

Riche en illustrations : Comment DeepSeek R1 a-t-il été développé ?
TechFlow SélectionTechFlow Sélection
Riche en illustrations : Comment DeepSeek R1 a-t-il été développé ?
À partir du rapport technique publié par DeepSeek, analyse du processus d'entraînement de DeepSeek - R1.
Auteur : Jiang Xinling, Produire de l'électricité pour l'IA

Source de l'image : générée par WuJie AI
Comment DeepSeek a-t-il entraîné son modèle de raisonnement R1 ?
Cet article s'appuie principalement sur le rapport technique publié par DeepSeek pour analyser le processus d'entraînement de DeepSeek-R1 ; il examine en particulier quatre stratégies clés de construction et d'amélioration des modèles de raisonnement.
L'article original provient du chercheur Sebastian Raschka, publié sur :
https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
Cet article résume la partie centrale du rapport concernant l'entraînement du modèle de raisonnement R1.
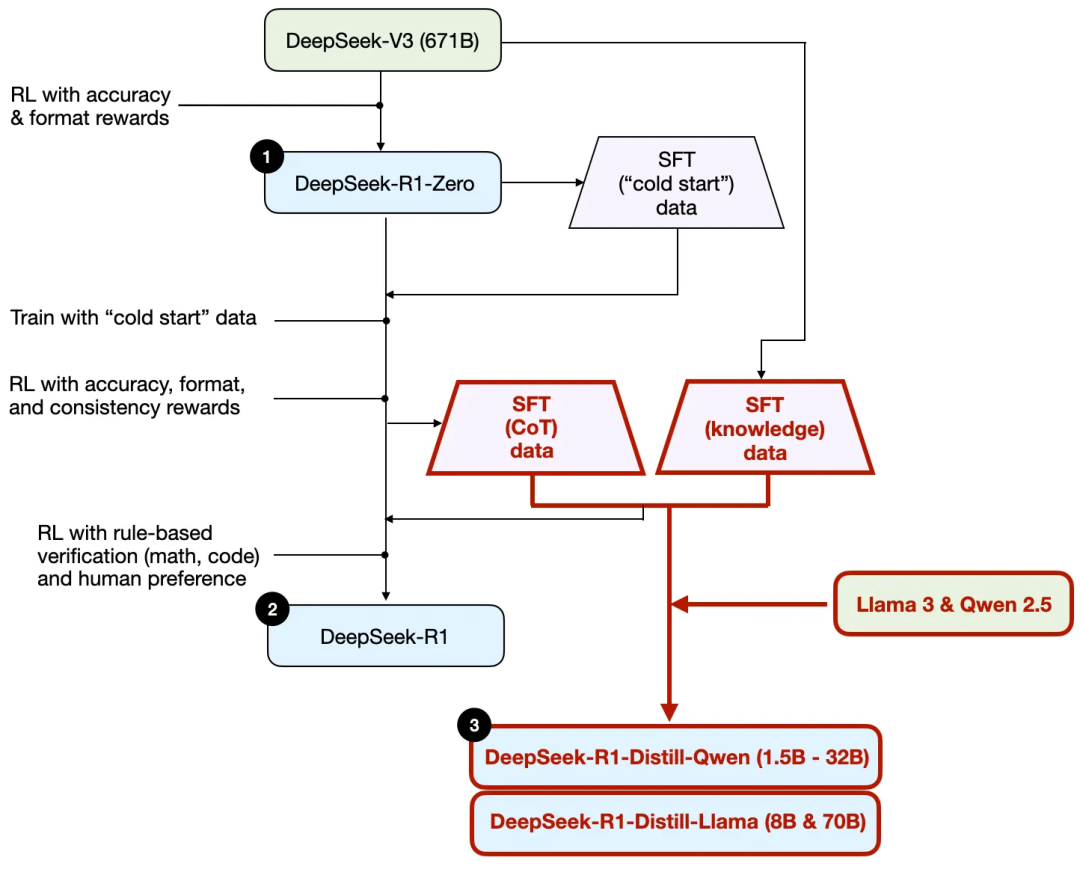
Tout d'abord, à partir du rapport technique publié par DeepSeek, voici un schéma du processus d'entraînement de R1.
