

Entretien avec le fondateur de Nil Foundation : la technologie ZK pourrait être mal utilisée, la traçabilité publique n'étant pas l'objectif initial du chiffrement
TechFlow SélectionTechFlow Sélection
Entretien avec le fondateur de Nil Foundation : la technologie ZK pourrait être mal utilisée, la traçabilité publique n'étant pas l'objectif initial du chiffrement
Misha estime que l'industrie des cryptomonnaies trouve son origine dans la cryptographie financière, visant à éliminer les hypothèses de confiance, plutôt que de rendre tout traçable et publiquement lisible.

Présentation de l’interview
Mikhail Komarov, surnommé Misha, est le fondateur et PDG de la fondation Nil. La fondation Nil travaille à construire le générateur de preuves à connaissance nulle (zk) le plus sûr ainsi qu’un marché pour ces preuves, afin de résoudre les problèmes les plus urgents auxquels Web3 fait face : créer des circuits zk sécurisés et fiables comme infrastructure pour ouvrir la voie au Web3 futur.
En 2023, la technologie zk est devenue un mot-clé très populaire. Toutefois, Misha souligne que « les solutions actuelles populaires telles que Polygon, zkSync ou Starkware reposent sur des circuits zkEVM dont la nature en boîte noire pourrait provoquer une crise majeure si elle était mal utilisée, car ces bases de données gèrent des liquidités considérables ».
Cet entretien explore en profondeur la technologie zk, y compris son histoire méconnue et ses multiples applications dans Web3. Le parcours de Misha dans la gestion traditionnelle des bases de données lui permet d’offrir des perspectives uniques et approfondies sur l’état actuel de l’industrie blockchain.
Quelles sont les différences fondamentales entre les blockchains et les bases de données traditionnelles ? Comment peuvent-elles coexister ? Les preuves à connaissance nulle domineront-elles tout à l’avenir ? Comment la confidentialité zk peut-elle bouleverser l’industrie de l’analyse de données ? Et comment comprendre simplement des termes techniques comme circuit, zk, compilateur ou base de données ?
Trouvons les réponses ensemble lors de cet entretien.
Résumé
-
La seule différence notable entre la gestion des bases de données traditionnelles et la blockchain réside dans la manière dont les journaux de validation ou séquences de blocs sont construits.
-
La taille et la complexité actuelles des circuits zkEVM pourraient dissimuler des vulnérabilités de sécurité latentes. Exploiter ces failles dans des roll-ups populaires comme Polygon, zkSync ou Starkware pourrait entraîner une crise majeure pour toute l’industrie, étant donné l’ampleur des liquidités et dépendances liées à ces bases de données.
-
L'utilisation erronée du zk comme outil de compression plutôt que comme outil de confidentialité explique sa large adoption — des applications telles que les roll-ups, zk-bridges, zk-mls ou zk-oracles exploitent essentiellement la fonctionnalité de compression du zk, pas ses propriétés de confidentialité.
-
Selon Misha, l’industrie cryptographique trouve ses origines dans la cryptographie financière, visant à éliminer les hypothèses de confiance, et non à rendre tout traçable et publiquement lisible.
À propos du parcours de Misha
TechFlow : Pouvez-vous vous présenter et nous raconter comment vous avez découvert le monde des cryptomonnaies ?
Misha : Mon entrée dans le terrier du lapin cryptographique a été tout à fait inattendue.
Aujourd’hui, beaucoup de projets partent d’une technologie pour ensuite chercher des cas d’usage. Mais en 2013, certaines personnes ont compris l’importance de protéger la confidentialité et la sécurité des canaux de communication, et Bitmessage offrait une solution. J’ai alors pensé : « Faisons-le marcher. » Je suis devenu l’un de ses premiers contributeurs.
Avant cela, j’étais étudiant en première année d’université. Avais-je mieux à faire ? Je me suis dit : « Bon, je suis déjà impliqué dans ce domaine, je peux sans doute développer quelque chose. » C’est ainsi que tout a commencé pour moi dans les cryptomonnaies.
Avant mon implication dans Bitmessage, j’avais étudié le fonctionnement des systèmes de gestion de bases de données (SGBD), principalement pour pratiquer le langage Cypher à l’université.
