

OpenAI vient de publier son nouveau modèle o1, nous entrons officiellement dans une ère nouvelle.
TechFlow SélectionTechFlow Sélection
OpenAI vient de publier son nouveau modèle o1, nous entrons officiellement dans une ère nouvelle.
Nous n'avons plus aucun obstacle sur la route vers l'AGI.
Auteur : Kazek
En pleine nuit, OpenAI a révélé son nouveau modèle, attendu depuis près de six mois.
Sans aucun avertissement préalable, il est officiellement arrivé.
Le nom officiel n’est pas « Fraise » — ce n’était qu’un pseudonyme interne. Son véritable nom est :

Pourquoi l’appeler o1 ? Voici ce qu’explique OpenAI :
Pour les tâches complexes de raisonnement, ceci constitue une avancée majeure et représente un nouveau niveau de capacité en intelligence artificielle. Étant donné cela, nous réinitialisons le compteur à 1 et nommons cette série OpenAI o1.
Autrement dit :
Pour les tâches complexes de raisonnement, ceci constitue une avancée majeure et marque un nouveau palier dans les capacités de l’IA. C’est pourquoi nous réinitialisons le compteur à 1 et baptisons cette nouvelle série OpenAI o1.
La puissance de ce modèle est telle qu’OpenAI a choisi d’abandonner la désignation GPT au profit d’une nouvelle série o.
Explosif. Vraiment explosif.
À cet instant précis, j’en ai la chair de poule. La sortie d’OpenAI o1 marque sans conteste l’entrée officielle de l’industrie de l’IA dans une ère entièrement nouvelle.
« Sur notre chemin vers l’AGI, il n’y a désormais plus aucun obstacle. »
Concernant ses compétences logiques et de raisonnement, je vais directement vous montrer une image pour que vous compreniez à quel point c’est impressionnant.
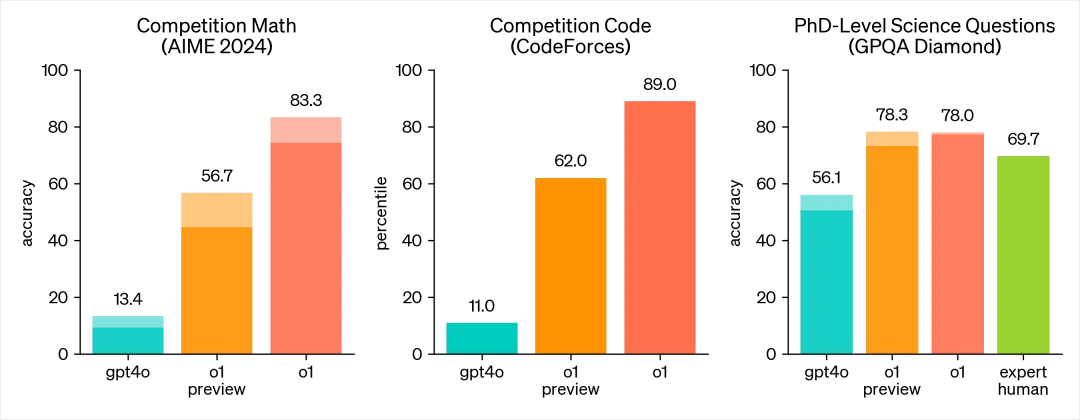
AIME 2024, une compétition mathématique de haut niveau : précision de 13,4 % pour GPT-4o, 56,7 % pour la version préliminaire d’o1, et 83,3 % pour la version finale non encore publiée d’o1.
Dans les concours de programmation : 11,0 % pour GPT-4o, 62 % pour o1 (version préliminaire), 89 % pour o1 (version finale).
Et le plus impressionnant, sur les questions scientifiques de niveau doctoral (GPQA Diamond) : GPT-4o atteint 56,1, les experts humains 69,7, tandis qu’o1 atteint un score effrayant de 78.
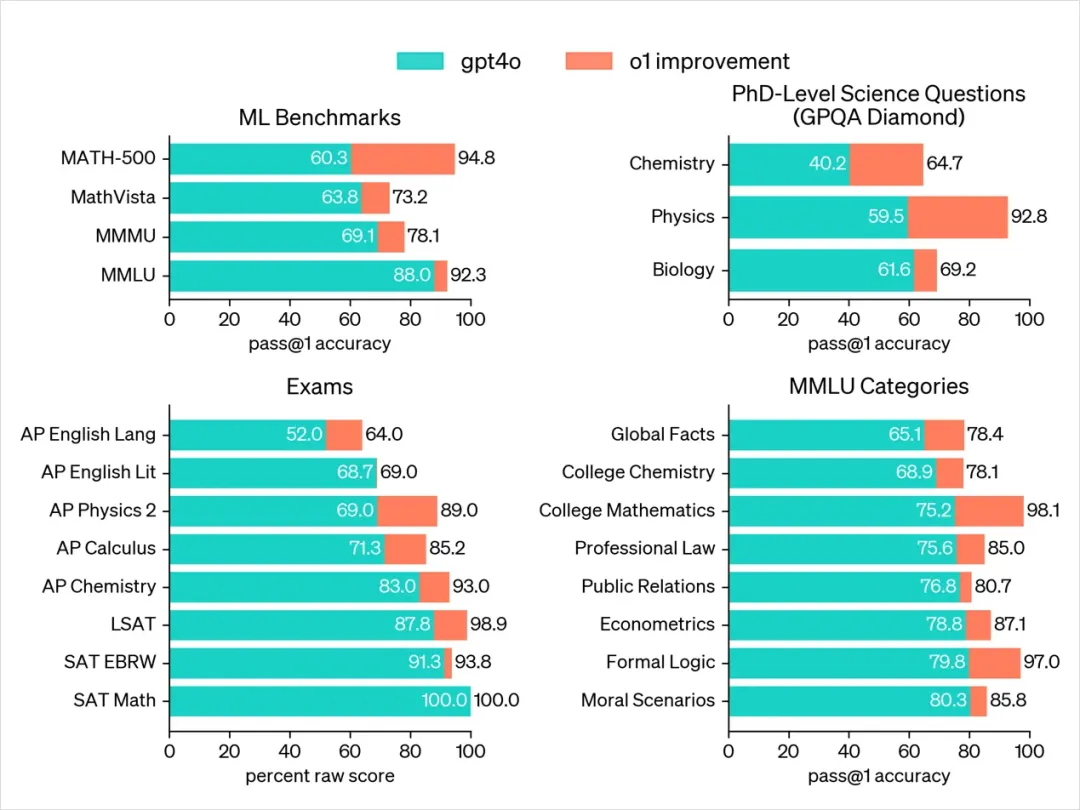
J’ai demandé à Claude de traduire le graphique d’o1. Le rendu est moche, mais on comprend bien chaque donnée.

