

Qwen3 by Alibaba Claims the Global Open-Source Throne, Outshining DeepSeek-R1 with 17K Stars in 2 Hours
TechFlow Selected TechFlow Selected
Qwen3 by Alibaba Claims the Global Open-Source Throne, Outshining DeepSeek-R1 with 17K Stars in 2 Hours
Qwen3 better aligns with human preferences, excelling in creative writing, role-playing, multi-turn conversations, and instruction following, thereby delivering a more natural, engaging, and authentic conversational experience.
Author: Xin Zhiyuan

[Editor's Note] Alibaba’s Qwen3 goes open source in the early hours, officially claiming the crown as the world’s leading open-source large model! With superior performance surpassing DeepSeek-R1 and OpenAI o1, it features a MoE architecture with 235 billion total parameters and dominates all major benchmarks. The entire Qwen3 family—eight hybrid reasoning models—is now fully open-sourced and free for commercial use.
Just today, at dawn, Alibaba unveiled its next-generation Qwen3 model to global anticipation!
Immediately upon release, Qwen3 has claimed the title of the world’s most powerful open-source model.
Despite having only one-third the parameter count of DeepSeek-R1, Qwen3 drastically reduces costs while outperforming top-tier global models including R1 and OpenAI-o1.
Qwen3 is China’s first "hybrid reasoning model," integrating both “fast thinking” and “slow thinking” within a single model. It delivers low-compute "instant responses" for simple queries and engages in multi-step "deep thinking" for complex problems—greatly saving computational resources.
It adopts a Mixture-of-Experts (MoE) architecture with a total of 235B parameters but activates only 22B.
Trained on 36 trillion tokens of data and enhanced through multiple rounds of reinforcement learning in post-training, it seamlessly integrates non-reasoning modes into the reasoning framework.
From birth, Qwen3 has dominated every benchmark.
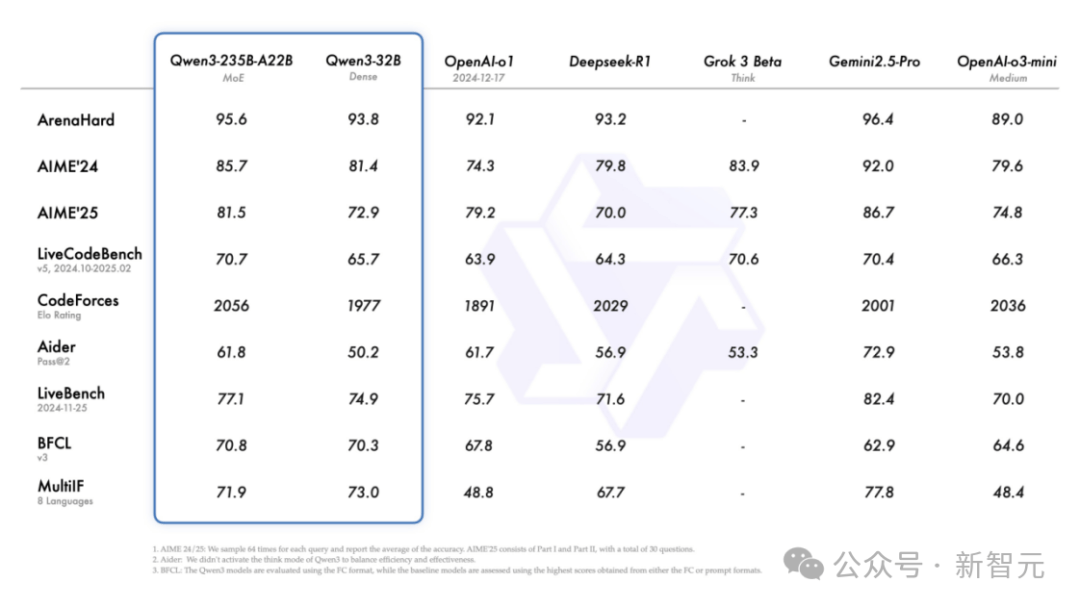
Remarkably, while delivering significantly enhanced performance, deployment costs have dropped sharply—Qwen3’s full version can be deployed using just four H20 GPUs, with VRAM usage merely one-third that of comparable-performance models!
Key Highlights:
- Diverse dense and Mixture-of-Experts (MoE) models across multiple scales: 0.6B, 1.7B, 4B, 8B, 14B, 32B, 30B-A3B, and 235B-A22B.
- Seamless switching between reasoning mode (for complex logical reasoning, math, and coding) and non-reasoning mode (for efficient general chat), ensuring optimal performance across diverse scenarios.
