

X nouvel algorithme open source, que devrions-nous écrire pour attirer davantage de personnes ?
TechFlow SélectionTechFlow Sélection
X nouvel algorithme open source, que devrions-nous écrire pour attirer davantage de personnes ?
Les « j'aime » ne valent presque rien, les interactions en dialogue sont la véritable monnaie d'échange.
Auteur : David, TechFlow
Le 20 janvier après-midi, X a publié en open source sa nouvelle version d'algorithme de recommandation.
La réponse accompagnant le message de Musk est assez intéressante : « Nous savons que cet algorithme est stupide, qu’il nécessite encore beaucoup de modifications, mais au moins vous pouvez voir que nous nous battons en temps réel pour l’améliorer. Aucune autre plateforme sociale n’ose faire cela. »
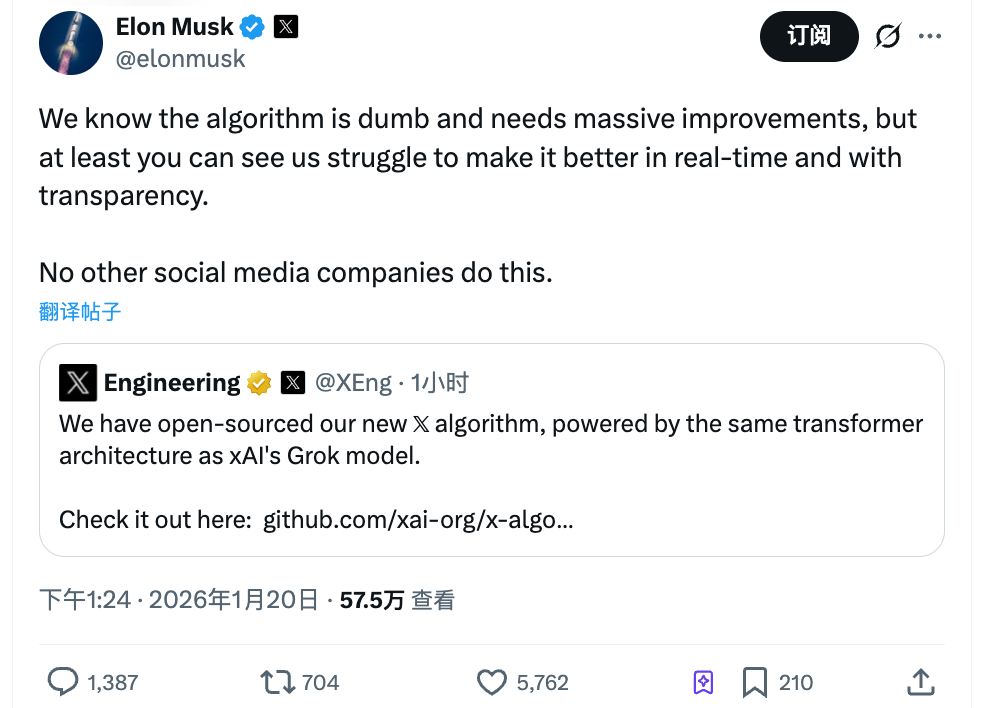
Ce commentaire contient deux messages implicites. L’un consiste à reconnaître les défauts de l’algorithme, l’autre utilise la « transparence » comme argument commercial.
C’est la deuxième fois que X ouvre son algorithme au public. La version publiée en 2023 n’avait pas été mise à jour depuis trois ans et était déjà totalement déconnectée du système réel. Cette nouvelle version a été entièrement réécrite, remplaçant le modèle principal basé sur l’apprentissage automatique traditionnel par un modèle Grok transformer. Selon l’équipe officielle, cela permet de « supprimer complètement l’ingénierie manuelle des caractéristiques ».
En langage clair : auparavant, l’algorithme reposait sur des réglages manuels de paramètres par les ingénieurs ; désormais, c’est une IA qui décide directement si votre contenu doit être diffusé, en analysant votre historique d’interactions.
Pour les créateurs de contenu, cela signifie que les anciennes règles empiriques telles que « à quelle heure publier » ou « quels hashtags utiliser pour gagner des abonnés » risquent de ne plus fonctionner.
