

a16z’s 10,000-Word Essay: AI’s Next Frontier Lies Not in Language—but in the Physical World: A Triple Flywheel of Robotics, Autonomous Science, and Brain–Computer Interfaces
TechFlow Selected TechFlow Selected
a16z’s 10,000-Word Essay: AI’s Next Frontier Lies Not in Language—but in the Physical World: A Triple Flywheel of Robotics, Autonomous Science, and Brain–Computer Interfaces
What can truly deliver the next generation of disruptive capabilities are general-purpose robots, autonomous science (AI scientists), brain-computer interfaces, and other novel human-machine interfaces.
Author: Oliver Hsu (a16z)
Translation & Editing: TechFlow
TechFlow Intro: This article is by Oliver Hsu, a researcher at a16z, and represents the most systematic “Physical AI” investment map published since 2026. His thesis is that while the language/code axis continues to scale, the three adjacent domains most likely to yield the next generation of disruptive capabilities are: general-purpose robotics, autonomous science (“AI scientists”), and novel human–machine interfaces—including brain–computer interfaces (BCIs). He decomposes the five foundational capabilities underpinning these domains and argues that these three frontiers will form a mutually reinforcing structural flywheel. For anyone seeking clarity on the investment logic behind Physical AI, this is currently the most comprehensive framework.
The paradigm dominating AI today is organized around language and code. The scaling laws governing large language models (LLMs) are now well understood; the commercial flywheel—driven by data, compute, and algorithmic improvements—is actively spinning; and each new capability tier still delivers substantial, highly visible returns. This paradigm fully merits the capital and attention it has absorbed.
Yet another cohort of adjacent domains—already in gestation—is making tangible progress. These include visual–language–action (VLA) models and world-action models (WAMs), representing general-purpose robotics pathways; physical and scientific reasoning centered on the “AI scientist”; and novel human–machine interfaces—including BCIs and neurotechnology—that leverage advances in AI to reshape interaction. Beyond the technology itself, all these directions are beginning to attract talent, capital, and founders. The foundational technical primitives enabling the extension of cutting-edge AI into the physical world are maturing in parallel; progress over the past 18 months signals that these fields are poised to enter their respective scaling phases.
In any technological paradigm, the areas where the delta between current capability and mid-term potential is largest tend to share two features: first, they can capture the same scaling dividends driving the current frontier; second, they sit just one step removed from the mainstream paradigm—close enough to inherit its infrastructure and research momentum, yet distant enough to require real, additional work. That distance itself serves a dual purpose: it naturally forms a moat against fast followers, while also defining a sparser, less crowded problem space—where genuinely novel capabilities are more likely to emerge precisely because shortcuts remain unexplored.

Caption: Schematic illustrating the relationship between today’s dominant AI paradigm (language/code) and adjacent frontier systems
Three domains currently meet this description: robotic learning; autonomous science—especially in materials and life sciences; and novel human–machine interfaces—including BCIs, silent speech, neural wearables, and new sensory modalities like digital olfaction. These are not wholly independent endeavors; thematically, they belong to the same cluster of “frontier systems operating in the physical world.” They share a common set of foundational primitives: learned representations of physical dynamics; architectures designed for embodied action; simulation and synthetic-data infrastructure; expanding sensory channels; and closed-loop agent orchestration. They reinforce one another through cross-domain feedback. And they represent the most fertile ground for emergent, qualitative leaps in capability—the product of interplay among model scale, physical deployment, and novel data modalities.
This article outlines these supporting technical primitives, explains why these three domains constitute the frontier opportunity, and proposes that their mutual reinforcement forms a structural flywheel propelling AI into the physical world.
The Five Foundational Primitives
Before examining specific applications, it’s essential to understand the shared technical foundation underlying these frontier systems. Advancing cutting-edge AI into the physical world rests on five primary primitives. These technologies are not exclusive to any single application domain—they are building blocks, enabling systems that extend AI into the physical world. Their synchronous maturation is what makes this moment uniquely significant.

Caption: The five foundational primitives enabling Physical AI
Primitive One: Learned Representations of Physical Dynamics
The most fundamental primitive is a compact, generalizable representation of physical-world behavior—how objects move, deform, collide, and respond to forces. Without such a layer, every physical AI system would need to learn the physics of its domain from scratch—a cost no one can bear.
Several architectural schools are converging on this goal from different angles. VLA models approach from the top down: they take pre-trained visual–language models—which already possess semantic understanding of objects, spatial relationships, and language—and add an action decoder to output motion control commands. Crucially, the massive cost of learning “to see” and “understand the world” can be amortized across internet-scale image–text pretraining. Physical Intelligence’s π₀, Google DeepMind’s Gemini Robotics, and NVIDIA’s GR00T N1 have all validated this architecture at increasingly large scales.
WAM models approach from the bottom up: they build upon video diffusion Transformers pre-trained on internet-scale video, inheriting rich priors about physical dynamics—how objects fall, become occluded, or interact under force—and then couple those priors with action generation. NVIDIA’s DreamZero demonstrated zero-shot generalization to entirely new tasks and environments, achieving cross-embodiment transfer from human video demonstrations using only minimal adaptation data—yielding meaningful gains in real-world generalization.
