

Entretien avec le fondateur de Grass : pourquoi devriez-vous participer à l'approvisionnement décentralisé de données pour l'IA ?
TechFlow SélectionTechFlow Sélection
Entretien avec le fondateur de Grass : pourquoi devriez-vous participer à l'approvisionnement décentralisé de données pour l'IA ?
Grass combine plusieurs récits haussiers différents : DePin + IA + Solana.
Rédaction : AYLO
Traduction : TechFlow
Grass est un projet extrêmement passionnant, dont le lancement du réseau principal est prévu au premier ou deuxième trimestre. Grass compte déjà plus de 500 000 utilisateurs. Lorsque le réseau Grass sera lancé, il deviendra l'un des plus grands protocoles cryptographiques du marché en termes de nombre d'utilisateurs, créant une nouvelle source de revenus pour chaque personne disposant d'une connexion Internet.
Grass combine plusieurs récits haussiers distincts : DePin + IA + Solana. Dans cet article, vous aurez l'opportunité d'écouter 0xdrej, fondateur de Grass, qui dévoile de nombreuses informations importantes. Cet article est long mais très enrichissant ; nous y aborderons ce qu'est Grass, son fonctionnement, pourquoi il a choisi Solana, entre autres sujets.
Qu'est-ce qui vous a attiré vers le domaine de la cryptographie ?
0xdrej : Oui, je suppose que j'ai manqué de nombreuses opportunités au début de mon entrée dans la cryptomonnaie. Je pense que c’est le cas pour beaucoup de gens. J’ai entendu parler de la cryptomonnaie pour la première fois au lycée, car un camarade de classe minait du Bitcoin sur son ordinateur portable. Depuis, je n’ai plus jamais eu de nouvelles de lui, mais je suis sûr qu’il se porte bien aujourd’hui. En réalité, j’ai également participé à une faucette Doge en 2014, juste après le lancement de Doge, mais j’ai perdu l’accès à ce compte. Ce sont donc là mes deux premières expériences marquantes avec la cryptomonnaie, mais ce n’est que depuis quelques années, lorsque j’ai commencé à découvrir la finance décentralisée (DeFi), que je me suis véritablement plongé dans la recherche et le développement.
J'ai travaillé un certain temps dans le secteur financier et je connais bien les mécanismes traditionnels. Voir un groupe de personnes ordinaires reconstruire toute l'infrastructure sur la blockchain est extrêmement excitant. Vous savez, il existe de nombreux points communs entre la finance traditionnelle et tout ce qui se passe sur chaîne, ce qui est fou, principalement parce qu'il s'agit d'un grand livre comptable immuable. Oui, c'est ainsi que j'ai commencé à m'impliquer dans certains protocoles DeFi il y a quelques années.
Quel est le pitch elevator de Grass ? Comment l’expliquez-vous à un haut niveau ?

0xdrej : Nous aimons l’appeler la couche de fourniture de données décentralisée pour l’intelligence artificielle. Cela signifie concrètement que nous disposons d’un réseau composé de plus de 500 000 extensions navigateur, qui parcourent l’internet public, prennent des instantanés de sites web et les téléchargent vers une base de données.
L'idée est que, puisque nous pouvons traiter et distribuer en parallèle toutes ces capacités de calcul, ainsi que ces vues résidentielles de l'internet (ce point est crucial, car les sites web affichent généralement aux consommateurs ce qu'ils souhaitent montrer au grand public, plutôt que ce qu'ils montrent aux centres de données ou aux solutions traditionnelles), nous pouvons créer des jeux de données impossibles à obtenir via d'autres sources.
Il existe alors plusieurs comparaisons. L’une d’elles est celle de l’oracle décentralisé pour l’IA, tandis que d’autres concernent la version décentralisée du crawl classique. Mais fondamentalement, il s’agit d’un protocole massif axé sur les données du web public.