Nous avons également exploré le dépôt GitHub publié, aidés par une IA, et découvert que certains principes logiques stricts étaient effectivement intégrés dans le code — voici ce qu’il faut savoir.
Évolution de l’algorithme : du réglage manuel à la décision automatisée par IA
Pour bien comprendre, commençons par clarifier les différences entre les anciennes et nouvelles versions — sans quoi les discussions suivantes pourraient prêter à confusion.
En 2023, Twitter avait publié une version appelée Heavy Ranker, fondée essentiellement sur un apprentissage automatique classique. Les ingénieurs devaient définir manuellement des centaines de « caractéristiques » : la présence d’une image dans le post, le nombre de followers de l’auteur, l’ancienneté du message, la présence de liens hypertexte, etc.
Chaque caractéristique se voyait attribuer un poids spécifique, ajusté itérativement jusqu’à trouver la combinaison optimale.
La nouvelle version, baptisée Phoenix, adopte une architecture radicalement différente. On peut la comprendre comme un algorithme davantage piloté par un grand modèle d’IA. Son cœur repose sur le modèle transformer Grok, une technologie similaire à celles utilisées par ChatGPT ou Claude.
Le document README officiel est sans détour : « We have eliminated every single hand-engineered feature. »
Toutes les règles artisanales d’extraction de caractéristiques ont été abandonnées, sans exception.
Mais alors, sur quoi se base désormais l’algorithme pour juger la qualité d’un contenu ?
La réponse réside dans vos séquences comportementales. Ce que vous avez aimé par le passé, à qui vous avez répondu, sur quels posts vous êtes resté plus de deux minutes, quels comptes vous avez bloqués ou masqués… Toutes ces données sont fournies au modèle transformer, qui apprend seul à en tirer des régularités.
