

Galaxy Digital: Understanding the Intersection of Cryptocurrency and Artificial Intelligence
TechFlow Selected TechFlow Selected
Galaxy Digital: Understanding the Intersection of Cryptocurrency and Artificial Intelligence
The emergence of public blockchains is one of the most profound advances in the history of computer science, and the development of artificial intelligence will and already is having a profound impact on our world.
Written by: Lucas Tcheyan
Translated by: Block unicorn
Introduction
The emergence of public blockchains is one of the most profound advancements in the history of computer science. Meanwhile, artificial intelligence (AI) is already having—and will continue to have—a transformative impact on our world. If blockchain technology provides a new blueprint for transaction settlement, data storage, and system design, then AI represents a revolution in computing, analysis, and content delivery. Innovations in both fields are unlocking novel use cases that could accelerate adoption across both sectors in the coming years. This report explores the ongoing convergence between cryptocurrency and AI, focusing on emerging applications designed to bridge the gap between the two and harness their combined strengths. Specifically, it examines projects developing decentralized computing protocols, zero-knowledge machine learning (zkML) infrastructure, and AI agents.
Cryptocurrency offers AI a permissionless, trustless, and composable settlement layer. This unlocks use cases such as making hardware more accessible via decentralized computing systems, building AI agents capable of executing complex tasks involving value exchange, and creating identity and provenance solutions to combat Sybil attacks and deepfakes. In return, AI brings to crypto many of the same benefits we see in Web2—such as enhanced user and developer experiences (UX) through large language models (e.g., specialized versions of ChatGPT and Copilot)—and significantly improves smart contract functionality and automation potential. Blockchains provide the transparent, data-rich environment AI needs. However, blockchains also have limited computational capacity, which remains a primary obstacle to directly integrating AI models.
The driving forces behind experimentation and eventual adoption at the intersection of crypto and AI mirror those powering crypto’s most promising use cases: access to a permissionless, trustless coordination layer that facilitates better value transfer. Given the immense potential, stakeholders must understand the fundamental ways these technologies intersect.
Key Takeaways:
-
In the near term (6–12 months), integration between crypto and AI will be led by AI applications that enhance developer efficiency, smart contract auditability and security, and user accessibility. These integrations are not unique to crypto but improve on-chain developer and user experience.
-
As high-performance GPUs remain severely scarce, decentralized computing platforms are launching AI-optimized GPU offerings, providing tailwinds for adoption.
-
User experience and regulation remain barriers to attracting customers to decentralized computing. However, recent developments at OpenAI and ongoing regulatory scrutiny in the U.S. highlight the value proposition of permissionless, censorship-resistant, decentralized AI networks.
-
On-chain AI integration—particularly smart contracts capable of using AI models—requires advances in zkML and other methods for verifying off-chain computations. Lack of comprehensive tools, developer talent, and high costs remain adoption hurdles.
-
AI agents are well-suited for crypto, where users (or agents themselves) can create wallets to transact with services, other agents, or people—something impossible with traditional financial rails. For broader adoption, additional integration with non-crypto products will be necessary.
Terminology
Artificial Intelligence (AI) refers to using computation and machines to mimic human reasoning and problem-solving capabilities.
Neural Networks are a method for training AI models. They process inputs through discrete algorithmic layers, refining them until desired outputs are produced. Neural networks consist of equations with adjustable weights that influence output. Training requires significant data and computation to ensure accuracy. This is one of the most common approaches to AI model development (e.g., ChatGPT uses neural networks based on Transformers).
Training is the process of developing neural networks and other AI models. It involves feeding vast datasets so models learn to interpret inputs correctly and generate accurate outputs. During training, model weights are continuously adjusted until satisfactory results are achieved. Training is extremely costly—ChatGPT, for example, used tens of thousands of its own GPUs. Teams with fewer resources typically rely on specialized cloud providers like AWS, Azure, and Google Cloud.
Inference refers to the actual use of an AI model to produce outputs or results (e.g., using ChatGPT to draft an outline for a paper on the intersection of crypto and AI). Inference occurs throughout the training process and in final products. While less computationally intensive than training, inference can still be expensive due to ongoing compute demands.
Zero-Knowledge Proofs (ZKPs) allow claims to be verified without revealing underlying information. In crypto, ZKPs are valuable for two main reasons: 1) privacy and 2) scalability. For privacy, they enable users to transact without disclosing sensitive details (e.g., how much ETH is in a wallet). For scalability, they allow off-chain computations to be proven on-chain faster than re-executing them, enabling blockchains and apps to run computations cheaply off-chain and verify them on-chain. For more on ZKPs and their role in Ethereum Virtual Machines, see Christine Kim’s report “zkEVMs: The Future of Ethereum Scalability.”
AI/Crypto Market Map

Projects at the intersection of AI and crypto are still building the foundational infrastructure needed to support large-scale on-chain AI interactions.
Decentralized computing markets are emerging to supply the massive physical hardware—primarily graphics processing units (GPUs)—required to train and run AI models. These two-sided markets connect providers and renters of computing power, facilitating value transfer and computation verification. Within decentralized computing, several subcategories are emerging with added functionalities. Beyond bilateral markets, this report also covers machine learning training providers offering verifiable training and fine-tuning outputs, and projects aiming to connect computing and model generation for AI—often referred to as intelligent incentive networks.
zkML is an emerging focus area for projects aiming to deliver verifiable model outputs on-chain in an economically viable and timely manner. These projects enable applications to handle heavy off-chain computations and publish verifiable proofs on-chain, confirming the integrity and accuracy of off-chain workloads. Current zkML implementations are expensive and time-consuming, yet increasingly adopted—evident in growing integration between zkML providers and DeFi/gaming applications seeking to leverage AI models.