Ainsi, en permettant à n’importe qui de participer à ce réseau et en intégrant la blockchain, vous avez trouvé un moyen de concurrencer les solutions existantes, n’est-ce pas ?
0xdrej : Nous avons testé plusieurs modèles économiques différents. Il est évident que lorsqu’on construit un tel protocole, on pourrait simplement payer les utilisateurs pour leur bande passante inutilisée. Par exemple, leur offrir un tarif fixe par gigaoctet, utiliser cette bande passante pour collecter de vastes jeux de données, en extraire des insights, puis monétiser ces derniers. À chaque étape – du crawling au jeu de données, puis aux insights – on capte une petite part de profit.
Habituellement, ces étapes sont gérées par différentes entités, tandis que les utilisateurs fournissant la bande passante (qui alimentent tout cela) ne voient qu’un petit tarif fixe par gigaoctet, voire rien du tout, car ils ont installé un SDK dans une application gratuite qui utilise simplement leur bande passante en arrière-plan. Nous trouvons cela injuste.
Nous nous sommes demandé comment créer un mécanisme de pool de valeur afin de récompenser les utilisateurs à tous les niveaux de la chaîne de valeur. Ainsi, si quelqu’un entraîne un modèle d’IA à partir de données collectées par votre nœud Grass, votre nœud devrait être récompensé, et pas seulement pour les données brutes. J’espère que cela a du sens. C’est l’un des grands problèmes que nous voulons résoudre sur la blockchain.
Un autre problème de plus en plus prégnant concerne la contamination des jeux de données. C’est un problème émergent, même s’il existe depuis longtemps dans le commerce électronique.
Par exemple, si vous scrapez un site comme eBay et souhaitez récupérer quotidiennement les prix de tout son inventaire, vous devez crawler environ 30 millions de SKU par jour. eBay sait que si vous bloquez leur adresse IP, vous en changerez. Alors, ils mettent en place des pièges tarifaires. S’ils détectent que vous essayez de les scraper et de faire pression sur leurs prix, ils vous donnent de faux prix. Nous avons vécu cela dès nos premiers tests avec Grass, et comparé cela à l’utilisation de centres de données.
Ces stratégies du e-commerce ont lentement migré vers la publicité numérique. Depuis l'essor explosif de HoloLens au cours des dix-huit derniers mois, elles ont aussi pénétré le domaine des jeux de données NLP (traitement du langage naturel).
Ainsi, si vous êtes un homme politique et savez qu’un jeu de données spécifique servira à entraîner un modèle, vous pouvez contacter ceux qui gèrent ce jeu de données pour leur demander d’insérer, disons, mille phrases favorables à un candidat particulier. De même, des entreprises financent l'insertion de fausses critiques dans des jeux de données déjà collectés sur Internet.
Or, résoudre ce problème est extrêmement difficile, n’est-ce pas ? Car, comme vous le savez probablement, les jeux de données d’entraînement des LLM ne font pas quelques gigaoctets ou téraoctets, mais des pétaoctets – soit des millions de gigaoctets.
