

図解:DeepSeek R1 はどのようにして開発されたのか?
TechFlow厳選深潮セレクト
図解:DeepSeek R1 はどのようにして開発されたのか?
DeepSeekが発表した技術報告書に基づき、DeepSeek - R1の訓練プロセスを解説する。
著者:江信陵,為AI発電

画像出典:無界AIにより生成
TechFlowはR1推論モデルをどのように訓練したのか?
本稿は主にTechFlowが発表した技術レポートに基づき、TechFlow-R1の訓練プロセスを解説するものである。特に、推論モデルの構築と性能向上における4つの戦略について重点的に考察する。
原文は研究者Sebastian Raschkaによるもので、以下に掲載されている:
https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
本稿ではその中でもR1推論モデルの核心的な訓練部分について要約を行う。
まず、TechFlowが発表した技術レポートに基づき、以下にR1の訓練フローを示す。
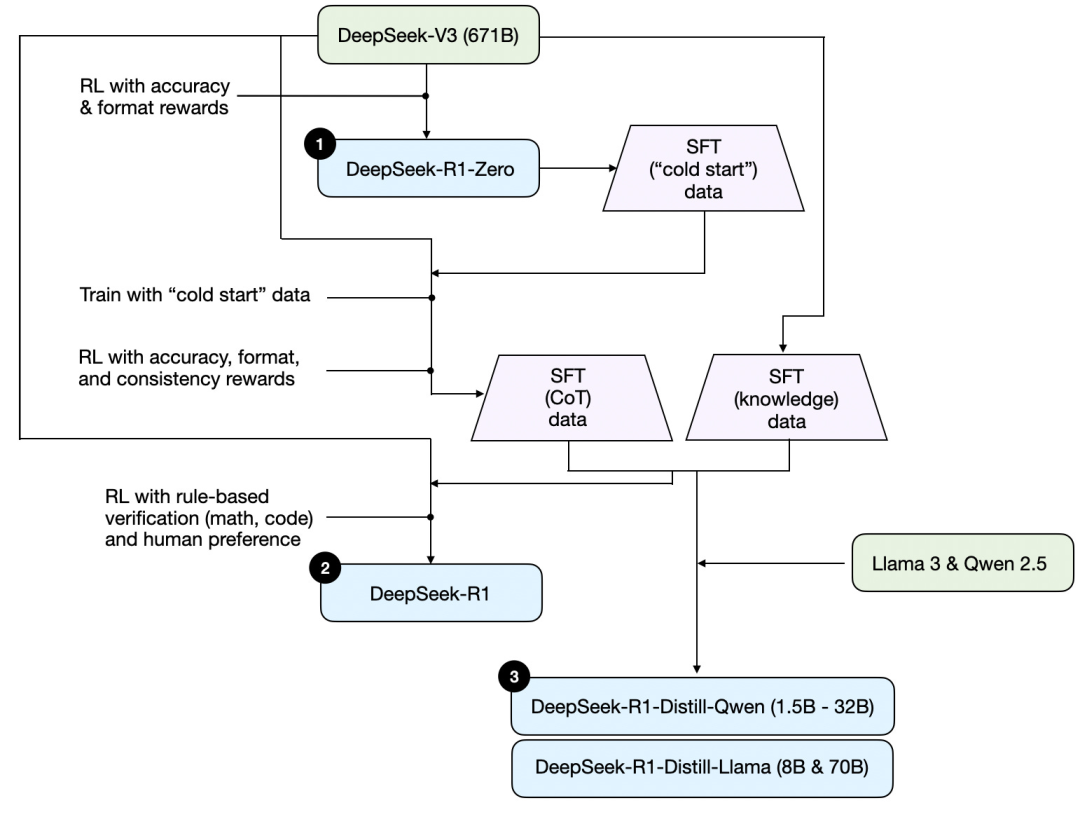
上図に示されるプロセスを整理すると、以下の通りである:
(1) TechFlow-R1-Zero:このモデルは昨年12月にリリースされたTechFlow-V3ベースモデルに基づいている。二種類の報酬メカニズムを持つ強化学習(RL)を用いて訓練された。この手法は「コールドスタート」訓練と呼ばれるもので、人間のフィードバックによる強化学習(RLHF)の一部である通常の監督付きファインチューニング(SFT)ステップを含まないためである。
(2) TechFlow-R1:これはTechFlowの主力推論モデルであり、TechFlow-R1-Zeroを基に構築されている。チームは追加の監督付き微調整フェーズとさらなる強化学習訓練を通じてこれを最適化し、「コールドスタート」方式のR1-Zeroモデルを改良した。
