暗号資産 × AIはもう流行らない?見落としがちな高ポテンシャルなナラティブをチェック
TechFlow厳選深潮セレクト
暗号資産 × AIはもう流行らない?見落としがちな高ポテンシャルなナラティブをチェック
初期のWeb3-AIブームは、現実離れした価値主張に主に集中していたが、今こそ実際に機能するソリューションの構築に重点を移すべきである。
翻訳:TechFlow
暗号資産とAI:もう終わりなのか?
2023年、Web3-AIは一時的に注目を集めた。
しかし今や、模倣者や実用性のない巨額プロジェクトが横行している。
ここでは避けるべき落とし穴と、注目すべきポイントを紹介する。

概要
IntoTheBlockのCEO@jrdothoughtsは最近、ある記事で彼の洞察を共有した。
彼が議論したのは以下の3点だ:
a. Web3-AIの根本的課題
b. 過剰に宣伝されたトレンド
c. 高い潜在力を秘めるトレンド
各項目の要点をすでに私が抽出済みだ。さあ、詳しく見ていこう:

市場の現状
現在のWeb3-AI市場は、過剰な宣伝と資金供給に包まれている。
多くのプロジェクトは、AI業界の実際のニーズから乖離している。
このズレは混乱を招く一方で、洞察力のある人々にとってはチャンスでもある。
(謝辞 @coinbase)
核心的課題
Web2とWeb3のAIの間には、以下3つの理由によりギャップが広がっている:
-
限られたAI研究人材
-
制限されたインフラ
-
不足するモデル・データ・計算リソース
生成AIの基礎
生成AIはモデル・データ・計算リソースという3つの柱に依存している。
現時点では、主要なモデルがWeb3インフラ向けに最適化されているものはまだ存在しない。
初期の資金は、AIの現実から乖離したWeb3プロジェクトを支援していた。
過大評価されているトレンド
多くの喧騒があるにもかかわらず、すべてのWeb3-AIトレンドが注目に値するわけではない。
以下は@jrdothoughtsが特に過大評価されていると考えるトレンドだ:
a. 分散型GPUネットワーク
b. ZK-AIモデル
c. 推論の証明(謝辞 @ModulusLabs)

分散型GPUネットワーク
これらのネットワークは、AIトレーニングの民主化を約束している。
しかし現実は、分散型インフラ上で大規模モデルを訓練することは遅く、非現実的である。
このトレンドは、高すぎる約束をまだ果たせていない。
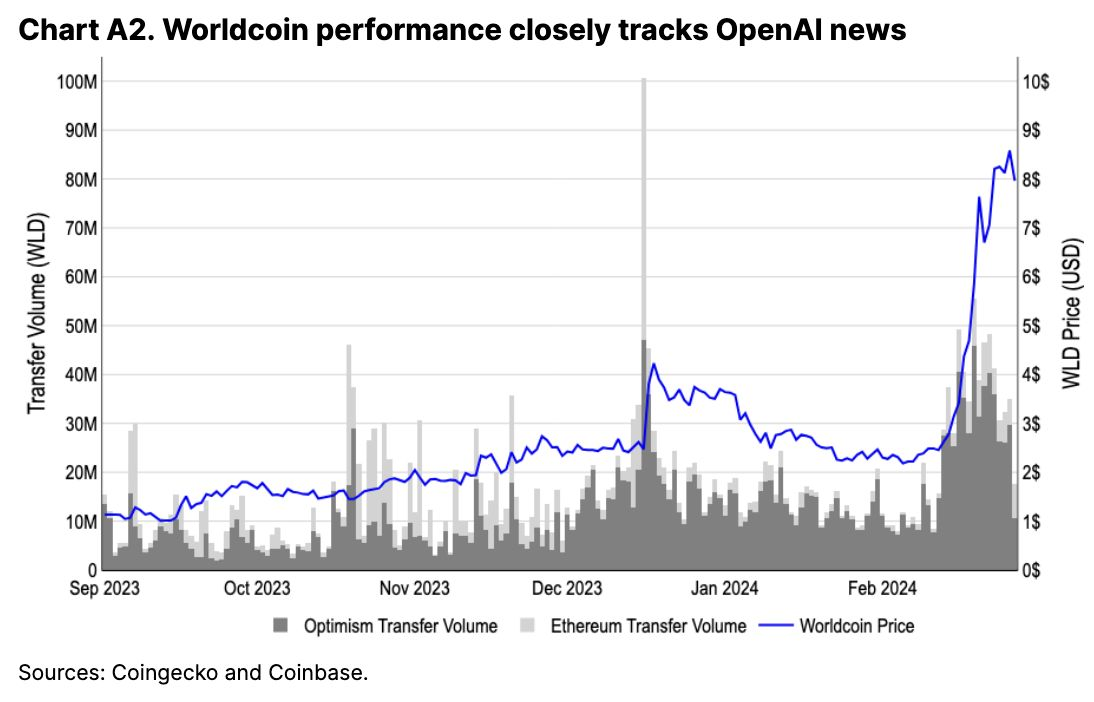
ゼロ知識AIモデル
ゼロ知識AIモデルは、プライバシー保護の観点から魅力的に見える。
しかし実際には、計算コストが高く、解釈も困難である。
そのため、大規模応用には向かない。
(謝辞 @oraprotocol )

