Uniswap V3 데이터 정제 프로세스 분석
글: Zelos
서론
지난 회차에서는 유니스왑(Uniswap)에서 사용자 주소 관점에서 순자산과 수익률을 통계적으로 분석했습니다. 이번에도 같은 목표를 가지고 있지만, 해당 주소가 보유한 현금까지 포함하여 총 순자산과 수익률을 산출하는 것이 목표입니다.
이번 통계 대상은 두 개의 풀(pool)이며 다음과 같습니다:
-
폴리곤(Polygon) 상의 USDC-WETH(수수료: 0.05%), 풀 주소: 0x45dda9cb7c25131df268515131f647d726f50608[1]. 이는 지난 번 분석에 사용된 동일한 풀입니다.
-
이더리움(Ethereum) 상의 USDC-ETH(수수료: 0.05%), 풀 주소: 0x88e6A0c2dDD26FEEb64F039a2c41296FcB3f5640[2]. 이 풀은 네이티브 토큰(native token)을 포함하고 있어 데이터 처리에 다소 복잡성이 추가됩니다.
최종 산출된 데이터는 시간 단위이며, 각 행의 데이터는 해당 시간의 마지막 순간 값을 의미합니다.
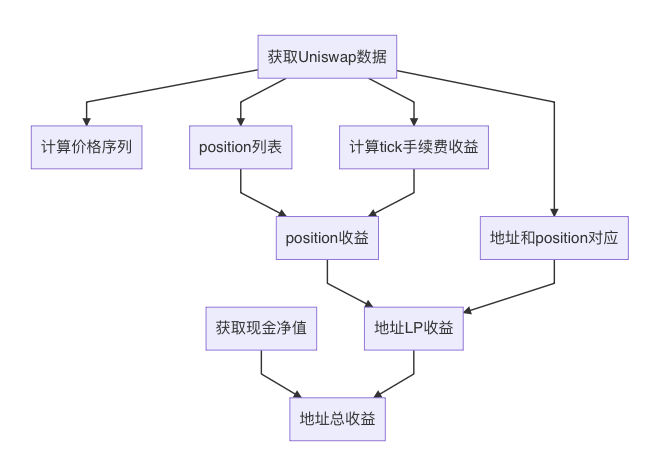
전체 프로세스
-
Uniswap 데이터 수집
-
사용자 현금 데이터 수집
-
가격 시계열 산정 (즉 ETH 가격)
-
분 단위로 각 tick에서 발생한 수수료 금액 계산
-
분석 기간 내 모든 position 목록 추출
-
주소와 position 간의 대응 관계 파악
-
각 position별 수익률 계산
-
position과 주소의 대응 관계를 바탕으로 각 사용자 주소의 LP 수익률 산정
-
사용자의 현금과 LP 자산을 통합하여 총 수익률 계산
1. Uniswap 데이터 수집
이전에 demeter 플랫폼을 위한 데이터 소스 제공을 위해 우리는 demeter-fetch라는 도구를 개발하였습니다. 이 도구는 다양한 경로를 통해 Uniswap 풀의 로그(log)를 수집하고 이를 다양한 형식으로 변환할 수 있습니다. 지원되는 데이터 소스는 다음과 같습니다:
-
Ethereum RPC: 이더리움 클라이언트의 표준 RPC 인터페이스. 데이터 수집 효율이 낮아 여러 스레드를 병렬로 실행해야 합니다.
-
Google BigQuery: BigQuery 데이터셋에서 데이터를 다운로드. 매일 한 번 업데이트되지만 사용이 간편하며 비용이 저렴합니다.
-
Trueblocks chifra: Chifra 서비스는 체인 상의 트랜잭션을 스크랩하여 재구성함으로써 트랜잭션, 잔고 등의 정보를 쉽게 내보낼 수 있게 해줍니다. 다만 노드 및 서비스를 직접 구축해야 합니다.
출력 가능한 형식은 다음과 같습니다:
-
minute: Uniswap swap 거래 정보를 분 단위로 리샘플링. 백테스트용
-
tick: 풀 내 모든 거래(swap 및 유동성 조작)를 기록
이번에는 주로 position 정보(자금량, 분 단위 수익, 수명주기, 보유자 등)를 통계화하기 위해 tick 데이터를 수집합니다.
이러한 데이터는 풀(pool)의 event log(mint, burn, collect, swap 등)를 통해 얻어집니다. 그러나 풀의 로그에는 토큰 ID가 포함되어 있지 않아 어떤 포지션이 해당 조작의 대상인지 특정할 수 없습니다.