A third path may offer the greatest insight into future direction: it skips both pre-trained VLMs and video diffusion backbones entirely. Generalist’s GEN-1 is a natively embodied foundation model trained from scratch on over 500,000 hours of real-world physical interaction data—collected primarily via low-cost wearable devices worn by humans performing everyday manipulation tasks. It is neither a standard VLA (no visual–language backbone is fine-tuned) nor a WAM. It is a foundation model purpose-built for physical interaction, learning—not the statistical regularities of internet images, text, or video—but the statistical regularities of human contact with objects.
Spatial intelligence efforts—such as those by World Labs—add value to this primitive by addressing a shared shortcoming across VLAs, WAMs, and native embodied models: none explicitly model the 3D structure of their environment. VLAs inherit 2D visual features from image–text pretraining; WAMs learn dynamics from video, which is inherently a 2D projection of 3D reality; models trained on wearable sensor data capture force and kinematics but not scene geometry. Spatial intelligence models fill this gap—learning to reconstruct, generate, and reason about the full 3D structure of physical environments: geometry, lighting, occlusion, object relationships, and spatial layout.
The convergence across these paths is itself noteworthy. Whether the representation is inherited from a VLM, co-trained from video, or built natively from physical interaction data, the underlying primitive is identical: a compressed, transferable model of physical-world behavior. The data flywheel powering these representations is vast—and largely untapped—not only internet video and robot trajectories, but also the massive corpus of human bodily experience now being scaled via wearables. The same representation can serve a robot learning to fold towels, an autonomous lab predicting reaction outcomes, and a neural decoder interpreting grasp intent from motor cortex activity.
Primitive Two: Architectures Designed for Embodied Action
Learning physical representations alone is insufficient. Translating “understanding” into reliable physical action requires architectures that solve several interrelated problems: mapping high-level intent to continuous motion commands; maintaining consistency over long action sequences; operating within real-time latency constraints; and improving continuously with experience.
The two-system hierarchical architecture has become the standard design for complex embodied tasks: a slow, powerful visual–language model handles scene understanding and task reasoning (System 2), paired with a fast, lightweight visual–motor policy for real-time control (System 1). GR00T N1, Gemini Robotics, and Figure’s Helix all adopt variants of this approach, resolving the fundamental tension between “large models delivering rich reasoning” and “physical tasks demanding millisecond-level control frequencies.” Generalist pursues an alternative path—“resonant reasoning”—in which thinking and action occur simultaneously.
Action-generation mechanisms themselves are evolving rapidly. π₀’s flow-matching and diffusion-based action heads have become the mainstream method for generating smooth, high-frequency continuous actions—replacing discrete tokenization borrowed from language modeling. These methods treat action generation as a denoising process akin to image synthesis, yielding physically smoother trajectories and greater robustness to error accumulation than autoregressive token prediction.
Yet the most consequential architectural advance may be extending reinforcement learning (RL) to pre-trained VLAs—a foundation model trained on demonstration data can continue improving through autonomous practice, much like humans refine skills through repetition and self-correction. Physical Intelligence’s π*₀.₆ work offers the clearest large-scale demonstration of this principle. Their method, RECAP (Reinforcement Learning with Advantage-Conditioned Policies), solves the long-sequence credit assignment problem that pure imitation learning cannot handle. If a robot grasps an espresso machine handle at a slightly skewed angle, failure may not manifest immediately—it might only appear several steps later, during insertion. Imitation learning lacks a mechanism to attribute that failure to the earlier grasp; RL does. RECAP trains a value function estimating the probability of success from any intermediate state, then guides the VLA toward high-advantage actions. Critically, it integrates heterogeneous data—demonstrations, on-policy autonomous experience, and expert teleoperation corrections—into a single training pipeline.
The results of this method are encouraging for RL’s prospects in action domains. π*₀.₆ folds 50 previously unseen clothing items reliably in real home environments, assembles cardboard boxes robustly, and brews espresso on professional machines—all running continuously for hours without human intervention. On the hardest tasks, RECAP more than doubles throughput and cuts failure rates by over half compared to pure imitation baselines. The system also demonstrates qualitative behavioral shifts inaccessible to imitation learning: smoother recovery motions, more efficient grasping strategies, and adaptive error correction absent from the demonstration data.
These gains signal one thing: the compute-scaling engine that propelled models from GPT-2 to GPT-4 is now beginning to operate in the embodied domain—albeit at an earlier point on the curve, where the action space is continuous, high-dimensional, and constrained by the unforgiving realities of the physical world.
Primitive Three: Simulation and Synthetic Data as Scaling Infrastructure
In the language domain, the data problem was solved by the internet: trillions of tokens of naturally occurring, freely available text. In the physical world, the problem is orders of magnitude harder—a consensus now widely accepted, evidenced most directly by the rapid proliferation of startups focused on physical-world data supply. Collecting real-world robot trajectories is costly, risky to scale, and limited in diversity. A language model can learn from a billion dialogues; a robot (for now) cannot execute a billion physical interactions.
Simulation and synthetic-data generation constitute the infrastructure layer solving this constraint—and their maturation is one key reason why Physical AI is accelerating now rather than five years ago.
