

a16z: Triển khai mô hình ngôn ngữ lớn đồng nghĩa với việc “mất trí nhớ”— liệu “học liên tục” có thể phá vỡ vòng luẩn quẩn này hay không?
Tuyển chọn TechFlowTuyển chọn TechFlow
a16z: Triển khai mô hình ngôn ngữ lớn đồng nghĩa với việc “mất trí nhớ”— liệu “học liên tục” có thể phá vỡ vòng luẩn quẩn này hay không?
Điểm đột phá nằm ở việc để mô hình thực hiện huấn luyện sau khi triển khai—chính là những yếu tố làm nên sức mạnh của mô hình: nén dữ liệu, trừu tượng hóa và học tập.
Tác giả: Malika Aubakirova, Matt Bornstein
Biên dịch: TechFlow
Giới thiệu từ TechFlow: Các mô hình ngôn ngữ lớn (LLM) sau khi huấn luyện xong thường bị “đóng băng”, và sau khi triển khai chỉ có thể duy trì hoạt động nhờ các “miếng vá” bên ngoài như cửa sổ ngữ cảnh (context window), truy xuất-tăng cường-sinh (RAG), v.v. Về bản chất, chúng giống hệt bệnh nhân mắc chứng mất trí nhớ trong phim Memento — có khả năng truy xuất thông tin nhưng không thực sự học được điều mới nào. Hai đối tác tại a16z đã hệ thống hóa toàn diện hướng nghiên cứu tiên phong mang tên “học liên tục” (continual learning), phân tích ba con đường tiếp cận — dựa trên ngữ cảnh, mô-đun và cập nhật trọng số — nhằm làm rõ lĩnh vực công nghệ này, vốn có tiềm năng tái định nghĩa ngưỡng khả năng của AI.
Trong bộ phim Memento của đạo diễn Christopher Nolan, nhân vật chính Leonard Shelby sống trong một hiện tại rời rạc. Chấn thương não khiến anh mắc chứng mất trí nhớ thuận chiều (anterograde amnesia), không thể hình thành ký ức mới. Cứ vài phút một lần, thế giới của anh lại khởi động lại, bị giam cầm trong khoảnh khắc “hiện tại vĩnh cửu”: không nhớ điều vừa xảy ra, cũng chẳng biết điều gì sẽ đến sau. Để tồn tại, anh xăm chữ lên người, chụp ảnh Polaroid, dùng những công cụ ngoại vi này thay thế chức năng ghi nhớ mà bộ não không còn đảm nhiệm được.
Các mô hình ngôn ngữ lớn cũng sống trong một “hiện tại vĩnh cửu” tương tự. Sau khi huấn luyện kết thúc, khối lượng kiến thức khổng lồ bị đóng băng trong các tham số; mô hình không thể hình thành ký ức mới, cũng không thể cập nhật tham số dựa trên kinh nghiệm mới. Để bù đắp thiếu sót này, chúng ta dựng cho nó hàng loạt giàn giáo: lịch sử trò chuyện đóng vai giấy ghi chú ngắn hạn, hệ thống truy xuất hoạt động như cuốn sổ tay bên ngoài, lời nhắc hệ thống (system prompt) giống như những dòng chữ xăm trên cơ thể. Nhưng bản thân mô hình chưa bao giờ thực sự nội hóa những thông tin mới này.
Ngày càng nhiều nhà nghiên cứu cho rằng cách làm hiện nay là chưa đủ. Học dựa trên ngữ cảnh (ICL) chỉ giải quyết được vấn đề nếu câu trả lời (hoặc mảnh vụn của câu trả lời) đã tồn tại ở đâu đó trong thế giới. Tuy nhiên, với những bài toán đòi hỏi khám phá thực sự (ví dụ: một chứng minh toán học hoàn toàn mới), các tình huống đối kháng (ví dụ: tấn công – phòng thủ an ninh mạng), hoặc những tri thức quá ngầm ẩn, khó biểu đạt bằng ngôn ngữ, có đầy đủ lý do để khẳng định: mô hình cần một cơ chế để ghi trực tiếp kiến thức và kinh nghiệm mới vào các tham số ngay sau khi đã được triển khai.
Học dựa trên ngữ cảnh chỉ mang tính tạm thời. Học thực sự đòi hỏi nén dữ liệu. Trước khi chúng ta cho phép mô hình thực hiện nén liên tục, có lẽ chúng ta vẫn mãi bị giam cầm trong “hiện tại vĩnh cửu” của Memento. Ngược lại, nếu chúng ta có thể huấn luyện mô hình học cách xây dựng kiến trúc bộ nhớ riêng thay vì phụ thuộc vào các công cụ tùy chỉnh bên ngoài, có thể mở khóa một chiều kích mở rộng (scaling) hoàn toàn mới.
Lĩnh vực nghiên cứu này gọi là học liên tục (continual learning). Khái niệm này không mới (xem bài báo năm 1989 của McCloskey và Cohen), nhưng chúng tôi cho rằng đây là một trong những hướng nghiên cứu quan trọng nhất hiện nay trong lĩnh vực AI. Sự bùng nổ về khả năng mô hình trong hai đến ba năm gần đây khiến khoảng cách giữa những gì mô hình “đã biết” và những gì nó “có thể biết” ngày càng rõ rệt. Mục đích của bài viết này là chia sẻ những điều chúng tôi học được từ các nhà nghiên cứu hàng đầu trong lĩnh vực này, giúp làm rõ các con đường tiếp cận khác nhau của học liên tục, đồng thời thúc đẩy chủ đề này phát triển trong hệ sinh thái khởi nghiệp.
Ghi chú: Bài viết này được hình thành nhờ những cuộc trao đổi sâu sắc với một nhóm các nhà nghiên cứu, nghiên cứu sinh tiến sĩ và doanh nhân xuất sắc, những người đã rất hào phóng chia sẻ công trình và quan điểm của họ về học liên tục. Từ nền tảng lý thuyết đến thực tiễn kỹ thuật của việc học sau khi triển khai, những hiểu biết sâu sắc của họ đã khiến bài viết này trở nên vững chắc hơn rất nhiều so với phiên bản chúng tôi tự viết. Xin chân thành cảm ơn quý vị đã dành thời gian và chia sẻ ý tưởng!
