

BitTorrent entre dans le domaine de la puissance de calcul IA : BTTInferGrid construit un réseau décentralisé de puissance de calcul pour l’inférence IA
TechFlow SélectionTechFlow Sélection
BitTorrent entre dans le domaine de la puissance de calcul IA : BTTInferGrid construit un réseau décentralisé de puissance de calcul pour l’inférence IA
BTTInferGrid vise à créer un réseau décentralisé de puissance de calcul dédié aux scénarios d’inférence IA, reliant l’offre mondiale de puissance de calcul GPU inutilisée à la demande de puissance de calcul sur le marché de l’inférence IA.
Au fur et à mesure que les agents IA se déployent concrètement dans des scénarios complexes tels que les flux de travail d’entreprise, l’automatisation de la production et l’exécution autonome, l’industrie mondiale de l’IA entre officiellement dans une nouvelle ère passant d’une « réponse passive » à une « exécution autonome ». Le cœur de la concurrence sectorielle s’est déjà éloigné d’une simple course aux paramètres des grands modèles pour se concentrer désormais sur la capacité concrète de déploiement opérationnel. Or, c’est précisément une puissante capacité de raisonnement logique qui constitue la fondation essentielle de cette transition.
Cette transformation paradigmatique des cas d’usage entraîne également un changement fondamental dans les besoins en infrastructures informatiques en amont : la consommation de puissance de calcul se déplace progressivement — et de façon irréversible — de l’entraînement des modèles vers l’inférence opérationnelle. Toutefois, les architectures centralisées dominantes actuelles révèlent, face à des demandes d’inférence massives, fréquentes et fortement fluctuantes (pics et creux), des lacunes critiques telles qu’un coût d’exploitation élevé, une faible capacité d’extension élastique et une stabilité insuffisante du service. L’ensemble du secteur de l’IA rencontre ainsi un goulot d’étranglement structurel au niveau de l’offre de puissance de calcul.
Le 17 juin, BitTorrent, l’un des plus anciens écosystèmes décentralisés de transfert de données, a lancé un produit stratégique majeur — BTTInferGrid — ciblant spécifiquement le segment de l’inférence IA et construisant un réseau décentralisé de puissance de calcul. En s’appuyant sur une architecture distribuée décentralisée, cette plateforme agrège efficacement des ressources GPU éparses et inutilisées à travers le monde, supprime les barrières entre les fournisseurs de ressources et les développeurs IA, et propose un service d’inférence IA ouvert, facile à intégrer, dont les résultats peuvent être vérifiés sur chaîne et facturés à l’usage.

Grâce à ses avantages technologiques décentralisés, BTTInferGrid ne comble pas seulement les lacunes des systèmes centralisés traditionnels dans les scénarios à haut débit et à charge variable, mais réalise également une percée spectaculaire du côté de l’offre de puissance de calcul, redéfinissant entièrement la logique d’allocation et de circulation des ressources au sein de l’écosystème global de calcul.
Par ailleurs, BTTInferGrid est un produit stratégique issu d’une mise à niveau profonde de BTFS, le service existant de BitTorrent. Il s’agit non seulement d’une extension clé de la capacité éprouvée de BitTorrent en matière d’orchestration décentralisée des ressources — depuis le domaine du stockage vers celui du calcul —, mais aussi d’un mouvement décisif dans sa stratégie globale de positionnement sur le marché décentralisé de l’IA.
La structure de la demande en puissance de calcul passe de « l’entraînement » à « l’inférence » : BTTInferGrid reconstruit l’offre de puissance de calcul dédiée à l’inférence IA selon une approche décentralisée
BTTInferGrid vise à reconstruire le système d’offre de puissance de calcul grâce à un modèle décentralisé, afin de résoudre les problèmes de coûts excessifs et de pénurie d’inférence IA. Ce faisant, il permet non seulement de réduire les coûts tout en augmentant l’efficacité, mais aussi d’améliorer sensiblement l’efficacité d’inférence des grands modèles, offrant ainsi à l’industrie une infrastructure de calcul haute performance, hautement résiliente et économiquement compétitive.