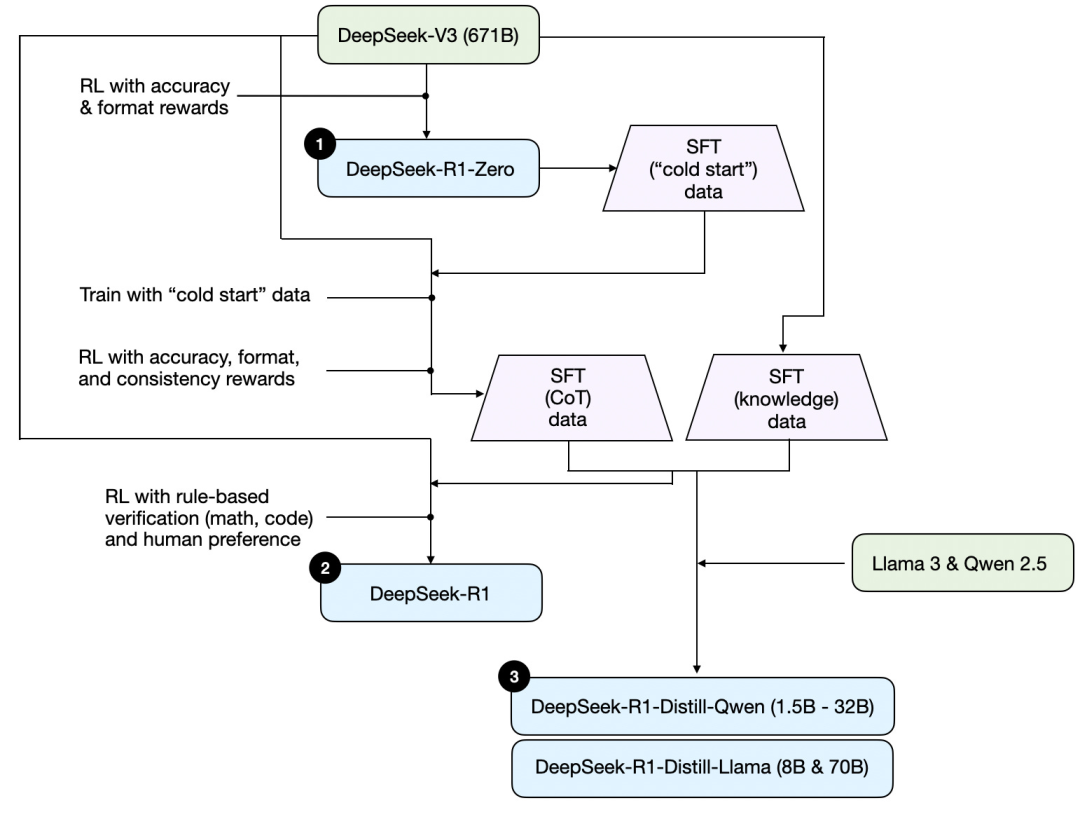
Passons en revue le processus illustré ci-dessus, où :
(1) DeepSeek - R1 - Zero : ce modèle est basé sur le modèle de base DeepSeek-V3 publié en décembre dernier. Il a été entraîné à l'aide d'un apprentissage par renforcement (RL) utilisant deux mécanismes de récompense. Cette méthode est appelée entraînement « cold start » car elle ne comprend pas d'étape d'ajustement fin supervisé (SFT), qui fait généralement partie de l'apprentissage par renforcement avec retour humain (RLHF).
(2) DeepSeek - R1 : c'est le modèle phare de DeepSeek pour le raisonnement, construit à partir de DeepSeek - R1 - Zero. L'équipe l'a optimisé par une étape supplémentaire d'ajustement fin supervisé et un apprentissage par renforcement complémentaire, améliorant ainsi le modèle R1 - Zero obtenu par « cold start ».
(3) DeepSeek - R1 - Distill : l'équipe DeepSeek a utilisé les données d'ajustement fin supervisées générées aux étapes précédentes pour fine-tuner les modèles Qwen et Llama afin d'améliorer leurs capacités de raisonnement. Bien qu'il ne s'agisse pas d'une distillation au sens traditionnel, ce processus consiste à entraîner des modèles plus petits (Llama 8B et 70B, ainsi que Qwen 1.5B - 30B) à partir des sorties du grand modèle DeepSeek - R1 de 671B.
Nous allons maintenant présenter quatre méthodes principales pour construire et améliorer les modèles de raisonnement.
1. Extension au moment de l'inférence / Inference-time scaling
Une manière d'améliorer les capacités de raisonnement d'un LLM (ou toute autre capacité en général) est l'extension au moment de l'inférence — augmenter les ressources de calcul durant l'inférence afin d'améliorer la qualité des sorties.
