
저자: @hicaptainz
최근 두 주간 BTC 생태계와 다양한 인스크립션 프로젝트들을 연구하면서, 원리와 기술적 세부사항을 명확히 설명하는 글이 거의 없다는 것을 발견했습니다. 예를 들어 인스크립션이 발행될 때 거래는 어떻게 시작되는지, UTXO 내의 사토시(sats)는 어떻게 추적되는지, 각인된 내용이 스크립트의 어디에 위치하는지, 그리고 BRC20이 전송 시 왜 두 번의 작업이 필요한지 등입니다. 이러한 기술적 세부사항을 이해하지 못하면 BRC20, BRC420, atomicals, stamps, 룬(Runes) 등의 다양한 프로토콜 간 차이점을 파악하기 어렵습니다. 본문에서는 BTC 블록체인의 기초 지식으로 깊이 들어가 위 질문들에 답해보려 합니다.
BTC의 블록 구조
블록체인은 본질적으로 다중 사용자 장부 기술이며, 컴퓨터 과학 용어로 분산 데이터베이스라고 할 수 있습니다. 일정 시간 동안의 기록(장부 항목)이 하나의 블록을 구성하고, 이들은 시간 순서에 따라 장부가 확장됩니다.
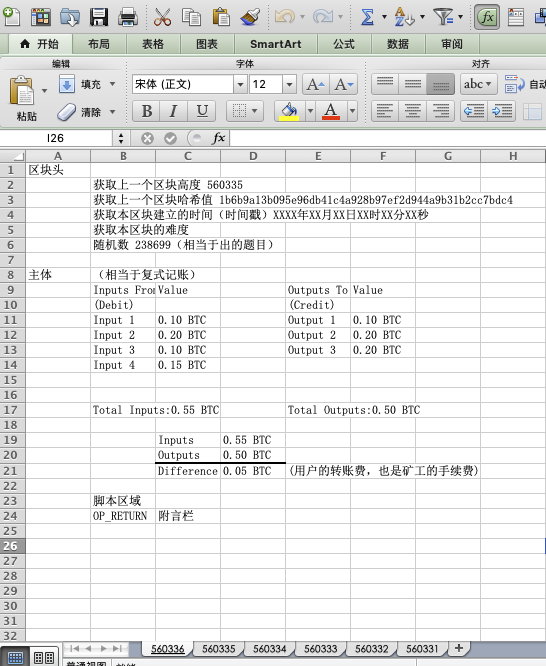
엑셀 표를 이용해 블록체인의 작동 원리를 설명하겠습니다. 하나의 엑셀 파일이 하나의 블록체인을 나타내며, 각각의 개별 시트는 블록을 의미합니다. 블록은 시간 순서에 따라 560331, 560332부터 최신 블록 560336까지 나열됩니다. 블록 560336은 최근의 거래들을 패키징하여 포함합니다. 블록 내부의 주요 부분은 회계에서 흔히 쓰이는 복식 부기법입니다. 한쪽 주소는 차변(debit), 즉 inputs from으로 기록되고, 다른 쪽 주소는 대변(credit), 즉 outputs to로 기록됩니다. Value는 해당 주소의 BTC 수량을 나타냅니다. Inputs의 코인 수량은 Outputs보다 많으며, 그 차액은 사용자가 지불하는 수수료이며, 채굴자(장부 작성자)가 받는 수수료입니다. 블록 헤더는 이전 블록의 높이와 해시값, 현재 블록 생성 시간(타임스탬프), 난수(nonce)를 포함합니다. 탈중앙화된 장부 기술에서 다음 블록의 장부 작성 권한은 누구에게 돌아갈까요? 바로 이 난수와 그에 대응하는 해시값을 통해 결정됩니다. 컴퓨팅 파워를 가진 채굴자들이 현재 블록의 난수에 대해 해시 연산을 수행하며, 조건에 맞는 해시값을 가장 먼저 찾은 채굴자가 다음 블록의 장부 작성 권한을 얻고, 블록 보상과 거래 수수료를 획득합니다. 마지막으로 스크립트 영역은 op_return과 같은 부가적인 응용을 위한 공간입니다. 참고로 실제 블록에서는 스크립트 영역이 input과 output 정보에 첨부되어 있으며, 별도의 독립된 영역이 아닙니다. input에 첨부된 스크립트는 잠금 해제 스크립트(ScriptSig)이며, 지갑 주소의 개인키 서명을 통해 출금을 승인받아야 합니다. 반면 output에 첨부된 스크립트는 잠금 설정 스크립트(ScriptPubKey)이며, 해당 BTC를 수령할 때 만족해야 하는 조건(일반적으로 "해당 개인키를 소유한 자만 소비 가능")을 설정합니다.
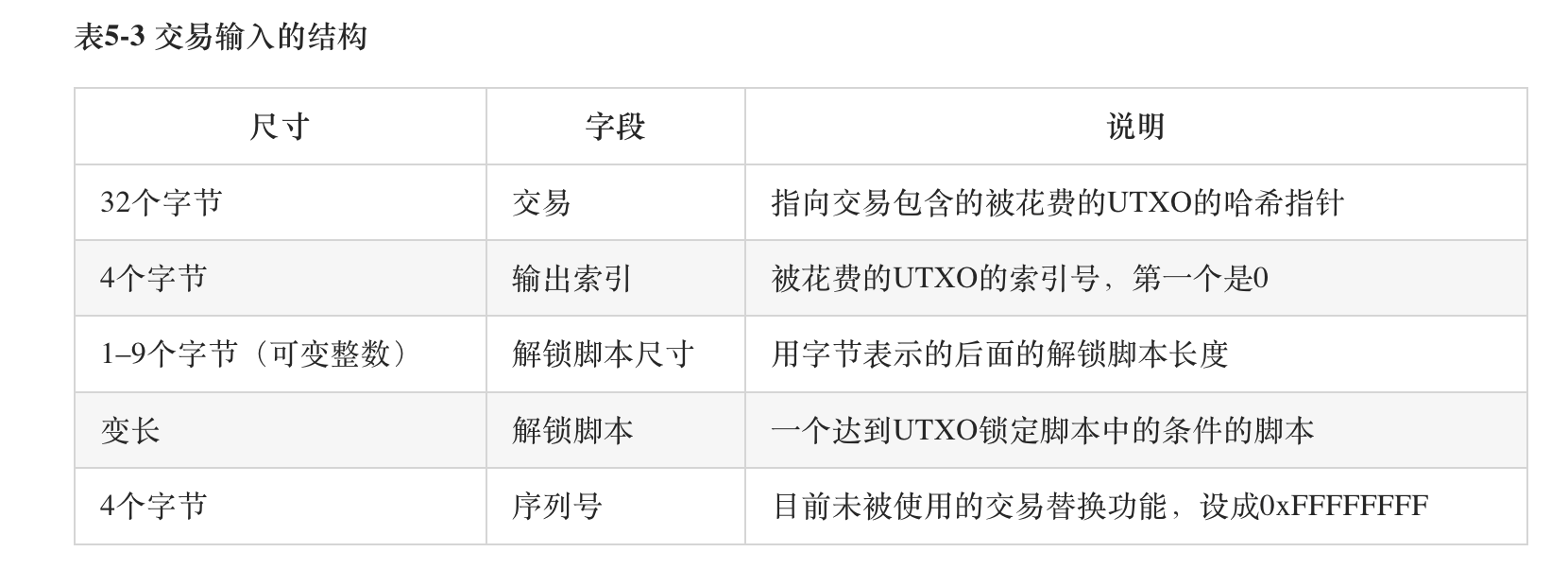

위의 두 이미지는 원본 input과 output의 데이터 구조표입니다. 실행 단계에서 스크립트는 거래 정보의 첨부 매개변수로 표현되며, 비공개키 승인이 필요한 잠금 해제 스크립트(ScriptSig)는 "증거 데이터(witness data)"라고도 불립니다.