실제로 Uniswap LP의 권리는 NFT로 관리되며, 이 NFT 토큰은 프록시(proxy) 컨트랙트에 의해 관리됩니다. 따라서 토큰 ID는 오직 프록시 컨트랙트의 event log에서만 확인할 수 있습니다. 따라서 완전한 LP position 정보를 얻으려면 프록시 컨트랙트의 event log를 확보하여 풀의 event log와 결합해야 합니다.
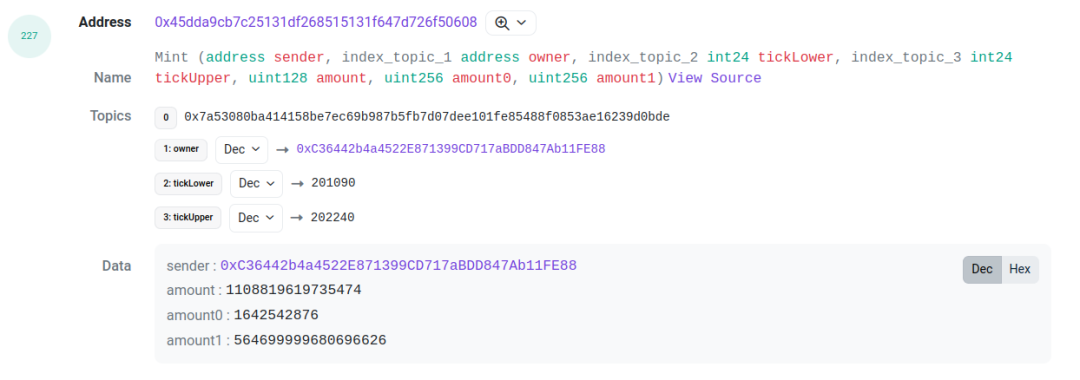
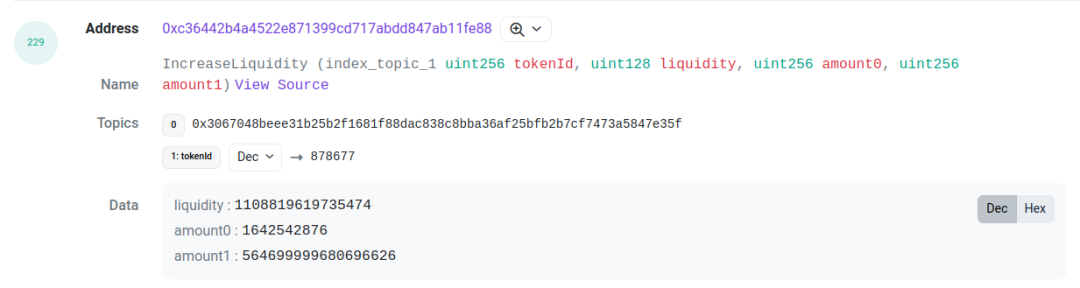
예를 들어 아래 거래[3]를 살펴보면, log index 227과 229의 두 개의 로그를 주목해야 합니다. 각각 풀 컨트랙트에서 발생한 mint 이벤트와 프록시 컨트랙트에서 발생한 IncreaseLiquidity 이벤트입니다. 이 둘의 amount(유동성), amount0, amount1 값은 동일하며, 이를 연관 짓는 근거로 활용할 수 있습니다. 이 두 로그를 연결하면 해당 LP 행동의 tick 범위, 유동성, 토큰 ID, 그리고 두 토큰의 금액을 모두 파악할 수 있습니다.
고급 사용자, 특히 일부 펀드들은 프록시를 우회하여 풀 컨트랙트를 직접 조작하기도 합니다. 이러한 경우 position은 토큰 ID를 가지지 않습니다. 이 경우에는 address-LowerTick-UpperTick 형식으로 임의의 ID를 생성하여 LP position을 식별합니다.
