

DeepSeek "steals" from OpenAI? More like the thief crying "thief"
TechFlow Selected TechFlow Selected
DeepSeek "steals" from OpenAI? More like the thief crying "thief"
Distillation is not plagiarism, but a necessary means of technological advancement.
Author: Deng Yongyi, Intelligence Emergence

Image source: Generated by Wujie AI
During the 2025 Spring Festival, the biggest sensation wasn't just *Ne Zha 2*, but also an app called DeepSeek—this inspiring story has been told repeatedly: On January 20, DeepSeek (Deep Thinking), an AI startup based in Hangzhou, released its new R1 model, directly competing with OpenAI's most powerful reasoning model, o1, and truly ignited global attention.
In just one week after launch, the DeepSeek app surpassed 20 million downloads and ranked first in over 140 countries. Its growth rate has exceeded that of ChatGPT when it launched in 2022 and is now about 20% of ChatGPT’s pace.
How popular is it? As of February 8, DeepSeek had already surpassed 100 million users, reaching far beyond AI enthusiasts to a global audience. From seniors and children to stand-up comedians and politicians, everyone is talking about DeepSeek.
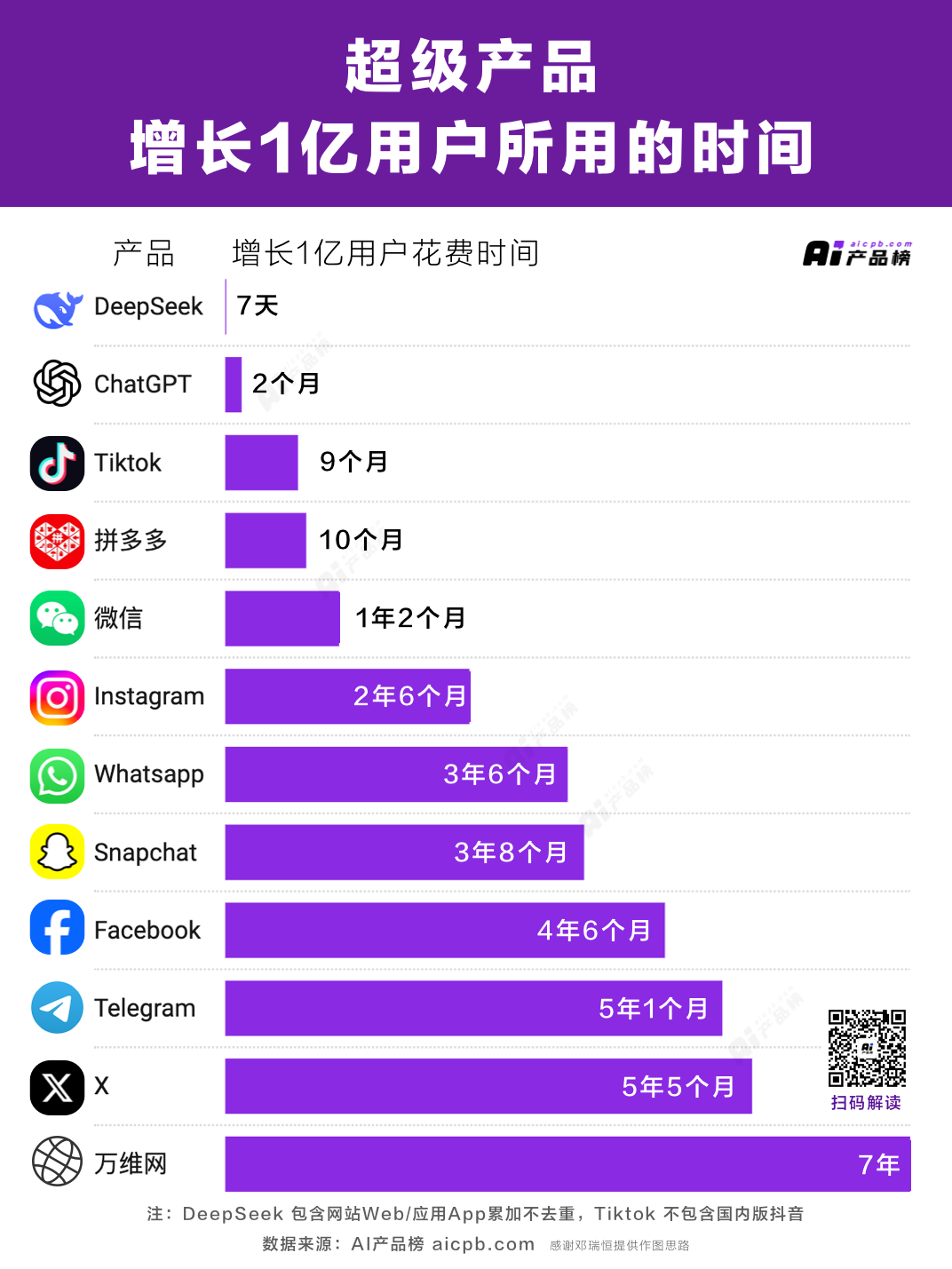
The ripple effect from DeepSeek continues even now. Over the past two weeks, DeepSeek has rapidly gone through TikTok's playbook—explosive popularity and rapid growth, defeating numerous American competitors, and quickly placing itself on the edge of geopolitics: discussions about "national security implications" have begun in the U.S. and Europe, with many regions swiftly issuing bans on downloading or installing the app.
Marc Andreessen, partner at A16Z, even exclaimed: The emergence of DeepSeek marks another "Sputnik Moment."
(A term originating from the Cold War era, referring to the Soviet Union successfully launching the world's first artificial satellite, Sputnik 1, in 1957, which triggered panic in American society and made them realize their technological superiority was being challenged.)
But fame brings controversy. Within the tech community, DeepSeek has also been embroiled in debates over "distillation" and "data theft."