격리 증거(SegWit)와 트레이프루트(Taproot)
비트코인 네트워크는 10년 이상 운영되면서 중대한 사건 없이 안정적으로 작동했지만, 거래 비용이 지나치게 상승하여 실현 가능성이 사라진 적이 여러 차례 있었습니다. 따라서 비트코인 개발자들은 미래에 증가할 거래량을 처리하기 위해 네트워크를 확장하는 최선의 방법에 대해 오랫동안 논의해 왔습니다.
2017년, 이 논쟁은 정점에 달했고 비트코인 개발 커뮤니티는 두 진영으로 나뉘었습니다. 하나는 소프트포크 방식으로 'SegWit' 기능을 도입하자는 입장이고, 다른 하나는 직접 블록 크기를 늘리는 '대규모 블록' 진영이었습니다.
앞서 언급했듯이 잠금 해제 스크립트에는 비밀키 승인이 필요해 '증거 데이터'가 생성됩니다. 그렇다면 이 증거 데이터를 블록에서 분리함으로써 각 블록이 더 많은 거래를 수용하도록 간접적으로 증가시킬 수 있지 않을까요? 격리 증거(Segregated Witness, SegWit)는 2017년 8월 공식적으로 활성화되었습니다. 그 구현 방식은 모든 거래 데이터를 두 부분으로 나누는 것입니다. 하나는 거래 기본 정보(Transaction Data), 다른 하나는 거래 서명 정보(Witness Data)이며, 후자를 새로운 데이터 구조인 '격리 증거(witness)' 블록에 저장하고 원래의 거래와 분리하여 전송합니다.
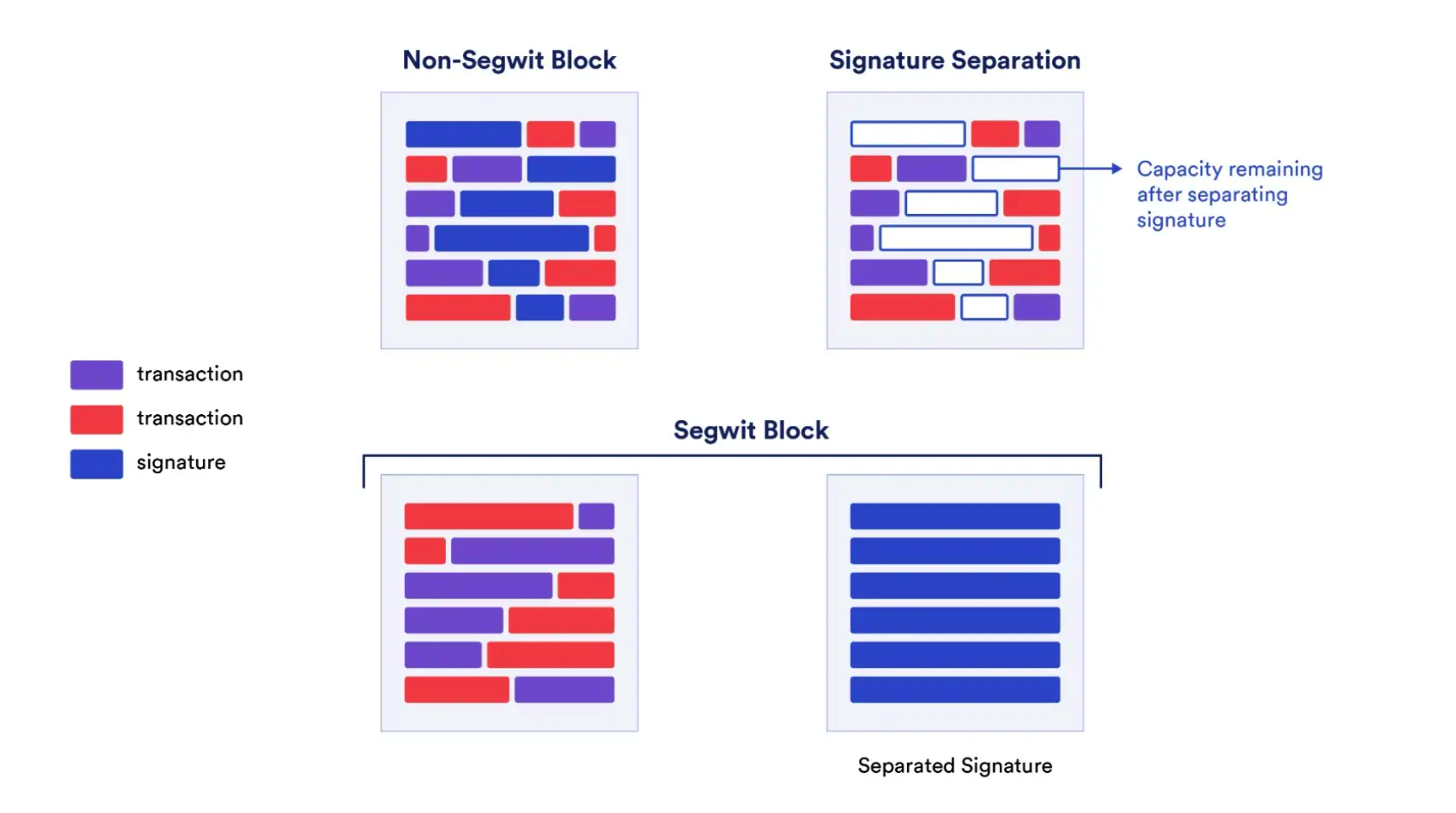
기술적으로 SegWit 적용은 이제 거래에 증거 데이터를 포함시킬 필요가 없음을 의미합니다(즉, 비트코인이 원래 블록에 할당한 1MB 공간을 차지하지 않음). 대신 블록 말미에 증거 데이터를 위한 별도의 추가 공간을 만듭니다. 이 공간은 임의의 데이터 전송을 지원하며, 할인된 '블록 무게(block weight)'를 가지며, 하드포크 없이도 비트코인의 블록 크기 제한 내에서 대량의 데이터를 유지할 수 있도록 합니다. 이렇게 함으로써 비트코인 거래의 데이터 크기 상한이 높아졌고, 서명 데이터에 대한 거래 수수료도 낮아졌습니다. SegWit 업그레이드 이전에 비트코인의 용량 상한은 1MB였으나, 이후 순수 거래 용량은 여전히 1MB지만 격리 증거 공간은 4MB까지 확장되었습니다.
