Décortiquer le processus de nettoyage des données d'Uniswap V3
TechFlow SélectionTechFlow Sélection
Décortiquer le processus de nettoyage des données d'Uniswap V3
Nous avons calculé la valeur nette des utilisateurs et le taux de rendement sur Uniswap à partir de l'adresse utilisateur.
Rédaction : Zelos
Introduction
Dans le précédent article, nous avions analysé la valeur nette et le rendement des utilisateurs sur Uniswap depuis la perspective des adresses. Cette fois-ci, notre objectif reste le même, mais nous allons intégrer également les liquidités détenues par ces adresses afin d’obtenir une valeur nette globale ainsi qu’un rendement agrégé.
Nous analysons ici deux pools :
-
Sur Polygon, le pool USDC-WETH (frais : 0,05 %), adresse du pool : 0x45dda9cb7c25131df268515131f647d726f50608[1], qui est le même que celui utilisé dans l’analyse précédente.
-
Sur Ethereum, le pool USDC-ETH (frais : 0,05 %), adresse du pool : 0x88e6A0c2dDD26FEEb64F039a2c41296FcB3f5640[2]. Ce pool contient un jeton natif, ce qui complique légèrement le traitement des données.
Les données finales sont au niveau horaire. Attention : chaque ligne représente la valeur à la dernière seconde de l'heure correspondante.
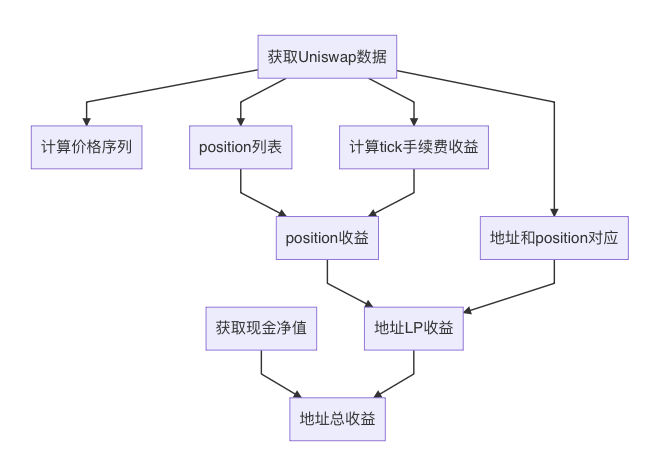
Processus général
-
Récupérer les données Uniswap
-
Récupérer les données de liquidités des utilisateurs
-
Calculer la série temporelle des prix, c’est-à-dire le prix de l’ETH.
-
Obtenir les frais générés chaque minute pour chaque tick.
-
Lister toutes les positions actives pendant la période d’analyse.
-
Établir la correspondance entre adresses et positions.
-
Calculer le rendement de chaque position.
-
Calculer le rendement global de chaque adresse en tant que fournisseur de liquidités (LP), grâce à la correspondance établie.
-
Combiner les liquidités et les positions LP pour obtenir le rendement total.
1. Récupération des données Uniswap
Précédemment, afin de fournir des données à Demeter, nous avons développé l’outil « demeter-fetch ». Cet outil permet de récupérer les logs d’un pool Uniswap via différentes sources et de les parser selon divers formats. Les sources supportées sont :
-
RPC Ethereum : interface RPC standard des clients Ethereum. L’efficacité est relativement faible ; plusieurs threads sont nécessaires.
-
Google BigQuery : téléchargement des jeux de données disponibles sur BigQuery. Bien que mis à jour quotidiennement, cet accès est simple d’utilisation et économique.
-
Trueblocks Chifra : le service Chifra permet de scraper les transactions de la chaîne et de les réorganiser, facilitant ainsi l’exportation des informations comme les transactions ou soldes. Toutefois, cela nécessite de mettre en place ses propres nœuds et services.
Les formats de sortie incluent :
-
minute : regrouper les transactions de swap Uniswap en données par minute, utile pour le backtesting.
-
tick : enregistrer chaque transaction du pool, y compris swaps et opérations sur la liquidité.
Ici, nous récupérons principalement les données au niveau « tick », afin d’analyser les informations des positions : montant fourni, revenus par minute, durée de vie, détenteurs, etc.