Si les années 2024–2025 ont été marquées par la « bataille des milliers de modèles » et la course aux paramètres pilotée par des clusters de dizaines de milliers de cartes GPU, l’année 2026 marque l’avènement de l’« ère de l’inférence », avec le déploiement à grande échelle des agents IA. L’inférence IA constitue la phase cruciale où la valeur des modèles se concrétise : elle transforme les « modèles pré-entraînés » en applications réelles, en valeur commerciale tangible et en services quotidiens. Autrement dit, l’entraînement consiste à « apprendre à l’IA », tandis que l’inférence consiste à « faire fonctionner concrètement l’IA » — par exemple, la reconnaissance d’un panneau « arrêt » par une voiture autonome sur une route jamais empruntée auparavant constitue un cas typique d’inférence. La qualité de l’inférence détermine directement l’expérience utilisateur, les coûts opérationnels et la valeur commerciale des produits IA.
Un consensus général s’est établi dans le secteur : plus de 70 % des ressources de calcul seront consacrées à l’inférence à l’avenir. Oracle avait déjà prédit que le marché de l’inférence dépasserait finalement celui de l’entraînement. De même, l’académicien de l’Académie chinoise des ingénieurs Zheng Weimin souligne que la majeure partie de la puissance de calcul est aujourd’hui consommée lors des interactions quotidiennes entre utilisateurs et grands modèles. Du point de vue de la composition des coûts, l’inférence des grands modèles implique seulement 3 % de coûts humains et 2 % de coûts liés aux données, tandis que la puissance de calcul représente à elle seule 95 % du total. Les coûts sont particulièrement élevés pour les applications phares : ChatGPT dépense environ 700 000 dollars américains par jour pour l’inférence, et DeepSeek V3 atteint 87 000 dollars américains.
Lorsque la demande de puissance de calcul IA passe d’un usage centralisé limité aux géants technologiques (entraînement) à des millions de développeurs issus de tous les secteurs (inférence commerciale), les critères d’évaluation des infrastructures sous-jacentes évoluent également. À l’ère de l’entraînement, les développeurs privilégiaient principalement la concentration et l’efficacité de la puissance de calcul ; à l’ère de l’inférence, les services IA étant directement exposés à des centaines de millions d’utilisateurs finaux, les milliards d’interactions quotidiennes génèrent une consommation massive de puissance de calcul. Les développeurs recentrent donc leur attention sur le coût par appel, la rapidité de réponse et la stabilité du service. Aujourd’hui, l’offre de puissance de calcul, le coût d’appel et la disponibilité du service constituent les critères fondamentaux d’évaluation des infrastructures IA, et déterminent directement la faisabilité du déploiement concret des applications IA.
Pourtant, face à la croissance exponentielle de la demande d’inférence, les faiblesses des systèmes centralisés dominants deviennent de plus en plus criantes : les loyers des GPU continuent d’augmenter, les plateformes subissent fréquemment des interruptions de service, et de nombreuses applications IA doivent même fermer en raison de coûts prohibitifs de puissance de calcul. Ces difficultés se concentrent sur trois points essentiels :
Premièrement, une gestion élastique insuffisante de la puissance de calcul, incapable de suivre les variations de trafic (pics et creux), conduisant à un déséquilibre entre coûts et stabilité : Bien que les grandes entreprises IA et les fournisseurs de services cloud investissent continuellement dans leurs infrastructures de calcul, la demande d’inférence augmente rapidement et présente des caractéristiques nettes de pics et creux — par exemple, les volumes de requêtes peuvent exploser de plusieurs dizaines de fois pendant les heures de bureau ou les campagnes marketing diurnes, puis chuter brutalement la nuit. Les centres de données centralisés manquent d’une capacité dynamique d’orchestration adaptée à ces fluctuations : si la capacité est dimensionnée selon les pics, les coûts d’amortissement deviennent excessifs pendant les périodes creuses ; si elle est calibrée sur la moyenne, les interruptions de service surviennent aux pics. On se retrouve ainsi coincé entre « coût élevé » et « stabilité faible ». Par ailleurs, la puissance de calcul centralisée supporte encore plusieurs couches de coûts supplémentaires (construction de centre de données, électricité, maintenance, marge commerciale), ce qui alourdit considérablement son prix final et réduit fortement l’espace d’expérimentation des petites équipes innovantes. Le marché a donc un besoin urgent de solutions nouvelles alliant avantage coût et capacité d’orchestration élastique.