J’ai trouvé la blockchain intéressante et similaire aux SGBD, mais je ne comprenais pas pourquoi tant de gens ne voyaient pas la blockchain comme un système de base de données valable.
Cela m’a poussé à creuser davantage, pour comprendre pourquoi elle était perçue uniquement comme un protocole financier cryptographique, plutôt que comme une solution complète de gestion des données (SGBD).
En approfondissant mes recherches, j’ai concentré mes études sur la topologie algébrique, ce qui m’a conduit à la théorie de la complexité puis à la cryptographie.
Ces deux chemins — SGBD et cryptographie — se sont croisés, c’est là que j’ai découvert le lien entre l’industrie des bases de données et celle de la cryptographie.
Objectifs et avancement actuel de la fondation Nil
TechFlow : En 2018, la fondation Nil a été créée, axée sur la recherche en systèmes de gestion de bases de données (SGBD) et cryptographie appliquée. Pouvez-vous expliquer comment une blockchain peut être comprise comme un système de gestion de bases de données ?
Misha : L’architecture des systèmes de gestion de bases de données traditionnels et celle des marchés cryptographiques sont en réalité très similaires.
Elles découlent toutes deux de l’idée fondamentale de gérer et stocker des données, par exemple via les journaux de validation dans les SGBD ou les chaînes de blocs. La méthode de tri chronologique ressemble fortement à l’organisation des entrées dans un journal de validation.
Les plaintes actuelles sur la voluminosité des données d’état dans l’industrie crypto ne sont pas uniques : les entreprises traditionnelles doivent aussi gérer et maintenir d’importantes bases d’état.
La seule différence notable entre les deux industries réside dans la manière dont les journaux de validation ou séquences de blocs sont construits. Le processus de construction n’est pas fondamentalement différent. Il est simplement adapté aux besoins spécifiques de chaque environnement.
Dans l’industrie crypto, l’accent est mis sur la réduction des hypothèses de confiance dans un environnement non fiable, tandis que l’industrie traditionnelle privilégie l’efficacité, sans nécessairement prioriser la question de la confiance.
Notre recherche vise à appliquer les principes et réalisations du secteur des SGBD traditionnels à l’industrie crypto, afin de traiter efficacement la gestion des données et les hypothèses de confiance, favoriser leur convergence et identifier des points communs.
TechFlow : Quels sont les défis et avantages potentiels liés à la fusion des industries des SGBD traditionnels et de la cryptographie ? Quel impact cela pourrait-il avoir ?
Misha : Il faut noter qu’un SGBD peut nécessiter plus de cinq ans de développement, alors que les projets crypto ont souvent des cycles bien plus courts. Cette différence de cycle de développement affecte directement la convergence entre les deux industries.
Nous faisons partie des rares projets tentant de combler l’écart entre les solutions de gestion des données en crypto et celles du secteur des SGBD. Notre focus est sur les solutions SGBD au sein de l’écosystème crypto, pas au niveau des protocoles.
Par exemple, l’interopérabilité est fréquemment discutée dans l’industrie crypto.
L’approche SGBD peut simplifier cette interopérabilité en offrant un accès complet aux données. Par exemple, la liquidité verrouillée sur Ethereum est une donnée écrite sur son réseau, accessible directement avec le même niveau de sécurité. Cela élimine le besoin de migration de données lors de la création de nouvelles bases (comme les roll-ups).
Cela réduit le besoin de ponts et simplifie la gestion des données entre différentes bases.
TechFlow : Concernant la fourniture d’un SGBD transparent et efficace pour l’industrie crypto, comment votre projet a-t-il évolué dans sa méthodologie ? Comment vos développements autour de zkLLVM et de la marchandisation des zk-SNARKs contribuent-ils à cet objectif ?
Misha : Ce qui relie notre objectif initial à nos travaux actuels, c’est la prise de conscience qu’il fallait réduire les hypothèses de confiance dans nos solutions SGBD. Nous souhaitons assurer la transparence et prouver les calculs exécutés au sein du système de gestion de bases de données.