burn 및 collect의 경우에도 동일한 방식으로 풀의 event에 대응하는 position ID를 찾을 수 있습니다. 하지만 여기서 문제가 하나 있는데, 때때로 두 이벤트의 금액이 정확히 일치하지 않고 약간의 차이가 생깁니다. 예를 들어 다음 거래처럼 말이죠:
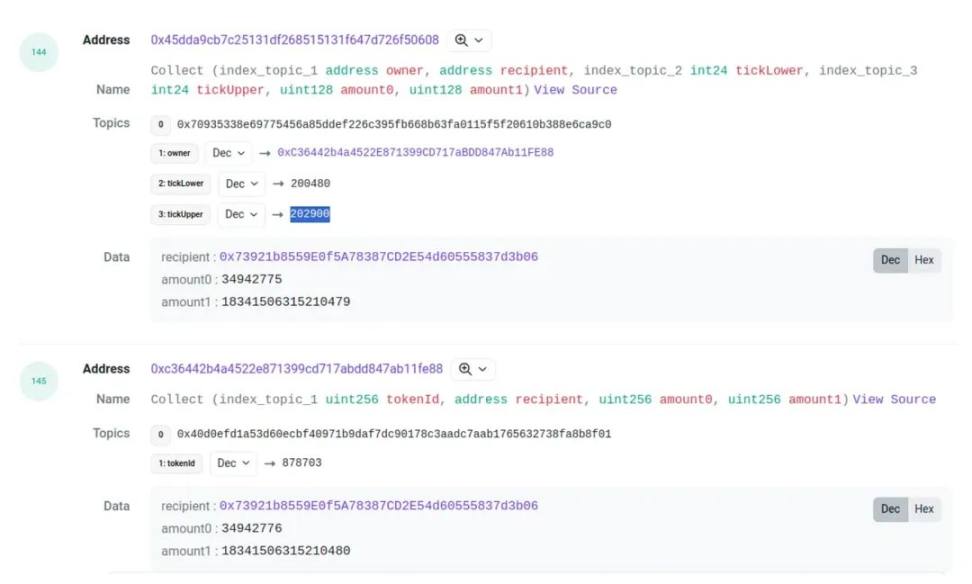
amount0과 amount1 사이에 작은 차이가 발생하는데, 비록 드물지만 종종 나타나는 현상입니다. 따라서 burn 및 collect 매칭 시 일정한 오차 범위를 설정하여 처리합니다.
다음으로 처리해야 할 문제는 '누가 이 거래를 시작했는가' 입니다. 유동성 철수(collect)의 경우 collect 이벤트의 receipt를 position의 보유자로 간주합니다. 반면 mint의 경우 풀의 mint 이벤트에서 sender를 확인해야 하는데(앞서 mint 이벤트 이미지 참조), 이 sender가 바로 LP 제공자가 됩니다.
사용자가 풀 컨트랙트를 직접 조작했다면 이 sender는 LP 제공자가 되겠지만, 일반 사용자가 프록시를 통해 조작했다면 sender는 프록시 주소가 됩니다. 왜냐하면 실제 자금은 프록시에서 풀로 이체되기 때문입니다. 다행히도 프록시는 NFT 토큰을 생성하며, 이 NFT 토큰은 반드시 LP 제공자에게 전송됩니다. 따라서 프록시 컨트랙트(NFT 토큰 컨트랙트)의 transfer 이벤트를 감지함으로써 mint에 해당하는 LP 제공자를 찾아낼 수 있습니다.
또한 NFT가 양도되면 position의 보유자가 변경될 수 있습니다. 저희는 이를 통계적으로 확인했으며, 그 사례는 매우 적습니다. 간소화를 위해 mint 이후의 NFT 양도는 고려하지 않았습니다.
2. 주소의 현금 보유량 수집
이 단계의 목적은 통계 기간 동안 각 주소의 모든 시점에서 보유한 토큰 수량을 파악하는 것입니다. 이를 위해서는 다음 두 가지 데이터가 필요합니다:
-
기준 시점(분석 시작 시점)의 잔고
-
통계 기간 중의 송금 기록
송금 기록을 기반으로 잔고를 더하거나 빼면 각 시점의 잔고를 추론할 수 있습니다.
기준 시점의 잔고는 RPC 인터페이스를 통해 조회 가능합니다. 아카이브 노드(archive node)를 사용하면 특정 블록 높이를 지정해 임의의 시점의 잔고를 조회할 수 있습니다. 네이티브 토큰과 ERC20 토큰 모두 동일한 방법으로 조회할 수 있습니다.
ERC20 토큰의 송금 기록은 비교적 쉽게 얻을 수 있으며, BigQuery, RPC, chifra 등 다양한 경로를 통해 수집할 수 있습니다.
반면 ETH 송금 기록은 트랜잭션과 trace를 통해 얻어야 합니다. 트랜잭션은 문제없지만 trace의 조회 및 처리는 계산량이 매우 큽니다. 다행히 chifra는 ETH 잔고 변화를 출력하는 기능을 제공합니다. 이는 잔고 변화 시점에 기록을 남기며, 전송 대상을 기록하지는 않지만 본 연구의 요구사항을 충족합니다. 이는 요구사항을 만족시키면서 비용을 최소화하는 가장 합리적인 방법입니다.
3. 가격 데이터 획득
Uniswap은 거래소로서 토큰 교환이 발생하면 swap 이벤트를 발생시키며, 이때 sqrtPriceX96 필드를 통해 토큰 가격을, liquidity 필드를 통해 당시 총 유동성을 얻을 수 있습니다.
본 연구의 풀은 안정화폐(USDC)를 포함하므로 U(달러) 대비 가격을 산출하는 것은 비교적 쉽습니다. 그러나 이 가격은 절대적으로 정확하지 않습니다. 우선 거래 빈도에 따라 영향을 받으며, swap 거래가 없으면 가격이 지연됩니다. 또한 안정화폐가 탈앵커링(anchor)될 경우 실제 가치와 차이가 발생할 수 있습니다. 하지만 일반적인 상황에서는 충분히 정확하여 시장 분석 목적에는 문제가 없습니다.