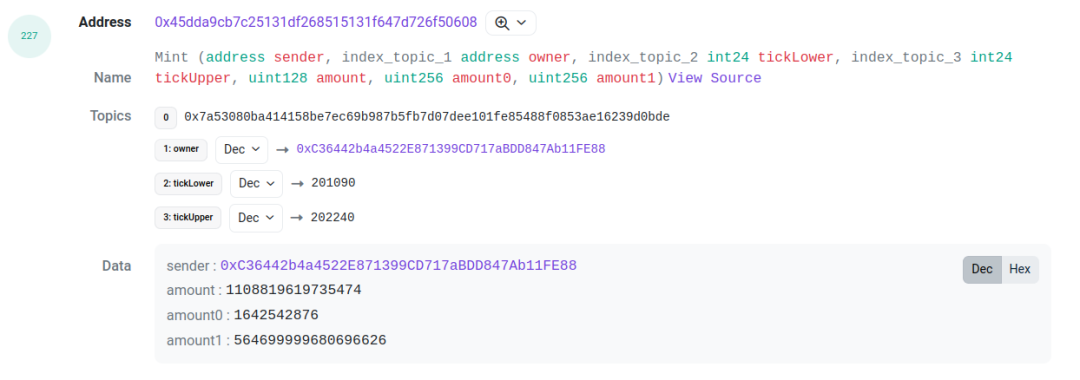
Ces données proviennent des événements du pool (logs) : mint, burn, collect, swap. Toutefois, les logs du pool ne contiennent pas l’identifiant du token (token ID). Il devient donc impossible de savoir à quelle position spécifique appartient une opération.
En réalité, les droits des LP Uniswap sont gérés via des NFTs, dont le contrat propriétaire est un proxy. Le token ID n’apparaît que dans les logs du contrat proxy. Pour obtenir une information complète sur les positions LP, il faut donc combiner les logs du pool avec ceux du proxy.
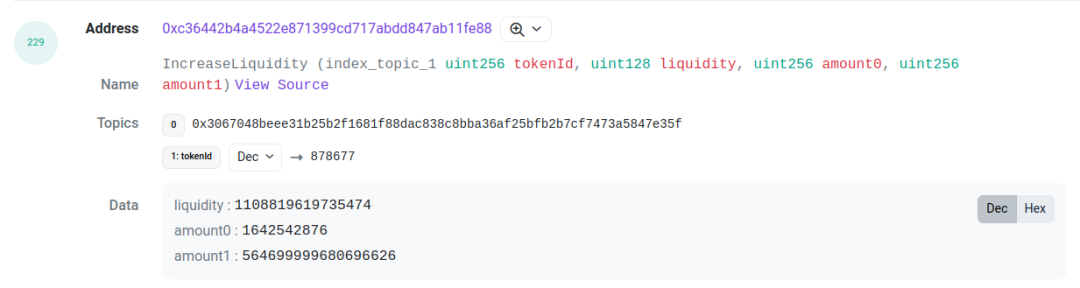
Prenons cet exemple de transaction [3] : examinons les logs aux index 227 et 229. Le premier provient du contrat pool (événement mint), le second du contrat proxy (événement IncreaseLiquidity). Les valeurs amount (liquidité), amount0 et amount1 sont identiques. Cela sert de base pour associer les deux événements. En reliant ces deux logs, on obtient ainsi la plage de ticks, la liquidité, le token ID et les montants respectifs des deux tokens pour cette position LP.
Certains utilisateurs expérimentés, notamment certains fonds, préfèrent contourner le proxy pour interagir directement avec le contrat pool. Dans ce cas, la position n’a pas de token ID. Nous créons alors un identifiant artificiel au format adresse-LowerTick-UpperTick.
