

DeepSeek 신모델 대공개, 왜 전 세계 AI 업계를 뒤흔들었을까?
騰訊科技《AI未來指北》特約作者:郝博陽
不到一個月的時間,DeepSeek 再度震撼全球AI界。
去年12月,DeepSeek 推出的 DeepSeek-V3 在全球AI領域掀起巨大波瀾。它以極低的訓練成本實現了與 GPT-4o 和 Claude Sonnet 3.5 等頂級模型媲美的性能,令業界震驚。騰訊科技曾對該模型進行深度拆解,用最直白的方式解析其兼具低成本與高效能的技術背景。
與上一次不同,此次發布的新模型 DeepSeek-R1 不僅成本更低,在技術上也有顯著提升,而且還是開源模型。
這款新模型延續了高性價比的優勢,僅用十分之一的成本就達到了 GPT-o1 級別的表現。
因此,許多業內人士甚至喊出「DeepSeek 接班 OpenAI」的口號,更多人關注其訓練方法上的突破。
例如,前Meta AI員工、知名AI論文推主Elvis強調,DeepSeek-R1 的論文堪稱瑰寶,因其探索了多種提升大語言模型推理能力的方法,並發現更明確的湧現特性。

另一位AI圈大V Yuchen Jin認為,DeepSeek-R1論文中提出的「模型通過純RL方法引導自主學習與反思推理」這一發現意義重大。
英偉達GEAR Lab項目負責人Jim Fan也在推文中提到,DeepSeek-R1使用硬編碼規則計算真實獎勵,避免了RL中常見的易被破解的學習型獎勵模型,從而促使模型產生自我反思與探索行為的湧現。
正因這些極其重要的成果被DeepSeek-R1完全開源,Jim Fan甚至認為,這本該是OpenAI做的事。

那麼問題來了,他們所說的純RL方法訓練模型究竟是什麼?模型出現的「Aha moment」又憑什麼證明AI具備了湧現能力?我們更想知道的是,DeepSeek-R1這項重要創新對AI領域未來發展究竟意味著什麼?
用最簡單的配方,回歸最純粹的強化學習
在o1推出後,推理強化成為業界最受關注的方法。
通常情況下,模型在訓練過程中會採用固定方法來提升推理能力。
而DeepSeek團隊在R1的訓練中,一次性實驗了三種截然不同的技術路徑:直接強化學習訓練(R1-Zero)、多階段漸進式訓練(R1)以及模型蒸餾,且全部成功。其中多階段訓練和模型蒸餾包含眾多具有行業影響力的創新元素。
最令人振奮的,仍是直接強化學習這一途徑。因為DeepSeek-R1是首個證明此方法有效的模型。