Abundant computing supply and the ability to verify on-chain computations open the door for on-chain AI agents. Agents are trained models capable of acting autonomously on behalf of users. They offer significant potential to enhance on-chain experiences—enabling users to execute complex transactions simply by chatting with a bot. However, agent-focused projects are currently prioritizing infrastructure and tooling development to enable fast and easy deployment.
Decentralized Computing
Overview
AI requires massive computation for model training and inference. Over the past decade, as models grow increasingly complex, computational demands have risen exponentially. For instance, OpenAI observed that from 2012 to 2018, the compute required for its models doubled every three and a half months—up from doubling every two years. This surge has driven demand for GPUs, leading some crypto miners to repurpose their GPUs for cloud computing services. As competition for compute intensifies and costs rise, several projects are leveraging crypto to offer decentralized computing solutions. They provide on-demand computing at competitive prices, allowing teams to train and run models affordably—though sometimes at the cost of performance or security.
Cutting-edge GPUs (e.g., those made by Nvidia) are in high demand. In September, Tether acquired a stake in German Bitcoin miner Northern Data, reportedly spending $420 million on 10,000 H100 GPUs—one of the most advanced GPUs for AI training. Lead times for top-tier hardware can exceed six months. Worse, companies are often forced into long-term contracts for compute they may never fully utilize, resulting in available capacity being locked away. Decentralized computing systems help solve these inefficiencies by creating secondary markets where owners can immediately rent out idle capacity, unlocking new supply.
Beyond competitive pricing and accessibility, a key value proposition of decentralized computing is censorship resistance. Leading-edge AI development is increasingly dominated by big tech firms with unparalleled access to compute and data. The 2023 AI Index Annual Report highlighted a key trend: industry now leads academia in AI model development, concentrating control among a few tech giants. This raises concerns about their outsized influence over the norms and values embedded in AI models—especially as these companies lobby for regulations that restrict AI development beyond their control.
Verticals in Decentralized Computing
Several decentralized computing models have emerged in recent years, each with distinct focuses and trade-offs.

General-Purpose Computing
Projects like Akash, io.net, iExec, and Cudos are decentralized computing platforms that offer or plan to offer dedicated access to computing for AI training and inference, in addition to general-purpose computing and data solutions.
Akash is currently the only fully open-source "supercloud" platform. It is a proof-of-stake network built using the Cosmos SDK. AKT is Akash’s native token, used for payments, securing the network, and incentivizing participation. Akash launched its first mainnet in 2020, focusing on a permissionless cloud marketplace initially offering storage and CPU rentals. In June 2023, Akash launched a GPU-focused testnet, followed by a GPU mainnet in September, enabling users to rent GPUs for AI training and inference.
Two main participants exist in the Akash ecosystem: tenants and providers. Tenants are users seeking to rent computing resources. Providers supply the compute. To match tenants and providers, Akash uses a reverse auction mechanism. Tenants submit their requirements—including hardware type, server location, and maximum price. Providers then bid, and the lowest bidder wins the job.
Validators maintain network integrity. The validator set is capped at 100 nodes, with plans to gradually increase. Anyone can become a validator by staking more AKT than the current minimum. AKT holders can delegate their tokens to validators. Transaction fees and block rewards are distributed in AKT. Additionally, for each lease, the Akash network earns a "take rate" fee determined by the community, which is redistributed to AKT holders.
Secondary Markets
Decentralized computing markets aim to address inefficiencies in existing compute markets. Supply constraints cause companies to hoard excess compute, while long-term contracts with centralized cloud providers further limit availability. Decentralized platforms unlock new supply, allowing anyone worldwide with spare compute to become a provider.
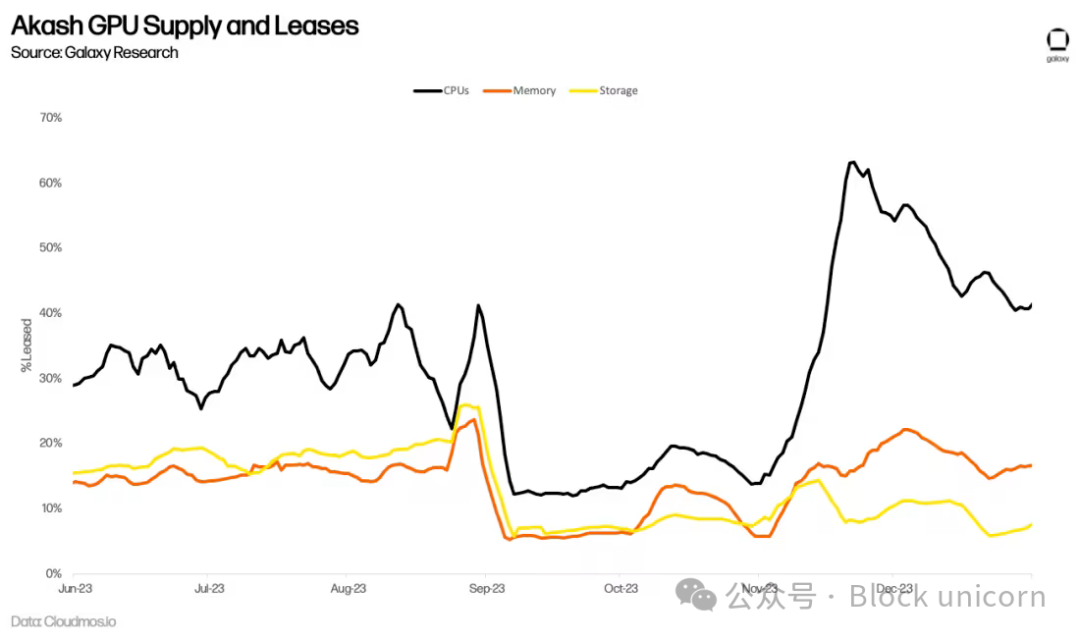
Whether the surge in GPU demand for AI training translates into sustained long-term usage on Akash remains to be seen. For example, Akash has long offered a CPU market with services similar to centralized alternatives at 70–80% discounts. Yet lower prices haven’t driven significant adoption. Active leases on the network have plateaued, averaging only 33% compute, 16% memory, and 13% storage by Q2 2023. While these are impressive on-chain metrics (for comparison, Filecoin, a leading storage provider, had 12.6% utilization in Q3 2023), they indicate supply still exceeds demand.