Voilà ce qu’on appelle une domination totale.
Particulièrement remarquable sur la référence GPQA-diamond, qui teste les connaissances spécialisées en chimie, physique et biologie, où o1 dépasse complètement les experts humains titulaires d’un doctorat — une première historique pour un modèle.
L’élément fondamental ayant permis à ce modèle d’atteindre un tel niveau est le Self-play RL. Pour ceux qui ne connaissent pas, je vous invite à lire mon article de prédiction publié il y a deux jours : Que vaut vraiment le nouveau modèle "Fraise" ?
Grâce au Self-play RL, o1 a appris à affiner sa chaîne de pensée et perfectionner ses stratégies. Il a appris à identifier et corriger ses propres erreurs.
Il a aussi appris à décomposer des étapes complexes en étapes plus simples.
Et lorsqu’une méthode actuelle échoue, il sait essayer d’autres approches.
Ce qu’il a ainsi acquis correspond exactement aux modes de pensée les plus fondamentaux de l’être humain : la pensée lente.
Daniel Kahneman, prix Nobel d’économie, a écrit un ouvrage intitulé *Thinking, Fast and Slow* (*Réfléchir, vite et lentement*), qui décrit très précisément ces deux systèmes cognitifs humains.
Le premier est la pensée rapide (système 1) : elle est rapide, automatique, intuitive et inconsciente. Par exemple :
-
Reconnaître qu’une personne souriante est de bonne humeur.
-
Effectuer mentalement un calcul simple comme 1+1=2.
-
Freiner brusquement en cas de danger pendant la conduite.
Tel est le mode de pensée rapide, correspondant aux grands modèles traditionnels, capables de réactions rapides acquises par apprentissage mécanique.
Le second type est la pensée lente (système 2) : elle est lente, exigeante, logique et consciente. Par exemple :
-
Résoudre un problème mathématique complexe.
-
Remplir une déclaration fiscale.
-
Prendre une décision importante après avoir pesé le pour et le contre.
Voilà la pensée lente, cœur de l’intelligence humaine, et pierre angulaire du prochain grand saut vers l’AGI.
Aujourd’hui, o1 franchit enfin une étape décisive : il possède désormais les caractéristiques de la pensée lente humaine. Avant de répondre, il réfléchit, décompose, comprend et raisonne intensivement, puis donne sa réponse finale.
Franchement, ces capacités accrues de raisonnement sont extrêmement utiles pour traiter des problèmes complexes dans des domaines comme la science, la programmation ou les mathématiques.
Par exemple, o1 pourrait aider des chercheurs médicaux à annoter des données de séquençage cellulaire, assister des physiciens dans la génération de formules mathématiques complexes nécessaires en optique quantique, ou permettre aux développeurs de divers domaines de concevoir et exécuter des flux de travail multi-étapes, entre autres applications.
o1 constitue également une toute nouvelle génération de boucle de données vertueuse : si la réponse est correcte, toute la chaîne logique devient un petit jeu de données d’entraînement incluant des récompenses positives et négatives.
Avec le niveau d’utilisation d’OpenAI, sa vitesse future d’évolution ne pourra être que terrifiante.
En écrivant ces lignes, j’ai soudain poussé un soupir. Comparé à o1 dans un an, je me sentirai peut-être totalement inutile… vraiment.
Actuellement, le modèle o1 est progressivement accessible à tous les utilisateurs de ChatGPT Plus et Team, et une ouverture future aux utilisateurs gratuits est envisagée.
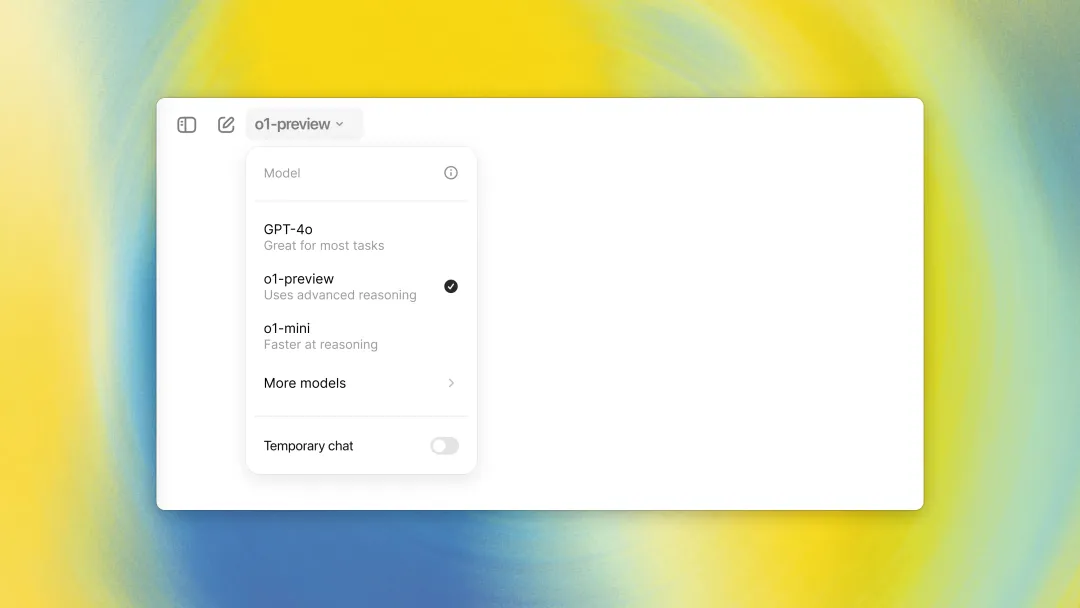
Deux modèles sont proposés : o1-preview et o1-mini. o1-mini est plus rapide, plus petit et moins coûteux, avec de bonnes performances en raisonnement, particulièrement adapté aux mathématiques et au code, bien qu’il manque de connaissances générales. Il convient parfaitement aux scénarios nécessitant un raisonnement sans exiger une vaste culture générale.
o1-preview dispose de 30 requêtes hebdomadaires, o1-mini de 50.
La limitation n’est même plus horaire comme auparavant (par exemple 3 heures), mais hebdomadaire — 30 requêtes seulement. Cela reflète indirectement combien ce modèle o1 est coûteux.
Pour les développeurs, l’accès est restreint aux niveaux 5 ayant déjà payé 1 000 dollars, avec une limite de 20 appels par minute.
Très peu, effectivement.
Les fonctionnalités sont aussi fortement limitées, mais étant donné qu’il s’agit d’une phase précoce, on peut le comprendre.

