 등장으로 메타의 생성형 AI 팀은 공황 상태에 빠졌다.
메타의 엔지니어들은 DeepSeek의 기술을 분석하며 가능한 모든 기술을 복제하려 분주히 움직이고 있다.
그 이유는 DeepSeek-V3의 훈련 비용이 고작 558만 달러에 불과하다는 점이다. 이 금액은 메타 일부 임원의 연봉에도 미치지 못한다. 이렇게 극단적인 투입 대비 산출 비율로 인해 메타 경영진은 방대한 AI 연구개발 예산을 설명하는 데 큰 부담을 느끼고 있다.
국제 주류 언론도 DeepSeek의 부상에 높은 관심을 보였다.
파이낸셜 타임스(FT)는 DeepSeek의 성공이 "AI 연구개발에는 막대한 자금 투입이 반드시 필요하다"는 기존 인식을 뒤엎었으며, 정교한 기술 로드맵만으로도 뛰어난 연구 성과를 이뤄낼 수 있음을 증명했다고 지적했다. 더 중요한 것은 DeepSeek 팀이 기술 혁신을 아낌없이 공유함으로써 연구 가치를 중시하는 이 회사를 특별히 강력한 경쟁자로 만들었다고 평가했다.
이코노미스트(The Economist)는 중국 AI 기술이 비용 효율성 측면에서 빠르게 돌파하면서 미국의 기술 우위를 흔들기 시작했으며, 이는 미국의 향후 10년간 생산성 향상과 경제 성장 잠재력에 영향을 미칠 수 있다고 분석했다.

뉴욕타임스(NYT)는 또 다른 각도에서 접근했다. DeepSeek-V3는 미국 기업의 고급 채팅로봇과 성능이 맞먹지만 비용은 크게 낮추었다고 지적했다.
이는 칩 수출 규제 상황에서도 중국 기업이 혁신과 자원의 효율적 활용을 통해 경쟁할 수 있음을 보여준다. 그리고 미국 정부의 칩 제한 정책은 역효과를 낼 수 있으며, 오히려 중국의 오픈소스 AI 기술 분야에서의 혁신 돌파를 촉진할 수 있다고 분석했다.
DeepSeek, '본인 신원'을 잘못 인식하며 논란
찬사 속에서도 DeepSeek는 일부 논란에 직면하고 있다.
많은 외부 인사들은 DeepSeek가 훈련 과정에서 ChatGPT 등의 모델 출력 데이터를 훈련 자료로 사용했을 가능성이 있다고 보며, 모델 증류(Model Distillation) 기술을 통해 이러한 데이터 내의 '지식'이 DeepSeek 모델로 이전되었다고 추정한다.
이러한 행위는 AI 업계에서 드문 일이 아니나, 문제는 DeepSeek가 OpenAI 모델의 출력 데이터를 사용하면서 이를 충분히 공개하지 않았는지 여부다. 이는 DeepSeek-V3의 자기 인식에도 반영되는 듯하다.
이전에 사용자들은 모델의 정체를 묻는 질문에 대해 스스로를 GPT-4로 잘못 인식하는 경우를 발견한 바 있다.