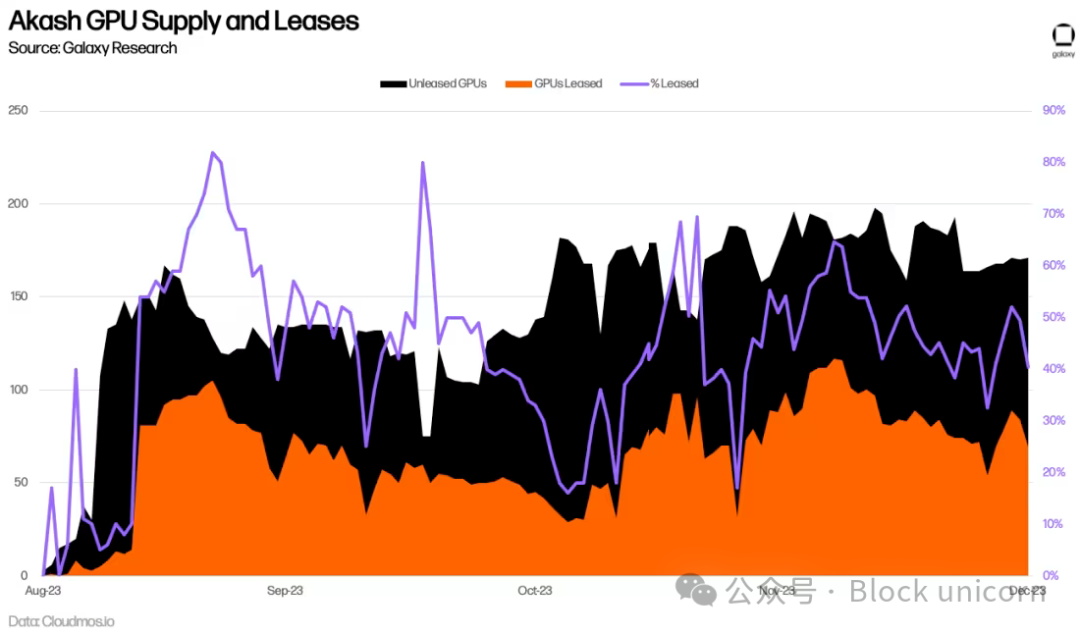
More than six months after Akash launched its GPU network, it's too early to accurately assess long-term adoption. So far, GPUs have averaged 44% utilization—higher than CPUs, memory, and storage—indicating stronger demand. This is primarily driven by demand for top-tier GPUs like the A100, over 90% of which are already rented.
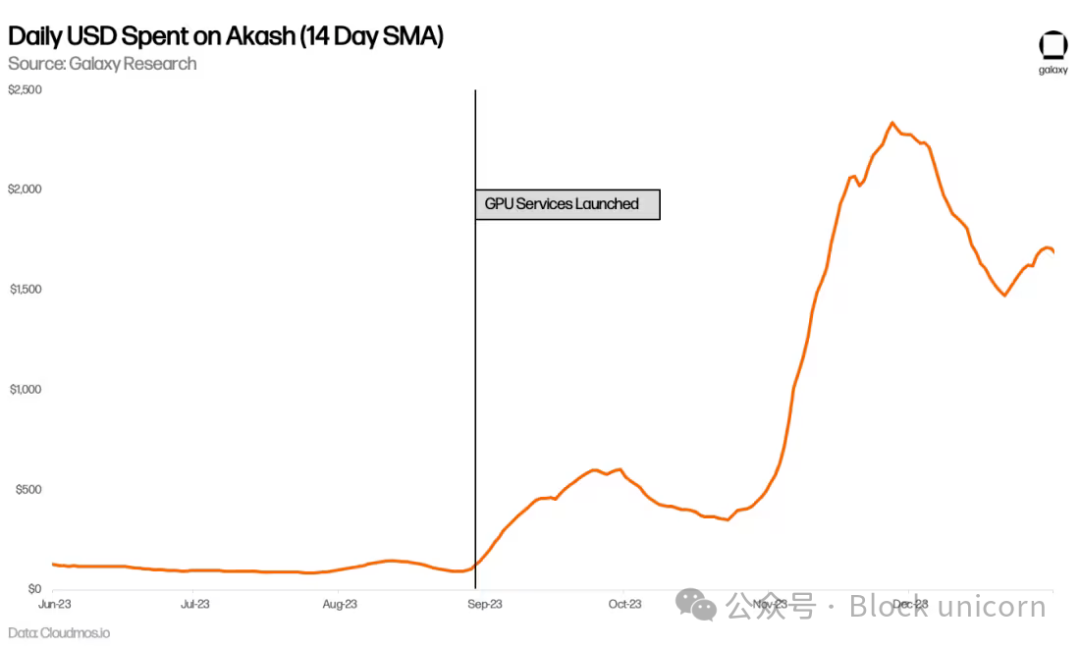
Daily spending on Akash has also increased, nearly doubling compared to pre-GPU levels. This is partly due to higher usage of other services, especially CPU, but primarily driven by new GPU demand.