Cela nous a conduit à explorer des circuits complexes tels que les preuves d’état et de consensus, en collaborant avec des fondations comme Mina ou Ethereum pour apprendre et mettre en œuvre ces solutions.
Au départ, nous créions manuellement les circuits, mais c’était un processus difficile et long. Pour y remédier, nous avons développé zkLLVM, un compilateur vérifiable capable de générer des circuits à partir de code lisible. La raison ? C’est exactement ce que font les gens dans les SGBD, et cela peut aussi s’appliquer aux futures bases de données décentralisées.
Nous avons choisi d’utiliser des langages et compilateurs existants pour générer des circuits, plutôt que de créer un langage spécifique (DSL). Un compilateur de circuits peut prouver presque n’importe quoi, même des applications simples comme des jeux. Mais prouver des éléments complexes requiert d’énormes capacités de calcul et une expertise pointue.
Lorsque vous traitez de très grands circuits, les temps de preuve deviennent colossaux — pas seulement quelques minutes ou heures, mais des jours, des semaines, voire des mois.
Cela nous a amenés à introduire une dynamique de marché afin d’inciter à l’optimisation — en rendant les zk-SNARKs commercialisables, nous encourageons la concurrence entre vérificateurs et optimiseurs. Cette compétition stimule l’innovation et améliore l’efficacité des preuves zk-SNARK. Notre but est de créer un écosystème où l’optimisation des preuves zk-SNARK est constamment recherchée, favorisant ainsi une amélioration continue.
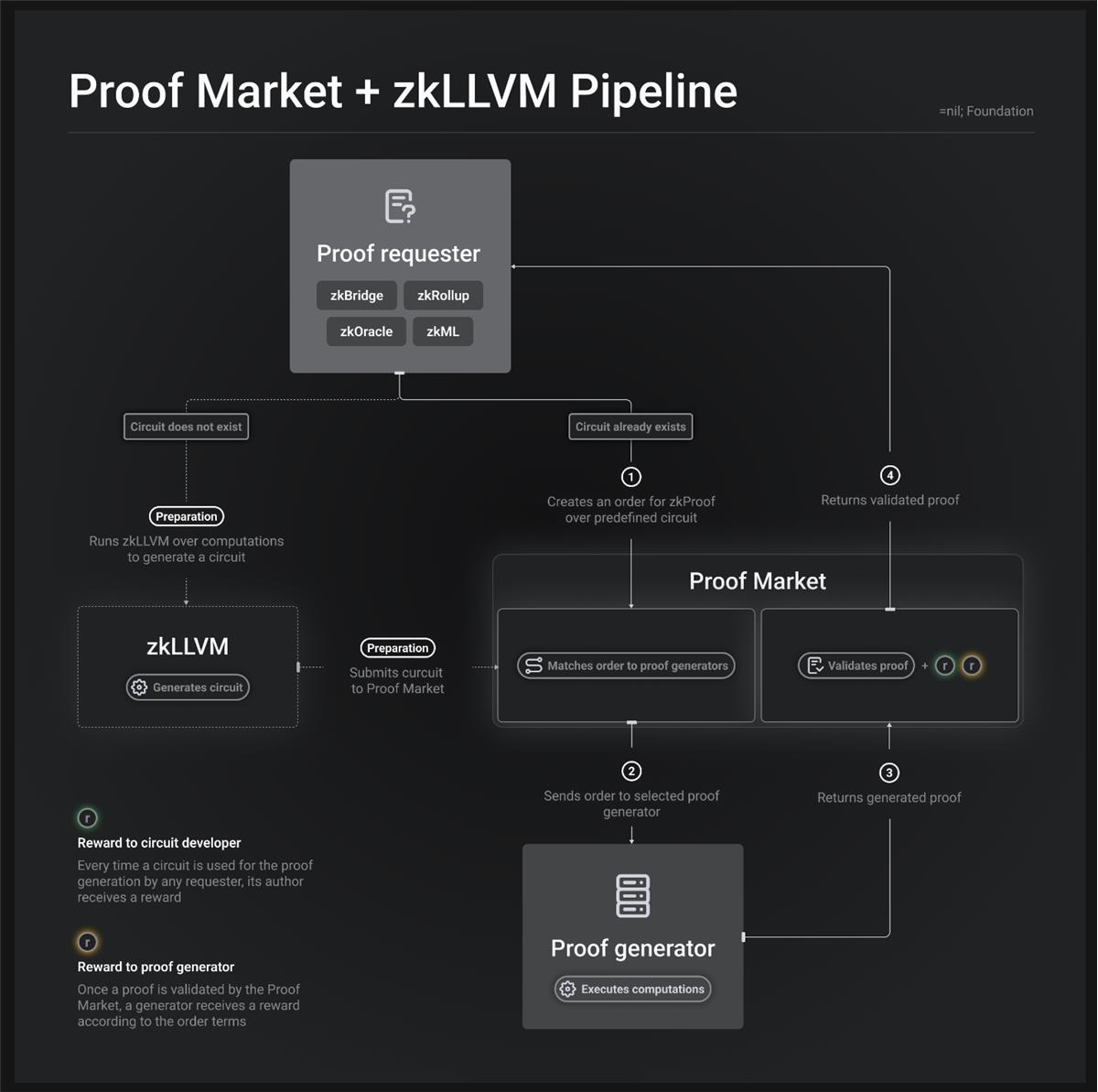
Popularité, mauvais usages et impacts de la technologie zk dans l’industrie crypto
TechFlow : Pouvez-vous retracer brièvement l’histoire de la recherche et du développement des preuves à connaissance nulle ? Depuis leur conception par des mathématiciens à la fin des années 1980, quelles limites et défis ont freiné leur adoption généralisée ?
Misha : L’adoption massive des preuves à connaissance nulle a été freinée par plusieurs obstacles majeurs.
Avant 2008–2010, avant l’apparition des bases de données et protocoles BFT (tolérance aux pannes byzantines), on utilisait déjà des preuves à connaissance nulle pour prouver des choses que l’on préférait ne pas divulguer publiquement, comme des certifications bancaires ou industrielles.
