
Jensen Huang's CES2026 Latest Speech: Three Key Topics, One "Chip Monster"
TechFlow Selected TechFlow Selected
Jensen Huang's CES2026 Latest Speech: Three Key Topics, One "Chip Monster"
When physical AI requires continuous thinking, long-term operation, and truly enters the real world, the issue is no longer just about whether computational power is sufficient, but about who can actually build the entire system.
Authors: Li Hailun, Su Yang
On January 6th Beijing time, NVIDIA CEO Jensen Huang once again stood on the main stage of CES 2026, clad in his iconic leather jacket.
At CES 2025, NVIDIA showcased the mass-produced Blackwell chip and a comprehensive physical AI technology stack. During the event, Huang emphasized that an "era of physical AI" was dawning. He painted a visionary future: autonomous vehicles with reasoning capabilities, robots that can understand and think, and AI agents capable of handling long-context tasks involving millions of tokens.
A year has passed in the blink of an eye, and the AI industry has undergone significant transformation and evolution. When reviewing the changes of the past year at the launch event, Huang specifically highlighted open-source models.
He stated that open-source reasoning models like DeepSeek R1 have made the entire industry realize that when true openness and global collaboration take off, the diffusion speed of AI becomes extremely rapid. Although open-source models still lag behind the most cutting-edge models by about six months in overall capability, they close the gap every six months, and their downloads and usage have already experienced explosive growth.

Compared to 2025, which focused more on showcasing visions and possibilities, this time NVIDIA began systematically addressing the question of "how to achieve it": focusing on reasoning AI, it aims to complete the computational power, networking, and storage infrastructure required for long-term operation, significantly reduce inference costs, and directly embed these capabilities into real-world scenarios like autonomous driving and robotics.
Jensen Huang's speech at this CES revolved around three main themes:
● At the system and infrastructure level, NVIDIA has redesigned its computational power, networking, and storage architecture around long-term inference needs. Centered on the Rubin platform, NVLink 6, Spectrum-X Ethernet, and the inference context memory storage platform, these updates directly target bottlenecks such as high inference costs, difficulty in sustaining context, and limitations in scaling, solving the problems of enabling AI to "think a bit longer," be affordable to compute, and run for extended periods.
● At the model level, NVIDIA places reasoning/agentic AI at its core. Through models and tools like Alpamayo, Nemotron, and Cosmos Reason, it aims to propel AI from "generating content" towards being capable of continuous thinking, shifting from "one-time response models" to "agents that can work long-term."
● At the application and implementation level, these capabilities are being directly introduced into physical AI scenarios like autonomous driving and robotics. Whether it's the Alpamayo-powered autonomous driving system or the GR00T and Jetson robotics ecosystem, both are promoting large-scale deployment through partnerships with cloud providers and enterprise platforms.

01 From Roadmap to Mass Production: Rubin's First Full Performance Data Disclosure
At this CES, NVIDIA for the first time fully disclosed the technical details of the Rubin architecture.
In his speech, Huang began by laying the groundwork with the concept of Test-time Scaling. This concept can be understood as: to make AI smarter, it's no longer just about making it "study harder," but rather about letting it "think a bit longer when encountering a problem."
In the past, improving AI capabilities mainly relied on pouring more computational power into the training phase, making models larger and larger. Now, the new change is that even if a model stops growing in size, giving it a bit more time and computational power to think during each use can also significantly improve results.
How to make "AI thinking a bit longer" economically viable? The new-generation AI computing platform based on the Rubin architecture is designed to solve this problem.
Huang introduced that this is a complete next-generation AI computing system, achieving a revolutionary reduction in inference costs through the co-design of Vera CPU, Rubin GPU, NVLink 6, ConnectX-9, BlueField-4, and Spectrum-6.

The NVIDIA Rubin GPU is the core chip responsible for AI computing within the Rubin architecture, aiming to significantly reduce the unit cost of inference and training.
Simply put, the core mission of the Rubin GPU is to "make AI cheaper and smarter to use."
The core capability of the Rubin GPU lies in: a single GPU can handle more work. It can process more inference tasks at once, remember longer contexts, and communicate faster with other GPUs. This means many scenarios that previously required "stacking multiple cards" can now be accomplished with fewer GPUs.
The result is that inference is not only faster but also significantly cheaper.
On stage, Huang reviewed the hardware parameters of the Rubin architecture's NVL72: containing 220 trillion transistors, with a bandwidth of 260 TB/s, it is the industry's first platform supporting rack-scale confidential computing.

Overall, compared to Blackwell, the Rubin GPU achieves a generational leap in key metrics: NVFP4 inference performance increases to 50 PFLOPS (5x), training performance to 35 PFLOPS (3.5x), HBM4 memory bandwidth to 22 TB/s (2.8x), and single GPU NVLink interconnect bandwidth doubles to 3.6 TB/s.
These improvements work together to enable a single GPU to handle more inference tasks and longer contexts, fundamentally reducing reliance on the number of GPUs.