Taproot는 2021년 11월 시행되었으며, Taproot, Tapscript 및 'Schnorr 서명'이라는 새로운 디지털 서명 방식을 포함한 3개의 비트코인 개선 제안(BIP)으로 구성됩니다. Taproot은 거래의 익명성 향상과 수수료 절감 등 비트코인 사용자에게 다양한 혜택을 제공하며, 더 복잡한 거래를 실행할 수 있게 해 애플리케이션 범위를 확장합니다(새로운 오퍼코드 opcodes 추가).
이러한 업데이트는 Ordinals NFT의 핵심 추진 요인이 되었으며, NFT 데이터를 Taproot 스크립트 경로의 사용된 스크립트(spent script)에 저장합니다(증거 데이터 공간). 이번 업그레이드로 구조화되고 임의의 증거 데이터를 저장하기 쉬워졌으며, "ord" 표준의 기반을 마련했습니다. 데이터 요구 사항이 완화됨에 따라, 거래가 거래 데이터와 증거 데이터로 전체 블록을 채울 수 있다면 -- 최대 4MB의 블록 크기(증거 데이터 공간) 제한까지 -- 체인에 올릴 수 있는 미디어 유형이 크게 확장됩니다.
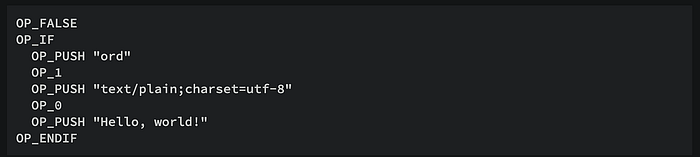
여기서 의문이 생길 수 있습니다. 스크립트에 문자열을 넣는다고 했는데, 이 문자열에 제한 조건이 없는 걸까? 만약 실제로 이 스크립트를 실행한다면? 아무런 내용이나 넣으면 오류 코드가 발생해 블록 생성이 거부되지 않을까? 여기서 OP_FALSE 명령어가 등장합니다. 비트코인 스크립트에서 OP_FALSE는 (또는 "0"으로 표시) 스크립트 언어 내 실행 경로가 절대 OP_IF 분기로 들어가지 않고 미실행 상태로 유지되도록 보장합니다. 고급 언어의 '주석(comment)'처럼 작동하는 스크립트 내 플레이스홀더 또는 노오퍼레이션(No Operation) 역할을 하여 후속 코드가 실행되지 않도록 합니다.
UTXO 전송 모델
지금까지는 컴퓨터 데이터 구조 관점에서 BTC의 기본 원리를 살펴보았고, 이제 금융 모델 측면에서 UTXO 모델을 논의해 보겠습니다.
UTXO는 Unspent Transaction Outputs의 약자로, 한국어로는 "사용되지 않은 거래 출력"이며, 실제로는 한 번의 송금 시 남은 잔액을 의미합니다. 그런데 비트코인은 왜 이런 개념을 사용할까요? 이것은 장부 기록 방식의 두 가지 모델, 즉 거래 모델과 계좌 잔고 모델에서 비롯됩니다.
우리는 오랫동안 중앙화된 체계에 익숙해져 있어 계좌 잔고 모델의 장부 방식에 매우 익숙합니다. 사용자 A가 사용자 B에게 100원을 송금할 때, 은행은 먼저 A의 계좌에 100원이 있는지 확인한 후, A의 계좌에서 100원을 차감하고 B의 계좌에 100원을 더하는 식으로 거래를 완료합니다.
그러나 비트코인의 장부 알고리즘에는 잔고라는 개념이 없습니다. 블록체인의 분산 원장에는 각 거래만 기록되며, 특정 계좌의 현재 잔고를 직접 기록하지 않습니다(잔고 기록은 일반적으로 전용 서버 노드가 필요하며, 이는 중앙화를 의미합니다). 예를 들어 사용자 A의 잔고가 1000원이라고 가정하고, 사용자 A가 사용자 B에게 100원을 송금한다고 하면, 이 거래는 다음과 같이 기록됩니다:
거래1: 사용자 A → 사용자 B, 100원 송금
거래2: 사용자 A → 사용자 A 자신, 900원 송금 (UTXO)

여기서 거래2는 한 건의 거래이지만 기능상 계좌 잔고 역할을 하며, 이 100원 송금 후 A의 계좌에 900원이 남아 있음을 나타냅니다.
그렇다면 왜 굳이 이런 UTXO를 만들어야 할까요? 왜냐하면 BTC 블록체인에는 거래만 기록되고 계좌 잔고는 기록되지 않기 때문입니다. 이 UTXO가 없다면 잔고를 계산하기 위해 계좌의 모든 입출금 내역을 전부 합산해야 하며, 이는 시간과 계산 리소스를 매우 많이 소모하는 작업입니다. UTXO는 잔고 계산 시 모든 거래를 추적해야 하는 문제를 교묘하게 피할 수 있게 해줍니다.