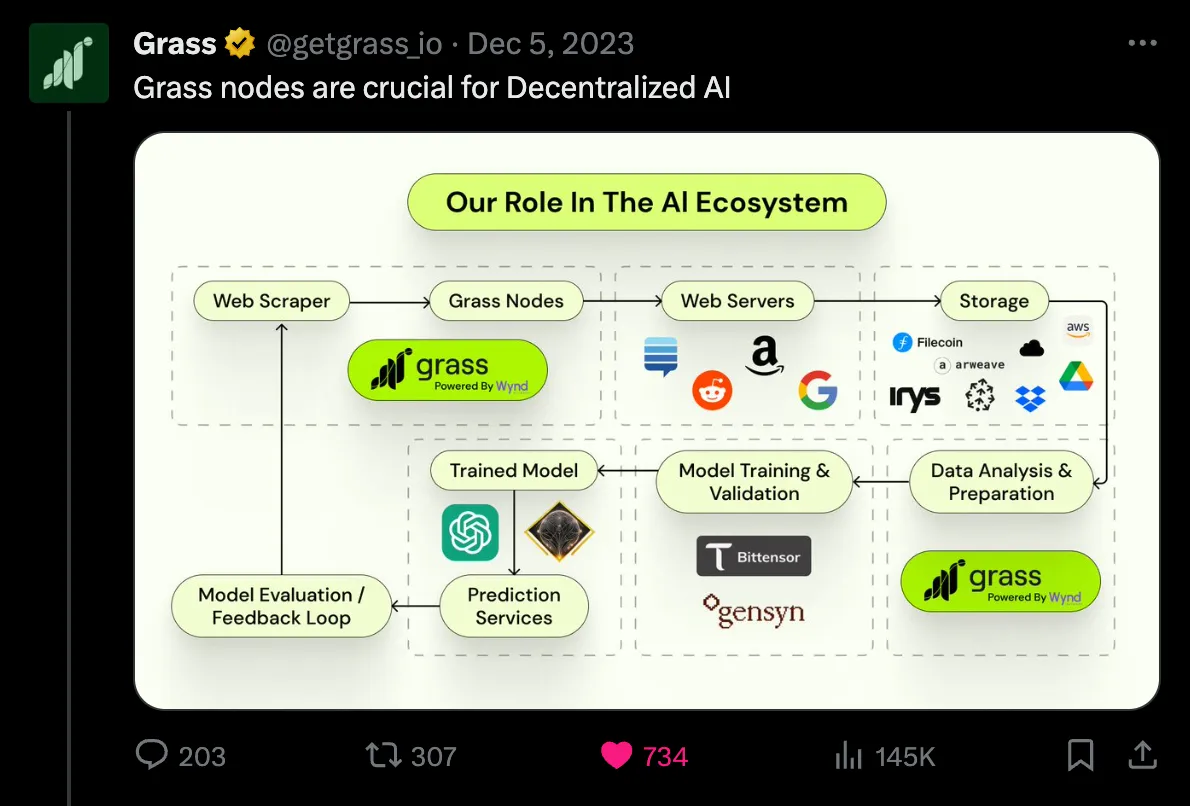
Il est donc irréaliste d’espérer que quiconque entraînant un LLM puisse vérifier si un jeu de données provient réellement du site prétendu. Par exemple, si j’affirme avoir scrapé l’intégralité de Medium, cela représente environ 50 millions d’articles, mais rien ne garantit que ces contenus soient effectivement ceux de Medium.
Pour résoudre ce problème, zk-TLS (zero-knowledge Transport Layer Security) offre une excellente solution. Honnêtement, cela n’est possible que grâce à une blockchain à haut débit.
L’idée est que, une fois décentralisé, ces nœuds soumettent une preuve de requête lorsqu’ils scrapent internet. Ils soumettent la preuve de requête, puis notre séquenceur (actuellement centralisé, mais que nous prévoyons de décentraliser) délègue une certaine quantité de jetons à un contrat intelligent.
Ce contrat se déverrouille lorsque la requête est approuvée. Vous pouvez alors associer cette preuve de requête à la réponse du réseau provenant de ce travail de scraping, puis directement au jeu de données. Soudainement, vous disposez d’une preuve cryptographique indiquant que ces lignes du jeu de données proviennent bien de ces sites web, et ont été collectées à une date et heure précises.
C’est puissant, car un tel mécanisme n’existe même pas dans le Web 2.0, et n’est rendu possible que par la blockchain.
Pouvez-vous expliquer ce qu’est la « guerre des données » et comment Grass y participe ?

0xdrej : Comme je l’ai suggéré précédemment, les premiers secteurs à bloquer l’accès aux données étaient ceux du e-commerce, car ces données étaient alors les plus directement monétisables. Avec l’évolution technologique et une meilleure compréhension des données linguistiques, ce type de données est devenu extrêmement précieux. Pourtant, jusqu’à présent, les données textuelles n’avaient pas autant de valeur qu’aujourd’hui. Beaucoup de sites web n’ont vraiment découvert comment monétiser ces données que récemment. Puis ils ont pris conscience de leur puissance et ont commencé à verrouiller l’accès à internet.