Pour faire une analogie approximative, tout comme une personne donne souvent une meilleure réponse lorsqu'elle dispose de plus de temps pour réfléchir à une question complexe, nous pouvons utiliser certaines techniques pour inciter un LLM à « réfléchir » plus profondément lorsqu'il génère une réponse.
Une méthode simple pour réaliser cette extension consiste en une ingénierie habile des prompts. Un exemple classique est le prompt de chaîne de pensée (CoT), qui consiste à ajouter dans le prompt d'entrée des phrases telles que « pense étape par étape ». Cela pousse le modèle à produire des étapes intermédiaires de raisonnement plutôt que de sauter directement à la réponse finale, ce qui conduit souvent à des résultats plus précis sur des problèmes complexes. (Notez que cette stratégie n'a aucun intérêt pour des questions simples fondées sur la connaissance, comme « quelle est la capitale de la France », ce qui constitue également une règle empirique pratique pour déterminer si un modèle de raisonnement est approprié pour une requête donnée.)

La méthode de chaîne de pensée (CoT) susmentionnée peut être considérée comme une extension au moment de l'inférence, car elle augmente le coût de raisonnement en générant davantage de tokens en sortie.
Une autre approche pour l'extension au moment de l'inférence consiste à utiliser des stratégies de vote et de recherche. Un exemple simple est la majorité par vote, où l'on demande au LLM de générer plusieurs réponses, puis on sélectionne la bonne réponse par vote majoritaire. De même, on peut utiliser la recherche en faisceau (beam search) ou d'autres algorithmes de recherche pour générer une réponse plus optimale.
Nous recommandons vivement l'article suivant : « Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters ».
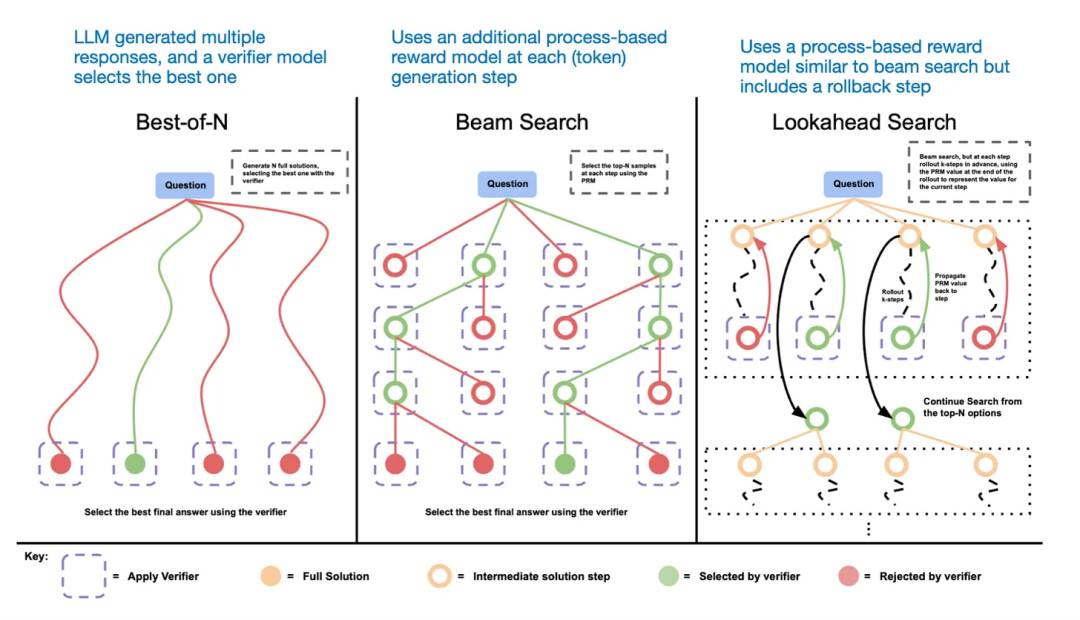
Différentes méthodes basées sur la recherche s'appuient sur un modèle de récompense procédurale pour choisir la meilleure réponse.
Le rapport technique DeepSeek R1 affirme que leur modèle n'utilise pas de techniques d'extension au moment de l'inférence. Toutefois, ces techniques sont généralement mises en œuvre au niveau de la couche applicative au-dessus du LLM, donc DeepSeek pourrait potentiellement les utiliser dans ses applications.