UTXO는 특징적으로 동전처럼 쪼갤 수 없으며, 그렇다면 거래 과정에서 입력 금액을 어떻게 맞추고 거스름돈은 어떻게 주는 것일까요? 이를 동전에 비유해 설명할 수 있습니다(실제로 UTXO라는 단어를 볼 때마다 자동으로 '동전'이라고 생각하는 것이 좋습니다).
소명이 소강에게 1비트코인을 송금합니다. 전체 과정은 다음과 같습니다. 소명은 충분한 input을 수집해야 합니다. 예를 들어 소명의 주소와 관련된 이전 거래에서 0.9 가치의 UTXO를 찾았지만, 1비트코인에는 부족합니다. 다행히 거래는 여러 입력을 허용하므로, 소명은 또 다른 0.2 가치의 UTXO를 찾습니다. 결과적으로 이번 송금 거래에는 두 개의 입력이 존재합니다. 동시에 출력도 두 개가 있는데, 하나는 소강의 주소로, 가치는 1비트코인입니다. 다른 하나는 소명 자신의 주소로, 가치는 0.1비트코인인데, 이것이 바로 거스름돈입니다(이 예시는 gas를 무시합니다).
다시 말해, 소명의 주머니에는 0.9와 0.2 가치의 두 개의 동전이 있고, 지금 1 가치의 동전을 지불해야 하므로 두 동전을 모두 소강에게 건네야 하며, 소강은 받은 후 0.1을 거스름돈으로 돌려줍니다. 따라서 이 장부 모델의 본질은 '거스름돈' 동작을 통해 '잔고 계산'을 피하는 것입니다.
Ordinal 프로토콜의 정렬 시스템
Ordinal 프로토콜은 현재 BTC 생태계 폭발의 근본적인 출발점이라 할 수 있으며, 동질적인 BTC를 최소 단위인 sat으로 분해한 후 각 sat에 일련번호를 부여합니다. 어떻게 이루어질까요?
우리가 아는 바와 같이 BTC의 총량은 2100만 개이며, 1 BTC는 1억 개(sat)까지 분할 가능하므로 BTC의 최소 단위는 sat입니다. BTC也好, 최소 단위 sat也好, 모두 전형적인 동질 토큰(FT)입니다. 이제 이 sats에 일련번호(ordinals)를 부여해 보겠습니다.
블록 데이터 구조를 설명할 때 거래 정보에는 input 주소와 금액, output 주소와 금액을 명시해야 한다고 언급했습니다. 각 블록은 두 가지 종류의 거래를 포함합니다: BTC 블록 보상과 송금 수수료. 수수료 거래는 반드시 input과 output을 가지지만, 블록 보상은 새로 생성된 BTC이므로 input 주소가 없으며, 이 'input from' 필드는 비어 있으며, 이를 'coinbase 거래'라고 부릅니다. BTC의 총량 2100만 개는 모두 이 coinbase 거래에서 비롯되며, 모든 블록의 거래 목록에서 가장 먼저 위치합니다.
Ordinal 프로토콜은 다음과 같이 규정합니다:
-
번호 부여: 각 sat은 채굴된 순서대로 번호가 매겨진다.
-
이전: 선입선출(FIFO) 규칙에 따라 입력에서 출력으로 이전된다.
첫 번째 규칙은 비교적 간단합니다. 이는 번호 부여가 오직 채굴 보상의 coinbase 거래에서만 생성될 수 있음을 의미합니다. 예를 들어 첫 번째 블록의 채굴 보상이 50 BTC라면, 첫 번째 블록은 [0;1;2;...;4,999,999,999] 범위의 sats를 배정합니다. 두 번째 블록의 보상도 50 BTC라면, 두 번째 블록은 [5,000,000,000;5,000,000,001;...;9,999,999,999] 범위의 sats를 배정합니다.

여기서 이해하기 어려운 부분은 UTXO가 실제로 많은 sat을 포함하고 있기 때문에, 이 UTXO 내 각 sat은 모두 동일해 보이는데 어떻게 정렬할 수 있을까 하는 점입니다. 사실 이는 두 번째 규칙이 결정하는 것입니다. 간단한 예를 들어보겠습니다:
BTC의 최소 분할 단위를 1이라고 가정하고, 총 10개의 블록이 생성되었으며, 각 블록의 보상은 10 BTC이므로 총량은 100 BTC입니다. 우리는 이 100개 BTC에 (0-99)의 일련번호를 부여할 수 있습니다. 만약 어떤 송금도 없다면, 첫 번째 블록의 10 BTC 번호는 (0-9), 두 번째 블록의 10 BTC 번호는 (10-19), ..., 열 번째 블록의 10 BTC 번호는 (90-99)임을 알 수 있습니다. 여기에는 소비가 전혀 없으므로 output도 없으며, 우리는 각 10개 BTC에만 번호 범위를 부여할 수 있습니다.
두 번째 블록에 두 개의 지출(output)을 추가한다고 가정합니다. 하나는 3 BTC, 다른 하나는 7 BTC의 '거스름돈'으로, 누군가에게 3 BTC를 송금하고 자신에게 7 BTC를 돌려받는 것입니다. 이때 블록의 거래 목록에서, 자신에게 돌려받는 7 BTC가 우선순위 1위(번호 10-16), 다른 사람에게 보내는 3 BTC가 2위(번호 17-19)라고 가정합니다. 이렇게 output의 이전을 통해 특정 UTXO가 포함하는 sats의 순서 집합이 확인됩니다.
주의할 점은 UTXO가 아니라 각 sat이라는 점입니다! UTXO는 더 이상 분할할 수 없는 최소 거래 단위이므로 sat는 반드시 UTXO 내에 존재하며, UTXO는 일정 범위의 sats를 포함하고, 특정 UTXO를 소비한 후 새로운 출력에서 sats 번호를 분할할 수 있습니다.
이 '번호'를 표현하는 방법은 다양하며, 앞서 언급한 '정수법' 외에도 10진수 소수법, 도수법, 백분율법, 순수 알파벳 명명법 등이 있습니다.
