

“I Don’t Need a Better Model Anymore”: The Diverse AI Community on a Viral Reddit Post
TechFlow Selected TechFlow Selected
“I Don’t Need a Better Model Anymore”: The Diverse AI Community on a Viral Reddit Post
For a flagship product that emphasizes capability leaps, “the usability cost incurred for security” has become a core factor influencing users’ purchasing decisions.
Author: Friday, TechFlow
Anthropic has just delivered a seemingly flawless report card on paper.
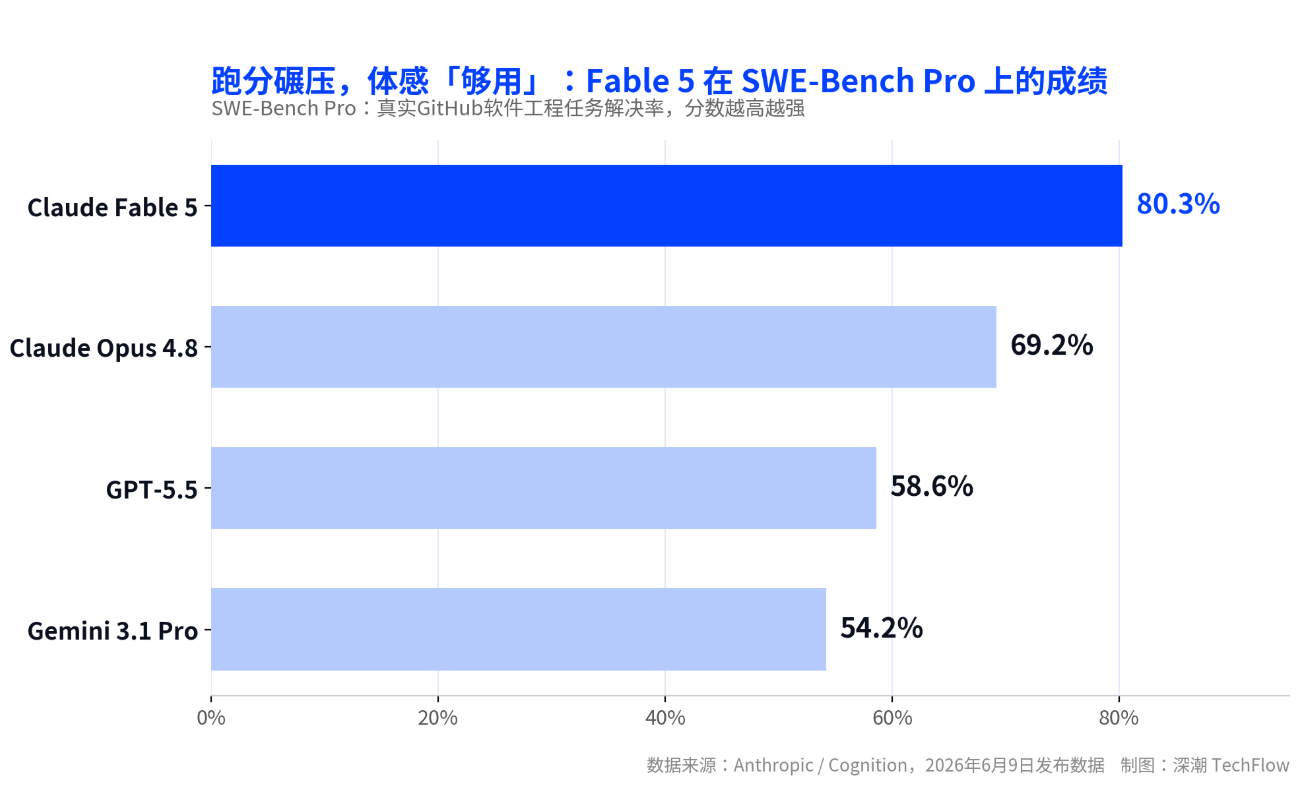
Claude Fable 5, released on June 9, is the company’s first publicly available Mythos-tier model. It achieved an 80.3% score on the real-world software engineering benchmark SWE-Bench Pro—roughly 11 percentage points ahead of its predecessor, Opus 4.8, and over 20 points ahead of GPT-5.5.
Yet user reaction poured cold water on the announcement.
Three days after launch, a top-voted post on Reddit’s r/artificial (with 305,000 weekly views) bore the title: “Claude Fable made me realize I don’t need a better model.” Poster Axi0m-22 reported using Fable for security research and daily tasks for a short time before switching almost immediately back to Opus for coding and Haiku for routine chores. He offered an analogy: “It’s like watching the iPhone 17 launch while still holding an iPhone 14—you know the new one is better, but you think, ‘Eh, mine works fine.’”
