

Niveau d'optimisation optimal : tirer des leçons de la maximisation des objectifs dans l'apprentissage machine
TechFlow SélectionTechFlow Sélection
Niveau d'optimisation optimal : tirer des leçons de la maximisation des objectifs dans l'apprentissage machine
Une faible efficacité n'est pas bonne, mais une efficacité très élevée est-elle nécessairement bonne ?
Par : DAN SHIPPER
Traduction : Ines
Prompt Midjourney : « Du point de vue d'une personne sur le point de traverser un pont, imaginer un pont suspendu en planches de bois et cordes enjambant un gouffre immense et dangereux, aquarelle. »
À quel point devrais-je optimiser ? C’est une question que je me pose souvent, et vous l’avez probablement aussi posée. Si vous cherchez à atteindre un objectif — par exemple créer une entreprise familiale durable, trouver le partenaire idéal ou concevoir un programme d’exercice parfait — votre tendance naturelle est de tout faire pour atteindre la perfection.
L’optimisation est une quête de perfection — nous optimisons parce que nous refusons de nous contenter de moins. Mais est-il toujours préférable de pousser l’optimisation à son maximum ? Autrement dit, à partir de quel moment l’optimisation va-t-elle trop loin ?
Depuis longtemps, les penseurs ont tenté de comprendre la difficulté de l’optimisation. On peut les placer sur un spectre.
À une extrémité se trouve John Mayer, qui croit que moins c’est plus. Dans son tube « Gravity », il chante :
« Oh, deux fois mieux n’est pas vraiment deux fois mieux / ni ne dure comme la moitié / vouloir plus m’écrase au sol. »
Dolly Parton, quant à elle, pense exactement le contraire. Son credo : « Moins, ce n’est pas plus. Plus, c’est plus. »
Aristote rejette ces deux positions. Il y a 2000 ans, il proposait déjà un juste milieu : lorsque vous optimisez vers un objectif, ce dont vous avez besoin se situe entre l’excès et le défaut.
Laquelle choisir ? Nous sommes en 2023. Sur cette question, nous voulons davantage de quantification, moins de généralités. Idéalement, nous aimerions pouvoir mesurer d’une manière ou d’une autre l’efficacité de notre optimisation vers un objectif.
Heureusement, nous pouvons aujourd’hui demander de l’aide aux machines. L’optimisation des objectifs est justement l’un des sujets clés étudiés par les chercheurs en apprentissage automatique et en intelligence artificielle. Pour que les réseaux neuronaux accomplissent quoi que ce soit d’utile, il faut leur fixer un objectif, puis s’efforcer de les améliorer dans sa réalisation. Ce que les informaticiens ont découvert dans ce domaine peut nous enseigner beaucoup sur l’optimisation en général.
Un article récent du chercheur en apprentissage automatique Jascha Sohl-Dickstein m’a particulièrement enthousiasmé. Il y expose l’idée suivante :
L’apprentissage automatique nous montre que trop optimiser un objectif peut tout gâcher — et cela peut être mesuré précisément. Quand un algorithme d’apprentissage automatique optimise excessivement son objectif, il finit par ignorer le contexte global, ce que les chercheurs appellent le « surajustement » (overfitting). En pratique, quand nous nous concentrons trop intensément sur l’amélioration d’un processus ou d’une tâche, nous devenons trop adaptés à la tâche en cours, et incapables de faire face efficacement à des changements ou à de nouveaux défis.
Donc, concernant l’optimisation — en effet, « plus » ne signifie pas toujours « plus ». Prends ça, Dolly Parton.
Cet article est ma tentative de résumer l’article de Jascha et d’en expliquer les idées en langage simple. Pour le comprendre, examinons comment s’effectue l’entraînement d’un modèle d’apprentissage automatique.
Mindsera utilise l’intelligence artificielle pour vous aider à découvrir vos schémas mentaux cachés, révéler vos biais cognitifs et mieux vous connaître.
Grâce à des modèles de journal intégrant des cadres utiles et des modèles mentaux, construisez votre pensée pour prendre de meilleures décisions, améliorer votre santé et booster votre productivité.
