

Celer:万神殿 Pantheon - ZKP開発フレームワーク評価プラットフォーム
TechFlow厳選深潮セレクト
Celer:万神殿 Pantheon - ZKP開発フレームワーク評価プラットフォーム
SHA-256の各種zk-SNARKおよびzk-STARK開発フレームワークにおける性能テスト結果。

ここ数か月間、zk-SNARKの簡潔な証明を利用した最先端インフラの構築に多くの時間と労力を費やしてきました。この次世代イノベーションプラットフォームにより、開発者はかつてない新しいタイプのブロックチェーンアプリケーションを構築できるようになります。
開発作業の中で、我々は複数のゼロ知識証明(ZKP)開発フレームワークをテストし、使用しました。このプロセスは非常に有益でしたが、同時に新たな課題にも気づきました。特に、新規の開発者が自身のユースケースやパフォーマンス要件に最も適したフレームワークを選択する際、多種多様なZKPフレームワークが障壁となることがよくあります。こうした問題意識から、包括的なパフォーマンステスト結果を提供するコミュニティ主導の評価プラットフォームがあれば、これらの新アプリケーションの開発を大きく促進できると考えました。
そのようなニーズに応えるため、我々は「ゼロ知識証明開発フレームワーク評価プラットフォーム『万神殿 Pantheon』」を立ち上げます。これはコミュニティ全体の公益的取り組みです。第一歩として、コミュニティにさまざまなZKPフレームワークの再現可能なパフォーマンステストの結果を共有してもらうことを奨励します。最終的には、低レベル回路開発フレームワーク、高レベルzkVM、コンパイラー、さらにはハードウェアアクセラレーションプロバイダーまでを含む、広く認められた評価プラットフォームを共同で構築・維持することを目指しています。このイニシアティブを通じて、開発者たちがフレームワーク選定時に性能比較の参考を持てるようになり、ZKPの普及が加速することを期待しています。また、標準的なパフォーマンステスト結果を提供することで、ZKPフレームワーク自体のアップグレードと反復的改善も促進したいと考えています。我々はこの計画に積極的に投資し、志を同じくするすべてのコミュニティメンバーを呼びかけて、共に貢献していきたいと思います!
第一段階:SHA-256を使用した回路フレームワークのパフォーマンステスト
本記事では、「ZKP Pantheon」構築への第一歩として、一連の低レベル回路開発フレームワークにおいてSHA-256に関する一連の再現可能なパフォーマンステスト結果を提示します。他の粒度やプリミティブでのテストも可能であることは承知していますが、SHA-256を選んだのは、それがブロックチェーンシステム、デジタル署名、zkDIDなど、幅広いZKPユースケースに適用可能だからです。
ちなみに、私たち自身のシステムでもSHA-256を使用しているため、テストも非常に便利でした!😂
