

Analyse approfondie de $VVV : des infrastructures privées pour l’IA et une courbe de croissance sous-évaluées
TechFlow SélectionTechFlow Sélection
Analyse approfondie de $VVV : des infrastructures privées pour l’IA et une courbe de croissance sous-évaluées
Décortiquer la chaîne complète de Venice, de son architecture de confidentialité à son modèle économique.
Auteur : Yan Liberman
Traduction et synthèse : TechFlow
Introduction de TechFlow : Les données d’abonnements récentes de Venice, couvrant les trois dernières semaines, montrent une accélération remarquable du taux de croissance de l’ARR (revenu annuel récurrent) nouvellement généré, atteignant 34 %. À sa capitalisation boursière actuelle, l’entreprise est valorisée à seulement 2,5 fois ses revenus attendus sur les 12 prochains mois. Cet ancien investisseur crypto démonte l’ensemble de la chaîne de valeur de Venice — de son architecture axée sur la confidentialité à son modèle économique — et estime que le marché sous-évalue gravement la taille réelle du segment émergent de « l’inférence IA privée », ainsi que l’avantage concurrentiel unique de Venice dans ce domaine, fondé sur une combinaison inégalée de fonctionnalités. Il adopte une position haussière sur le jeton $VVV.

Venice est une plateforme d’inférence IA priorisant la confidentialité, permettant aux utilisateurs d’exploiter des modèles de pointe ou open source sans révéler leur identité au fournisseur sous-jacent du modèle. Je considère qu’il s’agit actuellement de la solution de confidentialité la plus complète disponible sur le marché de l’IA : un proxy anonyme, un routage vers des modèles open source, une inférence sécurisée via des environnements confidentiels matériels (TEE) certifiés par matériel, et une inférence entièrement chiffrée de bout en bout — ces quatre fonctions sont intégrées dans un produit grand public, avec un mode de confidentialité pouvant être sélectionné pour chaque requête. Aucun autre acteur ne propose simultanément ces quatre caractéristiques.
Ce modèle économique connaît une croissance soutenue. Les discussions sur Crypto Twitter concernant Venice sous-estiment généralement à la fois ses revenus actuels, sa croissance récente et sa trajectoire future. Venice a récemment commencé à publier des données quotidiennes sur ses abonnements ; les données granulaires couvrant trois semaines révèlent clairement une accélération marquée de l’ARR généré par les nouveaux abonnements :
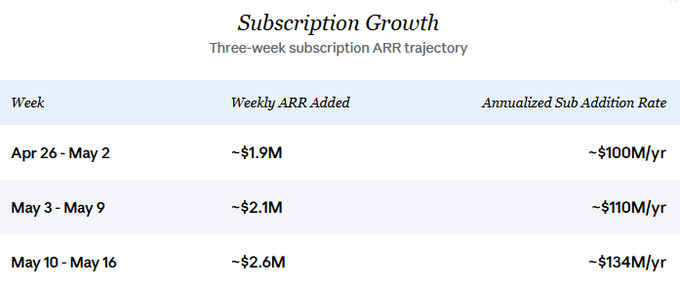
Cette dynamique de croissance continue constitue l’hypothèse centrale de cette analyse. Je suppose également que les revenus issus de l’API évoluent en parallèle avec la croissance des abonnements — hypothèse détaillée plus loin dans la section « Situation actuelle et croissance ». En prenant comme point d’ancrage conservateur une croissance annuelle de 100 millions de dollars pour les nouveaux abonnements (niveau observé fin avril), et en supposant une croissance équivalente pour l’API, l’augmentation totale des revenus sur les 12 prochains mois serait d’environ 200 millions de dollars.
L’accélération récente observée suggère que, si ce rythme se maintient, les chiffres réels offriront une marge significative de hausse.
Cet article décortique systématiquement les spécificités de Venice :
- Niveau de confidentialité : une architecture de confidentialité bien plus profonde que la simple notion standard de « chat IA privé ».
- Catégorie d’utilisateurs : les utilisateurs de Venice sont essentiellement exclus des voies dominantes (politiques de contenu, conformité, modèles de menace, principes éthiques), plutôt que séduits par des campagnes marketing.
- Taille du marché : un marché de l’inférence segmentée axé sur la confidentialité, en constante expansion, souvent sous-estimé par les cadres d’analyse centrés sur les chats grand public.
- Paysage concurrentiel : Venice combine confidentialité renforcée, accès non censuré aux modèles et distribution nativement cryptographique — une combinaison actuellement unique parmi ses concurrents.
- Conception du jeton et valorisation de $VVV : comment les mécanismes de VVV et DIEM transforment la croissance de la plateforme en valeur pour le jeton, et comment la valorisation de VVV se compare à celle d’acteurs similaires spécialisés dans l’inférence privée tels qu’OpenRouter, Fireworks ou Together AI.
Après une récente vague haussière suivie d’un recul jusqu’à 14 dollars, la capitalisation boursière de VVV s’élève à environ 660 millions de dollars, tandis que sa valorisation pleinement diluée (FDV) atteint environ 1,12 milliard de dollars. Son ARR actuel est estimé à environ 60 millions de dollars (calculé plus bas dans la section « Situation actuelle et croissance »), augmentant d’environ 200 millions de dollars par an, avec une accélération encore en cours. Sur la base de l’ARR actuel, le ratio cours/chiffre d’affaires de VVV est d’environ 11x (FDV ≈ 19x), inférieur au ratio de 26x d’OpenRouter, un acteur comparable spécialisé dans l’inférence privée. En revanche, sur la base d’un ARR projeté sur 12 mois d’environ 260 millions de dollars (60 millions de dollars actuels + 200 millions de dollars de croissance annuelle), le ratio cours/chiffre d’affaires de VVV tombe à environ 2,5x (FDV ≈ 4,3x).
Situation actuelle et croissance
Venice a récemment commencé à publier des données quotidiennes sur les nouveaux abonnements. Combinées aux annonces publiques régulières sur les jalons atteints en matière d’utilisateurs inscrits, ces deux flux de données me permettent d’estimer l’ARR actuel et de projeter sa trajectoire future.
Pour estimer l’ARR actuel, je commence par le nombre total d’inscriptions. Selon le rythme des annonces publiques sur une période donnée, le nombre total d’inscrits augmente régulièrement d’environ 300 000 par mois. Le dernier jalon confirmé indique environ 3 millions d’utilisateurs inscrits au 16 mai 2026, contre environ 2 millions au 1er février, ce qui correspond bien à une croissance mensuelle de 300 000. En supposant un taux de conversion payant à vie d’environ 5 % (ce qui pourrait être conservateur, compte tenu de la vitesse accrue de conversion observée récemment chez les nouveaux inscrits), cela signifie qu’au milieu du mois de mai, il y avait environ 150 000 abonnés payants actifs. Jusqu’à la mi-fin avril, seul le forfait Pro mensuel à 18 dollars était disponible ; les lancements des forfaits Pro+ (68 dollars/mois) et Max (200 dollars/mois) ont commencé à modifier cette structure, mais la grande majorité des utilisateurs payants restent encore sur le forfait à 18 dollars. Le revenu moyen par utilisateur payant (ARPPU) pondéré se situe donc entre 18 et 19 dollars par mois, ce qui implique un revenu mensuel récurrent (MRR) d’abonnements d’environ 2,8 millions de dollars, soit un ARR d’abonnements d’environ 33 millions de dollars. Ceci ne concerne que la composante abonnement ; les revenus issus de l’API seront ajoutés plus tard dans cette section afin d’obtenir une estimation complète de l’ARR actuel.
