

$VVVの深層分析:過小評価されているプライバシー重視型AIインフラと成長曲線
TechFlow厳選深潮セレクト
$VVVの深層分析:過小評価されているプライバシー重視型AIインフラと成長曲線
ヴェネツィアのプライバシー・アーキテクチャからビジネスモデルに至るまでの全プロセスを分解分析
著者:Yan Liberman
編集・翻訳:TechFlow
TechFlow解説:Veniceの直近3週間のサブスクリプションデータによると、新規ARR(年間定額収益)の増加率は高達34%に達しており、現在の時価総額における評価額は、今後12か月間の予想収益のわずか2.5倍にとどまっている。元暗号資産投資家である筆者は、Veniceがプライバシー指向のアーキテクチャからビジネスモデルに至るまで全工程を解体分析し、市場が「プライバシーAI推論」というセグメントの実際の規模を著しく過小評価していると指摘。さらに、Veniceがこの分野において他に類を見ない「コンビネーション・アドバンテージ」を有していると主張し、$VVVの上昇を予想している。

Veniceは、ユーザーが最先端のモデルやオープンソースモデルを利用する際に、その身元を基盤となるモデルプロバイダーに露呈することなく、プライバシーを最優先とするAI推論プラットフォームである。筆者は、これが現時点でAI市場で最も包括的なプライバシー解決策であると見ている。すなわち、匿名プロキシ、オープンソースモデルのルーティング、ハードウェア認証によるTEE(Trusted Execution Environment)推論、エンドツーエンド暗号化推論——この4つの機能がすべて、消費者向け製品1つに統合されており、プライバシーモードはリクエスト単位で選択可能である。競合他社で、これら4つを同時に提供できる企業は存在しない。
本ビジネスは継続的に顕著な成長を遂げている。Crypto Twitter上でのVeniceに関する議論は、現状の収益、最近の成長率および将来の軌道を一般的に過小評価している。Veniceは最近、日次サブスクリプションデータの公表を開始しており、3週間にわたる細かい粒度のデータから、新規サブスクリプションARRが明確に加速していることが確認された:
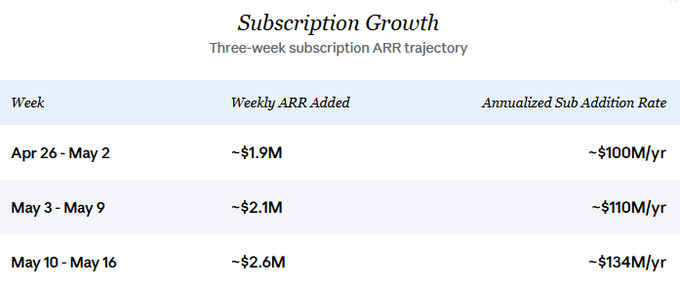
持続的な成長率は、本分析の中心的仮定である。また、API収益も最近、サブスクリプション成長と連動して増加していると筆者は仮定しており、この点については後述の「現状と成長」セクションで詳細に説明する。保守的な年間新規サブスクリプション収益増加額を4月下旬のペースと同水準の1億ドルと設定し、API新規収益も同額と仮定した場合、今後12か月間の総収益増加分は約2億ドルとなる。
最近の加速トレンドは、このペースが維持されるならば、実際の数値には明確な上方余地があることを示唆している。
本稿では、Veniceの独自性を以下の観点から順次解体していく:
- プライバシーの階層:標準的な「プライベートAIチャット」という表現を遥かに凌駕する、深遠なプライバシー・アーキテクチャ。
- ユーザーカテゴリー:Veniceのユーザー層は、主流の経路から内容ポリシー・コンプライアンス・脅威モデル・原則などによって「押し出された」ものであり、マーケティングによって引きつけられたものではない。
- 市場規模:拡大を続けるプライバシー指向の推論市場であり、消費者向けチャットという枠組みではしばしばその規模が過小評価される。
- 競争環境:Veniceは、プライバシーの深さ・検閲なしのモデルアクセス・暗号資産原生の配信を一括して提供しており、この組み合わせは現時点の競合他社には類を見ない。
- トークン設計とVVVの評価:VVVおよびDIEMのメカニズムが、いかにしてプラットフォームの成長をトークン価値へと転換するか、およびVVVの評価倍率が、OpenRouter・Fireworks・Together AIなどのプライバシー推論関連企業と比較してどう位置づけられるか。
最近の上昇と14ドルへの調整後、VVVの時価総額は約6.6億ドル、完全希薄化評価額(FDV)は約11.2億ドルである。現在のARRは約6,000万ドル(後述の「現状と成長」セクションにて算出)であり、年間約2億ドルのペースで増加中で、なおかつ加速している。現状のARRベースで計算すると、VVVの売上高倍率(P/S)は約11倍(FDVベースでは約19倍)となり、プライバシー推論関連企業のOpenRouterの26倍を下回る。今後12か月間のARRが約2.6億ドル(現在の6,000万ドル+年間2億ドルの新規増加分)と仮定した場合、VVVの売上高倍率は約2.5倍(FDVベースでは約4.3倍)となる。
現状と成長
Veniceは最近、日次新規サブスクリプションデータの公表を開始した。定期的に発表される公開登録ユーザー数のマイルストーン公告と併せることで、これらの2つのデータフローから、現在のARR推計および将来の軌道を構築することが可能となった。
現在のARRを推計するにあたり、まず登録ユーザー総数から着手した。一定期間にわたる公開公告の頻度から、登録ユーザー総数は毎月約30万人のペースで増加している。最近確認されたマイルストーンは、2026年5月16日時点で約300万人の登録ユーザーであり、2月1日の約200万人から、毎月30万人のペースと一致している。終身有料変換率を約5%と仮定(日次データが示す新規登録ユーザーの変換スピードを考慮すると、これは控えめな見積もりである可能性が高い)すると、5月中旬時点で約15万人のアクティブな有料サブスクリプションユーザーが存在することになる。4月中下旬までは、基本的な月額18ドルのProパッケージのみが提供されていた;Pro+(月額68ドル)およびMax(月額200ドル)パッケージの導入により構成が変化し始めたが、大多数の有料ユーザーは依然として18ドルのプランに留まっている。加重ARPPU(1ユーザー当たり平均課金額)は月額18〜19ドル程度であり、これより現在のサブスクリプションMRR(月間定額収益)は約280万ドル、すなわち年間サブスクリプションARRは約3,300万ドルと推計される。これはサブスクリプション部分のみの数字であり、本節の後半でAPI収益を加算して、完全な現在のARR推計値を導き出す。
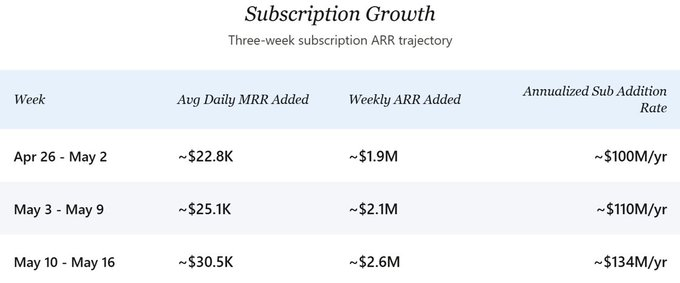