J'imagine que les modèles o1 et o3 d'OpenAI utilisent des techniques d'extension au moment de l'inférence, ce qui expliquerait pourquoi leur coût d'utilisation est relativement élevé comparé à des modèles comme GPT-4o. En plus de l'extension au moment de l'inférence, o1 et o3 ont très probablement été entraînés via un processus d'apprentissage par renforcement similaire à celui de DeepSeek R1.
2. Apprentissage par renforcement pur / Pure RL
Un point particulièrement remarquable dans l'article DeepSeek R1 est leur découverte selon laquelle le raisonnement peut émerger comme un comportement à partir d'un apprentissage par renforcement pur. Voyons ce que cela signifie.
Comme mentionné précédemment, DeepSeek a développé trois modèles R1. Le premier est DeepSeek - R1 - Zero, construit sur le modèle de base DeepSeek-V3. Contrairement au processus typique d'apprentissage par renforcement, où l'on effectue généralement un ajustement fin supervisé (SFT) avant l'apprentissage par renforcement, DeepSeek - R1 - Zero a été entièrement entraîné uniquement par apprentissage par renforcement, sans phase initiale de SFT, comme illustré ci-dessous.
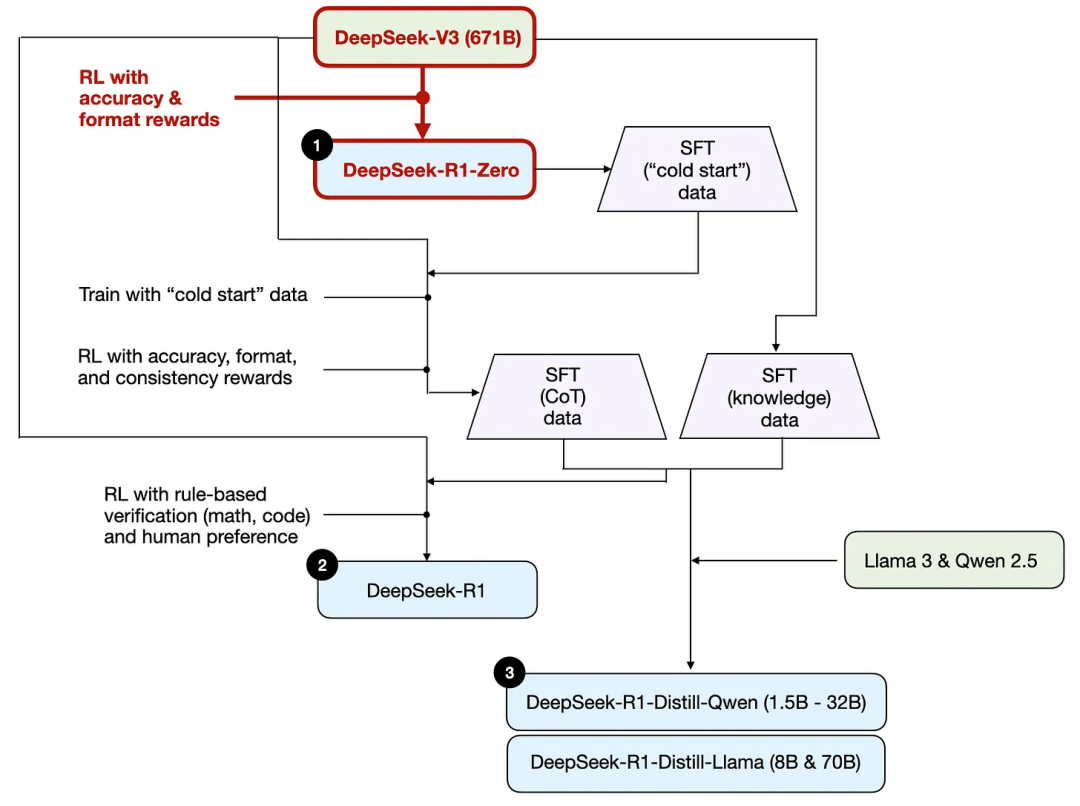
Néanmoins, ce processus d'apprentissage par renforcement est similaire à la méthode RLHF (apprentissage par renforcement avec retour humain) couramment utilisée pour l'ajustement des préférences des LLM. Cependant, comme indiqué ci-dessus, la différence clé de DeepSeek - R1 - Zero est qu'ils ont omis la phase de SFT utilisée pour l'ajustement des instructions. C'est pourquoi ils l'appellent « pur » apprentissage par renforcement / Pure RL.
En matière de récompenses, ils n'ont pas utilisé de modèle de récompense formé sur des préférences humaines, mais deux types de récompenses : une récompense d'exactitude et une récompense de format.
