

Xの新アルゴリズムがオープンソース化、一体どのようなコンテンツがより人々を引きつけるのか?
TechFlow厳選深潮セレクト
Xの新アルゴリズムがオープンソース化、一体どのようなコンテンツがより人々を引きつけるのか?
いいねはほとんど価値がなく、対話型のやり取りこそが真の通貨である。
筆者:David、TechFlow
1月20日午後、Xは新しい推薦アルゴリズムのコードをオープンソース化した。
Musk氏が付け加えた返信も興味深いものだった。「このアルゴリズムがまだ愚かであることを我々は承知している。大幅な改善が必要だ。だが少なくとも、我々がリアルタイムで必死に改良しようとしている様子を、あなたには見せている。他のSNSプラットフォームならこんなことは絶対にしないだろう」
この発言には二つの意味がある。一つはアルゴリズムに問題があると認めるということ。もう一つは「透明性」を売りにするということだ。
これはXがアルゴリズムを公開した二度目のことだ。2023年に公開されたバージョンのコードは3年間更新されず、実際のシステムとはすでに乖離していた。今回、完全に再構築され、コアモデルは従来の機械学習からGrokのtransformerへと置き換えられた。公式によれば、「手作業による特徴量設計(hand-engineered feature)を完全に排除した」という。
人間にわかる言葉に言い換えると:以前はエンジニアが手動でパラメータを調整していたが、今ではAIがユーザーの行動履歴を見て、そのままあなたのコンテンツを表示するかどうかを判断するようになった。
コンテンツ制作者にとっては、これまでの「何時に投稿するのがベストか」「どのタグを使えばフォロワーが増えるか」といったノウハウが、もはや通用しなくなるかもしれないということだ。
我々もGitHubのリポジトリを確認し、AIの支援を得てコードを分析したところ、いくつかの明確なロジックが確かに存在することがわかった。以下、詳しく解説する。
アルゴリズムの変化:手作業からの脱却、AIによる自動判断へ
まず新旧バージョンの違いを明確にしておこう。そうでなければ以降の議論が混乱する。
2023年にTwitterがオープンソース化したのは「Heavy Ranker」と呼ばれるもので、本質的には従来型の機械学習だった。エンジニアが数百個の「特徴量(feature)」を手動で定義する必要があった:この投稿に画像はあるか、投稿者のフォロワー数はどれくらいか、いつ投稿されたか、リンクを含んでいるか……など。
そして各特徴量に重みを設定し、どの組み合わせが最も効果的かを調整していく。
