

IA x DePIN : Quelles nouvelles opportunités naîtront de la convergence de ces deux secteurs en plein essor ?
TechFlow SélectionTechFlow Sélection
IA x DePIN : Quelles nouvelles opportunités naîtront de la convergence de ces deux secteurs en plein essor ?
En exploitant la puissance des algorithmes, de la puissance de calcul et des données, les progrès des technologies d'intelligence artificielle redéfinissent sans cesse les limites du traitement des données et de la prise de décision intelligente.
Rédaction : Cynic, Shigeru
Ce texte constitue le deuxième volet de la série d’études approfondies Web3 x IA. Pour une introduction, voir « Du parallèle à l'intersection : explorer la nouvelle vague de l'économie numérique menée par la convergence entre Web3 et l'IA ».
Alors que le monde accélère sa transformation numérique, l’IA et les DePIN (infrastructures physiques décentralisées) sont devenues des technologies fondamentales qui transforment tous les secteurs. La convergence entre l’IA et les DePIN ne favorise pas seulement une itération rapide des technologies et une large diffusion des applications, mais ouvre aussi la voie à des modèles de services plus sûrs, transparents et efficaces, entraînant ainsi des changements profonds dans l’économie mondiale.
DePIN : vers une décentralisation concrète, pilier de l’économie numérique
DePIN est l’abréviation de Decentralized Physical Infrastructure Network (réseau d’infrastructure physique décentralisée). Dans un sens étroit, les DePIN désignent principalement les réseaux physiques traditionnels — tels que les réseaux électriques, de télécommunications ou de géolocalisation — soutenus par une technologie de registre distribué. Dans un sens plus large, tout réseau distribué reposant sur des équipements physiques peut être considéré comme un DePIN, notamment les réseaux de stockage ou de calcul.
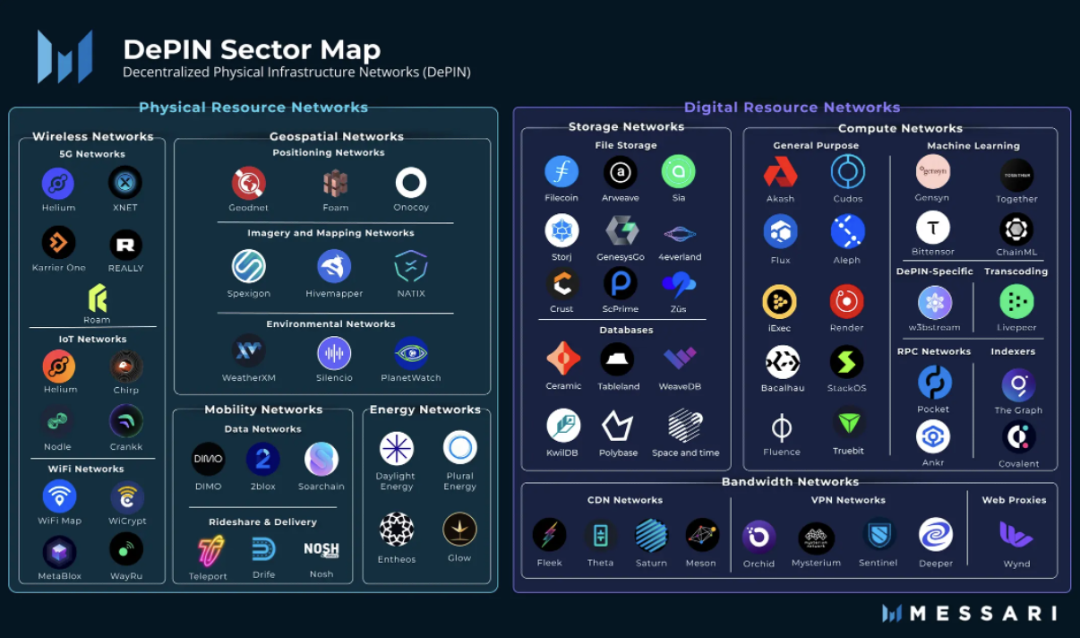
source : Messari
Si les cryptomonnaies ont introduit une transformation décentralisée au niveau financier, les DePIN représentent quant à elles la solution décentralisée appliquée à l’économie réelle. On peut dire que les machines de minage PoW sont déjà une forme de DePIN. Dès leur création, les DePIN ont été l’un des piliers centraux du Web3.
