

Besides making money and storytelling, what else can crypto do for AI?
TechFlow Selected TechFlow Selected
Besides making money and storytelling, what else can crypto do for AI?
In the field of AI, many fundamental issues can be addressed through cryptographic technologies.
Author: Pavel Paramonov
Translation: TechFlow
@newmichwill, the founder of Curve Finance, recently claimed on Twitter that the primary purpose of cryptocurrency lies in DeFi (decentralized finance), and that AI (artificial intelligence) fundamentally has no need for crypto. While I agree that DeFi is a crucial component within the crypto space, I disagree with the notion that AI does not require cryptocurrency.
With the rise of AI agents—many of which come bundled with their own tokens—there's a common misconception that the intersection between crypto and AI is limited to these agents. Another critical but often overlooked topic is "decentralized AI," which directly relates to how AI models themselves are trained.
What frustrates me about certain narratives is that most users blindly assume something must be important and useful simply because it’s trendy—or worse, they believe the sole objective of such narratives is to extract as much value as possible (in other words, make money).
When discussing decentralized AI, we should first ask ourselves: Why does AI need decentralization? And what implications would this have?
It turns out that the idea of decentralization is almost inevitably tied to the concept of “incentive alignment.”
In the field of AI, there are numerous fundamental problems that can be addressed through cryptographic techniques. Moreover, certain mechanisms not only solve existing issues but also enhance the trustworthiness of AI systems.
So why does AI need cryptocurrency?
1. High computational costs restrict participation and innovation
For better or worse, large-scale AI models require massive computational resources, naturally limiting participation from many potential contributors. In most cases, training AI models demands vast amounts of data and real computing power—resources that are nearly impossible for individuals to afford alone.
This issue is especially pronounced in open-source development. Contributors must invest not only time but also substantial computational resources, making open collaboration inefficient.
Certainly, individuals can dedicate significant resources to run AI models, just as users allocate computing power to operate blockchain nodes.
However, this doesn’t address the root problem, as individual computing capacity is often insufficient for meaningful tasks.
Independent developers or researchers cannot participate in developing large AI models like LLaMA simply because they cannot afford the associated computational costs—thousands of GPUs, data centers, and additional infrastructure.
Here are some illustrative figures:
→ Elon Musk stated that the latest Grok 3 model was trained using 100,000 Nvidia H100 GPUs.
→ Each chip is valued at approximately $30,000.
→ The total cost of AI chips used to train Grok 3 was around $3 billion.
This challenge resembles starting a tech startup: an individual may possess time, technical skills, and a solid execution plan, yet lack the initial capital to bring their vision to life.
As @dbarabander pointed out, traditional open-source software projects only require contributors’ time, whereas open-source AI projects demand both time and expensive resources like compute power and data.
Relying solely on goodwill and volunteer efforts is insufficient to attract enough individuals or groups to provide these costly resources. Additional incentive mechanisms are essential to drive participation.
2. Cryptoeconomics is the best tool for incentive alignment
Incentive alignment refers to designing rules that encourage participants to contribute to a system while simultaneously benefiting personally.
Cryptoeconomics has countless success stories in enabling incentive alignment across various systems, with one of the most prominent examples being the DePIN (Decentralized Physical Infrastructure Networks) sector—an ideal fit for this principle.
Projects like @helium and @rendernetwork, which utilize distributed networks of nodes and GPUs, exemplify effective incentive alignment.
So why can't we apply this same model to AI, making its ecosystem more open and accessible?
The truth is—we can.
A core driver behind Web3 and cryptocurrency is “ownership.”
You own your data, you control your incentives, and when you hold certain tokens, you own part of the network. Granting resource providers ownership incentivizes them to contribute their assets, expecting returns as the network succeeds.
To democratize AI, cryptoeconomics offers the optimal solution. Developers can freely share model designs across projects, while those providing computation and data receive ownership stakes (incentives) in return.
3. Incentive alignment is deeply connected to verifiability
If we envision a decentralized AI system with proper incentive alignment, it should inherit key characteristics from classic blockchain mechanisms:
-
Network effects.
-
Low entry barriers, where nodes are rewarded based on future earnings.
-
Slashing mechanisms to penalize malicious actors.
Slashing, in particular, requires verifiability. Without the ability to verify who acted maliciously, penalties cannot be enforced—making the system vulnerable to exploitation, especially in cross-team collaborations.
Verifiability is crucial in decentralized AI systems because we lack a central point of trust. Instead, we aim for a trustless yet verifiable system. Below are several components that may require verification:
-
Benchmark Phase: The system outperforms others on specific metrics (e.g., x, y, z).
