

Qwen3 của Alibaba lên ngôi vương mã nguồn mở toàn cầu, đánh bật DeepSeek-R1, giành 17k sao trong 2 giờ
Tuyển chọn TechFlowTuyển chọn TechFlow
Qwen3 của Alibaba lên ngôi vương mã nguồn mở toàn cầu, đánh bật DeepSeek-R1, giành 17k sao trong 2 giờ
Qwen3 phù hợp hơn với sở thích của con người, giỏi về viết sáng tạo, đóng vai, đối thoại đa vòng và tuân theo chỉ dẫn, từ đó mang lại trải nghiệm hội thoại tự nhiên, hấp dẫn và chân thực hơn.
Tác giả: Tân Trí Nguyên

【Dẫn đọc Tân Trí Nguyên】Qwen3 của Alibaba mở mã nguồn vào rạng sáng nay, chính thức đăng quang ngôi vương mô hình lớn mã nguồn mở toàn cầu! Hiệu năng vượt trội hoàn toàn so với DeepSeek-R1 và OpenAI o1, sử dụng kiến trúc MoE, tổng số tham số 235B, áp đảo mọi benchmark chính.
Ngay trong rạng sáng hôm nay, mô hình Thông Nghĩa Thiên Vấn thế hệ mới Qwen3 của Alibaba đã được công bố mã nguồn – sự kiện được cả thế giới mong đợi!
Mới ra đời, Qwen3 lập tức vươn lên ngôi vị mô hình mã nguồn mở mạnh nhất toàn cầu.
Với lượng tham số chỉ bằng 1/3 DeepSeek-R1, chi phí giảm mạnh nhưng hiệu năng vượt xa các mô hình hàng đầu thế giới như R1, OpenAI-o1.
Qwen3 là mô hình suy luận hỗn hợp đầu tiên tại Trung Quốc, tích hợp đồng thời "tư duy nhanh" và "tư duy chậm" trong cùng một mô hình. Với nhu cầu đơn giản, có thể trả lời tức thì với mức tiêu tốn tính toán thấp; với vấn đề phức tạp, có thể "suy nghĩ sâu" theo nhiều bước, tiết kiệm đáng kể tài nguyên tính toán.
Mô hình sử dụng kiến trúc Mixture-of-Experts (MoE), tổng cộng 235 tỷ tham số, nhưng chỉ cần kích hoạt 22 tỷ.
Dữ liệu tiền huấn luyện đạt tới 36 nghìn tỷ token, kết hợp giai đoạn hậu huấn luyện với học tăng cường đa vòng, tích hợp liền mạch chế độ không suy luận vào mô hình tư duy.
Vừa ra đời, Qwen3 đã quét sạch mọi benchmark chính.
Hơn nữa, khi hiệu năng được nâng cao rõ rệt, chi phí triển khai còn giảm mạnh – chỉ cần 4 card H20 là đã có thể triển khai phiên bản đầy đủ của Qwen3, lượng bộ nhớ video chiếm dụng chỉ bằng 1/3 các mô hình hiệu năng tương đương!
Tóm tắt điểm nổi bật:
· Cung cấp đa dạng mô hình dày đặc và mô hình Mixture-of-Experts (MoE) ở mọi kích cỡ, bao gồm 0.6B, 1.7B, 4B, 8B, 14B, 32B, 30B-A3B và 235B-A22B.
· Có khả năng chuyển đổi liền mạch giữa chế độ suy luận (dành cho suy luận logic, toán học và lập trình phức tạp) và chế độ không suy luận (dành cho trò chuyện chung hiệu quả), đảm bảo hiệu suất tối ưu trong mọi tình huống.
· Nâng cao rõ rệt khả năng suy luận, vượt qua các mô hình QwQ trước đó ở chế độ suy luận và Qwen2.5 instruct ở chế độ không suy luận về toán học, sinh mã và suy luận logic thông thường.
· Phù hợp hơn với sở thích con người, giỏi viết sáng tạo, đóng vai, hội thoại đa vòng và tuân thủ lệnh, mang lại trải nghiệm hội thoại tự nhiên, hấp dẫn và chân thực hơn.
· Thành thạo khả năng Agent AI, hỗ trợ tích hợp chính xác với công cụ bên ngoài ở cả hai chế độ suy luận và không suy luận, đạt hiệu suất dẫn đầu trong các nhiệm vụ Agent phức tạp so với các mô hình mã nguồn mở.
· Lần đầu tiên hỗ trợ 119 ngôn ngữ và phương ngữ, có khả năng theo dõi lệnh đa ngôn ngữ và dịch thuật mạnh mẽ.
Hiện tại, Qwen3 đã đồng thời ra mắt trên cộng đồng ModelScope, Hugging Face, GitHub và có thể trải nghiệm trực tuyến.