Toutefois, pendant longtemps, il n’existait aucun moyen de prouver des calculs complexes, généraux et Turing-complets. Les premières implémentations se limitaient à des calculs simples, incapables de traiter des opérations complexes. Avec le temps, des systèmes de preuve plus avancés et des opérations arithmétiques ont permis de prouver des calculs Turing-complets et des processus organisationnels complexes ; divers formalismes sont apparus, comme les systèmes de contraintes, structures organisationnelles spécifiques ou sites d’éligibilité, destinés à décrire et prouver des processus complexes et des protocoles BFT.
Malheureusement, cette technologie a été largement détournée : on s’est rendu compte que ces systèmes de preuve permettaient non seulement de cacher des calculs et données, mais aussi de compresser d’immenses volumes de calcul en de courtes preuves compactes.
Comme Eli Ben-Sasson de StarkWare le mentionne souvent, lorsque ces systèmes sont utilisés à des fins de compression, la propriété de « connaissance nulle » devient superflue.
Ce mauvais usage a conduit à l’émergence d’une série d’applications — roll-ups, zk-bridges, zk-mls, zk-oracles — qui excluent les usages liés à la confidentialité, et se concentrent sur le mécanisme de compression. En réalité, dans ces applications, le composant de confidentialité peut être retiré sans compromettre leur fonctionnement.
Par exemple, un roll-up peut fonctionner sans confidentialité, car il exploite principalement le système de preuve pour la compression des données. Ce recours massif — quoique erroné — à la technologie a néanmoins permis sa large diffusion dans le monde crypto.
TechFlow : Vous parlez donc de preuves à connaissance nulle sans fonctionnalité de confidentialité ? Comment percevez-vous cet usage « partiel » de la technologie ?
Misha : Bien qu’il soit possible de contourner ou supprimer le composant de confidentialité, celle-ci reste une propriété intrinsèque et un avantage de la technologie. Supprimer cet aspect revient à ôter certaines opérations du système de preuve, comme les multiplications.
Cela entraîne une perte de confidentialité, mais conserve la propriété de compression. Cette caractéristique de compression restera probablement toujours présente, et fait partie intégrante des schémas de promesse et modes de calcul de ce secteur.