-
Inference Phase: Whether the system runs correctly—i.e., the AI’s “thinking” process.
-
Training Phase: Whether the system was properly trained or fine-tuned.
-
Data Phase: Whether data was collected accurately.
While hundreds of teams are building on @eigenlayer, I’ve recently noticed increased attention toward AI—and I wonder whether this aligns with its original restaking vision.
Any AI system aiming for incentive alignment must be verifiable.
In this context, slashing equals verifiability: if a decentralized system can penalize bad actors, it must be capable of identifying and verifying their misconduct.
If the system is verifiable, AI can leverage cryptographic tools to access global computing and data resources, enabling the creation of larger, more powerful models. After all, more resources (compute + data) generally lead to better models—at least in today’s technological landscape.
@hyperbolic_labs has already demonstrated the potential of collaborative compute. Users can rent GPUs to train more complex AI models than they could run at home—all at lower costs.
How to make AI verification efficient and verifiable?
One might argue that cloud solutions already allow GPU rentals, seemingly solving the compute-resource problem.
However, centralized platforms like AWS or Google Cloud employ so-called “waitlist strategies,” artificially inflating demand to justify higher prices—a common tactic in oligopolistic markets.
In reality, vast GPU resources sit idle in data centers, mining farms, and even personal devices. These underutilized resources could contribute to AI model training but remain wasted.
You may have heard of @getgrass_io, which allows users to monetize unused bandwidth by selling it to enterprises—preventing waste while earning rewards.
I’m not suggesting compute resources are infinite, but any system can achieve win-win outcomes through optimization: opening up a more accessible market for those needing resources to train AI models, while fairly compensating those who contribute those resources.
The Hyperbolic team has built an open GPU marketplace. Here, users can rent GPUs for AI training at up to 75% lower cost, while GPU providers monetize idle hardware for profit.
Here’s how it works:
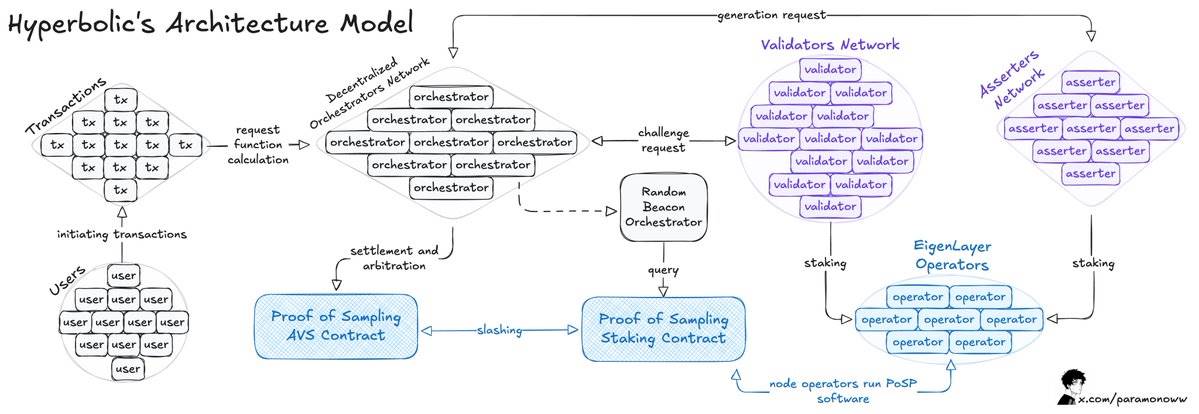
Hyperbolic organizes connected GPUs into clusters and nodes, allowing computational capacity to scale dynamically with demand.
At the heart of this architecture is the “Proof of Sampling” model, which reduces workload and computational overhead by randomly sampling and verifying transactions.
The main challenge arises during AI inference, where every inference executed on the network must be verified—with minimal added computational burden.
As previously mentioned, if an action can be verified, then rule-breaking behavior must be punishable via slashing.
When Hyperbolic adopts the AVS (Adaptive Verification System) model, it enhances verifiability. Validators are randomly selected to verify outputs, ensuring incentive alignment—under which dishonest behavior becomes unprofitable.
Training and improving AI models primarily require two resources: computational power and data. Renting compute is one solution, but we still need diverse data sources to avoid model bias.
Verifying AI data from multiple sources
More data generally leads to better models—but diversity matters. This remains a major challenge in AI development.
Data brokers have existed for decades. Whether public or private, they collect data—sometimes paying for it, sometimes not—and resell it for profit.
Problems in sourcing quality data for AI include single points of failure, censorship, and the absence of a trustless way to ensure reliable, authentic data feeds for AI models.
Who needs such data?
First, AI researchers and developers seeking accurate inputs for model training and inference.