To date, DeepSeek has not issued any public response. These debates have thus fallen into two extremes: fervent supporters elevating DeepSeek-R1 to a "national destiny-level" innovation, while some tech professionals question its extremely low training costs and distillation-based training methods, arguing these innovations are overly hyped.
Did DeepSeek "steal" from OpenAI? More like the thief crying foul
Almost as soon as DeepSeek went viral, Silicon Valley AI giants including OpenAI and Microsoft began publicly accusing DeepSeek, focusing primarily on its data practices. David Sacks, U.S. government AI and crypto chief, publicly stated that DeepSeek used a technique called distillation to "absorb" knowledge from ChatGPT.
In a report by the UK's Financial Times, OpenAI claimed it had found evidence that DeepSeek "distilled" ChatGPT, saying this violated OpenAI's model usage terms. However, OpenAI did not provide specific evidence.
In fact, this accusation does not hold up.
Distillation is a standard large-model training technique. It commonly occurs during the training phase—using outputs from a larger, more powerful model (the teacher model) to help a smaller model (the student model) achieve better performance. For specific tasks, smaller models can achieve similar results at significantly lower cost.
Distillation is not plagiarism. In simple terms, distillation is like having a top-performing student solve all difficult problems and compile a perfect solution notebook—not just containing answers, but detailed optimal approaches. An average student (small model) simply learns from this notebook and produces their own answers, checking whether their reasoning aligns with the teacher's thought process.
DeepSeek's key contribution lies in using more unsupervised learning—allowing machines to self-correct and reducing reliance on human feedback (RLHF). The most direct result is a dramatic reduction in training costs—this is precisely where much of the skepticism originates.
The DeepSeek-V3 paper disclosed the specific training cluster size for its V3 model (2048 H800 chips). Based on market prices, many estimate this cost around $5.5 million, roughly a fraction of what Meta and Google spend on model training.
However, it should be noted that DeepSeek clearly stated in its paper that this figure only represents the single-run cost of the final training stage, excluding earlier infrastructure, personnel, and training losses.