Modern simulation stacks integrate physics-based simulation engines, ray-traced photorealistic rendering, procedurally generated environments, and world foundation models that generate photorealistic video from simulation inputs—the latter bridging the sim-to-real gap. The entire pipeline begins with neural reconstruction of real environments (achievable with just a smartphone), populates physically accurate 3D assets, and culminates in large-scale synthetic-data generation with automatic annotation.
The significance of simulation-stack improvements lies in how they shift the economic assumptions underpinning Physical AI. If the bottleneck shifts from “collecting real-world data” to “designing diverse virtual environments,” the cost curve collapses. Simulation scales with compute—not human labor or physical hardware. Its impact on the economics of training Physical AI systems mirrors the internet’s impact on language-model training—meaning investment in simulation infrastructure yields enormous ecosystem-wide leverage.
But simulation is not merely a robotics primitive. The same infrastructure serves autonomous science (digital twins of lab equipment, simulated reaction environments for hypothesis pre-screening), novel interfaces (simulated neural environments for training BCI decoders, synthetic sensory data for calibrating new sensors), and other domains where AI interacts with the physical world. Simulation is the universal data engine for Physical AI.
Primitive Four: Expanding Sensory Channels
The signals conveying information in the physical world far exceed vision and language in richness. Touch conveys material properties, grasp stability, and contact geometry—information invisible to cameras. Neural signals encode movement intent, cognitive states, and perceptual experiences at bandwidths vastly exceeding any existing human–machine interface. Subvocal muscle activity encodes speech intent before any sound is produced. The fourth primitive is AI’s rapid expansion into these previously inaccessible sensory modalities—not only through research, but also via an entire ecosystem building consumer-grade devices, software, and infrastructure.
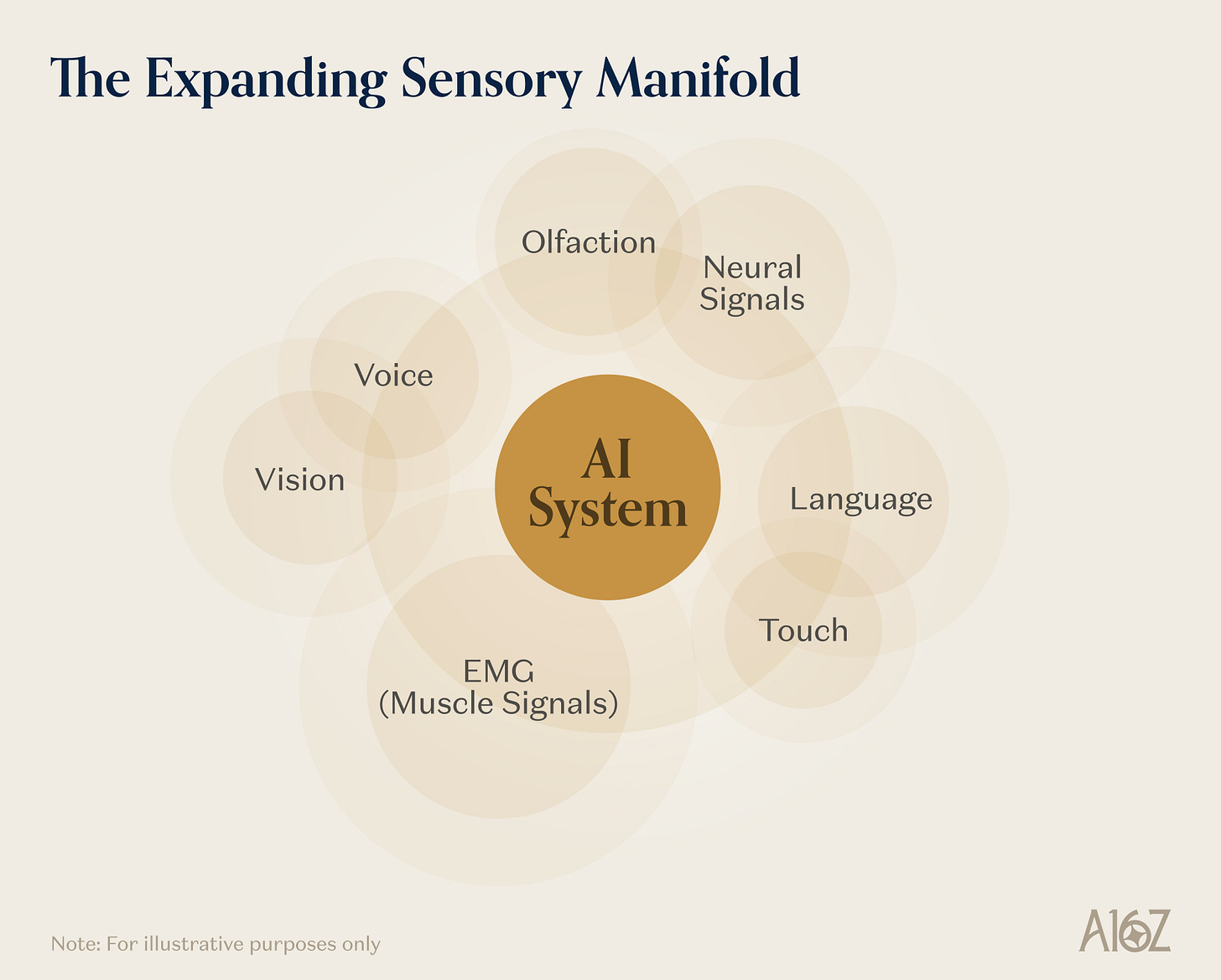
Caption: Expanding AI sensory channels—from AR and EMG to brain–computer interfaces
The most direct indicator is the emergence of new device categories. AR devices have seen dramatic improvements in experience and form factor in recent years (with companies already deploying consumer and industrial applications on this platform); voice-first AI wearables grant language-based AI richer physical-world context—they truly accompany users into physical environments. Long term, neural interfaces may unlock even more complete interaction modalities. The computational shift enabled by AI creates unprecedented opportunities to upgrade human–machine interaction, with companies like Sesame building new modalities and devices for this purpose.