For example, OpenLayer enables anyone to permissionlessly add data streams to the system, with each available data point recorded in a verifiable manner.
OpenLayer also uses zkTLS (zero-knowledge Transport Layer Security), detailed in my previous article, ensuring that reported data truly originates from the source (verifiability).
Here’s how OpenLayer works:
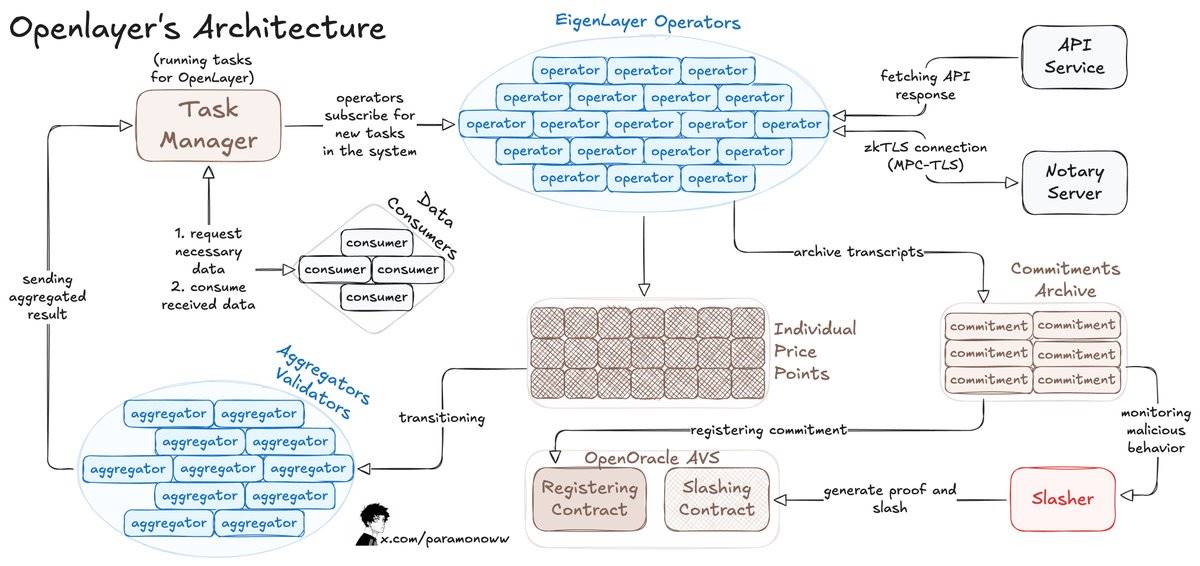
-
Data consumers submit data requests to OpenLayer’s smart contract and retrieve results via APIs (on-chain or off-chain), similar to primary data oracles.
-
Operators register via EigenLayer, stake assets to secure the OpenLayer AVS, and run AVS software.
-
Operators subscribe to tasks, process and submit data to OpenLayer, storing raw responses and proofs in decentralized storage.
-
For variable outputs, aggregators (special operators) standardize the results.
Developers can request fresh data from any website and feed it into the network. If you're building an AI project, you gain access to reliable real-time data.
After exploring AI computation and methods for obtaining verifiable data, we now turn to two core aspects of AI models: computation itself and its verification.
AI computation must be verified to ensure correctness
In an ideal scenario, nodes must prove their computational contributions to maintain system integrity.
In the worst case, nodes falsely claim to have performed computations without doing any actual work.
Requiring proof ensures only legitimate participants are recognized, preventing malicious behavior. This mechanism closely resembles traditional Proof of Work, differing only in the type of work performed.
Even with well-designed incentive alignment, if nodes cannot permissionlessly prove completed work, they may receive disproportionate rewards—potentially leading to unfair distribution.
If the network cannot assess computational contributions, some nodes may be assigned tasks beyond their capabilities while others remain idle—leading to inefficiencies or system failures.
By proving computational effort, the network can quantify each node’s contribution using standardized metrics like FLOPS (floating-point operations per second). Rewards can then be allocated based on actual work performed, rather than mere network presence.
The team at @HyperspaceAI developed a “Proof-of-FLOPS” system, allowing nodes to lease unused compute power. In exchange, they earn “flops” points, serving as the network’s universal currency.