Hãy bắt đầu với ngữ cảnh
Trước khi biện minh cho việc học ở cấp độ tham số (tức là cập nhật trọng số mô hình), cần thừa nhận một thực tế: học dựa trên ngữ cảnh thực sự hiệu quả. Thậm chí còn có một lập luận mạnh mẽ cho rằng phương pháp này sẽ tiếp tục chiếm ưu thế.
Bản chất của kiến trúc Transformer là một bộ dự đoán token tiếp theo dựa trên dãy điều kiện. Chỉ cần cung cấp đúng dãy đầu vào, bạn sẽ thu được hành vi đáng kinh ngạc phong phú, mà hoàn toàn không cần chạm tới trọng số. Đó là lý do vì sao quản lý ngữ cảnh, kỹ thuật viết lời nhắc (prompt engineering), tinh chỉnh theo chỉ dẫn (instruction tuning) và ví dụ học với ít mẫu (few-shot examples) lại mạnh mẽ đến vậy. Trí tuệ được “đóng gói” trong các tham số tĩnh, còn khả năng biểu hiện thì biến đổi mạnh mẽ tùy thuộc vào nội dung bạn đưa vào cửa sổ ngữ cảnh.
Một ví dụ tiêu biểu là bài viết chuyên sâu gần đây của Cursor về việc mở rộng quy mô các tác nhân trí tuệ tự chủ trong lập trình: trọng số mô hình cố định, còn yếu tố thực sự khiến hệ thống vận hành là việc sắp xếp tinh tế ngữ cảnh — đưa cái gì vào, khi nào tóm tắt, và làm thế nào duy trì trạng thái mạch lạc trong suốt hàng giờ đồng hồ vận hành tự chủ.
OpenClaw là một ví dụ khác. Nó gây tiếng vang không phải nhờ đặc quyền mô hình đặc biệt nào (mô hình nền tảng ai cũng có thể sử dụng), mà bởi khả năng chuyển đổi cực kỳ hiệu quả giữa ngữ cảnh và công cụ thành trạng thái làm việc: theo dõi bạn đang làm gì, cấu trúc hóa các sản phẩm trung gian, quyết định thời điểm chèn lại lời nhắc, duy trì ký ức bền vững về công việc trước đó. OpenClaw đã nâng “thiết kế vỏ bọc” cho tác nhân lên thành một ngành khoa học độc lập.
Khi kỹ thuật viết lời nhắc mới xuất hiện, nhiều nhà nghiên cứu hoài nghi rằng “chỉ dùng lời nhắc” có thể trở thành một giao diện nghiêm túc. Nó trông giống một thủ thuật “hack”. Nhưng thực tế, đây lại là sản phẩm nguyên sinh của kiến trúc Transformer, không cần huấn luyện lại, và tự động nâng cấp khi mô hình tiến bộ. Mô hình mạnh hơn, lời nhắc cũng mạnh hơn. Những giao diện “thô sơ nhưng nguyên sinh” thường chiến thắng, bởi chúng ghép nối trực tiếp với hệ thống nền tảng, chứ không chống lại nó. Đến nay, quỹ đạo phát triển của LLM đúng là như vậy.
Mô hình không gian trạng thái: phiên bản “steroid” của học dựa trên ngữ cảnh
Khi luồng công việc chính chuyển từ việc gọi LLM thô sang vòng lặp tác nhân (agent loop), áp lực lên các mô hình học dựa trên ngữ cảnh ngày càng gia tăng. Trước đây, việc điền đầy cửa sổ ngữ cảnh tương đối hiếm gặp. Điều này thường chỉ xảy ra khi LLM được yêu cầu thực hiện một chuỗi dài các tác vụ rời rạc, lúc đó tầng ứng dụng có thể dễ dàng cắt xén và nén lịch sử trò chuyện. Nhưng với tác nhân, một tác vụ duy nhất có thể chiếm phần lớn tổng dung lượng ngữ cảnh khả dụng. Mỗi bước trong vòng lặp tác nhân đều phụ thuộc vào ngữ cảnh được truyền từ các lần lặp trước. Và chúng thường thất bại sau khoảng 20–100 bước vì “mất kết nối”: cửa sổ ngữ cảnh bị đầy, tính mạch lạc suy giảm, không thể hội tụ.
Vì vậy, các phòng thí nghiệm AI hàng đầu hiện nay đang đầu tư nguồn lực lớn (tức là chạy huấn luyện quy mô lớn) để phát triển các mô hình có cửa sổ ngữ cảnh siêu dài. Đây là một hướng đi tự nhiên, vì nó xây dựng trên phương pháp đã chứng minh hiệu quả (học dựa trên ngữ cảnh) và phù hợp với xu hướng lớn của ngành là chuyển sang tính toán tại thời điểm suy luận (inference-time computation). Kiến trúc phổ biến nhất là xen kẽ các lớp bộ nhớ cố định giữa các đầu chú ý thông thường — tức là mô hình không gian trạng thái (SSM) và các biến thể chú ý tuyến tính (gọi chung là SSM ở phần sau). SSM cung cấp đường cong mở rộng (scaling curve) cơ bản tốt hơn nhiều trong các tình huống ngữ cảnh dài.