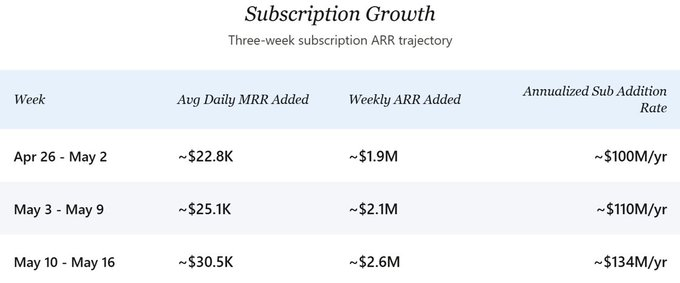
En ce qui concerne la trajectoire future, la croissance de l’ARR généré par les nouveaux abonnements s’accélère continuellement. À la fin avril, l’entreprise ajoutait environ 2 millions de dollars d’ARR d’abonnements par semaine. La semaine dernière (du 10 au 16 mai), ce chiffre a bondi à environ 2,6 millions de dollars par semaine, soit une croissance annuelle équivalente à 134 millions de dollars. Dans le scénario central de cette analyse, je retiens un chiffre conservateur de 100 millions de dollars par an, afin d’éviter de surestimer l’accélération récente. La croissance nette, après déduction du taux de désabonnement, serait légèrement inférieure, mais à l’échelle actuelle, cet écart est négligeable en termes de direction stratégique ; la croissance brute constitue donc le cœur de l’analyse prospective présentée ici.
Les données granulaires couvrant trois semaines (du 26 avril au 16 mai) révèlent une progression nette :
Dans la première semaine, l’augmentation quotidienne du MRR a progressé d’environ 34 % d’une semaine à l’autre. En supposant que les revenus issus de l’API suivent le MRR issu des nouveaux abonnements dans une proportion de 1:1 (explication fournie ci-dessous), la croissance annuelle totale implicite passe ainsi d’environ 200 millions de dollars à environ 268 millions de dollars. Deux facteurs semblent impulser ce changement de cap : le lancement des forfaits Pro+ et Max offre désormais aux utilisateurs disposés à payer davantage une option qui leur manquait auparavant, améliorant ainsi l’ARPPU pondéré ; par ailleurs, le taux de conversion payant semble s’accélérer suite à l’élargissement de l’offre de forfaits.
Les revenus issus de l’API sont plus difficiles à mesurer, car ils ne font pas l’objet d’une divulgation directe. Mon scénario de base est que les revenus opérationnels récents générés par l’API représentent approximativement 100 % des nouveaux revenus mensuels récurrents issus des abonnements (MRR), alors que le ratio historique était inférieur. Le résultat est que la base actuelle d’ARR issue de l’API, bien que substantielle, reste légèrement inférieure à celle issue des abonnements, mais tend progressivement à rejoindre ce niveau.
L’hypothèse d’une répartition 50/50 repose initialement sur des comparaisons avec des pairs. Sur les grandes plateformes de modèles fermés, l’API de ChatGPT représente environ 25 % des revenus, contre 75 % pour les abonnements, grâce à une base massive d’utilisateurs grand public qui réduit la part relative de l’API. Chez Anthropic, l’API représente environ 80 % des revenus, contre 20 % pour les abonnements, car sa clientèle est principalement composée de développeurs et d’entreprises. Venice se situe structurellement entre ces deux extrêmes : sa position axée sur la confidentialité ne séduit pas autant le grand public que ChatGPT, mais sa base d’utilisateurs payants est plus large que le mélange très orienté entreprises d’Anthropic. Une répartition 50/50 tombe donc logiquement au milieu de ce spectre.
Ce cadre est renforcé par deux éléments spécifiques à Venice.
Tout d’abord, l’API de Venice a déjà établi de nombreux canaux de distribution auprès des développeurs. OpenRouter route les modèles de Venice, Fleek définit par défaut Venice comme fournisseur d’inférence pour tous ses agents hébergés, Cursor, Brave Leo (via BYOM) et les extensions communautaires de VSCode prennent toutes en charge Venice. Ces intégrations se sont accumulées au cours de la dernière année, étayant l’argument selon lequel l’API est une activité réelle et importante, alimentée par un trafic de production à grande échelle.
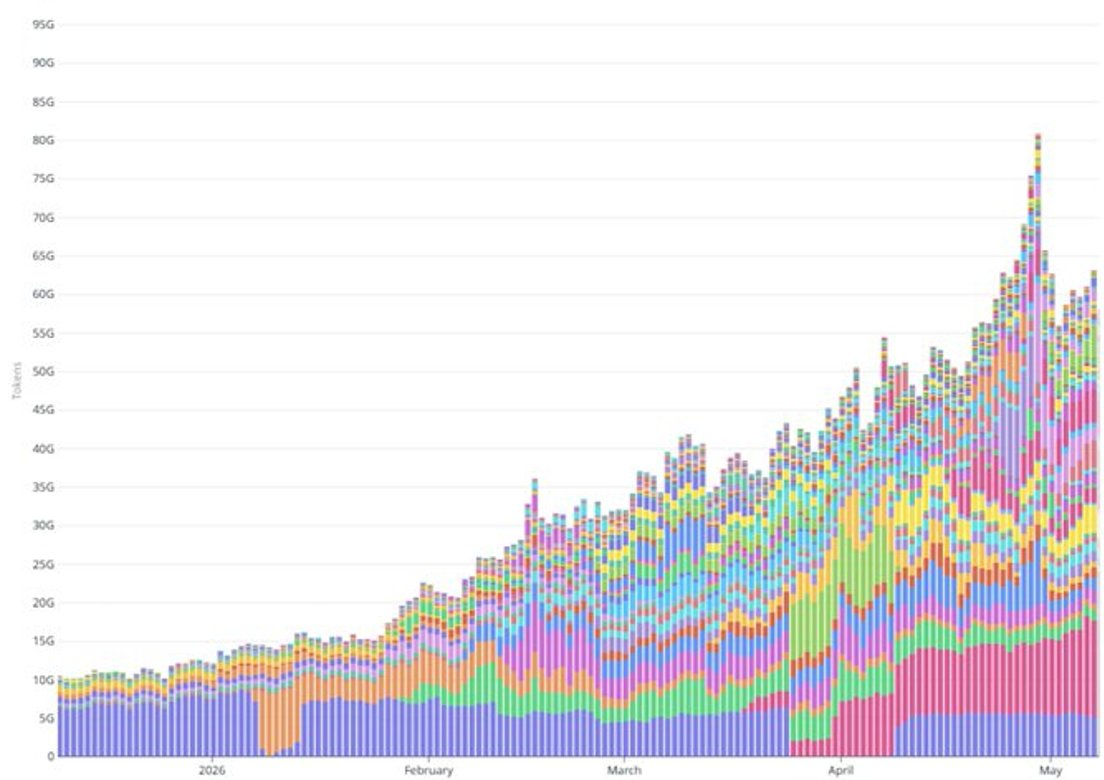
Deuxièmement, la hausse récente du volume de tokens traités dépasse largement ce que pourrait expliquer la seule croissance des abonnements. Le volume quotidien de tokens est passé de 20 milliards début février à plus de 60 milliards début mai, soit une multiplication par trois en trois mois. Pendant cette même période, la base d’abonnés payants n’a augmenté que d’environ 50 % (passant de 100 000 à environ 150 000). L’élargissement de l’offre avec les forfaits Pro+/Max début avril n’a conduit qu’une petite fraction des nouveaux inscrits à choisir des forfaits à ARPPU plus élevé ; même en faisant des hypothèses généreuses sur la consommation de tokens par utilisateur pour ces forfaits, on ne peut pas combler cet écart. La majeure partie de cette augmentation semble provenir de charges de travail facturées à l’usage via l’API : déploiement d’agents intelligents, augmentation du trafic de production par les partenaires d’intégration, et autres cas d’usage à forte intensité.