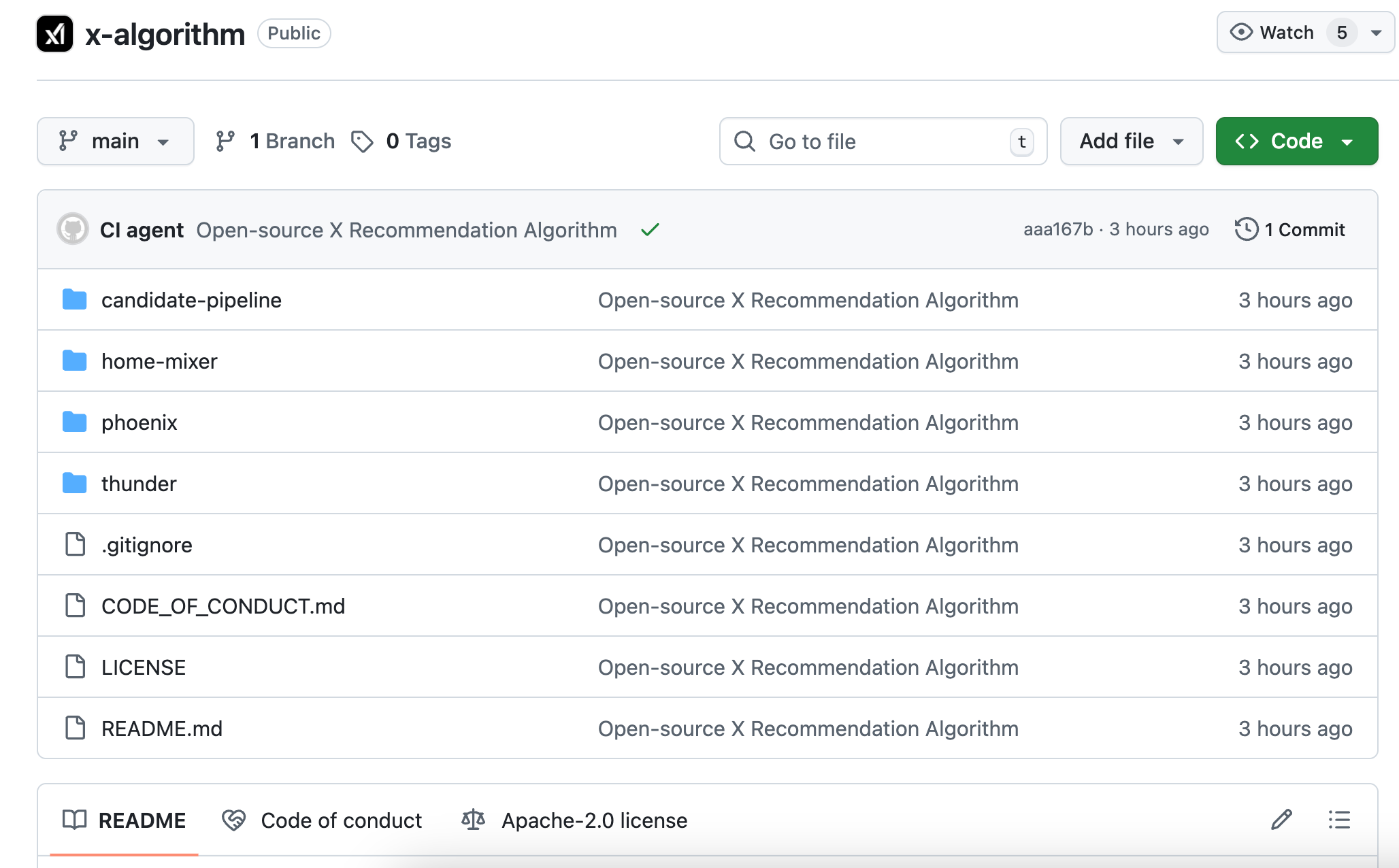
Illustrons cela : l’ancien algorithme ressemblait à un formulaire noté manuellement, où chaque critère ajoutait des points selon des cases cochées.
Le nouvel algorithme équivaut à une IA ayant lu tout votre historique de navigation, capable de deviner ce que vous allez vouloir voir juste après.
Pour les créateurs, deux conséquences :
Premièrement, les astuces du type « meilleur moment pour publier », « tags miracles » ont perdu de leur valeur. Le modèle ne s’appuie plus sur des caractéristiques fixes, mais sur les préférences individuelles de chaque utilisateur.
Deuxièmement, la diffusion de votre contenu dépend de plus en plus de la réaction qu’il suscite chez ceux qui le voient. Cette réaction est quantifiée via 15 types de comportements prédictifs — dont nous parlerons en détail dans la section suivante.
L’algorithme prédit 15 types de réactions de votre part
Lorsque Phoenix examine un post à recommander, il évalue 15 comportements potentiels de l’utilisateur face à ce contenu :
- Comportements positifs : like, réponse, retweet, retweet avec commentaire, clic sur le post, visite du profil de l’auteur, visionnage de plus de la moitié d’une vidéo, affichage d’une image, partage, temps passé supérieur à un seuil défini, abonnement à l’auteur
- Comportements négatifs : sélection de « non pertinent », blocage de l’auteur, masquage de l’auteur, signalement
À chaque comportement correspond une probabilité prédite. Par exemple, le modèle estime que vous avez 60 % de chances de liker ce post, 5 % de bloquer l’auteur, etc.
L’algorithme fait ensuite une opération simple : multiplier chaque probabilité par un poids spécifique, puis additionner le tout pour obtenir un score final.