Deuxièmement, la hausse continue des prix de location des GPU freine l’innovation des PME et des développeurs : Bien que les grands modèles open source (tels que Qwen ou DeepSeek) aient abaissé les seuils d’entrée dans le domaine de l’IA, leur déploiement et leur exécution restent tributaires d’une puissance de calcul d’inférence stable, peu coûteuse et facile à intégrer. Or, la réalité est que les tarifs de location des GPU ne cessent d’augmenter : pour la carte H100, le loyer horaire unitaire est passé de 1,70 dollar américain en octobre 2025 à 2,35 dollars américains en mars 2026, soit une hausse de près de 40 % en six mois. Ces coûts élevés dissuadent de nombreux développeurs indépendants et PME possédant d’excellentes idées, les plongeant dans une impasse « modèles disponibles, puissance de calcul absente », entravant gravement la vitalité innovante et le développement à grande échelle du secteur IA.
Troisièmement, une masse considérable de GPU haut de gamme inutilisés à l’échelle mondiale n’est pas exploitée efficacement, créant une grave disjonction offre-demande : En contraste frappant avec la « pénurie de puissance de calcul » observée sur le marché, des quantités massives de ressources GPU hautes performances inutilisées sont dispersées à travers le monde — sur des équipements personnels, dans des laboratoires universitaires, dans de petits centres de données ou encore dans des installations héritées de la transition minière cryptographique. Faute de canaux normalisés d’accès et de moteurs d’orchestration efficaces, ces ressources ne peuvent pas rejoindre le marché principal de l’inférence, créant une situation paradoxale où la demande souffre d’un « manque critique d’une seule carte » tandis que l’offre voit ses « GPU dormir » sans être activés. Le taux d’utilisation des ressources présente donc un potentiel énorme d’amélioration, et cette disjonction offre-demande exige une solution urgente.
En résumé, le marché actuel de la puissance de calcul dédiée à l’inférence IA fait face à trois blocages structurels simultanés : d’un côté, l’offre centralisée ne parvient pas à concilier coûts maîtrisés et flexibilité opérationnelle ; de l’autre, la hausse continue des loyers de puissance de calcul étouffe l’innovation IA ; et enfin, des millions de GPU inutilisés demeurent inactifs malgré leur disponibilité potentielle. Face à cette série de défis sectoriels, BTTInferGrid apporte une solution novatrice, fondée sur la technologie décentralisée, pour résoudre la disjonction structurelle entre offre et demande.
BTTInferGrid vise à connecter efficacement, via une approche décentralisée, les ressources GPU inutilisées dispersées à travers le monde avec la multitude de développeurs IA, brisant radicalement le monopole et les goulots d’étranglement des systèmes centralisés. D’une part, la plateforme intègre des ressources GPU fragmentées et inutilisées pour construire une infrastructure ouverte et partagée de puissance de calcul. D’autre part, elle établit un canal fluide entre l’offre et la demande, supprimant les barrières d’accès et l’opacité tarifaire inhérentes aux modèles centralisés traditionnels. En outre, grâce aux mécanismes d’incitation et de coordination propres au DePIN (Decentralized Physical Infrastructure Networks), BTTInferGrid fournit continuellement une puissance de calcul d’inférence hautement compétitive, attaquant ainsi à la racine les deux problèmes centraux — coûts excessifs et pénurie d’offre — et libérant pleinement l’efficacité inférentielle et la valeur commerciale des grands modèles.