今回公開された新版は「Phoenix」と呼ばれ、アーキテクチャが全く異なる。つまり、より大規模なAIモデルに依存するタイプのアルゴリズムであり、その中核はGrokのtransformerモデルである。ChatGPTやClaudeと同じ技術体系にある。
公式のREADMEには率直に書かれている。「We have eliminated every single hand-engineered feature.(すべての手作り特徴量を排除した)」
従来の、内容から特徴を人手で抽出するルールは、すべて撤廃された。
では現在、このアルゴリズムは一体何を基準に「良いコンテンツ」かどうかを判断しているのか?
答えはユーザーの行動系列(behavior sequence)だ。過去に誰の投稿にいいねをしたか、誰に返信したか、どの投稿に2分以上滞在したか、どのアカウントをブロックまたはミュートしたか――Phoenixはこうした行動データをtransformerモデルに入力し、モデル自身がパターンを見つけ出し、法則を学習する。
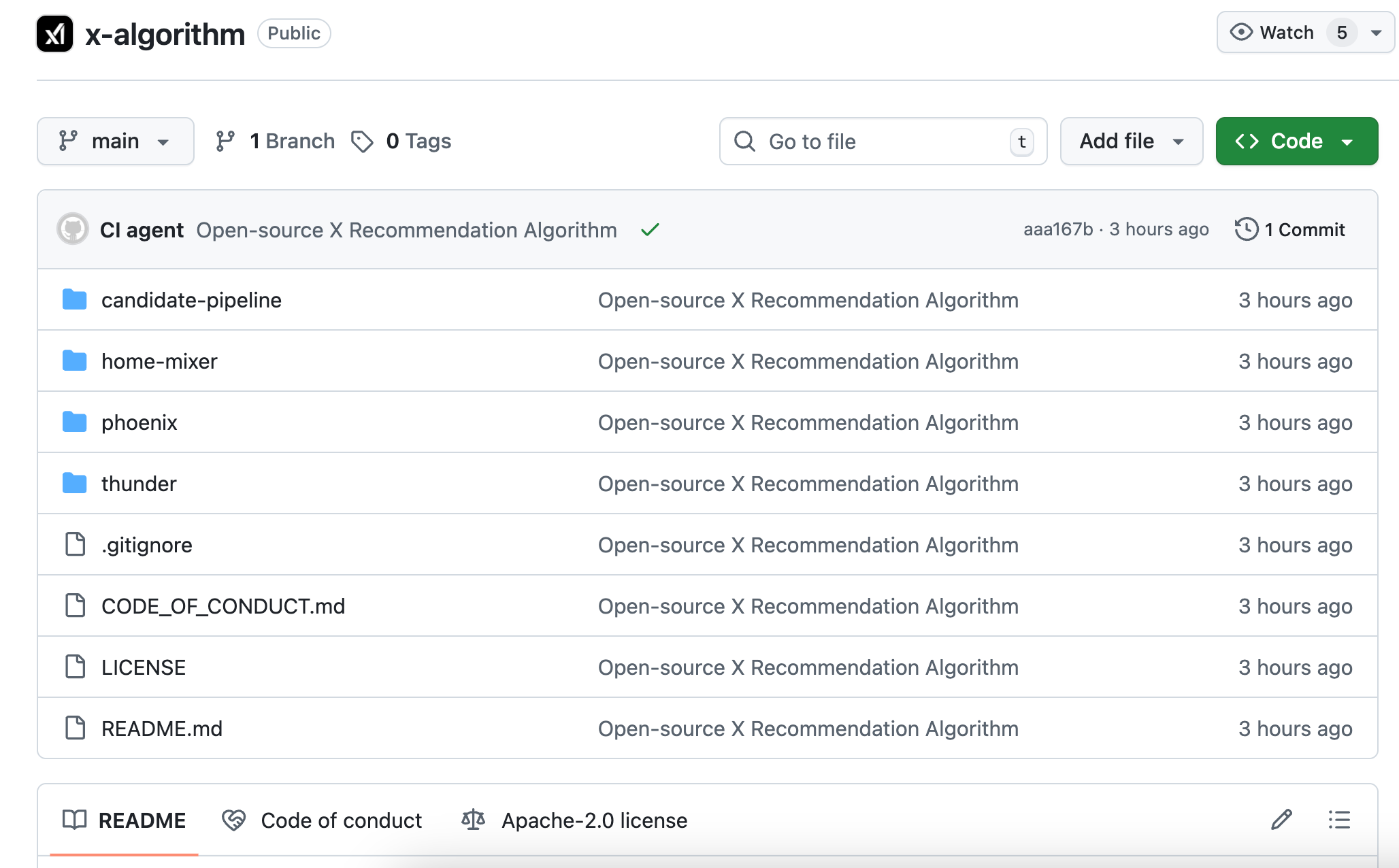
たとえるなら、旧アルゴリズムは人間が作ったチェックリスト式の採点表であり、項目ごとに得点を付けて合計する。
一方、新アルゴリズムはあなたのすべての閲覧履歴を読破したAIが、次に何を見たいかを直接予測するようなものだ。
クリエイターにとって、これは二つの重要な意味を持つ。
第一に、「最適な投稿時間」「黄金タグ」などのテクニックは、参考価値が低下する。 なぜならモデルはもはや固定的な特徴を見ていなくて、各ユーザーの個人的な好みを重視するからだ。
第二に、あなたのコンテンツが拡散されるかどうかは、「あなたの投稿を見た人がどう反応するか」にますます依存するようになる。 この反応は15種類の行動予測に数値化されており、次の章で詳しく説明する。
アルゴリズムはあなたの15種類の反応を予測している
Phoenixは、おすすめ候補となる投稿を受け取った後、現在のユーザーがその投稿に対して起こす可能性のある15種類の行動を予測する。
- 肯定的行動: いいね、返信、リツイート、引用リツイート、投稿クリック、プロフィールクリック、動画の半分以上視聴、画像展開、共有、一定時間以上の滞在、フォロー
- 否定的行動: 「興味なし」クリック、作者のブロック、作者のミュート、通報
それぞれの行動に対して、予測確率が割り当てられる。例えば、この投稿に60%の確率でいいねする、5%の確率でこの作者をブロックする、といった具合だ。