Pour les événements burn et collect, on peut appliquer une méthode similaire afin d’associer les logs du pool à une position ID. Cependant, un problème surgit : parfois, les montants des deux événements diffèrent légèrement. Par exemple :
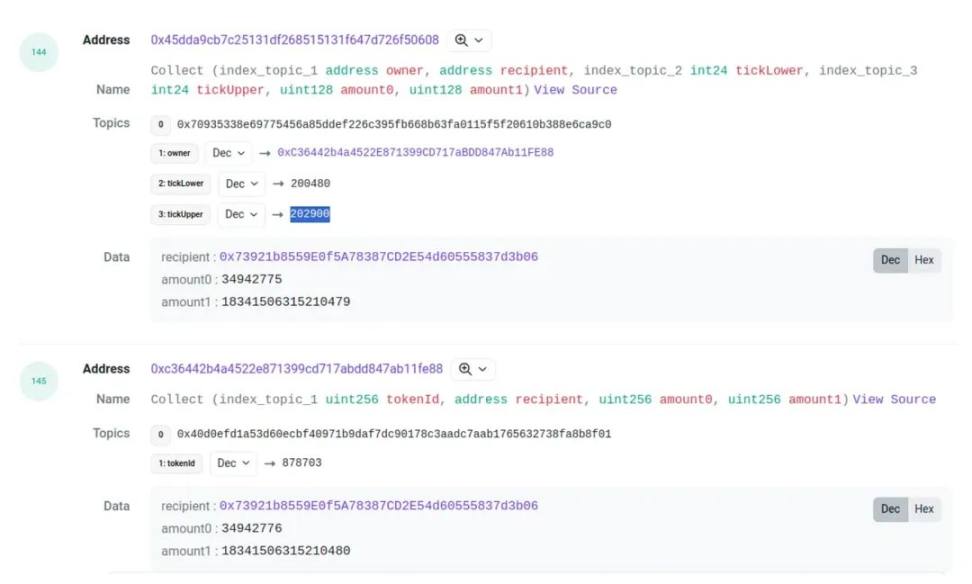
Les montants amount0 et amount1 présentent de légères différences. Bien que rares, ces écarts sont fréquents. Ainsi, lors de l’appariement des événements burn/collect, nous introduisons une marge d’erreur tolérée.
Un autre point à traiter : identifier l’initiateur de la transaction. Pour les retraits (collect), nous prenons l’adresse du destinataire (receipt) comme détenteur de la position. Pour les mint, seule l’adresse de l’émetteur (sender) est disponible dans l’événement mint du pool (voir image).
Si l’utilisateur interagit directement avec le pool, le sender est bien le fournisseur de liquidités. Mais si un utilisateur standard passe par le proxy, le sender sera l’adresse du proxy, car les fonds transitent effectivement du proxy vers le pool. Heureusement, le proxy crée un NFT, qui est toujours transféré au véritable fournisseur de liquidités. En surveillant les transferts du contrat proxy (contrat NFT), on peut donc retrouver le fournisseur initial du mint.
Par ailleurs, un transfert du NFT entraîne un changement de détenteur de la position. Nous avons constaté que ces cas sont rares. Pour simplifier, nous n’avons pas pris en compte les transferts de NFT après le mint initial.
2. Récupération des liquidités détenues par les adresses
L’objectif ici est d’obtenir, pour chaque adresse, la quantité de tokens détenue à chaque instant durant la période analysée. Deux types de données sont nécessaires :
-
Le solde initial de l’adresse au début de la période.
-
L’historique des transferts de l’adresse durant la période.
En ajustant le solde initial avec les mouvements entrants/sortants, on peut reconstruire le solde à chaque instant.
Le solde initial peut être consulté via une requête RPC. Avec un nœud archive, il est possible de spécifier la hauteur du bloc pour obtenir le solde à une date précise. Cette méthode fonctionne aussi bien pour les jetons natifs que pour les jetons ERC20.
La récupération des historiques de transfert ERC20 est simple, accessible via RPC, BigQuery ou Chifra.
Pour les transferts ETH, il faut exploiter les transactions et traces. Les transactions sont accessibles facilement, mais les traces sont coûteuses à traiter. Heureusement, Chifra propose une fonctionnalité d’export des modifications de soldes ETH : chaque changement de solde génère un enregistrement. Bien qu’elle ne mentionne pas le destinataire, cette information suffit à nos besoins, et constitue la solution la plus économique.
3. Récupération des prix
Uniswap étant un DEX, chaque swap génère un événement contenant un champ sqrtPriceX96, à partir duquel on peut extraire le prix du token. Le champ liquidity donne la liquidité totale du pool à cet instant.
Nos pools contiennent un stablecoin, ce qui facilite grandement l’obtention du prix en USD. Toutefois, ce prix n’est pas parfaitement précis. Premièrement, il dépend de la fréquence des swaps : en l’absence de swap, le prix stagne. Deuxièmement, en cas de décrochage du stablecoin, le prix diffère du cours réel. Néanmoins, dans la plupart des cas, cette approximation est suffisamment fiable pour des analyses de marché.