마지막으로 토큰 가격을 리샘플링하여 분 단위 가격 목록을 생성합니다.
또한 event의 liquidity 필드는 풀의 총 유동성 정보도 포함하므로 이를 함께 추가하여 다음과 같은 표를 생성합니다:
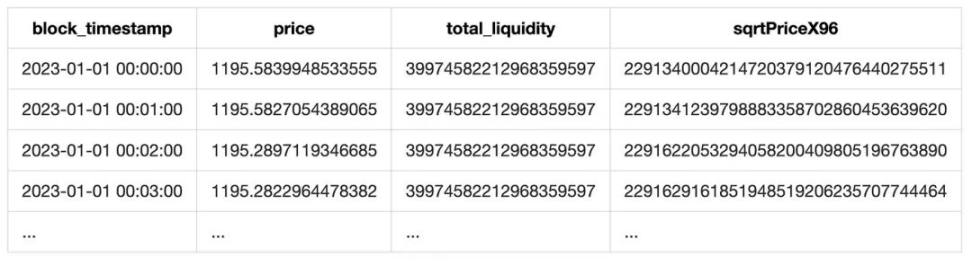
4. 수수료 통계
수수료는 position의 주요 수입원입니다. 사용자가 풀에서 swap을 수행할 때, 현재 tick을 포함하는 lower 및 upper tick 범위 내의 position들이 일정한 수수료를 수취합니다. 수령 금액은 유동성 비중, 풀의 수수료율, tick 범위 등에 따라 결정됩니다.
사용자의 수수료 수익을 통계화하기 위해, 풀이 분 단위로 어느 tick에서 얼마의 swap 금액이 발생했는지를 기록합니다. 이후 해당 분에서 해당 tick의 수수료 수익을 계산합니다:

최종적으로 다음과 같은 표를 생성합니다:
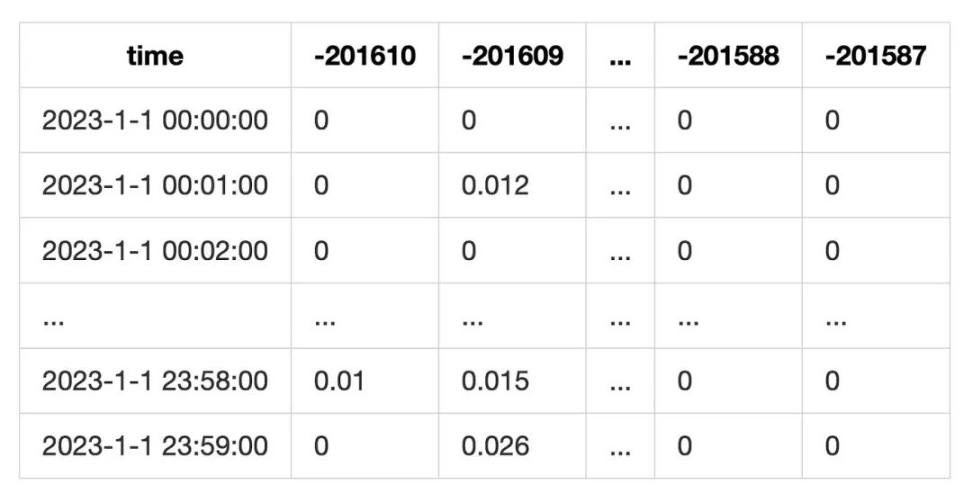
이 통계 방식은 swap 시 현재 tick의 유동성이 고갈되는 경우를 고려하지 않습니다. 그러나 본 연구의 대상이 LP이며 tick 범위 기반으로 통계를 산출하기 때문에 이러한 오차는 어느 정도 완화됩니다.
5. Position 목록 추출
Position 목록을 얻기 위해 먼저 position의 식별자(ID)를 정의해야 합니다.
-
프록시를 통해 투자하는 LP의 경우, 각 position은 NFT 즉 토큰 ID를 가지며, 이를 position ID로 사용할 수 있습니다.
-
풀 컨트랙트를 직접 조작하는 LP의 경우,
address_LowerTick_UpperTick형식의 임의 ID를 부여합니다. 이를 통해 모든 position에 고유 식별자가 부여됩니다.