今回のパフォーマンステストでは、さまざまなzk-SNARKおよびzk-STARK回路開発フレームワークにおけるSHA-256のパフォーマンスを評価しました。比較を通じて、各フレームワークの効率性と実用性に関する洞察を提供することを目指しています。このテスト結果が、開発者が最適なフレームワークを選ぶ際の参考となり、賢明な意思決定を支援することを願っています。
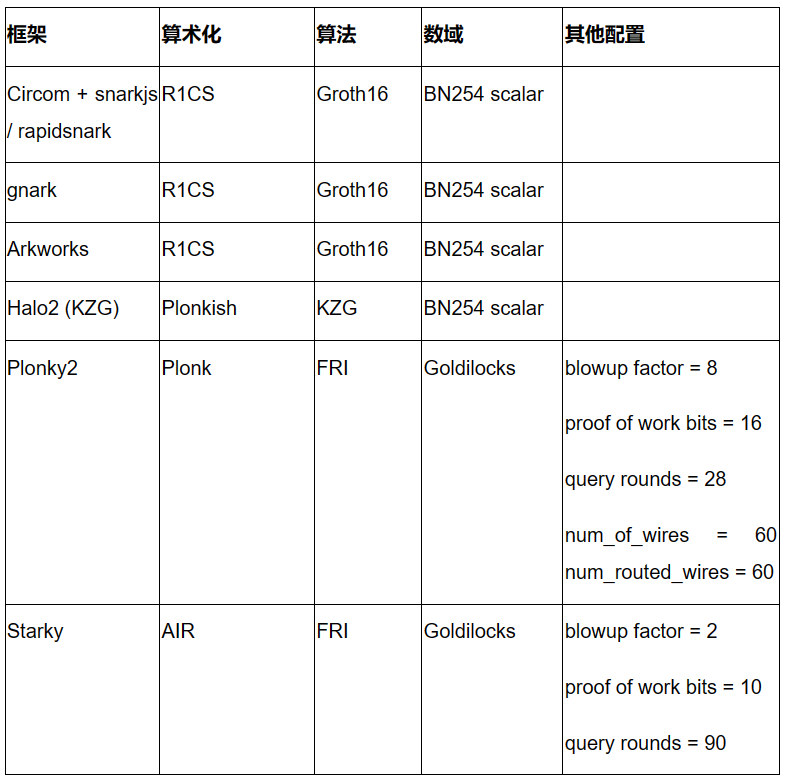
証明システム
近年、ゼロ知識証明システムが爆発的に増加しています。分野内のすべての進展についていくのは困難ですが、成熟度と開発者の採用状況に基づき、以下の証明システムをテスト対象として厳選しました。異なるフロントエンド/バックエンドの組み合わせを代表的にカバーすることを目標としています。
-
Circom + snarkjs / rapidsnark: Circomは回路記述とR1CS制約生成のための人気DSLであり、snarkjsはCircom向けにGroth16またはPlonk証明を生成できます。rapidsnarkもCircomのプローバーで、Groth16証明を生成します。ADX拡張を利用しており、並列化を最大限に行うことで、通常snarkjsよりもはるかに高速です。
-
gnark: Consensysが開発した包括的なGolangフレームワークで、Groth16、Plonk、および多数の上級機能をサポートしています。
-
Arkworks: zk-SNARK用の包括的なRustフレームワークです。
-
Halo2 (KZG): Halo2はZcashによるPlonkベースのzk-SNARK実装です。柔軟性の高いPlonkish算術を備え、カスタムゲートやルックアップテーブルなど多くの有用なプリミティブをサポートしています。我々は、Ethereum FoundationおよびScrollが支援するKZGバージョンのHalo2フォークを使用しています。
-
Plonky2: Plonky2はPolygon Zeroが開発した、PLONKとFRI技術に基づくSNARK実装です。 小さなGoldilocks体を使用し、効率的な再帰をサポートしています。本パフォーマンステストでは、推定100ビットのセキュリティをターゲットとし、証明時間が最良になるパラメータを使用しました。具体的には、28回のMerkle照会、倍率8、作業証明チャレンジ16ビットを採用。さらに、num_of_wires = 60、num_routed_wires = 60に設定しています。
-
Starky: StarkyはPolygon Zeroの高性能STARKフレームワークです。本パフォーマンステストでは、推定100ビットのセキュリティをターゲットとし、証明時間が最良になるパラメータを使用しました。具体的には、90回のMerkle照会、倍率2、作業証明チャレンジ10ビットを採用しています。
下表は上記フレームワークおよび本パフォーマンステストで使用した設定をまとめたものです。このリストは網羅的ではなく、今後Nova、GKR、Hyperplonkなど最新のフレームワーク/技術も調査予定です。