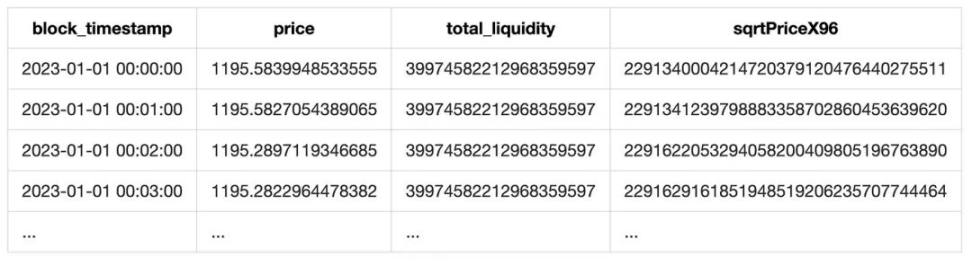
Enfin, en rééchantillonnant les prix, on obtient une série horaire.
De plus, le champ liquidity de l’événement contient la liquidité totale du pool. Nous ajoutons donc cette donnée à notre tableau final :
4. Statistiques des frais
Les frais constituent la principale source de revenus d’une position. À chaque swap sur le pool, les positions dont la plage de ticks englobe le tick courant perçoivent des frais proportionnels à leur part de liquidité, aux frais du pool et à la largeur de leur plage.
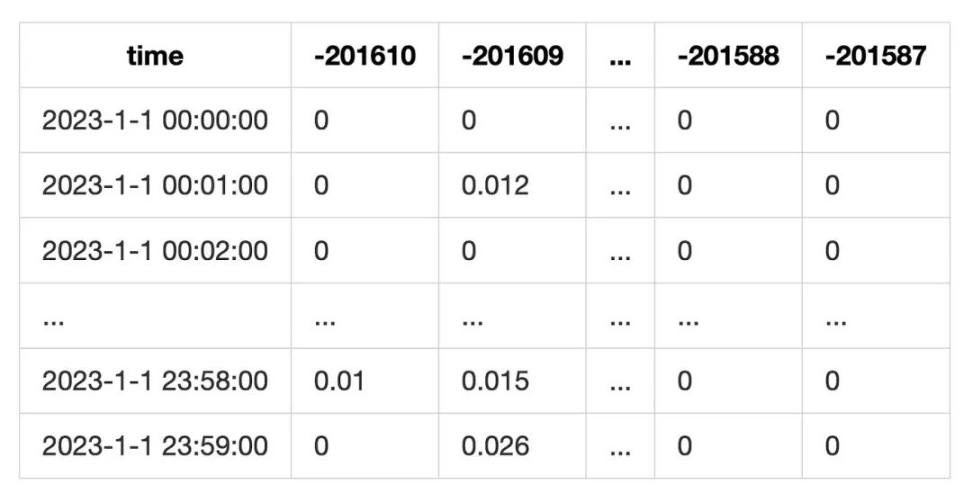
Pour calculer les revenus en frais, nous enregistrons chaque minute le montant échangé sur chaque tick. Puis nous calculons les revenus horaires pour chaque tick :

Ce qui donne un tableau comme suit :
Cette méthode ignore les cas où la liquidité du tick est épuisée pendant un swap. Toutefois, comme nous analysons par plage de ticks, cet effet est atténué.
5. Obtenir la liste des positions
Pour lister les positions, il faut d’abord définir un identifiant unique pour chacune :
-
Pour les LP passant par le proxy, chaque position possède un NFT avec un token ID, servant d’identifiant.
-
Pour les LP interagissant directement avec le pool, nous créons un identifiant artificiel au format
adresse_LowerTick_UpperTick. Ainsi, toutes les positions ont un identifiant unique.
Grâce à cet identifiant, nous pouvons agréger toutes les actions d’un LP et reconstruire l’historique complet de la position :

Toutefois, la période analysée est limitée à l’année 2023. Par conséquent, certaines positions peuvent avoir été créées avant janvier 2023, et leurs opérations antérieures sont inconnues. Nous devons donc estimer la liquidité initiale au 1er janvier 2023. Notre méthode est la suivante :
-
Additionner les liquidités de tous les mint et burn. Soit L ce résultat.
-
Si L > 0 (mint > burn), on suppose qu’il existait déjà de la liquidité avant 2023. On ajoute donc un événement fictif de mint au 1er janvier 2023 à 00:00:00.
-
Si L < 0, on suppose que la position conserve encore de la liquidité à la fin de la période.
Cette approche évite de télécharger les données antérieures à 2023, réduisant ainsi les coûts. Toutefois, elle pose le problème des « liquidités immergées » : si un LP n’a effectué aucune opération en 2023, il ne sera pas détecté. Ce cas est négligeable car, sur une année, les variations de prix incitent généralement les utilisateurs à ajuster leurs positions. Nous supposons donc que les utilisateurs actifs modifient leurs LP au fil du temps. Ceux qui laissent leurs fonds sans intervention sont considérés comme inactifs et exclus de l’analyse.