L’estimation de l’ARR actuel issu de l’API est plus complexe que celle issue des abonnements, car le ratio 1:1 semble n’avoir émergé que récemment ; avant mi-avril, la part de l’API était probablement plus faible. En adoptant une hypothèse médiane selon laquelle la part de l’API a historiquement représenté environ 70 à 80 % de celle des abonnements, avant d’atteindre récemment le ratio 1:1, l’ARR actuel issu de l’API est estimé entre 25 et 30 millions de dollars. L’ARR total actuel est donc estimé entre 55 et 65 millions de dollars, avec un point médian autour de 60 millions de dollars.
Une précision s’impose concernant la composante API : elle repose sur une annualisation des revenus opérationnels courants, et non sur des engagements récurrents d’abonnement, ce qui la rend intrinsèquement plus volatile que la composante abonnement. Une diminution notable de l’usage par un client majeur de l’API pourrait entraîner une baisse significative des revenus opérationnels, sans provoquer de désabonnement similaire dans la base d’abonnés.
Une vérification croisée avec les revenus depuis le début de l’année : le volume quotidien de tokens étant passé de 20 milliards début février à plus de 60 milliards début mai, Venice a déjà généré au moins 30 millions de dollars de revenus cumulés en 2026. Ce chiffre est cohérent avec une fourchette d’ARR actuel comprise entre 55 et 65 millions de dollars, une base qui croît rapidement vers une vitesse de croissance annuelle de 200 millions de dollars.
Il est important de noter que la vitesse de croissance annuelle de l’ARR ne correspond pas directement au montant de revenus gagnés sur une période de 12 mois. Le nouvel ARR augmente linéairement au cours de l’année, donc une vitesse de croissance annuelle de 200 millions de dollars, si elle se maintient tout au long de 2026, se traduit par environ 100 millions de dollars de nouveaux revenus gagnés sur l’année, auxquels s’ajoutent environ 60 millions de dollars provenant de la base actuelle d’ARR. Le revenu total gagné sur les 12 prochains mois devrait donc se situer entre 150 et 200 millions de dollars, tandis que l’ARR à la fin de cette période de 12 mois sera d’environ 260 millions de dollars (avant déduction du désabonnement) — soit 60 millions de dollars actuels + 200 millions de dollars de croissance d’ARR.
Un regard rétrospectif n’est ici qu’une note marginale. La vitesse actuelle de croissance annuelle de l’ARR de Venice est d’environ 200 millions de dollars ; la véritable question est de savoir si ce rythme actuel constitue un plancher ou un point de départ. Les variables clés sont : la persistance de la croissance des abonnements, la poursuite de la croissance de l’usage de l’API à un rythme supérieur à celui des abonnements, le niveau de désabonnement qui apparaîtra à mesure que la file d’attente mûrira, et la capacité du marché adressable à soutenir une croissance continue à ce rythme.
La question de la taille du marché devient plus facile à répondre une fois que l’on comprend précisément ce que fait Venice. La base la plus claire est une « échelle de confidentialité » pour les interactions avec les modèles de langage (LLM), où chaque niveau représente un ensemble différent d’hypothèses en matière de confidentialité, et où le modèle de Venice s’inscrit dans un niveau spécifique.
Niveaux de confidentialité
L’échelle ci-dessous classe l’utilisation de l’IA basée sur le cloud selon un axe étroit mais crucial : qui peut associer le texte brut des prompts à l’identité de l’utilisateur ? Elle ne résout pas tous les problèmes de confidentialité. L’infiltration des appareils, les traces de paiement, les métadonnées de compte, les risques liés aux assignations à comparaître et la sécurité des points de terminaison restent des questions indépendantes. Toutefois, elle clarifie concrètement ce qui change lorsque l’utilisateur passe d’un chatbot par défaut à un mode de confidentialité plus élevé chez Venice. Les numéros de niveau (0 à 7) sont de mon invention, afin de placer Venice dans un contexte plus large. La classification propre à Venice utilise uniquement quatre modes nommés : Anonymous (Anonyme), Private (Privé), TEE et E2EE, correspondant respectivement aux niveaux 3, 4, 6 et 7 ci-dessous.
L’option de confidentialité la plus forte n’apparaît pas sur cette échelle. Exécuter des modèles open source sur du matériel que vous possédez, sans aucune implication du cloud, bat toutes les options suivantes. Exécuter GLM 5.1 ou Qwen 3.6 sur un Mac puissant ou une station de travail, sans appel réseau ni intervention tierce. Rien ne vaut l’expression « le prompt ne quitte jamais ma machine », à condition que celle-ci soit correctement sécurisée. Mais ce n’est pas la voie empruntée par la plupart des gens. Le matériel est coûteux. Les modèles open source exécutables localement restent en retrait par rapport aux modèles de pointe des laboratoires fermés pour les tâches les plus complexes. Vous perdez les intégrations et l’exécution continue dans le cloud 24h/24, et vous assumez la responsabilité de la maintenance de toute la pile technique. En mettant de côté le déploiement local, l’échelle ci-dessous couvre les options réalistes d’inférence basée sur le cloud.