- Significantly enhanced reasoning capabilities, outperforming prior QwQ in reasoning mode and Qwen2.5-instruct in non-reasoning mode, especially in mathematics, code generation, and commonsense logic.
- Better alignment with human preferences, excelling in creative writing, role-playing, multi-turn dialogue, and instruction following, offering more natural, engaging, and authentic conversational experiences.
- Advanced agent capabilities: supports precise integration with external tools in both reasoning and non-reasoning modes, achieving state-of-the-art performance among open-source models on complex agent tasks.
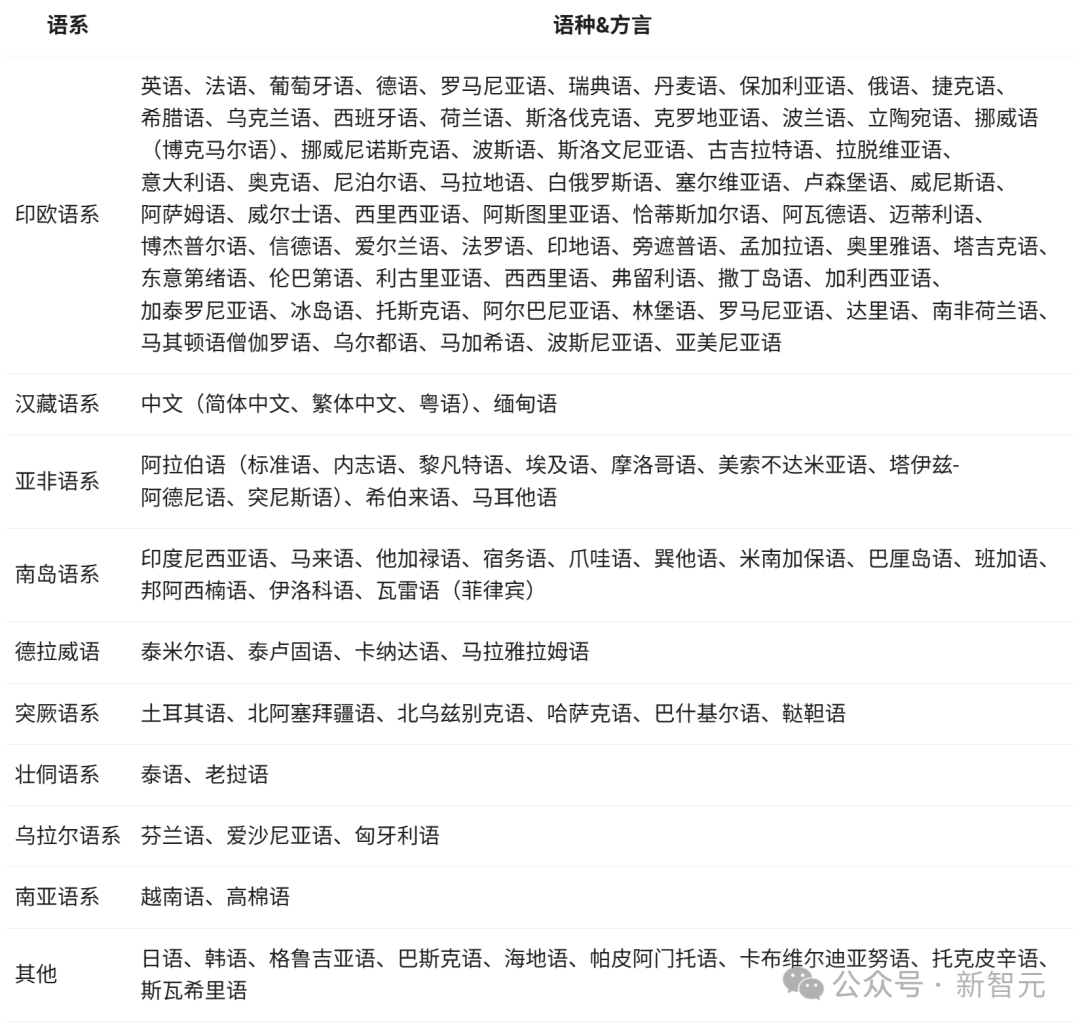
- Supports 119 languages and dialects—the first such capability—featuring robust multilingual instruction-following and translation abilities.
Qwen3 is now live on ModelScope, Hugging Face, and GitHub, with online demos available.
Developers, research institutions, and enterprises worldwide can freely download and use the models commercially. Qwen3 API services are also accessible via Alibaba Cloud’s Bailian platform. Individual users can experience Qwen3 immediately through the Tongyi app, while Quark is set to integrate Qwen3 across all its products soon.