Un cas plus problématique survient lorsque la position a été créée avant 2023, puis modifiée durant l’année sans être totalement retirée. Dans ce cas, seule une partie de la liquidité est observée, ce qui biaise l’estimation des frais et fausse le rendement. Ce phénomène sera discuté plus tard.
Dans les résultats finaux, 73 278 positions sur Polygon et 21 210 sur Ethereum ont été identifiées. Moins de 10 positions par chaîne présentent des anomalies de rendement, confirmant la validité de notre hypothèse.
6. Établir la correspondance entre adresses et positions
Comme l’objectif final est d’analyser le rendement par adresse, il est nécessaire d’établir la relation entre adresses et positions. Grâce aux travaux réalisés à l’étape 1 (identification des initiateurs des opérations mint/collect), il suffit désormais d’associer l’expéditeur du mint et le destinataire du collect pour lier une position à une adresse.
7. Calcul de la valeur nette et du rendement des positions
À cette étape, nous calculons la valeur nette de chaque position, puis son rendement.
Valeur nette
La valeur nette d’une position comporte deux composantes : la liquidité (capital investi) et les frais accumulés. La liquidité ne change pas en volume, mais sa valeur fluctue avec le prix. Les frais, stockés séparément dans fee0 et fee1, augmentent progressivement dans le temps.
À chaque minute, la combinaison de la liquidité et du prix donne la valeur du capital. Pour les frais, nous utilisons la table calculée à l’étape 4.
D’abord, on calcule la part de liquidité de la position par rapport à la liquidité totale du pool. Ensuite, on somme les frais générés sur chaque tick inclus dans la plage de la position.
Formellement :

En additionnant fee0 et fee1, on obtient la valeur nette des frais. Ajoutée à celle de la liquidité, on obtient la valeur nette totale.
Le calcul de la valeur nette est segmenté selon les événements mint/burn/collect :
-
Un mint augmente la liquidité.
-
Un burn diminue la liquidité. La valeur de la liquidité retirée est convertie en frais (comme le fait le contrat pool).
-
Un collect déclenche un calcul : entre le dernier collect et l’instant courant, on calcule la valeur nette et les revenus en frais minute par minute, produisant une liste.