Even more mainstream modalities like voice provide tailwinds for emerging interfaces. Products like Wispr Flow push voice to the forefront as the primary input modality (due to its high information density and inherent advantages), thereby improving market conditions for silent-speech interfaces. Silent-speech devices use multiple sensors to capture tongue and vocal cord movements for speech recognition without sound—an interaction modality with higher information density than audible speech.
Brain–computer interfaces (both invasive and non-invasive) represent a deeper frontier, with their commercial ecosystem advancing steadily. Signals converge at the intersection of clinical validation, regulatory approval, platform integration, and institutional capital—a domain that was purely academic just a few years ago.
Haptic perception is entering embodied AI architectures, with some robot-learning models explicitly incorporating touch as a first-class citizen. Olfactory interfaces are becoming real engineering products: wearable olfactory displays using miniature scent emitters with millisecond response times have already been demonstrated in mixed-reality applications; olfactory models are beginning to pair with visual AI systems for chemical-process monitoring.
A common pattern emerges across these developments: they converge at the limits. AR glasses continuously generate first-person visual and spatial data on user–environment interaction; EMG wristbands capture statistical patterns of human movement intent; silent-speech interfaces capture the mapping from subvocal articulation to linguistic output; BCIs capture neural activity at the highest resolution currently possible; tactile sensors capture contact dynamics of physical manipulation. Each new device category is simultaneously a data-generation platform feeding models across multiple application domains. A robot trained on EMG-inferred movement-intent data learns different grasping strategies than one trained solely on teleoperation data; a lab interface responding to subvocal commands enables a scientist–machine interaction fundamentally distinct from keyboard-controlled labs; a neural decoder trained on high-density BCI data produces motor-planning representations unavailable through any other channel.
The proliferation of these devices is expanding the effective dimensionality of data manifolds available for training frontier Physical AI systems—and much of this expansion is driven by well-capitalized consumer-device companies, not just academic labs, meaning the data flywheel scales with market adoption.
Primitive Five: Closed-Loop Agent Systems
The final primitive is more architectural in nature. It refers to integrating perception, reasoning, and action into a sustained, autonomous, closed-loop system capable of operating unattended over extended timeframes.
In language models, the analogous development is the rise of agent systems—multi-step reasoning chains, tool use, self-correction workflows—transforming models from single-turn Q&A tools into autonomous problem solvers. In the physical world, the same transformation is underway—but under far more stringent requirements. A language agent can revert at zero cost upon error; a physical agent that knocks over a reagent bottle cannot.
Physical-world agent systems possess three characteristics distinguishing them from their digital counterparts. First, they must embed experimental or operational closed loops—directly interfacing with raw instrument data streams, physical-state sensors, and actuation primitives—so reasoning lands in physical reality, not just textual descriptions thereof. Second, they require long-sequence persistence: memory, traceability, safety monitoring, and recovery behaviors that link multiple operational cycles, rather than treating each task as an isolated episode. Third, they demand closed-loop adaptation: revising strategies based on physical outcomes—not just textual feedback.
This primitive integrates individual capabilities—robust world models, reliable action architectures, rich sensor suites—into complete systems capable of autonomous operation in the physical world. It is the integration layer; its maturity is the prerequisite for the three application domains discussed below to exist as real-world deployments—not isolated research demos.
The Three Domains
The primitives above constitute generic enablers—they do not specify where the most important applications will emerge. Many domains involve physical action, measurement, or perception. What distinguishes “frontier systems” from “merely improved versions of existing systems” is the degree to which model-capability improvements and scaling infrastructure compound—producing not just better performance, but previously impossible new capabilities.
Robotics, AI-driven science, and novel human–machine interfaces are the three domains exhibiting the strongest compounding effects. Each assembles primitives in a unique way; each is currently bottlenecked by constraints that these primitives are now lifting; and each generates, as a byproduct of operation, structured physical data that feeds back to improve the primitives themselves—creating feedback loops that accelerate the entire system. They are not the only Physical AI domains worth watching, but they represent the densest intersections of frontier AI capability and physical reality—and the greatest distance from the current language/code paradigm, thus offering the largest space for new-capability emergence—while remaining highly complementary and able to capture its dividends.
Robotics
Robotics is the most literal embodiment of Physical AI: an AI system must perceive, reason, and exert physical action on the material world in real time. It also stress-tests every primitive.