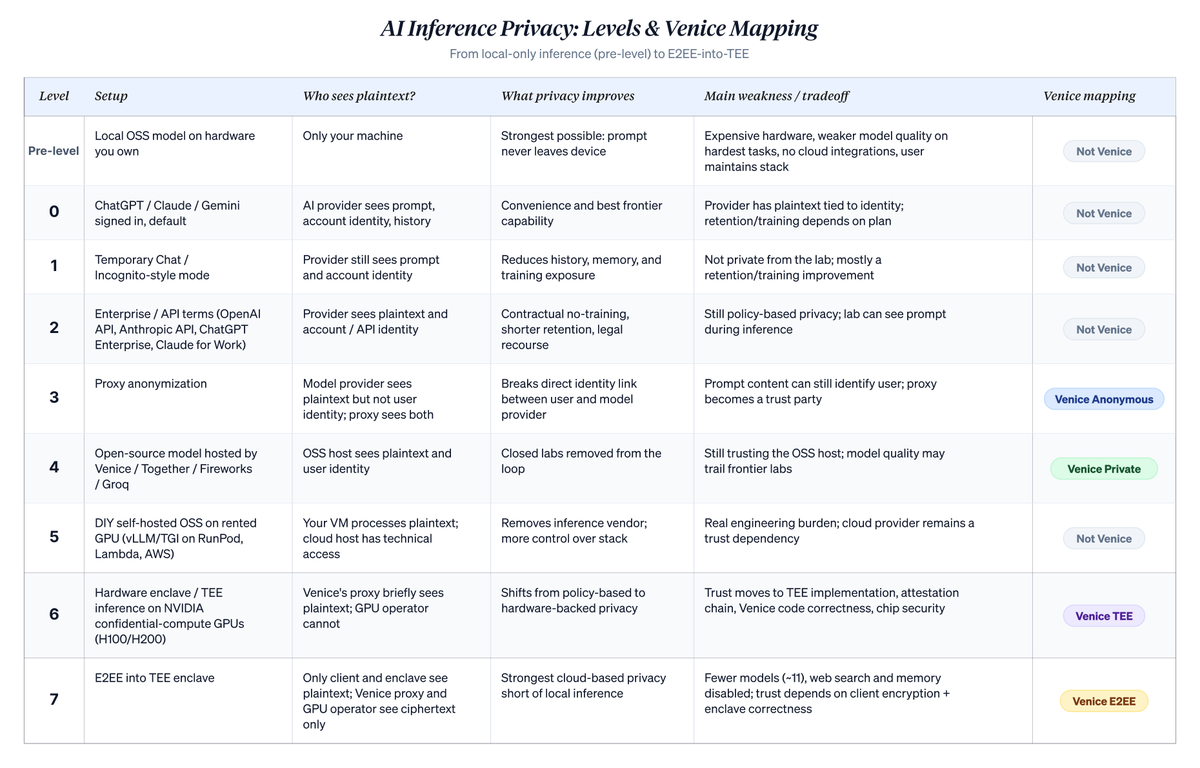
La décomposition détaillée niveau par niveau suit, accompagnée de métaphores illustratives :
Niveau 0 : « ChatGPT, Claude ou Gemini, connecté, état par défaut. » Vos prompts sont envoyés au laboratoire associé à votre compte. Ils savent qui vous êtes et ce que vous demandez. Dans les forfaits grand public, vos conversations peuvent être utilisées pour améliorer les futurs modèles, sauf si vous choisissez explicitement de ne pas y participer, et elles sont stockées dans votre historique de discussion côté serveur. Des engagements réels existent (pas de vente des données, durées de conservation limitées, contrôle de suppression), mais vous êtes identifié(e), vos données sont conservées, et vos conversations peuvent entrer dans le processus d’entraînement dans le cadre des forfaits grand public. La majorité des utilisateurs se trouvent à ce niveau. D’un point de vue architectural, tout service de consommation d’API hébergé, quelle que soit la localisation du fournisseur, adopte la même posture. Les offres hébergées des fournisseurs chinois (version hébergée de DeepSeek, GLM/智谱, MiniMax, Qwen en connexion directe) se situent au même niveau architectural : le fournisseur voit le texte brut, l’identité est liée au compte, et les politiques de conservation et d’entraînement varient selon le fournisseur. Les utilisateurs choisissent généralement ces services pour leur prix, car ils sont souvent nettement moins chers qu’Anthropic ou OpenAI. La juridiction applicable à vos données dépend du fournisseur spécifique, du point de terminaison que vous utilisez, de votre région géographique et de vos contrats. Ne supposez pas automatiquement que des modèles moins chers impliquent un traitement des données conforme aux standards américains ou européens.
Métaphore : Vous allez directement voir un consultant (le modèle) chez une grande entreprise (le fournisseur d’IA). Celui-ci lit votre mémo, répond à votre question, puis archivera une copie sous votre nom. Il pourrait utiliser des versions anonymisées de vos mémos antérieurs pour former d’autres consultants ou améliorer ses services.
Niveau 1 : « Chat temporaire ChatGPT / Chat invisible Claude. » Le même fournisseur, la même identité, le même texte brut sur leurs serveurs. La conversation n’apparaît pas dans votre historique, le modèle ne la transmet pas plus loin, et selon la politique, elle est exclue de l’entraînement. Très utile pour des conversations ponctuelles sensibles que vous ne souhaitez pas voir affecter votre compte. Le fournisseur sait toujours que c’est vous, et voit toujours le prompt intégral ; ce qu’il ne peut pas faire, c’est le conserver à long terme ou l’utiliser pour l’entraînement. Votre conversation est cachée de votre propre historique, mais pas du laboratoire.
Métaphore : Interaction identique avec le consultant (modèle), mais vous demandez qu’il exclue ce mémo spécifique de votre dossier principal. Il le lit, y répond, puis le place dans un tiroir temporaire (chat invisible), qui sera effacé au bout d’un certain temps. Il sait toujours que c’est vous, et a vu ce que vous lui avez envoyé.
Niveau 2 : « API Anthropic, Claude for Work, ChatGPT Enterprise, API OpenAI. » Passage des chats grand public aux conditions commerciales. Le contrat exclut l’utilisation de vos données pour l’entraînement. La durée de conservation est courte, généralement environ 30 jours pour des vérifications de sécurité, parfois zéro jour au niveau entreprise. En cas de violation de la politique, vous disposez de recours juridiques. Le laboratoire voit toujours le texte brut pendant l’inférence et associe le trafic à votre clé API, mais les garanties sont plus fortes et exécutoires contractuellement. C’est la posture de confidentialité réellement utilisée par la plupart des entreprises, une véritable amélioration par rapport aux chats grand public. Toutefois, elle repose encore sur la politique, et non sur l’architecture. La raison de continuer à monter sur l’échelle est réelle : modifications futures des politiques, divulgations forcées, fuites de données ou dégradation de la conduite du laboratoire lui-même.
Métaphore : Vous signez un contrat avec une société de conseil (conditions d’entreprise/API), stipulant notamment qu’aucune copie ne sera faite, qu’aucun partage inter-client ne sera effectué, que la durée de conservation sera courte, et que des recours juridiques sont prévus en cas de violation. Interaction directe identique avec le consultant (modèle), qui lit votre mémo et sait qu’il provient de vous, mais les règles relatives à ce qui se passe ensuite sont plus strictes.
Niveau 3 : « Mode anonyme Venice. » Un proxy se place entre vous et le laboratoire, supprimant votre identité avant la transmission. Le laboratoire voit le contenu du prompt en texte brut, mais ignore qu’il s’agit de vous. Il ne voit qu’une « demande provenant de Venice ». Pour les prompts dont le contenu ne vous identifie pas, cela rompt le lien entre votre requête et votre nom, rendant bien plus difficile la constitution d’un profil à long terme par le laboratoire. Pour les prompts dont le contenu vous identifie effectivement (votre entreprise, vos transactions, votre nom), cette mesure est largement cosmétique : le contenu vous révèle de toute façon. Vous ajoutez également Venice comme tiers de confiance. Réaliser cela soi-même n’est pas réaliste : vous seriez le seul utilisateur de votre propre proxy, et l’anonymat à utilisateur unique n’est pas de l’anonymat.
Métaphore : Un service de livraison (Venice) gère la remise. Ce service retire votre nom du mémo avant de le remettre au consultant (modèle). Le consultant lit le contenu, mais ignore qui l’a envoyé ; le service de livraison connaît les deux parties.