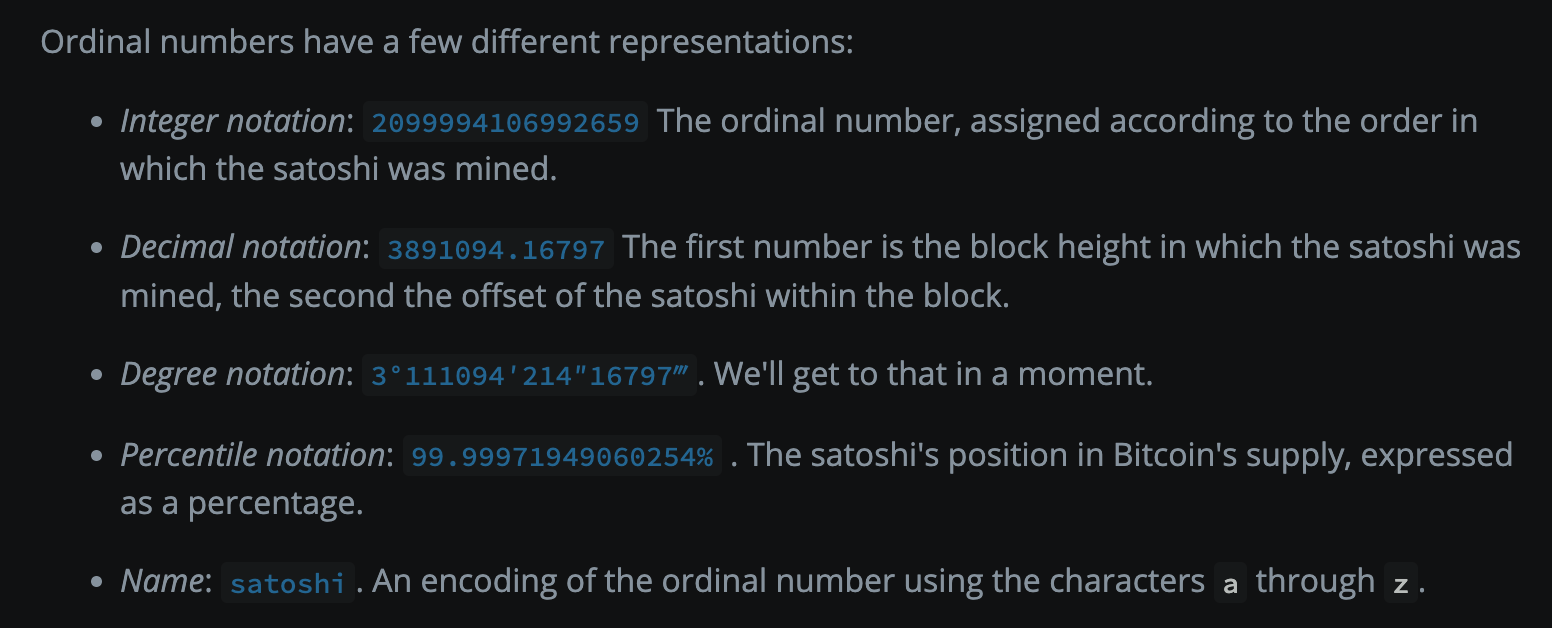
sats에 통일된 일련번호가 부여되면, 이제 각인(inscription)을 고려할 수 있습니다. 앞서 언급했듯이, 4MB 크기의 증거 데이터 영역에 텍스트, 이미지, 비디오 등 임의의 데이터 형식 파일을 업로드할 수 있으며, 업로드 후 파일은 자동으로 16진수로 변환되어 taproot 스크립트 영역에 저장됩니다. 즉, 1개의 UTXO가 1개의 Taproot 스크립트 영역에 대응하며, 이 1개의 UTXO는 동시에 많은 sats를 포함합니다(전체적으로 일련의 sats 집합이며, 분말 공격(dust attack)을 방지하기 위해 단일 UTXO 내 비트코인 수량은 546 sat 미만일 수 없습니다). Ordinal 프로토콜은 기록을 쉽게 하기 위해 인위적으로 "이 집합의 첫 번째 sat 번호를 바인딩 관계로 사용한다"고 규정합니다(백서 원문: 첫 번째 output의 첫 번째 sat 번호). 예를 들어 (17-19) 번호의 sats를 포함하는 UTXO는 이 집합과 각인된 내용을 바인딩할 때 단순히 17번으로 대체합니다.
Ordinal 자산의 발행과 이전
Ordinal NFT는 다양한 파일을 격리 증거 영역의 스크립트에 업로드하고 이를 sats 순서 집합과 연결함으로써 BTC 체인 상에서 NFT 자산을 발행하는 것입니다. 그러나 여기서 또 다른 문제가 있습니다. 격리 증거 영역의 스크립트는 input의 잠금 해제 스크립트와 output의 잠금 설정 스크립트를 모두 포함하는데, 내용은 어느 스크립트에 위치할까요? 정답은 둘 다 포함됩니다. 여기서 블록체인 기술의 commit-reveal 메커니즘을 언급하지 않을 수 없습니다.
블록체인의 Commit-Reveal 메커니즘은 정보의 공정성과 투명성을 보장하기 위한 프로토콜입니다. 이 메커니즘은 숨겨진 정보(예: 투표 선택이나 입찰가)를 제출한 후, 나중에 특정 시점에 그 정보를 공개해야 하는 상황에서 일반적으로 사용됩니다. Commit-Reveal 메커니즘은 두 단계로 나뉩니다: 제출(commit) 단계와 공개(reveal) 단계.
1. 제출(Commit) 단계: 이 단계에서 사용자는 정보(예: 투표 선택 또는 입찰가)를 제출하지만, 이 정보는 암호화됩니다. 일반적으로 사용자는 이 정보의 해시값(정보의 암호화 요약)을 생성한 후 블록체인에 전송합니다. 해시 함수의 특성상 원본 정보로부터 고유한 출력(해시값)을 생성하지만, 이는 원본 정보로 역추적이 불가능합니다. 즉, 해시값으로부터 원본 정보를 추론할 수 없습니다. 이 과정은 정보 제출 시 비밀성을 보장합니다.
2. 공개(Reveal) 단계: 정해진 이후 시점에 사용자는 원본 정보를 공개하고, 이 정보가 이전에 제출한 해시값과 일치함을 입증해야 합니다. 일반적으로 원본 정보와 해시값 생성에 사용된 추가 데이터(예: 난수 또는 '솔트')를 제출함으로써 이루어집니다. 네트워크는 이 원본 정보의 해시값이 이전에 제출한 해시값과 동일한지 검증합니다. 일치하면 원본 정보가 유효하다고 간주됩니다.