L’IA Mentor de Mindsera imite la pensée de géants intellectuels comme Marc Aurèle et Socrate, vous offrant de nouvelles voies d’insight.
L’analyse intelligente génère des œuvres originales à partir de vos écrits, mesure votre état émotionnel, reflète votre personnalité et vous donne des conseils personnalisés pour progresser.
Développez la conscience de soi, clarifiez votre esprit, réussissez dans un monde de plus en plus incertain.
Commencez maintenant.
Vous souhaitez être bénévole ? Cliquez ici.
👉https://www.passionfroot.me/every
Trop d’efficacité empire tout
Imaginez que vous souhaitiez créer un modèle d’apprentissage automatique excellent pour classifier des photos de chiens. Vous voulez entrer une photo de chien et obtenir la race correspondante. Mais vous ne voulez pas un simple classificateur standard. Vous visez une machine inégalée, prête à tout coûter, sans relâche, alimentée par d’innombrables cafés. (Après tout, nous sommes en phase d’optimisation.)
Comment y parvenir ? Bien qu’il existe plusieurs stratégies, vous choisirez probablement l’apprentissage supervisé. Celui-ci agit comme un tuteur pour votre modèle : il lui pose continuellement des questions et le corrige lorsqu’il se trompe, l’aidant ainsi à apprendre progressivement les bonnes réponses. Au fil du temps, la précision du modèle augmente.
Première étape : constituer un jeu de données d’images pour entraîner le modèle. Vous attribuez à chaque image une étiquette prédéfinie : « caniche », « cockerapoo », « terrier Dandie Dinmont », etc. Puis vous injectez ces images avec leurs étiquettes dans le modèle, lançant ainsi son apprentissage.
Le modèle apprend selon une méthode d’essais-erreurs. Vous lui montrez une image, il tente de deviner l’étiquette. S’il se trompe, vous ajustez légèrement ses paramètres pour améliorer sa réponse future. En continuant ainsi, vous constatez que le modèle devient de plus en plus performant pour prédire les étiquettes des images qu’il a vues pendant l’entraînement.
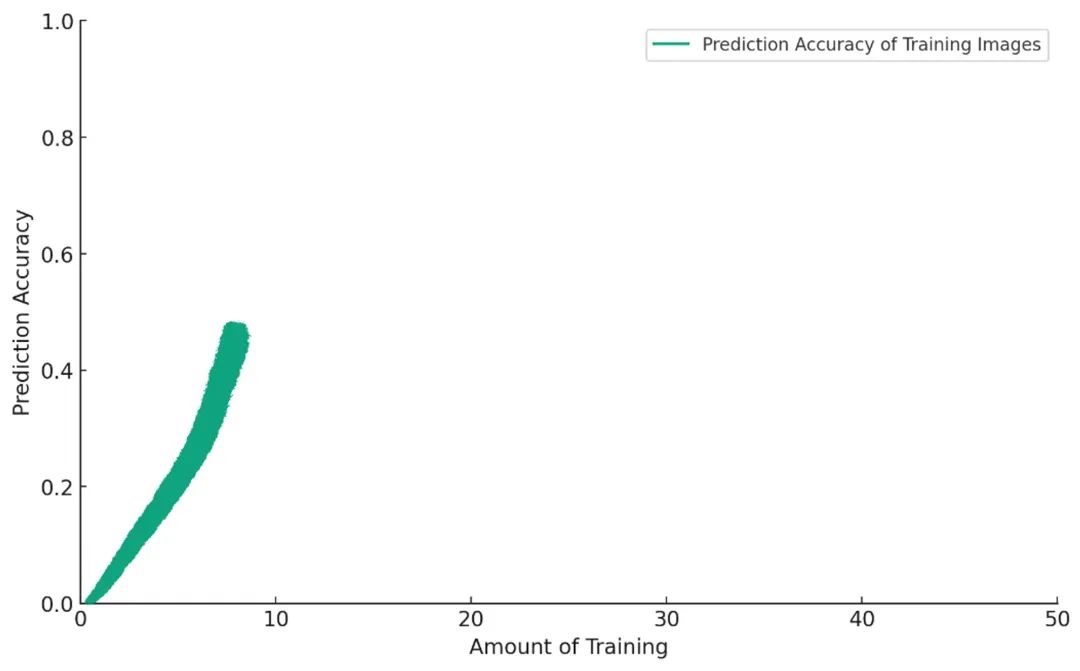
Le modèle excelle désormais à classer les images du jeu d’entraînement. Vous lui donnez alors une nouvelle mission : identifier des chiens sur des photos qu’il n’a jamais vues auparavant.