Try it online:
ModelScope:
https://modelscope.cn/collections/Qwen3-9743180bdc6b48
Hugging Face:
https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
GitHub:
https://github.com/QwenLM/Qwen3
To date, Alibaba’s Tongyi has open-sourced over 200 models, with more than 300 million downloads globally and over 100,000 derivative Qwen models—surpassing America’s Llama series to become the world’s #1 open-source model family!
The Qwen3 Family Arrives
All Eight “Hybrid Reasoning” Models Fully Open-Sourced
This time, Alibaba open-sourced eight hybrid reasoning models in one go—including two MoE models (30B and 235B)—and six dense models (0.6B, 1.7B, 4B, 8B, 14B, and 32B)—all under the permissive Apache 2.0 license.
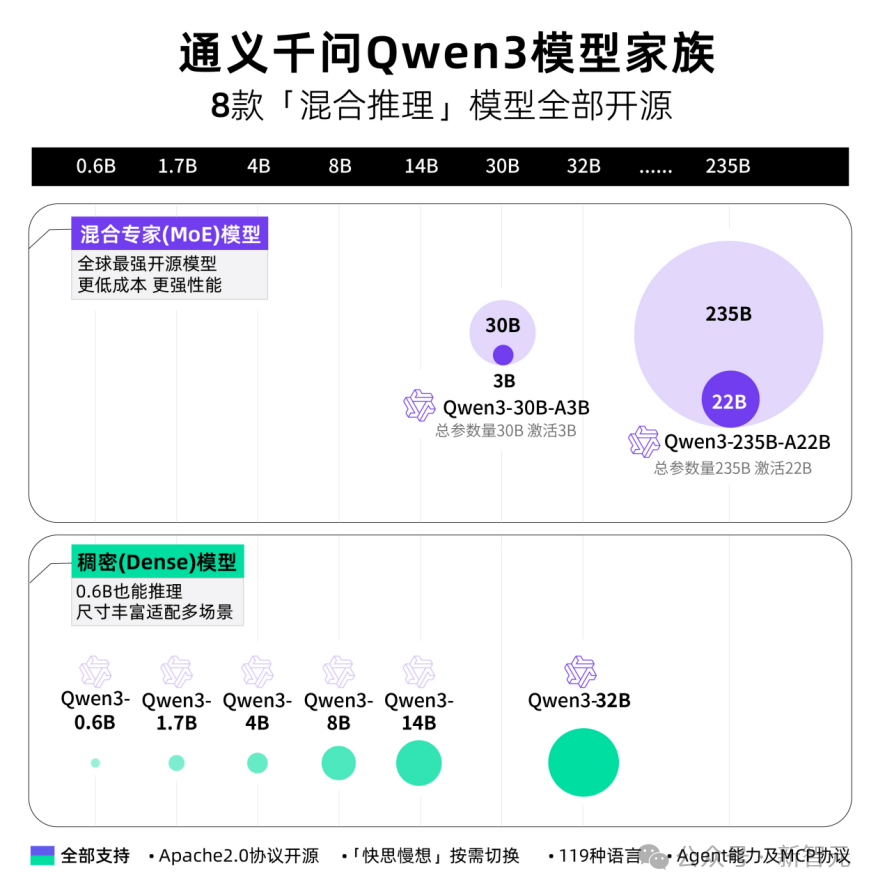
Each model achieves SOTA (state-of-the-art) performance within its size category.
The Qwen3 30B MoE model delivers over 10x performance leverage: activating only 3B parameters matches the performance of the previous-generation Qwen2.5-32B model.
Qwen3’s dense models continue to break new ground—achieving equivalent high performance with half the parameters. For example, the 32B version surpasses the performance of Qwen2.5-72B.
Moreover, all Qwen3 models support hybrid reasoning. Through the API, users can set a “reasoning budget” (i.e., the maximum number of tokens allocated for deep thinking), enabling flexible trade-offs between performance and cost for various AI applications and use cases.
For instance, the 4B model is ideal for mobile devices; the 8B model runs smoothly on PCs and in-car systems; the 32B model is most popular for enterprise-scale deployment, yet remains accessible even to individual developers.
New King of Open-Source Models Sets Records
Qwen3 demonstrates significant improvements in reasoning, instruction following, tool calling, and multilingual ability—setting new performance highs for all Chinese and global open-source models:
In AIME25, a benchmark measuring Olympiad-level math skills, Qwen3 scored 81.5, setting a new open-source record.
In LiveCodeBench, evaluating coding ability, Qwen3 broke through the 70-point mark—outperforming even Grok3.
In ArenaHard, assessing human preference alignment, Qwen3 achieved 95.6 points, surpassing both OpenAI-o1 and DeepSeek-R1.