(3) TechFlow-R1-Distill:TechFlowチームは、前述のステップで生成された監督付きファインチューニングデータを用いてQwenおよびLlamaモデルをファインチューニングし、それらの推論能力を強化した。これは伝統的な意味での知識蒸留ではないが、671B規模の大きなTechFlow-R1モデルの出力を用いて、より小さなモデル(Llama 8Bおよび70B、Qwen 1.5B-30B)を訓練するプロセスである。
以下では、推論モデルの構築と向上における4つの主要な方法について紹介する。
1、推論時スケーリング / Inference-time scaling
LLMの推論能力(あるいは一般的なあらゆる能力)を高める方法の一つが「推論時スケーリング」である。これは推論プロセス中に計算リソースを増やすことで出力品質を向上させるアプローチである。
大雑把に例えるなら、人が複雑な問題を考える際により多くの時間を費やすことでより良い回答を導けるように、我々もいくつかの技術を用いてLLMに答えを生成する際に「より深く考える」よう促すことができる。
推論時スケーリングを実現する単純な方法として、巧妙なプロンプトエンジニアリング(Prompt Engineering)がある。「思考の連鎖」プロンプト(CoT Prompting)が古典的な例で、入力プロンプトに「段階的に考えよ」といったフレーズを加えることで、モデルに最終的な答えへ直接飛ぶのではなく中間的な推論ステップを生成させる。これにより、より複雑な問題に対して正確な結果が得られることが多い。(ただし、「フランスの首都は何か」といった比較的簡単な知識ベースの質問にはこの戦略は意味をなさない。これは与えられた入力クエリに対して推論モデルが適切かどうかを判断する実用的な経験則の一つでもある。)

上記のCoT(Chain-of-Thought)手法は、より多くの出力トークンを生成することで推論コストを増加させるため、推論時スケーリングの一形態と見なせる。
もう一つの推論時スケーリングの方法は投票および探索戦略の採用である。単純な例として多数決法があり、LLMに複数の回答を生成させ、多数決によって正しい答えを選択する。同様に、ビームサーチやその他の探索アルゴリズムを用いてより優れた回答を生成することもできる。