将来の軌道に関して、新規サブスクリプションARRの成長率は継続的に加速している。4月下旬のペースでは、会社は週あたり約200万ドルのサブスクリプションARRを新規獲得していた。しかし、直近の1週間(5月10日〜16日)では、このペースが週あたり約260万ドルへと飛躍し、年率換算で1.34億ドルのサブスクリプション新規増加ペースに相当する。本分析の中心シナリオでは、最近の加速を過大評価しないよう、控えめな年率1億ドルという数字を基準としている。離脱を差し引いた純増加は若干低くなるが、現時点の規模ではこの差は方向性において無視できるほど小さいため、毛増加率が本稿の前向き分析の核心を構成する。
3週間にわたる細かい粒度のデータ(4月26日〜5月16日)は、明確な上昇傾向を示している:
第1週から第3週にかけて、日次MRR新規増加額は約34%増加した。API収益が新規サブスクリプションMRRと1:1で追跡されると仮定(後述)すれば、潜在的な総年率新規増加額は、約2億ドルから約2.68億ドルへと跳ね上がっている。この転換点を推進している要因は2つあるように思われる。第一に、Pro+およびMaxパッケージの導入により、高い支払意思を持つユーザーにそれまでなかった選択肢が提供され、加重ARPPUが向上した。第二に、パッケージの拡充後に有料変換率が加速したように見える。
API収益は直接的な開示がないため、測定が難しい。筆者の基本シナリオでは、最近の新規API運用収益と新規サブスクリプションMRRの比率は約1:1であり、歴史的な新規比率はこの比率を下回っていた。結果として、現在のAPI ARRのベースはかなり大きいものの、サブスクリプションARRをやや下回っており、時間の経過とともに両者は同等の水準へと収斂しつつある。
50:50の分割比率の根拠は、同業他社とのベンチマークから始まる。大規模なクローズドソースモデルプラットフォームでは、ChatGPTのAPI収益比率は約25%、サブスクリプション比率は約75%である。これは、膨大な消費者向けサブスクリプションベースがAPI比率を相対的に小さくしているためである。一方、AnthropicのAPI比率は約80%、サブスクリプション比率は約20%であり、そのユーザー層が開発者および企業に偏っているためである。Veniceは構造的にこの2者の中間に位置する:プライバシー指向であるため、ChatGPTほど一般消費者を惹きつけることはないが、有料ユーザー層はAnthropicの企業重視型混合よりも広範である。50:50の分割は、この範囲のちょうど中間にある。
この範囲は、Venice特有の2つの証拠によってさらに裏付けられている。
第一に、VeniceのAPIはすでに多数の開発者向け配信チャネルを確立している。OpenRouterはVeniceのモデルをルーティングし、FleekはすべてのホスティングプロキシをデフォルトでVenice推論に設定している。Cursor、Brave Leo(BYOM経由)、VSCodeコミュニティ拡張などもVeniceをサポートしている。これらの統合は過去1年以上にわたって積み重ねられてきたものであり、APIが実在し、重要なビジネスであり、規模ある生産トラフィックを支えるものであるという主張を裏付けている。
第二に、最近のトークンスループットの上昇は、サブスクリプションの成長だけでは説明できないほど急激なものである。1日あたりのトークンスループットは2月初めの200億から5月初めには600億以上へと、3か月間で約3倍に増加した。同一期間内、有料サブスクリプションベースは約50%増加(約10万件から約15万件へ)したにすぎない。4月中旬のPro+/Maxパッケージ拡充は、ごく少数の新規登録ユーザーのみをより高いARPPUのパッケージへと移行させたにすぎず、これらのパッケージの単ユーザー・トークン消費量についても大幅な仮定を置いても、このギャップを埋めることはできない。トークンスループットの大部分の上昇は、従量課金制のAPIワークロード、すなわちエージェントの展開、統合パートナーによる生産トラフィックの拡大、および同様の高容量利用シナリオから生じていると考えられる。
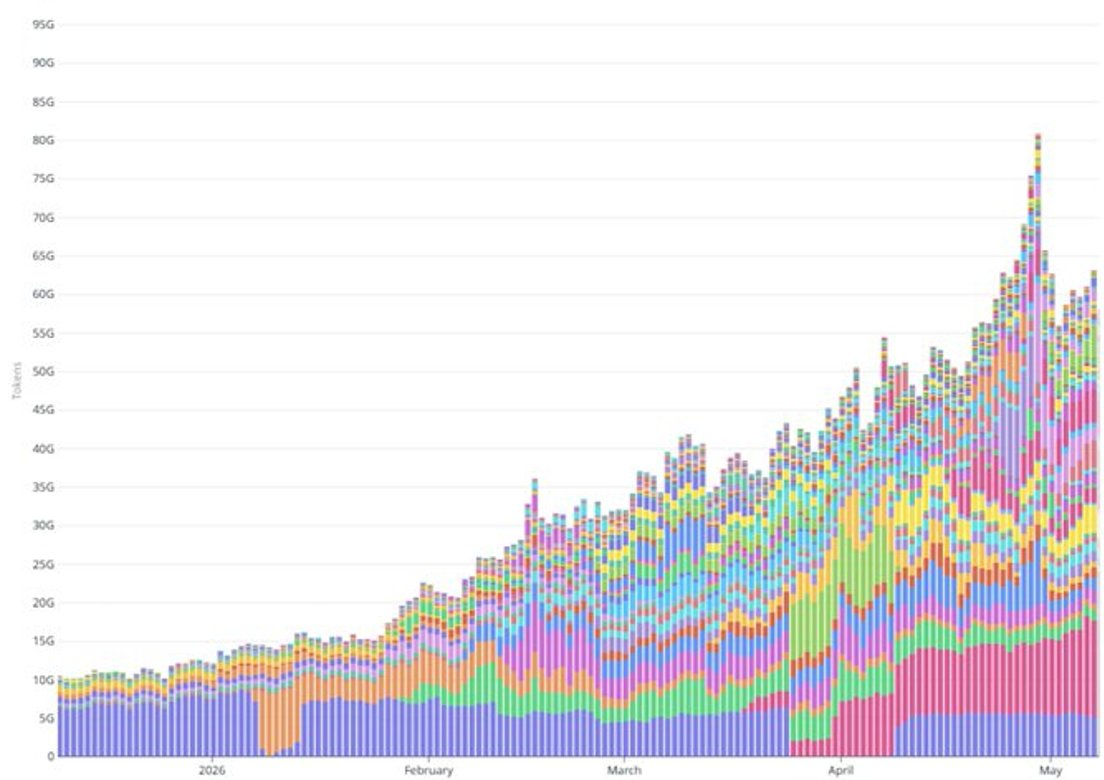
現在のAPI ARRをサブスクリプションARRと比較して推計するのはさらに困難である。なぜなら、1:1の比率はごく最近になって現れたものであり、4月中旬以前はAPIのシェアはおそらくさらに小さかったためである。中間的な仮定として、APIは歴史的にサブスクリプションの70〜80%程度であったが、最近になって1:1に達したとすると、現在のAPI ARRは約2,500〜3,000万ドルとなる。現在の総ARR推計値は、約5,500〜6,500万ドル、中央値は約6,000万ドルである。
API部分について簡単な補足:これは現在の使用に基づく運用収益の年率換算であり、循環的なサブスクリプションコミットメントではないため、サブスクリプション部分よりも内在的な変動性が高い。重度のAPI顧客が使用を減らすと、API運用収益は大きく減少する可能性があるが、サブスクリプションベースは同様の離脱を伴わない。
年初来の収益とのクロスバリデーション:2月初めの1日あたり200億トークンから5月初めの1日あたり600億トークン以上への上昇を踏まえると、Veniceは2026年だけで少なくとも3,000万ドルの累積収益を生み出している。この数字は、現在のARRが5,500〜6,500万ドルの範囲にあるという推計と一致しており、このベースは年率2億ドルというペースで急速に拡大している。
重要だが、年率新規増加額は、将来12か月間に稼得される収益とは同一ではない。新規ARRは1年間に線形に増加するため、2026年に2億ドルの年率新規増加ペースが継続した場合、1年間で稼得される新規収益は約1億ドルとなり、現在のARRベースが約6,000万ドルを追加する。将来12か月間に稼得される総収益は1.5〜2億ドルの範囲にあり、その12か月間の終了時のARRは離脱を差し引かずに約2.6億ドル(現在の6,000万ドル+新規2億ドルのARR)となる。
過去を振り返ることは単なる注釈に過ぎない。Veniceの現在のARR年率新規増加ペースは約2億ドルであり、真に重要な問いは、「今日のペースが底値なのか、それとも出発点なのか」である。重要な変数は以下の通り:サブスクリプションの成長が維持されるか、APIの使用がサブスクリプションの拡大を上回り続けるか、キューが成熟するにつれてどの程度の離脱が発生するか、そしてアドレス可能な市場がこのペースの持続的な成長を支えられるかである。