Les trois piliers de l’IA — algorithme, puissance de calcul, données — dont les DePIN contrôlent deux éléments
Le développement de l’intelligence artificielle repose généralement sur trois facteurs clés : les algorithmes, la puissance de calcul (« compute ») et les données. Les algorithmes désignent les modèles mathématiques et la logique programme pilotant les systèmes d’IA ; la puissance de calcul fait référence aux ressources informatiques nécessaires pour exécuter ces algorithmes ; enfin, les données constituent la base indispensable pour entraîner et optimiser les modèles d’IA.

Parmi ces trois éléments, lequel est le plus important ? Avant l’apparition de ChatGPT, on pensait généralement que c’étaient les algorithmes, d’où la profusion d’articles académiques centrés sur des ajustements algorithmiques. Mais depuis l’arrivée de ChatGPT et des grands modèles linguistiques (LLM), l’importance des deux autres facteurs s’est imposée. Une puissance de calcul massive est une condition préalable à la création de ces modèles, tandis que la qualité et la diversité des données sont essentielles pour construire des systèmes d’IA robustes et performants. En comparaison, les exigences en matière d’algorithmes ne sont plus aussi strictes qu’auparavant.
À l’ère des grands modèles, l’IA passe d’une approche de précision minutieuse à une stratégie de force brute. La demande croissante en puissance de calcul et en données trouve précisément dans les DePIN une réponse adaptée. Grâce à des incitations par jetons, les marchés de niche peuvent être activés, et les énormes capacités de calcul et de stockage grand public deviennent alors un terreau idéal pour les grands modèles.
La décentralisation de l’IA n’est pas une option, mais une nécessité
Certains pourraient objecter que la puissance de calcul et les données existent déjà dans les centres de données AWS, offrant même une meilleure stabilité et expérience utilisateur que les solutions DePIN. Alors pourquoi choisir les DePIN plutôt que les services centralisés ?
Cette objection a un certain fondement. En effet, aujourd’hui, presque tous les grands modèles sont directement ou indirectement développés par de grandes entreprises technologiques : derrière ChatGPT, il y a Microsoft ; derrière Gemini, Google ; et en Chine, chaque grand groupe internet dispose pratiquement de son propre modèle. Pourquoi ? Parce que seules ces grandes entreprises possèdent à la fois des données de haute qualité et les moyens financiers pour supporter une puissance de calcul colossale. Mais cette situation n’est pas souhaitable : les utilisateurs ne veulent plus être sous la domination exclusive des géants du web.
D’une part, l’IA centralisée comporte des risques importants en matière de confidentialité et de sécurité des données, et peut être sujette à la censure ou au contrôle. D’autre part, les IA conçues par les géants du numérique renforcent la dépendance des utilisateurs, accentuent la concentration du marché et élèvent les barrières à l’innovation.

source : https://www.gensyn.ai/
L’humanité ne devrait pas avoir besoin d’un nouveau Martin Luther à l’ère de l’IA ; chacun devrait pouvoir parler directement avec Dieu.
Du point de vue commercial : les DePIN permettent de réduire les coûts et d’améliorer l’efficacité
Indépendamment des débats idéologiques entre centralisation et décentralisation, les DePIN présentent également des avantages commerciaux indéniables lorsqu’elles sont utilisées pour l’IA.
Tout d’abord, bien que les grands groupes technologiques détiennent une grande quantité de GPU haut de gamme, la somme des cartes graphiques grand public inutilisées représente elle aussi un réseau de calcul extrêmement conséquent, illustrant ce qu’on appelle l’effet « longue traîne » de la puissance de calcul. Le taux d’inactivité de ces cartes grand public est en réalité très élevé. Tant que la récompense offerte par les DePIN dépasse le coût de l’électricité, les utilisateurs ont intérêt à contribuer à ce réseau. En outre, puisque les infrastructures physiques restent sous le contrôle des utilisateurs eux-mêmes, les réseaux DePIN évitent les coûts opérationnels inévitables des fournisseurs centralisés, et peuvent se concentrer uniquement sur la conception du protocole.
Concernant les données, les réseaux DePIN, grâce au calcul en périphérie (edge computing), rendent disponibles des données potentiellement inexploitées et réduisent les coûts de transmission. En outre, la plupart des réseaux de stockage distribués disposent d’une fonction de suppression automatique des doublons, réduisant ainsi la charge liée au nettoyage des données d’entraînement des modèles d’IA.
Enfin, l’économie crypto apportée par les DePIN augmente la marge de tolérance aux erreurs du système, et permet d’envisager une situation gagnant-gagnant pour les fournisseurs, les consommateurs et la plateforme.