なお、これらのパフォーマンステスト結果は回路開発フレームワークに限定されています。今後別の記事で、zkVM(例:Scroll、Polygon zkEVM、Consensys zkEVM、zkSync、Risc Zero、zkWasm)およびIRコンパイラー(例:Noir、zkLLVM)のパフォーマンステストを行う予定です。
パフォーマンス評価方法論
これらの異なる証明システムのパフォーマンスを評価するため、Nバイトデータに対するSHA-256ハッシュ値を計算しました。N = 64、128、...、64Kで実験を行いました(Starkyのみ、固定64バイト入力のSHA-256計算を繰り返すが、メッセージブロック総数は同一に保つ)。パフォーマンスコードおよびSHA-256回路設定はこちらのリポジトリで確認できます。
さらに、以下の指標で各システムのパフォーマンスを測定しました:
-
証明生成時間(ワイヤ生成時間を含む)
-
証明生成中のピークメモリ使用量
-
証明生成中の平均CPU使用率(この指標は並列化の程度を反映)
なお、証明サイズおよび検証コストについては、オンチェーン前にGroth16またはKZGと組み合わせることで軽減可能であるため、ある程度「妥協」している点に注意してください。
使用機器
以下の2台の異なるマシンでパフォーマンステストを実施しました:
-
Linuxサーバー:20コア @2.3GHz、384GBメモリ
-
Macbook M1 Pro:10コア @3.2GHz、16GBメモリ
Linuxサーバーは多数のCPUコアと豊富なメモリを持つ環境を模擬しています。一方、Macbook M1 Proは一般的な開発用途に使われ、より強力なCPUを持ちますが、コア数は少ないです。
オプションのマルチスレッドは有効にしましたが、GPUアクセラレーションは本パフォーマンステストでは使用していません。今後GPUパフォーマンステストを予定しています。
パフォーマンス評価結果
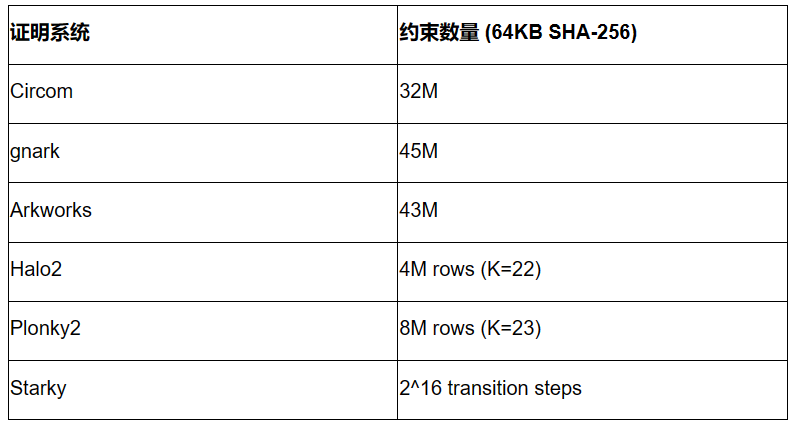
制約数
詳細なパフォーマンス結果に入る前に、まず各証明システムにおけるSHA-256の複雑さを理解するために、制約数を確認するのは有用です。ただし、異なる算術スキーム間の制約数は直接比較できないことに注意が必要です。
以下は64KBのプレインテキストサイズに対応する結果です。他のプレインテキストサイズでは結果が異なる可能性がありますが、おおよそ線形にスケールします。
-
Circom、gnark、Arkworksはいずれも同じR1CSアルゴリズムを使用しており、64KB SHA-256のR1CS制約数はおおむね30M~45Mの範囲です。Circom、gnark、Arkworks間の差異は設定の違いによるものと思われます。
-