앞서 언급했듯이, 각인된 내용은 UTXO에 포함된 sats 순서 집합과 결합되어야 하며, UTXO는 블록에서 output이므로 output의 잠금 설정 스크립트에 첨부되어야 합니다. 하지만 BTC의 풀노드는 로컬에서 전체 네트워크의 모든 UTXO 집합을 유지하고 전송해야 합니다. 만약 1만 개의 4MB 영상 파일을 1만 개의 UTXO 잠금 설정 스크립트에 직접 업로드한다면, 모든 풀노드는 매우 높은 저장 공간과 초고속 인터넷을 필요로 하게 되며, 이는 사실상 체인의 붕괴를 의미합니다. 따라서 유일한 해결책은 내용을 input의 잠금 해제 스크립트에 넣은 후, 이 내용이 다른 output을 '가리키도록' 하는 것입니다.
따라서 Ordinal 자산의 발행은 두 단계로 나뉩니다(지갑은 이 두 단계를 통합 처리합니다. 거래 생성 시 commit-reveal 부자 거래를 동시에 구성하여 사용자 경험상 하나의 단계처럼 느껴지고 gas 비용도 절감됩니다).
발행 단계에서 사용자는 먼저 파일의 해시값을 commit 거래(자신의 A 주소에서 B 주소로 송금)의 UTXO 잠금 설정 스크립트에 업로드해야 합니다. 해시값이므로 풀노드의 UTXO 데이터베이스 공간을 많이 차지하지 않습니다. 다음으로 사용자는 새로운 거래(자신의 B 주소에서 A 주소로 송금)를 생성하며, 이를 reveal 거래라고 부릅니다. 이때 input은 이전 단계의 commit 거래에서 파일 해시값을 포함한 UTXO를 사용해야 하며, 해당 input의 잠금 해제 스크립트는 원본 각인 파일을 포함해야 합니다. 백서의 원문으로 설명하면 "먼저 commit에서, 각인 내용을 포함하는 스크립트로 taproot 출력을 제출합니다. 다음으로 reveal 거래에서, commit 거래에서 생성된 출력을 사용하여 체인 상에 각인 내용을 표시합니다."
이전 단계에서 Ordinal NFT와 BRC20은 약간 다릅니다. Ordinal NFT는 전체 이전이므로 특정 UTXO에 바인딩된 NFT를 수취인에게 직접 전송하면 됩니다. 마치 일반 BTC 송금과 유사합니다. 그러나 BRC20은 사용자 정의 수량 송금을 포함하므로 역시 두 단계로 나뉩니다. 첫 번째는 각인 '거래'(Inscribe "TRANSFER"), 두 번째는 송금 '거래'(Transfer "TRANSFER")입니다. 첫 번째 각인 거래는 실제로 Ordinal NFT 발행 과정과 유사하며, commit-reveal 부자 거래 쌍을 암시합니다. 두 번째 송금 거래는 일반 Ordinal NFT 이전과 유사하며, 특정 UTXO에 바인딩된 BRC20 자산을 수취인에게 직접 전송합니다. 일부 지갑은 이 세 거래(조부-부-자三代 거래)를 동시에 구성하여 시간과 gas를 절약합니다.

요약하자면, commit 거래는 각인 내용(원본 내용의 해시값)과 일련번호가 매겨진 sats(UTXO)를 연결하고, reveal 거래는 내용을 표시합니다(원본 내용). 이 부자 거래 쌍이 함께 NFT의 발행을 완료합니다.
P2TR과 한 가지 예
지금까지의 발행 기술 논의는 아직 끝나지 않았습니다. 왜냐하면 누군가는 reveal 거래가 어떻게 commit 거래의 각인 정보를 검증하는지 궁금해할 수 있으며, 왜 거래 생성 시 자신의 AB 두 주소가 서로 송금해야 하는지, 각인 시 두 지갑을 준비할 필요가 없었던 것도 의문일 수 있기 때문입니다. 여기서 Taproot의 주요 업그레이드 중 하나인 P2TR을 설명해야 합니다.
P2TR(Pay-to-Taproot)은 Taproot 업그레이드로 도입된 새로운 유형의 비트코인 거래입니다. P2TR 거래는 사용자가 단일 공개키 또는 다중서명 지갑, 스마트 계약과 같은 더 복잡한 스크립트를 사용하여 비트코인을 사용할 수 있도록 하여, 더 높은 익명성과 유연성을 제공합니다. 이는 Merkleized Abstract Syntax Trees(MAST)와 Schnorr 서명을 통해 구현되며, 이러한 기술은 단일 거래 내에서 다양한 사용 조건을 효율적으로 인코딩할 수 있게 합니다.
-
사용 조건 생성
P2TR 거래를 생성하려면, 사용자는 먼저 비트코인 사용 조건(예: 다중서명 지갑 또는 스마트 계약)을 지정하는 단일 공개키 또는 더 복잡한 스크립트를 정의합니다.
-
Taproot 출력 생성
그 다음 사용자는 Taproot 출력을 생성하며, 여기에는 단일 공개키(공개키는 사용 조건을 나타냄)가 포함됩니다. 이 공개키는 사용자의 공개키와 스크립트 해시의 조합에서 파생되며, 'tweaking' 과정을 통해 이루어집니다. 이를 통해 출력은 표준 공개키처럼 보이며, 블록체인 상에서 다른 거래와 구별하기 어렵게 됩니다.
-
비트코인 사용
사용자가 비트코인을 사용하고자 할 때, 사용 조건이 충족되면 단일 공개키를 사용하거나, 원본 스크립트를 공개하고 사용 조건을 만족시키기 위한 필요한 서명 또는 데이터를 제공할 수 있습니다. 이는 Tapscript를 통해 이루어지며, 사용 조건을 더 효율적이고 유연하게 실행할 수 있게 합니다.
-
거래 검증
채굴자와 노드는 이후 제공된 Schnorr 서명과 데이터를 사용 조건과 비교하여 거래를 검증합니다. 조건이 충족되면 거래는 유효하다고 간주되며, 비트코인을 사용할 수 있습니다.
-
향상된 익명성과 유연성
P2TR 거래는 비트코인을 사용할 때 필요한 사용 조건만 공개하므로 높은 수준의 익명성을 유지합니다. 또한 MAST와 Schnorr 서명을 사용하면 여러 사용 조건을 효율적으로 인코딩할 수 있어, 거래의 전체 크기를 늘리지 않으면서도 더 복잡하고 유연한 거래를 가능하게 합니다.
이것이 바로 commit-reveal 메커니즘이 P2TR에 적용되는 방식이며, 실제 사례를 통해 설명하겠습니다.
블록체인 탐색기https://www.blockchain.com/를 사용하여 Ordinal 이미지 NFT의 발행 과정(commit-reveal 두 단계 포함)을 분석해 보겠습니다.