先了解傳統訓練AI推理能力的方式:一般是在SFT(監督微調)中加入大量思維鏈(COT)範例,並借助過程獎勵模型(PRM)等複雜神經網絡獎勵機制,讓模型學會以思維鏈方式思考。
有時還會引入蒙特卡洛樹搜索(MCTS),使模型能在多種可能中尋找最佳解法。
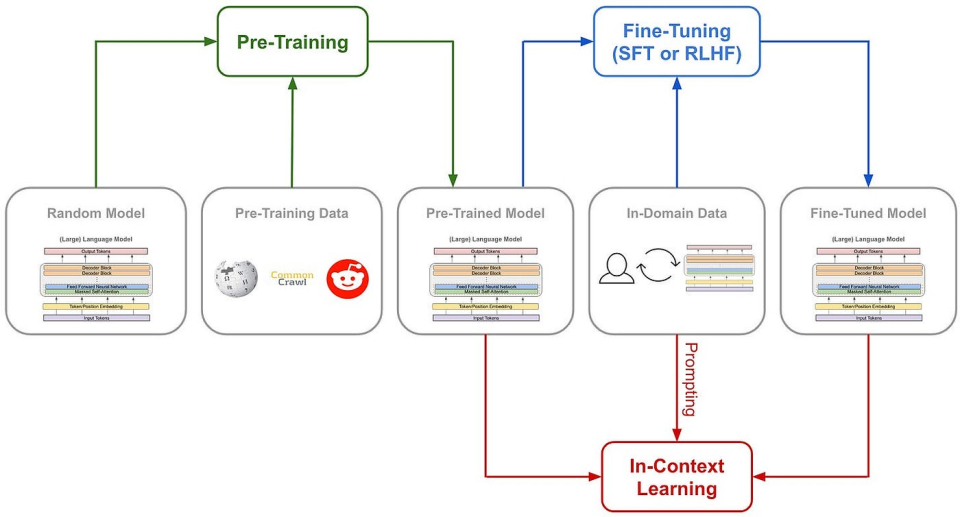
(傳統模型訓練路徑)
但DeepSeek-R1 Zero選擇了一條前所未有的道路——「純」強化學習路徑。它徹底拋棄預設的思維鏈模板(Chain of Thought)與監督式微調(SFT),僅依靠簡單的獎懲信號來優化模型行為。
這就像讓一名天才兒童在無任何範例或指導的情況下,單靠不斷嘗試與反饋來自行學習解題。
DeepSeek-R1 Zero擁有的只是一套最基礎的獎勵系統,用以激發AI的推理能力。
規則僅兩條:
1. 準確性獎勵:由準確性獎勵模型評估回應是否正確。答對加分,錯誤扣分。評估方式也很簡單:例如在結果確定的數學問題中,模型需以指定格式(如<answer>與</answer>之間)提供最終答案;程式問題則可透過編譯器根據預設測試案例生成反饋。
2. 格式獎勵:格式獎勵模型要求模型將思考過程置於<think>與</think>標籤之間。未遵守則扣分,符合則加分。
為了準確觀察模型在強化學習(RL)過程中的自然演進,DeepSeek甚至刻意將系統提示詞限制在這種結構格式上,避免引入任何內容相關偏見——例如強迫模型進行反思性推理或推廣特定解題策略。

(R1 Zero的系統提示詞)
僅靠如此簡單的規則,讓AI在GRPO(Group Relative Policy Optimization)機制下實現自我採樣+比較,從而自我提升。
GRPO模式其實很簡單,通過組內樣本的相對比較計算策略梯度,有效降低訓練不穩定性,同時提高學習效率。
簡單來說,你可以想像成老師出題,每道題讓模型多次作答,再依上述獎懲規則給每個答案打分,最後根據追求高分、避免低分的原則更新模型。
流程大致如下:
輸入問題 → 模型生成多個答案 → 規則系統評分 → GRPO計算相對優勢 → 更新模型。
這種直接訓練方法帶來幾個明顯優勢:首先是訓練效率提升,可在更短時間內完成;其次是資源消耗降低,由於省去SFT與複雜獎懲模型,大幅減少計算需求。
更重要的是,這種方法真的讓模型學會了思考,而且是以「頓悟」的方式學會的。
用自己的語言,在「頓悟」中學習
我們如何得知模型在這種極其「原始」的方法下,確實學會了「思考」?