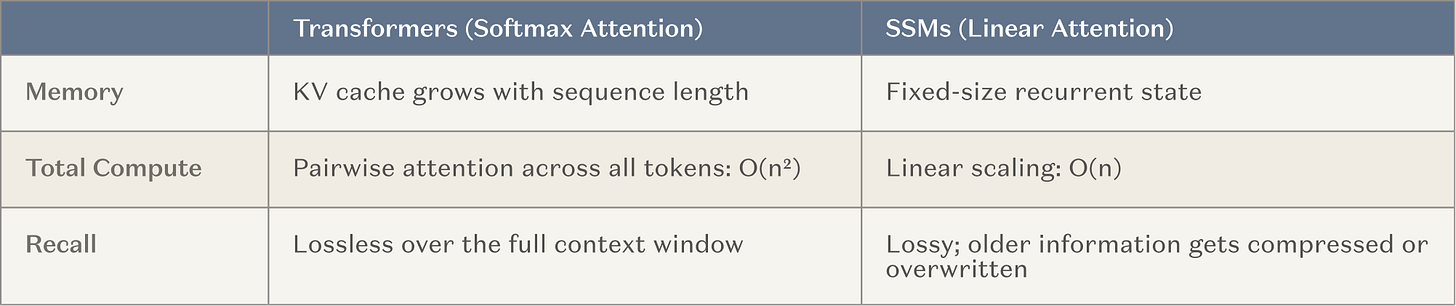
Chú thích ảnh: So sánh đường cong mở rộng giữa SSM và cơ chế chú ý truyền thống
Mục tiêu là giúp tác nhân tăng số bước vận hành mạch lạc lên vài bậc độ lớn — từ khoảng 20 bước lên khoảng 20.000 bước — mà không làm mất đi kỹ năng và kiến thức đa dạng vốn có của Transformer truyền thống. Nếu thành công, đây sẽ là một bước đột phá quan trọng đối với các tác nhân vận hành trong thời gian dài. Bạn thậm chí có thể coi phương pháp này như một dạng học liên tục: dù không cập nhật trọng số mô hình, nhưng đã giới thiệu một lớp bộ nhớ bên ngoài gần như không cần đặt lại.
Vì vậy, những phương pháp phi tham số này là có thật và mạnh mẽ. Bất kỳ đánh giá nào về học liên tục đều phải bắt đầu từ đây. Vấn đề không nằm ở chỗ hệ thống ngữ cảnh hiện nay có hữu ích hay không — nó thực sự hữu ích. Vấn đề là: chúng ta đã chạm tới giới hạn chưa, và các phương pháp mới có thể đưa chúng ta đi xa hơn không.
Những gì ngữ cảnh bỏ sót: “Ngụ ý tủ lưu trữ”
“AGI và việc huấn luyện trước (pretraining) đã ‘vượt mức’ theo một nghĩa nào đó… Con người không phải AGI. Đúng là con người có một nền tảng kỹ năng, nhưng lại thiếu rất nhiều kiến thức. Chúng ta phụ thuộc vào học liên tục. Nếu tôi tạo ra một cậu thiếu niên 15 tuổi siêu thông minh nhưng chẳng biết gì cả — một học sinh giỏi, rất khao khát học hỏi — bạn có thể bảo cậu ấy: ‘Hãy trở thành lập trình viên’, ‘Hãy trở thành bác sĩ’. Chính việc triển khai sẽ bao hàm một quá trình học tập và thử – sai nào đó. Đó là một quá trình, chứ không phải ném thẳng sản phẩm hoàn chỉnh ra ngoài.” — Ilya Sutskever
Hãy tưởng tượng một hệ thống có không gian lưu trữ vô hạn. Một chiếc tủ lưu trữ lớn nhất thế giới, mỗi sự kiện đều được lập chỉ mục hoàn hảo và có thể truy xuất tức thì. Hệ thống này có thể tra cứu bất cứ thứ gì. Nhưng nó đã học chưa?
Chưa. Nó chưa từng bị buộc phải nén dữ liệu.
Đây là luận điểm cốt lõi trong lập luận của chúng tôi, dựa trên quan điểm từng được Ilya Sutskever đưa ra trước đây: LLM về bản chất là các thuật toán nén. Trong quá trình huấn luyện, chúng nén toàn bộ Internet thành các tham số. Việc nén này là có tổn thất, và chính sự tổn thất này khiến nó trở nên mạnh mẽ. Nén buộc mô hình tìm kiếm cấu trúc, khái quát hóa và xây dựng các biểu diễn có thể di chuyển qua các ngữ cảnh. Một mô hình ghi nhớ máy móc tất cả các mẫu huấn luyện sẽ kém hơn một mô hình trích xuất được các quy luật nền tảng. Chính việc nén có tổn thất là học.
Một nghịch lý thú vị là: cơ chế khiến LLM mạnh mẽ trong giai đoạn huấn luyện (nén dữ liệu thô thành các biểu diễn ngắn gọn, có thể di chuyển) lại chính là điều chúng ta từ chối để chúng tiếp tục làm sau khi triển khai. Chúng ta ngừng nén ngay khoảnh khắc phát hành, thay thế bằng bộ nhớ bên ngoài. Dĩ nhiên, hầu hết các “vỏ bọc” tác nhân đều nén ngữ cảnh theo một cách tùy chỉnh nào đó. Nhưng bài học cay đắng (bitter lesson) chẳng phải đã dạy chúng ta rằng: chính mô hình cần học cách nén này — một cách trực tiếp và quy mô lớn — hay sao?
Yu Sun chia sẻ một ví dụ để minh họa tranh luận này: Toán học. Hãy xem Định lý cuối cùng của Fermat. Trong hơn 350 năm, không một nhà toán học nào chứng minh được nó, không phải vì họ thiếu tài liệu tham khảo đúng, mà vì lời giải mang tính đột phá cao độ. Khoảng cách khái niệm giữa kiến thức toán học sẵn có và đáp án cuối cùng quá lớn. Andrew Wiles cuối cùng đã chinh phục nó vào những năm 1990 sau bảy năm làm việc gần như cách ly hoàn toàn, phải phát minh ra các kỹ thuật hoàn toàn mới để đạt tới lời giải. Chứng minh của ông dựa trên việc thành công thiết lập cầu nối giữa hai nhánh toán học khác biệt: đường cong elliptic và dạng mô-đun. Mặc dù Ken Ribet trước đó đã chứng minh rằng nếu thiết lập được cầu nối này thì Định lý Fermat sẽ được giải quyết tự động, nhưng trước Wiles, chưa ai sở hữu công cụ lý thuyết đủ để thực sự xây dựng cây cầu ấy. Chứng minh Giả thuyết Poincaré của Grigori Perelman cũng có thể được lập luận tương tự.