Par exemple, il y a environ six mois, Elon Musk a commencé à imposer des limites de taux à tous les utilisateurs de Twitter car son contenu était scrapé. Avant cela, Twitter ne bloquait pas vraiment les scrapers, mais Elon Musk a compris la valeur des données Twitter et souhaite les utiliser pour entraîner son propre modèle d’IA. C’est exactement ce que nous avions prédit, et cela s’est bel et bien produit.

Un autre exemple est Reddit, qui a imposé diverses restrictions à son API. Vous ignorez peut-être que deux tiers des bibliothèques générales utilisées pour entraîner GPT proviennent en réalité de Reddit.

Reddit ne comprenait pas vraiment la valeur de ses données. Elles sont particulièrement précieuses à cause du fonctionnement du système Reddit : quelqu’un pose une question, d’autres répondent, les meilleures réponses remontent, les mauvaises descendent. Reddit dispose ainsi d’une communauté humaine qui entraîne manuellement les données destinées aux modèles.
Nous prédisons qu’une guerre des données est actuellement en cours, où tous ces sites tentent de bloquer leurs données. Ils ouvrent même des portes dérobées à quelques grandes entreprises technologiques, rendant l’IA inaccessible aux développeurs open-source ordinaires. C’est effrayant et crée de nombreux risques de centralisation.
Un autre bon exemple est Medium. Il y a quelques mois, le PDG de Medium a publié un billet sur la façon dont les scrapers injectaient les articles de Medium dans des modèles d’IA. Il a parlé de la contamination de ces jeux de données, du blocage des scrapers et de la restriction d’accès. Voilà pourquoi il est difficile de naviguer sur Medium sans compte.
Cela empêche les personnes ordinaires d’utiliser internet, car les entreprises cherchent à isoler leurs données.
Le PDG de Medium a aussi mentionné qu’ils autorisaient Google à accéder à leurs données. Les utilisateurs normaux ne peuvent pas correctement consulter leur site, mais Google peut le scraper gratuitement pour entraîner ses modèles d’IA. Il a expliqué pourquoi : Google donnera la priorité à Medium dans les résultats de recherche en échange de cet accès. Cela montre combien posséder un moteur de recherche est précieux, et comment on peut payer les données linguistiques via le référencement SEO. C’est la prochaine grande vague de la guerre des données.
Toutes ces entreprises se battent pour les données, cherchent à les verrouiller, et veulent obtenir un prix juste pour quelque chose qui n’avait jamais été valorisé auparavant dans l’histoire humaine. Les individus deviennent des victimes collatérales, et ces données ne sont accessibles qu’à quelques rares institutions. C’est injuste.
Ce qui est fou, c’est que certaines entreprises traditionnelles scrapent maintenant des sites comme Reddit en installant des SDK dans des applications gratuites téléchargées par des centaines de millions de personnes. Imaginez que vous téléchargez l’économiseur d’écran Roku TV ou un jeu mobile gratuit. Les développeurs sont payés en plaçant un SDK qui permet à ces grandes entreprises d’utiliser votre bande passante pour scraper des sites à partir de votre IP résidentielle, car leurs propres IPs sont bloquées. Ironiquement, nous acceptons toujours ces conditions d’utilisation, sous le prétexte : « Hé, vous obtenez une expérience sans publicité ». Ils prétendent que c’est ainsi que vous êtes récompensé. Mais nous savons très bien que la valeur de la publicité est bien inférieure à celle des données utilisées.
Notre philosophie chez Grass est que, s’il y a une guerre des données, nous ne pouvons peut-être pas l’arrêter, mais nous devrions au moins avoir la possibilité d’y participer. Nous devrions pouvoir choisir, soit de vendre des armes dans cette guerre des données, soit de créer pour internet un immense jeu de données ouvert, que chacun pourra utiliser pour entraîner ses propres modèles d’IA.