-
Récompense d'exactitude / accuracy reward : utilise le compilateur LeetCode pour valider les réponses de programmation et un système déterministe pour évaluer les réponses mathématiques.
-
Récompense de format / format reward : repose sur un juge LLM pour garantir que les réponses respectent le format attendu, par exemple en plaçant les étapes de raisonnement entre des balises.
Étonnamment, cette méthode suffit à permettre au LLM de développer des compétences de base en raisonnement. Les chercheurs ont observé un « moment eurêka », où le modèle commence à produire des traces de raisonnement dans ses réponses, bien qu'il n'ait pas été explicitement entraîné à cet effet, comme illustré ci-dessous, extrait du rapport technique R1.

Bien que R1 - Zero ne soit pas le meilleur modèle de raisonnement, comme le montre l'image ci-dessus, il démontre bel et bien une capacité de raisonnement en générant des étapes intermédiaires de « pensée ». Cela confirme qu'il est possible de développer des modèles de raisonnement via un apprentissage par renforcement pur, et DeepSeek est la première équipe à avoir montré (ou du moins publié des résultats sur) cette approche.
3. Ajustement fin supervisé et apprentissage par renforcement (SFT + RL)
Examinons maintenant le développement du modèle phare de DeepSeek, DeepSeek - R1, un véritable modèle de référence pour la construction de modèles de raisonnement. Ce modèle, basé sur DeepSeek - R1 - Zero, intègre davantage d'ajustement fin supervisé (SFT) et d'apprentissage par renforcement (RL) afin d'améliorer ses performances en matière de raisonnement.
Il convient de noter qu'ajouter une phase de SFT avant l'apprentissage par renforcement est courant dans le flux RLHF standard. Il est fort probable que le modèle o1 d'OpenAI ait été développé selon une méthode similaire.
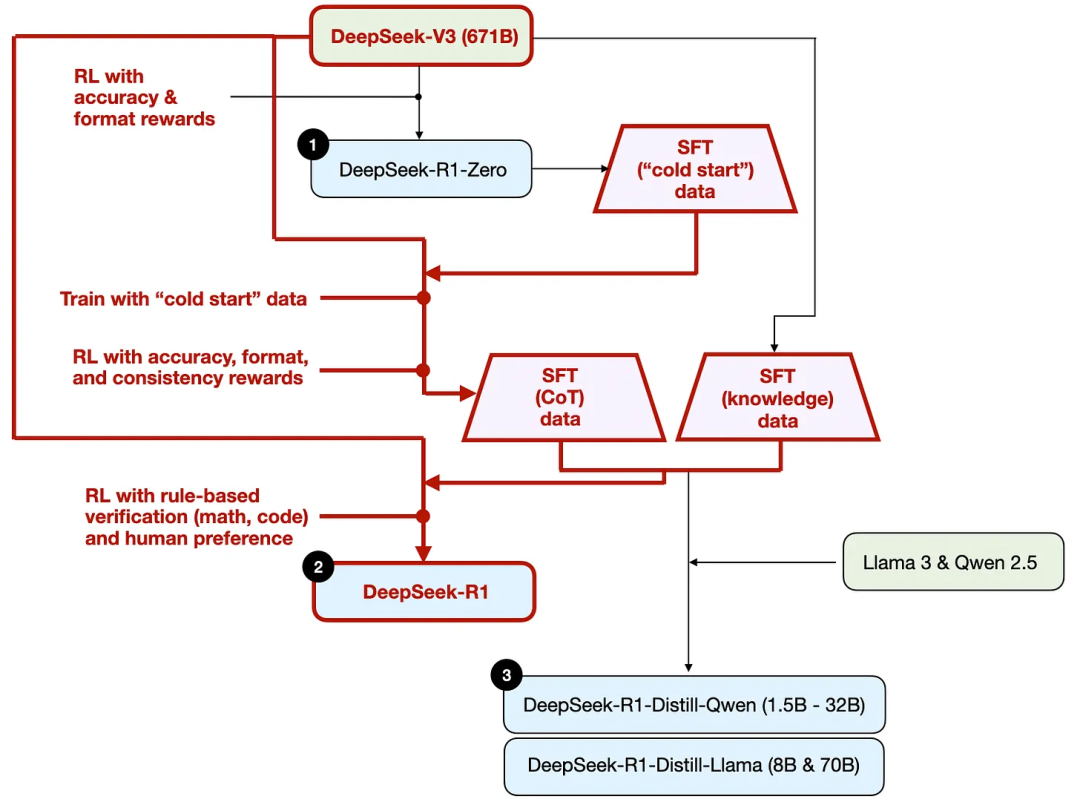
Comme illustré ci-dessus, l'équipe DeepSeek a utilisé DeepSeek - R1 - Zero pour générer ce qu'ils appellent des données d'ajustement fin supervisé (SFT) de « cold start ». Le terme « cold start » signifie que ces données ont été générées par DeepSeek - R1 - Zero, lui-même n'ayant jamais été entraîné sur aucune donnée SFT.