Côté API, o1-preview coûte 15 $ par million de tokens d’entrée et 60 $ par million de tokens de sortie — un coût de raisonnement tout simplement...

o1-mini est un peu moins cher : 3 $ par million d’entrées et 12 $ par million de sorties.

Le coût de sortie est systématiquement 4 fois supérieur au coût d’entrée. À titre de comparaison, GPT-4o coûte respectivement 5 $ et 15 $.

o1-mini présente encore quelques économies d’échelle, mais c’est juste le début. Attendons que OpenAI baisse drastiquement les prix.
Puisque o1 est désormais accessible aux utilisateurs Plus, j’ai immédiatement vérifié sur mon compte. Pas mal, j’y ai accès.
Naturellement, je l’ai testé sans tarder.
Pour l’instant, toutes les fonctions précédentes sont désactivées : pas de reconnaissance d’image, ni de génération d’image, ni d’interpréteur de code, ni de recherche web. Seul un modèle conversationnel nu est disponible.
J’ai commencé par poser une question classiquement difficile :
« Un fermier doit traverser une rivière avec un loup, un mouton et un chou. Il ne peut transporter qu’un seul élément à la fois. Le loup ne peut pas rester seul avec le mouton, ni le mouton seul avec le chou. Comment doit-il faire ? »