Vấn đề cốt lõi là: Những ví dụ này có chứng minh rằng LLM thiếu một thứ gì đó — một khả năng nào đó để cập nhật tiên nghiệm và thực hiện tư duy sáng tạo thực sự — hay ngược lại, câu chuyện này lại chứng minh rằng toàn bộ tri thức loài người chỉ đơn thuần là dữ liệu để huấn luyện và tổ hợp lại, và Wiles cũng như Perelman chỉ là minh chứng cho thấy LLM cũng có thể làm được điều tương tự ở quy mô lớn hơn?
Câu hỏi này mang tính thực nghiệm và câu trả lời hiện vẫn chưa xác định. Nhưng chúng ta thực sự biết rằng có nhiều loại bài toán mà học dựa trên ngữ cảnh hiện nay sẽ thất bại, trong khi học ở cấp độ tham số có thể thành công. Ví dụ:

Chú thích ảnh: Các loại bài toán mà học dựa trên ngữ cảnh thất bại, còn học dựa trên tham số có thể vượt trội
Quan trọng hơn, học dựa trên ngữ cảnh chỉ xử lý được những thứ có thể biểu đạt bằng ngôn ngữ, trong khi trọng số có thể mã hóa các khái niệm mà lời nhắc không thể truyền tải bằng văn bản. Một số mẫu có chiều kích quá cao, quá ngầm ẩn, quá cấu trúc sâu, nên không thể nhét vừa vào ngữ cảnh. Ví dụ: kết cấu thị giác phân biệt giữa giả ảnh lành tính và khối u trong quét y khoa, hoặc dao động vi mô âm thanh xác định nhịp nói đặc trưng của một người — những mẫu này khó có thể phân tách thành từ vựng chính xác. Ngôn ngữ chỉ có thể xấp xỉ chúng. Không lời nhắc nào, dù dài đến đâu, cũng truyền tải được những điều này; loại tri thức này chỉ tồn tại trong trọng số. Nó sống trong không gian ẩn (latent space) của việc học biểu diễn, chứ không phải trong văn bản. Dù cửa sổ ngữ cảnh mở rộng đến đâu, luôn tồn tại một số tri thức không thể mô tả bằng văn bản, mà chỉ có thể được chứa trong trọng số.
Điều này có thể giải thích vì sao chức năng “robot ghi nhớ bạn” được thể hiện rõ ràng (ví dụ: tính năng Memory của ChatGPT) thường khiến người dùng cảm thấy khó chịu hơn là ngạc nhiên. Người dùng thực sự muốn không phải “sự hồi tưởng”, mà là “khả năng”. Một mô hình đã nội hóa được mô hình hành vi của bạn có thể khái quát hóa sang các tình huống mới; còn một mô hình chỉ đơn thuần nhớ lại lịch sử tương tác của bạn thì không thể. Khoảng cách giữa “đây là nội dung bạn đã viết lần trước khi trả lời email này” (lặp lại từng chữ) và “tôi đã đủ hiểu tư duy của bạn để dự đoán bạn cần gì” chính là khoảng cách giữa truy xuất và học.
Nhập môn học liên tục
Học liên tục có nhiều hướng tiếp cận. Đường phân chia không nằm ở “có chức năng ghi nhớ hay không”, mà ở: sự nén xảy ra ở đâu? Các hướng này nằm dọc theo một phổ, từ không nén (truy xuất thuần túy, trọng số đóng băng), đến nén hoàn toàn nội tại (học ở cấp độ trọng số, mô hình trở nên thông minh hơn), và ở giữa là một vùng quan trọng (mô-đun).
