

Vitalik's new article: More than prediction markets, Polymarket could reshape information finance
TechFlow Selected TechFlow Selected
Vitalik's new article: More than prediction markets, Polymarket could reshape information finance
Predicting election outcomes is just the first application. The broader concept is that you can use finance as a way to coordinate incentives, thereby providing valuable information to your audience.
Author: Vitalik Buterin
Translation: 0xjs, Jinse Finance
One of the Ethereum applications that excites me most is prediction markets. In 2014, I wrote an article about futarchy, a prediction-based governance model conceived by Robin Hanson. As early as 2015, I was an active user and supporter of Augur (look, my name is in the Wikipedia article). I made $58,000 betting on the 2020 election. This year, I've been a close supporter and follower of Polymarket.
To many people, prediction markets mean betting on elections, and betting on elections means gambling—if it brings people enjoyment, great, but fundamentally, it's no more meaningful than buying random tokens on pump.fun. From this perspective, my interest in prediction markets might seem puzzling. Therefore, in this article, I aim to explain why this concept excites me. In short, I believe (i) even existing prediction markets are already very useful tools for the world, but additionally (ii) prediction markets are just one example of a broader, very powerful category with the potential to create better implementations of social media, science, news, governance, and other domains. I will call this category "info finance."
The Dual Nature of Polymarket: A Betting Site for Participants, a News Site for Everyone Else
Over the past week, Polymarket has been a highly effective source of information regarding the U.S. presidential election. Polymarket not only predicted Trump’s victory at 60/40 (while other sources were at 50/50, which in itself isn’t too impressive), but also demonstrated another key advantage: when results came in, while many experts and news outlets continued feeding their audiences false hope favoring Harris, Polymarket directly revealed the truth—Trump’s chances of winning exceeded 95%, and his probability of sweeping all branches of government surpassed 90%.
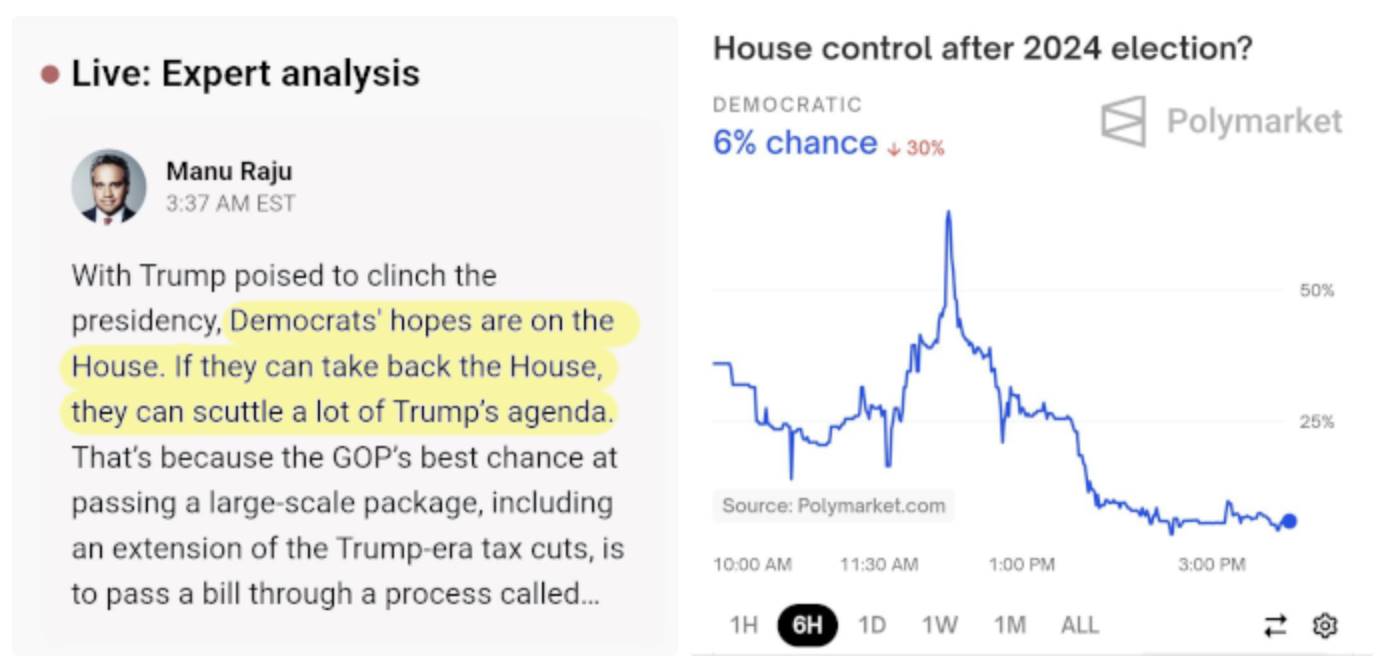
Both screenshots taken at 3:40 AM Eastern Time on November 6
But to me, this isn't even the best example of what makes Polymarket interesting. So let’s look at another case: Venezuela’s July election. The day after the election ended, I recall seeing out of the corner of my eye someone protesting the heavily manipulated outcome. At first, I didn’t pay much attention. I knew Maduro was already one of those “essentially dictators,” so I assumed, of course he would fake every election to retain power, of course there would be protests, and of course they would fail—unfortunately, like so many others had before. But then, while scrolling through Polymarket, I saw this:
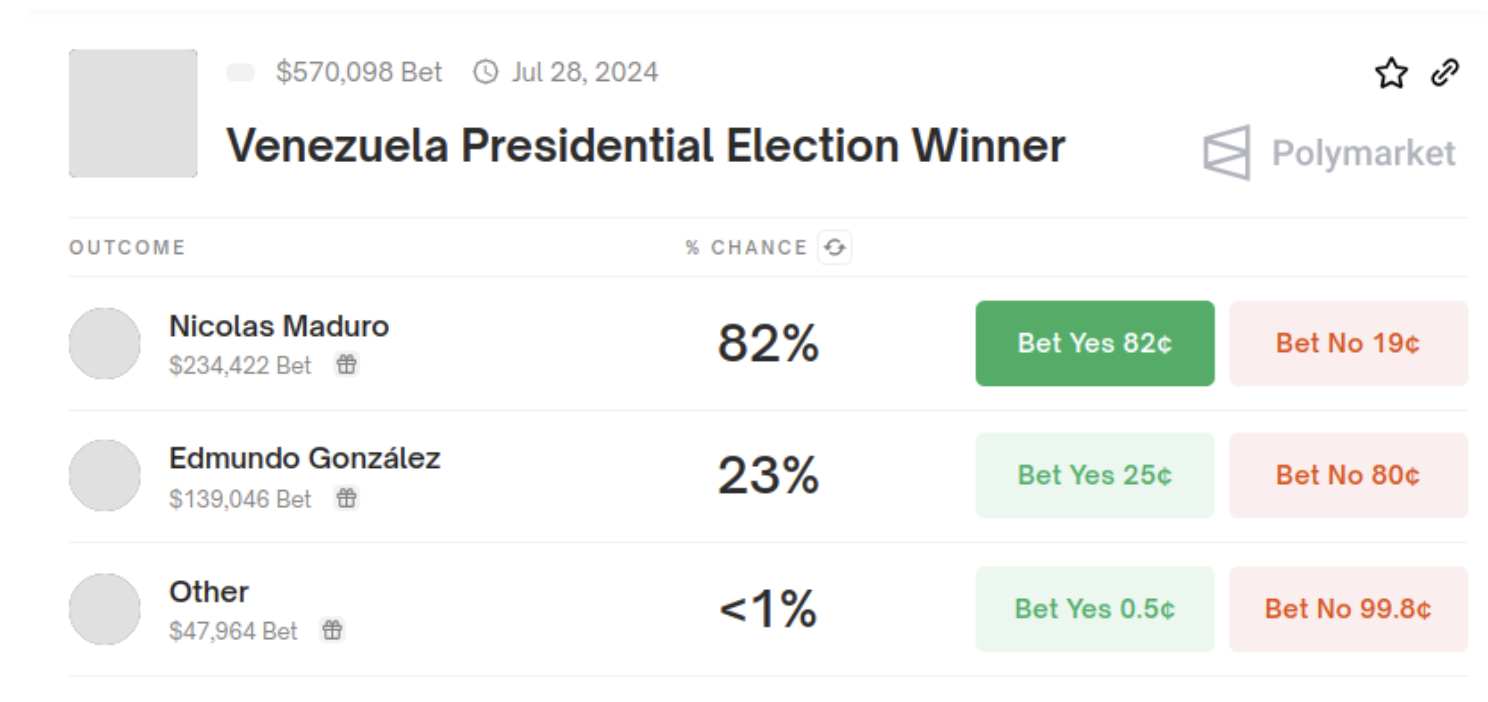
People were willing to put over a hundred thousand dollars on the line, betting that there was a 23% chance Maduro would be overthrown in this election. Now I started paying attention.
