
黄仁勋 CES2026 最新講演:三つの重要トピック、一台の「チップモンスター」
TechFlow厳選深潮セレクト
黄仁勋 CES2026 最新講演:三つの重要トピック、一台の「チップモンスター」
物理AIが継続的に思考し、長期間稼働し、現実世界に真に進出するとき、問題はもはや計算力が十分かどうかではなく、誰がシステム全体を実際に構築できるかという点に移ります。
著者:李海倫 蘇揚
北京時間 1月6日、NVIDIA CEO ジェンスン・ホアン(黄仁勲)がトレードマークの革ジャンを着て、再びCES2026のメインステージに立った。
2025年のCESでは、NVIDIAは量産化されたBlackwellチップと完全な物理AI技術スタックを披露した。会議で、ホアン氏は「物理AIの時代」が幕を開けつつあると強調。自律走行車が推論能力を備え、ロボットが理解し思考し、AIエージェントが百万トークン級の長文脈タスクを処理できる、想像力に満ちた未来を描いた。
あっという間に一年が過ぎ、AI業界は大きな変革と進化を経験した。ホアン氏は発表会でこの一年の変化を振り返り、特にオープンソースモデルに言及した。
彼は、DeepSeek R1のようなオープンソース推論モデルが、業界全体に気づかせたと述べた:開放とグローバルな協業が本当に始動すれば、AIの普及速度は極めて速くなる。オープンソースモデルは総合能力において最先端モデルより約半年遅れているが、6ヶ月ごとに追い上げ、ダウンロード数と使用量は爆発的に増加している。

2025年がよりビジョンと可能性を示したのに対し、今回はNVIDIAは体系的に「実現方法」の問題解決を目指し始めた:推論型AIを中心に、長期間稼働に必要な計算力、ネットワーク、ストレージインフラを補完し、推論コストを大幅に削減し、これらの能力を自律走行やロボットなどの実世界シナリオに直接埋め込む。
今回のCESにおけるホアン氏の講演は、三つの主軸を中心に展開された:
●システムとインフラストラクチャレベルでは、NVIDIAは長期的な推論ニーズに応じて計算力、ネットワーク、ストレージアーキテクチャを再構築した。Rubinプラットフォーム、NVLink 6、Spectrum-Xイーサネット、推論コンテキストメモリストレージプラットフォームを中核とし、これらの更新は推論コストの高さ、コンテキストの持続困難、スケーリング制限などのボトルネックに直撃し、AIが「もう少し考え、計算でき、長く稼働する」問題を解決する。
●モデルレベルでは、NVIDIAは推論型AI(Reasoning / Agentic AI)を中核に置いた。Alpamayo、Nemotron、Cosmos Reasonなどのモデルとツールを通じて、AIを「コンテンツ生成」から持続的思考が可能なものへ、「一回限り応答のモデル」から「長期間作業可能なエージェント」へと推進する。
●アプリケーションと実装レベルでは、これらの能力が自律走行やロボットなどの物理AIシナリオに直接導入される。Alpamayo駆動の自律走行システムであれ、GR00TとJetsonのロボットエコシステムであれ、クラウドプロバイダーやエンタープライズプラットフォームとの協業を通じて、スケーラブルなデプロイを推進している。

01 ロードマップから量産へ:Rubin、初めて完全な性能データを開示
今回のCESで、NVIDIAは初めてRubinアーキテクチャの技術詳細を完全に開示した。
講演で、ホアン氏はTest-time Scaling(推論時スケーリング)から話を始めた。この概念は、AIを賢くするには、もはや「より多くの努力で勉強させる」だけでなく、「問題に遭遇した時にもう少し考えさせる」ことによると理解できる。
過去、AI能力の向上は主にトレーニング段階でより多くの計算力を投入し、モデルを大きくすることに依存していた。現在、新しい変化は、モデルがこれ以上大きくならなくても、使用する度に少し余分な時間と計算力を与えて考えさせれば、結果も明らかに良くなることだ。
「AIにもう少し考えさせる」ことを経済的に実現可能にするには? Rubinアーキテクチャの次世代AIコンピューティングプラットフォームがこの問題を解決する。
ホアン氏は、これは完全な次世代AIコンピューティングシステムであり、Vera CPU、Rubin GPU、NVLink 6、ConnectX-9、BlueField-4、Spectrum-6の協調設計を通じて、推論コストの革命的な低下を実現すると紹介した。

NVIDIA Rubin GPUはRubinアーキテクチャにおいてAI計算を担当する中核チップで、推論とトレーニングの単位コストを大幅に削減することを目指す。
端的に言えば、Rubin GPUの中核任務は「AIをもっと安く、賢く使えるようにする」ことだ。
Rubin GPUの中核能力は:同一のGPUでより多くの作業ができる。一度により多くの推論タスクを処理し、より長いコンテキストを記憶し、他のGPUとの通信もより速い。これは、多くの元々「複数GPUを無理に積み上げる」必要があったシナリオが、より少ないGPUで完了できることを意味する。
結果として、推論はより速くなるだけでなく、明らかに安くなる。
ホアン氏は現場でRubinアーキテクチャのNVL72ハードウェア仕様を復習した:220兆個のトランジスタを含み、帯域幅260 TB/秒で、業界初のラックスケール機密計算をサポートするプラットフォームである。