Halo2およびPlonky2はPlonkish算術を使用しており、行数は2^22~2^23の範囲です。ルックアップテーブルの利用により、Halo2のSHA-256実装はPlonky2よりはるかに効率的です。
-
StarkyはAIRアルゴリズムを使用しており、実行トレース表は2^16の遷移ステップを必要とします。
証明生成時間
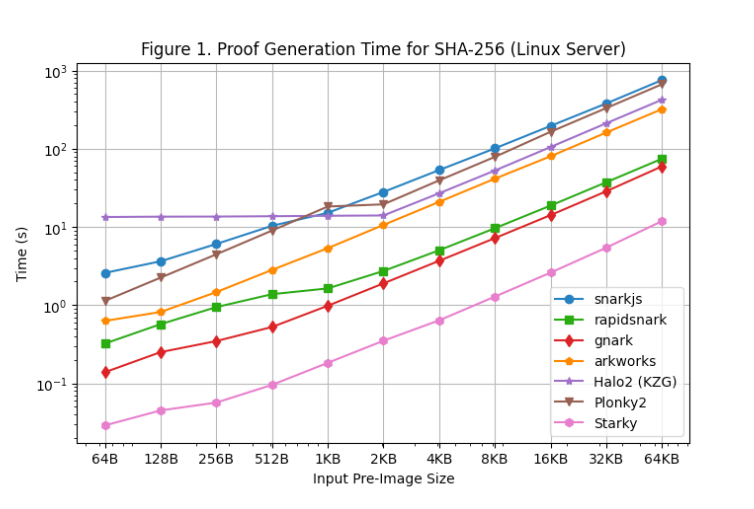
[図1] はLinuxサーバーで各種プレインテキストサイズにおける各フレームワークのSHA-256証明生成時間を示しています。以下の知見が得られました:
-
SHA-256に関しては、Groth16フレームワーク(rapidsnark、gnark、Arkworks)はPlonkフレームワーク(Halo2、Plonky2)より速く証明を生成します。これはSHA-256が主にビット演算(線値が0または1)で構成されるため、Groth16では楕円曲線スカラー乗算から点加算への大部分の計算が削減されるためです。しかし、Plonkでは線値が直接計算に使われないため、SHA-256の特殊な線構造がPlonkフレームワークの計算量削減に寄与しません。
-
すべてのGroth16フレームワークの中では、gnarkおよびrapidsnarkがArkworksおよびsnarkjsより5~10倍高速です。これは複数コアを活用して証明生成を並列化する能力に優れているためです。gnarkはrapidsnarkより25%高速です。
-
Plonkフレームワークでは、>=4KBの大規模プレインテキストの場合、Plonky2のSHA-256はHalo2より50%遅くなります。これはHalo2の実装がルックアップテーブルを多用してビット演算を高速化しており、行数がPlonky2より2倍少なくなっているためです。しかし、同じ行数で比較すると(例:Halo2で>2KB vs Plonky2で>4KB)、Plonky2はHalo2より50%高速です。もしPlonky2でもルックアップテーブルを用いてSHA-256を実装すれば、証明サイズは大きくなるものの、Halo2より高速になると予想されます。
-
一方、入力プレインテキストが小さい場合(<=512バイト)、ルックアップテーブルの固定セットアップコストが制約の大半を占めるため、Halo2はPlonky2(および他のフレームワーク)より遅くなります。しかし、プレインテキストが大きくなるにつれ、Halo2のパフォーマンスは競争力を持ち、2KBまでのプレインテキストでは証明生成時間がほぼ一定で、線形に近いスケーリングを示しています。
-
予想通り、Starkyの証明生成時間は任意のSNARKフレームワークよりはるかに短い(5~50倍)ですが、その代償として証明サイズが大幅に大きくなります。
-
なお、回路サイズはプレインテキストサイズに線形に依存しますが、SNARKの証明生成はO(nlogn)のFFTにより超線形に増加します(対数スケールのため、グラフ上ではあまり顕著ではありません)。
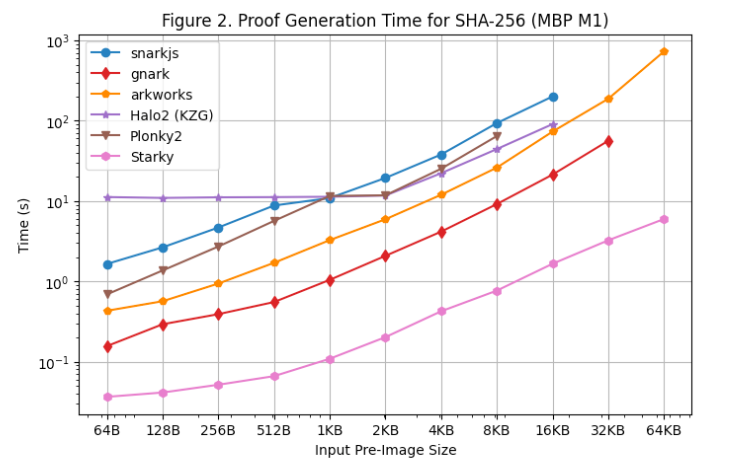