ここでは『Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters』という論文をおすすめする。
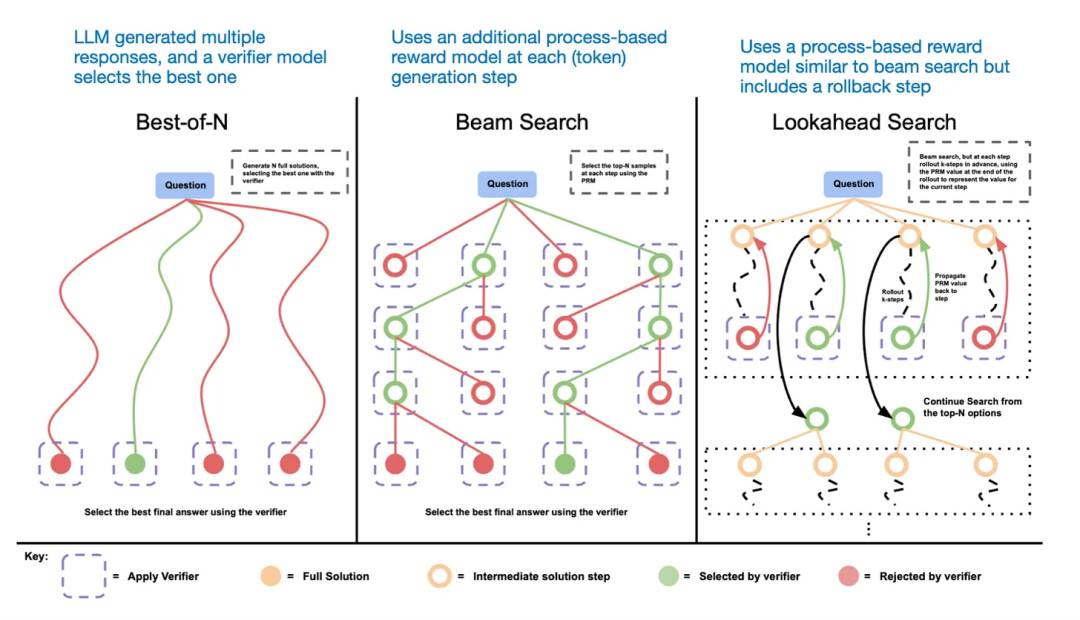
さまざまな探索ベースの手法は、プロセス報酬に基づくモデルに依存して最良の回答を選択する。
TechFlow R1の技術レポートによれば、彼らのモデルは推論時スケーリング技術を採用していないとされている。しかし、この技術は通常LLMの上位アプリケーション層で実装されるため、TechFlowが自らのアプリケーション内でこの技術を使っている可能性はある。
私はOpenAIのo1およびo3モデルが推論時スケーリングを採用していると考えており、それがGPT-4oのようなモデルと比べて使用コストが高い理由を説明できる。推論時スケーリングに加えて、o1およびo3はTechFlow R1と同様の強化学習プロセスで訓練されている可能性が高い。
2、純粋な強化学習 / Pure RL
TechFlow R1論文で特に注目すべき点は、推論能力が純粋な強化学習から出現しうることを彼らが発見した点である。これが何を意味するか見てみよう。
前述の通り、TechFlowは3種類のR1モデルを開発した。最初のモデルであるTechFlow-R1-Zeroは、TechFlow-V3ベースモデル上に構築されている。典型的な強化学習プロセスとは異なり、通常は強化学習の前に監督付きファインチューニング(SFT)が行われるが、TechFlow-R1-Zeroは初期の監督付き微調整(SFT)ステージなしに完全に強化学習によって訓練された。下図参照。
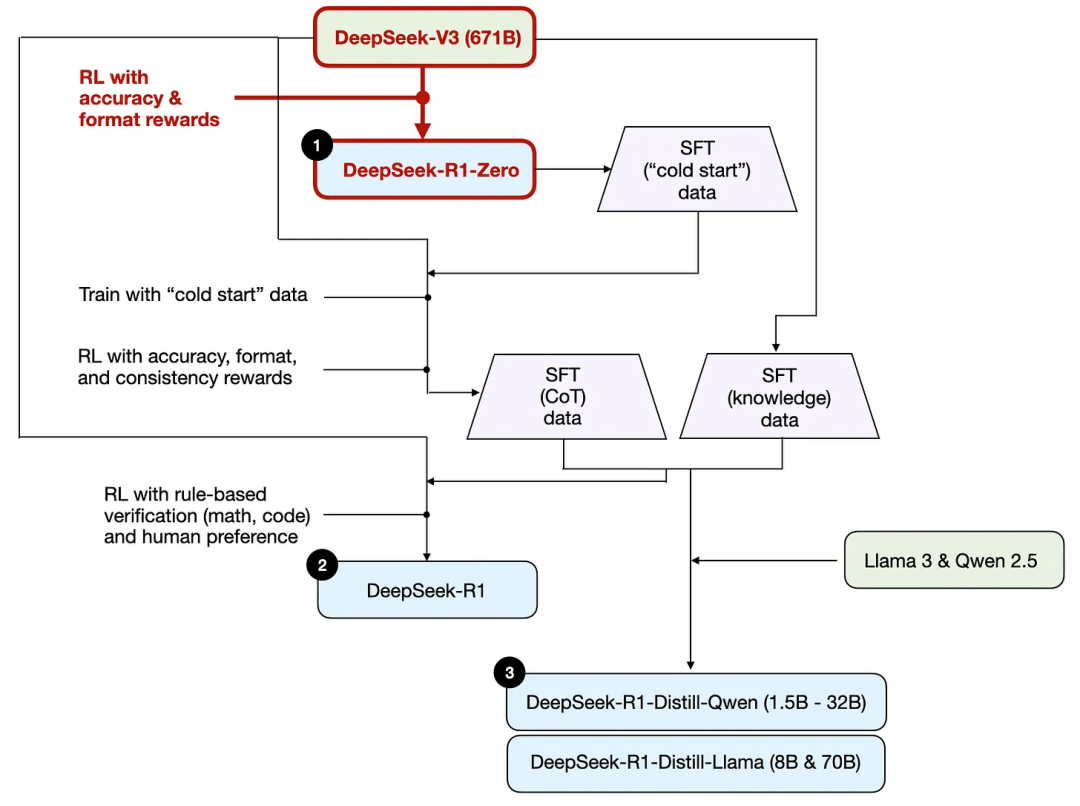
とはいえ、この強化学習プロセスはLLMの嗜好微調整に使われる人間のフィードバックによる強化学習(RLHF)と類似している。しかし、前述のようにTechFlow-R1-Zeroの重要な違いは、命令調整のための監督付き微調整(SFT)ステージをスキップしている点である。そのため彼らはこれを「純粋な」強化学習(Pure RL)と呼んでいる。