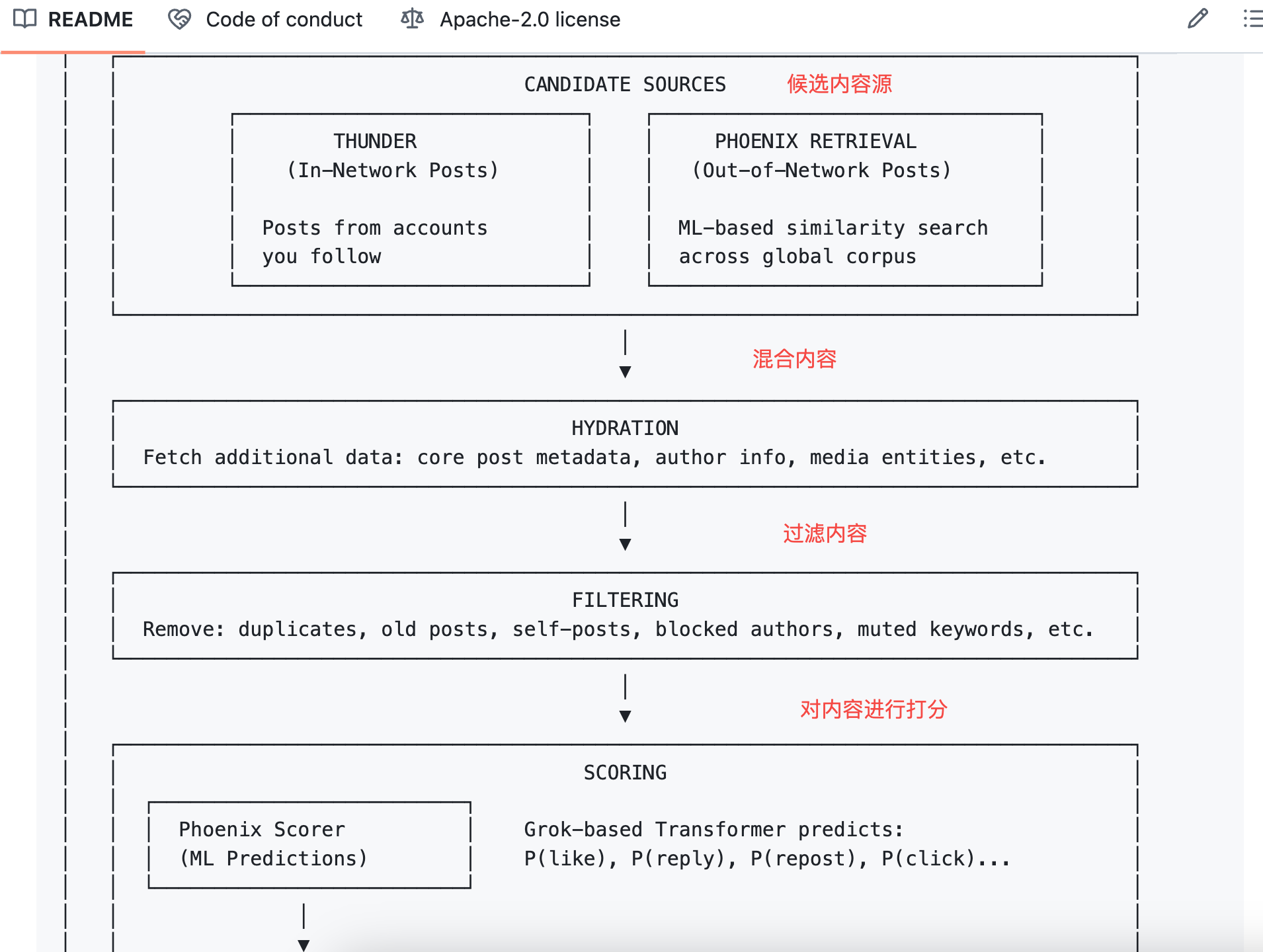
Voici la formule :
Score Final = Σ (poids × P(comportement))
Les comportements positifs ont un poids positif, les négatifs un poids négatif.
Les posts avec un score élevé remontent en haut du fil d’actualité, les autres disparaissent.
Au-delà de la formule, le message est clair :
La qualité d’un contenu ne dépend plus seulement de sa rédaction (même si lisibilité et utilité restent des bases pour la diffusion), mais surtout de la réaction qu’il provoque chez vous. L’algorithme se moque de la qualité intrinsèque du post — il ne regarde que vos actions.
Imaginons un cas extrême : un post racoleur, médiocre, mais qui pousse à commenter ou à s’indigner, pourrait avoir un score plus élevé qu’un contenu de grande qualité mais peu interagi. C’est peut-être précisément cette logique sous-jacente au système.
Cependant, la nouvelle version ne publie pas les valeurs exactes des poids. En revanche, la version de 2023 les avait rendues publiques.