TechFlow : Pourquoi choisir le zk plutôt que d’autres méthodes cryptographiques ?
Misha : Le zk offre le meilleur taux de compression. Aucun autre mécanisme ne permet de compresser les données à une telle échelle. De plus, aucune autre technologie ne permet de vérifier aussi facilement les données compressées.
TechFlow : Si le zk est si performant, zk-Everything est-il l’état futur de la blockchain ?
Misha : On a déjà essayé d’appliquer le zk à tout. Certains ont même tenté d’y intégrer des jeux, ce qui est assez étrange.
Des algorithmes de machine learning (ML) ont également été « zk-isés ». Effectuer des calculs dans un environnement sans confiance et selon des protocoles BFT reste coûteux — encore plus que de sous-traiter le calcul à des machines puissantes.
Malgré tous les efforts, ces calculs restent chers. Donc, même si l’on essaie de tout zk-iser, on cherche aussi à exécuter des opérations privées au-dessus du zk, en utilisant le chiffrement homomorphe (FHE), ou en explorant d’autres solutions de systèmes de preuve.
Sur notre site, certains cas d’usage exigent de générer des preuves à partir de données confidentielles sans les révéler. Pour cela, nous combinons zk et chiffrement homomorphe complet (FHE). Ces technologies deviendront aussi cruciales que les signatures sur courbes elliptiques, ajoutant une couche supplémentaire de sécurité et de confidentialité aux systèmes.
Protection de la vie privée, anonymat et traçabilité des données en chaîne
TechFlow : Vitalik Buterin a récemment évoqué trois transformations clés, notamment l’amélioration de l’extensibilité et de la confidentialité grâce aux technologies zk. Étant donné que les données de transaction et adresses sont généralement considérées comme anonymisées, pouvez-vous préciser le rôle spécifique des preuves à connaissance nulle dans le renforcement de la confidentialité ?
Misha : Il existe une distinction entre anonymat et pseudo-anonymat.
Par défaut, toutes ces bases de données et protocoles offrent un pseudo-anonymat. Cela signifie que vous pouvez retracer et observer ce qui se passe, mais vous ignorez l’identité des participants. Le pseudo-anonymat est l’état par défaut.
Mais l’anonymat réel et la confidentialité vont plus loin : ils impliquent de cacher même le fait qu’une activité a eu lieu — transfert, opération ou transaction. Il ne s’agit pas seulement de masquer l’identité des participants, mais aussi l’existence même de l’activité.
Prenons Zcash, l’un des exemples les plus célèbres de preuve zk. Dans Zcash, les données ne sont pas stockées de façon publiquement lisible, mais cryptées.
Lorsqu’un utilisateur doit modifier une donnée, il accède aux données, les déchiffre, effectue les changements nécessaires, les re-chiffre, puis les charge dans la base publique.
Toutefois, pour garantir qu’aucune action malveillante n’a été menée, la personne doit fournir une preuve qu’elle a correctement déchiffré et re-chiffré les données. Elle doit prouver avoir manipulé les données d’une manière valide et conforme.
TechFlow : Quel impact la protection de la vie privée a-t-elle sur l’analyse des données en chaîne ?
Misha : D’abord, cela va poser problème aux analystes de données en chaîne, rendant leur travail plus difficile.
Lorsque toutes les données seront cryptées et protégées, ils devront courir après les données. Ce sera comme une chasse aux données, rappelant les scènes de vieux films où quelqu’un demande à un autre : « Tu veux des données de transaction ? »
Les gens chercheront des données, et chaque découverte ressemblera à trouver quelque chose d’exploitable dans le désert. L’avenir sera donc une phase très intéressante, où la protection de la vie privée rendra les données moins accessibles, et où l’on en viendra peut-être à les échanger commercialement.
TechFlow : L’indisponibilité des traces causée par la confidentialité en chaîne contredit-elle l’idéologie de traçabilité inhérente à la blockchain ?
Misha : La situation est complexe quand il s’agit des applications de confidentialité et de leur émergence. Pour répondre à votre question, parfois oui, parfois non.
L’idée que tout doive être public et traçable n’est pas au cœur de la philosophie blockchain.