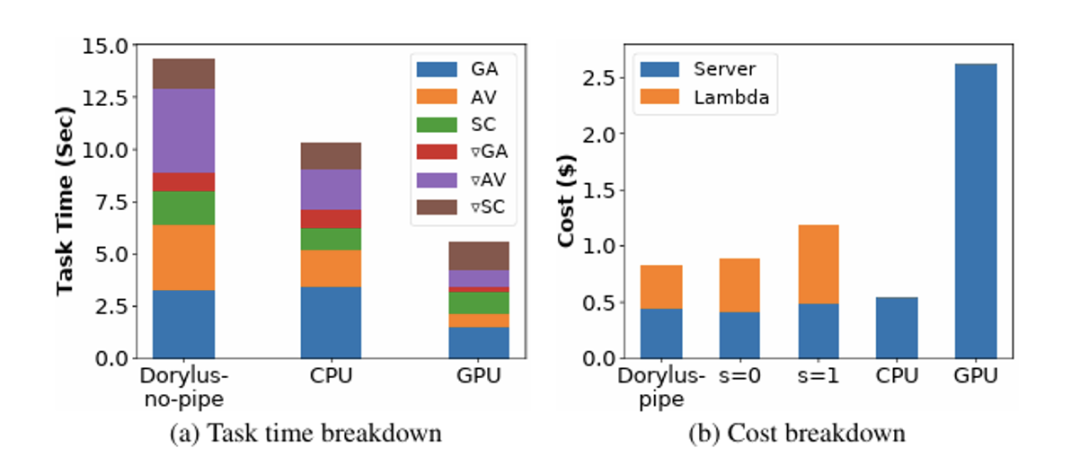
source : UCLA
Si vous en doutez encore, une étude récente de l’UCLA montre que, à coût égal, l’utilisation du calcul décentralisé par rapport aux clusters GPU traditionnels permet d’obtenir 2,75 fois plus de performance — soit 1,22 fois plus rapide et 4,83 fois moins cher.
Des défis persistants : quels obstacles pour l’association AIxDePIN ?
Nous avons choisi d’aller sur la Lune durant cette décennie, et de faire d’autres choses non pas parce que c’est facile, mais parce que c’est difficile. — John Fitzgerald Kennedy
Construire des modèles d’intelligence artificielle basés sur le stockage et le calcul distribués des DePIN, sans confiance, reste entouré de nombreux défis.
Validation des travaux
Fondamentalement, l’exécution d’un modèle de deep learning et le minage PoW relèvent tous deux du calcul généralisé, dont le niveau le plus basique repose sur des variations de signaux entre portes logiques. À un niveau macroscopique, le minage PoW correspond à un « calcul inutile » : il consiste à générer un grand nombre de nombres aléatoires et à les passer dans une fonction de hachage afin d’obtenir une valeur dont le préfixe contient n zéros ; en revanche, le calcul du deep learning est un « calcul utile », qui détermine progressivement les paramètres de chaque couche via propagation avant et arrière, afin de construire un modèle d’IA efficace.
Or, dans le cas du minage PoW, ce « calcul inutile » utilise des fonctions de hachage : il est facile de vérifier rapidement si un hachage donné provient d’une entrée spécifique, mais extrêmement difficile de retrouver l’entrée à partir du hachage. Ainsi, tout le monde peut valider facilement et rapidement la validité du calcul. En revanche, pour les modèles de deep learning, la structure hiérarchique fait que la sortie de chaque couche sert d’entrée à la suivante. Pour valider le résultat final, il faut donc refaire tous les calculs précédents, ce qui rend la validation simple et efficace impossible.
source : AWS
La validation des travaux est cruciale ; sans elle, les fournisseurs de calcul pourraient simplement ne rien calculer et soumettre un résultat aléatoire.
Une première approche consiste à demander à plusieurs serveurs d’exécuter la même tâche, puis de comparer les résultats pour en vérifier la cohérence. Toutefois, la majorité des calculs de modèles sont non déterministes : même dans des conditions identiques, les résultats ne peuvent être reproduits exactement, mais seulement similaires statistiquement. De plus, cette duplication entraîne une hausse rapide des coûts, ce qui va à l’encontre de l’objectif principal des DePIN : réduire les coûts et améliorer l’efficacité.