Après 6 secondes de réflexion, il m’a fourni une réponse parfaitement correcte.
Passons ensuite à une autre question piégeuse, célèbre pour avoir berné tous les grands modèles : celle des jours de congé ajustés en Chine.
« Voici le calendrier de congés et ajustements horaires en Chine du 9 septembre 2024 (lundi) au 13 octobre : travailler 6 jours, repos 3 jours ; travailler 3 jours, repos 2 jours ; travailler 5 jours, repos 1 jour ; travailler 2 jours, repos 7 jours ; puis travailler 5 jours, repos 1 jour. En excluant mes week-ends normaux, combien de jours de repos supplémentaires ai-je obtenus grâce aux congés ? »
Après exactement 30 secondes de réflexion, o1 a fourni une réponse d’une précision absolue, sans aucune erreur.
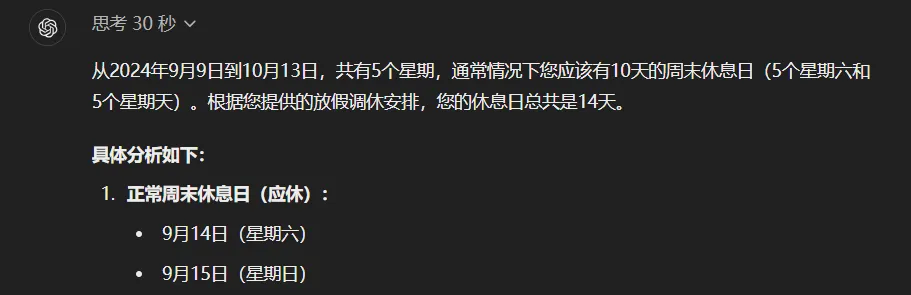

Imparable. Vraiment imparable.
Essayons-en une encore plus difficile : le problème d’olympiade mathématique de Jiang Ping.

Ne me demandez pas de quoi parle l’exercice — je ne comprends pas, je suis nul. Ce problème a éliminé tous les grands modèles jusqu’ici. Voyons comment o1 va s’en sortir.

Après plus d’une minute complète de réflexion, il a donné sa réponse.
...
To... tal... men... te... cor... rec... te...
Je suis scié.
D’après mes tests personnels, il semble que la manière de formuler les prompts devra être repensée. À l’ère des grands modèles axés sur la pensée rapide comme GPT, nous utilisions souvent des techniques comme « pense étape par étape ». Aujourd’hui, elles sont toutes inefficaces, voire nuisibles avec o1.
OpenAI recommande les meilleures pratiques suivantes :
-
Gardez les instructions simples et directes : le modèle excelle à comprendre et répondre à des consignes courtes et claires, sans besoin d’indications détaillées.
-
Évitez les prompts de type « chaîne de pensée » : comme le modèle effectue déjà un raisonnement interne, il est inutile de lui demander de « penser étape par étape » ou de « justifier votre raisonnement ».
-
Utilisez des délimiteurs pour plus de clarté : employez des guillemets triples, des balises XML ou des titres de section pour distinguer clairement les différentes parties de l’entrée, aidant ainsi le modèle à interpréter correctement chaque segment.
-
Limitez le contexte additionnel dans la génération assistée par récupération (RAG) : lorsque vous fournissez des documents ou contextes supplémentaires, incluez uniquement les informations les plus pertinentes afin d’éviter que le modèle n’alourdisse excessivement sa réponse.
Enfin, parlons un peu de la durée de réflexion.
Actuellement, o1 met une minute à réfléchir. Mais si l’on parle d’un véritable AGI, honnêtement, plus la réflexion sera longue, plus ce sera fascinant.
Et si un jour, il était capable de démontrer des théorèmes mathématiques, de concevoir des médicaments contre le cancer, ou d’effectuer des recherches en astrophysique ?
Et si chaque processus de réflexion durait plusieurs heures, plusieurs jours, voire plusieurs semaines ?
Le résultat final pourrait alors stupéfier l’humanité au-delà de toute imagination.
Personne aujourd’hui ne peut imaginer à quoi ressemblera l’IA de cette époque.
Et selon moi, l’avenir d’o1 ne se limitera certainement pas à être un simple ChatGPT amélioré.
Il sera bel et bien la pierre angulaire la plus importante vers la prochaine ère.
« Sur notre chemin vers l’AGI, il n’y a désormais plus aucun obstacle. »
Maintenant, je crois fermement à cette phrase, sans aucune hésitation.
Une ère radieuse et scintillante.
Aujourd’hui,
est officiellement arrivée.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














