

Un article scientifique sur l’IA de Google, ayant entraîné un effondrement des actions du secteur du stockage pour un montant de 9 milliards de dollars, est accusé de fraude expérimentale.
TechFlow SélectionTechFlow Sélection
Un article scientifique sur l’IA de Google, ayant entraîné un effondrement des actions du secteur du stockage pour un montant de 9 milliards de dollars, est accusé de fraude expérimentale.
Pour les investisseurs dans les infrastructures IA, lorsqu’un article scientifique affirme avoir réalisé une amélioration des performances « de plusieurs ordres de grandeur », la première question à se poser est de savoir si les conditions de comparaison utilisées comme référence sont équitables.
Auteur : TechFlow
Un article publié par Google, présenté comme « réduisant l’occupation mémoire de l’IA à un sixième », a provoqué la semaine dernière une érosion de plus de 90 milliards de dollars américains de la capitalisation boursière des fabricants mondiaux de puces de stockage, tels que Micron et SanDisk.
Pourtant, seulement deux jours après sa publication, Gao Jianyang, postdoctorant à l’École polytechnique fédérale de Zurich (ETH Zurich) et auteur principal de l’algorithme contesté, a publié une lettre ouverte de dix mille mots accusant l’équipe de Google d’avoir utilisé, dans ses expériences comparatives, un script Python exécuté sur un seul cœur CPU pour tester l’algorithme concurrent, tandis qu’elle testait son propre algorithme TurboQuant sur des GPU NVIDIA A100. Il affirme également que l’équipe de Google avait été informée du problème avant soumission de l’article, mais avait refusé d’y apporter des corrections. La lecture de cet article sur Zhihu a rapidement dépassé les 4 millions de vues ; le compte officiel de Stanford NLP l’a relayé, provoquant une onde de choc tant dans la communauté académique que sur les marchés financiers.
(Pour approfondir : Un article qui a fait chuter les actions des sociétés de stockage)
L’enjeu central de cette controverse est simple : un article présenté comme une contribution majeure en intelligence artificielle, largement promu par Google et ayant directement déclenché une vente paniquée des valeurs liées aux puces au niveau mondial, a-t-il systématiquement déformé un travail antérieur publié, et ce, via des expérimentations volontairement biaisées afin de créer un récit fallacieux d’avantage de performance ?
TurboQuant : comment réduire la « feuille de brouillon » de l’IA à un sixième de son épaisseur initiale
Lorsqu’un modèle de langage grande échelle génère une réponse, il doit constamment relire les résultats intermédiaires déjà calculés. Ces derniers sont temporairement stockés dans la mémoire vidéo sous forme de « cache KV » (cache clé-valeur). Plus la conversation est longue, plus ce « bloc-notes » grossit, augmentant ainsi la consommation de mémoire vidéo et les coûts associés.
L’algorithme TurboQuant, développé par l’équipe de recherche de Google, prétend justement réduire ce bloc-notes à un sixième de sa taille initiale, tout en affirmant conserver une précision inchangée et accroître la vitesse d’inférence jusqu’à huit fois. L’article a été publié pour la première fois en avril 2025 sur la plateforme de prépublications arXiv, accepté en janvier 2026 par ICLR, une conférence phare en IA, puis repackagé et promu officiellement par le blog de Google le 24 mars 2026.
Au plan technique, l’approche de TurboQuant peut être simplifiée ainsi : appliquer d’abord une transformation mathématique permettant de « normaliser » des données désordonnées, puis compresser chaque élément à l’aide d’une table de compression optimale précalculée, et enfin corriger les erreurs numériques induites par la compression grâce à un mécanisme de correction d’erreur de 1 bit. Des implémentations indépendantes par la communauté ont confirmé la validité de ces performances de compression, et la contribution mathématique sous-jacente est réelle.
La controverse ne porte donc pas sur l’utilisabilité de TurboQuant, mais sur les méthodes employées par Google pour prétendre qu’il « surpasse largement ses concurrents ».
La lettre ouverte de Gao Jianyang : trois accusations ciblées et fondées
Le 27 mars à 22 heures, Gao Jianyang a publié un long article sur Zhihu, tout en soumettant simultanément un commentaire formel sur la plateforme de relecture OpenReview d’ICLR. Il est le premier auteur de l’algorithme RaBitQ, publié en 2024 lors de SIGMOD, une conférence prestigieuse en gestion de bases de données, et visant précisément le même objectif : la compression efficace de vecteurs de haute dimension.