市場規模の問題は、Veniceが実際に何をしているかを理解した上で初めて答えやすくなる。最も明確な基礎は、LLMインタラクションのプライバシー・ステアケースであり、各レベルは異なるプライバシー前提を表しており、Veniceのモードは特定のレベルに埋め込まれている。
プライバシーの階層
以下に示すステアケースは、クラウドベースのAI利用を、非常に狭いが重要な軸——誰が平文のプロンプトをユーザーの身元と関連付けることができるか——に基づいてランク付けしたものである。これはすべてのプライバシー問題を解決するものではない。デバイスの侵害、支払い痕跡、アカウントのメタデータ、召喚状リスク、エンドポイントのセキュリティは、それぞれ独立した問題である。しかしながら、ユーザーがデフォルトのチャットボットからVeniceのより高いプライバシーモードへと移行する際に、実際に何が変わるのかを明らかにするものである。レベル番号(0〜7)は筆者が、Veniceをより広い枠組みに位置付けるために独自に設定したものである。Venice自身の分類法では、Anonymous(匿名)、Private(プライベート)、TEE、E2EEの4つの名前付きモードのみを使用し、これらは以下のLevel 3、4、6、7に対応する。
最も強力なプライバシー・オプションは、このステアケースにはそもそも含まれていない。ユーザー所有のハードウェア上でオープンソースモデルを実行し、クラウドを一切介さないことである。高性能のMacまたはワークステーション上でGLM 5.1やQwen 3.6を実行し、ネットワーク呼び出しを行わず、第三者を一切介さないことである。「プロンプトが私のマシンを決して離れない」という状態は、マシン自体が適切に強化されている限り、比類なき最高のプライバシーである。しかしこれは、ほとんどの人が選ぶ道ではない。ハードウェアは高価であり、ローカルで実行可能なオープンソースモデルは、最も困難なタスクにおいては、依然としてクローズドソース研究所の最先端水準に及ばない。統合や24時間365日のクラウド稼働を失い、スタック全体のメンテナンス責任を負うことにもなる。ローカル展開を横に置き、以下に示すステアケースは、クラウドベースの推論の現実的な選択肢をカバーする。
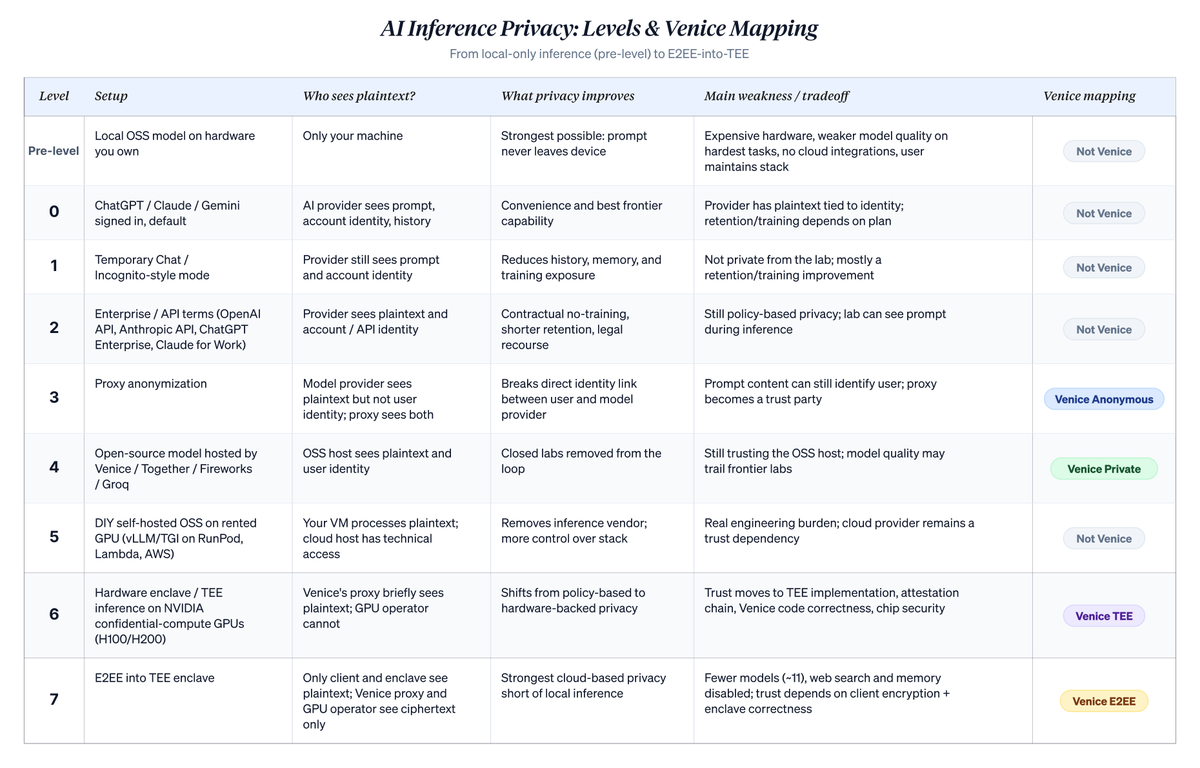
以下に、各レベルの詳細な分解と、それを支える比喩を記載する。
Level 0:「ログイン済みのChatGPT、Claude、Geminiのデフォルト状態」。あなたのプロンプトは、あなたのアカウントに関連付けられた研究所へ送信される。彼らはあなたが誰であるか、そしてあなたが何を尋ねたかを知っている。消費者向けパッケージでは、明示的にオプトアウトしない限り、会話は将来のモデル改善のために使用される可能性があり、サーバー側のチャット履歴に保存される。ここには、データを販売しない、保存期間を限定する、削除コントロールを行うといった、実質的な約束があるが、あなたは識別され、保存され、消費者向けパッケージでは訓練プロセスに組み込まれる可能性もある。大多数のユーザーはこのレベルにいる。アーキテクチャ的には、プロバイダーの所在地に関係なく、あらゆるホスティングAPI消費サービスは同じ姿勢を取る。中国のプロバイダーのホスティングプラン(DeepSeekホスティング版、GLM/智譜、MiniMax、Qwenダイレクト接続)も、同じアーキテクチャ・レベルに位置する:プロバイダーは平文を視認し、身元はアカウントと関連付けられ、保存および訓練方針はプロバイダーごとに異なる。ユーザーは通常、価格を理由にこれらのサービスを選択する。なぜなら、それらはAnthropicやOpenAIに比べてはるかに安価であることが多いからだ。あなたのデータが最終的にどの法域で管理されるかは、具体的なプロバイダー、アクセスするエンドポイント、地域、契約内容によって決まる。モデルが安価だからといって、米国やEU並みのデータ処理が保証されていると想定してはならない。
比喩: あなたは直接、大手企業(AIプロバイダー)のコンサルタント(モデル)に相談に行く。彼らはあなたのメモを読み、質問に答え、その後あなたの名前でコピーをアーカイブする。彼らは、過去のメモの匿名版を他のコンサルタントの訓練やサービスの改善に使うかもしれない。
Level 1:「ChatGPTのテンポラリーチャット/Claudeのインビジブルチャット」。同じプロバイダー、同じ身元、サーバー上で同じ平文である。会話はあなたの履歴には表示されず、モデルはこれを継続的に渡すこともない。ポリシー上、訓練には使われない。アカウントに影響を与えないようなセンシティブなワンタイム会話に有用である。プロバイダーは依然としてあなたが誰であるかを知り、完全なプロンプトを視認するが、長期保存や訓練への使用はできない。自分の履歴からは隠されるが、研究所からは隠されない。
比喩: コンサルタント(モデル)との直接的なやり取りは同じだが、あなたはこの特定のメモをメインファイルから除外するよう依頼する。彼らはそれを読み、回答し、その後「インビジブルチャット」という一時的な引き出しに入れる。一定期間後にクリアされる。彼らは依然としてあなたが誰であるかを知り、あなたが送信した内容も視認している。
Level 2:「Anthropic API、Claude for Work、ChatGPT Enterprise、OpenAI API」。消費者向けチャットから商業的条項への移行。契約により、あなたのデータが訓練に使われることが排除される。保存期間は短く、通常はセキュリティ監査のために約30日間、企業レベルではゼロの場合もある。ポリシー違反に対しては、法的救済手段が与えられる。研究所は推論中に依然として平文を視認し、トラフィックをあなたのAPIキーと関連付けるが、保証はより強く、契約上執行可能である。これは、多くの企業が実際に採用しているプライバシー姿勢であり、消費者向けチャットに対する真のアップグレードである。しかしこれは依然としてポリシーに基づくものであり、アーキテクチャに基づくものではない。さらに上位へと進む理由は現実にある:将来的なポリシー変更、強制的な開示、データ漏洩、あるいは研究所そのものの悪化。