全体として、Blackwellと比較し、Rubin GPUは主要指標で世代を超えた飛躍を実現:NVFP4推論性能は50 PFLOPS(5倍)に向上、トレーニング性能は35 PFLOPS(3.5倍)に向上、HBM4メモリ帯域幅は22 TB/s(2.8倍)に向上、単一GPUのNVLink相互接続帯域幅は倍増して3.6 TB/sとなった。
これらの向上が共同で作用し、単一GPUがより多くの推論タスクとより長いコンテキストを処理できるようになり、GPU数の依存を根本的に減少させる。

Vera CPUはデータ移動とAgentic処理のために設計された中核コンポーネントで、88個のNVIDIA自社開発Olympusコアを採用し、1.5 TBのシステムメモリ(前世代Grace CPUの3倍)を備え、1.8 TB/sのNVLink-C2C技術によりCPUとGPU間の一貫性メモリアクセスを実現する。
従来の汎用CPUとは異なり、VeraはAI推論シナリオにおけるデータスケジューリングと多段階推論ロジック処理に特化し、本質的に「AIにもう少し考えさせる」ことを効率的に実行させるシステムコーディネーターである。
NVLink 6は3.6 TB/sの帯域幅とネットワーク内計算能力により、Rubinアーキテクチャ内の72個のGPUが一つのスーパーGPUのように協調作業できるようにし、推論コスト削減を実現する鍵となるインフラストラクチャである。
これにより、AIが推論時に必要とするデータと中間結果はGPU間を迅速に流転し、繰り返し待機、コピー、再計算する必要がなくなる。


Rubinアーキテクチャでは、NVLink-6がGPU内部の協調計算を担当し、BlueField-4がコンテキストとデータスケジューリングを担当し、ConnectX-9はシステム対外の高速ネットワーク接続を担う。これはRubinシステムが他のラック、データセンター、クラウドプラットフォームと効率的に通信できることを保証し、大規模トレーニングと推論タスクが円滑に実行される前提条件である。
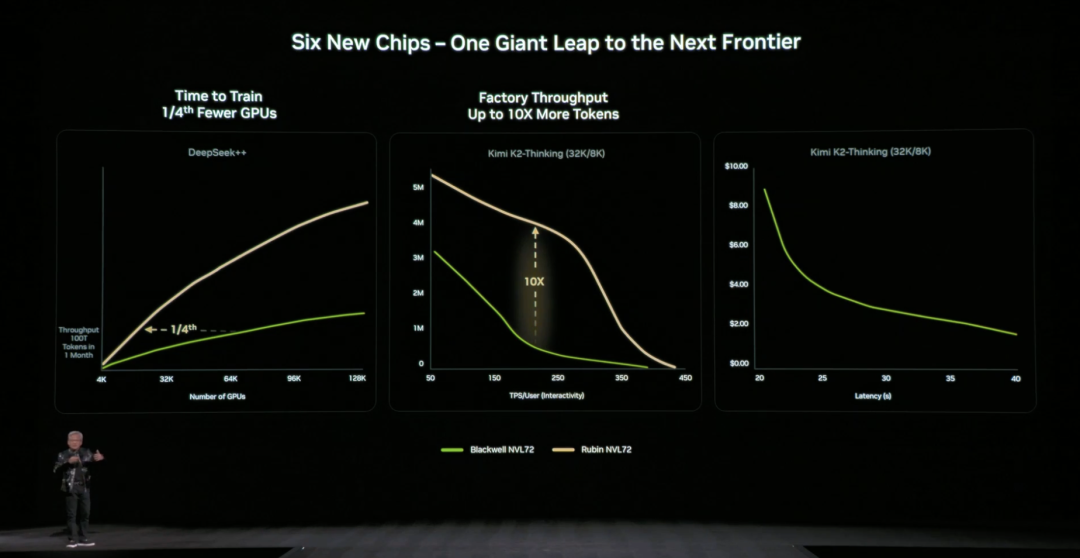
前世代アーキテクチャと比較し、NVIDIAは具体的で直観的なデータも提示:NVIDIA Blackwellプラットフォームと比較し、推論段階のトークンコストを最大10倍削減し、混合専門家モデル(MoE)のトレーニングに必要なGPU数を元の1/4に削減できる。
NVIDIA公式は、現在マイクロソフトが次世代Fairwater AIスーパーファクトリーに数十万個のVera Rubinチップをデプロイすることを約束し、CoreWeaveなどのクラウドサービスプロバイダーが2026年後半にRubinインスタンスを提供すると表明、この「AIにもう少し考えさせる」インフラストラクチャは技術デモからスケーラブルな商用化へ向かっている。

02 「ストレージボトルネック」はどう解決する?
AIに「もう少し考えさせる」には、もう一つの重要な技術的課題に直面する:コンテキストデータはどこに置くべきか?
AIが多輪対話、多段階推論を必要とする複雑なタスクを処理する時、大量のコンテキストデータ(KVキャッシュ)が生成される。従来のアーキテクチャは、それらを高価で容量が限られたGPUメモリに詰
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