Niveau 4 : « Modèles open source sur Together AI / Fireworks / Groq, ou mode privé Venice. » Passage aux modèles open source, les laboratoires fermés sortent de la boucle. Ils ne sont pas impliqués, car vous n’utilisez pas leurs modèles. La confiance se déplace vers ceux qui hébergent les modèles open source. Fournisseurs différents, garanties contractuelles similaires, souvent culturellement plus soucieux de confidentialité (notamment le mode privé Venice). Vous sacrifiez certaines capacités, bien que l’écart se soit réduit. GLM 5.1, Qwen 3.6, Minimax M2.7 et DeepSeek V4 se distinguent bien dans les tâches courantes de codage, d’écriture et d’analyse. Leur capacité à atteindre le niveau des meilleurs modèles fermés dépend fortement des benchmarks ; les laboratoires fermés gardent un avantage sur les tâches à long contexte, les tâches multimodales et les workflows complexes d’agents. Vous réduisez également le risque de concentration, et le nombre de parties de confiance diminue. Est-ce strictement plus privé que le niveau 3 ? Cela dépend de vos priorités. Le niveau 3 cache votre identité aux laboratoires de pointe ; le niveau 4 révèle votre identité à des acteurs plus petits, mais coupe totalement les laboratoires. Priorités différentes, hiérarchie différente. Cela ne vous aide que pour le trafic que vous acheminez effectivement via des modèles open source. Une utilisation mixte signifie que les laboratoires voient toujours tout ce que vous leur envoyez. À l’intérieur du niveau 4, les fournisseurs diffèrent aussi quant à l’emplacement physique des GPU : Together, Fireworks et le mode privé Venice spécifient leurs propres centres de données, tandis que des agrégateurs comme OpenRouter acheminent vers le fournisseur sous-jacent le moins cher, ce qui peut inclure des fournisseurs opérant dans des juridictions que vous n’avez pas choisies. Pour les utilisateurs soucieux de ce point (éviter les appels API acheminés vers certains pays), l’option de spécifier un hôte diffère fondamentalement de l’acheminement vers l’agrégateur le moins cher, qui ajoute également un saut de confiance supplémentaire.
Métaphore : Vous apportez directement votre mémo à une société de conseil différente (fournisseur de modèles open source, comme Together AI, Fireworks ou le mode privé Venice). L’ancienne entreprise ne voit rien, car vous avez cessé de l’utiliser. Le nouveau consultant (un modèle différent) lit votre mémo et sait qu’il provient de vous, avec la même structure d’interaction directe, mais une entreprise différente.
Niveau 5 : « DIY : vLLM sur RunPod / Lambda Labs / AWS. » Saut complet de la couche « inférence en tant que service ». Louez des GPU bruts, installez vous-même vLLM ou TGI, chargez les poids, exposez votre propre point de terminaison. Aucun fournisseur d’inférence ne voit votre trafic, seulement le fournisseur de cloud hébergeant votre machine virtuelle. Techniquement, ce fournisseur pourrait inspecter votre machine virtuelle s’il en avait la motivation ou y était contraint. Toutefois, il dispose d’une posture de conformité, de protections contractuelles et de pistes d’audit plus solides que celles des petits fournisseurs d’inférence. Le compromis est le suivant : vous passez des politiques des petits fournisseurs à celles des fournisseurs de cloud hyperscalaires, au prix d’un vrai travail d’ingénierie et d’exploitation.
Métaphore : Vous engagez votre propre consultant (votre propre modèle, auto-hébergé), qui travaille exclusivement pour vous dans un bureau privé (machine virtuelle louée auprès de fournisseurs de cloud tels que RunPod, Lambda Labs ou AWS). Aucune société de conseil intermédiaire, juste vous et le consultant que vous avez engagé personnellement. Le propriétaire de l’immeuble (le fournisseur de cloud) pourrait techniquement accéder à votre bureau s’il en avait la motivation, mais il dispose généralement d’une posture de conformité plus robuste que les petites entreprises des niveaux précédents.
Niveau 6 : « Mode TEE Venice. » Ici, la garantie de confidentialité change de nature. Les modes TEE et E2EE sont disponibles pour tout abonné Pro payant ; le choix entre eux se fait par requête, et non par forfait. Pour l’inférence TEE, Venice achemine vers des hôtes GPU exploitant des technologies de calcul confidentiel fournies par NEAR AI Cloud et Phala Network, sur du matériel NVIDIA H100 et H200. NEAR et Phala fournissent les protocoles et outils ; les GPU eux-mêmes sont exploités par des tiers utilisant cette technologie. La fonctionnalité de calcul confidentiel sur les GPU empêche l’opérateur de lire le contenu à l’intérieur de l’enclave pendant l’exécution. La preuve à distance permet à votre client de vérifier cryptographiquement, avant l’envoi de tout contenu, que le code exécuté dans l’enclave est bien celui publié par Venice, résolvant ainsi la question « s’agit-il bien du code publié par Venice ? ». Ce qui n’est pas encore résolu est un audit formel et indépendant de la correction de ce code. L’opérateur GPU n’est plus une partie pouvant espionner. Le proxy Venice voit brièvement le texte brut, mais l’hôte GPU ne voit rien. Ce changement marque un passage de la politique au matériel. La confiance ne disparaît pas ; elle change de cible. Vous faites désormais confiance à la conception du calcul confidentiel de NVIDIA, à la chaîne de signatures de preuve et à l’implémentation de Venice. Robuste face aux menaces réelles, bien qu’imparfaite : les conceptions TEE (Intel SGX, AMD SEV) ont été répétitivement vulnérables à des attaques par canaux auxiliaires, et les conceptions actuelles n’y sont pas immunisées. Pour les utilisateurs suivant de près cette recherche sur les vulnérabilités, le niveau 4 (mode privé Venice dans un centre de données d’un opérateur de confiance) pourrait constituer un point d’arrêt rationnel, plutôt que le niveau 6, car faire confiance à l’hygiène opérationnelle de Venice peut sembler plus confortable que faire confiance à la chaîne de preuve des fabricants de puces. Le Private Cloud Compute d’Apple relève globalement de la même série architecturale : inférence privée dans le cloud, avec support matériel et vérifiabilité. Mais les différences avec Venice sont réelles. Apple utilise son propre Apple Silicon, exécutant uniquement Apple Intelligence, sans exposer de choix de modèles. Venice utilise des partenaires externes TEE, prend en charge les modèles open source, et permet aux utilisateurs de choisir le niveau de confidentialité par requête.
Métaphore : Le service de livraison (Venice) achemine votre mémo vers un consultant (modèle) travaillant dans une salle étanche et insonorisée (enclave matérielle/Tee sur GPU NVIDIA à calcul confidentiel, exploitée par les partenaires de Venice, NEAR AI Cloud et Phala Network). Le service de livraison lit le mémo en transit, mais le consultant à l’intérieur ne peut être observé par personne, y compris le propriétaire de l’immeuble (l’opérateur GPU). La salle est vidée après chaque session.
Niveau 7 : « Mode E2EE Venice. » TEE combiné à un chiffrement côté client. Le chiffrement s’effectue directement entre votre client et l’enclave matérielle. Le proxy Venice intermédiaire ne détient jamais la clé, donc tout ce qui lui est transmis est du texte chiffré venant de votre machine, jusqu’au moment précis où il est traité à l’intérieur de l’enclave. L’opérateur GPU et Venice lui-même sont éliminés comme parties pouvant espionner ; seul le modèle exécuté dans l’enclave traite le texte brut, et ce de façon éphémère. Il s’agit de la garantie de confidentialité la plus forte disponible sur du matériel tiers, juste derrière le chiffrement homomorphe pleinement fonctionnel (qui n’est pas encore réalisable à une vitesse utilisable pour les LLM). Toutes les dépendances de confiance du niveau 6 persistent, avec un ajout : le chiffrement côté client doit être correctement implémenté. Deux compromis spécifiques à ce niveau. Les fonctionnalités nécessitant que l’infrastructure Venice lise le texte brut, comme la recherche web et la mémoire persistante, sont désactivées. Le choix des modèles se restreint également : actuellement, onze modèles exactement sont déployés dans l’infrastructure TEE/E2EE : Venice Uncensored 1.2, GLM 5.1, GLM 4.7, GLM 4.7 Flash, Qwen3.5 122B A10B, Qwen 2.5 7B, Qwen3 30B A3B, Qwen3 VL 30B A3B, Gemma 3 27B, GPT OSS 20B et GPT OSS 120B.