The “Good Enough” Camp Dominates Top Comments: Model Fatigue Becomes the Prevailing Sentiment
The top-rated comment, with 42 upvotes, reads: “Aside from a larger context window, I haven’t felt the need for a stronger model since Opus 4.5.”
Another user, hyprlab, earned 13 upvotes with this statement: “Switching to a model that burns tokens more aggressively doesn’t improve my workflow—I’m already comfortable with Opus 4.8’s high-intensity mode.”
Beneath such comments lies a shared cost calculus.
Fable 5’s API pricing stands at $10 per million input tokens—nearly double that of Opus 4.8. User siromega37 put it bluntly: “Higher token consumption, but no return on investment. I think we’re hitting a plateau—and the bubble will eventually burst.”
User hobopwnzor offered a more systematic interpretation: “We’ve been sitting atop the S-curve for a while now. Recent progress stems mainly from tool calling and peripheral engineering—not improvements in the model’s core capabilities.”
Safety Guardrails Emerge as the Biggest Pain Point: “90% of Use Cases Are Immediately Rejected”
If “good enough” reflects sentiment, complaints about safety guardrails represent concrete product issues.
According to Anthropic’s official documentation, Fable 5 shares the same underlying model as Mythos 5—a version accessible only to select institutions—but adds a safety classifier. Requests involving high-risk domains like cybersecurity are intercepted and routed to Opus 4.8 for handling. Anthropic states this mechanism is deliberately conservative, triggering in fewer than 5% of conversations and occasionally flagging harmless queries.
On this Reddit thread, however, users’ perceived trigger rate far exceeds 5%. User jradoff—whose comment garnered 17 upvotes—said he asked Fable to audit his code’s security, only to find that “it refuses to process anything mentioning security.” The request was then downgraded to Opus. Another comment, earning 12 upvotes, was even blunter: “90% of what you want to do gets rejected outright—it’s effectively useless.”
Paying customers voiced sharper frustration. Subscriber kaitava—who pays $200/month—wrote: “I’m paying double the token cost for a security review, only to get downgraded to Opus. Now I dislike everything about it—and I’m just waiting for OpenAI to catch up.”
For a flagship product marketed around capability leaps, “the usability cost paid for safety” is becoming the central factor determining whether users will pay up.
The Counterargument: Heavy-Task Users Report a “Night-and-Day” Difference
The hot post isn’t without dissent—and the opposing voices follow a clear pattern: the heavier the task, the higher the praise.
User Phylaras earned 15 upvotes: “Fable makes a tangible difference for me. On complex tasks demanding huge context windows, it caught errors previously missed.” One user, working on high-energy physics simulations, noted that individual simulation models often span 8,000–10,000 lines of code and involve interactions among hundreds of submodels—“having a model that can work independently, continuously, and grasp environmental details is incredibly valuable.”
The most forceful rebuttal came from user Navetz: “Honestly, anyone who’s actually used this model would consider this post delusional. To me, it’s strikingly smarter—like night and day. I’ve been using it nonstop. When explaining it to non-technical friends, I say it’s like going straight from a college player to an NBA starter.”
Others proposed pragmatic usage patterns. User ready-eddy suggested treating Fable as a “planner and fixer,” not a daily “builder”—unless budget isn’t a concern. Another comment summed it up like a user manual: “Using Fable for spreadsheet calculations is choosing the wrong model; running 16 agents simultaneously on Haiku is also choosing the wrong model. There’s no inherently bad model—only models misapplied to the wrong scenario.”
When Benchmarks and User Experience Diverge: Will Public AI Keep Getting Stronger?
The most intriguing comment in this debate shifts focus from product to industry structure.
User KedMcJenna proposed an “Open AI Freeze Hypothesis”: models accessible to ordinary users may permanently plateau near current levels, while enterprises and government elites continue receiving ever-stronger private models—“We know about Mythos at minimum, and there’s likely something even stronger we’ll never hear of.”
This comment points to a fact: Mythos 5 is indeed not open to the public and is currently available only to network defense agencies and critical infrastructure firms via Project Glasswing.
Viewing benchmarks alongside user sentiment yields a coherent picture—not contradictory, but complementary.
Benchmarks measure capability ceilings; Reddit’s top comments reflect everyday demand ceilings. When most users’ needs were already met by Opus 4.6, stronger models prove their worth only in extreme scenarios—physics simulation, ultra-long-context reasoning, and so on. For model vendors, the question is no longer “Can we build it?” but rather “Who needs it? Who’s willing to pay how much? And how much safety friction can they tolerate?”
Three days after launch, Fable 5 received two entirely different report cards—one on leaderboards, another in the court of public opinion. Which reflects reality more closely hinges on how quickly Anthropic tunes its safety classifier—and where heavy users ultimately allocate their dollars.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News