À l'aide de ces données SFT de « cold start », DeepSeek a d'abord entraîné le modèle par ajustement fin d'instructions, puis est passé à une autre phase d'apprentissage par renforcement (RL). Cette phase RL reprend les récompenses d'exactitude et de format utilisées dans le processus RL de DeepSeek - R1 - Zero. Toutefois, ils ont ajouté une récompense de cohérence pour empêcher le modèle de mélanger les langues dans ses réponses, c’est-à-dire de passer d’une langue à une autre au cours d’une même réponse.
Après la phase RL, une autre collecte de données SFT intervient. À ce stade, 600 000 exemples SFT de type chaîne de pensée (CoT) ont été générés à l’aide du dernier checkpoint du modèle, tandis que 200 000 exemples SFT supplémentaires basés sur la connaissance ont été créés à l’aide du modèle de base DeepSeek-V3.
Ensuite, ces 600 000 + 200 000 échantillons SFT ont été utilisés pour effectuer un ajustement fin d'instructions sur le modèle de base DeepSeek-V3, suivi d’un dernier cycle de RL. À cette étape, pour les problèmes mathématiques et de programmation, ils ont à nouveau utilisé des méthodes basées sur des règles pour définir la récompense d’exactitude, tandis que pour les autres types de questions, ils ont utilisé des étiquettes de préférence humaine. En résumé, cela ressemble beaucoup au RLHF classique, sauf que les données SFT contiennent (plus d’) exemples de chaînes de pensée, et que l’apprentissage par renforcement inclut non seulement des récompenses basées sur les préférences humaines, mais aussi des récompenses vérifiables.
Le modèle final, DeepSeek - R1, grâce aux phases supplémentaires de SFT et de RL, présente une amélioration significative des performances par rapport à DeepSeek - R1 - Zero, comme le montre le tableau ci-dessous.
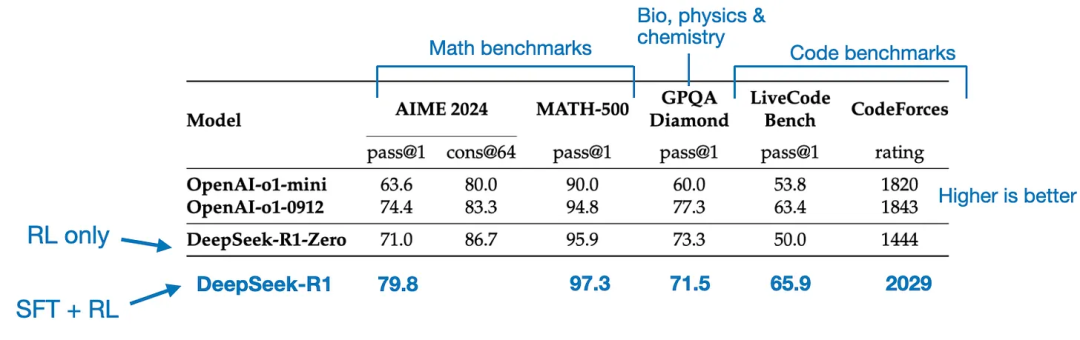
4. Ajustement fin supervisé pur (SFT) et distillation
Jusqu'à présent, nous avons présenté trois méthodes clés pour construire et améliorer les modèles de raisonnement :
1/ Extension au moment de l'inférence, une technique qui améliore les capacités de raisonnement sans nécessiter d'entraînement ni modification du modèle sous-jacent.
2/ Pure RL, comme utilisé dans DeepSeek - R1 - Zero, qui montre que le raisonnement peut apparaître comme un comportement acquis, sans ajustement fin supervisé.
3/ Ajustement fin supervisé (SFT) + apprentissage par renforcement (RL), menant au modèle de raisonnement DeepSeek - R1.