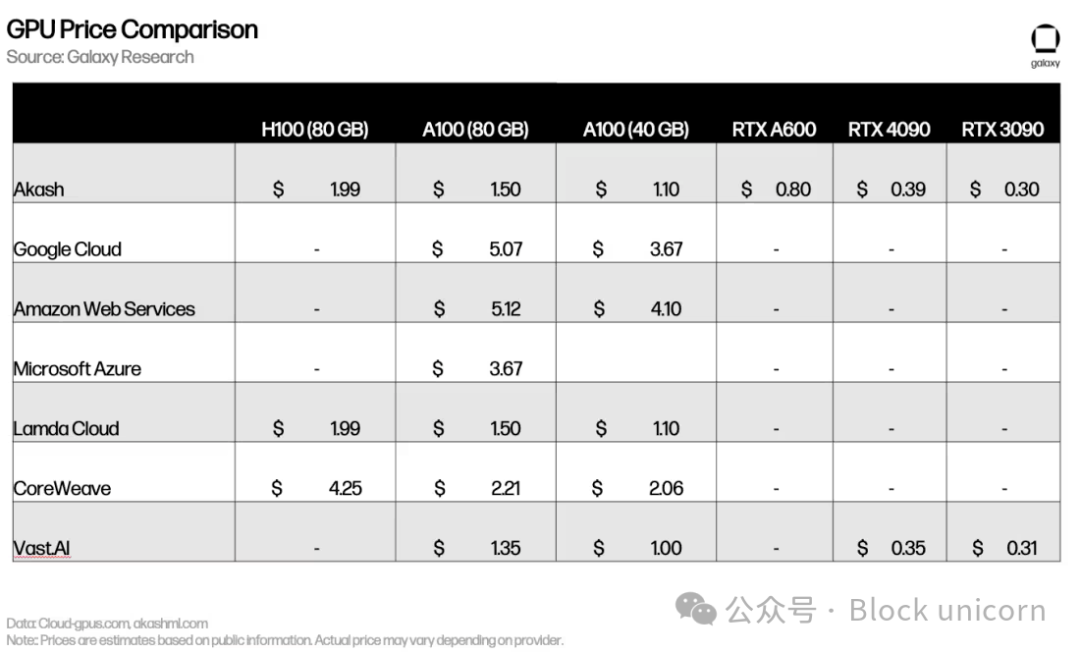
Pricing is comparable to—or in some cases higher than—centralized competitors like Lambda Cloud and Vast.ai. High demand for top-end GPUs (e.g., H100 and A100) means most owners have little incentive to list on competitively priced markets.
While initial signals are positive, adoption barriers remain (discussed further below). Decentralized computing networks need to do more to generate both demand and supply. Teams are experimenting with strategies to attract new users. For example, in early 2024, Akash passed Proposal 240, increasing AKT emissions for GPU providers and incentivizing more supply—especially for high-end GPUs. The team is also developing proof-of-concept models to showcase real-time network capabilities. Akash is training its own base model and has launched chatbot and image-generation products powered by Akash GPUs. Similarly, io.net has developed a stable diffusion model and is rolling out new features to better demonstrate network performance and scale.
Decentralized Machine Learning Training
Beyond general-purpose computing platforms catering to AI workloads, a new category of specialized AI GPU providers focused on machine learning model training is emerging. Gensyn, for example, aims to "coordinate power and hardware to build collective intelligence," operating on the principle that "if someone wants to train something and someone else is willing to train it, that training should be allowed to happen."
The protocol involves four main actors: Submitters, Solvers, Validators, and Challengers. Submitters send training tasks to the network, including the training objective, model, and dataset. As part of submission, they must prepay for the estimated compute required by Solvers.
Once submitted, tasks are assigned to Solvers who perform the actual training. Solvers then submit completed tasks to Validators, who check that training was done correctly. Challengers ensure Validators act honestly. To incentivize Challenger participation, Gensyn plans to periodically introduce deliberate errors, rewarding Challengers who catch them.
Beyond providing compute for AI workloads, Gensyn’s key innovation lies in its validation system—still under development. Verifying that external GPU providers correctly execute computations (i.e., ensuring models are trained as intended) is essential. Gensyn tackles this with a novel approach combining "probabilistic proofs of learning, graph-based exact protocols, and Truebit-style incentive games." This optimistic execution model allows Validators to confirm correct model execution without re-running it entirely—a costly and inefficient alternative.
Beyond its innovative validation, Gensyn claims significant cost advantages—offering ML training up to 80% cheaper than AWS, while outperforming similar projects like Truebit in testing.