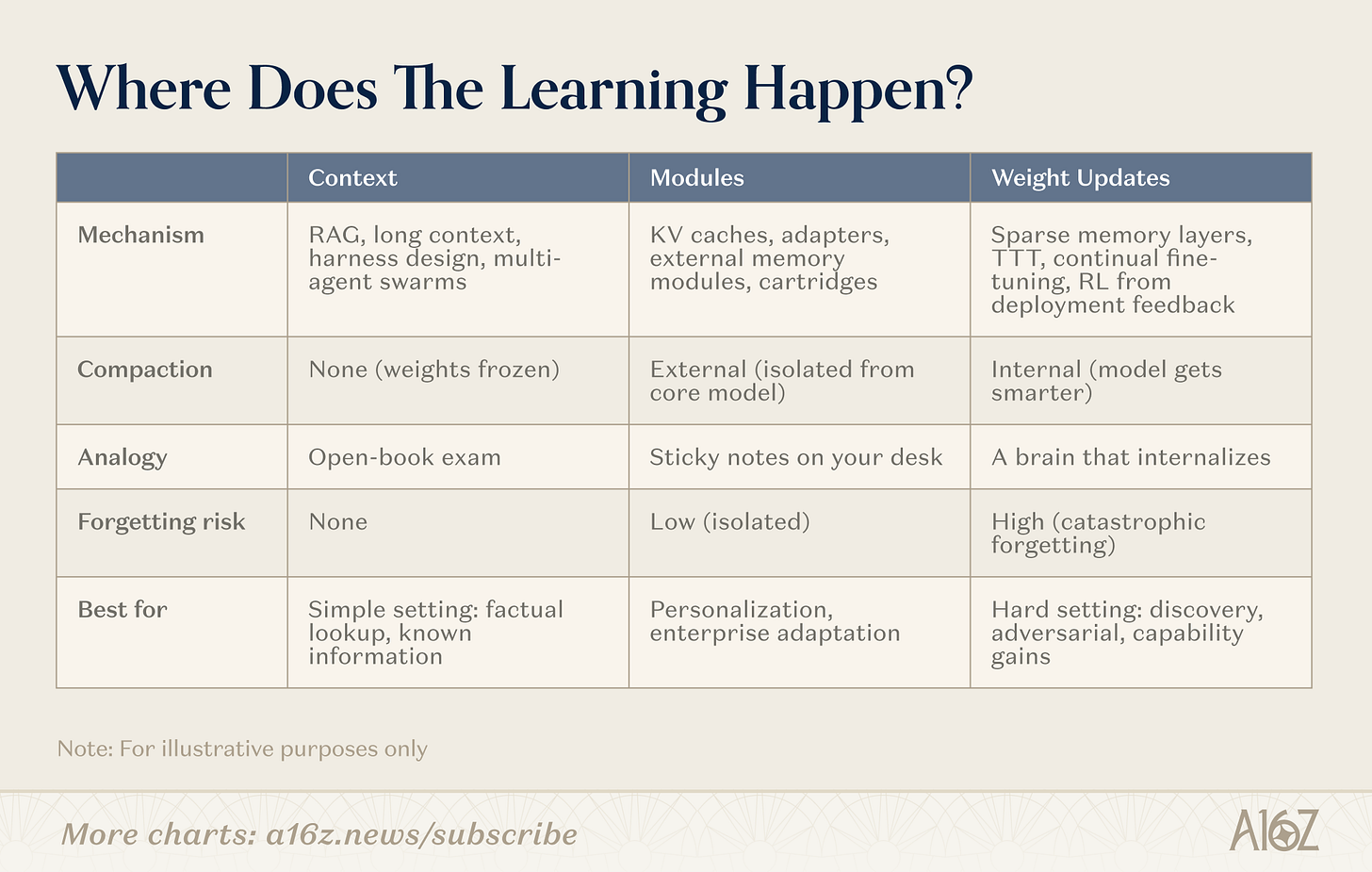
Chú thích ảnh: Ba hướng tiếp cận học liên tục — ngữ cảnh, mô-đun, trọng số
Ngữ cảnh
Ở đầu phổ “ngữ cảnh”, các nhóm xây dựng các đường ống truy xuất thông minh hơn, “vỏ bọc” tác nhân và việc sắp xếp lời nhắc. Đây là danh mục trưởng thành nhất: hạ tầng đã được kiểm chứng, lộ trình triển khai rõ ràng. Giới hạn nằm ở độ sâu: độ dài ngữ cảnh.
Một hướng mới đáng chú ý: kiến trúc đa tác nhân như một chiến lược mở rộng chính bản thân ngữ cảnh. Nếu một mô hình đơn lẻ bị giới hạn trong cửa sổ 128K token, thì một nhóm tác nhân phối hợp — mỗi tác nhân giữ ngữ cảnh riêng, tập trung vào một phần của vấn đề, và trao đổi kết quả lẫn nhau — có thể xấp xỉ bộ nhớ làm việc vô hạn về mặt tổng thể. Mỗi tác nhân thực hiện học dựa trên ngữ cảnh trong cửa sổ riêng; hệ thống thực hiện tổng hợp. Dự án autoresearch gần đây của Karpathy và ví dụ về trình duyệt web do Cursor xây dựng là những trường hợp đầu tiên. Đây là phương pháp hoàn toàn phi tham số (không thay đổi trọng số), nhưng nó nâng cao đáng kể giới hạn tối đa mà hệ thống ngữ cảnh có thể đạt được.
Mô-đun
Trong không gian mô-đun, các nhóm xây dựng các mô-đun kiến thức có thể cắm rời (cache KV đã nén, lớp bộ điều hợp (adapter), bộ lưu trữ bộ nhớ bên ngoài), cho phép mô hình tổng quát chuyên biệt hóa mà không cần huấn luyện lại. Một mô hình 8B cộng với các mô-đun phù hợp có thể đạt hiệu suất tương đương mô hình 109B trên tác vụ mục tiêu, trong khi chi phí bộ nhớ chỉ bằng một phần nhỏ. Sức hút nằm ở khả năng tương thích với hạ tầng Transformer hiện có.
Trọng số
Ở đầu phổ “trọng số”, các nhà nghiên cứu theo đuổi học thực sự ở cấp độ tham số: các lớp bộ nhớ thưa (sparse memory layer) chỉ cập nhật các phân đoạn trọng số liên quan, vòng lặp học tăng cường (reinforcement learning) tối ưu hóa mô hình từ phản hồi, và huấn luyện tại thời điểm kiểm tra (test-time training) nén ngữ cảnh vào trọng số trong quá trình suy luận. Đây là những phương pháp sâu sắc nhất, cũng là khó triển khai nhất, nhưng chúng thực sự cho phép mô hình nội hóa hoàn toàn thông tin hoặc kỹ năng mới.
Có nhiều cơ chế cụ thể để cập nhật trọng số. Dưới đây là một số hướng nghiên cứu:
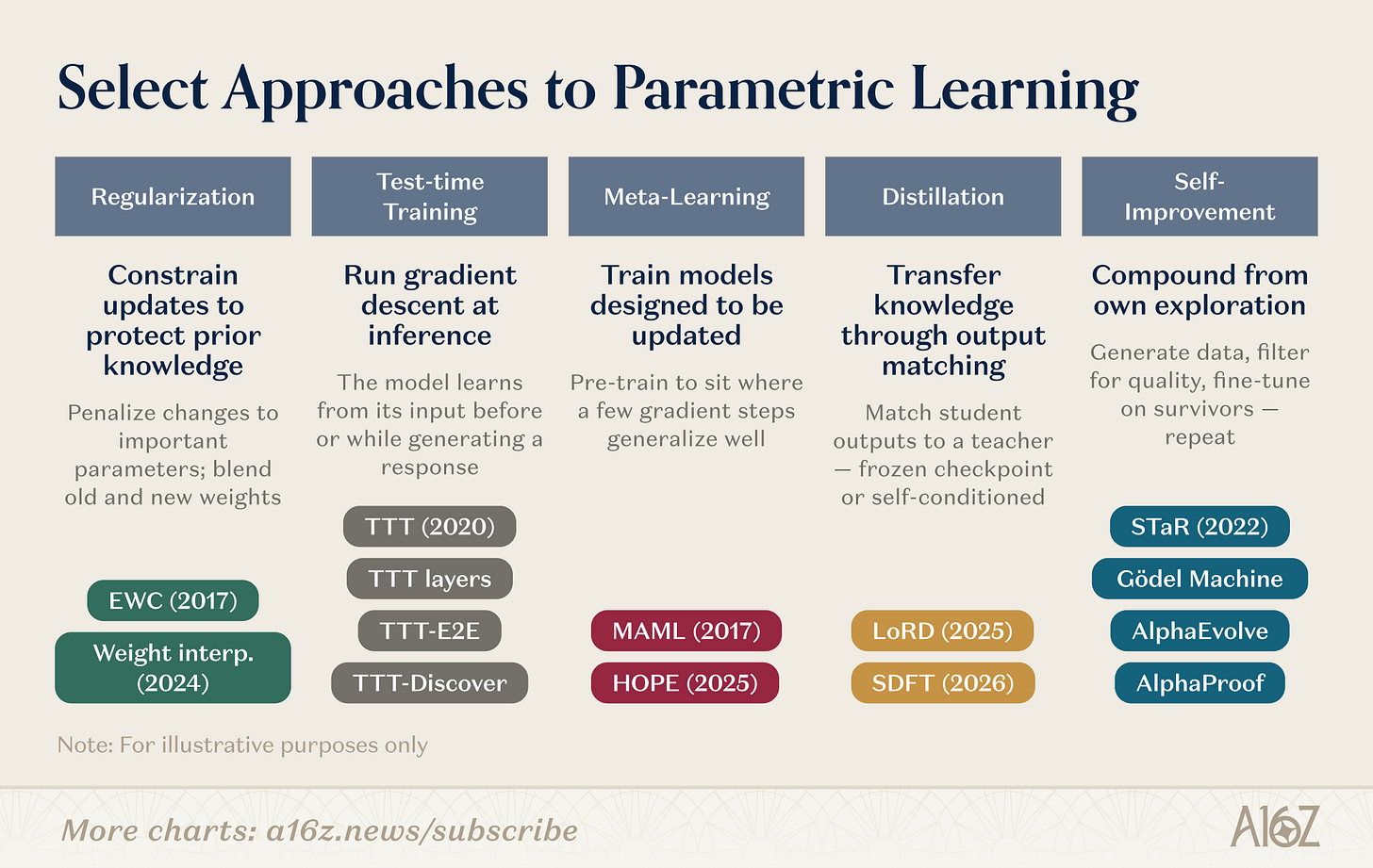
Chú thích ảnh: Tổng quan các hướng nghiên cứu học ở cấp độ trọng số