Il reste maintenant la « distillation » du modèle. DeepSeek a également publié des modèles plus petits entraînés par ce qu'ils appellent un processus de distillation. Dans le contexte des LLM, la distillation ne suit pas nécessairement la méthode classique de distillation de connaissances utilisée en apprentissage profond. Traditionnellement, dans la distillation de connaissances, un petit modèle « élève » est entraîné sur les sorties logiques d'un grand modèle « enseignant » ainsi que sur l'ensemble de données cible.
Cependant, ici, la distillation désigne l'ajustement fin d'instructions sur un petit LLM à l'aide d'un ensemble de données SFT généré par un LLM plus grand, par exemple les modèles Llama 8B et 70B, ainsi que Qwen 2.5B (0.5B - 32B). Plus précisément, ces grands LLM sont DeepSeek-V3 et un checkpoint intermédiaire de DeepSeek-R1. En réalité, les données SFT utilisées pour ce processus de distillation sont identiques à celles décrites dans la section précédente pour entraîner DeepSeek-R1.
Pour clarifier ce processus, j'ai mis en évidence la partie distillation dans le schéma ci-dessous.
Pourquoi développer ces modèles distillés ? Deux raisons principales :
1/ Les modèles plus petits sont plus efficaces. Cela signifie qu'ils coûtent moins cher à exécuter et peuvent fonctionner sur du matériel bas de gamme, ce qui les rend particulièrement attrayants pour de nombreux chercheurs et amateurs.
2/ Comme étude de cas d'ajustement fin supervisé pur (SFT). Ces modèles distillés constituent une référence intéressante pour montrer jusqu'où un ajustement fin supervisé pur peut amener un modèle en l'absence d'apprentissage par renforcement.
Le tableau ci-dessous compare les performances de ces modèles distillés à celles d'autres modèles populaires ainsi qu'aux modèles DeepSeek - R1 - Zero et DeepSeek - R1.
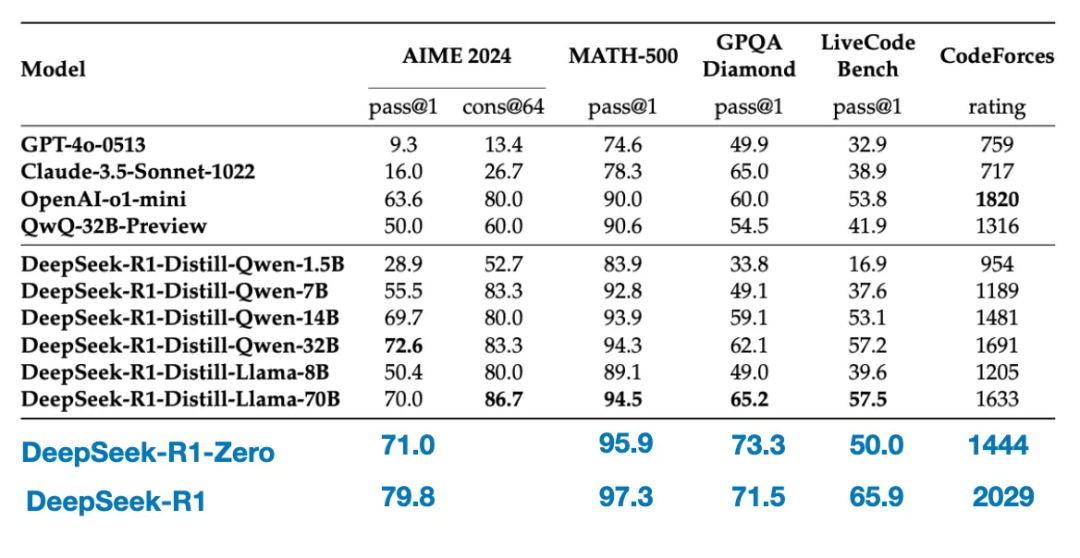
Comme on peut le voir, bien que les modèles distillés soient plusieurs ordres de grandeur plus petits que DeepSeek - R1, ils sont nettement plus puissants que DeepSeek - R1 - Zero, bien qu'ils restent inférieurs à DeepSeek - R1. De façon tout aussi intéressante, ces modèles se comparent favorablement à o1-mini (on soupçonne que o1-mini est lui-même une version similaire de distillation de o1).
Une autre comparaison mérite d'être mentionnée. L'équipe DeepSeek a testé si le comportement de raisonnement émergent observé dans DeepSeek - R1 - Zero pouvait également apparaître dans des modèles plus petits. Pour étudier cela, ils ont appliqué directement la même méthode d'apprentissage par renforcement pur de DeepSeek - R1 - Zero au modèle Qwen-32B.
