

AI x Web3:新産業のエコシステムと将来性を探る
TechFlow厳選深潮セレクト
AI x Web3:新産業のエコシステムと将来性を探る
AIとWeb3は、一見すると互いに独立した技術であり、根本的に異なる原理に基づき、それぞれ異なる機能を果たしているように見える。しかし、詳しく考察すると、これらの技術がお互いのトレードオフを補完し合い、それぞれの独自の強みが相まって相互に強化し合う可能性があることがわかる。
執筆:IOSG Ventures
Part One
一見すると、AI × Web3は互いに独立した技術であり、根本的に異なる原理に基づき、異なる機能を提供しているように思える。しかし、深く考察すると、これら二つの技術にはお互いの欠点を補完し合い、それぞれの独自の強みを活かして相互に向上させる可能性がある。Balaji SrinivasanはSuperAIカンファレンスでこの相補性の概念を的確に説明しており、これらの技術がどのように相互作用するかについての詳細な比較を促した。
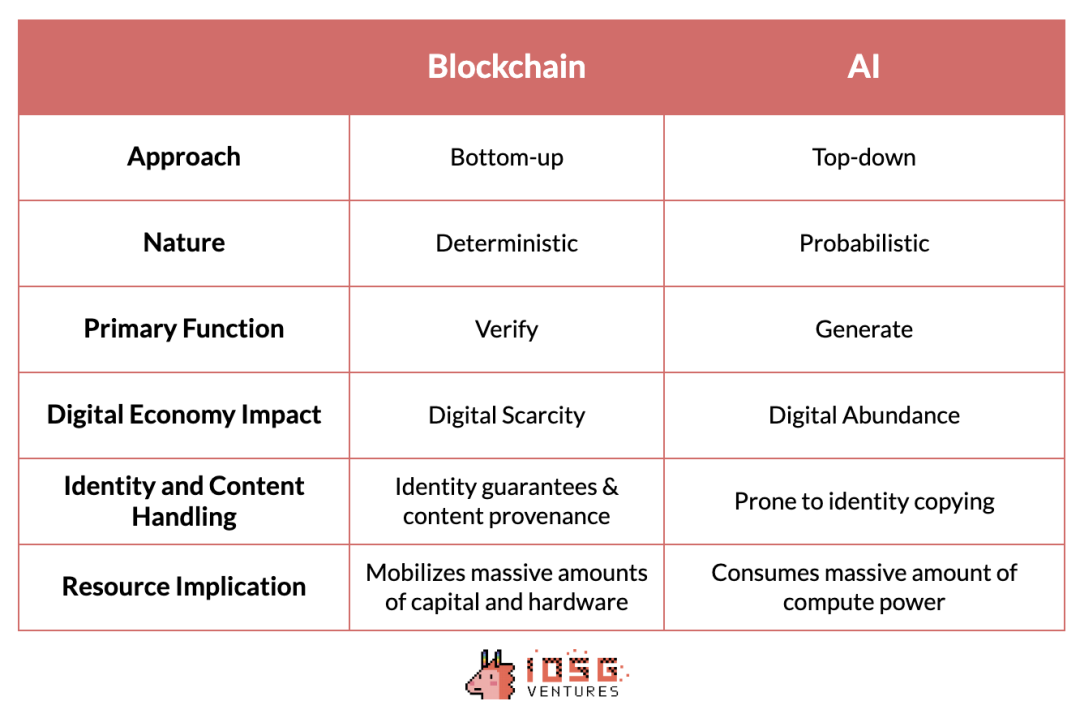
トークンは、匿名ネットワークパンクの分散型努力から生まれたボトムアップ型のアプローチを採用しており、十数年にわたり、世界中の多数の独立した実体による協働によって進化してきた。一方、AIはトップダウン型のアプローチで開発されており、少数の大手テック企業が業界のペースとダイナミクスを支配している。参入障壁は、技術的な複雑さというよりも、むしろリソースの集中度によって決まる。
また、両技術には本質的な違いもある。本質的に、トークンは決定論的システムであり、ハッシュ関数やゼロ知識証明のように不変かつ予測可能な結果を生み出す。これは、AIの確率的でしばしば予測不可能な性質と対照的である。
同様に、暗号技術は検証において優れており、取引の真正性と安全性を保証し、信頼不要(trustless)なプロセスやシステムを構築する。一方、AIは生成に注力しており、豊かなデジタルコンテンツを創造する。しかし、その過程でコンテンツの出所を確保し、身元盗用を防ぐことは課題となる。
幸運にも、トークンは「デジタルリッチネス(豊かさ)」に対立する概念——デジタル希少性——を提供する。これは、AI技術に応用可能な比較的成熟したツール群であり、コンテンツの出所の信頼性を確保し、身元盗用の問題を回避できる。
トークンの顕著な利点の一つは、特定の目的のために大量のハードウェアと資本を集めて調整ネットワークに導入する能力にある。これは計算能力を大量に消費するAIにとって特に有利である。未使用のリソースを動員してより安価な計算能力を提供することは、AIの効率を大幅に向上させることができる。
この二大技術を比較することで、それぞれの貢献だけでなく、どのように共に新しい技術および経済の道を開くかも理解できる。各技術は他方の弱点を補完し合い、より統合され、革新的な未来を創り出す。本ブログ記事では、新興するAI × Web3産業マップを探索し、これらの技術が交差する分野におけるいくつかの新興垂直領域に焦点を当てる。