Une autre approche est le mécanisme dit « optimiste » (Optimistic) : on suppose initialement que le résultat a été correctement calculé, tout en autorisant toute personne à vérifier ultérieurement le résultat. Si une erreur est détectée, une preuve de fraude (Fraud Proof) peut être soumise, entraînant la confiscation des jetons mis en jeu par le fraudeur et une récompense pour le lanceur d’alerte.
Parallélisation
Comme mentionné précédemment, les DePIN mobilisent principalement le marché de la puissance de calcul grand public, ce qui implique que la capacité de calcul fournie par un seul appareil est relativement limitée. Pour entraîner de grands modèles d’IA, le temps nécessaire sur un seul appareil serait excessivement long. Il est donc indispensable de recourir à la parallélisation pour réduire le temps d’entraînement.
La principale difficulté de la parallélisation en apprentissage profond réside dans les dépendances entre les différentes tâches, ce qui complique fortement sa mise en œuvre.
Actuellement, la parallélisation en apprentissage profond se divise principalement en deux types : parallélisation des données et parallélisation du modèle.
La parallélisation des données consiste à répartir les données sur plusieurs machines, chaque machine conservant l’intégralité des paramètres du modèle et effectuant l’entraînement localement, avant que les paramètres soient agrégés. Cette méthode est efficace lorsque les volumes de données sont très élevés, mais nécessite une communication synchronisée pour l’agrégation.
La parallélisation du modèle intervient lorsque le modèle est trop volumineux pour tenir sur une seule machine. On découpe alors le modèle entre plusieurs machines, chacune stockant une partie des paramètres. Des communications entre machines sont nécessaires lors des phases de propagation avant et arrière. Cette méthode présente un avantage pour les très grands modèles, mais génère des frais de communication élevés.
Concernant les gradients inter-couches, on distingue aussi les mises à jour synchrones et asynchrones. Les mises à jour synchrones sont simples mais augmentent les temps d’attente ; les asynchrones réduisent ces délais mais posent des problèmes de stabilité.
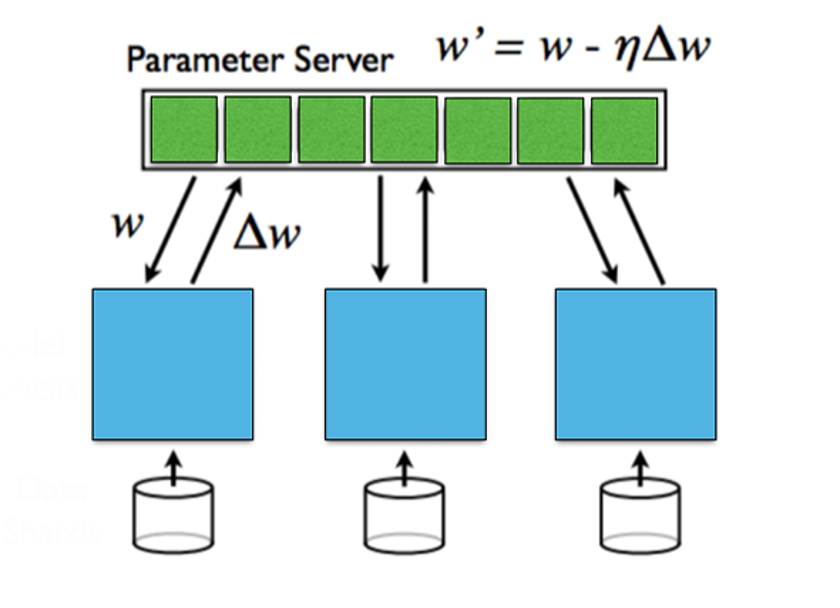
source : Stanford University, Parallel and Distributed Deep Learning
Confidentialité
Un mouvement mondial de protection de la vie privée est en cours, et les gouvernements renforcent partout la sécurité des données personnelles. Bien que l’IA utilise massivement des jeux de données publics, ce qui distingue véritablement les différents modèles d’IA, ce sont les données propriétaires des entreprises.
Comment bénéficier de ces données propriétaires pendant l’entraînement sans compromettre la confidentialité ? Comment garantir que les paramètres du modèle d’IA construit ne soient pas divulgués ?
Ces questions soulèvent deux aspects de la confidentialité : celle des données et celle du modèle. La confidentialité des données protège l’utilisateur, tandis que celle du modèle protège l’organisation qui le développe. Actuellement, la protection des données est bien plus critique que celle du modèle.