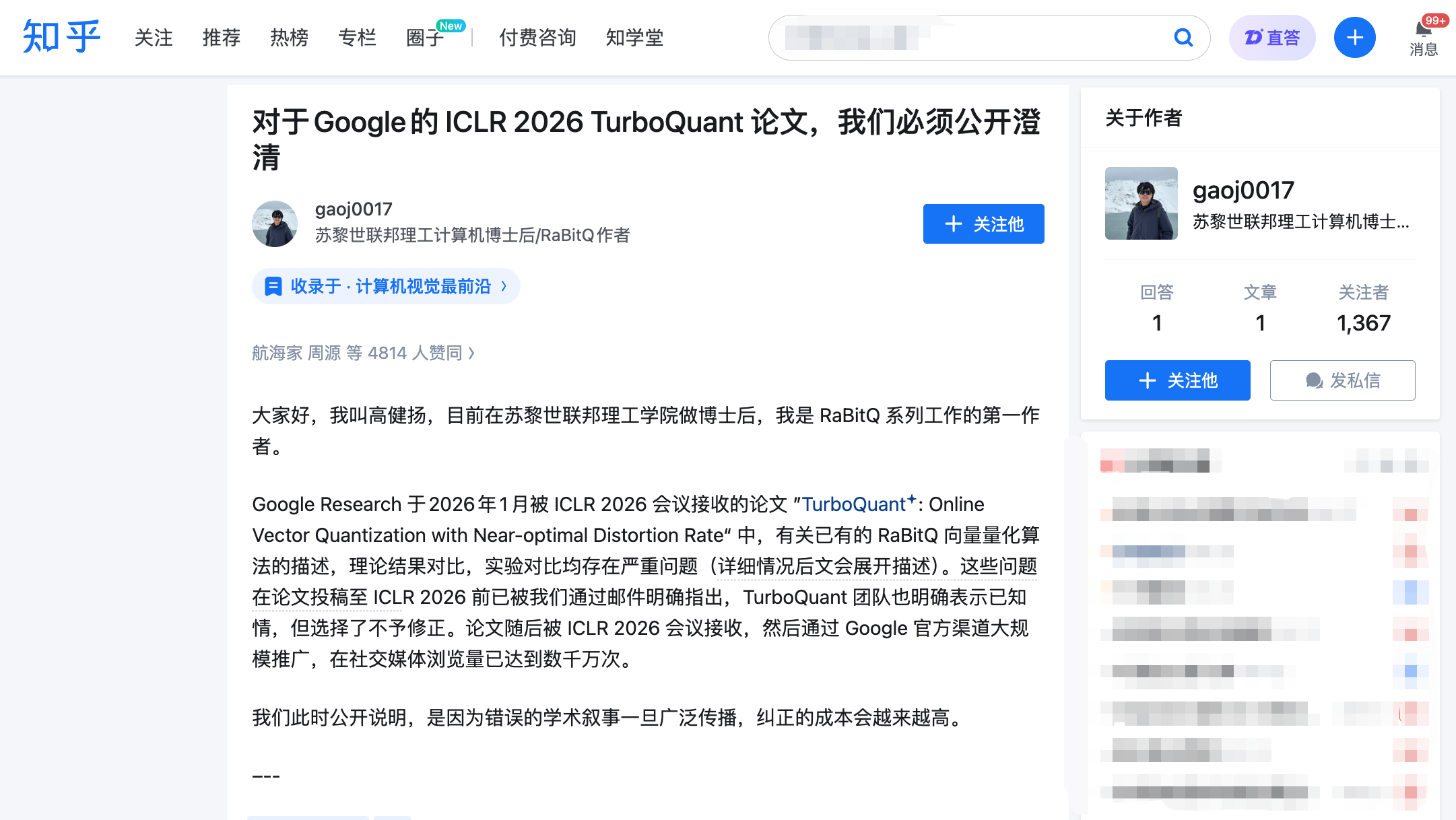
Ses trois accusations sont étayées chacune par des échanges de courriels et des chronologies vérifiables.
Accusation n°1 : appropriation d’une méthode centrale sans attribution.
TurboQuant et RaBitQ partagent une étape cruciale : avant compression, ils appliquent tous deux une « rotation aléatoire » aux données. Cette opération transforme une distribution initialement irrégulière en une distribution uniforme prédictible, réduisant drastiquement la difficulté de compression. Il s’agit là du point le plus fondamental et le plus proche entre les deux algorithmes.
Les auteurs de TurboQuant l’ont eux-mêmes reconnu dans leurs réponses aux relecteurs, mais n’ont jamais explicitement mentionné dans leur article le lien entre cette méthode et RaBitQ. Un détail encore plus significatif : Majid Daliri, deuxième auteur de TurboQuant, a contacté activement l’équipe de Gao Jianyang en janvier 2025 pour demander de l’aide dans le débogage d’une version Python de RaBitQ qu’il avait modifiée. Son courriel détaillait précisément les étapes de reproduction et les messages d’erreur — autrement dit, l’équipe de TurboQuant connaissait parfaitement les détails techniques de RaBitQ.