BTTInferGrid : Construire un réseau décentralisé de puissance de calcul dédié à l’inférence IA, trois avantages redéfinissent les mécanismes d’allocation des ressources
BTTInferGrid adopte une position claire et précise : il se concentre exclusivement sur la construction d’un réseau décentralisé de puissance de calcul dédié à l’inférence IA, reliant l’offre mondiale de ressources GPU inutilisées aux besoins du marché de l’inférence IA, et proposant un service global de puissance de calcul IA ouvert, vérifiable sur chaîne et facturé à l’usage.
Plus concrètement, BTTInferGrid s’appuie sur les mécanismes sous-jacents du réseau DePIN pour appairer avec précision l’offre de puissance de calcul et la demande explosive en inférence IA, générant ainsi une valorisation mutuelle bilatérale :
- Côté offre de puissance de calcul, il agrège efficacement les ressources GPU fragmentées et inutilisées à l’échelle mondiale afin de construire une base de puissance de calcul ouverte et partagée. Grâce aux mécanismes d’incitation et d’orchestration intelligente du DePIN, il crée d’une part un canal de monétisation accessible et durable pour les détenteurs de puissance de calcul, transformant ainsi les GPU « endormis » du globe en « actifs fluides » ; d’autre part, il garantit la stabilité et la capacité d’extension élastique de la puissance de calcul, assurant ainsi un service d’inférence global hautement compétitif, extensible et sécurisé.
- Côté demande de puissance de calcul, il propose aux développeurs IA du monde entier un service d’inférence global facile à intégrer, dont les résultats sont vérifiables sur chaîne et facturés à l’usage. Comparé aux tarifs surévalués des fournisseurs cloud centralisés, BTTInferGrid offre un avantage concurrentiel extrême en matière de coûts et une capacité d’extension élastique remarquable, permettant aux petites équipes technologiques et aux développeurs indépendants de réduire significativement leurs coûts d’expérimentation, de valider rapidement leurs produits et d’accélérer leurs itérations commerciales, tout en renforçant rétroactivement l’écosystème d’offre de puissance de calcul en amont.
Ainsi, BTTInferGrid répond concrètement aux besoins pressants des développeurs IA — à un stade crucial de « confrontation commerciale » — en matière de puissance de calcul peu coûteuse et hautement élastique, tout en ouvrant, pour les ressources matérielles inutilisées à l’échelle mondiale, un canal viable et durable de création de valeur.
Plus important encore, BTTInferGrid réussit à créer une boucle vertueuse auto-alimentée : l’ajout continu de nœuds GPU inutilisés réduit les coûts d’inférence, attirant davantage de développeurs ; la montée constante de la demande incite à son tour davantage de fournisseurs mondiaux de puissance de calcul à rejoindre l’écosystème. En réinventant l’offre de puissance de calcul selon un modèle décentralisé, BTTInferGrid transforme une ressource spécialisée, rare et coûteuse — la puissance de calcul IA — en une infrastructure fondamentale publique, universellement accessible et appelée à la demande.
Sur le plan des performances techniques, la plupart des plateformes décentralisées de GPU existantes sur le marché souffrent actuellement de problèmes tels qu’un seuil d’accès élevé à la puissance de calcul, une fiabilité insuffisante des services et un modèle économique difficile à pérenniser à long terme. BTTInferGrid, quant à lui, procède à une optimisation fondamentale de son architecture sous-jacente, réalisant des percées complètes sur trois axes critiques — agrégation de la puissance de calcul, vérification des services et durabilité du modèle économique — et développant ainsi une compétitivité unique, dont les avantages spécifiques sont les suivants :
1. Un réseau ouvert d’offre de puissance de calcul, capable de rassembler rapidement les ressources GPU inutilisées à l’échelle mondiale : Contrairement aux seuils d’accès élevés des fournisseurs cloud traditionnels (exigence de salles de serveurs certifiées, d’adresses IP publiques fixes, de commutateurs coûteux, etc.), BTTInferGrid construit un réseau véritablement ouvert d’offre de puissance de calcul. Toute entité ou individu disposant de ressources GPU inutilisées peut y accéder sans friction, dès lors qu’il remplit les exigences minimales de performances (capacité de mémoire vidéo, puissance de calcul de référence) et de stabilité réseau. Cette conception abaisse radicalement le seuil de participation côté offre, permettant ainsi une convergence ultra-rapide, en réseau et en matrice, des ressources GPU inutilisées à l’échelle mondiale.