Of course, we know how this unfortunate situation ultimately turned out. In the end, Maduro did indeed remain in power. Yet the market made me realize that this time, the attempt to overthrow Maduro was serious. The protests were massive, the opposition executed an unexpectedly well-organized strategy, and clearly demonstrated to the world how fraudulent the election was. If I hadn’t received Polymarket’s initial signal—“this time, something is worth watching”—I wouldn’t have started paying attention at all.
You should never fully trust Polymarket betting charts: if everyone trusted them completely, anyone with enough money could manipulate the charts, and no one would dare bet against them. On the other hand, fully trusting news is also a bad idea. News has sensationalist incentives, exaggerating consequences for clicks. Sometimes this is justified, sometimes not. If you see a sensational article but then check the market and find the probability of the related event hasn’t changed at all, skepticism is warranted. Or, if you notice unexpectedly high or low probabilities in the market, or sudden unexpected shifts, that’s a signal to read the news and see what caused it. Conclusion: reading both news and betting charts together gives you far more information than relying on either alone.
Let’s reflect on what’s happening here. If you’re a gambler, you can place bets on Polymarket—it’s a betting site for you. If you’re not a gambler, you can read the betting charts—it’s a news site for you. You should never fully trust the betting charts, but personally, I’ve integrated chart-reading into my information-gathering workflow (alongside traditional media and social media), and it helps me gather more insight more efficiently.
The Broader Significance of Info Finance
Now we come to the important part: predicting election outcomes is just the first application. The broader concept is that you can use finance as a way to coordinate incentives in order to deliver valuable information to an audience. A natural reaction now might be: isn’t all finance fundamentally about information? Different participants make different buy/sell decisions because they have different views on what will happen in the future (aside from personal needs like risk preferences and hedging desires), and you can infer a lot about the world by reading market prices.
To me, info finance is exactly that—but structurally sound. Similar to the concept of structural correctness in software engineering, info finance is a discipline that requires you to (i) start with the fact you want to know, and then (ii) deliberately design a market to extract that information from participants in the optimal way.
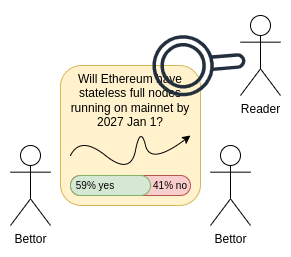
Info finance is a three-sided market: bettors make predictions, readers consume predictions. The market outputs forecasts about the future as a public good (because that is its intended purpose).
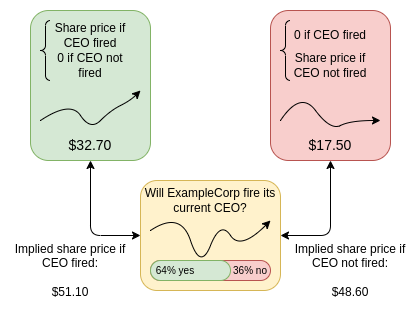
Prediction markets are one example: you want to know whether a specific future fact will occur, so you set up a market for people to bet on it. Another example is decision markets: you want to know whether decision A or decision B will lead to a better outcome according to some metric M. To achieve this, you set up a conditional market: you ask people to bet on (i) which decision will be chosen, (ii) the value of M if decision A is chosen (otherwise zero), and (iii) the value of M if decision B is chosen (otherwise zero). With these three variables, you can determine whether the market believes decision A or B is better for achieving M.
I expect AI (whether large language models or future technologies) to be one of the key technologies driving info finance over the next decade.
This is because many of the most interesting applications of info finance relate to “micro” questions: millions of small markets where each individual decision has relatively minor impact. In practice, low-volume markets often fail to function effectively: for experienced participants, spending time on detailed analysis just to earn a few hundred dollars in profit is not worthwhile. Many believe such markets cannot function without subsidies, since outside of the largest, most sensational topics, there aren’t enough naive traders for skilled ones to profit from. AI completely changes this equation, making it possible to obtain reasonably high-quality information even in markets with only $10 in trading volume. Even if subsidies are needed, the cost per question becomes very affordable.
Info Finance Needs Distilled Human Judgment
Judgment
Suppose you have a trusted human judgment mechanism—one that the entire community trusts in terms of legitimacy—but making judgments is slow and expensive. However, you want low-cost, real-time access to at least an approximation of this “expensive mechanism.” Here’s an idea proposed by Robin Hanson: whenever you need to make a decision, you create a prediction market forecasting what result the expensive mechanism would produce if invoked. You let the prediction market run and invest a small amount of capital to subsidize market makers.