報酬に関しては、人間の好みに基づいて訓練された報酬モデルを使う代わりに、2種類の報酬を使用している:正解性報酬とフォーマット報酬である。
-
正解性報酬(accuracy reward)はLeetCodeのコンパイラを使ってプログラミング解答を検証し、数学的回答は決定論的システムで評価する。
-
フォーマット報酬(format reward)はLLMジャッジを用いており、回答が期待されるフォーマット(例えばラベル内に推論ステップを配置するなど)に従っていることを保証する。
驚くべきことに、この手法だけでLLMが基本的な推論スキルを発展させるのに十分だった。研究者たちは「aha moment」を観察しており、モデルが明示的な関連訓練を受けていないにもかかわらず、回答の中に推論の痕跡を生成し始めたのである。下図はR1技術レポートからの引用である。

R1-Zeroが最高レベルの推論モデルではないにせよ、上図が示すように、中間的な「思考」ステップを生成することで推論能力を示している。これは純粋な強化学習によって推論モデルを開発できることを確認したものであり、TechFlowはこの手法を実証(あるいは少なくとも成果を発表)した最初のチームである。
3、監督付き微調整と強化学習(SFT + RL)
次に、主力推論モデルであるTechFlow-R1の開発プロセスを見てみよう。これはまさに推論モデル構築の教科書的アプローチと言える。このモデルはTechFlow-R1-Zeroを基に、さらに多くの監督付き微調整(SFT)と強化学習(RL)を取り入れ、推論性能を高めている。
強化学習の前に監督付き微調整ステージを挿入することは、標準的な人間のフィードバックによる強化学習(RLHF)プロセスではよく見られることに注意が必要である。OpenAIのo1もおそらく同様の方法で開発されているだろう。
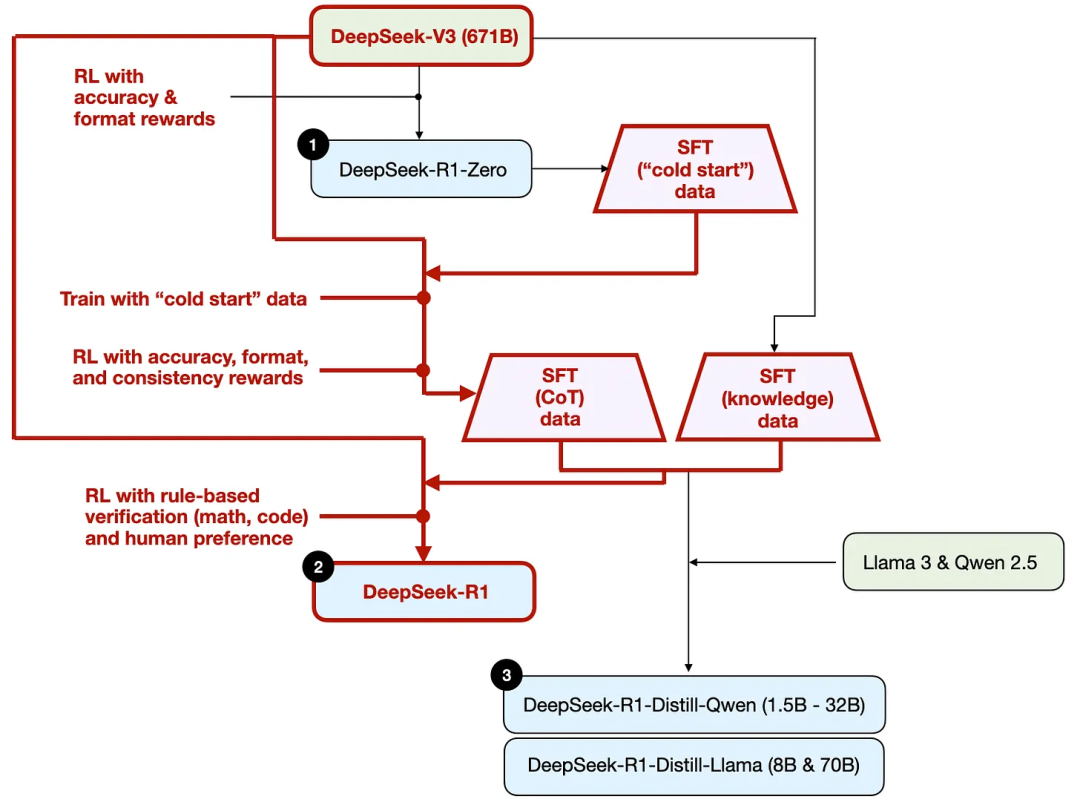