2. Une qualité de service et un comportement des nœuds vérifiables, résolvant le défi fondamental de la confiance décentralisée : Le principal obstacle des calculs décentralisés réside dans la question de la confiance : comment empêcher les mineurs d’utiliser des cartes graphiques bas de gamme pour simuler des performances hautes ? Comment garantir que les résultats d’inférence sont réellement fiables ? BTTInferGrid construit un cycle fermé vérifiable par quatre leviers complémentaires — orchestration des tâches (répartition intelligente), vérification par défis (échantillonnage cryptographique aléatoire), notation par consensus (score de réputation dynamique) et coordination sur chaîne (contrats intelligents régulant les récompenses et sanctions). Ce dispositif renforce efficacement la fiabilité des services d’inférence.
3. Un modèle économique piloté par la demande réelle, assurant la pérennité de l’écosystème : De nombreux projets DePIN initiaux ont connu une spirale mortelle : une forte émission de jetons pour attirer aveuglément les nœuds vers le minage, suivie d’une inflation des jetons, d’un effondrement des prix et d’un départ massif des nœuds, faute de demande réelle. Dès ses premières étapes, BTTInferGrid a choisi de bâtir un écosystème économique piloté par la demande réelle — où les appels d’inférence authentiques et les performances réelles des nœuds constituent les seules bases d’incitation. Seuls les fournisseurs de puissance de calcul reçoivent une part des revenus et des bonus de réputation lorsque les développeurs IA paient effectivement pour utiliser des modèles. Ce mécanisme favorise une croissance harmonieuse et adaptée entre l’offre et la demande, garantissant ainsi la santé et la pérennité à long terme de l’écosystème.
En résumé, depuis la suppression des barrières d’accès traditionnelles — permettant à n’importe quel GPU inutilisé conforme aux spécifications techniques d’entrer sans friction dans le réseau d’offre ouvert — jusqu’à la construction d’un rempart de confiance vérifiable à chaque étape, reposant sur une orchestration des tâches, des défis de vérification, une notation par consensus et des récompenses/sanctions sur chaîne, en passant par l’abandon complet des bulles spéculatives et l’ancrage des incitations sur la demande réelle d’inférence IA — BTTInferGrid redéfinit l’allocation des ressources de puissance de calcul selon trois dimensions fondamentales : la consolidation des ressources, la fiabilité des services et la répartition équitable de la valeur.
BTTInferGrid développera progressivement un nouvel écosystème de puissance de calcul piloté par la demande réelle
BTTInferGrid ne se contente pas d’« agréger de la puissance de calcul » de façon simpliste. Il s’agit d’un réseau décentralisé de puissance de calcul sophistiqué, intégrant des fonctions multiples telles que la planification et l’exécution des tâches d’inférence IA, la mise en relation intelligente et dynamique entre offre et demande, ainsi que la coordination et le règlement des ressources sur chaîne.
Dans l’écosystème décentralisé de puissance de calcul de BTTInferGrid, tous les participants s’organisent autour des trois fonctions fondamentales de la puissance de calcul — « fournir », « utiliser » et « vérifier » — formant ainsi trois rôles centraux :
- Fournisseurs de puissance de calcul (mineurs) : ils mettent à disposition leurs ressources GPU inutilisées, traitent et exécutent les tâches d’inférence IA. Le système attribue automatiquement des récompenses proportionnelles au volume effectif de travail validé, à la qualité d’exécution des tâches et au score de performance dynamique.
- Demandeurs de puissance de calcul (développeurs IA) : BTTInferGrid fournit une interface API standardisée, permettant aux développeurs d’accéder aux ressources GPU distribuées à l’échelle mondiale.
- Gardiens du réseau (validateurs) : ils participent au système décentralisé de vérification et de notation, auditant et lançant des défis aléatoires aux performances des nœuds mineurs, identifiant les comportements anormaux et préservant la qualité du service réseau. En contrepartie, ils reçoivent des récompenses pour avoir contribué à l’intégrité du réseau, garantissant ainsi l’équité et la fiabilité du système.