Macbook M1 Proでも証明生成時間のパフォーマンステストを実施しました([図2]参照)。ただし、arm64アーキテクチャへの対応不足のため、rapidsnarkは含まれていません。snarkjsをarm64で使用するにはWebAssemblyでワイヤを生成する必要があり、Linuxサーバーで使用したC++版より遅くなります。
Macbook M1 Proでのテストにおける追加の観察結果は以下の通りです:
-
Starkyを除くすべてのSNARKフレームワークは、プレインテキストが大きくなるとメモリ不足(OOM)エラーまたはスワップメモリ使用(証明時間遅延)に陥ります。具体的には、Groth16フレームワーク(snarkjs、gnark、Arkworks)はプレインテキスト>=8KBでスワップメモリを使用し始め、gnarkは>=64KBでOOMになります。Halo2は>=32KBでメモリ制限に達し、Plonky2は>=8KBでスワップメモリを使用し始めます。
-
FRIベースのフレームワーク(Starky、Plonky2)は、Macbook M1 Pro上でLinuxサーバーより約60%高速ですが、他のフレームワークは両マシンで証明時間に大きな差はありません。そのため、Plonky2でルックアップテーブルを使用しなくても、Macbook M1 Pro上ではHalo2とほぼ同等の証明時間を達成しています。主な理由は、Macbook M1 Proがより強力なCPUを持ちながらコア数が少ないため、FRIはハッシュ演算中心でCPUクロックサイクルに敏感だが、KZGやGroth16ほど並列性が高くないためです。
ピークメモリ使用量
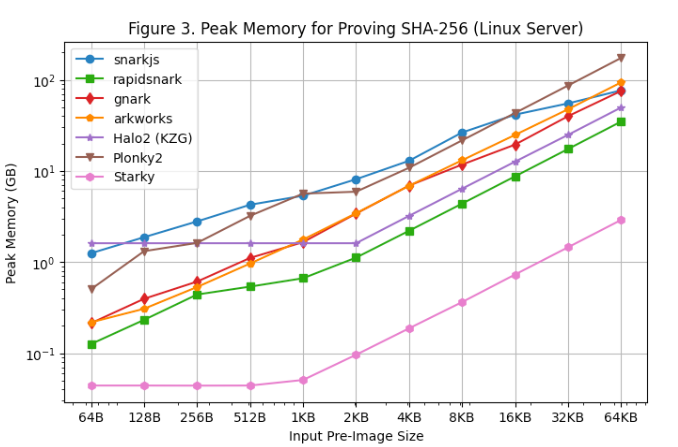
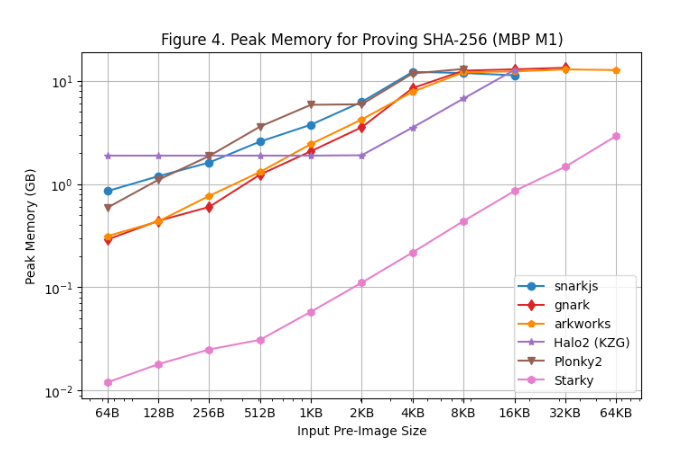
[図3]および[図4]はそれぞれLinuxサーバーおよびMacbook M1 Proにおける証明生成中のピークメモリ使用量を示しています。これらの結果から以下の観察が得られます:
-
すべてのSNARKフレームワーク中、rapidsnarkが最もメモリ効率が高いです。また、ルックアップテーブルの固定セットアップコストのため、プレインテキストが小さいときHalo2はより多くのメモリを使用しますが、プレインテキストが大きいときには全体的に少ないメモリを消費します。
-
StarkyはSNARKフレームワークより10倍以上メモリ効率が高く、これは行数が少ないための部分もあります。
-
プレインテキストが大きくなるとスワップメモリが使用されるため、Macbook M1 Pro上のピークメモリ使用量は比較的安定しています。
CPU利用率
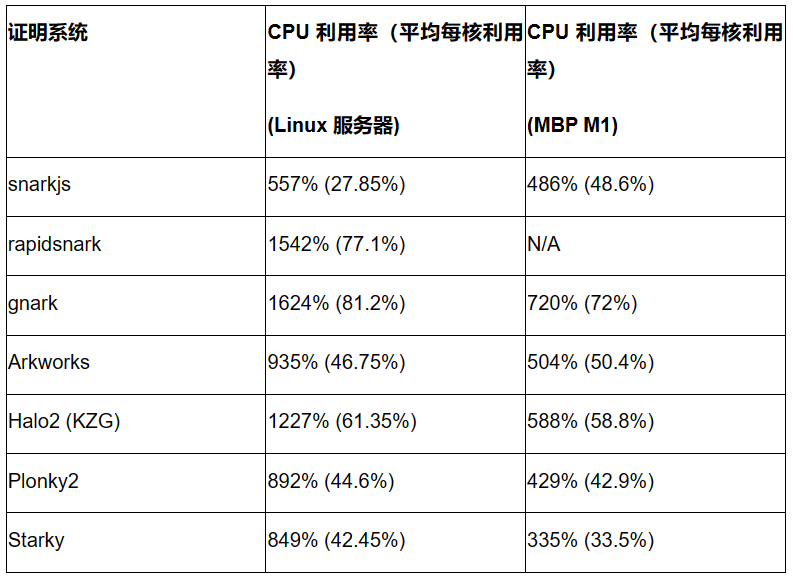