이 식별자를 통해 LP의 모든 조작을 통합하여 position의 전체 수명주기를 설명하는 목록을 생성할 수 있습니다. 예시:

주의할 점은 이번 통계 대상 기간이 2023년 전체이며 풀 설립 초기부터가 아니라는 점입니다. 따라서 일부 position의 2023년 1월 1일 이전 조작 기록은 불가피하게 누락됩니다. 이를 보완하기 위해 분석 시작 시점에서 해당 position의 유동성 양을 추정해야 하며, 다음과 같은 경제적 접근법을 사용합니다:
-
mint와 burn의 유동성을 합산하여 L 값을 산출
-
L > 0인 경우(mint > burn), 분석 시작 전 이미 유동성이 존재했다고 간주하고, 분석 시작 시점(2023.1.1 0:0:0)에 가상의 mint 조작을 추가
-
L < 0인 경우, 분석 종료 시점에도 여전히 유동성을 보유하고 있다고 간주
이 방식은 2023년 이전 데이터를 다운로드하지 않아도 되므로 비용을 절감할 수 있습니다. 하지만 잠긴 유동성(sunken liquidity) 문제에 직면합니다. 즉, 해당 연도 동안 아무런 조작도 하지 않은 LP는 발견되지 않게 되는 것입니다. 그러나 이 문제는 심각하지 않습니다. 통계 기간이 1년이라는 점에서 대부분의 사용자는 기간 내에 LP를 조정할 것으로 가정합니다. 1년이라는 시간은 ETH 가격이 크게 변동할 수 있는 기간이며, 사용자는 다양한 이유로 LP를 조정합니다(tick 범위 초과, 다른 DeFi로 자금 이전 등). 따라서 활발한 사용자는 가격에 따라 LP를 조정할 것이며, 자금을 풀에 방치한 채 전혀 조정하지 않는 사용자는 비활성 사용자로 간주하여 통계 대상에서 제외합니다.
더 복잡한 경우는 2023년 이전에 유동성을 mint한 후 분석 기간 내 일부 mint/burn을 수행했지만, 분석 종료 시점에서도 모든 유동성을 burn하지 않은 경우입니다. 이 경우 일부 유동성만 통계화되며, 이는 수수료 추정에 영향을 미쳐 수익률 산출에 이상치를 초래할 수 있습니다. 이에 대한 구체적인 원인은 이후에 논의하겠습니다.
최종 통계 결과, 폴리곤에는 총 73,278개의 position이 있었고, 이더리움에는 21,210개의 position이 있었습니다. 각 체인에서 수익률 이상치는 10개 미만으로, 이 가정이 신뢰할 수 있음을 입증합니다.
6. 주소와 position의 대응 관계 추출
최종 목표가 주소 단위 수익률이므로, 주소와 position의 대응 관계를 파악해야 합니다. 이를 통해 사용자의 구체적인 투자 행동을 이해할 수 있습니다.
1단계에서 자금 조작(mint/collect)과 관련된 사용자를 식별하는 작업을 수행하였으므로, mint의 sender와 collect의 receipt를 파악함으로써 position과 주소의 대응 관계를 도출할 수 있습니다.
7. Position의 순자산 및 수익률 계산
이 단계에서는 각 position의 순자산을 계산하고, 이를 기반으로 수익률을 산출합니다.
순자산
Position의 순자산은 두 부분으로 구성됩니다. 첫째는 LP의 유동성으로, 마켓 메이킹의 원금에 해당합니다. 사용자가 자금을 position에 투입하면 유동성 수량은 변하지 않지만, 가격 변화에 따라 순자산 가치는 변동합니다. 둘째는 수수료 수익으로, 유동성과 독립되어 fee0 및 fee1 필드에 별도로 저장되며, 시간이 지남에 따라 증가합니다.
따라서 임의의 분에서 유동성과 해당 분의 가격을 결합하면 원금 부분의 순자산을 얻을 수 있습니다. 수수료의 계산은 4단계에서 생성한 수수료 표를 활용합니다.
먼저 해당 position의 유동성을 현재 풀의 총 유동성으로 나누어 분배 비율을 산출합니다. 이후 해당 position의 tick 범위에 포함되는 모든 tick의 수수료를 합산하여 해당 분의 수수료 수익을 계산합니다.
수식으로 표현하면 다음과 같습니다:

마지막으로 fee0과 fee1의 수수료를 합산하여 수수료 순자산을 산출하고, 유동성 순자산과 더하면 총 순자산을 얻습니다.
순자산 계산 시 mint/burn/collect 거래를 기준으로 position의 수명주기를 분할합니다.
-
mint 거래 발생 시 유동성 증가
-
burn 거래 발생 시 유동성 감소. 유동성 가치는 수수료 필드로 전환됩니다(풀 컨트랙트 코드도 동일하게 작동).
-
collect 거래 발생 시 계산이 트리거되며, 이전 collect 시점부터 현재까지의 분 단위 순자산 및 수수료 수익을 계산하여 목록을 생성합니다.