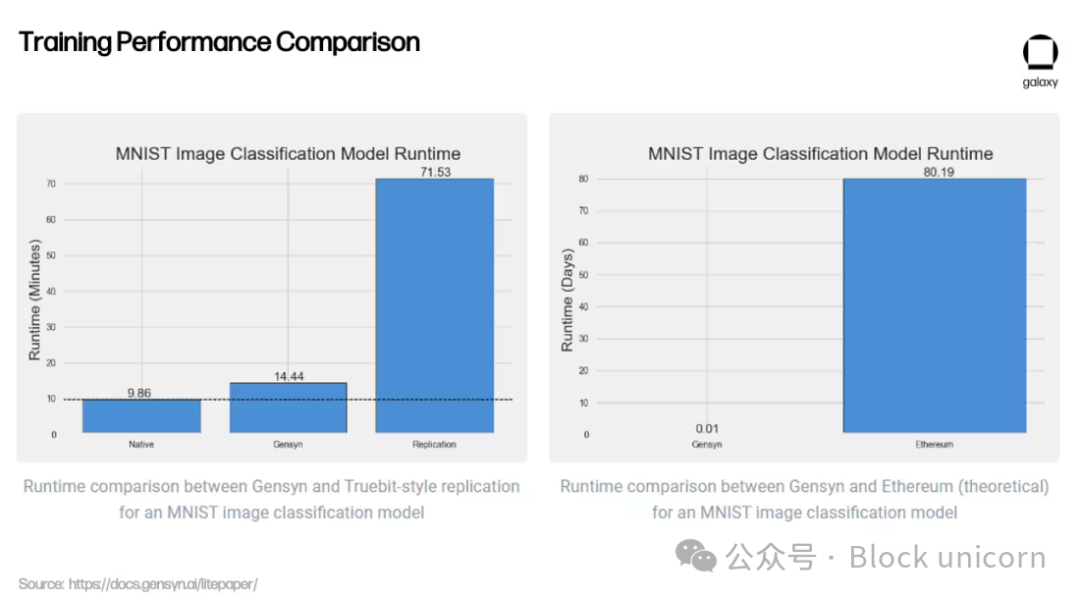
Whether these early results can scale on a decentralized network remains to be seen. Gensyn aims to tap excess compute from small data centers, retail users, and eventually even mobile devices like smartphones. However, as the Gensyn team acknowledges, relying on heterogeneous hardware introduces new challenges.
For centralized providers like Google Cloud and Coreweave, computation is expensive, but inter-compute communication (bandwidth and latency) is cheap—they’re optimized for rapid hardware communication. Gensyn flips this: by letting anyone globally provide GPUs, it reduces compute costs but increases communication overhead, as the network must now coordinate jobs across geographically dispersed, heterogeneous hardware. Gensyn hasn’t launched yet, but it serves as a compelling proof of concept for what might be possible in decentralized ML training.
Decentralized General Intelligence
Decentralized computing platforms also open new possibilities for designing AI creation methods. Bittensor, a decentralized computing protocol built on Substrate, asks: "How can we turn AI into a collaborative endeavor?" Bittensor aims to decentralize and commoditize AI generation. Launched in 2021, it seeks to harness collaborative machine learning models to iteratively improve AI quality.
Inspired by Bitcoin, Bittensor’s native token TAO has a fixed supply of 21 million and a four-year halving cycle (first halving in 2025). Instead of proof-of-work for random numbers and block rewards, Bittensor uses "proof-of-intelligence," requiring miners to run models and generate outputs in response to inference requests.
Incentivizing Intelligence
Bittensor initially relied on a Mixture-of-Experts (MoE) model. Rather than using one generalized model, MoE routes inference requests to the most accurate model for a given input type—like hiring different specialists for various aspects of home construction (architects, engineers, painters, etc.). Applied to ML, MoE leverages different models based on input. As co-founder Ala Shaabana explained, it’s like "talking to a room full of smart people and getting the best answer, rather than talking to one person." Due to challenges in routing, synchronization, and incentives, this approach has been paused until further development.
Two main actors exist in Bittensor: Validators and Miners. Validators send inference requests to Miners, evaluate responses, and rank them by quality. To ensure reliable rankings, Validators earn a "vtrust" score based on how closely their rankings align with others’. Higher vtrust yields more TAO emissions, incentivizing consensus over time.
Miners (also called servers) run the actual ML models. They compete to deliver the most accurate outputs for queries, earning more TAO for better performance. Miners can source models however they choose—for example, training models on Gensyn to earn TAO on Bittensor.
Today, most interactions occur directly between Validators and Miners. Validators submit inputs, receive outputs, rank Miners, and submit rankings to the network.
This interaction—Validators using PoS, Miners using a form of PoW called Proof-of-Model—is known as Yuma Consensus. It incentivizes Miners to produce high-quality outputs and Validators to rank accurately, forming the network’s consensus mechanism.
Subnets and Applications
Current Bittensor interactions mainly involve Validators submitting queries and evaluating Miner outputs. But as Miner quality improves and overall network intelligence grows, Bittensor plans to add an application layer, enabling developers to build apps querying the network.
In October 2023, Bittensor introduced subnets via the Revolution upgrade—a major step toward this goal. Subnets are separate networks incentivizing specific behaviors. Revolution opened subnet creation to all. Within months, over 32 subnets launched, covering text prompts, web scraping, image generation, and storage. As subnets mature, creators will develop app integrations, enabling teams to build apps querying specific subnets. Some apps (chatbots, image generators, Twitter bots, prediction markets) exist today, but lack formal incentives for Validators to accept and forward queries beyond foundation grants.