Est-il facile pour les gens de rejoindre Grass et d’en tirer profit ?

0xdrej : Actuellement, le réseau est en phase bêta, très simple. Le matériel nécessaire est déjà présent sur vos appareils. Tout ce dont vous avez besoin est un code de parrainage. Ensuite, vous créez simplement un compte ou utilisez l’application Saga sur téléphone, et vous êtes opérationnel. Le processus est très fluide.
Un problème que nous rencontrons récemment est que la croissance du nombre d’utilisateurs est bien plus rapide que prévu. Pendant que nous développons l’infrastructure, certains utilisateurs peuvent rencontrer de petits problèmes.
Quelle est selon vous la taille de ce marché ?
0xdrej : Nous visons actuellement deux domaines verticaux, ou trois, chacun ayant une taille de marché différente.
Le premier est celui des données alternatives, que je considère comme un marché de 20 milliards de dollars. Par données alternatives, j’entends principalement celles utilisées par les hedge funds. Par exemple, en analysant les prix et stocks de certains magasins, on peut estimer les bénéfices trimestriels d’une entreprise. Les hedge funds paient cher pour ce genre d’informations.

Le marché du web scraping lui-même, bien qu’encore émergent, vaut actuellement plusieurs milliards de dollars et connaît une croissance massive. Cette croissance importante est due au troisième marché : l’intelligence artificielle.
La taille du marché des données pour l’IA est aujourd’hui extrêmement difficile à quantifier. Elle pourrait croître exponentiellement jour après jour, ce qui rend son évaluation très complexe pour nous. Mais quand on voit certaines personnes discuter de la vente de données à des jeux de données IA, on comprend que c’est une énorme opportunité.
Alors, à mesure que le nombre d’utilisateurs augmente, Grass devient-il plus précieux et compétitif ?
0xdrej : Oui, c’est une excellente question. Plus le réseau est grand, plus il devient viable.
Prenons l’exemple de hivemapper, que je trouve un produit et une idée très cool. Si vous voulez cartographier le monde entier mais que seulement 10 voitures roulent, vous n’obtiendrez qu’une petite partie de la carte. Cela peut être utile pour certaines applications très spécifiques, mais ce n’est pas très large.
En revanche, si des millions de conducteurs cartographient chaque route du monde, vous pouvez créer une vue beaucoup plus complète. Vous pouvez alors vendre un meilleur produit à un prix plus élevé, et l’économie unitaire s’améliore considérablement pour chaque participant.
Réfléchissez-y : Grass cartographie fondamentalement tout l’internet.
Permettez-moi un autre exemple, lié non pas à l’IA, mais à un secteur énorme : les billets d’avion, les voyages et les hôtels. Si vous êtes un agrégateur de voyages, vous voulez obtenir les meilleurs prix auprès de chaque fournisseur à chaque destination. Par exemple, le prix d’un vol Berlin-Singapour peut différer selon qu’on le regarde depuis New York ou Berlin. Un agrégateur doit connaître les prix de chaque vol depuis autant d’adresses IP que possible pour offrir le meilleur service. Or, s’il ne dispose que d’IPs situées à Singapour, en Chine et aux États-Unis, il aura du mal à scraper les bons prix pour un vol entre deux destinations européennes. Le réseau débloque davantage d’utilisations à mesure qu’il grossit, ce qui est passionnant.
Avec l’expansion du réseau, pensez-vous que la récompense des utilisateurs sera diluée ? Ou atteindra-t-elle un équilibre grâce à la rentabilité accrue du réseau ?
0xdrej : J’essaierai de répondre sans faire de déclaration prospective. La première variable est que le réseau est désormais très proche de la disponibilité. C’est pourquoi, pendant cette phase bêta, nous avons choisi de récompenser le temps de fonctionnement. Nous n’avons pas l’intention de récompenser indéfiniment les utilisateurs pour leur simple connexion.