比喩: あなたはコンサルティング会社(企業/API条項)と契約を結び、複製禁止、他顧客との共有禁止、短期間の保存、違反時の法的救済手段などを条項に含める。コンサルタント(モデル)との直接的なやり取りは同じで、彼らはあなたのメモを読み、それが誰から来たかを知るが、メモのその後の扱いに関するルールがより厳格になる。
Level 3:「Veniceの匿名モード」。代理がユーザーと研究所の間に位置し、転送前にあなたの身元を剥ぎ取る。研究所は平文でプロンプトの内容を視認するが、それが誰からのものかは知らない。彼らが視認するのは「Veniceからのリクエスト」である。コンテンツにあなたの身元を特定する要素が含まれていないプロンプトであれば、この手法はあなたのクエリとあなたの名前との関連を断ち切り、研究所の長期的な人物像構築を極めて困難にする。一方、コンテンツにあなたの身元を特定する要素(あなたの会社、取引、名前)が含まれている場合は、これはほとんど表面的なものにすぎない。コンテンツ自体がいずれにせよあなたを暴露してしまうからである。さらに、あなたはVeniceを信頼する当事者として追加することになる。自分でこれを実行することは非現実的である。あなた自身の代理は、あなただけのユーザーであり、単一ユーザーの匿名性は匿名ではない。
比喩: 配送サービス(Venice)が配達を処理する。配送は、コンサルタント(モデル)にメモを渡す前に、そこからあなたの名前を剥ぎ取る。コンサルタントは内容を読むが、誰が送ったかは知らない。配送サービスは双方を知っている。
Level 4:「Together AI/Fireworks/Groq上のオープンソースモデル、またはVeniceのプライベートモード」。オープンソースモデルへと切り替え、閉鎖型研究所はこのトラフィックから完全に外れる。彼らはループにいない。なぜなら、あなたが彼らのモデルを使っていないからだ。信頼は、オープンソースモデルをホスティングする者へと移る。異なるサプライヤーでありながら、同様の契約上の保証を持ち、文化的にプライバシーを重視する傾向がある(特にVeniceのプライベートモード)。能力を若干犠牲にするが、そのギャップは縮小している。GLM 5.1、Qwen 3.6、Minimax M2.7、DeepSeek V4は、日常的なコーディング、ライティング、分析において十分な性能を発揮する。それらがトップクラスのクローズドモデルに匹敵するかどうかは、ベンチマークに大きく依存する。クローズド研究所は、長いコンテキスト処理、マルチモーダルタスク、複雑なエージェントワークフローにおいて依然として優位である。また、集中リスクを低下させ、信頼すべき当事者も少なくなる。これは、Level 3より厳密にプライベートか?それはあなたが何を重視するかによる。Level 3は最先端の研究所からあなたの身元を隠すが、Level 4は小さなプレイヤーにあなたの身元を明かす代わりに、研究所を完全に遮断する。異なる優先順位、異なる順序付けである。これは、実際にオープンソースルーティングを通じて流れるトラフィックにのみ有効である。ミックス使用では、研究所は依然としてあなたが送信した内容を視認する。Level 4内部では、GPU作業が行われる場所についてもプロバイダーによって異なる:Together、Fireworks、Veniceプライベートモードは自社のデータセンターを指定するが、OpenRouterのようなアグリゲーターは、最も安価な下位プロバイダーへとルーティングするため、あなたが選択しなかった法域で動作するプロバイダーを含む可能性がある。この点を重視するユーザー(特定の国へのAPI呼び出しを回避したい)にとって、ホストを指定するオプションと、最も安価なアグリゲーターへとルーティングするオプションは、本質的に異なる。後者は信頼のジャンプポイントを1つ追加する。
比喩: あなたは直接、別のコンサルティング会社(Together AI、Fireworks、Veniceプライベートモードなどのオープンソースモデルホスティング会社)にメモを持っていく。元の会社は何も見えない。なぜなら、あなたが彼らの使用を停止したからだ。新しいコンサルタント(別のモデル)はあなたのメモを読み、それが誰から来たかを知る。以前と同じ直接的なやり取り構造だが、会社が異なるだけである。
Level 5:「DIY:RunPod/Lambda Labs/AWS上のvLLM」。推論即サービス層を完全にスキップする。原始GPUをレンタルし、vLLMまたはTGIを自分でインストールし、重みをロードし、独自のエンドポイントを公開する。推論プロバイダーはあなたのトラフィックを視認せず、あなたの仮想マシンが動作するクラウドホストのハードウェアのみが視認可能である。動機や強制力があれば、クラウドホストは技術的にあなたの仮想マシンをチェックできる。しかし、彼らは小規模な推論サプライヤーよりも、コンプライアンス姿勢、契約上の保護、監査追跡が強い。トレードオフは、小規模サプライヤーのポリシーから、超大規模クラウドプロバイダーのポリシーへと移行することであり、その代償として、実際のエンジニアリングおよび運用作業が発生することである。
比喩: あなたは自分専用のコンサルタント(あなた自身のモデル、セルフホスティング)を雇う。彼は、RunPod、Lambda Labs、AWSなどのクラウドホストからレンタルした仮想マシン(プライベートオフィス)で、あなただけのために働く。中間にコンサルティング会社は存在せず、あなたとあなたが直接雇ったコンサルタントのみである。ビルの所有者(クラウドホスト)は、動機があれば技術的にアクセスできるが、通常は初期のレベルの小規模企業よりも強固なコンプライアンス姿勢を持つ。