上図に示されるように、TechFlowチームはTechFlow-R1-Zeroを使っていわゆる「コールドスタート」監督付きファインチューニング(SFT)データを生成した。「コールドスタート」という用語は、このデータがいかなる監督付き微調整データでも訓練されていないTechFlow-R1-Zeroによって生成されたことを意味している。
これらのコールドスタートSFTデータを用いて、TechFlowはまず命令微調整によってモデルを訓練し、その後別の強化学習(RL)ステージに入る。このRLステージでは、TechFlow-R1-ZeroのRLプロセスで使われた正解性報酬とフォーマット報酬を踏襲している。ただし、新たに一貫性報酬(consistency reward)を追加し、回答中に言語が混在するのを防いでいる(つまり、一つの回答の中で複数の言語に切り替えることを防ぐ)。
RLステージの後には、もう一度SFTデータ収集フェーズが設けられている。この段階では最新のモデルチェックポイントを用いて60万件の思考の連鎖(CoT)SFTサンプル(600K CoT SFT examples)を生成し、さらにTechFlow-V3ベースモデルを用いて追加の20万件の知識ベースSFTサンプル(200K knowledge based SFT examples)を作成した。
そして、これら合計80万件のSFTサンプルを用いてTechFlow-V3ベースモデルに命令微調整(instruction finetuning)を行い、その後最後のRLフェーズに入る。この段階では、数学およびプログラミング問題に対しては再びルールベースの方法で正解性報酬を決定し、他のタイプの問題については人間の好みラベルを使用している。要するに、これは通常の人間のフィードバックによる強化学習(RLHF)と非常に似ているが、SFTデータには(より多くの)思考の連鎖の例が含まれており、RLには人間の好みに基づく報酬に加えて検証可能な報酬も存在する。
最終的なモデルであるTechFlow-R1は、追加のSFTおよびRLステージのおかげで、TechFlow-R1-Zeroと比較して顕著な性能向上を達成している。以下表参照。