Source: IOSG Ventures
Part Two
2.1 計算ネットワーク
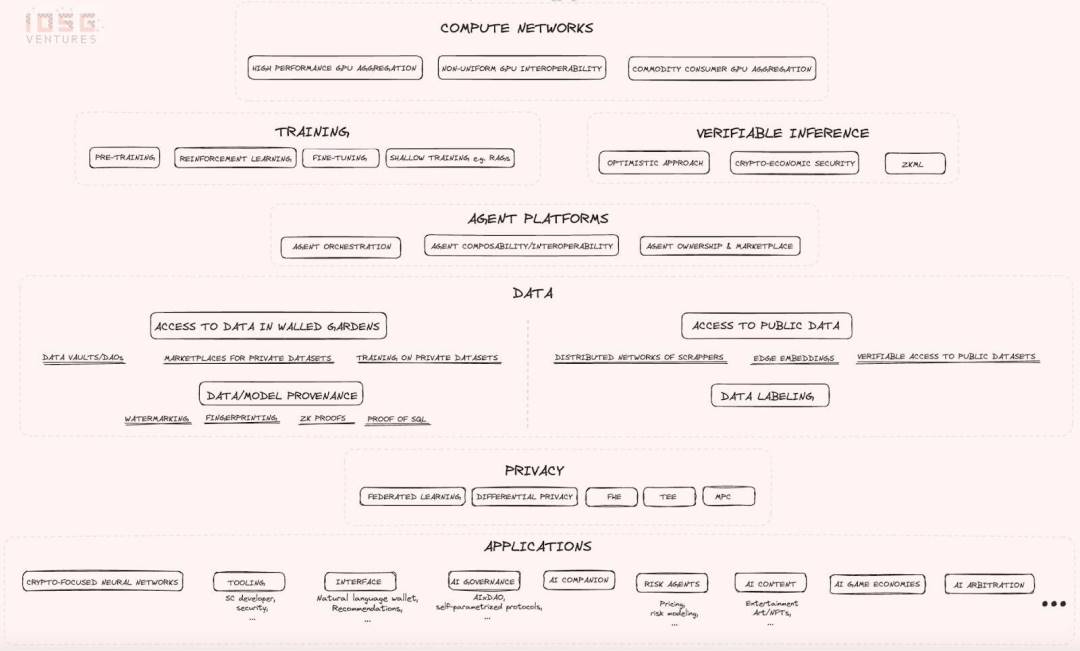
産業マップはまず、限定されたGPU供給の問題を解決し、さまざまな方法で計算コストを削減しようとする「計算ネットワーク」から紹介している。注目すべきは以下のものだ:
- 非均一GPU間の相互運用性:非常に野心的な試みであり、技術的リスクと不確実性が極めて高いが、成功すれば規模と影響力ともに巨大な成果を生み出し、すべての計算リソースを交換可能にできる可能性がある。本質的には、供給側にあらゆるハードウェアリソースを接続でき、需要側ではすべてのハードウェアの非均一性が完全に抽象化されるようなコンパイラなどの前提条件を構築することを目指す。こうしたビジョンが達成されれば、現在AI開発者が完全に依存しているCUDAソフトウェアへの依存を低下させられる。ただし技術的リスクは高く、多くの専門家はこのアプローチの実現可能性に対して強い懐疑を示している。
- 高性能GPUの集約:人気のある高性能GPUをグローバルに分散されたパーミッションレスネットワークに統合するもので、非均一なGPUリソース間の相互運用性の問題を気にせずに済む。
- 汎用コンシューマーGPUの集約:性能は低いものの、消費者向けデバイスに搭載されている可能性のあるGPUを集約する方向性。これらは供給側で最も活用されていないリソースであり、性能や速度を犠牲にしてでも低コストで長時間の学習プロセスを望むユーザー層に適している。
2.2 学習と推論
計算ネットワークは主に二つの機能に使われる:学習(トレーニング)と推論(インファレンス)。これらのネットワークに対する需要は、Web 2.0およびWeb 3.0プロジェクトから生じている。Web 3.0の分野では、Bittensorのようなプロジェクトがモデルのファインチューニングに計算リソースを利用している。推論の面では、Web 3.0プロジェクトはプロセスの検証可能性に重点を置いている。この重点により、「検証可能な推論(verifiable inference)」が市場の垂直領域として登場し、AI推論をスマートコントラクトに統合しつつも、分散化の原則を維持する方法が探られている。
2.3 スマートエージェントプラットフォーム
次にスマートエージェントプラットフォームがあり、マップはこのカテゴリのスタートアップが解決すべき核心課題を概説している:
- エージェント間の相互運用性・発見・通信能力:エージェント同士が互いに発見し、通信できること。
- エージェントクラスタの構築と管理能力:エージェントがクラスタを形成し、他のエージェントを管理できること。
- AIエージェントの所有権と市場:AIエージェントに所有権を与え、市場を提供すること。