먼저 commit 거래의 Hash ID는 (2ddf90ddf7c929c8038888fc2b7591fb999c3ba3c3c7b49d54d01f8db4af585c)입니다. 이 거래의 출력에는 각인 데이터(실제로는 16진수 이미지 파일의 해시값)가 포함되어 있지 않으며, 웹페이지에서도 관련 각인 정보가 없습니다. 이 출력의 (bc1p4mtc.....) 주소는 사실 'tweaking' 과정을 통해 생성된 임시 주소(스크립트 잠금 해제 조건의 공개키를 나타냄)이며, taproot 메인 주소(bc1pg2mp...)와 동일한 개인키를 공유합니다. 이 거래의 두 번째 UTXO는 반환된 '거스름돈' 작업에 해당합니다. 이를 통해 각인 내용과 첫 번째 UTXO에 포함된 sats가 연결됩니다.
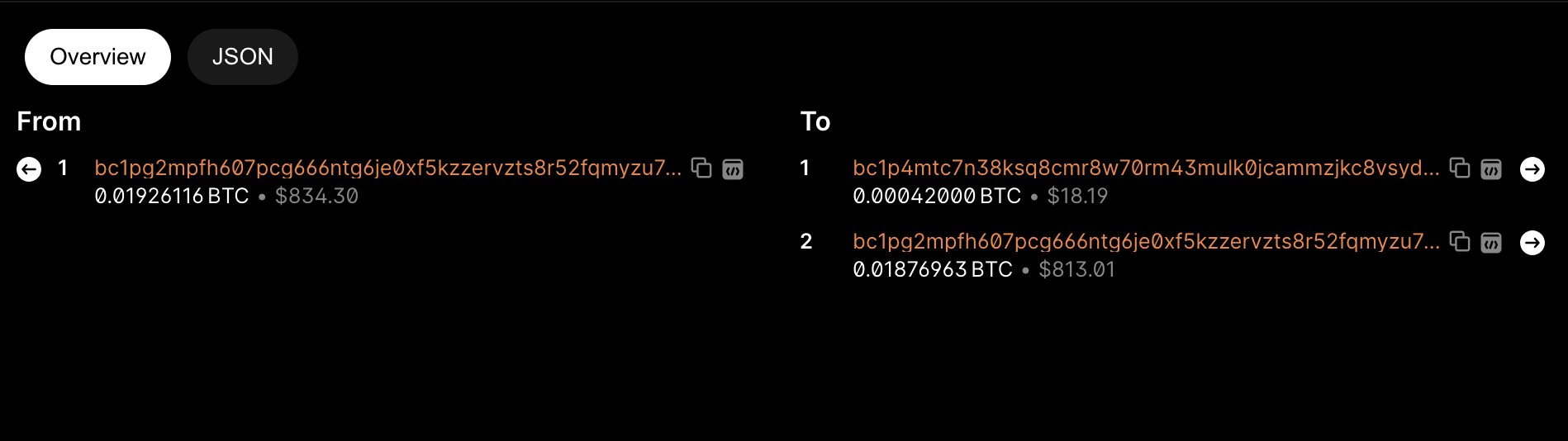
다음으로 reveal 거래 기록을 확인합니다. Hash ID는 (e7454db518ca3910d2f17f41c7b215d6cba00f29bd186ae77d4fcd7f0ba7c0e1)입니다. 여기서 Ordinals inscription 정보를 확인할 수 있습니다. 이 거래의 input 주소는 바로 이전 거래에서 생성된 임시 출력 주소(bc1p4mtc.....)이며, input의 잠금 해제 스크립트에는 원본 이미지의 16진수 파일이 포함되어 있습니다. 출력의 0.00000546 BTC(546 sat)는 이 NFT를 자신의 taproot 메인 주소(bc1pg2mp...)로 전송한 것입니다. 선입선출(FIFO) 원칙과 '바인딩되는 것은 첫 번째 output의 첫 번째 sat 번호'라는 규정에 따라, 전후 두 UTXO에 포함된 sats 수량은 변화했지만 바인딩된 sat 일련번호는 동일합니다. 따라서 우리는 (sat 1893640468329373)에서 이 각인된 sat을 찾을 수 있습니다.
(https://ordinals.com/sat/1893640468329373)
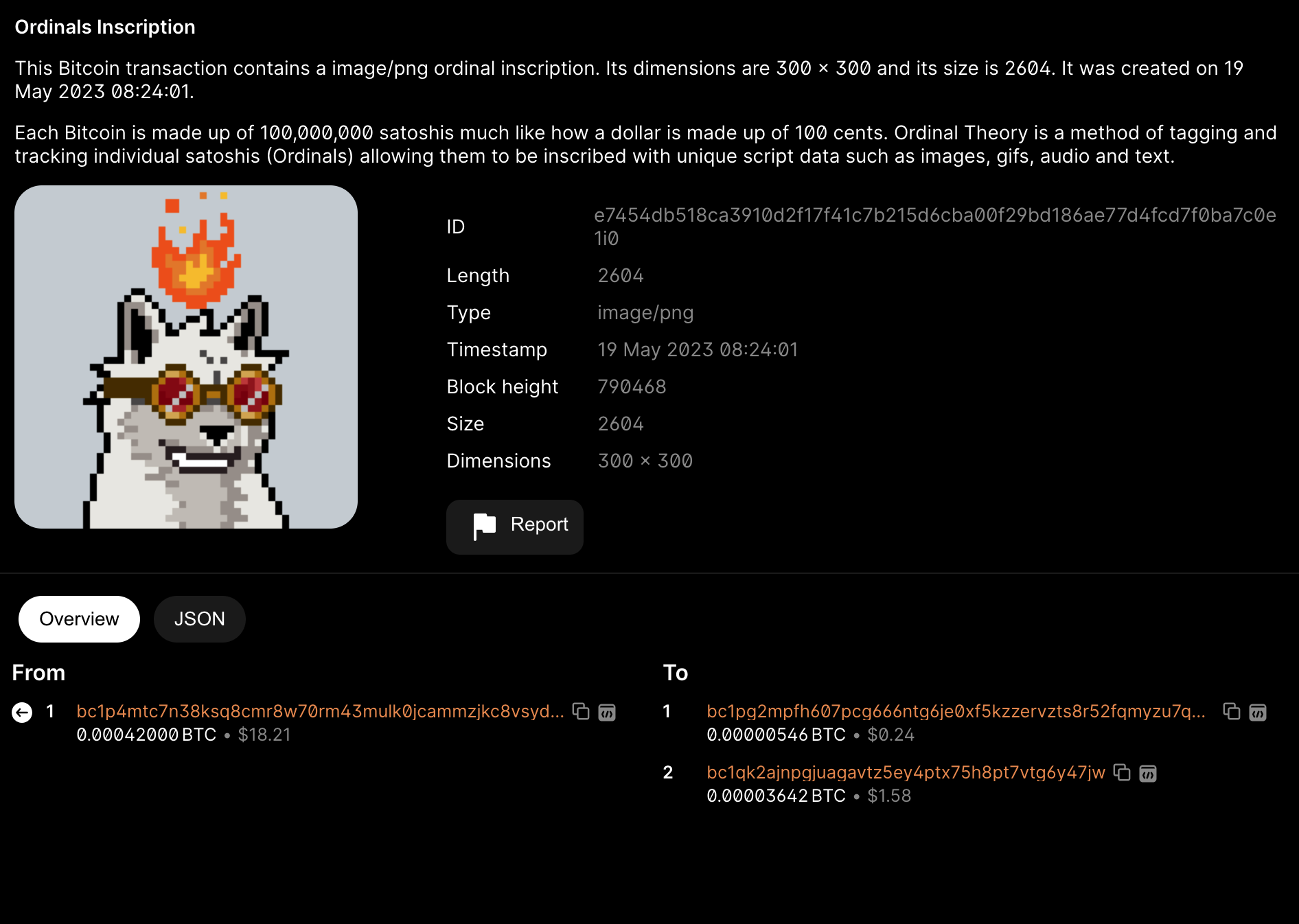
이 두 거래(부자 거래)는 지갑에 의해 메모리 풀에 동시에 제출되므로 단 한 번의 gas만 지불하면 되며, 대부분 같은 블록에 포함되어 채굴자에 의해 기록되고 브로드캐스트될 가능성이 큽니다(위 예시의 두 거래는 실제로 모두 블록 790468에 존재합니다). 채굴자와 노드는 이후 reveal 거래의 input에서 제공된 Schnorr 서명과 16진수 이미지 해시값을 commit 거래의 output 잠금 설정 스크립트에 있는 16진수 이미지 해시값과 비교하여 검증합니다. 두 해시값이 동일하면 거래는 유효하다고 간주되며, 이 비트코인의 UTXO를 사용할 수 있고, 두 거래는 자연스럽게 BTC 블록체인 데이터베이스에 영구적으로 기록되며, NFT 이미지도 저장되어 표시됩니다. 두 해시값이 다르면 두 거래는 취소되며 각인이 실패합니다.
BRC20 프로토콜과 인덱서