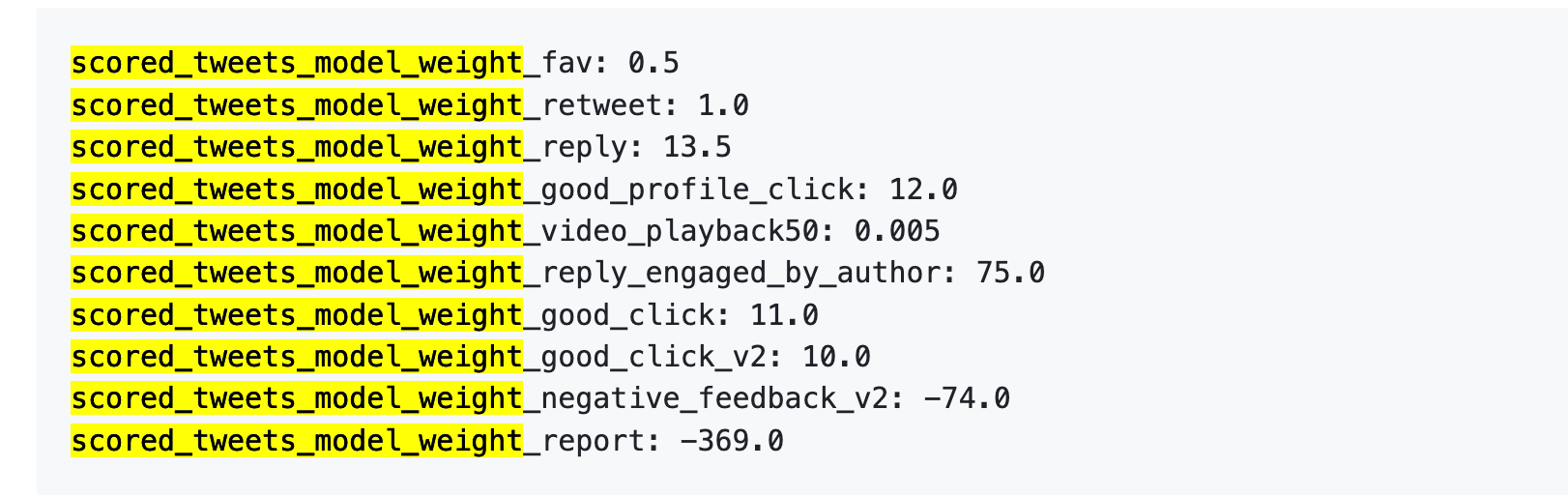
Référence ancienne : un signalement équivaut à 738 likes
Jetons un œil aux données de 2023. Même si elles sont obsolètes, elles permettent de mesurer l’importance relative accordée par l’algorithme à différents comportements.
Le 5 avril 2023, X a bien publié un jeu de données de poids sur GitHub.
Voyons les chiffres :
Traduisons cela plus crûment :

Source des données : ancien dépôt GitHub twitter/the-algorithm-ml, cliquez pour consulter l’algorithme original
Quelques chiffres méritent une attention particulière.
Premièrement, le like vaut presque rien. Son poids est de 0,5, le plus bas parmi tous les comportements positifs. Pour l’algorithme, un like a quasiment aucune valeur.
Deuxièmement, les échanges verbaux sont la monnaie forte. Le scénario « vous répondez, l’auteur vous répond » a un poids de 75 — soit 150 fois plus qu’un like. Ce que l’algorithme cherche avant tout, ce n’est pas un simple like, mais un dialogue réciproque.
Troisièmement, les retours négatifs coûtent très cher. Un blocage ou un masquage (-74) exige 148 likes pour être compensé. Un signalement (-369) en nécessite 738. Ces malus s’accumulent dans le score de crédibilité de votre compte, affectant la diffusion de tous vos futurs posts.
Quatrièmement, la durée de visionnage des vidéos est ridiculement peu valorisée. Son poids est de 0,005 — presque négligeable. Cela contraste fortement avec TikTok ou Douyin, où la durée complète de visionnage est un indicateur central.
Dans le même document, l’équipe précise : « The exact weights in the file can be adjusted at any time... Since then, we have periodically adjusted the weights to optimize for platform metrics. »
Les poids peuvent être modifiés à tout moment — et ils l’ont été.
La nouvelle version ne publie pas les chiffres exacts, mais le cadre logique reste identique dans le README : bonus pour comportements positifs, malus pour les négatifs, somme pondérée.