これらの特性は、さまざまなブロックチェーンおよびAIアプリケーションにシームレスに統合可能な柔軟でモジュール化されたシステムの重要性を強調している。AIエージェントは、私たちがインターネットと関わる方法を根本的に変える可能性を持っており、我々はエージェントがインフラを活用してその操作を支えると考えている。以下のような形で、AIエージェントがインフラに依存すると想定している:
- 分散型クローリングネットワークを利用してリアルタイムのウェブデータにアクセス
- DeFiチャネルを使用してエージェント間の支払いを行う
- 不正行為時の罰則だけでなく、エージェントの発見可能性を高めるために経済的デポジットが必要(発見プロセスでデポジットを経済的信号として利用)
- 合意形成(consensus)を通じて、どのイベントがステーキングの削減を引き起こすべきかを決定
- オープンな相互運用性標準およびエージェントフレームワークにより、合成可能な集合体(composable collectives)の構築を支援
- 不変のデータ履歴に基づいて過去のパフォーマンスを評価し、リアルタイムで適切なエージェント集団を選択

Source: IOSG Ventures
2.4 データレイヤー
AI × Web3の融合において、データは中心的な構成要素である。データは計算資源とともに、AI競争における戦略的資産として重要なリソースを構成する。しかし、業界の注目が計算層に集中しているため、この分野はしばしば軽視される。実際、データ取得プロセスにおいてプリミティブは多くの興味深い価値方向を提供しており、主に以下の二つの高次元の方向性に分けられる:
- 公共インターネットデータへのアクセス
- 保護されたデータへのアクセス
公共インターネットデータへのアクセス:この方向性は、数日でインターネット全体をクロールできる分散型クローラーネットワークを構築することを目指しており、膨大なデータセットの取得や、非常に特定的なインターネットデータのリアルタイムアクセスを可能にする。しかし、大量のデータセットをクロールするにはネットワークリソースの要求が非常に高く、意味ある作業を始めるには少なくとも数百ノードが必要となる。幸運にも、Grassという分散型クローラーノードネットワークはすでに200万以上のノードがネットワークにインターネット帯域幅を積極的に共有しており、インターネット全体のクロールを目標としている。これは、経済的インセンティブが貴重なリソースを惹きつける潜在力を示している。
Grassが公共データの分野で公平な競争環境を提供するとしても、依然として潜在的なデータ活用の難題——つまり、独自データセットへのアクセス——が残っている。具体的には、感度の高い性質を持つため、プライバシー保護の観点から保存されている大量のデータが存在する。多くのスタートアップは、機密情報を秘匿しつつも、独自データセットの基盤データ構造を活用して大規模言語モデルの構築やファインチューニングを行うために、暗号学的手法を利用している。