En synthèse, pour les développeurs IA, BTTInferGrid offre un service d’inférence IA plus rentable, hautement extensible et parfaitement fiable, atténuant efficacement les interruptions de produit et les pertes de clients causées par les pénuries de puissance de calcul. Pour les fournisseurs de GPU, il active les ressources matérielles marginales et inutilisées à l’échelle mondiale, créant un canal de revenus durable pour les détenteurs de GPU et permettant à chaque unité de puissance de calcul de produire sa juste valeur dans l’ère de l’inférence.
Concrètement, contrairement au modèle « lourd » des fournisseurs cloud centralisés — qui consiste à « construire d’abord l’infrastructure matérielle, puis attendre la demande » — les projets DePIN rencontrent naturellement, dès leur lancement, un défi double de coordination : une offre excédentaire conduit à l’inactivité des nœuds et à l’effondrement de l’économie des jetons, tandis qu’une offre insuffisante nuit à l’expérience des développeurs et à l’efficacité du système. C’est pourquoi BTTInferGrid a adopté une stratégie de démarrage claire, robuste et orientée demande, évitant toute croissance désordonnée et privilégiant d’abord l’optimisation du taux d’utilisation des ressources, la viabilité économique et l’expansion progressive de l’architecture technique.
- Objectif à court terme (2026) : démarrage à froid du réseau, validation des nœuds centraux fondamentaux et du service d’inférence distribué, puis expansion progressive du nombre de nœuds GPU.
- Objectif à moyen terme (2027) : diversification de l’écosystème, amélioration de la stabilité et de la sécurité des données du réseau, compatibilité accrue avec davantage de formats de modèles IA et de frameworks d’inférence, extension progressive vers des cas d’usage comme l’ajustement fin des modèles.
- Objectif à long terme (à partir de 2028) : devenir l’infrastructure fondamentale native IA, constituer la couche de puissance de calcul privilégiée pour les agents IA et les applications automatisées, fournir un soutien élastique à l’échelle industrielle pour les applications IA massives, et finalement assurer une coordination harmonieuse entre puissance de calcul, stockage distribué et contrats intelligents sur chaîne au sein d’une architecture unifiée.
Dans sa mise en œuvre concrète, BTTInferGrid suit également une stratégie d’évolution progressive. Au lancement, le réseau repose principalement sur des cartes graphiques professionnelles, et l’accès des fournisseurs de puissance de calcul (mineurs) est soumis à une validation préalable ; les utilisateurs demandeurs peuvent déjà utiliser le service d’inférence via la plateforme. À l’avenir, il évoluera vers une grille super-mondiale entièrement ouverte : prise en charge de types variés de GPU (grand public, professionnels, centre de données), intégration et tarification différenciées selon les niveaux de performance ; ouverture complète de l’accès aux mineurs, accompagnée de mécanismes de mise en gage (staking) pour garantir la qualité du service ; ouverture d’une interface API unique côté demande, compatible avec divers formats de modèles IA et frameworks d’inférence, offrant des options de déploiement souples.
À ce jour, BTTInferGrid a déjà intégré avec succès plusieurs grands modèles IA open source largement utilisés, notamment la série Qwen d’Alibaba Cloud — Qwen3.6 27B et Qwen2.5 7B Instruct — ainsi que Llama 3.1 8B Instruct de Meta. Les développeurs IA peuvent ainsi invoquer ces modèles de façon flexible et à la demande, selon leurs scénarios métiers spécifiques. À l’avenir, la plateforme poursuivra l’élargissement de son écosystème de modèles, offrant aux développeurs un soutien accru pour les modèles les plus avancés.