Here’s how the architecture functions:
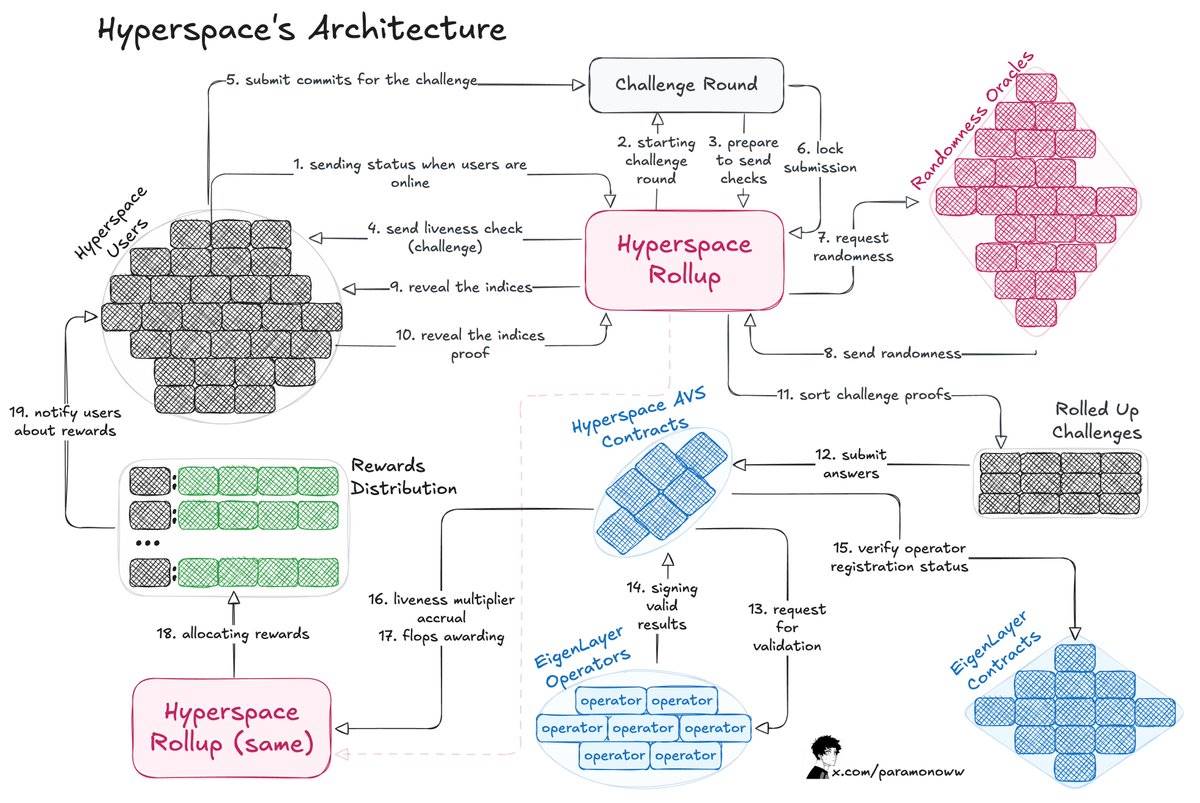
-
The process begins with a challenge issued to users, who respond by submitting commitments.
-
Hyperspace Rollup manages the workflow, ensuring submission security and fetching random numbers from oracles.
-
Users reveal indices, completing the challenge process.
-
Operators check responses and notify the Hyperspace AVS contract of valid results, which are then confirmed via EigenLayer contracts.
-
Compute liveliness multipliers are calculated, and flops points are awarded accordingly.
Proving computational contribution provides a clear picture of each node’s capabilities, enabling intelligent task allocation—assigning complex AI computations to high-performance nodes and lighter tasks to less capable ones.
The most interesting aspect is how this system achieves verifiability, allowing anyone to validate the correctness of completed work. Hyperspace’s AVS continuously sends challenges, requests random numbers, and executes multi-layer verification processes, as illustrated in the architecture diagram above.
Operators can confidently participate, knowing results are verified and rewards are fairly distributed. Incorrect results will result in slashing—without exception.
There are several key reasons to verify AI computation:
-
Incentivize nodes to join and contribute resources.
-
Fairly distribute rewards based on effort.
-
Ensure contributions directly support specific AI models.
-
Efficiently assign tasks based on verified node capabilities.
Decentralization and verifiability in AI
As @yb_effect noted, “decentralized” and “distributed” are entirely different concepts. Distribution merely means hardware is geographically dispersed, but still connected through a centralized hub.
True decentralization means no single master node exists—the training process can tolerate failures, much like how most modern blockchains operate.
To achieve genuine decentralization in AI networks, multiple solutions are required—but one thing is certain: we need to verify nearly everything.
If you’re building an AI model or agent, you must ensure every component and dependency is verifiable.
Inference, training, data, oracles—each of these can be verified, introducing cryptoeconomic incentives compatible with AI systems while making them fairer and more efficient.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News