各証明システムの並列化程度を評価するため、4KBプレインテキスト入力時のSHA-256証明生成中の平均CPU利用率を測定しました。下表はLinuxサーバー(20コア)およびMacbook M1 Pro(10コア)における平均CPU利用率(括弧内はコアあたりの平均利用率)を示しています。
主な観察結果は以下の通りです:
-
Linuxサーバーでは、gnarkおよびrapidsnarkが最も高いCPU利用率を示し、多コアを効果的に活用して並列証明生成ができていることがわかります。Halo2も良好な並列化性能を示しています。
-
ほとんどのフレームワークはLinuxサーバーでのCPU利用率がMacbook Pro M1の2倍ですが、snarkjsだけは例外です。
-
当初、FRIベースのフレームワーク(Plonky2、Starky)は多コアを効果的に活用しづらいと予想されていましたが、本パフォーマンステストでは特定のGroth16またはKZGフレームワークより劣っていません。100コアなどのより多くのコアを持つマシンでは、CPU利用率に差が出るかどうかは今後の検討課題です。
結論および今後の研究
本記事では、さまざまなzk-SNARKおよびzk-STARK開発フレームワークにおけるSHA-256のパフォーマンスを包括的に比較しました。比較を通じて、SHA-256操作に簡潔な証明を生成する必要がある開発者にとって、各フレームワークの効率性と実用性に関する深い洞察を得ることができました。
我々の発見は以下の通りです。Groth16フレームワーク(例:rapidsnark、gnark)はPlonkフレームワーク(例:Halo2、Plonky2)より証明生成が高速である。Plonkish算術化におけるルックアップテーブルは、大規模プレインテキストを使用する際にSHA-256の制約数および証明時間を大幅に削減します。また、gnarkおよびrapidsnarkは多コアを活用して並列処理を行う能力に優れています。一方、Starkyは証明生成時間がはるかに短いものの、証明サイズが大幅に大きくなります。メモリ効率に関しては、rapidsnarkおよびStarkyが他を凌駕しています。
「ゼロ知識証明評価プラットフォーム『万神殿 Pantheon』」構築の第一歩として、本パフォーマンステスト結果は最終的な包括的プラットフォームとしては不十分であることを認識しています。フィードバックや批判を歓迎し、誰もがこの取り組みに貢献できるよう呼びかけます。ZKPの利用をより簡単かつ低门槛にし、コミュニティ全体の利益に資するよう、共に効率性と実用性を高めていきたいと思います。また、大規模なパフォーマンステストの計算リソース費用に対し、個人貢献者への資金提供も検討しています。
最後に、パフォーマンステスト結果の貴重なレビューおよびフィードバックを提供してくれたPolygon Zeroチーム、Consensysのgnarkチーム、Pado Labs、Delphinus Labチームに感謝します。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