To illustrate, here’s an example of how Bittensor might function post-application integration:
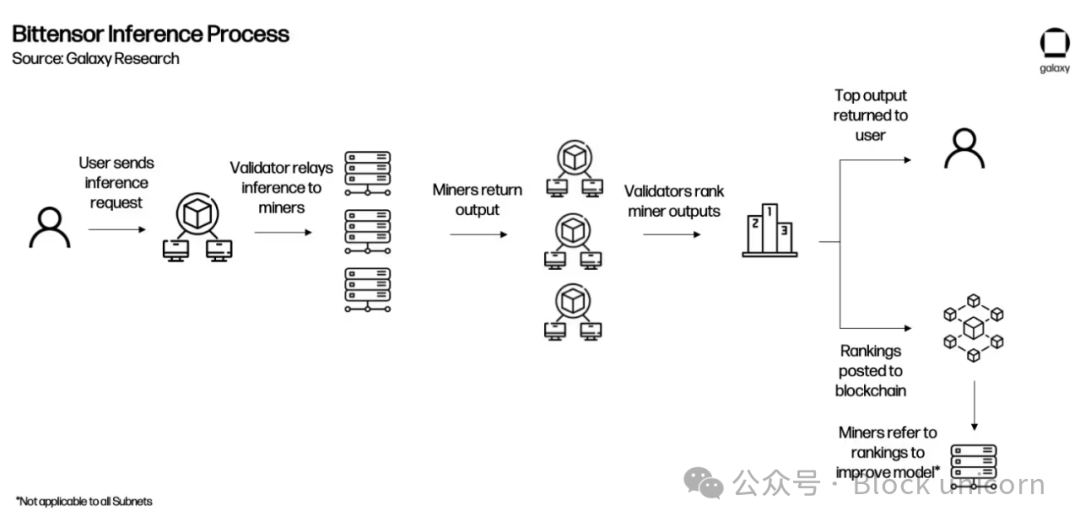
Subnets earn TAO based on performance assessed by the root network. The root network sits atop all subnets, managed by the 64 largest subnet validators via stake. Root validators rank subnets and periodically distribute TAO emissions—making subnets function like miners for the root network.
Bittensor Outlook
Bittensor faces growing pains as it scales to incentivize intelligence across multiple subnets. Miners constantly devise new attacks to earn more TAO—e.g., slightly modifying high-rated inference outputs and submitting multiple variants. Governance proposals affecting the entire network can only be submitted and implemented by the Triumvirate, composed solely of Opentensor Foundation stakeholders (though proposals require approval from the Bittensor Senate, made of Bittensor validators). Tokenomics are being revised to better incentivize TAO use across subnets. The project has gained rapid notoriety for its unique approach—HuggingFace’s CEO recently suggested Bittensor integrate its resources into the platform.
In a recent article titled "Bittensor Paradigm," core developers outlined a vision for Bittensor to eventually become "agnostic to what is measured." Theoretically, this could let Bittensor develop subnets incentivizing any behavior backed by TAO. Significant practical limitations remain—most notably, proving such networks can scale to diverse processes and that incentives drive progress beyond centralized alternatives.
Building a Decentralized Compute Stack for AI Models
The above sections provide a deep overview of various decentralized AI computing protocols under development. In their early stages, they lay the groundwork for an ecosystem that could eventually foster "AI building blocks," akin to DeFi’s "money legos." The composability of permissionless blockchains enables each protocol to build atop another, creating a more comprehensive decentralized AI ecosystem.
For example, here’s one way Akash, Gensyn, and Bittensor could interact to fulfill an inference request:
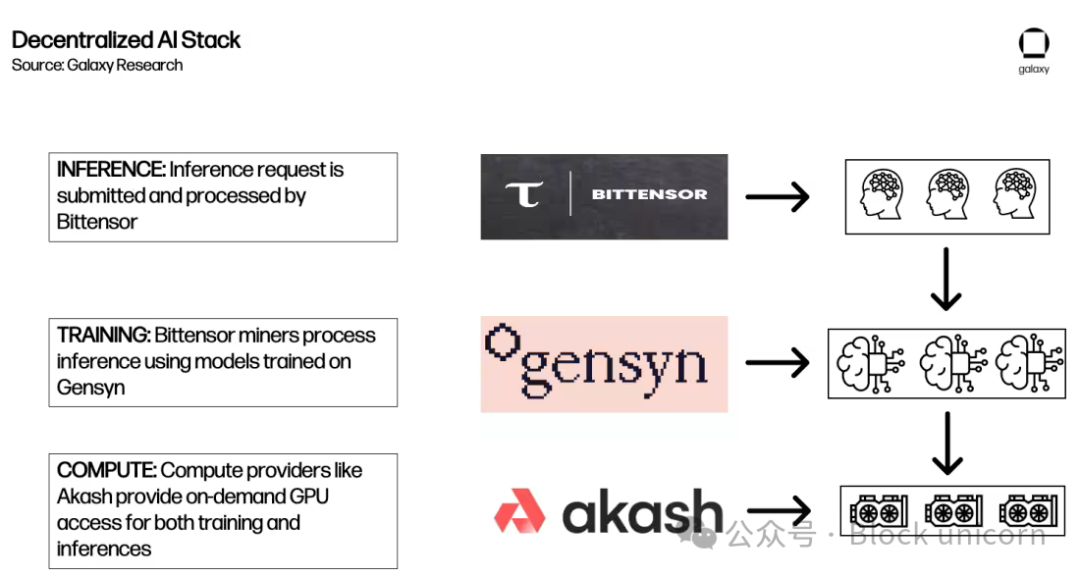
To be clear, this is merely an illustrative example of a possible future—not representative of current ecosystems, partnerships, or likely outcomes. Interoperability limits and other considerations described below greatly constrain integration possibilities today. Moreover, fragmented liquidity and the need to use multiple tokens could harm UX—a concern raised by founders of both Akash and Bittensor.