Les valeurs numériques ont pu changer, mais les ordres de grandeur sont probablement conservés. Répondre à quelqu’un a plus d’impact que 100 likes. Être bloqué par des utilisateurs est pire que de ne recevoir aucune interaction.
Que pouvons-nous faire en tant que créateurs ?
Après analyse des codes anciens et nouveaux de Twitter, voici quelques conclusions concrètes exploitables.
1. Répondez à vos commentateurs. Dans le tableau des poids, « l’auteur répond au commentateur » est la meilleure action (+75), 150 fois plus valorisée qu’un like. Il ne s’agit pas de solliciter des commentaires, mais simplement de répondre quand il y en a. Même un simple « merci » sera pris en compte par l’algorithme.
2. Évitez que les gens veuillent vous ignorer. Le malus d’un blocage équivaut à 148 likes. Certes, les sujets polémiques génèrent de l’interaction, mais si celle-ci prend la forme de « ce type m’énerve, je le bloque », votre score de crédibilité baisse durablement, nuisant à la diffusion de tous vos futurs posts. Le trafic polémique est une arme à double tranchant — elle blesse d’abord celui qui la brandit.
3. Placez les liens externes en commentaire. L’algorithme ne veut pas que les utilisateurs quittent la plateforme. Un lien dans le texte principal est pénalisé, comme Musk l’a lui-même reconnu publiquement. Pour rediriger, mettez le contenu dans le post et le lien dans le premier commentaire.
4. Ne spammez pas. La nouvelle version inclut un « Author Diversity Scorer » qui pénalise l’apparition fréquente de publications du même auteur. L’objectif est de diversifier le fil d’actualité, mais cela signifie aussi que publier dix fois de suite est moins efficace qu’un seul bon post.
6. Oubliez le « meilleur moment pour publier ». L’ancien algorithme incluait une caractéristique manuelle « heure de publication », désormais supprimée. Phoenix se base uniquement sur les séquences comportementales des utilisateurs, pas sur l’heure de publication. Les guides du type « publiez le mardi à 15h pour plus d’engagement » perdent donc toute pertinence.
Ce qui précède découle directement de l’analyse du code.
D’autres facteurs influencent aussi la visibilité, mais proviennent de documents publics de X, non inclus dans ce dépôt open source : certification Blue vérifiée (bonus), texte entièrement en majuscules (pénalité), contenu sensible (réduction de 80 % de la portée). Ces règles ne sont pas ouvertes — nous n’entrerons pas dans les détails.
En résumé, cette ouverture est plutôt sincère.
L’architecture complète du système, la logique de récupération des contenus candidats, le processus de notation, l’implémentation des filtres… Le code, principalement en Rust et Python, est bien structuré, et le README est plus détaillé que bien des projets commerciaux.
Mais certaines choses clés n’ont pas été publiées.
1. Les paramètres de poids ne sont pas divulgués. Le code indique seulement que « les comportements positifs ajoutent des points, les négatifs en retirent », mais ne dit pas combien vaut un like ou combien coûte un blocage. En 2023, au moins les chiffres étaient connus — cette fois, seul le cadre formel est fourni.
2. Les poids du modèle ne sont pas publiés. Phoenix utilise un modèle transformer Grok, mais les paramètres internes du modèle ne sont pas accessibles. Vous voyez comment il est utilisé, mais pas comment il calcule ses résultats.
3. Les données d’entraînement ne sont pas disponibles. On ignore sur quelles données le modèle a été entraîné, comment les comportements utilisateurs ont été échantillonnés, ni comment les exemples positifs et négatifs ont été construits.
Pour faire une analogie, cette ouverture revient à vous dire : « Nous calculons un score total par somme pondérée », sans révéler les poids ; ou « Nous utilisons un transformer pour prédire les probabilités », sans montrer ce qu’il y a à l’intérieur du transformer.
Comparé à TikTok ou Instagram, qui n’ont jamais rien publié de tel, X va nettement plus loin. Mais on est encore loin de la « transparence totale ».
Cela ne signifie pas que cette initiative est sans valeur. Pour les créateurs et les chercheurs, voir le code est toujours mieux que de ne rien voir du tout.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