Métaphore : Tout ce qui s’applique au niveau 6 reste valable : le consultant (modèle) travaille dans une salle étanche et insonorisée, personne à l’extérieur ne peut l’observer, et la salle est vidée après chaque session. L’ajout est que vous placez vous-même votre mémo dans une boîte verrouillée (chiffrement côté client) avant de le remettre au service de livraison (toujours Venice). Le service de livraison transporte désormais une boîte opaque, ne voyant pas ce qu’elle contient, donc le seul à pouvoir lire votre message est le consultant à l’intérieur de la salle étanche.
Point clé : Les niveaux 0 à 2 reposent principalement sur des améliorations de politique et de contrat. Les niveaux 3 à 4 modifient le routage et l’exposition du modèle/fournisseur. Les niveaux 6 à 7 modifient fondamentalement le modèle de confiance en passant au calcul confidentiel matériel et à l’inférence chiffrée. La différenciation de Venice réside dans sa capacité à couvrir les niveaux 3, 4, 6 et 7 au sein d’un seul produit.
Le niveau approprié pour un utilisateur donné dépend de son modèle de menace. Choisir le niveau en fonction de la technologie la plus impressionnante est une mauvaise interprétation. Les niveaux 6 et 7 sacrifient certaines capacités de pointe et introduisent de nouvelles dépendances de confiance. Même avec ces coûts, il s’agit encore aujourd’hui de la mise à niveau de confidentialité la plus significative disponible pour l’inférence dans le cloud.
C’est ainsi que fonctionne l’architecture. La question plus difficile est de savoir qui a vraiment besoin de quel niveau, et quelle est la taille de ce public. Des modèles de menace différents poussent différents utilisateurs vers différentes parties de l’échelle, généralement de force plutôt que par préférence, ce qui donne un marché plus vaste que ne le suggère la communication technique. Voici la décomposition.
Catégories d’utilisateurs
La posture en matière de confidentialité n’est pas une préférence abstraite. Une part significative du public de Venice est venue ici parce qu’elle a été écartée des options par défaut par des politiques de contenu, des équipes de conformité, des modèles de menace ou des principes éthiques. Lorsqu’un utilisateur cherche activement une alternative qu’il ne peut plus utiliser, le marketing devient beaucoup plus facile. Voici six segments à examiner :
Travail réglementé et piloté par la conformité. Équipes financières traitant d’informations non publiques importantes, professionnels de santé soumis à la HIPAA, avocats traitant de communications privilégiées, experts en fusions & acquisitions et en processus transactionnels. Les équipes de conformité n’autorisent généralement pas le niveau 0. Beaucoup semblent rester au niveau 2, car les conditions d’entreprise d’Anthropic et d’OpenAI (pas d’entraînement, conservation limitée, recours contractuels) permettent de franchir les seuils de conformité courants. Une partie progresse jusqu’au niveau 6, souvent parce qu’elle a été lésée par des changements de politique ailleurs, ou parce que les données qu’elle traite causeraient des dommages réels en cas de divulgation forcée. Anthropic semble avoir établi une activité d’entreprise substantielle sur ce segment, et la réglementation dans les domaines médical et financier évolue vers des exigences de calcul privé de plus en plus strictes. Le point de convergence le plus évident de Venice ici semble actuellement être des praticiens indépendants achetant Pro par prudence personnelle, plutôt que des achats d’entreprise. L’achat d’entreprise ne porte pas uniquement sur l’architecture de confidentialité. Les équipes de conformité exigent, avant de signer, des contrôles de gestion, des journaux d’audit, des rapports SOC2, des accords de traitement des données (DPA) signés, des SLA réels et un support d’intégration. L’histoire du chiffrement est importante, mais pas suffisante. Le marché d’entreprise piloté par les achats est en concurrence directe avec Apple PCC, Microsoft Azure Confidential Computing, ainsi qu’avec Phala ou NEAR.
Développeurs construisant sur l’API Venice. L’API Venice a attiré l’attention grâce à des intégrations développeur sur OpenRouter, Cursor, VSCode, Brave Leo et Fleek. L’usage le plus évident est que les développeurs intègrent des fonctionnalités IA respectueuses de la confidentialité dans leurs propres produits, souhaitant garantir à leurs utilisateurs finaux que « vos données restent privées ». Le niveau correspondant peut varier selon ce que le développeur construit : des fonctionnalités grand public sensibles au coût utilisent le mode anonyme (niveau 3), le routage par défaut vers des modèles OSS utilise le mode privé (niveau 4), et des produits spécifiquement commercialisés sur l’architecture de confidentialité utilisent le TEE ou l’E2EE (niveaux 6 à 7). Un développeur utilisant l’API Venice peut servir de nombreux utilisateurs finaux sans qu’ils aient tous besoin d’acheter un abonnement Venice, ce qui rend l’économie unitaire potentiellement très différente de celle des abonnements grand public directs.
Utilisations personnelles à haut risque. Les personnes peuvent ne pas vouloir que leurs requêtes liées à la santé mentale ou à la thérapie restent dans l’historique de leur compte. L’exploration de l’identité liée à l’orientation sexuelle ou au genre, pour laquelle l’utilisateur n’est pas encore prêt à se dévoiler. Les discussions sur le mariage, le divorce, l’emploi ou la dynamique familiale, dont la simple exposition pourrait causer du tort. Beaucoup de ces utilisateurs restent probablement au niveau 1, pensant que le chat invisible les dissimule. Une sous-catégorie sensible à la confidentialité passe généralement au niveau 6 une fois qu’elle comprend que cela ne les cache pas complètement du laboratoire. La santé mentale assistée par l’IA semble être une catégorie en croissance, bien que l’échelle et la qualité des produits cliniques et grand public varient fortement. Il est difficile d’estimer sa taille depuis Venice, car de nombreux utilisateurs de ce segment ne savent peut-être pas qu’ils doivent rechercher une confidentialité certifiée par matériel, jusqu’à ce qu’un incident embarrassant se produise pour eux ou pour quelqu’un qu’ils connaissent.
Environnements adverses. Journalistes protégeant leurs sources, militants vivant dans des juridictions surveillant l’utilisation de l’IA, dissidents et organisateurs politiques, chercheurs en sécurité étudiant les acteurs malveillants, avocats représentant des lanceurs d’alerte. Ces utilisateurs ont généralement besoin des niveaux 6 et 7. Les niveaux inférieurs ne survivraient probablement pas à leur modèle de menace. Prenez Proton : même avec sa réputation axée sur la confidentialité et son siège légal en Suisse, il se conforme à la plupart des demandes légales reçues, souvent parce que la loi suisse l’y oblige. Il s’agit d’un mode d’échec possible de la confidentialité basée sur la politique lorsqu’elle est mise à l’échelle. L’architecture TEE et E2EE de Venice appartient à la catégorie de configurations cloud où le fournisseur n’est pas conçu pour détenir le texte brut, or c’est précisément ce texte brut qui est requis pour se conformer à de telles obligations forcées. Toutefois, l’architecture a ses limites. Les niveaux 6 et 7 réduisent l’exposition du texte brut, mais ne résolvent pas l’ensemble du problème. Les métadonnées de compte, les traces de paiement, les informations d’utilisation enregistrées par Venice, les activités de votre ordinateur portable, et ce que le tribunal peut vous contraindre à fournir, tout cela reste sous la responsabilité de l’utilisateur. Pour les personnes ayant un modèle de menace réellement adversaire, il ne s’agit que d’un outil parmi un ensemble plus large. Numériquement, ce segment est petit. La volonté de payer pour un outil capable de résister à une assignation à comparaître est souvent très élevée.