Finalement, on agrège les listes de chaque collect, puis on rééchantillonne et traite statistiquement pour obtenir le résultat final.
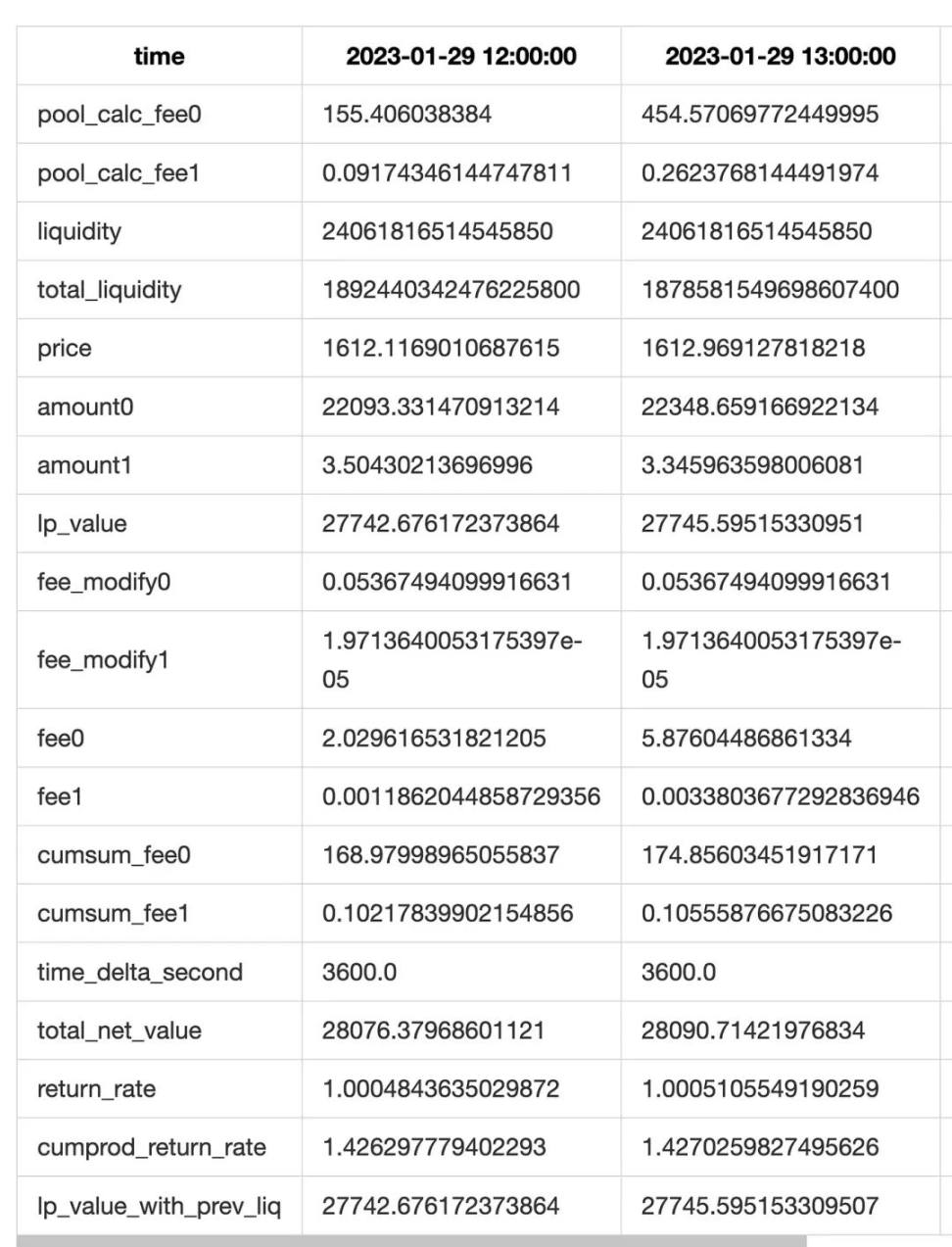
Deux optimisations améliorent la précision :
Premièrement, pour les heures contenant des transactions (mint/burn/collect), nous effectuons un calcul minuté. Pour les autres, un calcul horaire suffit. Le tout est ensuite rééchantillonné à l’échelle horaire.
Deuxièmement, l’événement collect fournit la somme réelle de liquidité + frais. En comparant cette valeur avec notre estimation théorique, nous obtenons un écart. Ce différentiel (qui inclut aussi une petite erreur sur le capital, négligeable) est réparti sur chaque ligne pour corriger les frais estimés (colonnes fee_modify0 et fee_modify1 dans le tableau ci-dessus).
Remarques :
-
Lors de la compensation, il faut pondérer par la liquidité horaire, sinon les frais apparaîtraient artificiellement élevés.
-
Comme les données couvrent seulement 2023, le phénomène des « liquidités immergées » (étape 5) peut faire apparaître des frais réels beaucoup plus élevés que prévus, entraînant des rendements anormalement élevés.
Étant donné que chaque ligne représente la valeur à la fin de l’heure, une position clôturée aura une valeur nette nulle à sa dernière heure. Sa valeur finale serait alors perdue. Pour la préserver, nous ajoutons une ligne factice à 2038-01-01 00:00:00 contenant la valeur nette au moment de la fermeture, utile pour d’autres analyses ultérieures.
Rendement
Habituellement, le rendement se calcule comme le ratio entre valeur finale et valeur initiale. Mais cela ne convient pas ici, car :
-
Le rendement doit être calculé minute par minute.
-
Des flux entrants/sortants peuvent survenir en cours de route, rendant obsolète le simple ratio final/initial.
Pour le point 1, on peut diviser chaque minute la valeur nette par celle de la minute précédente, puis multiplier les rendements partiels pour obtenir le rendement total :
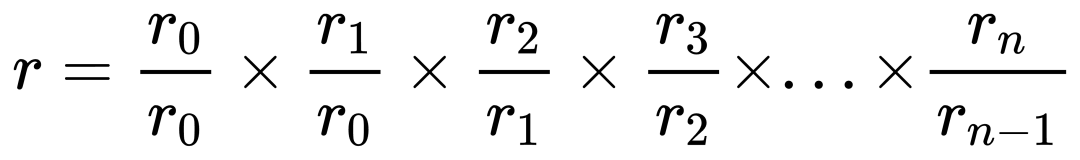
Mais cette méthode est fragile : une erreur sur une seule minute fausse tout le résultat. L’analyse devient extrêmement sensible aux erreurs — bien que cela permette de repérer rapidement toute anomalie.
Pour le point 2, si une transaction intervient, le rendement direct serait absurde. Il faut donc affiner le calcul.