In the AI field, distillation is nothing new—many model vendors have disclosed their distillation efforts. For example, Meta has previously revealed how its models were distilled: Llama 2 used larger, smarter models to generate data containing thinking processes and methods, then fine-tuned smaller-scale inference models with this data.
△ Source: Meta FAIR
But distillation has its drawbacks.
A senior AI application practitioner told Intelligence Emergence that while distillation enables rapid capability gains, its downside is that data generated by the "teacher model" is often too clean and lacks diversity. Learning from such data makes models resemble standardized "pre-prepared meals," limiting their ability to surpass the teacher model.
Data quality largely determines model performance. If distillation constitutes most of the training, the resulting model becomes overly homogenized. With so many large models available globally today, each offering its own "premium version," distilling an identical model holds little value.
An even more critical issue may be increased hallucinations. This is because small models, to some extent, only mimic the "surface" behavior of large models without deeply understanding underlying logic, leading to poorer performance on new tasks.
Therefore, if engineers want models to develop unique characteristics, they must intervene early—from data selection, data ratios, to training methods—all of which greatly influence the final model.
A typical example is OpenAI and Anthropic today. As pioneers in large models, neither company had existing models to distill from initially; instead, they directly scraped and learned from public internet sources and datasets.
Different learning paths have led to markedly different model styles: Today, ChatGPT resembles a disciplined STEM student, excelling at solving practical life and work problems; Claude, on the other hand, performs exceptionally well in humanities, widely recognized as the gold standard in writing tasks, though it doesn't lag behind in coding either.
Another irony in OpenAI's accusations is that it uses vague contractual clauses to accuse DeepSeek, despite engaging in similar practices itself.
In its early days, OpenAI was an open-source-oriented organization, but shifted to closed-source after GPT-4. OpenAI's training process extensively crawled global public internet data. After going closed-source, OpenAI has remained entangled in copyright disputes with news media and publishers.
The accusation against DeepSeek for "distillation" is seen as "the thief crying foul," especially since neither OpenAI's o1 nor DeepSeek's R1 disclosed details about their data preparation in their papers—this issue remains a mystery.
Moreover, DeepSeek-R1 was released under the MIT open-source license—the most permissive open-source license available. DeepSeek-R1 allows commercial use, permits distillation, and provides six pre-distilled small models for public deployment on phones and PCs—an extremely sincere gesture toward the open-source community.
On February 5, Tanishq Mathew Abraham, former research lead at Stability AI, wrote an article specifically pointing out that the accusation falls into a gray area: First, OpenAI provided no evidence showing DeepSeek directly used GPT for distillation. He speculated that DeepSeek might have used publicly available datasets generated by ChatGPT (of which many already exist), a practice not explicitly prohibited by OpenAI.
Is distillation the criterion for determining AGI pursuit?
In public discourse, many now use "whether distillation was used" as a litmus test for plagiarism or genuine AGI development—this is overly simplistic.
DeepSeek's work has revived interest in the concept of "distillation," a technique that actually emerged nearly a decade ago.
In 2015, a paper titled *Distilling the Knowledge in a Neural Network* co-authored by AI pioneers Hinton, Oriol Vinyals, and Jeff Dean formally introduced "knowledge distillation" in large models, which later became standard practice in the field.
For model developers focused on specific domains or tasks, distillation is often a more pragmatic path.
An AI practitioner told Intelligence Emergence that virtually no major Chinese model vendor avoids distillation—it's practically an open secret. "Public web data has almost been exhausted. The cost of zero-to-one pre-training and data annotation is enormous—even for big companies, it's hard to bear easily."
A notable exception is ByteDance. In its recently released Doubao 1.5 Pro version, ByteDance explicitly stated, "We never used data generated by any other model during training and firmly reject taking the distillation shortcut," signaling its determination to pursue AGI.
Large companies choosing to avoid distillation do so for practical reasons, such as avoiding future compliance disputes. Under closed-source conditions, this also creates certain capability barriers. According to Intelligence Emergence, ByteDance's current data annotation costs are on par with Silicon Valley levels—reaching up to $200 per data point, requiring experts in various fields, such as master's or PhD-level talent, to perform annotations.