Level 6:「Venice TEEモード」。ここでプライバシー保証の性質が変わる。TEEおよびE2EEは、Proサブスクリプションを有するすべてのユーザーに利用可能であり、選択はプランではなくリクエスト単位で行われる。TEE推論では、VeniceはNEAR AI CloudおよびPhala Networkが提供する機密計算技術を搭載したGPUホストへとルーティングする。NVIDIA H100およびH200ハードウェア上で動作する。NEARおよびPhalaはプロトコルおよびツールを提供するが、GPU自体はこの技術を使用する第三者ホストが運営する。GPU上の機密計算機能は、実行時にエンクレーブ内の内容をオペレーターが読み取ることを防止する。リモート証明により、クライアントは内容を送信する前に、エンクレーブ内で実行されるコードを暗号的に検証できるため、「本当にVeniceがリリースしたコードか?」という問いは既に解決済みである。未解決なのは、そのコードの正しさに対する正式な第三者監査である。GPUオペレーターはもはや覗き見可能な当事者ではない。Veniceのプロキシは依然として一時的に平文を視認するが、GPUホストは視認できない。ここでの変化は、ポリシーからハードウェアへの移行である。信頼は消えていない。それは目標を変えただけである。あなたは今、NVIDIAの機密計算設計、証明署名チェーン、Veniceの実装を信頼している。実際の脅威に対しては堅牢であるが、防弾ではない:TEE設計(Intel SGX、AMD SEV)は、繰り返しサイドチャネル脆弱性が発見されており、現在の設計は免疫ではない。この脆弱性研究を密に追跡しているユーザーにとっては、Level 4(信頼できるオペレーターのデータセンター上でのVeniceプライベートモード)が、Level 6よりも理性的な停止地点となるかもしれない。なぜなら、Veniceの運用衛生を信頼する方が、チップベンダーの証明チェーンを信頼するよりも快適だからである。AppleのPrivate Cloud Computeは、ほぼ同じアーキテクチャシリーズに属する:ハードウェア支援によるプライバシーおよび検証可能なプライベートクラウド推論。しかし、Veniceとの違いは現実的である。Appleは自社が制御するApple Siliconを使用し、Apple Intelligenceのみを実行し、モデル選択を公開していない。Veniceは外部TEEパートナーを使用し、オープンソースモデルをサポートし、ユーザーがリクエスト単位でプライバシーレベルを選択できる。
比喩: 配送サービス(Venice)は、あなたのメモを、密封された防音室(NVIDIAの機密計算GPU上のTEE/ハードウェアエンクレーブ、VeniceのパートナーであるNEAR AI CloudおよびPhala Networkが運営)で働くコンサルタント(モデル)へと届ける。配送は途中でメモを読むが、室内のコンサルタントは誰にも観察されず、ビルの所有者(GPUオペレーター)も観察できない。部屋は各セッション後に空にされる。
Level 7:「Venice E2EEモード」。TEEにクライアント側暗号化を追加。暗号化のセットアップは、クライアントとシリコンエンクレーブの間で直接行われる。中間のVeniceプロキシは鍵を一切所有しないため、そこを通過するすべての内容は、あなたのマシンから発信される暗号文であり、シリコン内で処理される瞬間までそうである。GPUオペレーターおよびVenice自体も、覗き見可能な当事者から除外される。平文を処理できる唯一の存在は、エンクレーブ内で実行されるモデルであり、しかもそれは一時的なものである。これは、他人のハードウェア上で利用可能な最強のプライバシー保証であり、完全準同型暗号(現時点ではLLMに実用的な速度で適用できない)を除けば、これ以上のものはない。Level 6のすべての信頼依存関係は継承されるが、それに加えて新たな依存関係が1つ追加される:クライアント側暗号化自体が正しく実装される必要がある。このレベルに特有の2つの機能トレードオフがある。ネットワーク検索や永続的メモリなど、Veniceのインフラストラクチャが平文を読み取る必要がある機能は無効化される。また、モデル選択も狭まる:現在、TEE/E2EEインフラストラクチャ内には、正確に11のモデルが展開されている。Venice Uncensored 1.2、GLM 5.1、GLM 4.7、GLM 4.7 Flash、Qwen3.5 122B A10B、Qwen 2.5 7B、Qwen3 30B A3B、Qwen3 VL 30B A3B、Gemma 3 27B、GPT OSS 20B、GPT OSS 120Bである。
比喩: Level 6のすべては引き続き適用される:コンサルタント(モデル)は密封された防音室内で働き、外からは誰にも観察されず、部屋は各セッション後に空にされる。新たに追加されるのは、あなたが配送(依然としてVenice)に渡す前に、自分でメモを鍵付きの箱(クライアント側暗号化)に入れるということである。配送は今、中身が見えない不透明な箱を運ぶ。そのため、あなたのメッセージを視認できるのは、密封された室内のコンサルタントのみである。
重要なポイント:Level 0〜2は主にポリシーおよび契約のアップグレードである。Level 3〜4はルーティングおよびモデル/サプライヤーの露出を変える。Level 6〜7は、ハードウェア支援および暗号化推論へと移行することで、信頼モデルをより根本的に変える。Veniceの差別化は、単一製品内でLevel 3、4、6、7を横断することにある。
特定のユーザーにとって正しいレベルは、その脅威モデルから導き出される。技術的に最も印象的な仕組みを選ぶことは、要点を捉えていない。Level 6および7は、いくつかの最先端機能を犠牲にし、新たな信頼依存関係を追加する。こうしたコストがあっても、これは今日のクラウド推論で利用可能な最も意味のあるプライバシー向上である。
これがアーキテクチャの動作方法である。より難しい問いは、誰がどのレベルを本当に必要とし、その対象がどれほど大きな市場を形成するかである。異なる脅威モデルは、ユーザーを階段の異なる部分へと押し込むが、それは通常、好んでではなく、むしろ必然的に起こる。その結果として生まれる市場は、技術的な宣伝が示唆するものよりも大きい。以下に分解する。
ユーザー分類
プライバシーの立場は抽象的な好みではない。Veniceの相当数のユーザーは、コンテンツポリシー、コンプライアンスチーム、脅威モデル、あるいは原則によってデフォルトの選択肢から「押し出された」人々である。ユーザーが、もう利用できない代替手段を自ら探すとき、マーケティング活動ははるかに容易になる。検討すべき6つのセグメントを以下に示す。