Ce test est crucial : interroger uniquement sur des images déjà connues reviendrait à tricher à un examen. Vous récupérez donc de nouvelles photos de chiens que vous êtes certain que le modèle n’a jamais vues.
Au début, tout va bien. Plus vous entraînez le modèle, mieux il fonctionne :
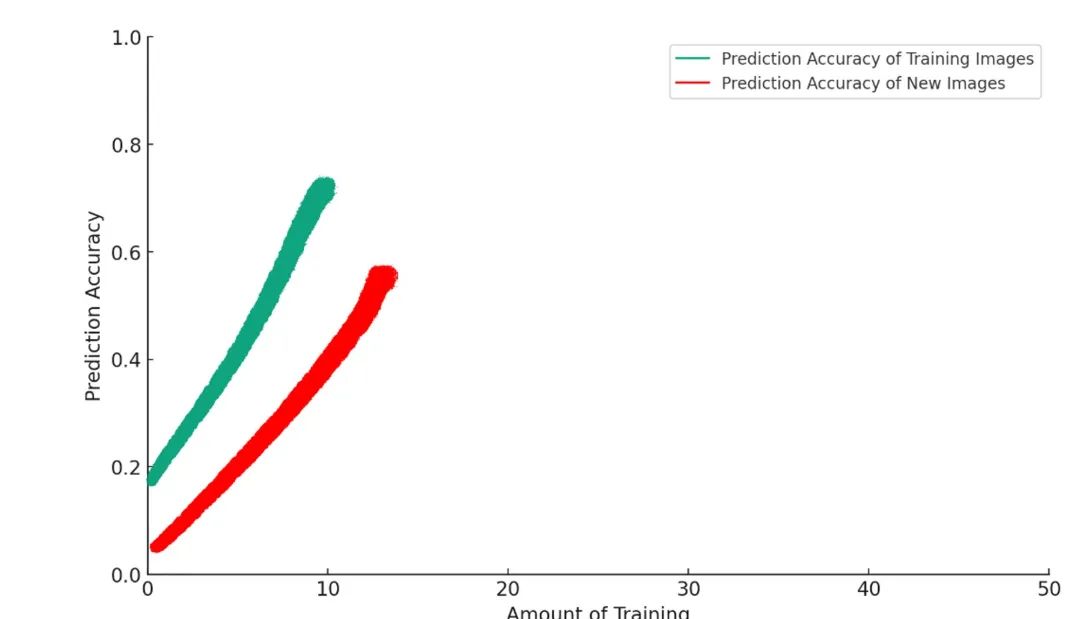
Mais si vous continuez à entraîner le modèle, il commence à faire des choses absurdes — une sorte de version IA de « faire caca sur le tapis ». Que se passe-t-il donc ?