Nghiên cứu học ở cấp độ trọng số bao gồm nhiều hướng song song. Các phương pháp chuẩn hóa và trong không gian trọng số có lịch sử lâu đời nhất: EWC (Kirkpatrick et al., 2017) phạt sự thay đổi trọng số dựa trên mức độ quan trọng của tham số đối với các tác vụ trước đó; nội suy trọng số (Kozal et al., 2024) trộn các cấu hình trọng số cũ – mới trong không gian tham số, nhưng cả hai đều khá dễ tổn thương ở quy mô lớn. Huấn luyện tại thời điểm kiểm tra do Sun et al. (2020) khởi xướng, sau đó phát triển thành các nguyên thủy kiến trúc (lớp TTT, TTT-E2E, TTT-Discover), với tư duy hoàn toàn khác biệt: thực hiện lan truyền ngược (gradient descent) trên dữ liệu kiểm tra để nén thông tin mới vào trọng số ngay tại thời điểm cần thiết. Học siêu (meta-learning) đặt câu hỏi: Liệu chúng ta có thể huấn luyện một mô hình biết “cách học”? Từ việc khởi tạo tham số thân thiện với học ít mẫu (few-shot) của MAML (Finn et al., 2017) đến học lồng ghép (Nested Learning, Behrouz et al., 2025), nơi mô hình được cấu trúc thành một bài toán tối ưu phân cấp, với các mô-đun thích nghi nhanh và cập nhật chậm vận hành trên các thang thời gian khác nhau, lấy cảm hứng từ quá trình củng cố ký ức sinh học.
Sự cô đặc (distillation) duy trì kiến thức từ các tác vụ trước bằng cách để mô hình học sinh khớp với điểm kiểm tra (checkpoint) của mô hình thầy đã đóng băng. LoRD (Liu et al., 2025) làm cho sự cô đặc hiệu quả đến mức có thể chạy liên tục bằng cách đồng thời cắt tỉa mô hình và bộ đệm phát lại (replay buffer). Cô đặc tự thân (SDFT, Shenfeld et al., 2026) đảo ngược nguồn tín hiệu, sử dụng đầu ra của chính mô hình trong điều kiện chuyên gia làm tín hiệu huấn luyện, tránh hiện tượng quên thảm khốc (catastrophic forgetting) trong vi điều chỉnh tuần tự. Cải tiến tự thân đệ quy vận hành theo tư duy tương tự: STaR (Zelikman et al., 2022) khơi dậy khả năng lập luận từ chuỗi lập luận tự sinh; AlphaEvolve (DeepMind, 2025) khám phá ra các tối ưu hóa thuật toán chưa được cải tiến trong hàng chục năm; “Kỷ nguyên kinh nghiệm” của Silver và Sutton (2025) định nghĩa việc học của tác nhân là một dòng kinh nghiệm liên tục không bao giờ ngừng.
Các hướng nghiên cứu này đang hội tụ. TTT-Discover đã kết hợp huấn luyện tại thời điểm kiểm tra và khám phá điều khiển bởi học tăng cường. HOPE nhúng các vòng học nhanh – chậm vào một kiến trúc duy nhất. SDFT biến sự cô đặc thành một thao tác cơ bản của cải tiến tự thân. Ranh giới giữa các cột đang trở nên mờ nhạt. Hệ thống học liên tục thế hệ tiếp theo rất có thể sẽ kết hợp nhiều chiến lược: dùng chuẩn hóa để ổn định, dùng học siêu để tăng tốc, dùng cải tiến tự thân để tạo lợi ích kép. Một loạt công ty khởi nghiệp ngày càng tăng đang đặt cược vào các tầng khác nhau của ngăn xếp công nghệ này.