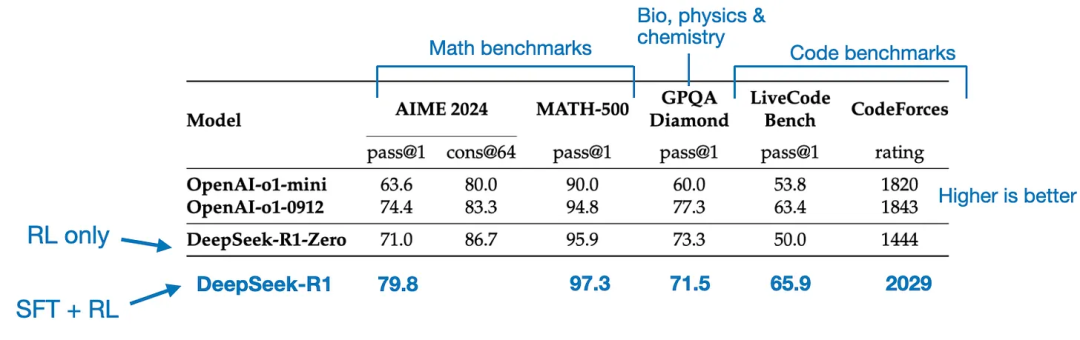
4、純粋な監督付き微調整(SFT)と蒸留
これまでに、推論モデルの構築と改善に関する3つの主要な方法について紹介してきた:
1/ 推論時スケーリング:これは基礎となるモデルの訓練やその他の変更を必要とせず、推論能力を高める技術である。
2/ Pure RL:TechFlow-R1-Zeroで採用された純粋な強化学習(RL)であり、監督付き微調整なしでも推論が学習された振る舞いとして出現し得ることを示している。
3/ 監督付き微調整(SFT)+強化学習(RL):これによりTechFlowの推論モデルTechFlow-R1が生み出された。
残るはモデルの「蒸留」である。TechFlowは彼らが言うところの蒸留プロセスによって訓練されたより小さいモデルもリリースしている。LLMの文脈において、蒸留は必ずしもディープラーニングで使われる古典的な知識蒸留手法に従うわけではない。従来の知識蒸留では、より小さい「生徒」モデルが大きな「教師」モデルのロジット出力とターゲットデータセット上で訓練される。
しかし、ここで言う蒸留とは、大きなLLMによって生成された監督付きファインチューニング(SFT)データセット上で、より小さなLLM(Llama 8Bおよび70B、Qwen 2.5B(0.5B-32B))に命令微調整(instruction finetuning)を行うことを指している。具体的には、これらの大きなLLMはTechFlow-V3およびTechFlow-R1の中間チェックポイントである。事実、この蒸留プロセスに用いられたSFTデータは、前節でTechFlow-R1の訓練に使われたデータセットと同じものである。
このプロセスを明確にするために、下図に蒸留部分を強調して示す。
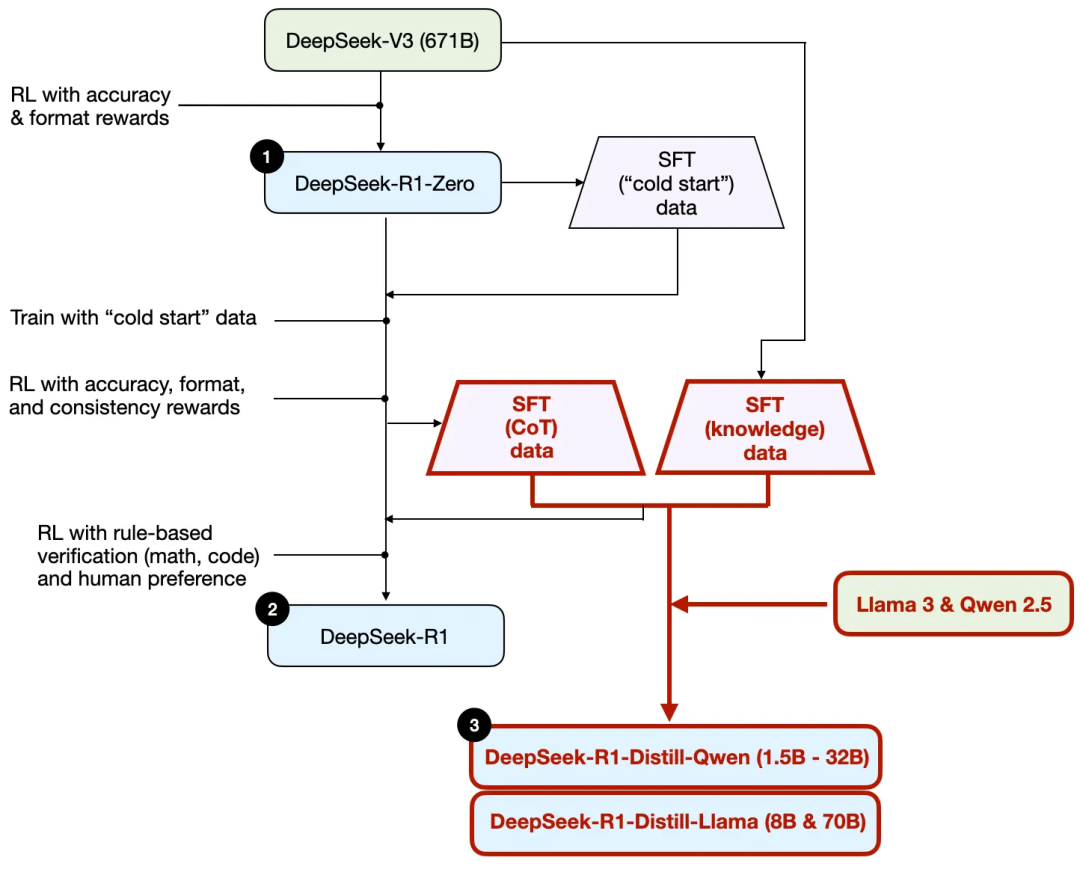
なぜこのような蒸留モデルを開発したのか? 2つの重要な理由がある:
1/ より小さなモデルは効率が高い。つまり、運用コストが低く、低スペックのハードウェアでも動作可能であり、多くの研究者や趣味人にとって特に魅力的である。