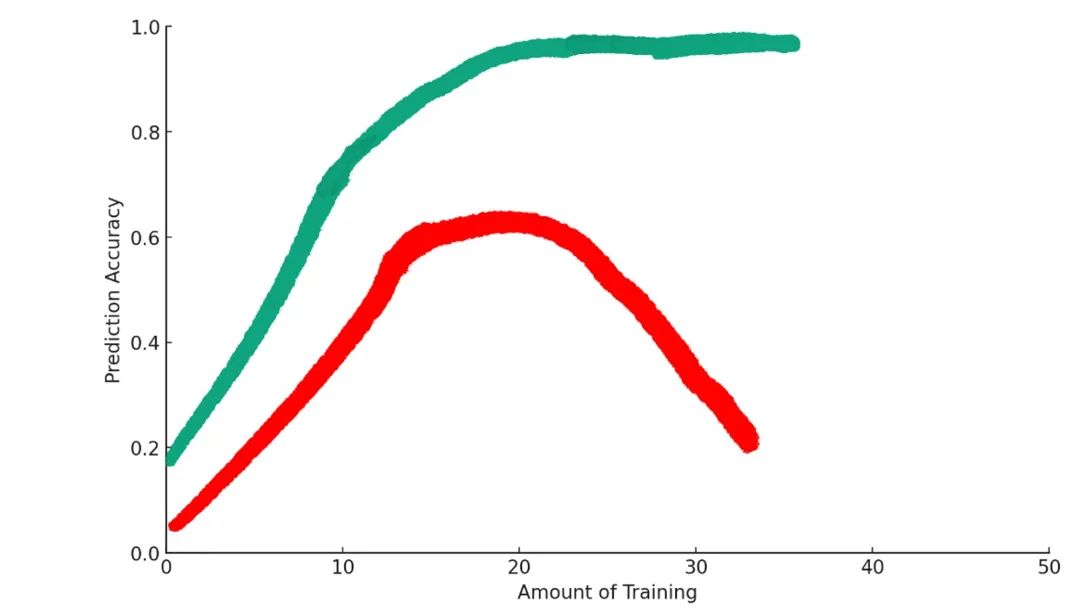
Quel est le problème ?
Un peu d’entraînement rend le modèle meilleur pour atteindre son but. Mais au-delà d’un certain seuil, trop d’entraînement détériore en réalité les performances. En apprentissage automatique, ce phénomène s’appelle le « surajustement » (overfitting).
Pourquoi le surajustement empire les choses
Entraîner un modèle implique une opération subtile.
Nous voulons que le modèle classe correctement n’importe quelle photo de chien — c’est notre véritable objectif. Mais nous ne pouvons pas directement optimiser cela, car il est impossible d’avoir toutes les photos possibles de chiens. À la place, nous optimisons un objectif intermédiaire : un petit sous-ensemble d’images censé représenter l’objectif réel.
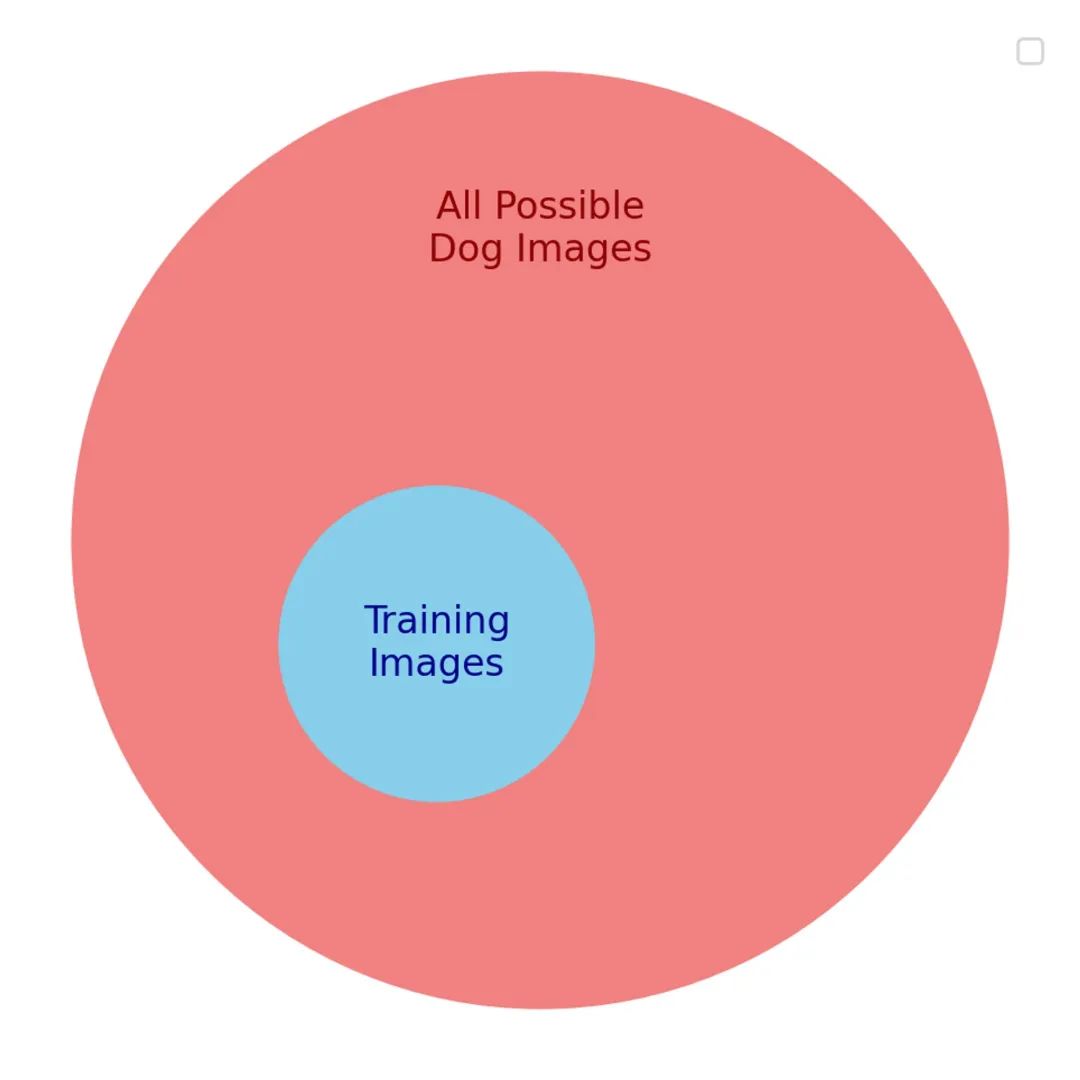
Il existe de nombreuses similitudes entre cet objectif intermédiaire et l’objectif réel. Au début, le modèle progresse sur les deux fronts. Mais plus l’entraînement avance, plus ces similitudes utiles disparaissent. Le modèle devient alors expert uniquement sur les données d’entraînement, mais échoue sur les autres.
En continuant l’entraînement, le modèle commence à trop dépendre des détails spécifiques de votre jeu de données. Par exemple, si celui-ci contient beaucoup de photos de labradoodles jaunes, un modèle surentraîné pourrait conclure que tous les chiens jaunes sont des labradoodles.
Quand il rencontre une nouvelle image différente des données d’entraînement, ce modèle surajusté échoue lamentablement.
Le surajustement révèle une vérité importante sur l’optimisation.