その後、アルゴリズムは単純な処理を行う:各確率にそれぞれの重みを掛け、合計して総合スコアを算出する。
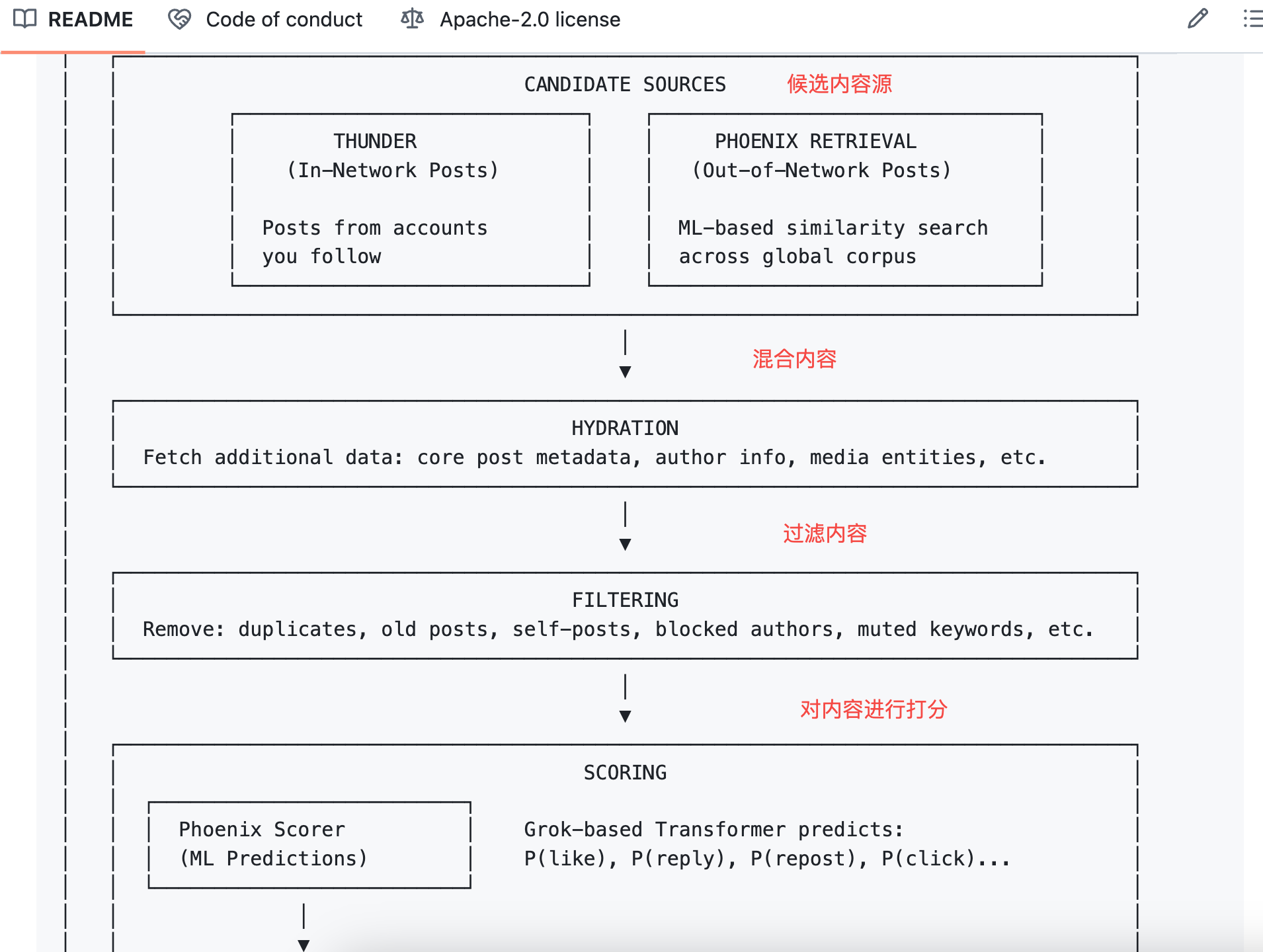
計算式は以下の通り:
最終スコア = Σ (重み × P(行動))
肯定的行動の重みは正の値、否定的行動の重みは負の値である。
総合スコアが高い投稿ほど上位に表示され、低いものは下に沈む。
数式を離れて考えると、要するにこうなる:
今やコンテンツの良し悪しは、文章が上手く書けているかどうかでは決まらない(もちろん読みやすさや利他性は拡散の基礎条件だが)。むしろ「そのコンテンツがあなたにどんな反応を引き出すか」によって決まる。アルゴリズムは投稿そのものの品質には関心がなく、関心があるのはあくまであなたの行動なのだ。
極端な場合を考えれば、低俗だがついついコメントで批判してしまうような投稿の方が、高品質なのに誰も反応しない投稿よりも高いスコアを得る可能性がある。このシステムの根本的なロジックはおそらくそこにある。
ただし、今回公開された新バージョンのアルゴリズムでは、具体的な行動の重みの数値は非公開だ。しかし2023年の旧版では公開されていた。
旧版の参考値:通報1回 = いいね738回
ここからは2023年のデータを分析してみよう。古い情報ではあるが、アルゴリズムが各行動をどのように「価値あるもの」と見なしているかを理解する上で非常に参考になる。
2023年4月5日、XはGitHub上で一連の重みデータを実際に公開していた。
数字だけ示す:
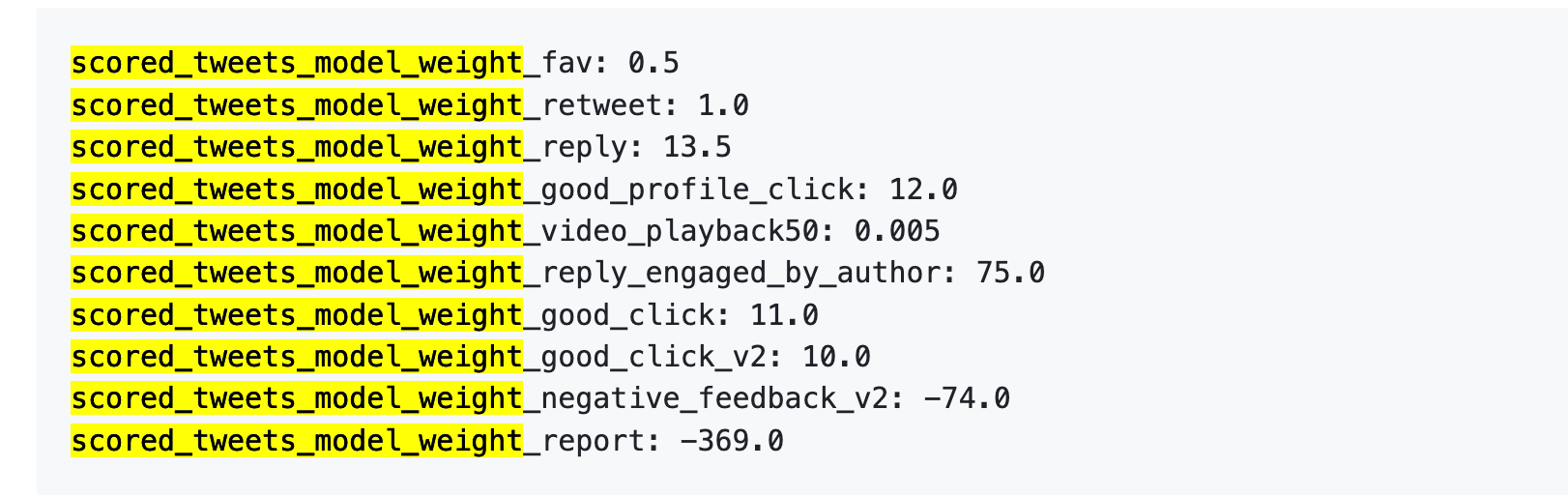
さらにわかりやすく翻訳すると:

データ元:旧版 GitHub twitter/the-algorithm-ml リポジトリ、クリックでオリジナルアルゴリズムを確認可能
注目すべき数字がいくつかある。
第一に、「いいね」はほとんど価値がない。 重みはわずか0.5で、すべての肯定的行動の中で最低。アルゴリズム的には、いいね1回の価値はほぼゼロと見なされている。
第二に、双方向のやり取りこそが真の価値を持つ。 「あなたが返信し、作者がそれに返信する」という行動の重みは75で、いいねの150倍。アルゴリズムが最も望んでいるのは一方的な称賛ではなく、往復の会話なのである。
第三に、否定的フィードバックの代償は非常に大きい。 ブロックまたはミュート1回(-74)を相殺するには、148回のいいねが必要。通報1回(-369)を相殺するには、738回のいいねが必要だ。しかもこれらの減点はアカウントの信頼スコアに累積され、今後のすべての投稿の配信に影響を与える。