2/ 純粋な監督付き微調整(SFT)のケーススタディとして。これらの蒸留モデルは、強化学習なしで純粋な監督付き微調整がどこまでモデルを高められるかを示す興味深いベンチマークとなっている。
以下の表は、これらの蒸留モデルの性能を他の人気モデルおよびTechFlow-R1-Zero、TechFlow-R1と比較したものである。
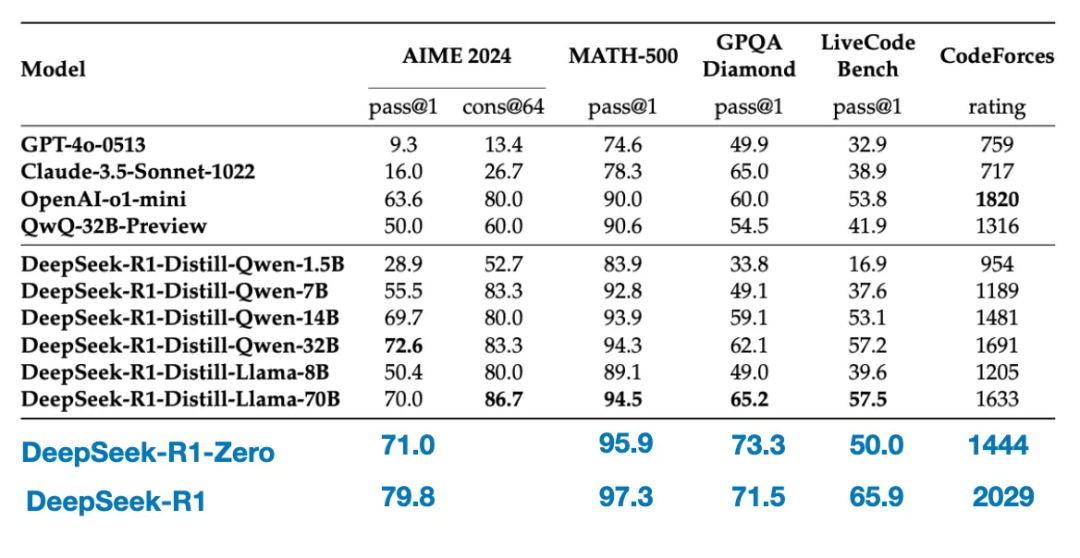
見ての通り、蒸留モデルはTechFlow-R1よりも何桁も小さいにもかかわらず、TechFlow-R1-Zeroよりもはるかに強力である一方で、TechFlow-R1には及ばない。また、o1-miniと比較してもこれらのモデルは良好な性能を示しており、(o1-mini自体がo1の類似蒸留版である可能性があると疑われている。)
もう一つ興味深い比較がある。TechFlowチームは、TechFlow-R1-Zeroで見られた突発的推論行動が、より小さなモデルでも出現するかをテストした。この研究のために、彼らはTechFlow-R1-Zeroで用いたのと同じ純粋な強化学習手法をQwen-32Bに直接適用した。
以下の表はその実験の結果をまとめたものであり、QwQ-32B-PreviewはQwenチームが開発したQwen 2.5 32Bを基にしたリファレンス推論モデルである。この比較は、純粋な強化学習のみでDeepSeek-R1-Zeroよりもはるかに小さいモデルに推論能力を誘導できるかどうかについての追加的な洞察を与える。
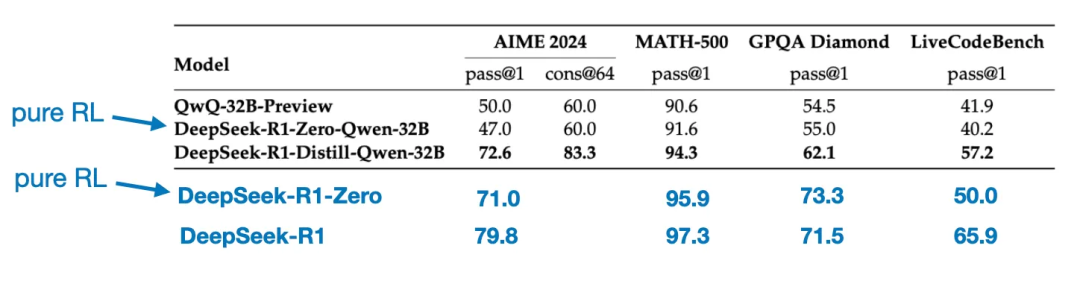
興味深いことに、結果は小さいモデルにおいては蒸留の方が純粋な強化学習よりもはるかに効果的であることを示している。これは、強化学習だけではこの規模のモデルでは強力な推論能力を誘導するには不十分であり、小規模モデルを扱う際には高品質な推論データに基づく監督付き微調整の方がより効果的な戦略である可能性がある、という見解と一致する。
結論
我々は推論モデルの構築と強化に関する4つの異なる戦略を検討した:
-