規制およびコンプライアンス駆動の業務。 大規模な非公開情報を扱う金融チーム、HIPAAに準拠した医療従事者、特権通信を扱う弁護士、M&Aおよび取引プロセスの専門家。コンプライアンスチームは通常、Level 0を許可しない。多くのチームはLevel 2に留まっているように見えるが、これはAnthropicおよびOpenAIの企業向け条項(訓練に使用しない、短期間の保存、契約上の法的救済)が、一般的なコンプライアンスのハードルを満たすためである。一部のチームはLevel 6へと進んでいるが、これは他の場所でポリシー変更によって被害を受けた経験があるか、あるいは強制開示によって実際の損失を被る可能性があるデータを扱っているためである。Anthropicは、このセグメントで相当な企業向けビジネスを確立しているように見える。医療および金融分野の規制動向は、より厳格なプライバシー保護計算の要件へと向かっている。Veniceがこの領域で最も明確な適合点は、現在、個人的な慎重さからProを購入する独立した実務家であり、企業調達の動きではない。企業調達は、プライバシー・アーキテクチャだけでなく、その他多くの要素を求める。コンプライアンスチームは、署名を押す前に、管理コントロール、監査ログ、SOC2レポート、署名済みDPA(データ処理委託契約)、実際のSLA(サービスレベル合意)、統合サポートを要求する。暗号資産の物語は重要だが、それだけでは不十分である。調達主導の企業市場は、Apple PCC、Microsoft Azure Confidential Computing、PhalaまたはNEARが直接競合している。
Venice APIを活用する開発者。 VeniceのAPIは、OpenRouter、Cursor、VSCode、Brave Leo、Fleekなどの開発者向け統合で注目を集めている。最も明確なユースケースは、開発者が自社製品にプライバシーを尊重するAI機能を構築し、エンドユーザーに対して「あなたのデータはプライベートに保たれます」と保証したいというニーズである。レベルのマッピングは、開発者が構築する内容によって異なり得る:コストに敏感な消費者向け機能には匿名モード(Level 3)、デフォルトのOSSルーティングにはプライベートモード(Level 4)、アーキテクチャ上のプライバシーを売りにした製品にはTEEまたはE2EE(Level 6〜7)が該当する。Venice APIを利用する開発者は、エンドユーザー一人一人がVeniceのサブスクリプションを購入する必要なく、多数のエンドユーザーにサービスを提供できる。これは、直接的な消費者向けサブスクリプションとは全く異なる単位当たりの経済性を可能にする。
高リスクな個人的利用。 心理的健康や治療に関する問い合わせがアカウント履歴に残ることを望まない人々。性的指向やジェンダーに関するアイデンティティ探索において、まだ開示する準備ができていないユーザー。婚姻、離婚、雇用、家族のダイナミクスに関する議論は、これらの問い合わせ自体が暴露された場合、害を及ぼす可能性がある。こうしたユーザーの多くはLevel 1に留まり、インビジブルチャットが彼らを隠してくれると思っているかもしれない。プライバシー意識の高いサブセットは、それが研究所に対して完全に隠蔽されないことを理解した後、Level 6へと移行する傾向がある。AIを活用した心理的健康支援は成長中のカテゴリーであり、臨床および消費者向け製品の規模や品質は様々である。Veniceの視点からは、このセグメントの規模を推定するのは難しい。なぜなら、この市場の多くのユーザーは、自分や知人が不都合な出来事を経験するまで、ハードウェア認証付きプライバシーを求める必要性に気づかないからである。
対抗的環境。 情報源を守るジャーナリスト、AI利用を監視する法域に所在する活動家、異見者、政治的組織者、脅威行動者を研究するセキュリティ研究者、告発者を代表する弁護士。こうしたユーザーは通常、Level 6および7を必要とする。低いレベルでは、彼らの脅威モデル下では生存できない可能性がある。Protonを見てみよう:プライバシー重視の評判とスイスの法的管轄地を有していても、受け取った大多数の法的要請には従う傾向がある。これは、スイスの法律がそうすることを義務付けているためである。これは、ポリシーに基づくプライバシーがスケールしたときに遭遇する可能性のある失敗モードである。VeniceのTEEおよびE2EEアーキテクチャは、クラウド設定において、プロバイダーが平文を保持することを設計上意図していないタイプに属する。平文こそが、このような強制的な要請に応じるために必要なものである。しかし、アーキテクチャがどこまで役立つかには限界がある。アカウントのメタデータ、支払いの痕跡、Veniceが記録する利用情報、あなたのノートパソコンが何をしているか、そして裁判所があなたから強制的に取得できるものは、すべてユーザー自身に残る。実際の対抗的脅威モデルを持つ人にとって、これはより広範なツールキットの中の1つのツールにすぎない。数字的には、このセグメントは小さい。訴訟に耐えうるツールに支払う意欲は、通常非常に高い。
暗号資産原生およびプライバシー文化ユーザー。 Web3開発者、主権を重視する技術専門家、自らノードを運営し、ハードウェア認証保証を原則として重んじる人々。このセグメントは、個人の脅威モデルに応じてLevel 3〜7を横断する可能性があり、原則を重んじるサブセットは、通常、センシティブなクエリで6または7をデフォルトで使用する。AI × 暗号資産は、より広範な暗号資産エコシステム内で有意義なカテゴリーとなっており、Bittensorのようなインフラストラクチャ参加者が重要な足場を築いている。業界調査では、中央集権的な支払い監視が懸念される新興市場において、セルフホスティングへの関心がより高いと報告されることが多い。Veniceの立場は、このセグメントとの適合性において、クローズドラボの競合他社が達成できていないものである:VVVによる価格設定、KYCなし、Erik Voorheesの評判、そしてVVVおよびMOR保有者に対する歴史的な無料Proレベルの提供が、このグループの育成に貢献した。Veniceの自然な文化的基盤および最初の有料ユーザーの重要な一部である可能性がある。