Je pense que l’industrie crypto découle de la cryptographie financière, dont l’objectif est d’éliminer les hypothèses de confiance, pas de rendre tout traçable et publiquement lisible. Il s’agit de réduire la confiance requise dans le code, et de surmonter ce problème. Dans cette évolution, les applications de confidentialité ne changent pas cet objectif fondamental.
Les hypothèses de confiance continueront d’être éliminées, mais la traçabilité, autrefois cruciale, pourrait bien s’avérer moins nécessaire à l’avenir. L’industrie crypto n’a pas été inventée pour la traçabilité ou l’ouverture, mais pour éliminer les hypothèses de confiance — c’est-à-dire atteindre un consensus sur quelque chose, même dans des conditions de confiance extrêmement strictes, grâce à des moyens cryptographiques.
Défis des applications zk
TechFlow : Quels sont les défis actuels des applications zk ? Combien de temps faudra-t-il, par exemple, pour atteindre un véritable anonymat en blockchain via les preuves zk ?
Misha : Cela prendra probablement 3 à 5 ans, car nous devons résoudre les problèmes de vulnérabilités. Plus précisément, l’efficacité de la technologie zk est aujourd’hui notre principal défi.
Tout calcul réalisé ainsi est plus lent que le calcul natif.
Cependant, réduire ce surcoût est une priorité absolue. Nous améliorons les compilateurs, tout en répondant aux besoins du marché, par exemple en proposant des solutions de gestion de données comparables à une version privée de Facebook, tout en maintenant une haute efficacité. L’efficacité est donc notre premier défi à relever.
Deuxièmement, il faut savoir gérer la demande croissante de confidentialité. À mesure que les problèmes liés au manque de confidentialité s’accumulent, la demande pour nos solutions augmentera, accélérant ainsi notre développement.
Actuellement, les gens subissent divers pièges à cause du manque de confidentialité. Plus ces problèmes seront nombreux, plus vite ce processus avancera.
Mais en raison de ce problème d’efficacité, le développement et l’utilisation de ces solutions restent difficiles, et certaines technologies sont encore expérimentales, enfermées en laboratoire. C’est donc un domaine hautement expérimental, nécessitant une grande prudence.
Feuille de route de Nil
TechFlow : Comment les défis actuels du zk se reflètent-ils dans la feuille de route de la fondation Nil ?
Misha : Je peux affirmer sans hésiter que, dans les prochaines années, Nil ne produira pas de solutions totalement privées et non traçables.
Nous voulons que la gestion des données dans cette industrie devienne appropriée. Ainsi, ceux qui ont besoin d’accéder et de traiter des données n’auront pas à utiliser des technologies complexes ni payer des frais exorbitants pour résoudre des problèmes mineurs.
Notre objectif est de la rendre moins chère, plus rapide et plus simple. C’est pourquoi nous aurons certainement un SGBD opérationnel. Nous serons excellents, sans hypothèse de confiance. Il sera sûrement sécurisé. Nous aspirons à devenir le choix le plus sûr de l’industrie.
Conclusion
Pendant notre conversation, Misha se trouvait à Chypre, où se situe également son entreprise. Quand je lui ai demandé « Ça va ? », il m’a répondu avec une grimace expressive et un haussement d’épaules : « Comme ça. » Très sincère et touchant !
Misha est l’un des fondateurs techniques les plus expressifs et intelligents que je connaisse. Drôle, direct, et vraiment sympathique. Je suis reconnaissant qu’il ait patiemment répondu à toutes mes questions, y compris celles qui semblaient naïves ou basiques.
Pour les lecteurs sans formation technique : si vous vous demandez ce qu’est un circuit en preuve à connaissance nulle, pourquoi un compilateur est nécessaire, quelle est la méthode traditionnelle de création de circuits sans compilateur, ou quels sont les cas d’usage concrets des preuves zk, consultez la lecture complémentaire ci-dessous.
Lecture complémentaire : notions de base sur les preuves à connaissance nulle
TechFlow : Comment fonctionne un compilateur de circuits ? Pourquoi en avons-nous besoin ?
Misha : Pour prouver un calcul particulier, un circuit est nécessaire. Différentes méthodes existent.