마지막으로 각 collect에서 얻은 순자산 목록을 통합하고, 리샘플링 및 기타 통계 처리를 거쳐 최종 결과를 도출합니다.
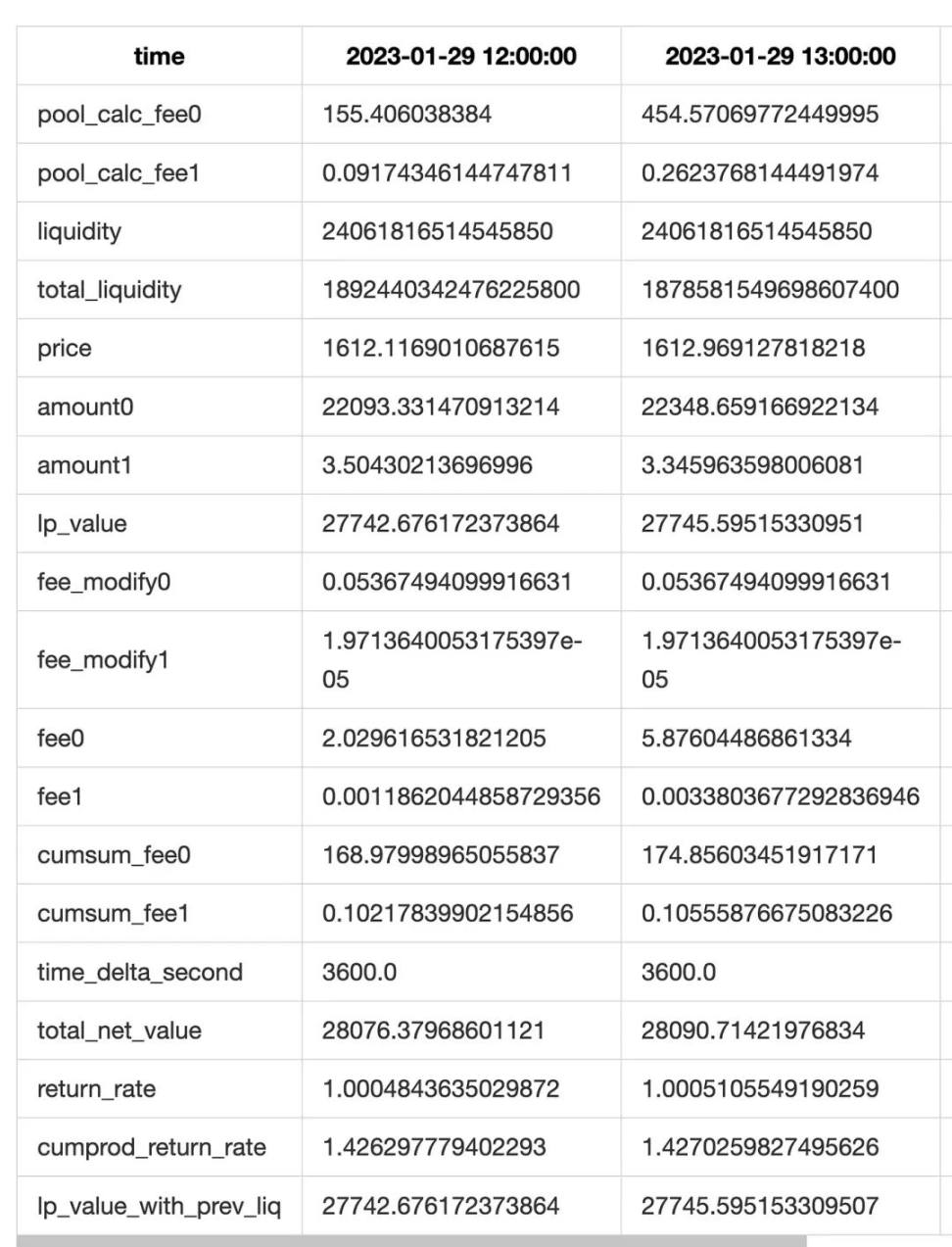
추가로 정밀도를 높이기 위해 두 가지 최적화를 수행합니다.
첫째, 거래가 발생한 시간(분 단위)은 분 단위 통계를 적용하고, 거래가 없는 시간은 시간 단위 통계를 적용한 후 최종적으로 시간 단위로 리샘플링합니다.
둘째, collect 이벤트에서는 유동성과 수수료의 총합을 얻을 수 있으므로, 실제로 수령한 값과 이론적 계산값을 비교하여 이론 수수료와 실제 수수료의 차이를 산출합니다(실제로는 LP 원금의 차이도 포함되지만, 오차가 매우 작아 거의 0으로 간주). 이 차이를 각 행에 보정하여 수수료 추정 정밀도를 높입니다(즉 위 표의 fee_modify0 및 fee_modify1 필드).