Specifically, the flagship Qwen3-235B-A22B model outshines other top models—including DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro—across coding, mathematics, and general capabilities in various benchmarks.
Additionally, the smaller MoE model Qwen3-30B-A3B, despite activating only one-tenth the parameters of QwQ-32B, delivers superior performance.
Even compact models like Qwen3-4B match the performance of the much larger Qwen2.5-72B-Instruct.
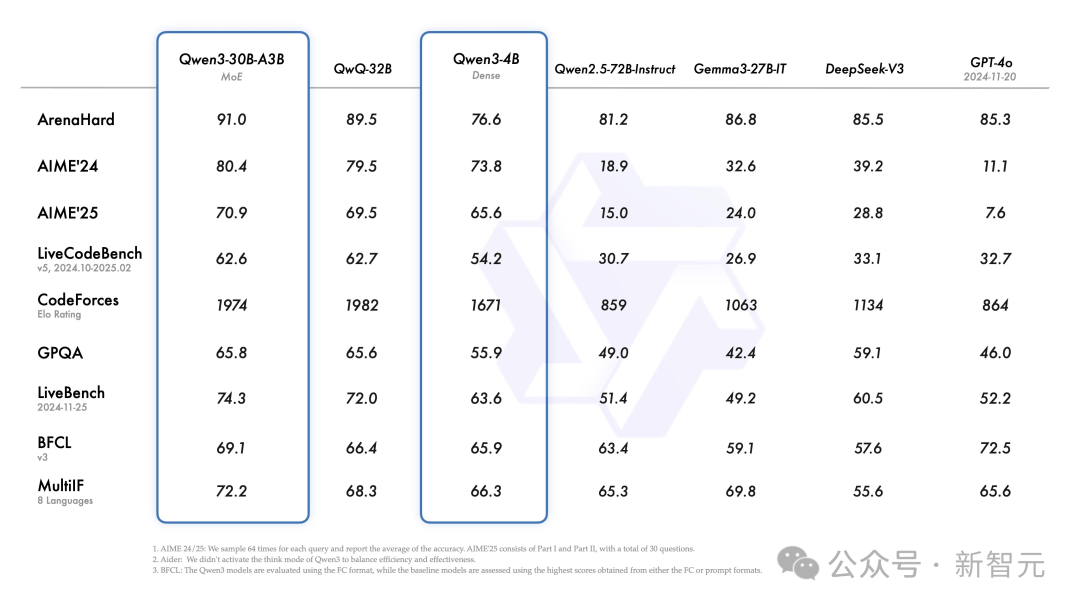
Fine-tuned versions such as Qwen3-30B-A3B, along with their pre-trained counterparts (e.g., Qwen3-30B-A3B-Base), are now available on platforms like Hugging Face, ModelScope, and Kaggle.
For deployment, Alibaba recommends frameworks such as SGLang and vLLM. For local usage, tools like Ollama, LMStudio, MLX, llama.cpp, and KTransformers are highly recommended.
Whether for research, development, or production, Qwen3 can be easily integrated into any workflow.
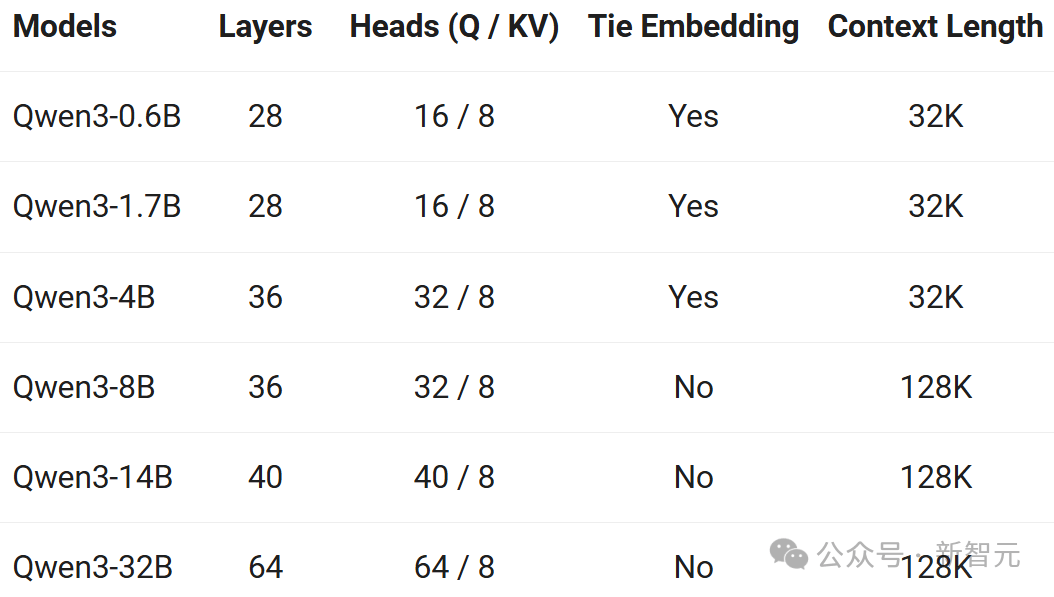
Boosting the Explosion of Agents and LLM Applications
Qwen3 provides strong support for the imminent explosion of AI agents and large model applications.