The Vera CPU is a core component designed for data movement and agentic processing, featuring 88 NVIDIA-designed Olympus cores, equipped with 1.5 TB of system memory (3 times that of the previous Grace CPU), and achieving coherent memory access between CPU and GPU through 1.8 TB/s NVLink-C2C technology.
Unlike traditional general-purpose CPUs, Vera focuses on data scheduling and multi-step reasoning logic processing in AI inference scenarios, essentially acting as the system coordinator that enables "AI thinking a bit longer" to run efficiently.
NVLink 6, with its 3.6 TB/s bandwidth and in-network computing capability, allows the 72 GPUs within the Rubin architecture to work together like a super GPU. This is the key infrastructure for achieving reduced inference costs.
This way, the data and intermediate results needed by AI during inference can flow rapidly between GPUs without repeated waiting, copying, or recomputation.


Within the Rubin architecture, NVLink-6 handles internal GPU collaborative computing, BlueField-4 manages context and data scheduling, while ConnectX-9 undertakes the system's high-speed external network connectivity. It ensures the Rubin system can communicate efficiently with other racks, data centers, and cloud platforms, a prerequisite for the smooth operation of large-scale training and inference tasks.
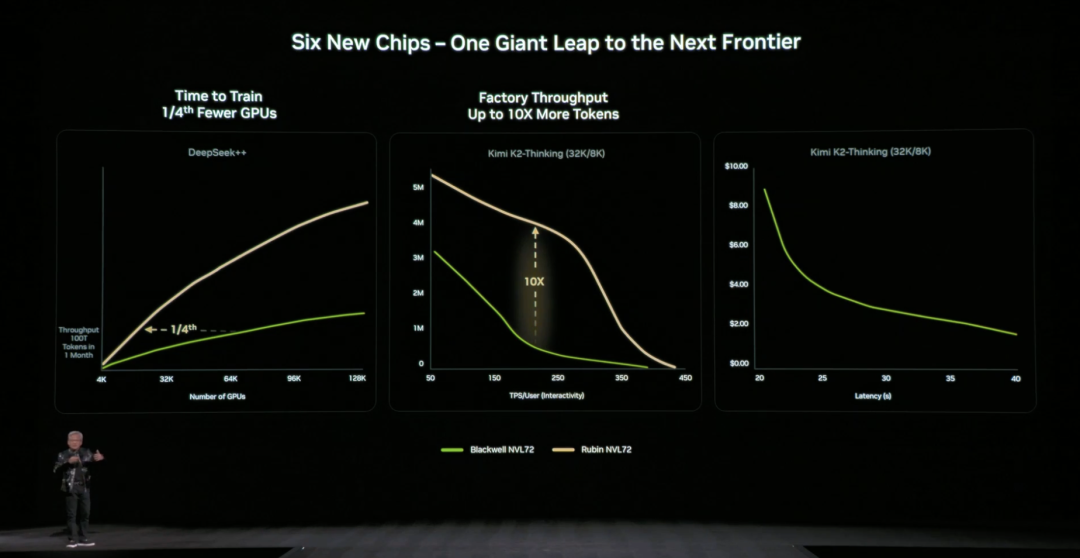
Compared to the previous generation architecture, NVIDIA also provided specific, tangible data: compared to the NVIDIA Blackwell platform, it can reduce token costs in the inference phase by up to 10 times and cut the number of GPUs required for training Mixture of Experts (MoE) models to one-fourth.
NVIDIA officially stated that Microsoft has already committed to deploying hundreds of thousands of Vera Rubin chips in its next-generation Fairwater AI super factory, and cloud service providers like CoreWeave will offer Rubin instances in the second half of 2026. This infrastructure for "letting AI think a bit longer" is moving from technical demonstrations to large-scale commercial deployment.

02 How is the "Storage Bottleneck" Solved?
Enabling AI to "think a bit longer" also faces a key technical challenge: where should the context data be stored?
When AI handles complex tasks requiring multi-turn dialogues or multi-step reasoning, it generates large amounts of context data (KV Cache). Traditional architectures either cram it into expensive and capacity-limited GPU memory or place it in regular storage (which is too slow to access). If this "storage bottleneck" isn't solved, even the most powerful GPU will be held back.
To address this issue, NVIDIA at this CES for the first time fully disclosed the BlueField-4-driven Inference Context Memory Storage Platform. Its core goal is to create a "third layer" between GPU memory and traditional storage—fast enough, with ample capacity, and capable of supporting long-term AI operation.
From a technical implementation perspective, this platform isn't the result of a single component but rather a set of co-designed elements:
- BlueField-4 is responsible for accelerating context data management and access at the hardware level, reducing data movement and system overhead.
- Spectrum-X Ethernet provides high-performance networking, supporting high-speed data sharing based on RDMA.
- Software components like DOCA, NIXL, and Dynamo are responsible for optimizing scheduling, reducing latency, and improving overall throughput at the system level.
We can understand this platform's approach as extending context data, which originally could only reside in GPU memory, to an independent, high-speed, shareable "memory layer." This relieves pressure on the GPU while enabling rapid sharing of this context information across multiple nodes and multiple AI agents.
In terms of actual effectiveness, NVIDIA's official data shows: in specific scenarios, this approach can increase the number of tokens processed per second by up to 5 times and achieve equivalent levels of energy efficiency optimization.
Huang emphasized multiple times during the launch that AI is evolving from "one-time conversation chatbots" into true intelligent collaborators: they need to understand the real world, engage in continuous reasoning, call tools to complete tasks, and retain both short-term and long-term memory. This is precisely the core characteristic of Agentic AI. The Inference Context Memory Storage Platform is designed for this long-running, repeatedly-thinking form of AI. By expanding context capacity and accelerating cross-node sharing, it makes multi-turn dialogues and multi-agent collaboration more stable, preventing them from "slowing down over time."