참고:
-
보정 시 해당 시간의 유동성에 따라 수수료 배분을 가중평균해야 하며, 그렇지 않으면 해당 시간의 수수료가 과대 산정될 수 있습니다.
-
통계 데이터가 2023년 전체가 아닌 부분 데이터이므로, 5절에서 언급한 잠긴 유동성(sunken liquidity) 현상이 발생할 수 있습니다. 이는 실제 수수료가 이론 수수료보다 훨씬 많아져 수익률이 비정상적으로 높게 나타나게 할 수 있습니다.
각 행이 해당 시간의 마지막 순간 데이터임을 고려할 때, 완전히 종료된(position close) position의 순자산은 0이 됩니다. 이 경우 종료 시점의 순자산이 소실됩니다. 이를 보존하기 위해 파일 끝에 2038-1-1 00:00:00 시각의 데이터 행을 추가하여 position 종료 시점의 순자산 등을 저장합니다. 이는 다른 프로젝트의 통계 용도를 위한 것입니다.
수익률
일반적으로 수익률은 시작 순자산을 종료 순자산으로 나누어 계산합니다. 그러나 본 연구에서는 이 방법이 적합하지 않습니다. 그 이유는 다음과 같습니다:
-
수익률을 분 단위로 세분화해야 함
-
position 중간에 자금의 입출금이 발생하므로, 단순히 시작과 종료의 순자산만으로는 수익 실적을 정확히 반영할 수 없음
문제 1에 대해서는 각 분의 순자산을 나누어 분 단위 수익률을 계산한 후, 이를 누적곱하여 총 수익률을 산출할 수 있습니다.
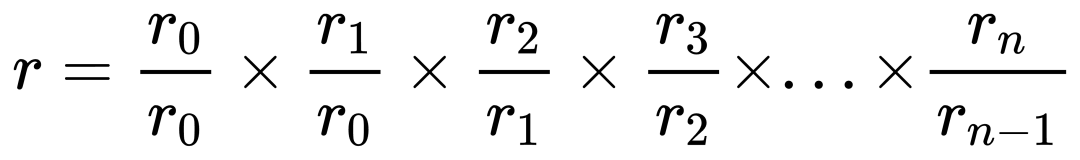
그러나 이 알고리즘은 심각한 문제를 안고 있습니다. 분 단위 수익률 중 하나라도 계산 오류가 발생하면 총 수익률에 큰 편차가 생깁니다. 즉 통계 과정이 '칼날 위를 걷는' 상황이 되어 오차가 전혀 허용되지 않습니다. 반면, 이는 모든 통계 오류가 명백하게 드러나도록 만들어 줍니다.
문제 2에 대해서는 해당 분에 자금 입출금이 있을 때 수익률을 직접 나누는 방식은 비현실적인 결과를 초래합니다. 따라서 분 단위 수익률 알고리즘을 더욱 세분화할 필요가 있습니다.
우리가 시도한 첫 번째 방법은 순자산 변화를 상세히 분해하고 자금 변동을 제거하는 것입니다. 순자산 변화를 다음과 같이 분류합니다: 1) 가격 변동에 의한 원금 변화, 2) 해당 분의 수수료 누적, 3) 자금의 유입/유출. 여기서 3은 통계에서 제외해야 합니다. 이를 위해 다음과 같은 계산 방법을 설정합니다:
-
현재 분을 n, 이전 분을 n-1이라 가정
-
현재 분의 모든 송금 조작은 n:0.000초에 발생한다고 가정. 이후 남은 시간 동안 LP의 순자산은 변하지 않으며, 즉 n:0.001초의 순자산은 n:59.999초와 동일
-
수수료 누적은 해당 분의 마지막 순간, 즉 n:59.999초에 발생
-
이전 분 마지막 시점(n-1:59.999)의 가격 및 수수료가 현재 분(n:0.000)의 시작 가격 및 수수료
위 가정을 기반으로, 분 단위 수익률은 "말미의 유동성 / 가격 / 수수료"를 "말미의 유동성 / 시작 가격 / 시작 수수료"로 나눈 값입니다. 수식으로 표현하면 다음과 같으며, f는 유동성을 순자산으로 환산하는 함수입니다.