Consider what a general-purpose robot must do to fold a towel. It needs a learned representation of how deformable materials behave under force—a physical prior not provided by language pretraining. It needs an action architecture translating high-level instructions into continuous motion command sequences at control frequencies exceeding 20 Hz. It needs simulation-generated training data, as no one has collected millions of real towel-folding demonstrations. It needs tactile feedback to detect slippage and adjust grip force, since vision cannot distinguish a stable grasp from one failing in real time. It also needs a closed-loop controller to recognize errors during folding and recover—not blindly execute memorized trajectories.
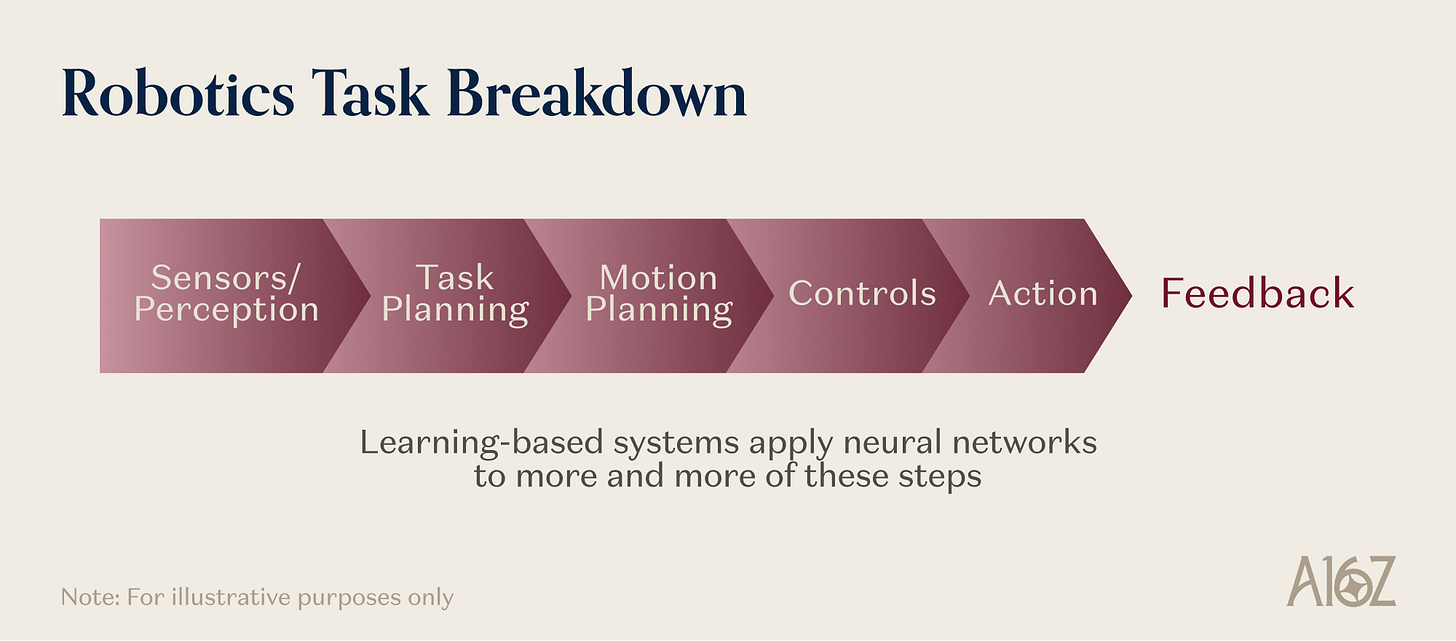
Caption: Simultaneous invocation of the five foundational primitives in a robotics task
This is why robotics is a frontier system—not merely a mature engineering discipline with better tools. These primitives do not merely enhance existing robot capabilities; they unlock entirely new categories of operation, motion, and interaction previously impossible outside narrow, controlled industrial settings.
Frontier progress over the past few years has been significant—we’ve written about it previously. First-generation VLAs proved foundation models could control robots across diverse tasks. Architectural advances are bridging high-level reasoning and low-level control in robot systems. On-device inference is becoming feasible; cross-embodiment transfer means a model can adapt to a completely new robot platform with limited data. The remaining core challenge is scalable reliability, still the deployment bottleneck. A 95% per-step success rate yields only ~60% success over a 10-step task chain—far below production requirements. RL post-training holds great promise here, helping the field cross the threshold of capability and robustness needed to enter the scaling phase.
These advances impact market structure. For decades, robotics value has resided in mechanical systems—mechanics remain a critical part of the stack—but as learning policies become standardized, value migrates toward models, training infrastructure, and data flywheels. Robotics also feeds back into the above primitives: every real-world trajectory improves world-model training data; every deployment failure exposes gaps in simulation coverage; testing on each new embodiment expands the diversity of physical experience available for pretraining. Robotics is both the most demanding consumer of these primitives and one of their most important sources of improvement signals.
Autonomous Science
If robotics tests primitives via “real-time physical action,” autonomous science tests something subtly different: sustained, multi-step reasoning about causally complex physical systems over hour- or day-long timescales, requiring interpretation and contextualization of experimental results to revise strategies.