第四に、動画の再生完了率の重みが異常に低い。 たった0.005で、事実上無視できるレベル。これは抖音(ドウイン)やTikTokと鮮明な対比を成しており、後者のプラットフォームでは再生完了率が最も重要な指標の一つとなっている。
公式文書には同じく記載されている。「ファイル内の正確な重みはいつでも調整可能…以来、我々は定期的に重みを調整し、プラットフォームの指標最適化を図ってきた」
重みはいつでも変更され得るし、実際に変更されてきた。
新バージョンでは具体的な数値は非公開だが、READMEに記述されたロジックの枠組みは同じ:肯定的行動は加点、否定的行動は減点、加重合計。
正確な数字は変わっているかもしれないが、数量級の関係性はおそらく維持されている。つまり、他人のコメントに返信することは、100個のいいねをもらうよりも効果的だ。また、ユーザーに「ブロックしたい」と思わせる行為は、誰も反応されないよりもはるかに悪い。
これを踏まえて、クリエイターができること
新旧両方のアルゴリズムコードを分析し、総合的に考察した結果、実践可能ないくつかの結論を導き出した。
1. コメントに返信する。 重み表において「作者がコメントに返信する」は最高得点(+75)であり、ユーザーの一方的ないいねの150倍の価値がある。コメントを求める必要はないが、コメントがあれば必ず返信すること。たとえ「ありがとう」と一言でも、アルゴリズムはそれを記録する。
2. ユーザーにスクロールアウトさせない。 1回のブロックによるネガティブな影響を相殺するには148回のいいねが必要。議論を呼びやすいコンテンツは確かにエンゲージメントを生むが、その反応が「うざいからブロック」であれば、アカウントの信頼スコアは持続的に損なわれ、今後のすべての投稿の配信に悪影響を及ぼす。炎上系のトラフィックは両刃の剣であり、他人を斬る前に自分を傷つける。
3. 外部リンクはコメント欄に掲載する。 アルゴリズムはユーザーを外部サイトへ流出させることを好まない。本文にリンクを入れると評価が下がる。これはMusk氏自身も公に述べている。外部導線を張りたい場合は、本文でコンテンツを提供し、リンクは最初のコメントに記載する。
4. スパム投稿は避ける。 新版コードには「Author Diversity Scorer(投稿者多様性スコア)」があり、同一著者の連続投稿に対して評価を下げる機能がある。意図としてはユーザーのフィードを多様化することだが、副作用として「10回連続投稿するよりも、1回の良質な投稿の方が効果的」という結果になる。