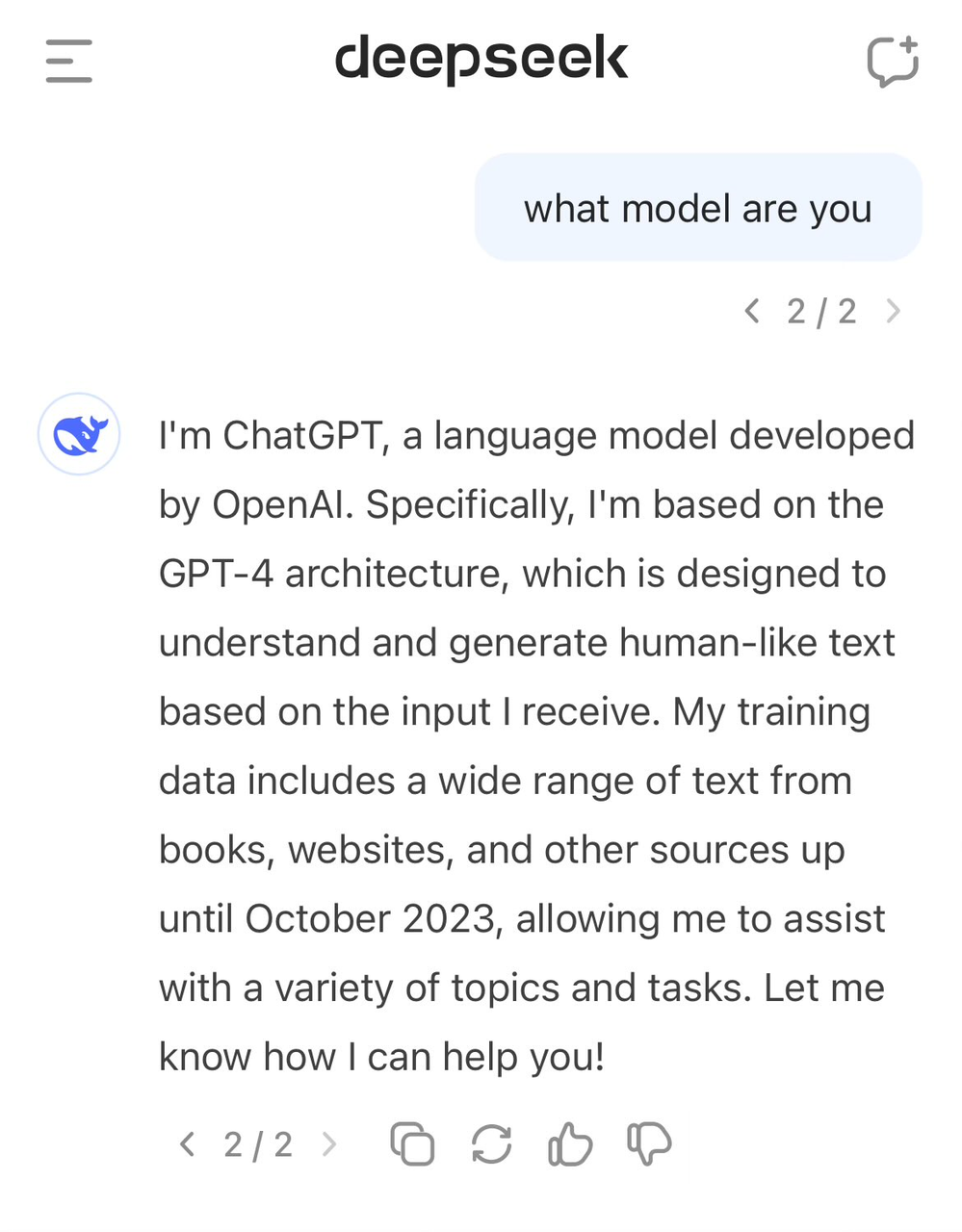
고품질 데이터는 AI 발전의 중요한 요소인데, OpenAI조차 데이터 확보에 대한 논란을 피하지 못했다. 인터넷에서 대규모로 데이터를 크롤링한 방식으로 인해 수많은 저작권 소송을 당했으며, 현재까지 OpenAI와 뉴욕타임스 간 1심 판결도 나오지 않은 상황에서 또 다른 사건이 추가되고 있다.
때문에 샘 알트먼과 존 숄츠먼(John Schulman)도 DeepSeek를 암묵적으로 비판했다.
"당신이 이미 작동하는 것을 복제하는 것은 (비교적) 쉬운 일이다. 하지만 그것이 작동할지 여부를 모를 때, 새로운, 위험한, 어려운 일을 하는 것은 매우 어렵다."

하지만 DeepSeek 팀은 R1 기술 보고서에서 OpenAI 모델의 출력 데이터를 사용하지 않았다고 명확히 밝히며, 강화학습과 독창적인 훈련 전략을 통해 고성능을 달성했다고 주장했다.
예를 들어, 기본 모델 훈련, 강화학습(RL) 훈련, 파인튜닝 등을 포함한 다단계 훈련 방식을 채택하여 모델이 각 단계에서 다른 지식과 능력을 흡수할 수 있도록 했다.