In the BFCL benchmark, which evaluates agent capabilities, Qwen3 sets a new record of 70.8, surpassing top models like Gemini2.5-Pro and OpenAI-o1—significantly lowering the barrier for agents to call tools.
Furthermore, Qwen3 natively supports the MCP protocol and boasts robust tool-calling capabilities, enhanced by the Qwen-Agent framework, which includes built-in templates and parsers for tool calls.
This greatly reduces coding complexity, enabling efficient execution of agent tasks on smartphones and computers alike.
Main Features
Hybrid Reasoning Modes
Qwen3 introduces a hybrid problem-solving approach with two operational modes:
- Reasoning Mode: The model performs step-by-step reasoning before delivering an answer—ideal for complex problems requiring deep thought.
- Non-Reasoning Mode: The model responds instantly, suitable for simple queries where speed is critical.
This flexibility allows users to control the reasoning process based on task complexity.
Complex problems benefit from extended reasoning, while simple ones are answered directly without delay.
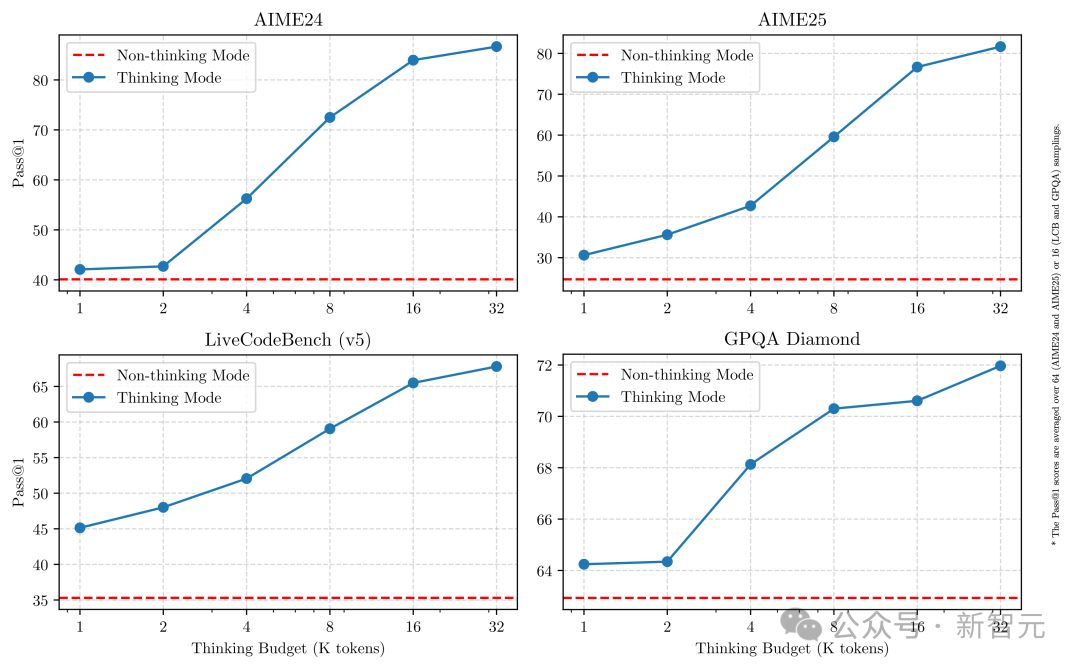
Critically, combining both modes greatly enhances the model’s ability to manage reasoning resources stably and efficiently.
As shown above, Qwen3 exhibits scalable and smooth performance improvement directly correlated with the allocated computational reasoning budget.
This design enables easier configuration of task-specific budgets, optimizing the balance between cost-efficiency and reasoning quality.
Multilingual Support
Qwen3 supports 119 languages and dialects.
This extensive multilingual capability positions Qwen3 to power globally popular international applications.
Enhanced Agent Capabilities
Alibaba optimized Qwen3 for improved coding and agent capabilities, with strengthened support for MCP.
The example below clearly illustrates how Qwen3 thinks and interacts with its environment.