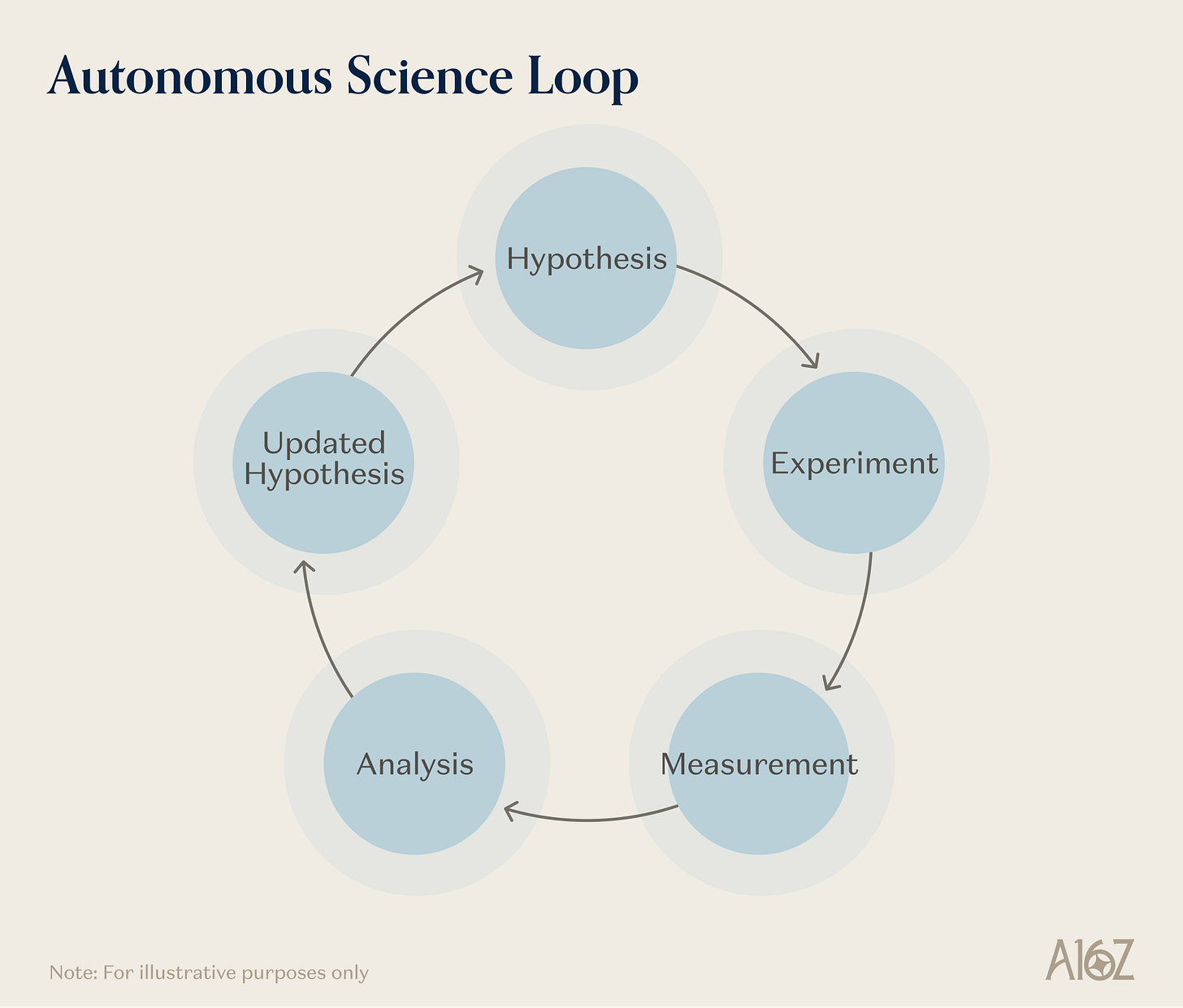
Caption: How autonomous science (“AI scientist”) integrates the five foundational primitives
AI-driven science is the most thorough combination of primitives. A self-driving lab (SDL) requires learned physical–chemical dynamics representations to predict experimental outcomes; embodied action to pipette, position samples, and operate analytical instruments; simulation for candidate-experiment pre-screening and scarce-instrument time allocation; and expanded sensing—spectroscopy, chromatography, mass spectrometry, and increasingly novel chemical and biological sensors—to characterize results. It demands the closed-loop agent orchestration primitive more than any other domain: sustaining multi-round “hypothesis–experiment–analysis–revision” workflows unattended, preserving traceability, monitoring safety, and adapting strategy based on insights revealed in each round.
No other domain calls upon these primitives so deeply. This is why autonomous science is a frontier “system”—not merely better software for lab automation. Companies like Periodic Labs and Medra, operating in materials and life sciences respectively, synthesize scientific reasoning with physical validation to enable scientific iteration—and produce experimental training data along the way.
The value of such systems is intuitively clear. Traditional materials discovery takes years from concept to commercialization; AI-accelerated workflows theoretically compress this dramatically. The key constraint is shifting from hypothesis generation—where foundation models already assist well—to fabrication and validation—requiring physical instruments, robotic execution, and closed-loop optimization. SDLs target precisely this bottleneck.