Notre première approche consiste à décomposer soigneusement la variation de valeur nette et à exclure les flux de capitaux. Nous scindons la variation en trois parties : 1) variation due au prix, 2) frais accumulés, 3) flux entrants/sortants. La partie 3 doit être exclue. Nous adoptons donc la méthode suivante :
-
Soit n la minute courante, n-1 la précédente.
-
Supposons que tous les transferts de la minute n aient lieu à n:00.000. Ensuite, la valeur nette reste constante jusqu’à n:59.999.
-
L’accumulation des frais a lieu à la fin de la minute, soit à n:59.999.
-
Le prix et les frais à la fin de n-1 (n-1:59.999) deviennent le prix et frais initiaux de n (n:00.000).
Sous ces hypothèses, le rendement horaire est le ratio entre (valeur finale en liquidité/prix/frais) et (valeur initiale en liquidité/prix/frais), avec f représentant la fonction de conversion en valeur nette :
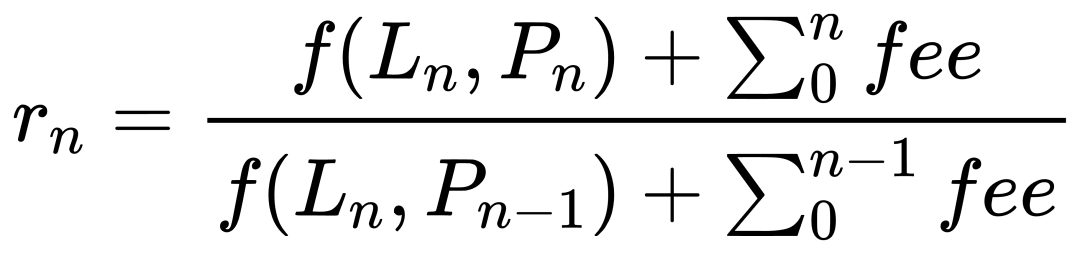
Cette méthode semble idéale : elle isole parfaitement l’impact du prix et des frais, indépendamment des flux. Mais en pratique, certains cas produisent des rendements aberrants. Après investigation, le problème vient des burnings. Rappelons que chaque ligne représente la fin de l’heure. Or, les colonnes ont des significations différentes :
-
La colonne valeur nette est une valeur instantanée (à la fin de l’heure).
-
La colonne frais est cumulative (somme des frais de l’heure).
Ainsi, lors d’un burn complet :
-
Après le retrait et le transfert des tokens, la valeur nette à la fin de l’heure est nulle.
-
Mais les frais restent positifs, car ils sont cumulés.
Cela conduit à une division par zéro ou un dénominateur très petit, générant un rendement infini ou très élevé. Ce problème survient non seulement à la fin de vie de la position, mais aussi lors de réductions partielles de liquidité.
Pour simplifier, nous fixons le rendement à 1 lors d’un changement de valeur nette. Cela introduit une légère erreur, mais comme les transactions sont rares par rapport à la durée totale, l’impact global est minime.
8. Calcul du rendement total LP par adresse
Ayant le rendement de chaque position et la correspondance adresse-position, nous pouvons maintenant calculer le rendement LP de chaque adresse.
L’algorithme est simple : concaténer chronologiquement les positions d’une même adresse. Pendant les périodes sans position, la valeur nette est nulle et le rendement fixé à 1 (car aucune variation).
Si plusieurs positions coexistent, leurs valeurs nettes sont additionnées dans les plages superposées. Pour le rendement agrégé, une moyenne pondérée par la valeur nette de chaque position est utilisée.
9. Fusion des liquidités et du rendement LP total
Enfin, en combinant les liquidités détenues et les investissements LP, nous obtenons le résultat final.
La fusion des valeurs nettes est plus simple que l’étape précédente. Il suffit, pour chaque intervalle horaire, de récupérer la valeur nette LP, les liquidités détenues et le prix de l’ETH pour calculer la valeur nette totale.
Pour le rendement, nous appliquons initialement la méthode de l’étape 7 (rendement par minute puis produit). Cela nécessite de distinguer les composantes fixes (liquidités cash, liquidité LP) des variables (prix, frais, flux). Comparé à l’analyse LP seule, la complexité augmente fortement : pour les flux LP, seuls mint et collect sont pertinents. Mais pour les liquidités, il faut tracer chaque transfert ERC20 et ETH, déterminer s’il va vers un LP ou sort vers l’extérieur. Si externe, ajuster le capital. Cela exige de suivre les destinations des transferts — une tâche ardue. En particulier, lors d’un mint/collect, le transfert peut aller au pool ou au proxy. Pire encore, pour ETH (jeton natif), certains transferts ne sont visibles que via les traces, dont le volume dépasse nos capacités de traitement.