Các nhà phát triển, tổ chức nghiên cứu và doanh nghiệp toàn cầu đều có thể tải miễn phí và dùng thương mại, hoặc gọi dịch vụ API Qwen3 thông qua Bách Luyện đám mây Alibaba. Người dùng cá nhân có thể ngay lập tức trải nghiệm Qwen3 qua ứng dụng Thông Nghĩa, Kuai cũng sẽ sớm tích hợp toàn diện Qwen3.
Trải nghiệm trực tuyến:
Cộng đồng ModelScope:
https://modelscope.cn/collections/Qwen3-9743180bdc6b48
Hugging Face:
https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
GitHub:
https://github.com/QwenLM/Qwen3
Tính đến nay, Thông Nghĩa Alibaba đã mở mã nguồn hơn 200 mô hình, lượt tải toàn cầu vượt 300 triệu lần, số lượng mô hình phái sinh từ Thiên Vấn vượt 100.000, hoàn toàn vượt mặt Llama Mỹ, trở thành mô hình mã nguồn mở số một thế giới!
Gia đình Qwen3 xuất hiện
8 mô hình "suy luận hỗn hợp" đồng loạt mở mã nguồn
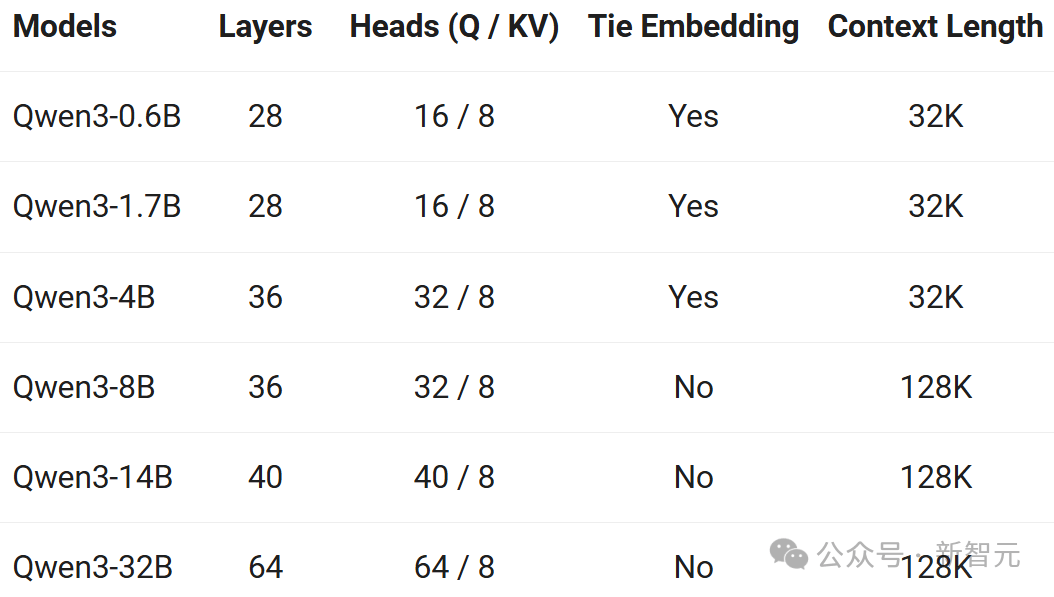
Lần này, Alibaba công bố đồng thời 8 mô hình suy luận hỗn hợp, bao gồm 2 mô hình MoE 30B và 235B, cùng 6 mô hình dày đặc 0.6B, 1.7B, 4B, 8B, 14B, 32B, tất cả đều theo giấy phép Apache 2.0.
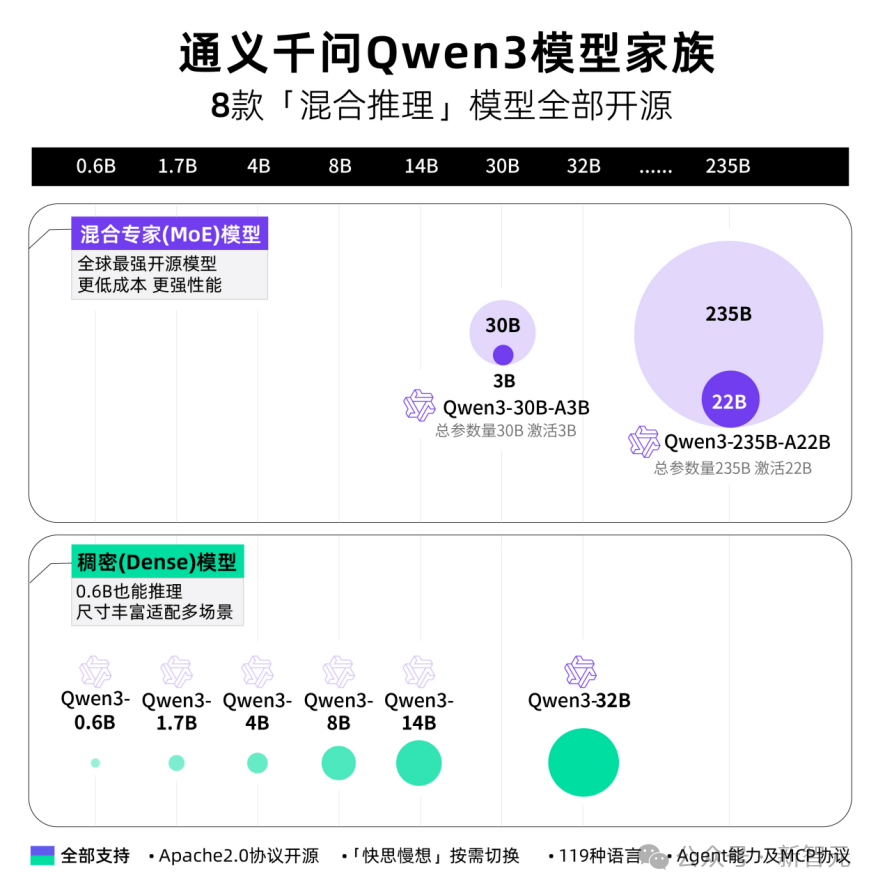
Trong đó, mỗi mô hình đều giành SOTA trong nhóm kích cỡ tương ứng.