成人向けコンテンツおよびクローズドラボが直接拒否するその他のカテゴリー。 OpenAI、Anthropic、Googleは通常、NSFW(不適切な性的コンテンツ)を拒否する。Level 0で妨げられる他のカテゴリーとしては、成熟したクリエイティブライティング、薬物に関するハームリダクションの問題、そして汚名化されているが合法なトピックの長リストがあり、異なるプロバイダーによって異なる対応がなされることがある。こうしたカテゴリーのユーザーは、通常Level 0から始めることができない。モデルは通常、これを拒否する。モデル選択のみでさえ、彼らをLevel 4〜7へと押し上げる。なぜなら、そこが検閲されていないオープンソースのバリエーションが利用可能な場所だからである。大多数の有料ユーザーは日常的な利用ではLevel 4に留まるが、プライバシーに敏感なサブセットは6または7へと進む。このカテゴリーは大きく見える:Character.AIおよびReplikaは、有意義な消費者規模で運営されており、AIによる同伴アプリケーションは、消費者向けAIの顕著なサブセットへと成長している。これらのユーザーは、通常のチャットボットユーザーと比較してプライバシーをより重視する可能性がある。その理由は、暴露のコストである:プロファイルの漏洩は、婚姻、職業、親権裁判を台無しにする可能性があるからである。Veniceの現在の最大の按量課金ユーザー層である可能性がある。
これらのグループに共通して目立つ点は、彼らの多くがファネルのトップにいるわけではないということである。大多数は、コンテンツポリシー、コンプライアンスチーム、脅威モデル、または原則によって、容易なパスから「強制的に」または「押し出されて」形成されたように見える。プライバシー優先のAIは、通常、人々が最初に訪れるカテゴリーではない。彼らは、元の場所に留まれないと気づいた後に到達するのである。同様の論理で、規模の推定はしないが、標識を付けておくべき2つの隣接するセグメントを説明できる:所在法域が彼らを中央集権的な支払いおよびAI監視から遠ざける国際的なユーザー、および早期の個人AIエージェント群(そのオーケストレーションデータは、プライバシーを尊重するバックエンドから恩恵を受けることができる)である。
市場規模
Veniceの最終的な上限は、現在の実行状況ではなく、アドレス可能な市場の規模に依存する。正しいフレームワークは「推論シェア」である:VeniceはAI推論サービスを販売しており、関連市場は世界の推論支出であり、Veniceの収益はそのプールの一部である。
2027年の推論市場に関する独立した見積もりは、世界規模で1400〜1600億ドルに収斂しており、ベイン、IDC、マッキンゼーの予測はおおむねこの範囲内にある。Veniceの予測(本稿の評価セクションで展開)である2027年末の年率4億ドルの運用率であっても、Veniceはそのプールの0.3%未満に過ぎず、あらゆる妥当な市場定義において微々たるシェアである。参考までに、OpenAIのAPI事業だけで、現在の推論支出の一位数パーセントを占めると推定されており、AnthropicのAPIも同程度の範囲にある。Veniceの現在の位置は、中規模の推論プラットフォームが占めるシェアをはるかに下回っている。
しかし、Veniceはこのプール全体を奪おうとしているわけではない。Veniceのターゲットは、プライバシーに特化したセグメントである:匿名性、ハードウェア認証プライバシー、検閲されていないアクセス、または推論過程における法域選択を必要とするユーザーおよび企業である。このサブセットの規模を正確に計算するのは難しいが、方向性のシグナルは明確である。
推論のプライバシー・セグメントを拡大させる力がいくつか存在する:欧州およびアジアの一部地域におけるデータ滞在規制の強化、企業とデフォルトのクローズドラボ製品との間のコンプライアンス摩擦の増大、TEEに基づくプライバシー・インフラストラクチャの成熟である。企業調査では、AI駆動のデータ暴露に対する懸念が高まっていることが継続的に指摘されている。これらの力は個別には速くないが、重畳する。
仮にプライバシー・セグメントのクラウド推論市場が、2027年の1400〜1600億ドルの推論市場の5〜15%に過ぎないとしても、それは70〜230億ドルの市場である。一桁のシェアでさえ、Veniceを数億ドルの収益へと導き、現在の運用率をはるかに上回り、さらなる成長余地を残す。中一桁のシェアであれば、Veniceは10億ドルを超える範囲に入る。
悲観的なシナリオには3つの次元がある。第一に、プライバシー・セグメントのクラウド推論市場が、意味のある規模に達しない可能性がある。なぜなら、超大規模クラウドプロバイダーが既存のプラットフォーム内で十分なプライバシー・オプションを提供するからである。Apple PCC、Azure Confidential Computing、AWS Bedrockの秘密推論は、すべてこの方向に向かっている。この場合でもプライバシーは重要であるが、それは既存のクラウドおよび消費者向けプラットフォームにパッケージ化されるため、独立したプライバシー優先市場は、独立したプレイヤーを支えるほど大きくなることは決してない。
第二に、ローカル推論が主流ユーザーにとって実現可能になることである。オープンソースモデルの品質は、大多数の日常的なワークロードに対してすでに十分に強い。ボトルネックは、ローカルモデルを実行するために必要なセットアップの煩雑さと技術スキルである。このボトルネックが、より洗練された開箱即用ソリューション、より簡単なインストール手順、運用負担を処理する統合によって緩和されるにつれ、プライバシーを重視するユーザーの相当な割合が、任意のクラウドサービスに支払う代わりにローカルで推論を実行することを選択する可能性がある。これにより、彼らは完全にVeniceのアドレス可能な市場から除外されることになる。この懸念のタイミングは、消費者向けに使いやすいローカルスタックが成熟する速度に依存する。
第三に、プライバシー市場が意味のある規模で実現したとしても、VeniceはBrave Leo、DuckDuckGo、ProtonのLumo、Maple、Tinfoilなどの他のプライバシー原生プレイヤーとの競争においてシェアを勝ち取る必要がある。これらはそれぞれ、Veniceのバンドルのさまざまな部分を異なる角度から狙っている。競争環境のセクションでは、Veniceのプライバシーの深さ・検閲されていないアクセス・暗号資産原生の配信の組み合わせが、これらの特定の脅威とどのように比較されるかを議論する。
競争環境
Veniceの競合集合は、「他のプライベートAIアプリケーション」という範囲をはるかに超える。異なるプラットフォームが、同じニーズを競い合う:プライバシーを重視する消費者、モデル選択を望む開発者、検閲されていないコンテンツを求める者、暗号資産原生の買い手。以下のセクションでは5つのカテゴリーをカバーする。