Premièrement, quand vous essayez d’optimiser quelque chose, vous n’optimisez presque jamais directement cet objectif — vous optimisez un substitut. Dans le cas du chien, nous ne pouvons pas entraîner sur toutes les photos possibles. Nous nous contentons d’un sous-ensemble, espérant une bonne généralisation. Cela marche… jusqu’à ce que nous trop optimisions.
Deuxièmement : en surextrayant un objectif intermédiaire, vous vous éloignez en réalité de votre but initial.
Une fois que vous comprenez ce mécanisme en apprentissage automatique, vous commencez à le repérer partout.
Appliquer le surajustement au monde réel
Prenons l’école :
À l’école, nous voulons optimiser l’apprentissage des disciplines enseignées. Mais mesurer la profondeur des connaissances est difficile. Alors, nous utilisons des tests standardisés, qui reflètent approximativement la maîtrise d’un sujet.
Mais lorsque élèves et écoles mettent trop l’accent sur les résultats aux tests, l’optimisation de la note nuit à l’apprentissage réel. Les élèves deviennent trop adaptés au processus de notation. Ils apprennent à passer des tests (ou à tricher) plutôt qu’à acquérir des connaissances solides.
Le monde des affaires connaît aussi ce phénomène. Dans son livre « Fooled by Randomness », Nassim Taleb raconte l’histoire de Carlos, un banquier élégant spécialiste des obligations des marchés émergents. Sa stratégie : acheter au plus bas. En 1995, après la dévaluation mexicaine, Carlos achète massivement et gagne quand les obligations remontent.
Cette stratégie rapporte 80 millions de dollars nets à sa société. Mais Carlos devient « trop adapté » au marché qu’il connaît. Son obsession du rendement cause sa chute.