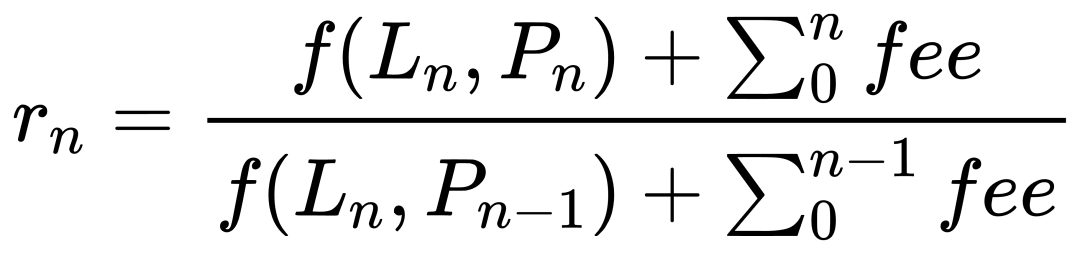
이 방식은 유동성 변화를 완벽히 회피하면서 가격 및 수수료의 영향을 반영하므로 매우 우수해 보입니다. 그러나 실제로 몇몇 행에서 비정상적으로 높은 수익률이 발생합니다. 조사 결과, 이는 유동성 철수(burn) 시점에서 문제가 발생한다는 것을 알게 되었습니다. 우리의 규칙을 다시 살펴보면: 각 행은 해당 분/시간의 마지막 순간을 의미합니다. 이는 데이터 통계에 통일된 기준을 제공하지만, 각 열의 의미가 다르다는 점에 유의해야 합니다:
-
순자산 열은 순간값, 즉 해당 분/시간의 마지막 값
-
수수료 열은 누적값, 즉 해당 분/시간 동안 누적된 수수료
따라서 유동성을 철수한 시간의 경우:
-
LP가 burn되고 토큰이 이체되면, 해당 시간 말순 순자산은 0이 됨
-
수수료는 누적값이므로 해당 시간 말순 수수료는 0보다 큼
이로 인해 위의 공식이 다음과 같이 퇴화(degenerate)됩니다:
이 현상은 position 수명주기의 끝뿐 아니라 일부 유동성만 burn할 때도 발생하며, 수수료 증가와 LP 순자산 비율의 변화를 초래합니다.
간소화를 위해 LP 순자산이 변화할 때 수익률을 1로 설정합니다. 이는 수익률 계산에 오차를 유발하지만, 정상적으로 지속 투자하는 position의 경우 거래가 발생하는 시간은 전체 수명주기에 비해 매우 적으므로 영향은 크지 않습니다.
8. 주소별 LP 총 수익 계산
각 position의 수익률과 position-주소 대응 관계를 활용하면, 각 사용자 주소의 position별 수익률을 도출할 수 있습니다.
이 알고리즘은 간단합니다. 동일 주소의 서로 다른 시기의 position을 연결하며, 투자하지 않은 기간은 순자산을 0, 수익률을 1로 설정합니다(시작과 종료 모두 0이므로 변화 없음).
동일 시기에 여러 position이 있는 경우 중첩 기간의 순자산을 합산하여 총 순자산을 산출합니다. 수익률을 통합할 때는 각 position의 순자산을 기준으로 가중평균합니다.
9. 현금 및 LP 통합 총 수익 계산
마지막으로 사용자 주소의 현금 보유량과 LP 투자 자산을 통합하면 최종 결과를 얻을 수 있습니다.
순자산 통합은 이전 단계(position 통합)보다 단순합니다. LP 순자산의 시간 범위를 확인한 후, 해당 시간의 현금 보유량과 ETH 가격을 찾아 총 순자산을 계산하면 됩니다.
수익률의 경우에도 분 단위 수익률을 계산한 후 누적곱하는 알고리즘을 사용합니다. 처음에는 7절에서 언급한 오류가 있는 수익률 알고리즘을 사용하였습니다. 이는 고정 부분(현금의 cash 수량, LP의 유동성)과 가변 부분(가격 변동, 수수료 누적, 자금 입출금)을 분리해야 합니다. position 통계에 비해 복잡도가 훨씬 높습니다. 왜냐하면 Uniswap의 자금 입출금은 mint 및 collect 이벤트만 주시하면 되지만, 현금의 추적은 매우 까다롭기 때문입니다. 자금이 LP로 이체되었는지 외부로 이체되었는지 구분해야 하며, LP로 이체된 경우 원금은 유지되지만 외부로 이체된 경우 원금 수량을 수정해야 합니다. 이를 위해 ERC20 및 ETH 송금 대상 주소를 추적해야 하며, 이는 매우 번거로운 작업입니다. mint/collect 시 전송 주소는 풀 또는 프록시일 수 있으며, 더 복잡한 것은 ETH 전송입니다. ETH는 네이티브 토큰이므로 일부 송금 기록은 trace를 통해서만 확인 가능하지만, trace 데이터량이 너무 커서 처리 능력을 초과합니다.
결국 마지막 결정타는 우리가 각 행의 순자산이 해당 시간의 순간값이고 수수료는 누적값이라는 사실을 매우 늦게 발견했다는 점입니다. 물리적 의미상 직접 더할 수 없습니다.
따라서 이 알고리즘
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News