Un relecteur anonyme d’ICLR a également relevé, de façon indépendante, l’usage commun de cette technique et demandé une discussion approfondie. Or, dans la version finale de l’article, l’équipe de TurboQuant n’a pas seulement omis d’ajouter cette discussion, mais a également déplacé vers l’annexe la description (déjà incomplète) de RaBitQ présente dans le corps principal.
Accusation n°2 : qualification infondée de « sous-optimal ».
L’article TurboQuant qualifie RaBitQ de « sous-optimal » sur le plan théorique, arguant que son analyse mathématique serait « approximative ». Gao Jianyang rétorque que la version étendue de RaBitQ démontre rigoureusement que son erreur de compression atteint effectivement la borne théorique optimale — résultat publié dans une conférence de haut niveau en informatique théorique.
En mai 2025, l’équipe de Gao Jianyang avait fourni, via plusieurs échanges de courriels, une explication détaillée de cette optimalité théorique. Daliri, deuxième auteur de TurboQuant, a confirmé avoir transmis cette information à l’ensemble des auteurs. Pourtant, la version finale de l’article conserve l’appellation « sous-optimal », sans fournir aucun argument contradictoire.
Accusation n°3 : conditions expérimentales biaisées – « une main liée, l’autre armée ».
C’est l’accusation la plus percutante. Gao Jianyang souligne que l’article TurboQuant emploie, dans ses expériences comparatives de vitesse, deux conditions injustes :
Premièrement, RaBitQ fournit officiellement une implémentation C++ optimisée (avec prise en charge native du multithreading), mais l’équipe de TurboQuant n’a pas utilisé cette version ; elle a plutôt recouru à une traduction maison en Python. Deuxièmement, RaBitQ a été testé sur un seul cœur CPU avec le multithreading désactivé, tandis que TurboQuant a été évalué sur des GPU NVIDIA A100.
L’effet combiné de ces deux choix conduit à une conclusion trompeuse : « RaBitQ est plusieurs ordres de grandeur plus lent que TurboQuant », alors que le lecteur ignore totalement que cette conclusion repose sur une compétition où l’adversaire a été entravé. L’article ne divulgue pas suffisamment ces différences de conditions expérimentales.
La réponse de Google : « la rotation aléatoire est une technique universelle, impossible à citer systématiquement »
Comme le révèle Gao Jianyang, l’équipe de TurboQuant a répondu par courriel en mars 2026 : « L’usage de la rotation aléatoire et de la transformation de Johnson-Lindenstrauss est devenu une technique standard dans ce domaine ; nous ne pouvons pas citer chaque article qui utilise ces méthodes. »
L’équipe de Gao Jianyang considère cela comme un sophisme : la question ne porte pas sur la nécessité de citer tous les travaux utilisant la rotation aléatoire, mais sur le fait que RaBitQ est le premier à avoir intégré précisément cette méthode, dans le même cadre applicatif, à la compression de vecteurs, et à en avoir démontré rigoureusement l’optimalité. TurboQuant devrait donc décrire avec exactitude les liens entre les deux travaux.
Le compte officiel X (ex-Twitter) de Stanford NLP Group a relayé la déclaration de Gao Jianyang. Son équipe a publié un commentaire public sur la plateforme OpenReview d’ICLR et déposé une plainte formelle auprès du président et du comité d’éthique d’ICLR. Un rapport technique détaillé sera également publié prochainement sur arXiv.