36 Trillion Tokens, Multi-Stage Training
How did Qwen3, the most powerful model in the Qwen series, achieve such remarkable performance?
Let’s dive into the technical details behind Qwen3.
Pretraining
Compared to Qwen2.5, Qwen3’s pretraining dataset nearly doubles—from 18 trillion to 36 trillion tokens.
Covering 119 languages and dialects, the data comes not only from the web but also from text extracted from documents such as PDFs.
To ensure data quality, the team used Qwen2.5-VL to extract document text and refined accuracy using Qwen2.5.
Additionally, to boost performance in math and coding, Qwen3 leveraged synthetic data generated by Qwen2.5-Math and Qwen2.5-Coder—including textbooks, question-answer pairs, and code snippets.
Qwen3’s pretraining consists of three stages, progressively enhancing model capabilities:
Stage 1 (S1): Building Foundational Language Skills
Pretrained on over 30 trillion tokens with a 4K context length, establishing solid language proficiency and general knowledge.
Stage 2 (S2): Knowledge-Dense Optimization
Trained further on an additional 5 trillion tokens, increasing the proportion of knowledge-intensive data such as STEM, coding, and reasoning tasks to enhance specialized capabilities.
Stage 3 (S3): Expanding Context Capacity
Using high-quality long-context data, the model’s context length is extended to 32K, enabling it to handle complex, ultra-long inputs.
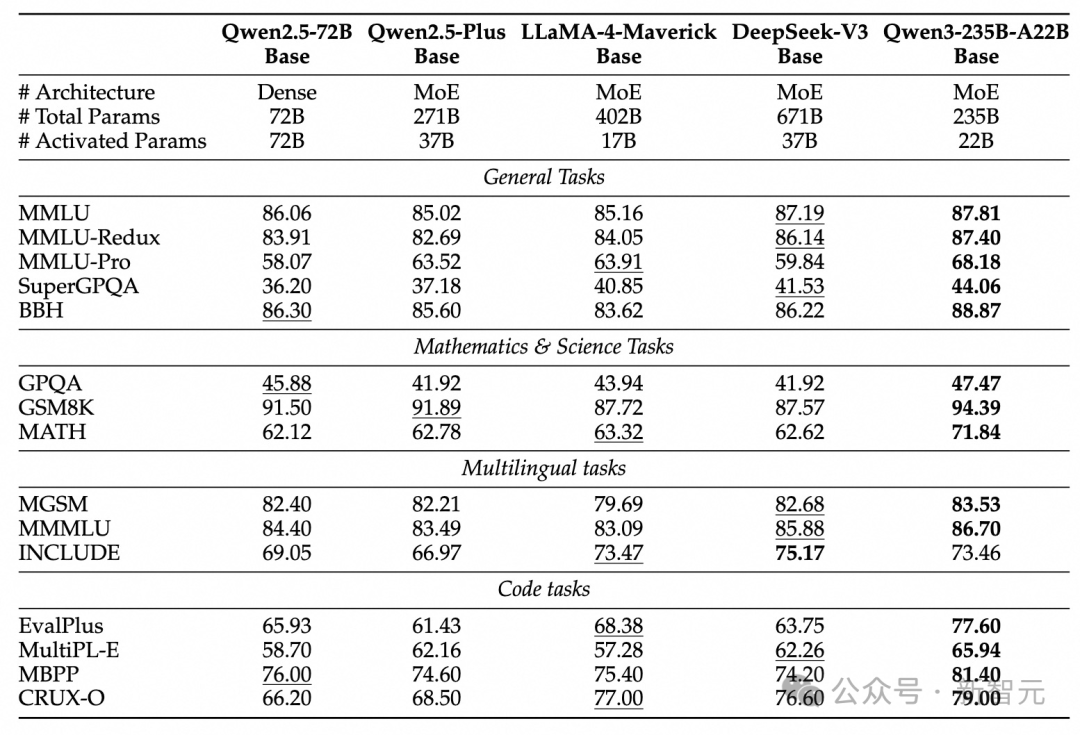
Thanks to architectural improvements, expanded data scale, and more efficient training methods, Qwen3 Dense base models deliver outstanding performance.
As shown in the table, Qwen3-1.7B/4B/8B/14B/32B-Base match or exceed Qwen2.5-3B/7B/14B/32B/72B-Base, achieving larger-model performance with fewer parameters.
Notably, in fields like STEM, coding, and reasoning, Qwen3 Dense base models even outperform larger Qwen2.5 models.
More impressively, Qwen3 MoE models achieve similar performance to Qwen2.5 Dense base models using only 10% of activated parameters.
This dramatically reduces training and inference costs while offering greater flexibility for real-world deployment.