Bản đồ khởi nghiệp học liên tục
Đầu phổ phi tham số là phần quen thuộc nhất. Các công ty “vỏ bọc” (Letta, mem0, Subconscious) xây dựng các lớp điều phối và giàn giáo để quản lý nội dung đưa vào cửa sổ ngữ cảnh. Cơ sở hạ tầng lưu trữ bên ngoài và RAG (như Pinecone, xmemory) cung cấp xương sống cho truy xuất. Dữ liệu tồn tại, thách thức nằm ở việc đưa đúng mảnh dữ liệu vào trước mặt mô hình vào đúng thời điểm. Khi cửa sổ ngữ cảnh mở rộng, không gian thiết kế của các công ty này cũng tăng theo, đặc biệt ở phía “vỏ bọc”, một làn sóng công ty khởi nghiệp mới đang nổi lên nhằm quản lý các chiến lược ngữ cảnh ngày càng phức tạp.
Đầu phổ tham số còn non trẻ hơn và đa dạng hơn. Các công ty ở đây đang thử nghiệm một phiên bản nào đó của “nén sau khi triển khai”, để mô hình nội hóa thông tin mới vào trọng số. Các hướng tiếp cận có thể chia thành vài kiểu “đặt cược” khác nhau về việc mô hình nên “học như thế nào” sau khi phát hành.
Nén một phần: học mà không cần huấn luyện lại. Một số nhóm đang xây dựng các mô-đun kiến thức có thể cắm rời (cache KV đã nén, lớp bộ điều hợp, bộ lưu trữ bộ nhớ bên ngoài), cho phép mô hình tổng quát chuyên biệt hóa mà không động đến trọng số cốt lõi. Luận điểm chung là: bạn có thể đạt được nén có ý nghĩa (không chỉ truy xuất), đồng thời kiểm soát được sự đánh đổi giữa tính ổn định và tính linh hoạt trong phạm vi có thể quản lý, vì việc học được cách ly, chứ không phân tán khắp không gian tham số. Một mô hình 8B kèm các mô-đun phù hợp có thể đạt hiệu suất tương đương mô hình lớn hơn nhiều trên tác vụ mục tiêu. Ưu điểm là khả năng kết hợp: các mô-đun có thể cắm – dùng ngay với kiến trúc Transformer hiện có, có thể hoán đổi hoặc cập nhật độc lập, chi phí thử nghiệm thấp hơn nhiều so với huấn luyện lại.
Học tăng cường và vòng phản hồi: học từ tín hiệu. Một số nhóm khác đặt cược vào việc tín hiệu học phong phú nhất sau khi triển khai đã tồn tại ngay trong chính vòng lặp triển khai — sự sửa chữa của người dùng, thành bại của tác vụ, tín hiệu phần thưởng từ kết quả thực tế trong thế giới. Ý tưởng cốt lõi là mô hình nên coi mỗi tương tác như một tín hiệu huấn luyện tiềm năng, chứ không chỉ là một yêu cầu suy luận. Điều này rất giống cách con người tiến bộ trong công việc: làm việc, nhận phản hồi, nội hóa những phương pháp nào hiệu quả. Thách thức kỹ thuật nằm ở việc chuyển đổi phản hồi thưa, nhiễu và đôi khi mang tính đối kháng thành các cập nhật trọng số ổn định, mà không gây quên thảm khốc. Nhưng một mô hình thực sự có thể học từ quá trình triển khai sẽ tạo ra giá trị tích lũy theo cách mà hệ thống ngữ cảnh không thể làm được.
Tập trung vào dữ liệu: học từ tín hiệu đúng. Một kiểu “đặt cược” liên quan nhưng khác biệt là: điểm nghẽn không nằm ở thuật toán học, mà ở dữ liệu huấn luyện và hệ thống xung quanh. Các nhóm này tập trung vào việc lọc, tạo hoặc tổng hợp dữ liệu đúng để thúc đẩy cập nhật liên tục — với tiền đề rằng một mô hình có tín hiệu học chất lượng cao, có cấu trúc tốt, chỉ cần rất ít bước lan truyền ngược để cải thiện một cách có ý nghĩa. Điều này tự nhiên kết nối với các công ty vòng phản hồi, nhưng nhấn mạnh vào vấn đề thượng nguồn: mô hình có thể học được hay không là một chuyện, còn nó nên học từ cái gì và học đến mức độ nào lại là chuyện khác.
Kiến trúc mới: thiết kế khả năng học từ nền tảng. Kiểu “đặt cược” táo bạo nhất cho rằng chính kiến trúc Transformer là điểm nghẽn, và học liên tục đòi hỏi các nguyên thủy tính toán hoàn toàn khác biệt: kiến trúc có cơ chế động thời gian liên tục và bộ nhớ nội tại. Luận điểm ở đây là mang tính cấu trúc: nếu bạn muốn một hệ thống học liên tục, bạn nên nhúng cơ chế học vào kiến trúc nền tảng cơ bản.

Chú thích ảnh: Bản đồ công ty khởi nghiệp học liên tục
Tất cả các phòng thí nghiệm lớn đều đang tích cực triển khai trong các danh mục này. Một số đang khám phá quản lý ngữ cảnh và lập luận chuỗi suy nghĩ (chain-of-thought) tốt hơn, một số đang thử nghiệm các mô-đun bộ nhớ bên ngoài hoặc đường ống tính toán “thời gian ngủ” (sleep-time), và một vài công ty đang hoạt động bí mật theo đuổi kiến trúc mới. Lĩnh vực này còn quá non trẻ, chưa có phương pháp nào chiến thắng tuyệt đối, và xét đến sự đa dạng của các trường hợp sử dụng, cũng không nên chỉ có một người chiến thắng duy nhất.
Tại sao cập nhật trọng số đơn giản sẽ thất bại
Cập nhật trọng số mô hình trong môi trường sản xuất sẽ gây ra một chuỗi các kiểu thất bại hiện chưa được giải quyết ở quy mô lớn.