Le tableau ci-dessous résume les résultats de cette expérience, où QwQ-32B-Preview est un modèle de référence de raisonnement basé sur Qwen 2.5 32B développé par l'équipe Qwen. Cette comparaison apporte des éléments de compréhension supplémentaires sur la capacité de l'apprentissage par renforcement pur à induire des compétences de raisonnement dans des modèles bien plus petits que DeepSeek - R1 - Zero.
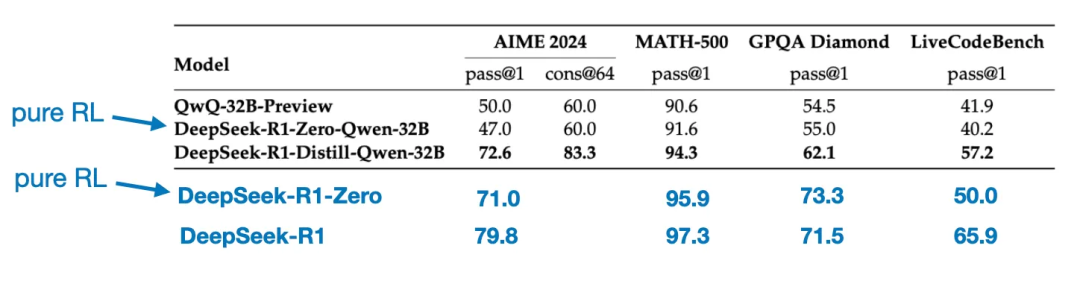
Fait intéressant, les résultats montrent que pour les modèles plus petits, la distillation est beaucoup plus efficace que l'apprentissage par renforcement pur. Cela va dans le sens de l'idée que l'apprentissage par renforcement seul pourrait ne pas suffire pour induire de fortes capacités de raisonnement dans des modèles de cette taille, et que pour les petits modèles, l'ajustement fin supervisé basé sur des données de raisonnement de haute qualité pourrait être une stratégie plus efficace.
Conclusion
Nous avons exploré quatre stratégies différentes pour construire et améliorer les modèles de raisonnement :
-
Extension au moment de l'inférence : ne nécessite aucun entraînement supplémentaire, mais augmente le coût d'inférence. À mesure que le nombre d'utilisateurs ou de requêtes croît, le coût du déploiement à grande échelle devient plus élevé. Toutefois, c'est toujours une méthode simple et efficace pour améliorer les performances d'un modèle déjà puissant. Je soupçonne fortement qu'o1 utilise l'extension au moment de l'inférence, ce qui expliquerait pourquoi le coût par token généré est plus élevé avec o1 comparé à DeepSeek - R1.
-
Apprentissage par renforcement pur (Pure RL) : intéressant d'un point de vue recherche, car cela nous aide à mieux comprendre le raisonnement comme un comportement émergent. Toutefois, en développement de modèles pratiques, combiner apprentissage par renforcement et ajustement fin supervisé (RL + SFT) est une option supérieure, car cela permet de construire des modèles de raisonnement plus performants. Je soupçonne également fortement qu'o1 a été entraîné avec RL + SFT. Plus précisément, je pense qu'o1 part d'un modèle de base plus faible et plus petit que DeepSeek - R1, mais compense cet écart grâce à RL + SFT et à l'extension au moment de l'inférence.
-
Comme indiqué ci-dessus, RL + SFT est la méthode clé pour construire des modèles de raisonnement hautement performants. DeepSeek - R1 nous offre une excellente feuille de route pour y parvenir.
-
Distillation : une méthode attrayante, particulièrement utile pour créer des modèles plus petits et plus efficaces. Toutefois, sa limitation réside dans le fait que la distillation ne peut pas stimuler l'innovation ni produire la prochaine génération de modèles de raisonnement. Par exemple, la distillation dépend toujours d'un modèle existant plus puissant pour générer les données d'ajustement fin supervisé (SFT).
Ensuite, une direction intéressante que j'attends avec impatience est la combinaison de RL + SFT (méthode 3) avec l'extension au moment de l'inférence (méthode 1). C'est très probablement ce qu'OpenAI fait avec o1, bien que o1 parte peut-être d'un modèle de base plus faible que DeepSeek - R1, ce qui expliquerait pourquoi DeepSeek - R1 excelle en performance d'inférence avec un coût relativement bas.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News