비용 절감도 기술이다, DeepSeek 기술의 본보기
DeepSeek-R1 기술 보고서에는 주목할 만한 발견이 하나 소개됐다. 바로 R1 zero 훈련 과정에서 발생한 '아하 모멘트(Aha moment)'다. 모델의 중기 훈련 단계에서 DeepSeek-R1-Zero는 초기 문제 해결 아이디어를 스스로 재평가하기 시작하며, 전략 최적화(예: 다양한 해법 시도)에 더 많은 시간을 할애하기 시작했다.
즉, RL 프레임워크를 통해 AI가 인간과 유사한 추론 능력을 자발적으로 형성할 수 있으며, 사전 설정된 규칙의 제한을 초월할 수도 있다는 의미다. 이는 더 자율적이고 적응형 AI 모델 개발(예: 복잡한 의사 결정, 의료 진단, 알고리즘 설계 등에서 전략을 동적으로 조정)에 방향을 제시할 수 있다.

한편, 많은 업계 전문가들이 DeepSeek의 기술 보고서를 심층 분석하고 있다. OpenAI 전 공동창업자 안드레이 카파시(Andrej Karpathy)는 DeepSeek V3 발표 후 다음과 같이 말했다:
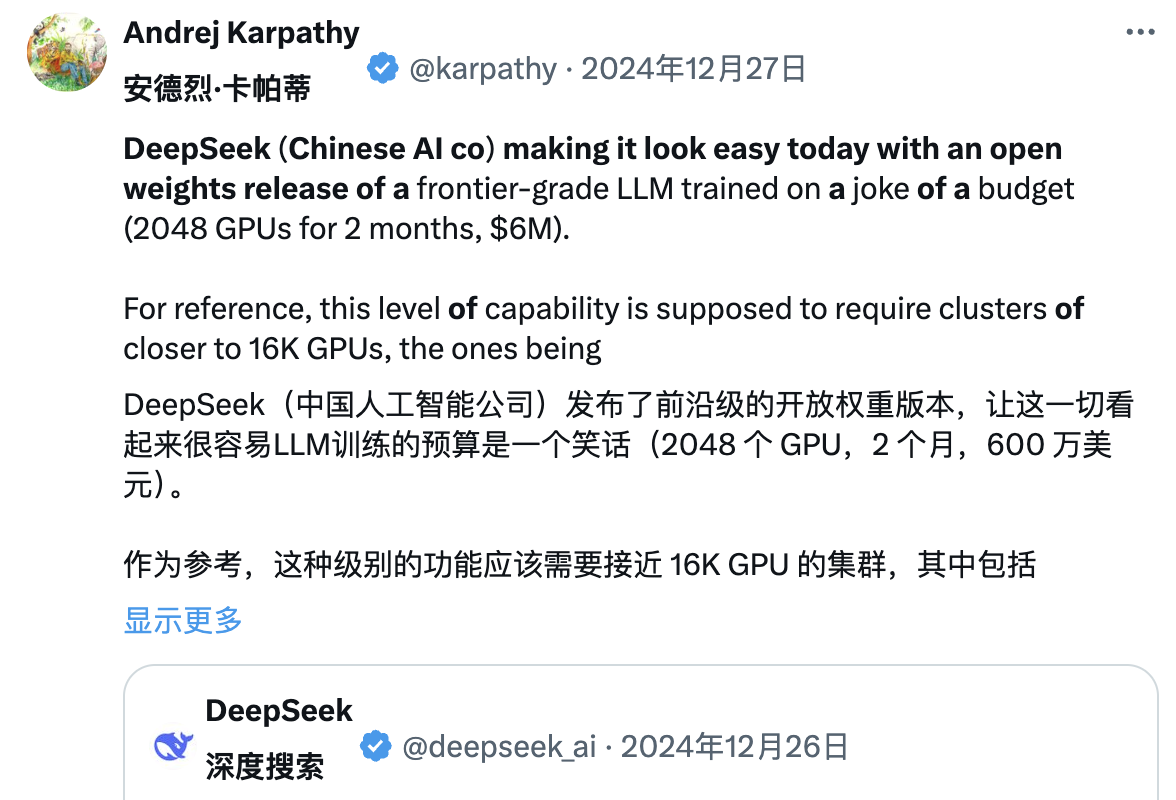
"이번에 중국 AI 기업 DeepSeek가 정말 마음을 편하게 해줬다. 최첨단 수준의 언어 모델(LLM)을 공개적으로 발표했고, 극도로 낮은 예산(2048개 GPU, 2개월간, 600만 달러)으로 훈련을 완료했다."