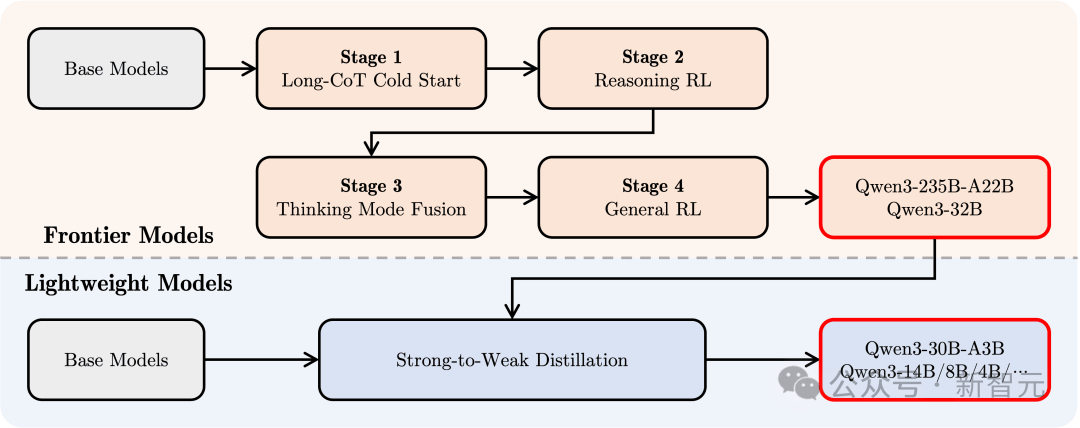
Post-Training
To create a hybrid model capable of both deep reasoning and rapid response, Qwen3 employs a four-stage post-training pipeline.
1. Long Chain-of-Thought Cold Start
Using diverse long chain-of-thought data covering math, coding, logical reasoning, and STEM problems to train fundamental reasoning skills.
2. Long Chain-of-Thought Reinforcement Learning
Expanding RL compute resources and incorporating rule-based reward mechanisms to improve the model’s ability to explore and exploit reasoning paths.
3. Reasoning Mode Fusion
Fine-tuning using both long chain-of-thought and instruction-tuning data to embed fast-response capabilities into the reasoning model, ensuring precision and efficiency on complex tasks.
This data is generated by the enhanced reasoning model from Stage 2, ensuring seamless integration of reasoning and quick response abilities.
4. General Reinforcement Learning
Applying RL across over 20 general domains—including instruction following, format adherence, and agent capabilities—to further improve generalization, robustness, and correct undesirable behaviors.