Ainsi, c’est actuellement le seul moment où vous pouvez gagner des points simplement en gardant votre appareil allumé. À l’avenir, les nœuds ne seront rémunérés que pour l’utilisation réelle de la bande passante. Concernant l’équilibre, l’exemple du voyage que j’ai mentionné plus tôt est très parlant.
Dans ce domaine, on ne peut jamais avoir assez de nœuds. Pour rester compétitif, l’agrégateur le plus performant sera celui qui dispose du plus grand nombre de nœuds. Donc, s’il peut débloquer cela, il injectera simplement plus de contenu et plus de débit via le réseau.
Qu’est-ce qui vous a poussé à choisir Solana pour le développement ?
0xdrej : Pour ce que nous essayons de faire, une blockchain à haut débit est clairement essentielle. Lorsque le réseau Grass sera lancé, il deviendra l’un des protocoles cryptographiques avec le plus grand nombre d’utilisateurs. Cela nécessite des frais de gaz très bas pour inciter les utilisateurs. Solana est actuellement la blockchain la plus économique en termes de gas, et probablement aussi la plus rapide. Certaines mises à jour à venir (comme FireDancer) sont très prometteuses, car les transactions parallèles sont exactement ce dont nous avons besoin.
Il existe de nombreux protocoles DePin sur Solana, et d’un point de vue commercial, nous sommes heureux de collaborer avec d’autres projets DePin. Une chose que nous trouvons particulièrement intéressante est que Solana possède son propre téléphone. Nous croyons que l’adoption du téléphone Solana ne fera qu’augmenter. C’est quelque chose que nulle autre blockchain ne propose. Pour nous, installer une application sur un téléphone Solana est un choix évident.
Vous êtes-vous inspiré d’autres projets du domaine DePin, comme Helium ?
0xdrej : Bien sûr. L’idée fondamentale derrière DePin concerne votre propre autonomie. Non seulement vous payez trop pour beaucoup de choses dans la vie, mais on vous prive aussi de ce qui pourrait vous rapporter de l’argent.
La récente poussée vers la décentralisation dans DePin, ainsi que certaines initiatives comme Helium Mobile ou le téléphone Saga, ont ouvert les yeux de tout le monde. On réalise alors : « J’ai tant de ressources, mais dans bien des cas, on me les vole. » Maintenant, les gens voient une alternative, un chemin où ils ont le choix de refuser cette situation. C’est extrêmement puissant, et je ne veux pas le rater. C’est donc de là que nous tirons beaucoup d’inspiration.
À l’avenir, à quoi ressemblera Grass en 2024 ? Pouvez-vous nous donner un aperçu de votre feuille de route ?
0xdrej : Nous prévoyons de lancer pleinement le réseau à un moment donné en 2024, ce qui ne surprendra personne, je pense.
En dehors de cela, dans la feuille de route, nous souhaitons implémenter les preuves de requête utilisant zk-TLS, liant les requêtes réseau aux jeux de données, ce qui pourrait arriver en second semestre. Nous prévoyons également de décentraliser bon nombre de nos séquenceurs. La manière exacte reste à définir, mais nous avons de nombreuses idées passionnantes qui permettront aux gens d’exécuter plus facilement l’infrastructure Grass.

Nous réfléchissons aussi au matériel. Actuellement, le coût d’utilisation de Grass est nul, et nous aimons cela, nous voulons le maintenir ainsi. Mais imaginons que vous ne souhaitiez pas laisser votre appareil allumé en continu, ou que pour une raison quelconque, vous ne vouliez pas exécuter ce nœud sur votre appareil. Nous voulons offrir aux gens le choix d’acheter simplement un boîtier, de le connecter à leur internet et de le laisser fonctionner en arrière-plan. Un aspect passionnant du matériel, au-delà des préférences personnelles, est que nous pouvons intégrer des agents d’IA dans le matériel et leur permettre d’opérer. Ils peuvent effectuer pour vous d’importantes tâches de scraping et de crawling. Vous n’aurez qu’à vous asseoir pendant que ces agents IA font le travail, comme posséder une voiture autonome capable de cartographier.