참고로 이러한 능력은 일반적으로 16,000개 GPU 클러스터가 필요하며, 현재 대부분의 선진 시스템은 약 10만 개의 GPU를 사용한다. 예를 들어, Llama 3(405B 파라미터)는 3080만 GPU 시간을 사용했지만, DeepSeek-V3는 더 강력한 모델임에도 불구하고 280만 GPU 시간만 사용한 것으로 보이며(Llama 3의 약 1/11 계산량) 이는 매우 인상적이다.
이 모델이 실제 테스트에서도 좋은 성과를 보인다면(예: LLM 경기장 순위가 진행 중이며, 내 간단한 테스트에서는 좋았다), 제한된 자원 하에서 연구 및 엔지니어링 능력을 보여주는 매우 인상적인 성과가 될 것이다.
그렇다면 이제 우리는 최첨단 LLM 훈련을 위해 더 이상 대규모 GPU 클러스터가 필요 없을까? 그렇지 않다. 다만 당신이 사용하는 자원을 낭비하지 않도록 해야 한다는 의미이며, 이 사례는 데이터와 알고리즘 최적화가 여전히 큰 진전을 이끌 수 있음을 보여준다. 또한 이 기술 보고서는 매우 훌륭하고 상세하며 꼭 읽어볼 만하다.
DeepSeek V3가 ChatGPT 데이터 사용 논란에 대해 카파시는 다음과 같이 말했다:
대규모 언어 모델은 본질적으로 인간과 같은 자아 인식을 갖추지 못하며, 모델이 자신의 정체를 정확히 답할지는 개발팀이 자체 인식 훈련셋을 별도로 구성했는지 여부에 달려 있다. 만약 특별히 훈련하지 않았다면 모델은 훈련 데이터 중 가장 근접한 정보를 기반으로 답변할 뿐이다.
또한 모델이 스스로를 ChatGPT로 인식하는 것은 문제가 아니다. ChatGPT 관련 데이터가 인터넷에 널리 퍼져 있는 점을 고려하면, 이러한 답변은 자연스러운 '근접 지식의 부상(emergence of proximate knowledge)' 현상을 반영한다고 볼 수 있다.
짐 판(Jim Fan)은 DeepSeek-R1 기술 보고서를 읽은 후 다음과 같이 지적했다:
이 논문의 가장 중요한 주장은 완전히 강화학습(RL) 기반으로 감독학습(SFT)을 전혀 사용하지 않았다는 점이다. 이것은 인간 기사의 수법을 모방하지 않고 '콜드 스타트(Cold Start)'로 바둑, 장기, 체스를 완전히 스스로 익히는 알파제로(AlphaZero)와 유사하다.
– 강화학습이 쉽게 '해킹'할 수 있는 학습형 보상 모델이 아닌, 하드코딩된 규칙으로 계산된 진짜 보상을 사용한다.
– 모델의 사고 시간은 훈련이 진행됨에 따라 안정적으로 증가하는데, 이는 사전에 프로그래밍된 것이 아니라 자발적인 특성이다.
– 자기성찰 및 탐색 행동이 나타난다.
– PPO 대신 GRPO 사용: GRPO는 PPO의 비평자 네트워크(critic network)를 제거하고 여러 샘플의 평균 보상을 사용한다. 이는 메모리 사용을 줄이는 간단한 방법이다. 참고로 GRPO는 DeepSeek 팀이 2024년 2월에 개발한 것으로, 정말 강력한 팀이다.
같은 날 Kimi가 유사한 연구 성
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News