論文記載了一個引人注目的案例:在處理涉及複雜數學表達式 √a - √(a + x) = x 的問題時,模型突然停下來說:"Wait, wait. Wait. That's an aha moment I can flag here"(等等、等等、這是個值得標記的啊哈時刻),隨後重新審視整個解題過程。這種類似人類頓悟的行為完全是自發產生,而非預先設定。
這種頓悟往往是模型思維能力躍升的關鍵時刻。
根據DeepSeek的研究,模型的進步並非均勻漸進。在強化學習過程中,回應長度會突然顯著增長,這些「跳躍點」往往伴隨著解題策略的質變。這種模式酷似人類長期思考後的突然領悟,暗示某種深層認知突破。
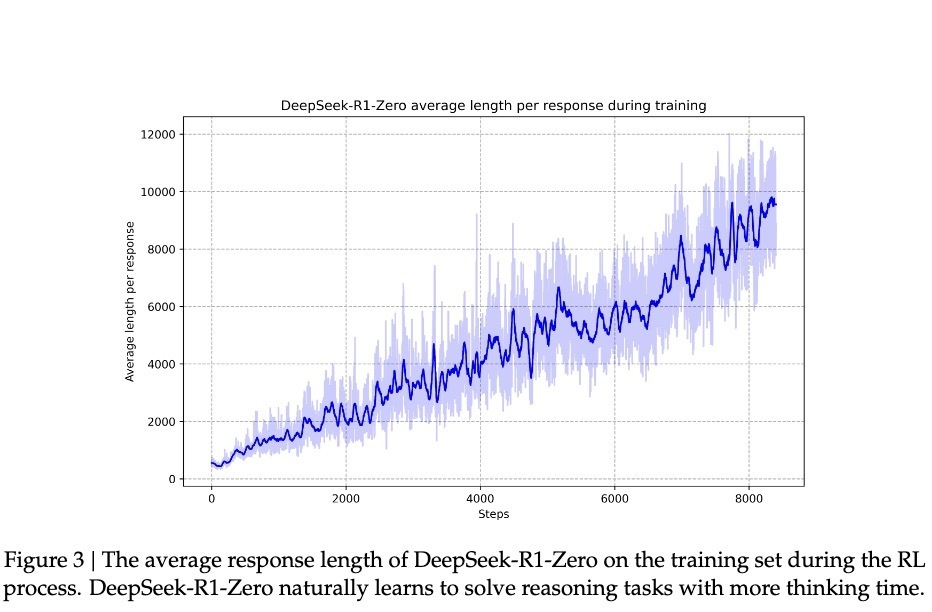
伴隨著這種頓悟式的提升,R1-Zero在數學界享譽盛名的AIME競賽中,正確率從最初的15.6%一路攀升至71.0%。當對同一問題多次嘗試時,準確率甚至達到86.7%。這不是簡單的「看過就會做」——因為AIME題目需要深厚的數學直覺與創造性思維,而非機械套用公式。模型唯有真正具備推理能力,才可能實現如此提升。
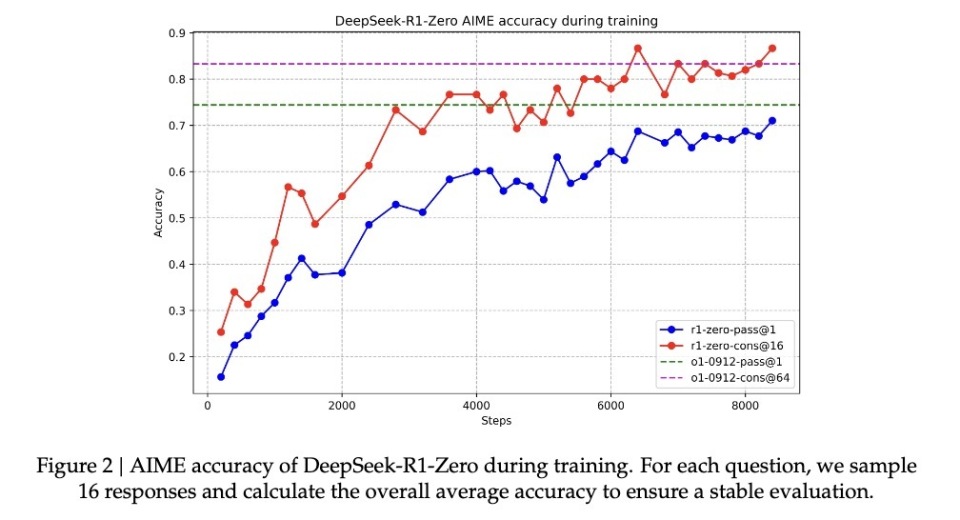
另一個核心證據是,模型的回應長度會根據問題複雜度自然調整。這種自適應行為表明,它不是在機械套用模板,而是真正理解問題難度,並相應投入更多「思考時間」。正如人類面對簡單加法與複雜積分會自然調整思考時間一樣,R1-Zero展現出類似的智慧。
最具說服力的或許是其遷移學習能力。在完全不同的程式競賽平台Codeforces上,R1-Zero表現超越96.3%的人類參賽者。這種跨域表現說明,模型並非死記硬背特定領域技巧,而是掌握了某種普適的推理能力。
這是一個聰明,但口齒不清的天才
儘管R1-Zero展現驚人推理能力,研究人員很快發現一個嚴重問題:它的思維過程往往難以為人類理解。
論文坦承指出,這個純強化學習訓練出的模型存在「poor readability」(可讀性差)與「language mixing」(語言混雜)問題。
此現象其實容易理解:R1-Zero完全依靠獎懲信號優化行為,毫無人類示範的「標準答案」作為參考。就像天才兒童自創一套解題方法,雖屢試不爽,但向他人解釋時卻語無倫次。它可能在解題中混用多種語言,或發展出特殊表達方式,導致推理過程難以追蹤與理解。
正是為解決此問題,研究團隊開發改進版DeepSeek-R1。通過引入更傳統的「cold-start data」(冷啟動數據)與多階段訓練流程,R1不僅保持強大推理能力,也學會以人類易懂方式表達思維過程。這就像為天才兒童配備溝通教練,教會他清晰表達想法。