Si vous souhaitez contribuer davantage au réseau, nous espérons mettre à disposition un dispositif adapté.
Nous développons aussi de petites fonctionnalités, comme de nouveaux éléments gamifiés dans le tableau de bord. Nous souhaitons ajouter des fonctionnalités spéciales en forme d’easter eggs pour les utilisateurs de Saga, et explorons actuellement ces idées. En outre, nous travaillons sur des versions pour d’autres appareils. Nous pensons désormais non seulement aux extensions, mais aussi à des versions téléchargeables pour ceux qui le souhaitent. Beaucoup de gens n’aiment pas installer d’extensions, et c’est tout à fait compréhensible. Nous prévoyons donc d’étendre le support à d’autres plateformes comme Android, iOS, Raspberry Pi, Linux, etc.
Globalement, nous voulons offrir davantage de choix pour faciliter l’adhésion au réseau Grass.
Comment envisagez-vous la gouvernance de Grass ? Sera-t-il un réseau complètement décentralisé et appartenant à la communauté ?
0xdrej : Notre transition vers la décentralisation comporte plusieurs étapes. La première concerne le mécanisme d’attestation, nous permettant de récompenser les contributions des utilisateurs sur la chaîne.
La deuxième étape concerne la décentralisation de nos séquenceurs et de l’approbation des requêtes de scraping. La gouvernance joue ici un rôle clé. Fondamentalement, nous voulons devenir un vaste réseau de fourniture de données, où les membres de la communauté puissent dire : « Hé, j’entraîne ce modèle d’IA, j’ai besoin de ce type de jeu de données, je propose que nous orientions le scraping vers ces données. » Ensuite, les séquenceurs peuvent agir comme validateurs pour s’assurer que les bonnes données sont collectées.
L’une des rares fonctions de gouvernance que nous voulons inclure est la protection du réseau. Dans un réseau décentralisé bien conçu, l’efficacité du marché s’établit généralement avec le temps. De nombreuses applications monétisent le CPU, GPU inutilisés, généralement en monnaie fiduciaire. Elles peuvent initialement offrir un tarif fixe aux nouveaux inscrits, puis le réduire progressivement, jusqu’à ce que les gains deviennent négligeables.
Grâce à une structure de gouvernance, vous pouvez protéger la communauté, car ceux qui contribuent au réseau possèdent réellement une partie du réseau. C’est l’état que nous voulons atteindre : chaque personne exécutant un nœud Grass possède une partie du réseau lui-même.
Pensez-vous théoriquement disposer actuellement d’une taille suffisante pour lancer le réseau ? Ou souhaitez-vous encore augmenter le nombre de nœuds avant le lancement ?
0xdrej : En termes de nombre total de nœuds, nous sommes très proches de notre objectif. Cependant, dans certaines régions géographiques spécifiques, nous sommes moins proches. Dans certaines zones, la demande de collecte de données spécifiques dépasse l’offre. Nous voulons nous assurer d’avoir la capacité de répondre à toutes les demandes, c’est l’un de nos objectifs pour le lancement.
Comme vous le savez, nous sommes en phase de test, donc nous faisons de notre mieux pour garantir l’évolutivité du réseau. Comme notre croissance est plus rapide que prévue, certains utilisateurs rencontrent des problèmes d’accès au réseau ou de visualisation sur le tableau de bord. Ce sont des problèmes que nous comptons résoudre avant le lancement complet. C’est pourquoi nous restons en phase de test. En ce qui concerne le nombre de nœuds, nous prenons en compte de nombreux facteurs. Globalement, nous sommes assez satisfaits de la situation actuelle.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