Another crucial characteristic of autonomous science—true across all physical-world systems—is its role as a data engine. Every experiment run by an SDL yields not just a scientific result, but a physically grounded, experimentally verified training signal. A measurement of how a polymer crystallizes under specific conditions enriches the world model’s understanding of material dynamics; a validated synthesis pathway becomes training data for physical reasoning; a characterized failure tells the agent system where its predictions break down. Data produced by an AI scientist conducting real experiments differs fundamentally from internet text or simulation outputs—it is structured, causal, and empirically verified. This is precisely the kind of data physical-reasoning models most need—and the only source capable of providing it. Autonomous science is the direct conduit transforming physical reality into structured knowledge, improving the entire Physical AI ecosystem.
Novel Interfaces
Robotics extends AI into physical action; autonomous science extends it into physical research. Novel interfaces extend it into direct coupling between artificial intelligence and human perception, sensory experience, and physiological signals—spanning AR glasses, EMG wristbands, and implantable BCIs. What binds this category together is not a single technology, but a shared function: expanding the bandwidth and modalities of the channel between human intelligence and AI systems—and, in doing so, generating human–world interaction data directly usable for building Physical AI.

Caption: The spectrum of novel interfaces—from AR glasses to brain–computer interfaces
Their distance from the mainstream paradigm is both the challenge and the opportunity. Language models conceptually know these modalities but are not natively familiar with the motor patterns of silent speech, the geometric structure of olfactory receptor binding, or the temporal dynamics of EMG signals. Representations decoding these signals must be learned from the expanding sensory channels themselves. Many modalities lack internet-scale pretraining corpora; data often originates solely from the interfaces—meaning systems and their training data co-evolve, a phenomenon with no counterpart in language AI.
The domain’s recent performance is the rapid rise of AI wearables as a consumer category. AR glasses are perhaps the most visible example, while other voice- or vision-first wearables are emerging in parallel.
This consumer-device ecosystem provides both a new hardware platform for AI’s extension into the physical world and an infrastructure for physical-world data. A person wearing AI glasses continuously generates first-person video streams documenting how humans navigate, manipulate objects, and interact with the physical world; other wearables continuously capture biometric and motion data. AI-wearable installed base is becoming a distributed physical-world data collection network, recording human physical experience at an unprecedented scale. Consider the scale of smartphones as consumer devices—a new category of consumer device at comparable scale allows computers to perceive the world in novel modalities, opening a massive new channel for AI–physical-world interaction.
Brain–computer interfaces represent a deeper frontier. Neuralink has implanted multiple patients, with surgical robots and decoding software iterating rapidly. Synchron’s intravascular Stentrode has enabled paralyzed users to control digital and physical environments. Echo Neurotechnologies is developing a BCI system for language restoration, building on high-resolution cortical speech decoding research. New companies like Nudge are forming to gather talent and capital for next-generation neural interfaces and brain–interaction platforms. Research milestones are also notable: the BISC chip demonstrated wireless neural recording from 65,536 electrodes on a single chip; the BrainGate team decoded internal language directly from motor cortex activity.
The unifying thread across AR glasses, AI wearables, silent-speech devices, and implantable BCIs is not merely “they are all interfaces,” but that they collectively constitute a spectrum of increasing bandwidth between human physical experience and AI systems—each point on the spectrum supporting ongoing progress in the primitives underpinning the three domains discussed herein. A robot trained on high-quality first-person video from millions of AI-glasses users learns manipulation priors radically different from those trained on curated teleoperation datasets; a lab AI responding to subvocal commands operates with latency and fluency utterly distinct from keyboard-controlled labs; a neural decoder trained on high-density BCI data produces motor-planning representations inaccessible through any other channel.
Novel interfaces are the mechanism that expands the sensory channels themselves—they open data channels between the physical world and AI that previously did not exist. And this expansion is driven by consumer-device companies pursuing scalable deployment, meaning the data flywheel accelerates alongside consumer adoption.
Systems in the Physical World
Viewing robotics, autonomous science, and novel interfaces as distinct instances of the same set of primitives reveals why they mutually enable one another—and compound.