Utilisateurs natifs de la cryptographie et de la culture de la confidentialité. Développeurs Web3, experts techniques soucieux de la souveraineté, personnes exécutant leurs propres nœuds et valorisant les garanties certifiées par matériel. Ce segment peut couvrir les niveaux 3 à 7, selon le modèle de menace individuel, et la sous-catégorie guidée par des principes utilise souvent par défaut les niveaux 6 ou 7 pour les requêtes sensibles. L’intersection IA/cryptographie est devenue une catégorie significative au sein de l’écosystème crypto plus large, des infrastructures comme Bittensor ayant établi des positions importantes. Les enquêtes sectorielles signalent fréquemment un intérêt accru pour l’auto-hébergement dans les marchés émergents, où la surveillance centralisée des paiements est une préoccupation. La posture de Venice s’aligne avec ce segment d’une manière que les concurrents des laboratoires fermés ne parviennent pas à reproduire : tarification en VVV, absence de KYC, réputation d’Erik Voorhees, et accès gratuit historique au niveau Pro pour les détenteurs de VVV et MOR ont contribué à façonner ce groupe. Il pourrait constituer la base culturelle naturelle de Venice et une part importante de ses premiers utilisateurs payants.
Contenu pour adultes et autres catégories directement refusées par les laboratoires fermés. OpenAI, Anthropic et Google refusent généralement le contenu NSFW (non sûr pour le travail). D’autres catégories bloquées au niveau 0, comme l’écriture créative mature, les questions de réduction des risques liées aux drogues, et une longue liste de sujets stigmatisés mais légaux, sont traitées différemment selon les fournisseurs, parfois avec une certaine tolérance. Les utilisateurs de ces catégories ne peuvent généralement pas commencer au niveau 0 ; les modèles refusent souvent leurs requêtes. Le simple choix du modèle les pousse souvent vers les niveaux 4 à 7, car c’est généralement là que les variantes open source non censurées sont disponibles. La plupart des utilisateurs payants restent probablement au niveau 4 dans leur usage quotidien, tandis que la sous-catégorie sensible à la confidentialité se dirige vers les niveaux 6 ou 7. Cette catégorie semble très large : Character.AI et Replika opèrent toutes deux à une échelle grand public significative, et les applications d’IA compagnon ont grandi pour devenir un sous-ensemble notable de l’IA grand public. Ces utilisateurs pourraient accorder plus d’importance à la confidentialité qu’un utilisateur typique de chatbot, car le coût de la divulgation est élevé : une fuite de profil pourrait détruire un mariage, un emploi ou une affaire de garde d’enfants. Il pourrait s’agir du plus grand public de Venice actuel, mesuré en volume.
Un point saillant parmi ces groupes est que peu d’entre eux semblent se trouver au sommet du tunnel d’acquisition. La plupart semblent façonnés par une exclusion forcée ou subie des chemins faciles, imposée par des politiques de contenu, des équipes de conformité, des modèles de menace ou des principes. L’IA priorisant la confidentialité n’est généralement pas une catégorie dans laquelle les gens arrivent par la porte principale ; ils y parviennent souvent après avoir découvert qu’ils ne peuvent pas rester là où ils étaient. La même logique explique deux segments adjacents dignes de mention, bien que non quantifiés : les utilisateurs internationaux dont la juridiction pourrait les éloigner des paiements centralisés et de la surveillance de l’IA, et le groupe émergent des agents IA personnels, dont les données d’orchestration pourraient bénéficier d’un backend respectueux de la confidentialité.
Taille du marché
Le plafond final de Venice dépend de la taille du marché adressable, et non de ses performances actuelles. Le cadre correct est la part de marché de l’inférence : Venice vend des services d’inférence IA, et le marché pertinent est la dépense mondiale globale en inférence, dont les revenus de Venice constituent une fraction.
Des estimations indépendantes du marché de l’inférence pour 2027 convergent globalement vers 140 à 160 milliards de dollars, les prévisions de Bain, IDC et McKinsey se situant toutes dans cette fourchette. Même en prenant le taux de croissance annuelle projeté pour Venice (mon estimation, développée dans la section de valorisation) de 400 millions de dollars à la fin 2027, Venice ne représenterait pas plus de 0,3 % de ce marché, un pourcentage insignifiant selon toute définition raisonnable du marché. À titre de comparaison, l’activité API d’OpenAI seule représenterait déjà quelques pourcents de la dépense actuelle en inférence, et l’API d’Anthropic se situerait dans une fourchette similaire. La position actuelle de Venice est loin en dessous même de la part de marché occupée par des plateformes d’inférence de taille moyenne.
Mais Venice ne cherche pas à conquérir l’ensemble de ce marché. Venice vise la tranche de marché axée sur la confidentialité : les utilisateurs et entreprises ayant besoin d’anonymat, de confidentialité certifiée par matériel, d’accès non censuré ou de choix de juridiction pendant l’inférence. Ce sous-segment est plus difficile à calculer avec précision, mais les signaux directionnels sont très forts.
Plusieurs forces élargissent la part de marché de l’inférence axée sur la confidentialité : la réglementation de plus en plus stricte en matière de résidence des données en Europe et dans certaines parties de l’Asie, la friction croissante en matière de conformité entre les entreprises et les produits par défaut des laboratoires fermés, et la maturation des infrastructures de confidentialité basées sur les TEE. Les enquêtes entreprises signalent continuellement une préoccupation croissante face à l’exposition des données par l’IA. Prises isolément, ces forces ne sont pas rapides, mais elles se cumulent.
Même si la part de marché de l’inférence dans le cloud axée sur la confidentialité ne représentait que 5 à 15 % des 140 à 160 milliards de dollars du marché de l’inférence en 2027, cela représenterait un marché de 7 à 23 milliards de dollars. Une part à un chiffre suffirait à porter les revenus de Venice à plusieurs centaines de millions de dollars, bien au-dessus de son taux actuel et avec encore une grande marge de croissance. Une part à deux chiffres pourrait faire entrer Venice dans la fourchette des milliards de dollars.
Le scénario baissier comporte trois dimensions. Premièrement, le marché de l’inférence dans le cloud axé sur la confidentialité ne parvient pas à atteindre une taille significative, car les fournisseurs de cloud hyperscalaires offrent des options de confidentialité suffisantes au sein de leurs plateformes existantes. Apple PCC, Azure Confidential Computing et AWS Bedrock Confidential Inference évoluent toutes dans cette direction. Dans ce cas, la confidentialité reste importante, mais elle est intégrée aux plateformes cloud et grand public existantes, et un marché indépendant axé sur la confidentialité ne deviendra jamais assez grand pour soutenir une entreprise indépendante.