Chú thích ảnh: Các kiểu thất bại của cập nhật trọng số đơn giản
Các vấn đề kỹ thuật đã được ghi chép đầy đủ. Quên thảm khốc (catastrophic forgetting) nghĩa là một mô hình đủ nhạy cảm với dữ liệu mới để học sẽ phá hủy các biểu diễn đã có — đó là nghịch lý giữa tính ổn định và tính linh hoạt. Giải độc lập thời gian (time decoupling) là việc các quy tắc bất biến và trạng thái có thể thay đổi bị nén chung vào cùng một tập trọng số, nên việc cập nhật một trong hai sẽ làm hỏng cái còn lại. Thất bại trong tích hợp logic xảy ra vì việc cập nhật sự kiện không lan truyền đến các suy luận của nó: thay đổi bị giới hạn ở cấp độ dãy token, chứ không phải ở cấp độ khái niệm ngữ nghĩa. Việc “hủy học” (unlearning) vẫn bất khả thi: không tồn tại một phép toán trừ khả vi, nên tri thức sai lệch hoặc độc hại không thể bị loại bỏ một cách chính xác như một ca phẫu thuật.
Còn một lớp vấn đề thứ hai ít được quan tâm hơn. Việc tách biệt giữa huấn luyện và triển khai hiện nay không chỉ là tiện lợi kỹ thuật, mà còn là ranh giới về an ninh, khả năng kiểm toán và quản trị. Mở rộng ranh giới này sẽ khiến nhiều việc cùng lúc gặp trục trặc. Độ phù hợp an toàn (safety alignment) có thể suy giảm một cách không thể dự đoán: ngay cả việc vi điều chỉnh trong phạm vi hẹp trên dữ liệu lành tính cũng có thể tạo ra hành vi lệch lạc trên diện rộng. Việc cập nhật liên tục tạo ra một bề mặt tấn công cho việc đầu độc dữ liệu — một phiên bản chậm và dai dẳng của việc tiêm lời nhắc (prompt injection), nhưng nó cư trú trong trọng số. Khả năng kiểm toán sụp đổ, bởi một mô hình cập nhật liên tục là một “mục tiêu di động”, không thể kiểm soát phiên bản, kiểm thử hồi quy hay chứng nhận một lần. Khi tương tác người dùng được nén vào trọng số, rủi ro về quyền riêng tư gia tăng, vì thông tin nhạy cảm bị “nướng chín” vào các biểu diễn, khó lọc hơn nhiều so với thông tin trong ngữ cảnh truy xuất.
Đây là những vấn đề mở, chứ không phải điều bất khả thi về mặt nguyên lý. Giải quyết chúng cũng quan trọng như giải quyết các thách thức kiến trúc cốt lõi — đều là một phần trong chương trình nghị sự nghiên cứu về học liên tục.
Từ “Memento” đến ký ức thực sự
Bi kịch của Leonard trong Memento không nằm ở việc anh không thể vận hành — trong bất kỳ tình huống nào, anh đều thông minh và thậm chí xuất sắc. Bi kịch của anh nằm ở việc anh không bao giờ có thể tạo ra lợi ích kép. Mỗi trải nghiệm đều dừng lại ở bên ngoài — một tấm ảnh Polaroid, một dòng chữ xăm, một mẩu giấy ghi chú bằng nét bút của người khác. Anh có thể truy xuất, nhưng không thể nén kiến thức mới.
Khi Leonard lang thang trong mê cung do chính mình dựng nên, ranh giới giữa thực tại và niềm tin dần trở nên mờ nhạt. Căn bệnh của anh không chỉ tước đoạt ký ức; nó buộc anh phải liên tục xây dựng lại ý nghĩa, khiến anh vừa là thám tử, vừa là người kể chuyện thiếu đáng tin cậy trong chính câu chuyện của mình.
AI ngày nay vận hành dưới cùng những ràng buộc đó. Chúng ta đã xây dựng những hệ thống truy xuất rất mạnh: cửa sổ ngữ cảnh dài hơn, “vỏ bọc” thông minh hơn, nhóm tác nhân phối hợp hiệu quả hơn — và chúng thực sự hiệu quả. Nhưng truy xuất không phải là học. Một hệ thống có thể tra cứu bất kỳ sự kiện nào đều không bị buộc phải tìm kiếm cấu trúc. Nó không bị buộc phải khái quát hóa. Cơ chế nén có tổn thất — biến dữ liệu thô thành các biểu diễn có thể di chuyển — vốn khiến việc huấn luyện trở nên mạnh mẽ, lại chính là điều chúng ta tắt ngay khoảnh khắc triển khai.
Con đường tiến lên phía trước có thể không phải là một đột phá đơn lẻ, mà là một hệ thống phân tầng. Học dựa trên ngữ cảnh sẽ vẫn là hàng rào thích nghi đầu tiên: nó là nguyên sinh, đã được kiểm chứng và không ngừng được cải tiến. Cơ chế mô-đun có thể xử lý vùng trung gian giữa cá nhân hóa và chuyên biệt hóa theo lĩnh vực. Nhưng với những bài toán thực sự khó khăn — khám phá, thích nghi đối kháng, tri thức ngầm không thể biểu đạt bằng lời — chúng ta có thể cần để mô hình tiếp tục nén kinh nghiệm vào trọng số sau khi huấn luyện. Điều này đồng nghĩa với tiến bộ trong kiến trúc thưa, mục tiêu học siêu và các vòng lặp cải tiến tự thân. Nó cũng có thể đòi hỏi chúng ta định nghĩa lại khái niệm “mô hình”: không còn là một tập trọng số cố định, mà là một hệ thống đang tiến hóa, bao gồm bộ nhớ của nó, thuật toán cập nhật của nó, và khả năng trừu tượng hóa từ chính kinh nghiệm của nó.
Tủ lưu trữ ngày càng lớn. Nhưng dù lớn đến đâu, nó vẫn chỉ là một chiếc tủ lưu trữ. Đột phá nằm ở việc để mô hình thực hiện chính điều khiến nó mạnh mẽ trong giai đoạn huấn luyện: nén, trừu tượng hóa và học. Chúng ta đang đứng ở ngã rẽ từ những mô hình mất trí nhớ sang những mô hình mang trong mình ánh sáng đầu tiên của kinh nghiệm. Nếu không, chúng ta sẽ mãi bị giam cầm trong chính Memento của mình.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News