フェデレーテッドラーニング、差分プライバシー、信頼できる実行環境(TEE)、完全準同型暗号、マルチパーティ計算などの技術は、異なるレベルのプライバシー保護とトレードオフを提供する。Bagelのリサーチ記事は、これらの技術に関する優れた概要をまとめている。これらの技術は機械学習プロセスにおけるデータプライバシーを保護するだけでなく、計算レイヤーにおいても包括的なプライバシー保護型AIソリューションを実現できる。
2.5 データとモデルの出所
データおよびモデルの出所(プロvenance)技術は、ユーザーが期待するモデルおよびデータと実際にやり取りしていることを保証する仕組みを構築することを目的としている。さらに、真実性と出所の保証も提供する。例としてウォーターマーキング技術があり、これはモデルの出所技術の一つで、署名を機械学習アルゴリズムに直接埋め込む、より具体的にはモデルの重みに直接埋め込むことで、推論結果が本当にそのモデル由来かどうかを検証できるようにする。
2.6 アプリケーション
アプリケーションの分野では、設計の可能性は無限である。上記の産業マップでは、AI技術がWeb 3.0分野に応用されることで特に期待される発展事例をいくつか列挙している。これらのユースケースの多くは自己説明的であるため、ここでは追加のコメントはしない。ただし、AIとWeb 3.0の交差点が多くの垂直領域を再形成する可能性を持っていることに留意すべきである。なぜなら、これらの新しいプリミティブは、開発者が革新的なユースケースを創造したり、既存のものを最適化したりする自由度を高めるからだ。
Part Three
まとめ
AI × Web3の融合は、革新と可能性に満ちた将来像を提示している。それぞれの技術が持つ独自の強みを活かすことで、さまざまな課題を解決し、新たな技術的道筋を開くことができる。この新興産業を探求する中で、AIとWeb 3.0の相乗効果は進歩を推進し、私たちの将来のデジタル体験やネットワーク上での関わり方を再形成するだろう。
デジタル希少性とデジタルリッチネスの融合、計算効率のための未使用リソースの動員、安全でプライバシー保護されたデータ活用の確立——これらが次世代の技術進化を特徴づける時代を定義するだろう。
しかし、この業界はまだ初期段階にあり、現在の産業マップは短期間で陳腐化する可能性があることを認識しなければならない。急速なイノベーションのペースは、今日の最先端のソリューションですら、すぐに新たな突破によって置き換えられるということを意味する。それでもなお、計算ネットワーク、エージェントプラットフォーム、データプロトコルといった基礎的概念の探求は、AIとWeb 3.0が融合する巨大な可能性を浮き彫りにしている。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News