6. 「最適な投稿時間」はもはや存在しない。 旧アルゴリズムには「投稿時刻」という人工特徴量があったが、新版では即座に削除された。Phoenixはユーザーの行動系列のみを見るため、投稿が何時にされたかは関係ない。つまり「火曜日の午後3時がベスト」といった攻略法の参考価値はますます低下している。
以上はコードから読み取れる内容である。
その他にも、Xの公開ドキュメントに基づく加点・減点要素があるが、これらは今回のオープンソースリポジトリには含まれていない:ブルーバッジ認証にはボーナスがある、すべて大文字の投稿は減点、センシティブコンテンツは到達率が80%カットされる、など。これらのルールは非公開のため、ここでは詳述しない。
まとめると、今回のオープンソース化はかなり実質的だ。
システム全体のアーキテクチャ、候補コンテンツのリコールロジック、ランキングスコアの計算プロセス、各種フィルターの実装方法――すべてが含まれている。コードの主な言語はRustとPythonで、構造は明確であり、READMEの記述は多くの商用プロジェクトよりも詳細だ。
ただし、いくつかの重要な要素は公開されていない。
1. 重みパラメータが非公開。 コード内には「肯定的行動は加点、否定的行動は減点」としか書かれておらず、いいね1回が何点か、ブロックが何点引かれるかは明記されていない。2023年版では少なくとも数値が公開されていたが、今回は計算式の枠組みのみ。
2. モデルの重みが非公開。 PhoenixはGrokのtransformerを使用しているが、モデル自体のパラメータは公開されていない。呼び出し方法は見えるが、内部の計算プロセスは見えない。
3. 学習データが非公開。 モデルの学習に使われたデータ、ユーザー行動のサンプリング方法、正例・負例の構築方法などについては一切言及されていない。
たとえるなら、今回のオープンソース化は「加重合計で総合スコアを算出している」と教えてくれるが、重みの具体的数値は教えてくれない。また「transformerで行動確率を予測する」とは言うが、transformerの中身は見せてくれない。
横並びで比較すれば、TikTokやInstagramはこのような情報を一度も公開したことがない。Xが今回公開した情報量は、確かに他の主要プラットフォームよりも多い。ただ、「完全な透明性」まではまだ届いていない。
だからといって、オープンソース化に価値がないとは言えない。クリエイターにとっても研究者にとっても、コードが見られるという事実は、見られないよりもはるかに有益なのである。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