For most participants in the AI field, whether using distillation or other engineering techniques, the essence is exploring the boundaries of Scaling Law (scale effect principle). This is a necessary condition for pursuing AGI, not a sufficient one.
In the first two years of large models' rise, Scaling Law was often crudely understood as "brute force creates miracles"—simply piling on compute power and parameters could lead to emergent intelligence, mainly during the pre-training phase.
The current heated discussion around "distillation" reflects an underlying shift in large model development paradigms: Scaling Law still exists, but the focus has genuinely shifted from pre-training to post-training and inference stages.
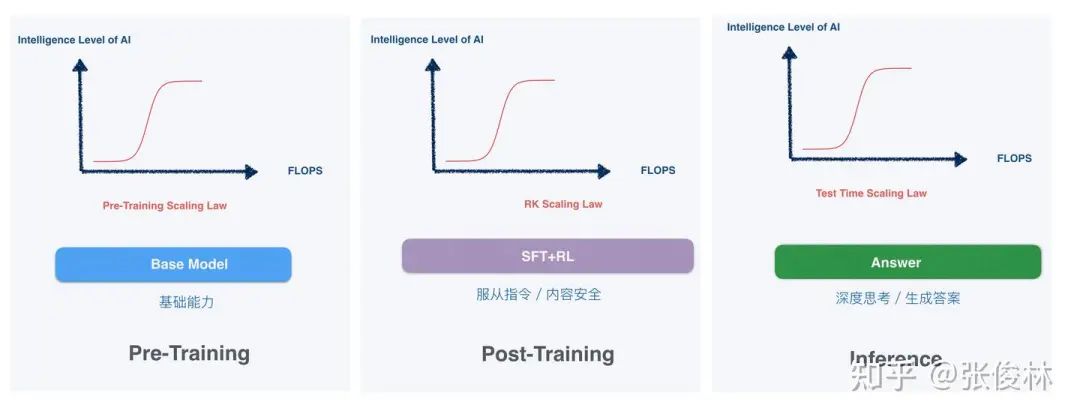
△ Source: Column article by Zhang Junlin, PhD, Institute of Software, Chinese Academy of Sciences
OpenAI's o1, released in September 2024, is considered a landmark marking the shift of Scaling Law to post-training and inference phases and remains the world's leading reasoning model. However, OpenAI has never disclosed its training methodology or details, and application costs remain high: o1 pro costs $200/month, and its inference speed is slow, seen as a major bottleneck for AI application development.
Most recent work in the AI community focuses on replicating o1's performance while reducing inference costs to enable broader applications. DeepSeek's milestone significance lies not only in drastically shortening the time for open-source models to catch up with top-tier closed-source models—nearly matching multiple o1 metrics within about three months—but more importantly, in uncovering the key breakthrough behind o1's capability leap and making it open-source.
An important overarching premise cannot be ignored: DeepSeek achieved this innovation by standing on the shoulders of giants. Viewing engineering techniques like "distillation" merely as taking shortcuts is too narrow-minded—this is more accurately a victory for open-source culture.
The ecosystem prosperity and open-source impact brought by DeepSeek have quickly become evident. Shortly after its surge in popularity, a new project by "AI godmother" Fei-Fei Li went viral: using Google's Gemini as the "teacher model" and fine-tuned Alibaba Qwen2.5 as the "student model," they trained a reasoning model s1 via distillation for less than $50, replicating the capabilities of both DeepSeek-R1 and OpenAI-o1.
NVIDIA is another telling case. Although its market cap plummeted approximately $600 billion overnight following the release of DeepSeek-R1—the largest single-day drop in history—it quickly rebounded the next day with a ~9% gain—the market still broadly anticipates strong demand driven by R1's advanced reasoning capabilities.
It's foreseeable that as players across the large model landscape absorb R1's capabilities, a wave of AI application innovation will soon follow.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News