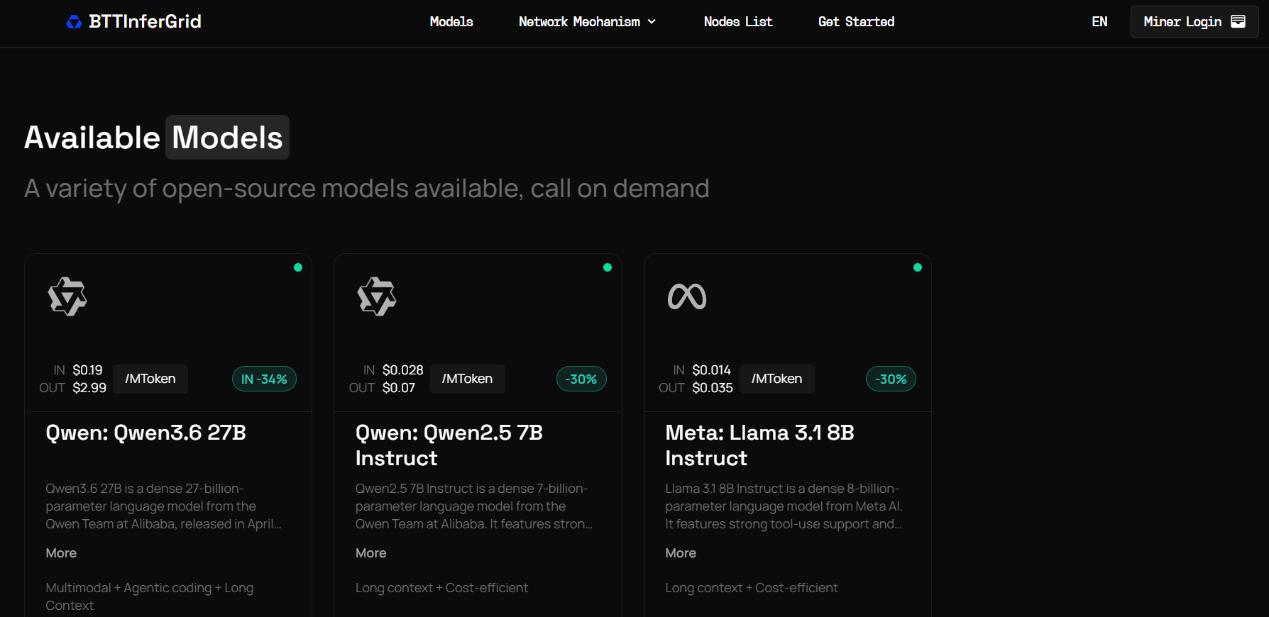
Plus important encore, BTTInferGrid bénéficie d’un solide socle constitué par les acquis accumulés au fil des années par BitTorrent et BTFS, ce qui lui confère un avantage de développement naturel. BitTorrent et son service BTFS ont approfondi pendant de nombreuses années le domaine du stockage décentralisé : BitTorrent compte plus de 100 millions d’utilisateurs actifs et plus de 2 milliards d’installations, ayant ainsi démontré avec succès la faisabilité du modèle DePIN et accumulé une expertise éprouvée dans les domaines de l’intégration des ressources, des incitations par jetons, des règlements sur chaîne et de l’animation communautaire. En tant que produit stratégique de BitTorrent pour le secteur IA, BTTInferGrid, issu d’une mise à niveau de BTFS, peut transférer sans heurt cette expertise mature vers le domaine de la puissance de calcul dédiée à l’inférence IA, accélérant ainsi la croissance de l’écosystème.
Grâce à la technologie décentralisée, BTTInferGrid résout avec précision le dilemme industriel paradoxal où « puissance de calcul inutilisée » et « pénurie de puissance de calcul » coexistent. Son concept d’accès ouvert, de collaboration décentralisée, de contribution vérifiable et de construction collective par la communauté ne constitue pas seulement une percée décisive contre le monopole des systèmes centralisés de puissance de calcul, mais dessine également, grâce à une position produit claire et une base technologique solide, un nouveau plan ambitieux pour une infrastructure mondiale de puissance de calcul décentralisée. Ici, chaque unité de puissance de calcul inutilisée sera activée, et chaque développeur pourra accéder à l’avenir intelligent à un coût abordable.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