Overwhelming Praise Across the Web
Within three hours of its open-source release, Qwen3 garnered 17,000 stars on GitHub, igniting immense enthusiasm in the open-source community. Developers rushed to download and began rapid testing.
Project link:
https://github.com/QwenLM/Qwen3
Awni Hannun, an Apple engineer, announced that Qwen3 is now supported by the MLX framework.
Moreover, Qwen3 can run locally on consumer devices ranging from iPhones (0.6B, 4B) and MacBooks (8B, 30B, 3B/30B MoE) to M2/M3 Ultra machines (22B/235B MoE).
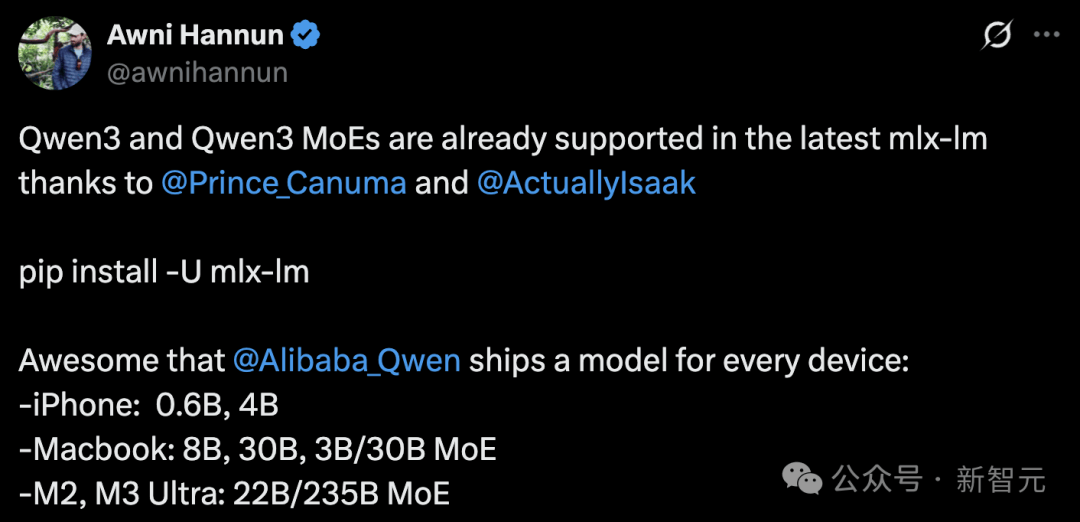
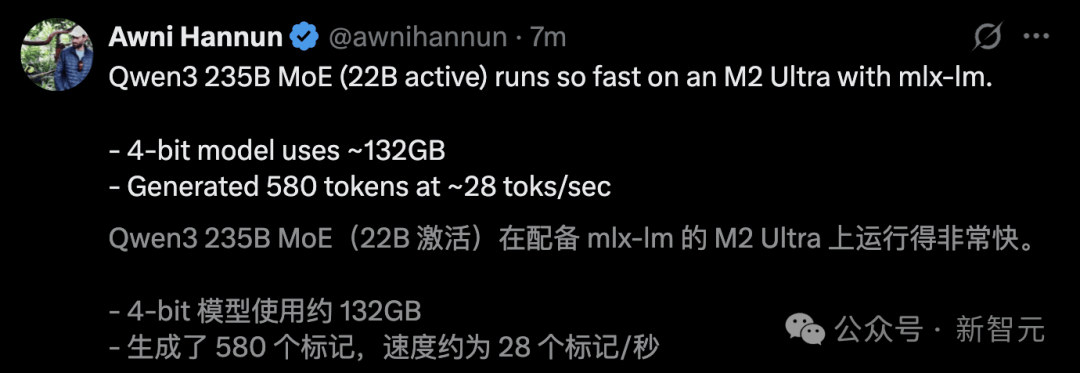
He ran Qwen3 235B MoE on an M2 Ultra, achieving a generation speed of up to 28 tokens per second.
Some users found in real-world tests that Llama models of comparable size simply aren’t in the same league. Qwen3 offers deeper reasoning, longer context retention, and the ability to solve harder problems.

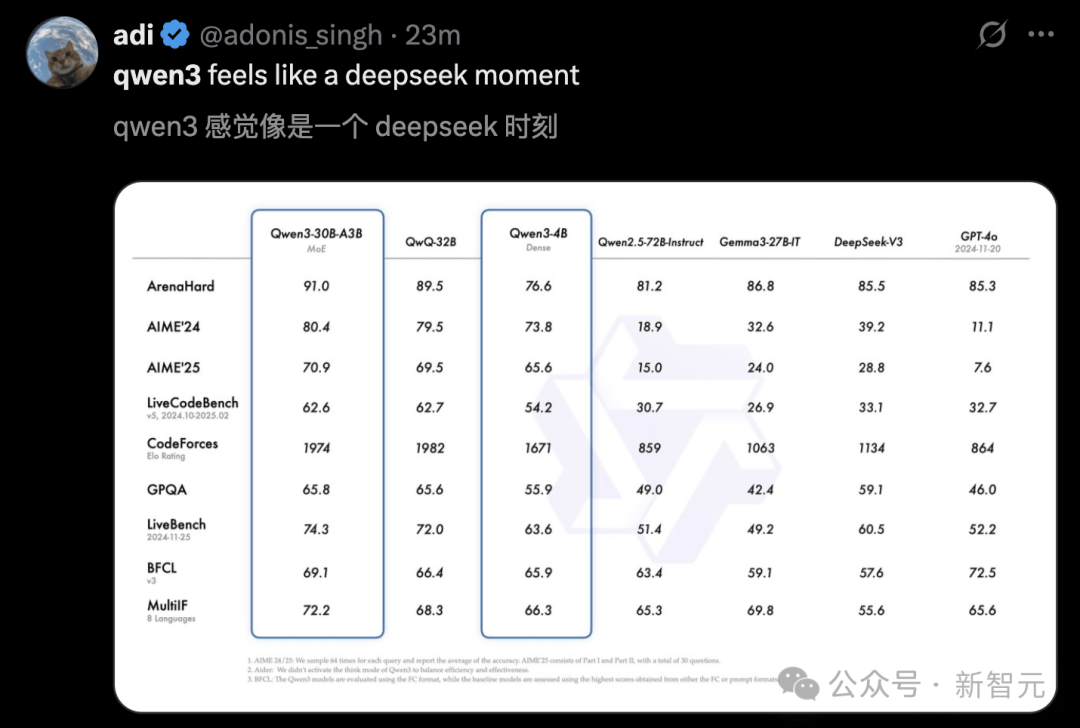
Others remarked that Qwen3 feels like a “DeepSeek moment.”
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News