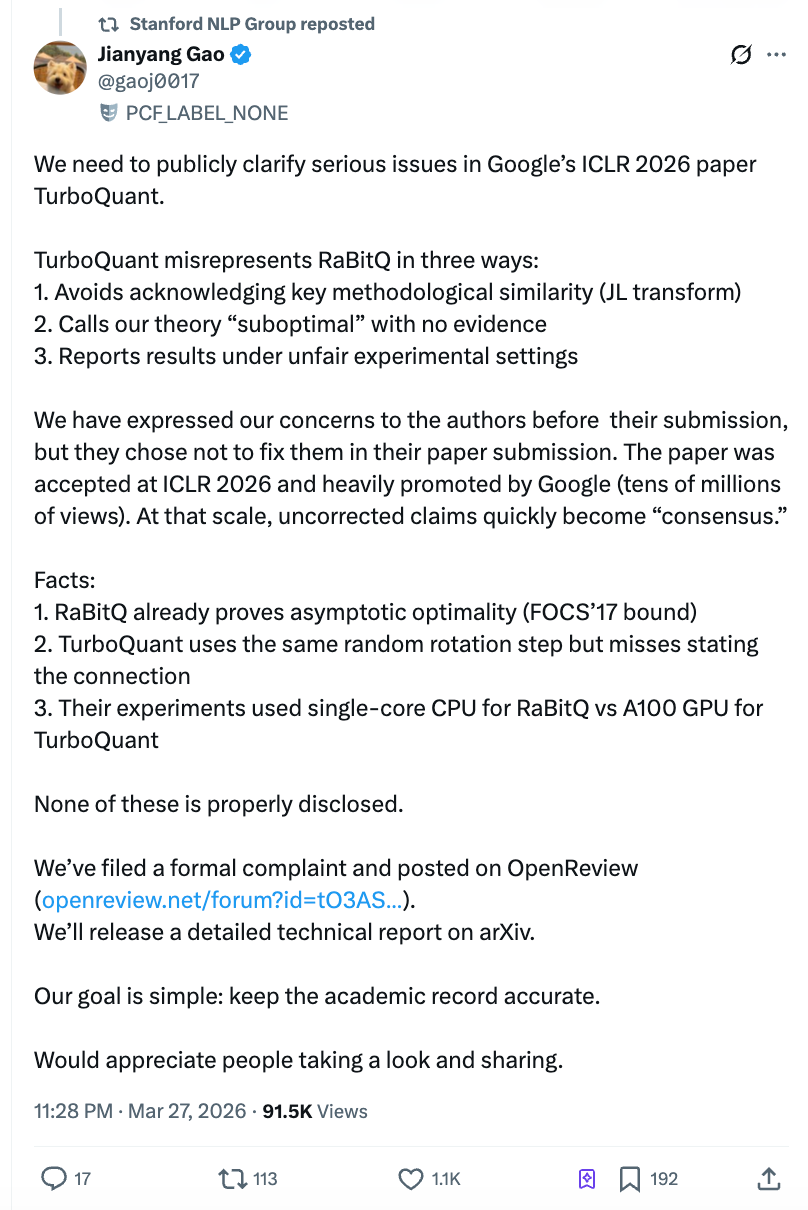
Le blogueur technique indépendant Dario Salvati offre une évaluation relativement neutre : TurboQuant apporte effectivement une contribution mathématique réelle, mais ses liens avec RaBitQ sont bien plus étroits que ne le laisse entendre l’article.
Une érosion de 90 milliards de dollars : la convergence de la controverse académique et de la panique des marchés
Le timing de cette controverse est particulièrement délicat. Après la publication officielle de TurboQuant par le blog de Google le 24 mars, le secteur mondial des puces de stockage a subi une forte pression vendeuse. Selon CNBC et d’autres médias, Micron Technology a connu six séances consécutives de baisse, avec un repli cumulé supérieur à 20 % ; SanDisk a perdu 11 % en une seule journée ; SK Hynix (Corée du Sud) a reculé d’environ 6 %, Samsung Electronics de près de 5 %, et Kioxia (Japon) d’environ 6 %. La logique de panique des marchés est brutale : si la compression logicielle réduit de six fois la demande mémoire pour l’inférence IA, les perspectives de croissance de la demande de puces de stockage seront structurellement révisées à la baisse.
Joseph Moore, analyste chez Morgan Stanley, a contredit cette logique dans un rapport daté du 26 mars, maintenant ses recommandations « surpondérer » pour Micron et SanDisk. Moore précise que TurboQuant ne compresse que le cache KV, un type spécifique de mémoire tampon, et non la consommation mémoire globale, qualifiant cette avancée de « progrès normal en productivité ». De même, Andrew Rocha, analyste chez Wells Fargo, invoque le paradoxe de Jevons pour souligner que toute amélioration d’efficacité, en abaissant les coûts, pourrait stimuler un déploiement plus massif de l’IA, entraînant finalement une hausse de la demande mémoire.
D’anciens travaux, nouveau packaging : les risques systémiques dans la chaîne de transmission entre recherche IA et récits boursiers
Comme l’analyse le blogueur technique Ben Pouladian, l’article TurboQuant était disponible depuis avril 2025 et ne constitue donc pas une découverte récente. Ce n’est que le 24 mars 2026 que Google l’a repackagé et promu officiellement via son blog, tandis que les marchés l’ont immédiatement traité comme une percée entièrement nouvelle. Cette stratégie de « nouvel article, ancienne publication », couplée à des biais potentiels dans les expérimentations décrites, met en lumière les risques systémiques présents dans la chaîne de transmission allant de la recherche académique aux récits financiers.
Pour les investisseurs en infrastructures IA, lorsqu’un article revendique des gains de performance « de plusieurs ordres de grandeur », la première question à se poser est celle de l’équité des conditions de comparaison.
L’équipe de Gao Jianyang a clairement indiqué qu’elle poursuivrait les démarches pour obtenir une résolution formelle de ce litige. À ce jour, Google n’a pas encore répondu publiquement aux accusations spécifiques formulées dans la lettre ouverte.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