Other Decentralized Products
Beyond compute, several other decentralized infrastructure services have launched to support crypto’s emerging AI ecosystem. Listing all is beyond this report’s scope, but notable examples include:
-
Ocean: A decentralized data marketplace. Users create data NFTs representing their data and sell access via data tokens. This lets users monetize and retain sovereignty over their data while giving AI teams access to training data.
-
Grass: A decentralized bandwidth market. Users sell excess bandwidth to AI companies scraping web data. Built on Wynd Network, it enables individuals to monetize bandwidth while giving buyers more diverse perspectives on online content (since internet access is usually tailored by IP address).
-
HiveMapper: Building a decentralized mapping product using data collected from everyday drivers. HiveMapper uses AI to analyze dashboard camera images and rewards users with tokens for helping fine-tune models via Reinforced Human Learning Feedback (RHLF).
Overall, these point to nearly infinite opportunities to explore decentralized market models supporting AI models or building surrounding infrastructure. Most remain in proof-of-concept stages, requiring further R&D to prove scalable operation at levels needed for comprehensive AI services.
Outlook
Decentralized computing products are still in early development. They’ve just begun offering cutting-edge compute capable of training the most powerful AI models in production. To gain meaningful market share, they must demonstrate tangible advantages over centralized alternatives. Potential catalysts for broader adoption include:
-
GPU Supply/Demand. GPU scarcity amid rapidly growing compute demand is fueling an arms race. At times, OpenAI has restricted platform access due to GPU limits. Platforms like Akash and Gensyn can offer cost-competitive alternatives for teams needing high-performance computing. The next 6–12 months present a unique opportunity for decentralized providers to attract users forced to consider decentralized options due to limited market access. Combined with increasingly capable open-source models like Meta’s LLaMA2, users no longer face the same barriers to deploying effective fine-tuned models—making compute the primary bottleneck. Yet platform existence alone doesn’t guarantee sufficient supply or demand. Procuring high-end GPUs remains difficult, and cost isn’t always the main driver. These platforms must quickly demonstrate real benefits—whether cost, censorship resistance, uptime, resilience, or accessibility—to build sticky users. They must act fast—GPU infrastructure investment is accelerating.
-
Regulation. Regulation remains a headwind for decentralized computing. Short-term uncertainty exposes suppliers and users to risks. What if a supplier provides compute or a buyer unknowingly purchases from a sanctioned entity? Users may hesitate to adopt decentralized platforms lacking centralized oversight. Protocols attempt to mitigate concerns by adding controls or filters limiting access to known providers (e.g., requiring KYC). But stronger methods balancing privacy and compliance are needed. We may soon see KYC-compliant platforms restricting protocol access to address this. Additionally, discussions around new U.S. regulatory frameworks—best exemplified by the Executive Order on Safe, Secure, and Trustworthy AI—highlight potential regulations that could further restrict GPU access.
-
Censorship. Regulation cuts both ways—decentralized computing products can benefit from efforts to restrict AI access. Beyond executive orders, OpenAI founder Sam Altman testified before Congress advocating licensing for AI development. Discussions on AI regulation are just beginning, but any attempts to restrict access or censor AI capabilities could accelerate adoption of decentralized platforms free from such barriers. The November leadership turmoil at OpenAI further illustrates the risks of entrusting decisions over the world’s most powerful AI models to a select few. Moreover, all AI models inevitably reflect the biases of their creators—intentionally or not. One way to reduce bias is to make models as open as possible for fine-tuning and training, ensuring global access to diverse models and perspectives.
-
Data Privacy. When integrated with external data and privacy solutions empowering user data sovereignty, decentralized computing could become more attractive than centralized alternatives. Samsung learned this the hard way when engineers used ChatGPT for chip design, inadvertently leaking sensitive data. Phala Network and iExec offer SGX secure enclaves to protect user data, and ongoing research in fully homomorphic encryption could further unlock privacy-preserving decentralized computing. As AI integrates deeper into life, users will increasingly value running models on privacy-protecting applications. They’ll also need services supporting data composability—enabling seamless transfer of data between models.
-
User Experience (UX). UX remains a major barrier to broader adoption of all crypto applications and infrastructure. This holds true for decentralized computing—and in some cases worsens, as developers must understand both crypto and AI. Improvements are needed—from simplifying onboarding to abstracting blockchain interactions—so users get outputs matching current market leaders. That many functional decentralized computing protocols offering cheaper alternatives struggle to gain regular usage underscores this challenge.
Smart Contracts and zkML
Smart contracts are core building blocks of any blockchain ecosystem. They automatically execute under predefined conditions, reducing or eliminating reliance on trusted third parties—enabling complex dApps like those in DeFi. Yet smart contract functionality remains limited, constrained by preset parameters that require updates.
For example, a lending/borrowing protocol’s smart contract includes rules for liquidating positions based on loan-to-value ratios. While useful in static environments, in dynamic risk scenarios these contracts must constantly update to adapt—posing challenges for contracts not managed centrally. DAOs relying on decentralized governance may react too slowly to systemic risks.
Integrating AI—specifically machine learning models—into smart contracts could enhance functionality, security, and efficiency while improving UX. However, these integrations carry added risks—ensuring the underlying models won’t be exploited or misinterpret edge cases (which are hard to train due to rare data inputs) remains unproven.