この環境は、部分的な代替品が異なる角度からVeniceの楔を引っ張るものである。BraveおよびDuckDuckGoは配信を競い、OpenRouterは開発者向けAPIを競い、Tinfoil、NEAR、Phala、Mapleはプライバシー・アーキテクチャそのものを競い、最先端のラボは企業向けに、十分なプライバシーを備えた優れたモデルを埋め込んでいる。これらの製品のうち、Veniceの完全なバンドル(デフォルトでプライベートな消費者向けAI、検閲されていないアクセス、マルチモデル選択、暗号資産原生の支払い、トークン化された利用経済)をパッケージ化しているものは存在しない。
プライバシーのレベルを、最も弱いものから最も強いものまで区別することが重要である:
訓練なし:プロバイダーがユーザーのデータを訓練に使用しないと約束(標準的なAnthropicおよびOpenAI API条項)
限定的またはゼロ保存:プロバイダーは、悪用監視のためにプロンプトを一時的に保存するか、またはZDR(Zero Data Retention)設定を提供し、処理後にプロンプトおよびレスポンスの内容を保存しない(OpenAI ZDR、OpenRouter ZDR)
匿名プロキシ:プロバイダーはプロンプトを視認するが、身元は視認しない(Venice Anonymous、Brave Leo、DuckDuckGo AI Chat)
TEE/ハードウェア認証:プロンプトは、オペレーターが読み取ることのできないエンクレーブ内で実行される(Venice TEE、Tinfoil、NEAR Private Chat、Apple PCC)
E2EEによるTEEへのアクセス:プロバイダーは暗号文のみを視認(Venice E2EE、Maple AI)
ローカル:モデルがユーザー自身のハードウェア上で実行される(Ollama、LM Studio)
Veniceは、匿名プロキシ、プライベートチャット、TEE、E2EEモードを、単一の消費者向け体験内で横断する、少数の消費者向け製品の一つであり、ユーザーはリクエスト単位でモードを選択できる。
デフォルトAIプラットフォーム(OpenAI、Anthropic、Google、xAI)
最先端のラボは、企業向けに真のプライバシーを提供している。OpenAIは、APIまたは商用データをデフォルトで訓練に使用せず、条件を満たす顧客にはZDR設定を提供している。Anthropicは、商用製品の入力または出力を訓練に使用しない。Google Vertex AIは、企業向けの訓練制限を提供している。xAIもユーザーのプライバシー制御を宣伝しているが、その姿勢は、OpenAI、Anthropic、Googleのより成熟した企業向け約束とは区別して扱うべきである。Veniceと企業およびAPIプライバシーのギャップは、多くの人が想定するよりも狭く、消費者向けの匿名性のギャップは依然として非常に大きい。消費者向けChatGPT、Claude、Geminiは、デフォルトで身元とプロンプトを紐付け、サーバー側のチャット履歴を保存しており、訓練使用に関するポリシーは製品およびユーザー設定によって異なる。
Veniceは、最先端のラボが行わないことを追求している:匿名アクセス、検閲されていないモデル、暗号資産原生の支払いである。この市場は主流のAIよりも小さいが、現実に存在する。最先端のラボは、大多数の一般ユーザーをサービスしている。Veniceは、デフォルトのオプションから抜け出したい一部のユーザーをサービスしている。
セグメントごとに見てみよう:
消費者向けチャット:Veniceは匿名性、より少ないパターナリズム的なコンテンツ、暗号資産支払いを提供する。ラボは能力とブランドで勝っている。
プロフェッショナル消費者:Veniceはモデル選択とより少ないロックインを提供する。ラボはコーディング統合、メモリ、ツールで勝っている。
企業:現在、SOC2、DPA、管理コントロール、監査ログを備えたVeniceのストーリーはない。ラボおよび超大規模クラウドプロバイダーがこの市場を支配している。
API:Veniceはプライバシーの深さと検閲されていないアクセスを提供する。ラボはモデルの品質とエコシステムで勝っている。
プライバシー原生の配信面(Brave、DuckDuckGo)
Braveは、プライバシー分野で最も強力な消費者向け配信戦略である。Braveは、2026年4月時点で1.15億人を超える月間アクティブユーザーと4,700万人の日間アクティブユーザーを報告しており、Leo Premiumは月額14.99ドルで、無料のレベルも提供している。Leoはアカウントの選択が可能で、履歴はローカルに保存され、Braveの公式ポリシーによれば、Braveサーバー上にはプロンプトを保存しない。Braveはまた、NEAR AIのNVIDIA対応TEEを介して、プロキシプライバシーから検証可能なプライバシーへと移行し始め、ハードウェア支援のAIプライバシーが主流の製品機能になりつつあることを強化している。
DuckDuckGo AI Chatは、姿勢が類似している:無料、アカウント不要、OpenAI、Anthropic、Metaなど、ローテーションする第三者モデルへの匿名プロキシ。DuckDuckGoは、チャットは保存されず、訓練に使用されないと述べている。Duck.aiには現在、より高度なモデルを提供する有料レベルもある。
ProtonのLumoは、この分野における第3の有意義なプレイヤーである。Lumoは2025年7月にリリースされ、2026年1月にはプロジェクトベースの暗号化ワークスペースを介して拡張された。これはゼロアクセス暗号化AIアシスタントを提供し、サーバー側のログを保持せず、ユーザーのデータを訓練に使用しない。LumoはProtonの欧州拠点で運営されており、米国の管轄下にはなく、メール、VPN、クラウドストレージ製品を含む、既存のプライバシー重視のProtonユーザー層をターゲットとしている。Veniceと比較して、Lumoのモデル選択は狭く、最先端のクローズドラボモデルはなく、検閲されていないコンテンツもなく、暗号資産原生の配信もない。しかし、Protonはプライバシー重視のユーザーにおけるブランドを確立しており、Veniceのブランドは、現在のセグメント以外で認められるようになるには、まだ努力が必要である。
Brave、DuckDuckGo、Lumoが危険なのは、それらがコンバージ
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News