Certains créent manuellement leurs propres circuits pour différents types de zkEVM. Puis ils utilisent ces circuits dans leurs bases de données ou clusters (comme les roll-ups), en utilisant le zkEVM comme environnement d’exécution. De même, dans notre SGBD, nous avons besoin d’une couche d’exécution pour traiter les données — un peu comme dans MySQL, où il existe une couche d’exécution ou une machine virtuelle.
L’objectif est de prouver de manière transparente les calculs sur les données, réduire les hypothèses de confiance et éviter les boîtes noires. Pour cela, on peut construire un zkEVM supplémentaire, ou compiler le code pour obtenir le circuit requis. Cela permet de prouver les calculs sur ses propres données ou celles d’autrui.
Construire un zkEVM peut prendre plusieurs années, aboutissant à des circuits complexes, dont même Vitalik reconnaît les risques de sécurité.
Plutôt que de dépenser des sommes énormes pendant des années à auditer ou comprendre des circuits complexes, il est plus efficace de compiler le circuit directement à partir du code EVM original ou d’autres sources. Nous avons rencontré ce problème lors de la mise à jour de nos circuits de preuve d’état et de consensus : cela nous a pris environ un an. Une fois terminé, nous avons compris l’importance du compilateur, même si tout le monde n’en avait pas saisi toute la portée initialement. Pour éviter cela, nous avons créé ce compilateur.
Cette approche élimine les problèmes de sécurité et la complexité liée aux grands circuits.
TechFlow : Que signifie exactement « circuit » ?
Misha : Un circuit sert à définir le calcul à prouver. Chaque application spécifique nécessite son propre circuit. Dans le cas du zkEVM, on utilise généralement un seul circuit pour tous les calculs, ce qui est acceptable mais inefficace.
En outre, ces circuits sont souvent énormes et difficiles à comprendre, rendant la détection de failles de sécurité ou de vulnérabilités très ardue. Si un circuit utilisé par un roll-up populaire (comme Polygon, zkSync ou Starkware) contenait une faille exploitée, cela pourrait provoquer une catastrophe à l’échelle de toute l’industrie, vu l’ampleur des liquidités et dépendances concernées.
Pour réduire ce risque, notre site propose un compilateur capable de générer des circuits à partir de code lisible, compréhensible, portable et transparent. Cela garantit que les circuits ne reposent pas sur des constructions opaques impossibles à vérifier ou analyser.
De plus, différents services (ZKML, ZK Oracle, ZK Bridge, preuves de consensus ou d’état) nécessitent des circuits différents. Pour gagner en efficacité et éviter de créer manuellement un circuit unique pour tout, notre compilateur permet de générer des circuits spécialisés, adaptés à chaque service. Cela simplifie le processus et améliore l’efficacité des preuves.
En fournissant un compilateur générant des circuits à partir de code lisible et capable de créer des circuits spécialisés, nous visons à renforcer la transparence, prévenir les catastrophes industrielles et améliorer l’efficacité globale des calculs.
TechFlow : Comment fonctionnent les circuits ?
Misha : Fondamentalement, tous les circuits sont des représentations de programmes optimisées, produisant une disposition de polynômes sur un corps fini.
Par exemple, la représentation polynomiale simple du calcul « a + b » ressemble à « a + b = 0 », incluant données substituées et coefficients. Vous avez alors des variables, remplacées par des coefficients, et vous injectez les données correspondantes. Ce processus suit des méthodes d’optimisation classiques.
Quand le programme devient plus complexe, le nombre de circuits ou de polynômes augmente. L’ensemble représente le calcul via ces polynômes. Ainsi, un circuit ressemble essentiellement à un ensemble de polynômes effectuant diverses opérations sur un corps fini, selon le calcul à prouver.
Globalement, l’objectif est de compiler du code en circuit et de représenter le calcul comme un ensemble de polynômes, assurant transparence et réduction de la complexité.
TechFlow : Comment zkLLVM peut-il être utilisé dans un marché de GPU décentralisé ?
Misha : Sur ce sujet, certaines personnes utilisent le concept de calcul GPU distribué pour le machine learning. S’ils doivent prouver qu’un
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