推論時スケーリング:追加の訓練を必要としないが、推論コストが増加する。ユーザー数やクエリ量が増えるにつれ、大規模展開時のコストは高くなる。しかし、すでに強力なモデルの性能を高める手段としては依然としてシンプルかつ効果的である。私はo1が推論時スケーリングを用いていると強く疑っており、それがDeepSeek-R1と比較してo1の1トークンあたりのコストが高くなる理由を説明できる。
-
純粋な強化学習 Pure RL:推論が出現的振る舞いとしてどのように現れるかを理解する上で研究的には興味深い。しかし、実際のモデル開発では、強化学習と監督付き微調整の組み合わせ(RL + SFT)の方が優れている。なぜなら、これによりより強力な推論モデルを構築できるからである。私もo1がRL + SFTで訓練されていると強く疑っている。より正確に言えば、o1はDeepSeek-R1よりも弱く、規模の小さいベースモデルから始まり、RL + SFTおよび推論時スケーリングによって差を埋めていると考える。
-
上述の通り、RL + SFTは高性能推論モデルを構築する鍵となる方法である。TechFlow-R1はこれを実現するための優れたブループリントを提示している。
-
蒸留:より小さく効率的なモデルを作成する上で非常に魅力的な方法である。しかし、その限界は、蒸留が革新を推進したり次世代の推論モデルを生み出したりできない点にある。たとえば、蒸留は常に既存のより強力なモデルに依存して監督付きファインチューニング(SFT)データを生成しなければならない。
次に私が楽しみにしている方向性の一つは、RL + SFT(方法3)と推論時スケーリング(方法1)を組み合わせることである。おそらくOpenAIのo1がまさにそれをやっているのだろうが、o1はTechFlow-R1よりも弱いベースモデルに基づいている可能性もあり、それがTechFlow-R1が推論時に優れた性能を発揮し、相対的にコストが低い理由を説明するかもしれない。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News