03
New Generation DGX SuperPOD: Enabling 576 GPUs to Work in Concert
At this CES, NVIDIA announced the launch of a new-generation DGX SuperPOD based on the Rubin architecture, extending Rubin from a single rack to a complete data center solution.
What is a DGX SuperPOD?
If the Rubin NVL72 is a "super rack" containing 72 GPUs, then the DGX SuperPOD connects multiple such racks to form a larger-scale AI computing cluster. The version announced this time consists of 8 Vera Rubin NVL72 racks, equivalent to 576 GPUs working in concert.
When AI task scales continue to expand, the 576 GPUs of a single rack may not be enough. For example, training ultra-large-scale models, simultaneously serving thousands of Agentic AI agents, or handling complex tasks requiring millions of tokens of context. This is when multiple racks need to work together, and the DGX SuperPOD is the standardized solution designed for such scenarios.
For enterprises and cloud service providers, the DGX SuperPOD provides an "out-of-the-box" large-scale AI infrastructure solution. There's no need to research how to connect hundreds of GPUs, configure networks, manage storage, etc.
The five core components of the new-generation DGX SuperPOD:
○ 8 Vera Rubin NVL72 racks - The core providing computing power, each rack with 72 GPUs, totaling 576 GPUs.
○ NVLink 6 expansion network - Enables the 576 GPUs across these 8 racks to work together like one super-large GPU.
○ Spectrum-X Ethernet expansion network - Connects different SuperPODs, as well as to storage and external networks.
○ Inference Context Memory Storage Platform - Provides shared context data storage for long-duration inference tasks.
○ NVIDIA Mission Control software - Manages scheduling, monitoring, and optimization of the entire system.
In this upgrade, the foundation of the SuperPOD is centered on the DGX Vera Rubin NVL72 rack-scale system. Each NVL72 is itself a complete AI supercomputer, internally connecting 72 Rubin GPUs via NVLink 6, capable of performing large-scale inference and training tasks within a single rack. The new DGX SuperPOD consists of multiple NVL72 units, forming a system-level cluster capable of long-term operation.
When the computing scale expands from "single rack" to "multiple racks," new bottlenecks emerge: how to stably and efficiently transmit massive amounts of data between racks. Addressing this, NVIDIA at this CES simultaneously launched a new-generation Ethernet switch based on the Spectrum-6 chip and for the first time introduced "Co-Packaged Optics" (CPO) technology.
Simply put, this involves directly packaging the originally pluggable optical modules next to the switch chip, reducing the signal transmission distance from meters to millimeters, thereby significantly lowering power consumption and latency, and also improving the overall stability of the system.
04 NVIDIA's Open-Source AI "Full Suite": Everything from Data to Code
At this CES, Jensen Huang announced the expansion of its open-source model ecosystem (Open Model Universe), adding and updating a series of models, datasets, code libraries, and tools. This ecosystem covers six major areas: Biomedical AI (Clara), AI Physical Simulation (Earth-2), Agentic AI (Nemotron), Physical AI (Cosmos), Robotics (GR00T), and Autonomous Driving (Alpamayo).
Training an AI model requires more than just computational power; it needs a complete set of infrastructure including high-quality datasets, pre-trained models, training code, evaluation tools, etc. For most enterprises and research institutions, building these from scratch is too time-consuming.
Specifically, NVIDIA has open-sourced content across six layers: computing platforms (DGX, HGX, etc.), training datasets for various domains, pre-trained foundation models, inference and training code libraries, complete training workflow scripts, and end-to-end solution templates.
The Nemotron series is a key focus of this update, covering four application directions.
In the reasoning direction, it includes small-scale inference models like Nemotron 3 Nano, Nemotron 2 Nano VL, as well as reinforcement learning training tools like NeMo RL and NeMo Gym. In the RAG (Retrieval-Augmented Generation) direction, it provides Nemotron Embed VL (vector embedding model), Nemotron Rerank VL (re-ranking model), related datasets, and the NeMo Retriever Library. In the safety direction, there are the Nemotron Content Safety model and its accompanying dataset, and the NeMo Guardrails library.
In the speech direction, it includes Nemotron ASR for automatic speech recognition, the Granary Dataset for speech, and the NeMo Library for speech processing. This means that if an enterprise wants to build an AI customer service system with RAG, it doesn't need to train its own embedding and re-ranking models; it can directly use the code NVIDIA has already trained and open-sourced.
05 Physical AI Field, Moving Towards Commercial Implementation
The physical AI field also has model updates—Cosmos for understanding and generating physical world videos, the robotics
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