Deuxièmement, l’inférence locale devient accessible au grand public. La qualité des modèles open source est déjà suffisamment forte pour la plupart des charges de travail courantes. Le goulot d’étranglement réside dans la friction de configuration et les compétences techniques nécessaires pour faire fonctionner des modèles locaux. À mesure que ce goulot d’étranglement est atténué par des solutions « prêt-à-l’emploi » plus sophistiquées, des installateurs plus simples et des intégrations gérant la charge opérationnelle, une part significative des utilisateurs soucieux de la confidentialité pourrait choisir d’exécuter localement l’inférence plutôt que de payer pour un service cloud quelconque. Cela les retirerait totalement du marché adressable de Venice. Ce risque dépend du rythme de maturation de la pile locale conviviale pour les consommateurs.
Troisièmement, même si le marché de la confidentialité atteint une taille significative, Venice devra encore conquérir des parts de marché face à d’autres acteurs natifs de la confidentialité, tels que Brave Leo, DuckDuckGo, Lumo de Proton, Maple et Tinfoil, chacun visant différentes parties du « bundle » de Venice sous un angle différent. La section sur le paysage concurrentiel examine la comparaison entre la combinaison de Venice (profondeur de confidentialité, accès non censuré, distribution nativement cryptographique) et ces menaces spécifiques.
Paysage concurrentiel
L’ensemble concurrentiel de Venice est plus large que « d’autres applications IA privées ». Différentes plates-formes rivalisent pour satisfaire les mêmes besoins : les consommateurs soucieux de la confidentialité, les développeurs désirant un choix de modèles, ceux recherchant un contenu non censuré, et les acheteurs natifs de la cryptographie. La section suivante couvre cinq catégories.
Ce paysage est constitué de substituts partiels qui tirent sur Venice sous différents angles. Brave et DuckDuckGo rivalisent pour la distribution. OpenRouter rivalise pour l’API destinée aux développeurs. Tinfoil, NEAR, Phala et Maple rivalisent pour l’architecture de confidentialité elle-même. Les laboratoires de pointe partent du côté entreprise pour intégrer une confidentialité suffisante dans de meilleurs modèles. Aucun de ces produits ne regroupe actuellement l’ensemble complet de Venice : une IA grand public par défaut privée, un accès non censuré, un choix multiple de modèles, des paiements nativement cryptographiques et une économie d’utilisation tokenisée.
Il convient de distinguer les niveaux de confidentialité, du plus faible au plus fort :
Aucun entraînement : le fournisseur s’engage à ne pas utiliser vos données pour l’entraînement (conditions standard de l’API Anthropic et OpenAI)
Rétention limitée ou nulle : le fournisseur conserve brièvement les prompts pour la détection d’abus, ou propose une configuration ZDR (Zero Data Retention) où les prompts et les réponses ne sont pas stockés après traitement (ZDR d’OpenAI, ZDR d’OpenRouter)
Proxy anonyme : le fournisseur voit le prompt mais pas l’identité (Venice Anonymous, Brave Leo, DuckDuckGo AI Chat)
TEE/Certification matérielle : le prompt est exécuté dans une enclave inaccessible à l’opérateur (Venice TEE, Tinfoil, NEAR Private Chat, Apple PCC)
E2EE vers TEE : le fournisseur ne voit que du texte chiffré (Venice E2EE, Maple AI)
Local : le modèle s’exécute sur votre propre matériel (Ollama, LM Studio)
Venice fait partie des rares produits grand public qui couvrent, dans une seule expérience utilisateur, les modes proxy anonyme, chat privé, TEE et E2EE, avec un choix du mode par requête.
Plateformes IA par défaut (OpenAI, Anthropic, Google, xAI)
Les laboratoires de pointe offrent déjà une vraie confidentialité aux entreprises. OpenAI ne forme par défaut pas ses modèles à partir des données de l’API ou des clients commerciaux, et propose une configuration ZDR aux clients éligibles. Anthropic ne forme pas ses modèles à partir des entrées ou sorties des produits commerciaux. Google Vertex AI propose des limitations d’entraînement au niveau entreprise. xAI promeut également le contrôle de la confidentialité des utilisateurs, bien que sa posture doive être distinguée des engagements plus matures des entreprises OpenAI, Anthropic et Google. L’écart entre Venice et la confidentialité entreprise/API des laboratoires est plus étroit que beaucoup ne le supposent ; l’écart en matière d’anonymat grand public reste toutefois beaucoup plus large. Les chats grand public ChatGPT, Claude et Gemini lient par défaut l’identité au prompt et conservent l’historique des conversations côté serveur, les politiques relatives à l’entraînement variant selon le produit et les paramètres de l’utilisateur.
Venice poursuit ce que les laboratoires de pointe ne feront pas : l’accès anonyme, les modèles non censurés et les paiements nativement cryptographiques. Ce marché est plus petit que l’IA grand public, mais il est réel. Les laboratoires de pointe servent la majorité des utilisateurs grand public. Venice sert la partie de ceux qui veulent sortir des options par défaut.
Par segment :
Chats grand public : Venice offre l’anonymat, moins de restrictions parentales sur le contenu et des paiements cryptographiques. Les laboratoires conservent l’avantage en termes de capacité et de marque.
Consommateurs professionnels : Venice offre un choix de modèles et moins de verrouillage. Les laboratoires gagnent sur l’intégration au codage, la mémoire et les outils.
Entreprises : Venice n’offre pas aujourd’hui d’histoire SOC2, DPA signé, contrôles d’administration et journaux d’audit. Ce marché appartient aux laboratoires et aux fournisseurs de cloud hyperscalaires.
API : Venice offre une profondeur de confidentialité et un accès non censuré. Les laboratoires ont la qualité des modèles et l’écosystème.
Interfaces de distribution natives de la confidentialité (Brave, DuckDuckGo)
Brave est la stratégie de distribution grand public la plus forte dans le domaine de la confidentialité. Brave annonce plus de 115 millions d’utilisateurs mensuels actifs et 47 millions d’utilisateurs quotidiens actifs au 1er avril 2026, avec Leo Premium à 14,99 dollars/mois, en plus d’un niveau gratuit. Leo est optionnel pour le compte, stocke l’historique localement, et, selon la politique déclarée de Brave, ne conserve pas les prompts sur les serveurs de Brave. Brave commence également à passer d’une confidentialité par proxy à une confidentialité vérifiable, en utilisant les TEE pris en charge par NVIDIA de NEAR AI, renforçant ainsi l’idée que l’IA à confidentialité vérifiable soutenue par matériel devient une caractéristique de produit grand public.
DuckDuckGo AI Chat est similaire dans sa posture : gratuit, sans compte, proxy anonyme vers un ensemble de modèles tiers rotatifs provenant d’OpenAI, Anthropic, Meta, etc. DuckDuckGo affirme que les chats ne sont ni stockés ni utilisés pour l’entraînement. Duck.ai propose désormais également un niveau payant, offrant des modèles plus avancés.
Lumo de Proton est le troisième acteur significatif dans ce domaine. Lumo a été lancé en juillet 2025 et étendu en janvier 2026 via des espaces de travail cryptographiques basés sur des projets, offrant une assistance IA à chiffrement zéro accès, sans journaux côté serveur ni utilisation des données utilisateur pour l’entraînement. Lumo opère depuis la base européenne de Proton, hors de la juridiction américaine, et cible la base existante d’utilisateurs soucieux de la confidentialité de Proton, couvrant les produits de messagerie, VPN et cloud. Comparé à Venice, Lumo propose un choix de modèles plus limité, aucun laboratoire fermé de pointe, aucun contenu non censuré, et aucune distribution nat
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News