図中の情報:
b) 現在、オーバーヘッドは最大1000倍に達する。
しかし、この手法は特にVitalikが挙げたようなユースケースに至るまでには、依然として大きな距離がある。以下はその例だ:
-
zkMLフレームワークEZKLは、1M-nanoGPTモデルの証明を生成するのに約80分かかる。
-
Modulus Labsのデータによると、zkMLのオーバーヘッドは純粋な計算に比べて1000倍以上であり、最新の報告では1000倍となっている。
-
EZKLのベンチマークによると、RISC Zeroはランダムフォレスト分類タスクにおいて平均173秒の証明時間を記録している。
推論の証明
推論の証明フレームワークは、AI出力に暗号化された証明を提供する。
しかし、@jrdothoughtsは、これらのソリューションが存在しない問題を解決しようとしていると指摘する。
したがって、現実世界での応用は限定的である。
高い潜在力を持つトレンド
一部のトレンドが過剰に宣伝されている一方で、他のトレンドには顕著な可能性が秘められている。
以下は過小評価されているが、真のチャンスを提供しうるトレンドだ:
a. ウォレット付きAIエージェント
b. 暗号資産によるAI資金調達
c. 小規模基礎モデル
d. 合成データ生成
ウォレット付きAIエージェント
AIエージェントが暗号資産を通じて金融的行動能力を持つ世界を想像してほしい。
このようなエージェントは、他のエージェントを雇ったり、品質保証のために資金をステーキングしたりできる。
もう一つ興味深い応用は、@vitalikbuterinが言及した「予測エージェント」だ。
暗号資産によるAI資金調達
生成AIプロジェクトはしばしば資金不足に悩む。
空売りやインセンティブといった、暗号資産が持つ効率的な資本形成手法は、オープンソースAIプロジェクトにとって重要な資金源となる。
これらの手法は革新を推進する助けとなる。(謝辞 @oraprotocol)
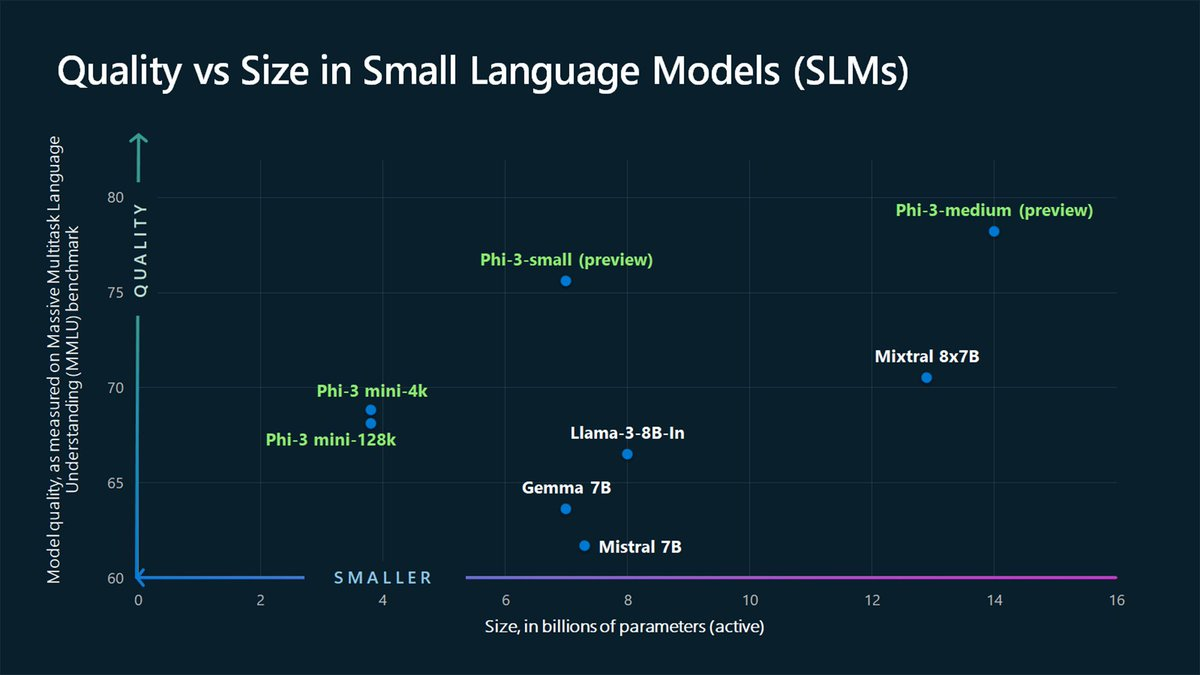
小規模基礎モデル
マイクロソフトのPhiモデルのような小規模基礎モデルは、「少ないほど良い」という理念を示している。
10億〜50億のパラメータを持つモデルは、分散型AIにとって重要であり、強力な端末側AIソリューションを提供できる。
(出典:@microsoft)
合成データ生成
データ不足は、AI発展における主要な障壁の一つである。
基礎モデルによって生成される合成データは、現実世界のデータセットを効果的に補完できる。
過剰な宣伝を乗り越える
初期のWeb3-AIブームは、現実離れした価値主張に集中していた。
@jrdothoughtsは、今こそ実際に機能するソリューション構築に焦点を当てるべきだと考える。
関心が移り変わる中、AI分野には依然としてチャンスが満ちており、鋭い目を持つ者を待っている。
本記事は教育目的のみであり、財務アドバイスではない。@jrdothoughtsによる貴重な洞察に感謝する。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News