Ordinal 프로토콜에서 텍스트를 각인하면 텍스트 NFT가 되며(이더리움의 Loot에 대응), 이미지를 각인하면 이미지 NFT가 되며(이더리움의 PFP에 대응), 음악을 각인하면 오디오 NFT가 됩니다. 그렇다면 우리가 코드를 각인하고, 그 코드가 'FT 동질 토큰 발행' 코드라면 어떨까요?
BRC20은 Ordinal 프로토콜을 활용하여 inscriptions(각인)을 JSON 데이터 형식으로 설정함으로써 토큰을 배포, 발행 및 이전합니다. JSON에는 공급량, 최대 발행 단위, 고유 코드 등 토큰의 다양한 속성을 설명하는 코드 조각이 포함됩니다. 이전 글에서 이미 언급했듯이, BRC20 토큰의 본질은 반동질 토큰(SFT)입니다. 즉, 어떤 상황에서는 NFT처럼 거래되고, 다른 상황에서는 FT처럼 거래됩니다. 이러한 '다른 상황'에 대한 제어는 어떻게 가능한 것일까요? 답은 인덱서(indexer)에 있습니다.
인덱서는 실제로 장부 기록자로서, 수신된 정보를 분류하여 데이터베이스에 기록합니다. Ordinal 프로토콜에서 인덱서는 input과 output을 추적함으로써 정렬된 sats가 서로 다른 주소에서 어떻게 변화하는지 결정합니다. BRC-20 프로토콜에서는 인덱서가 추가 기능을 갖습니다: 각인 내 토큰 잔고가 서로 다른 주소에서 어떻게 변화하는지 기록합니다.
따라서 장부 기록자의 관점에서 다양한 토큰 존재 형태를 볼 수 있습니다. BRC20 프로토콜 토큰은 사실상 삼중 데이터베이스에 존재합니다. 첫 번째 레이어1, 장부 기록자는 BTC 채굴자이며, 데이터베이스 유형은 '체인형 데이터베이스'이며, 생성된 BTC는 FT 자산입니다. 두 번째 레이어2, 장부 기록자는 Ordinal 인덱서이며, 데이터베이스 유형은 '관계형 데이터베이스'이며, 생성된 일련번호가 매겨진 sats는 NFT 자산입니다. 세 번째 레이어3, 장부 기록자는 BRC20 인덱서이며, 데이터베이스 유형은 '관계형 데이터베이스'이며, 생성된 BRC20 자산은 FT 자산입니다. BRC20을 '장' 단위로 계산할 때는 ordinal 인덱서의 관점(해당 인덱서가 기록)에서 보기 때문에 자연스럽게 NFT입니다. 반면 BRC20을 분할된 '개' 단위로 생각할 때(특히 중심화된 거래소에 입금한 후), 관점은 BRC20 인덱서(해당 인덱서 또는 중심화 거래소 서버가 기록)이므로 자연스럽게 FT입니다. 따라서 반동질 토큰(SFT)의 존재는 서로 다른 계층의 장부 기록자들로 인해 발생한다고 결론지을 수 있습니다.
블록체인 자체가 분산 데이터베이스이기 때문에, '체인형 데이터베이스'를 공동으로 유지하기 위해 채굴자라는 장부 기록자 집단이 존재합니다(오직 체인형 데이터베이스만이 진정한 탈중앙화를 가능하게 하기 때문입니다). 그러나 결국 우리는 다시 중심화된 '관계형 데이터베이스'의 길로 돌아왔습니다. 이것이 바로 최근에 Ordinal 프로토콜 창시자, BRC20 프로토콜 창시자, unisat 지갑이 인덱서 업그레이드 여부를 두고 격렬하게 논쟁했던 근본적인 이유입니다