En été 1998, il achète massivement des obligations russes au plus bas. La baisse s’accentue — Carlos continue d’acheter. Il double ses paris jusqu’à ce que les prix soient très bas, perdant finalement 300 millions de dollars — trois fois ce qu’il avait gagné dans toute sa carrière.
Comme le souligne Taleb : « Sur les marchés, les traders les plus performants sont souvent ceux les mieux adaptés au dernier cycle. »
Autrement dit, trop optimiser le rendement signifie trop s’adapter au cycle actuel. Vos performances grimpent à court terme. Mais ce cycle n’est qu’un échantillon du comportement global du marché — quand il change, votre stratégie gagnante peut vous ruiner.
Le même principe s’applique à mon entreprise. Every est un média en abonnement. Je veux augmenter le MRR (revenu mensuel récurrent). Pour cela, je pourrais inciter les auteurs à générer plus de pages vues, augmentant ainsi le trafic.
Ça marcherait probablement ! Plus de trafic signifie plus d’abonnés payants — jusqu’à un certain point. Au-delà, je parierais que les auteurs commenceraient à produire des articles racoleurs ou choquants, attirant des lecteurs peu engagés et peu enclins à payer. Finalement, si Every devient une usine à clics, nos abonnés payants risquent de diminuer, pas d’augmenter.
Si vous observez attentivement votre vie ou votre entreprise, vous verrez sûrement ce schéma se reproduire. Alors, que faire ?
Que devrions-nous faire ?
Les chercheurs en apprentissage automatique utilisent plusieurs techniques pour éviter le surajustement. L’article de Jascha en propose trois : arrêt précoce, bruit aléatoire et régularisation.
Arrêt précoce
Cela consiste à surveiller régulièrement la performance du modèle sur son objectif réel, et à interrompre l’entraînement dès que celle-ci diminue.
Dans le cas de Carlos, trader ayant tout perdu en achetant des obligations en chute libre, cela aurait pu signifier mettre en place un système strict de limitation des pertes, l’obligeant à sortir d’une position après une perte cumulée donnée.
Ajout de bruit aléatoire
Introduire du bruit dans les entrées ou les paramètres d’un modèle d’apprentissage automatique rend le surajustement plus difficile. Le même principe s’applique à d’autres systèmes.
Pour les élèves et les écoles, cela pourrait signifier organiser des tests standardisés à des moments aléatoires, rendant la préparation intensive plus difficile.
Régularisation
En apprentissage automatique, la régularisation pénalise les modèles trop complexes. Plus un modèle est complexe, plus il risque de surajuster. Ces détails techniques importent peu ici ; l’idée peut être appliquée ailleurs en ajoutant volontairement de la friction dans un système.
Si je veux motiver tous les auteurs d’Every à augmenter le MRR via les pages vues, je peux modifier le système de récompense : au-delà d’un certain seuil, chaque page vue supplémentaire compterait de moins en moins.
Ce sont là des solutions potentielles au surajustement, ramenant à notre question initiale : quel est le niveau optimal d’optimisation ?
Le niveau optimal d’optimisation
La principale leçon est celle-ci : vous ne pouvez presque jamais optimiser directement un objectif — vous optimisez presque toujours un substitut qui ressemble à votre but, mais n’est pas identique. C’est un proxy.
Étant donné que vous devez optimiser via un proxy, trop d’optimisation vous rend trop habile à maximiser ce proxy — ce qui vous éloigne souvent de l’objectif réel.
Retenez donc ceci : sachez exactement ce que vous optimisez. Souvenez-vous que le proxy n’est pas l’objectif. Restez flexible durant le processus, et soyez prêt à arrêter ou changer de stratégie lorsque les similarités utiles entre votre proxy et l’objectif réel s’épuisent.
Quant aux avis de John Mayer, Dolly Parton et Aristote sur la sagesse en matière d’optimisation, je pense que le prix doit revenir à Aristote et à son juste milieu.
Lorsque vous optimisez vers un but, le niveau optimal se situe entre trop et pas assez. C’est le « juste ce qu’il faut ».
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News