Zero-Knowledge Machine Learning (zkML)
Machine learning requires heavy computation to run complex models, making direct on-chain execution prohibitively expensive. For example, a DeFi protocol offering yield optimization via AI would struggle to run the model on-chain without exorbitant gas fees. One solution is scaling base-layer blockchain compute—but this increases demands on validators, potentially compromising decentralization. Instead, some projects explore zkML to verify outputs trustlessly without intensive on-chain computation.
A common use case for zkML is when a user needs someone to run data through a model and verify the counterparty actually used the correct model. Perhaps a developer uses a decentralized compute provider to train a model and worries the provider might cut corners—using a cheaper model with nearly imperceptible output differences. zkML lets the provider run data through their model and generate an on-chain verifiable proof confirming correct output for a given input. Here, the model provider gains an advantage: offering their model without revealing the underlying weights.
The reverse is also possible. If a user wants to run a model on private data—e.g., medical records or proprietary business info—but doesn’t want the model provider to access their data—they can run the model locally, then prove they executed the correct model. By overcoming daunting computational limits, zkML vastly expands the design space for integrating AI with smart contracts.
Infrastructure and Tools
Given zkML’s early stage, development focuses on building infrastructure and tools to convert models and outputs into on-chain verifiable proofs—abstracting as much zero-knowledge complexity as possible.
EZKL and Giza are two projects building such tools by generating verifiable proofs of ML model execution. Both help teams build ML models that produce results in a format that can be trusted and verified on-chain. They use the Open Neural Network Exchange (ONNX) to convert models written in standard languages like TensorFlow and PyTorch into a standardized format, then output versions that generate zk proofs during execution. EZKL is open-source and produces zk-SNARKs; Giza is closed-source and produces zk-STARKs. Both are currently EVM-compatible only.
Over recent months, EZKL has made significant progress enhancing zkML solutions—focusing on lowering costs, improving security, and speeding up proof generation. For example, in November 2023, EZKL integrated a new open-source GPU library, reducing aggregate proof time by 35%. In January, EZKL launched Lilith, a software solution enabling integration with high-performance computing clusters and concurrent job orchestration when using EZKL proofs. Giza stands out by not only providing tools for verifiable ML models but also planning a web3 equivalent of Hugging Face—a user marketplace for zkML collaboration and model sharing, eventually integrating decentralized compute. In January, EZKL published a benchmark comparing performance across EZKL, Giza, and RiscZero (described below). EZKL demonstrated faster proof times and lower memory usage.
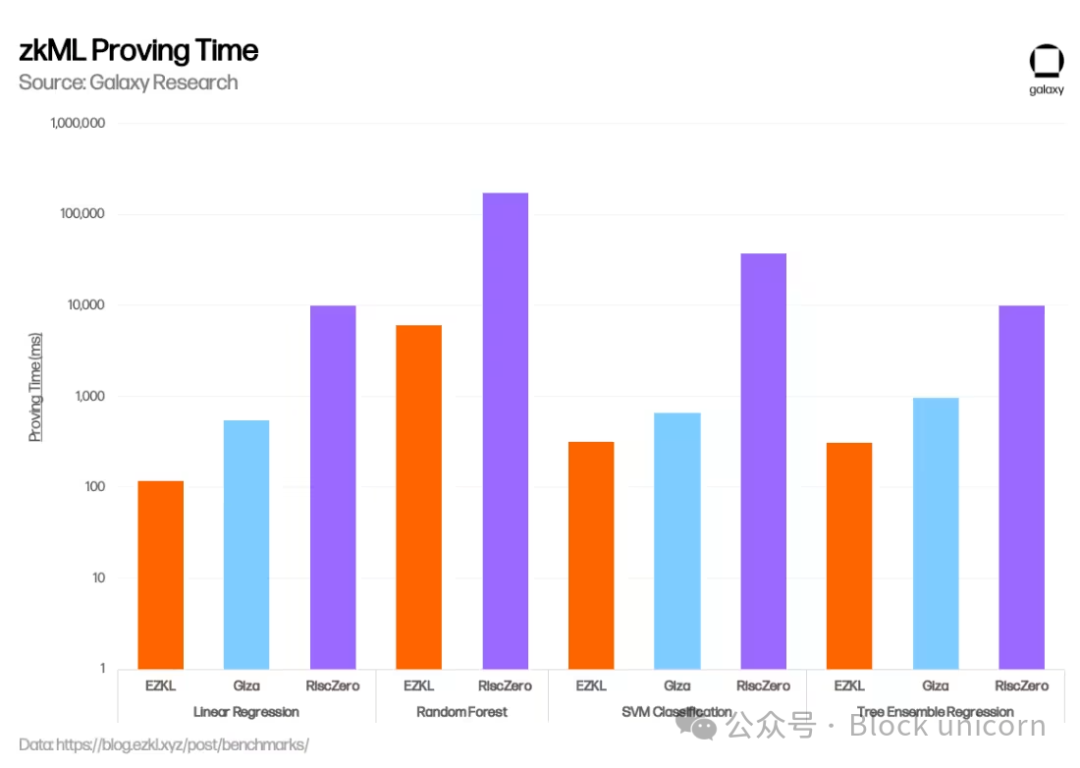

Modulus Labs is also developing a new zk-proof technique customized for AI models. Their paper, “Intelligent Cost” (a nod to the high cost of running AI on-chain), benchmarks existing zk-proof systems to
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News