Le coup de grâce vient de la découverte tardive que la valeur nette horaire est une valeur instantanée (fin de l’heure), tandis que les frais sont cumulés (sur toute l’heure). Du point de vue physique, ces deux grandeurs ne sont pas directement additionnables.
Nous abandonnons donc cette méthode au profit d’un calcul simple : rendement = valeur nette(n) / valeur nette(n-1). Beaucoup plus simple, mais toujours sensible aux flux : quand un transfert intervient, le rendement devient aberrant. Comme nous savons que distinguer les flux est trop complexe, nous sacrifions un peu de précision : lorsque des flux sont détectés, le rendement est fixé à 1.
Reste à détecter les heures avec flux. Initialement, nous comparons la valeur nette théorique (basée sur le solde précédent et le prix) à la valeur réelle. Une différence indique un flux. Formellement :

Mais cette méthode ignore la complexité des LP Uniswap : la composition des tokens dans une position varie avec le prix, et les frais s’accumulent. L’erreur atteint environ 0,1 %.
Pour améliorer la précision, nous affinons la décomposition : calculons séparément la variation de valeur du LP et intégrons les frais :
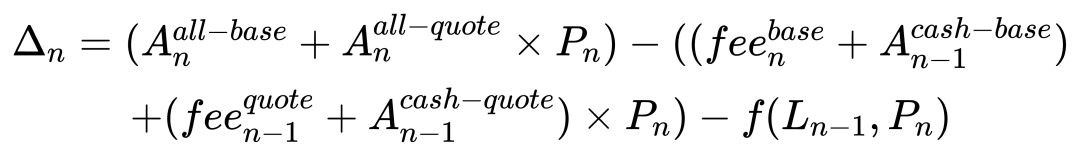
Avec cette méthode, l’erreur tombe sous 0,001 %.
Enfin, nous limitons la précision décimale pour éviter la division par des nombres très petits (souvent inférieurs à 10⁻¹⁰), résultant d’erreurs d’arrondi cumulées. Sans traitement, ces divisions amplifient les erreurs et faussent gravement le rendement.
Autres problèmes
Jeton natif
Cette analyse inclut le pool USDC-ETH sur Ethereum, où ETH est un jeton natif, nécessitant un traitement particulier.
ETH ne peut pas être utilisé directement dans les protocoles DeFi ; il doit être converti en WETH. Ce pool est donc techniquement un pool USDC-WETH. Pour les utilisateurs interagissant directement avec le pool, l’ajout/retrait de WETH fonctionne comme pour tout autre pool.
Pour les utilisateurs passant par le proxy, ils doivent envoyer ETH dans le champ « value » de la transaction au contrat proxy. Ce dernier convertit l’ETH en WETH puis injecte la liquidité dans le pool. Lors d’un collect, USDC est envoyé directement à l’utilisateur, mais l’ETH doit d’abord être retiré du pool vers le proxy, converti en ETH natif, puis transféré à l’utilisateur via une transaction interne. Voir exemple dans cette transaction [4].
Ainsi, le pool USDC-ETH ne diffère d’un pool standard que par les mécanismes d’entrée/sortie de fonds. Cela affecte uniquement la correspondance position-adresse. Pour y remédier, nous avons récupéré tous les transferts NFT du pool depuis sa création, puis utilisé le token ID pour identifier le détenteur de chaque position.
Positions manquantes
Certaines positions n’apparaissent pas dans la liste finale. Elles présentent souvent des particularités.
Beaucoup sont des transactions MEV : pures opérations d’arbitrage, pas des investissements classiques, donc exclues de notre analyse. Leur suivi est aussi technique, nécessitant des données au niveau trace. Ici, nous appliquons une règle simple : filtrer les positions dont la durée de vie est inférieure à une minute. Étant donné que notre granularité maximale est la minute, toute position vivant moins d’une minute ne peut être capturée.
Une autre possibilité : absence d’événement collect. Comme expliqué à l’étape 7, le calcul des rendements est déclenché par un collect. Sans collect, aucun calcul n’est effectué. Normalement, les utilisateurs retirent régulièrement leurs gains ou capital. Mais certains pourraient choisir de laisser leurs actifs dans les champs fee0/fee1 du pool. Ces cas sont considérés comme atypiques et exclus.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News