Plusieurs solutions sont explorées. L’apprentissage fédéré (federated learning) permet d’entraîner les modèles à la source des données, en gardant celles-ci en local et en ne transférant que les paramètres du modèle, préservant ainsi la confidentialité. Quant aux preuves à divulgation nulle (zero-knowledge proofs), elles pourraient devenir un acteur majeur à l’avenir.
Analyse de cas : quels projets prometteurs sur le marché ?
Gensyn
Gensyn est un réseau de calcul distribué destiné à l’entraînement de modèles d’IA. Ce réseau utilise une blockchain de couche 1 basée sur Polkadot pour vérifier que les tâches de deep learning ont été correctement exécutées, et déclencher les paiements associés. Fondé en 2020, Gensyn a levé 43 millions de dollars en financement de série A en juin 2023, avec a16z en tête de file.
Gensyn utilise des métadonnées issues du processus d’optimisation basé sur les gradients pour créer des certificats attestant de l’exécution des travaux. Ces certificats sont validés par un protocole précis, multi-niveau et basé sur les graphes, ainsi que par des évaluateurs croisés, permettant de rejouer les validations et comparer les résultats, avant confirmation finale par la chaîne elle-même. Pour renforcer davantage la fiabilité de la validation, Gensyn introduit un système de mise en jeu (staking).
Le système comprend quatre types d’acteurs : les soumissionnaires, les solveurs, les vérificateurs et les dénonciateurs.
-
Les soumissionnaires sont les utilisateurs finaux du système, qui soumettent les tâches à calculer et paient pour les unités de travail accomplies.
-
Les solveurs sont les principaux travailleurs du système : ils exécutent l’entraînement du modèle et produisent des preuves destinées aux vérificateurs.
-
Les vérificateurs jouent un rôle clé en reliant le processus d’entraînement non déterministe à un calcul linéaire déterministe. Ils reproduisent partiellement les preuves des solveurs et comparent les écarts avec un seuil prédéfini.
-
Les dénonciateurs constituent la dernière ligne de défense : ils examinent le travail des vérificateurs et peuvent lancer un défi. S’il est validé, ils reçoivent une récompense.
Les solveurs doivent miser des jetons. Les dénonciateurs examinent leur travail, et s’ils détectent une malversation, ils lancent un défi. En cas de succès, les jetons misés par le solveur sont confisqués, et le dénonciateur est récompensé.
Selon les prévisions de Gensyn, cette solution pourrait réduire les coûts d’entraînement à un cinquième de ceux des fournisseurs centralisés.
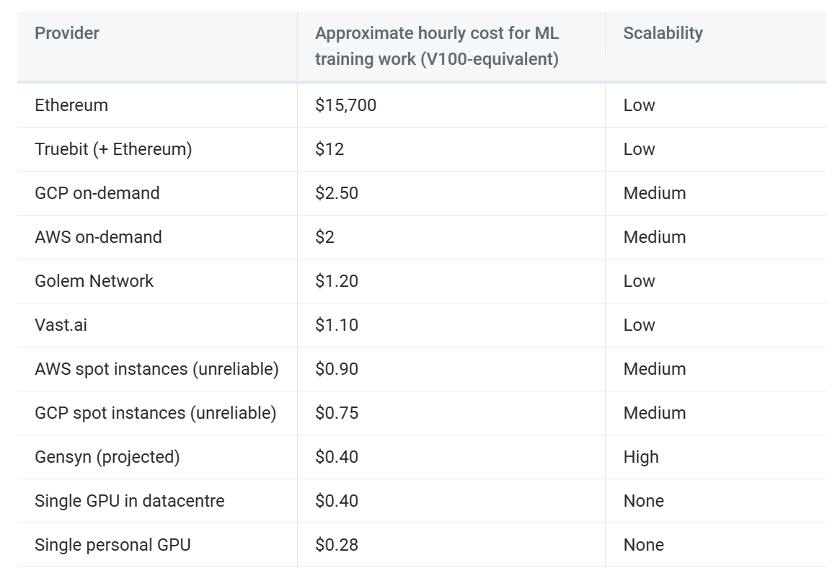
source : Gensyn
FedML
FedML est une plateforme d’apprentissage machine décentralisée et collaborative, permettant de développer de l’IA de manière décentralisée et coopérative à toute échelle et en tout lieu. Plus précisément, FedML propose un écosystème MLOps pour entraîner, déployer, surveiller et améliorer continuellement des modèles d’apprentissage machine, tout en collaborant de façon confidentielle sur des données, modèles et ressources de calcul combinés. Fondée en 2022, FedML a levé 6 millions de dollars lors d’un tour de financement initial en mars 2023.