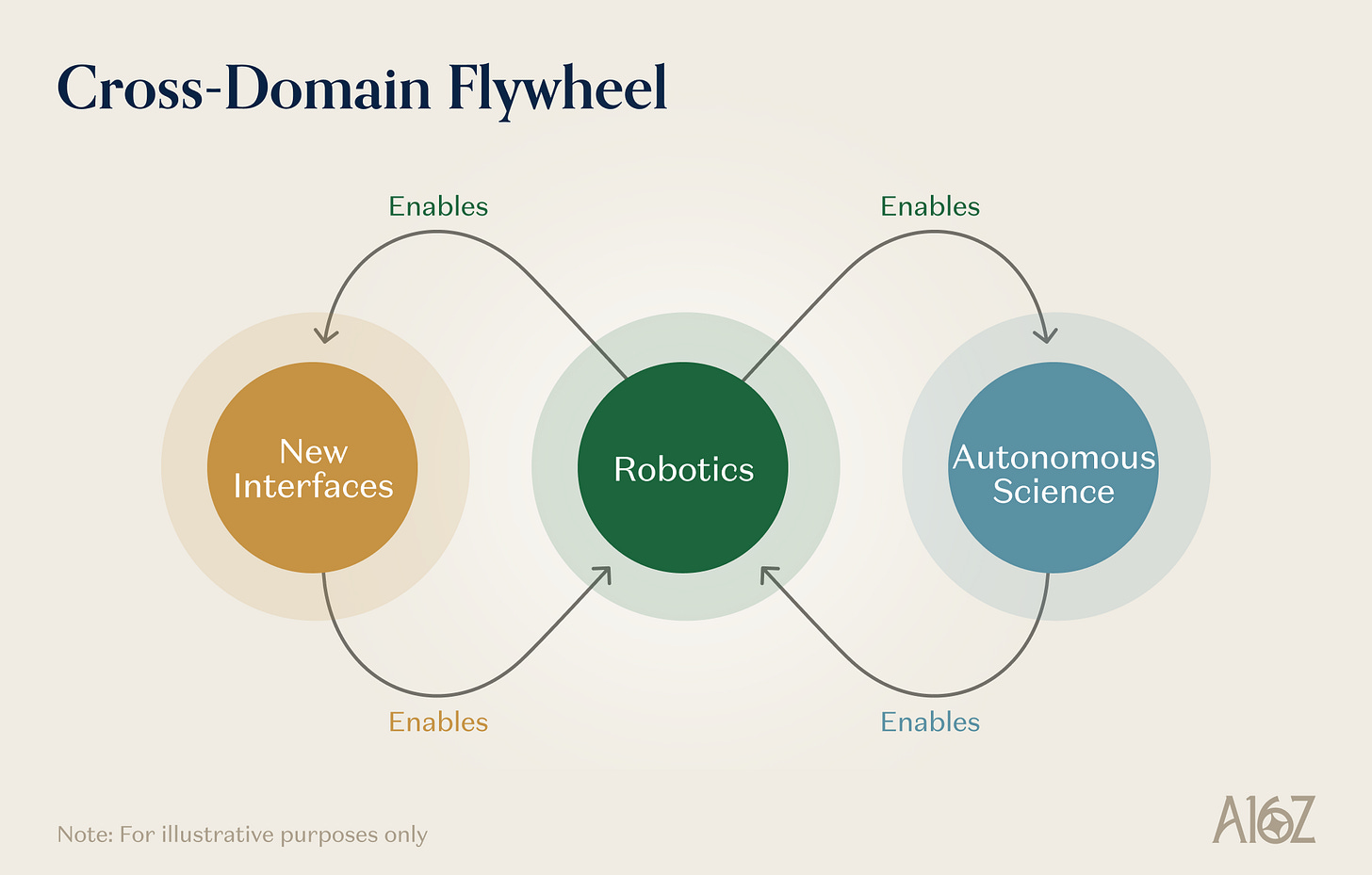
Caption: The mutual feedback flywheel among robotics, autonomous science, and novel interfaces
Robotics enables autonomous science. Self-driving labs are, at their core, robot systems. Operational capabilities developed for general-purpose robotics—dexterous grasping, liquid handling, precise positioning, multi-step task execution—transfer directly to lab automation. Every advance in robot generality and robustness expands the range of experimental protocols an SDL can autonomously execute. Every advance in robot learning lowers the cost and raises the throughput of autonomous experimentation.
Autonomous science enables robotics. Scientific data produced by self-driving labs—validated physical measurements, causal experimental results, materials property databases—provides the world models and physical-reasoning engines with precisely the kind of structured, grounded training data they most need. Further, the next-generation materials and devices required by robotics—better actuators, more sensitive tactile sensors, higher-density batteries—are themselves products of materials science. Autonomous discovery platforms accelerating materials innovation directly improve the hardware substrate on which robot learning operates.
Novel interfaces enable robotics. AR devices provide a scalable way to collect data on “how humans perceive and interact with the physical environment.” Neural interfaces generate data on human movement intent, cognitive planning, and sensory processing. This data is invaluable for training robot-learning systems—especially for human–robot collaboration or teleoperation tasks.
There is a deeper observation about the nature of frontier AI progress itself. The language/code paradigm has yielded extraordinary results and remains strongly ascendant in the scaling era. Yet the physical world offers nearly infinite new problems, new data types, new feedback signals, and new evaluation criteria. Grounding AI systems in physical reality—through robots manipulating objects, labs synthesizing materials, and interfaces connecting to biology and physics—opens new scaling axes complementary to the existing digital frontier—and likely mutually improving.
Caption: Interaction and emergence across Physical AI scaling axes
Predicting exactly what behaviors will emerge from these systems is difficult—the definition of emergence is interaction among independently understandable, yet collectively unprecedented, capabilities. But historical patterns are optimistic. Each time AI systems gain a new modality for interacting with the world—seeing (computer vision), speaking (speech recognition), reading/writing (language models)—the resulting capability leap has far exceeded the sum of individual improvements. Transitioning to physical-world systems represents the next such phase transition. In this sense, the primitives discussed herein are being constructed right now—potentially enabling frontier AI systems to perceive, reason about, and act upon the physical world, unlocking immense value and progress.
Disclaimer: This article is for informational purposes only and does not constitute investment advice. It should not be used as a basis for legal, business, investment, or tax advice.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