99.99% of the time, you don’t actually invoke the expensive mechanism: perhaps you “reverse the trade” and return everyone’s stake, or simply pay everyone zero, or take the average price and treat it as ground truth based on whether it’s closer to 0 or 1. 0.01% of the time—perhaps randomly, perhaps for markets with the highest trading volume, perhaps a combination—you actually run the expensive mechanism and compensate participants accordingly.
This gives you a credible, neutral, fast, and cheap “distilled version” of your original highly trustworthy but costly mechanism (using “distilled” analogously to “knowledge distillation” in LLMs). Over time, this distilled mechanism roughly mirrors the behavior of the original—because only participants who help align the market with the true outcome will profit, while others lose money.
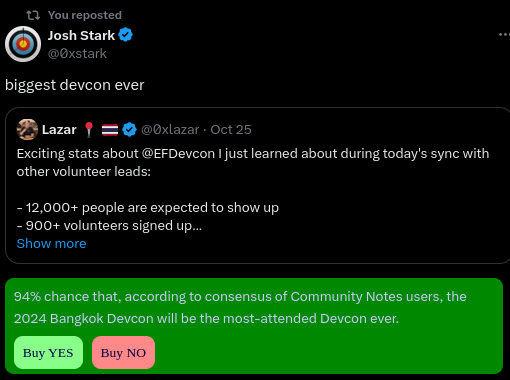
A possible model combining prediction markets with community notes.
This applies not only to social media but also to DAOs. A major problem with DAOs is the overwhelming number of decisions, causing most members to disengage. This leads either to widespread delegation—carrying risks of centralization and principal-agent failures common in representative democracies—or vulnerability to attacks. If actual voting in a DAO rarely occurs, and most decisions are instead determined by prediction markets (with outcomes forecasted by a combination of humans and AI), such a DAO might function well.
As we saw in the example of decision markets, info finance contains many promising paths for solving critical problems in decentralized governance—the key lies in balancing markets with non-market mechanisms: markets act as the “engine,” while other non-financialized trust mechanisms serve as the “steering wheel.”
Other Use Cases for Info Finance
Personal tokens—projects like Bitclout (now Deso) and friend.tech, which create tokens for individuals and make speculation easy—are part of what I call “primitive info finance.” They intentionally create market prices for specific variables (i.e., expectations about a person’s future reputation), but the exact information revealed by prices is too vague and subject to reflexivity and bubble dynamics. It may be possible to build improved versions of such protocols that address important issues like talent discovery, by more carefully designing token economics—particularly clarifying where their ultimate value comes from. Robin Hanson’s concept of “reputation futures” represents a possible end-state in this direction.
Advertising—the ultimate “expensive but trustworthy signal” is whether you actually purchase a product. Info finance based on such signals could help people decide what to buy.
Scientific peer review—the scientific community has long faced a “replication crisis,” where certain famous results become part of folk wisdom but ultimately fail to reproduce in new studies. We could use prediction markets to identify which results need re-examination. Before re-testing, such markets would also allow readers to quickly estimate how much trust to place in any given finding. Experiments based on this idea have already been conducted and appear successful so far.
Public goods funding—one of the main issues with Ethereum’s current public goods funding mechanisms is their “popularity contest” nature. Every contributor must run their own social media marketing campaign to gain recognition, making it hard for those unable to do so—or those playing more “background” roles—to receive significant funding. An attractive solution would be to try tracking the entire dependency graph: for each positive outcome, measure how much each project contributed, then for each of those projects, trace contributions further back, etc. The main challenge in such designs is determining edge weights in a way resistant to manipulation. After all, such manipulation already happens frequently. A distilled human judgment mechanism could help.
Conclusion
These ideas have been theorized for a long time: the earliest writings on prediction markets—and even decision markets—are decades old, and similar concepts in financial theory are even older. Yet I believe the current decade offers a unique opportunity, primarily for the following reasons:
Info finance addresses real-world trust problems. A shared concern of our era is the lack of knowledge—and worse, lack of consensus—about whom to trust in political, scientific, and business contexts. Info finance applications can help be part of the solution.
We now have scalable blockchains as a foundation. Until recently, fees were too high to truly implement these ideas. Now, they are no longer prohibitively expensive.
AI as a participant. Info finance was relatively difficult to scale when relying solely on human participation for each question. AI dramatically improves this, enabling effective markets even on small-scale questions. Many markets may involve a mix of AI and human participants, especially when the number of relevant questions suddenly increases from small to large.
To fully seize this opportunity, we should go beyond merely predicting elections and explore what else info finance can offer us.
Special thanks to Robin Hanson and Alex Tabarrok for feedback and comments.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