經過此番調教,DeepSeek-R1展現出與OpenAI o1相當甚至部分更優的性能。在MATH基準測試中,R1達到77.5%準確率,略高於o1的77.3%;在更具挑戰性的AIME 2024中,R1準確率達71.3%,超過o1的71.0%。在程式領域,R1於Codeforces評測中得分2441,超越96.3%人類參與者。
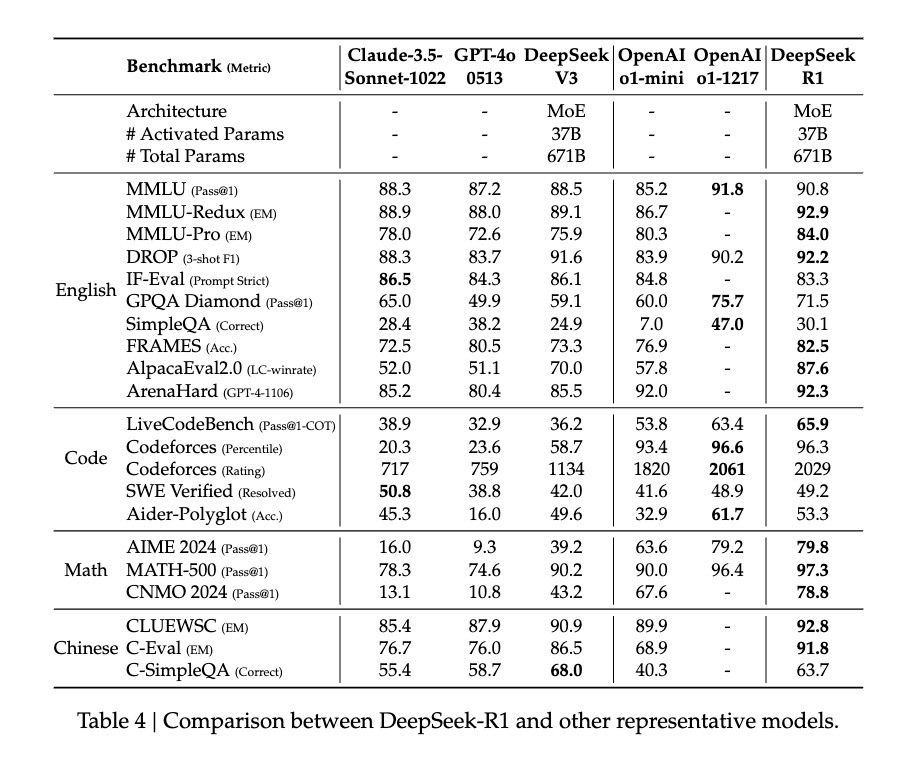
然而,DeepSeek-R1 Zero的潛力似乎更大。它在AIME 2024測試中使用多數投票機制時達到86.7%準確率——此成績甚至超過OpenAI的o1-0912。這種「多次嘗試更準確」的特徵,暗示R1-Zero可能掌握某種基礎推理框架,而非單純記憶解題模式。論文數據顯示,從MATH-500到AIME,再到GSM8K,模型表現出穩定的跨域性能,尤其在需要創造性思維的複雜問題上。這種廣譜性能提示R1-Zero可能確實培養出某種基礎推理能力,與傳統任務專用優化模型形成鮮明對比。
因此,雖然口齒不清,但或許DeepSeek-R1 Zero才是真正理解推理的「天才」。
純粹強化學習,也許才是通往AGI的意外捷徑
之所以DeepSeek-R1的發布讓業界焦點集中於純強化學習方法,因其堪稱打開了AI進化的一條全新路徑。
R1-Zero——這個完全透過強化學習訓練出的AI模型,展現出驚人的通用推理能力。它不僅在數學競賽中取得亮眼成績。
更重要的是,R1-Zero不只是模仿思考,而是真正發展出某種形式的推理能力。
這項發現可能改變我們對機器學習的理解:傳統AI訓練方法或許一直在重複根本性錯誤——我們太執著於讓AI模仿人類思維方式,業界需重新審視監督學習在AI發展中的角色。透過純粹強化學習,AI系統似乎能發展出更原生的問題解決能力,而非受限於預設解決方案框架。
雖然R1-Zero在輸出可讀性上有明顯缺陷,但這個「缺陷」本身可能恰恰印證其思維方式的獨特性。就像天才兒童發明了自己的解題法卻難以用常規語言解釋一樣。這提醒我們:真正的通用人工智慧(AGI)可能需要完全不同於人類的認知方式。
這才是真正的強化學習。正如著名教育家皮亞傑的理論:真正的理解來自主動建構,而非被動接受。
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News