FedML repose sur deux composants clés : FedML-API et FedML-core, représentant respectivement les API de haut niveau et les API de bas niveau.
FedML-core comprend deux modules indépendants : la communication distribuée et l’entraînement du modèle. Le module de communication gère les échanges entre différents travailleurs / clients, basé sur MPI ; le module d’entraînement repose sur PyTorch.
FedML-API est construite au-dessus de FedML-core. Grâce à cette dernière, il devient facile d’implémenter de nouveaux algorithmes distribués via des interfaces orientées client.
Dans ses derniers travaux, l’équipe de FedML a démontré que l’utilisation de FedML Nexus AI sur une carte graphique grand public RTX 4090 permettait une inférence de modèle d’IA 20 fois moins chère et 1,88 fois plus rapide qu’avec une A100.
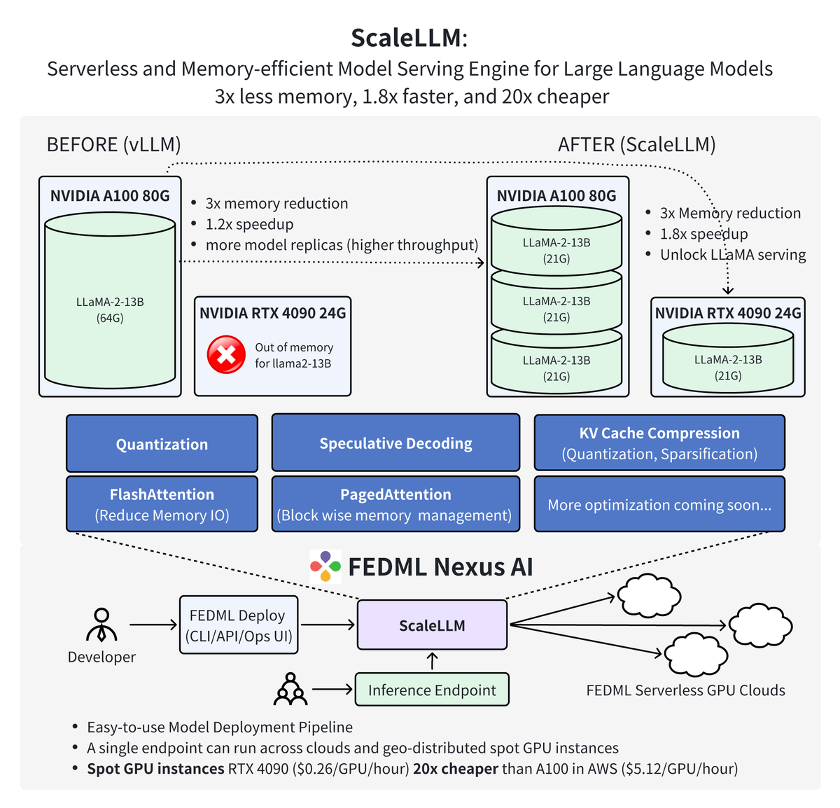
source : FedML
Perspectives d’avenir : les DePIN, vecteur de démocratisation de l’IA
Un jour, lorsque l’IA aura évolué vers une intelligence générale (AGI), la puissance de calcul deviendra de facto une monnaie universelle. Les DePIN accélèrent ce processus.
La convergence entre l’IA et les DePIN ouvre une nouvelle voie de croissance technologique, offrant d’immenses opportunités au développement de l’intelligence artificielle. Les DePIN fournissent à l’IA une puissance de calcul et des données distribuées massives, permettant d’entraîner des modèles plus vastes et d’atteindre une intelligence plus forte. Par ailleurs, elles orientent l’IA vers une direction plus ouverte, plus sûre et plus fiable, réduisant ainsi la dépendance vis-à-vis d’infrastructures centralisées uniques.
À l’avenir, l’IA et les DePIN évolueront de concert. Les réseaux distribués fourniront une base solide pour l’entraînement de modèles géants, qui à leur tour joueront un rôle crucial dans les applications des DePIN. Tout en protégeant la vie privée et la sécurité, l’IA contribuera également à l’optimisation des protocoles et algorithmes des réseaux DePIN. Nous aspirons à un monde numérique plus efficace, plus juste et plus digne de confiance grâce à la synergie entre l’IA et les DePIN.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