Mô hình MoE 30B tham số Qwen3 đạt mức đòn bẩy hiệu năng mô hình hơn 10 lần, chỉ cần kích hoạt 3B đã sánh ngang hiệu năng mô hình Qwen2.5-32B thế hệ trước.
Mô hình dày đặc Qwen3 tiếp tục đột phá hiệu năng, chỉ cần một nửa tham số đã đạt hiệu suất cao tương đương, ví dụ như mô hình Qwen3 phiên bản 32B có thể vượt bậc hiệu năng Qwen2.5-72B.
Đồng thời, mọi mô hình Qwen3 đều là mô hình suy luận hỗn hợp, API có thể thiết lập "ngân sách suy luận" (số lượng token tối đa dự kiến cho suy luận sâu) theo nhu cầu, thực hiện mức độ suy luận khác nhau, linh hoạt đáp ứng nhu cầu đa dạng về hiệu suất và chi phí của ứng dụng AI và các tình huống khác nhau.
Ví dụ, mô hình 4B là kích thước lý tưởng cho thiết bị di động; 8B có thể triển khai mượt mà trên máy tính và xe hơi; 32B được doanh nghiệp ưa chuộng nhất cho triển khai quy mô lớn, các nhà phát triển có điều kiện cũng dễ dàng tiếp cận.
Ông vua mới của mô hình mã nguồn mở, lập kỷ lục mới
Qwen3 được tăng cường mạnh mẽ về suy luận, tuân thủ lệnh, gọi công cụ, khả năng đa ngôn ngữ, lập kỷ lục hiệu năng mới cho mọi mô hình nội địa và mô hình mã nguồn mở toàn cầu ——
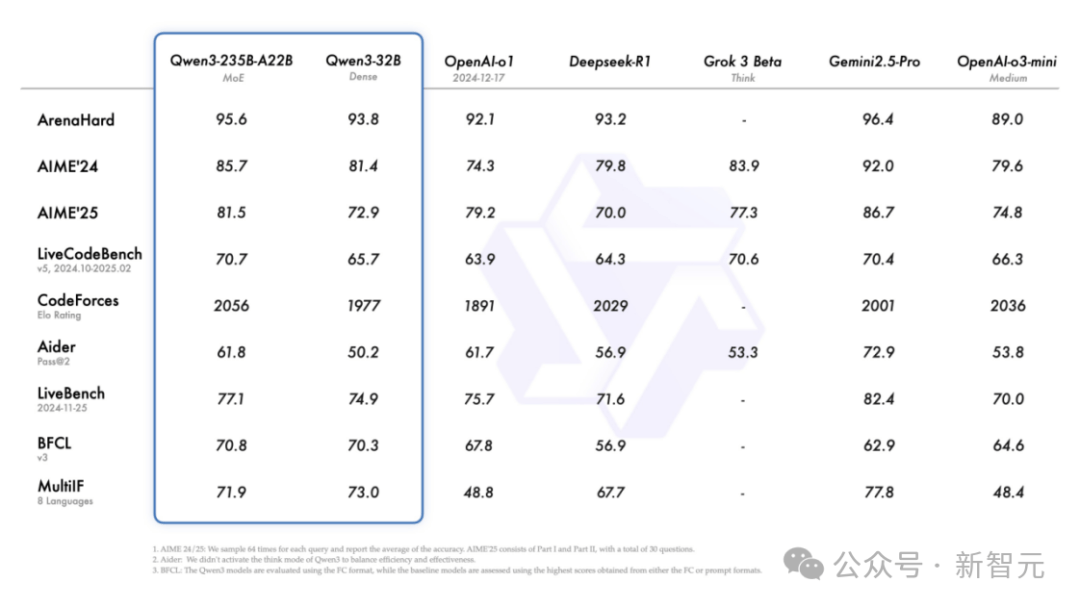
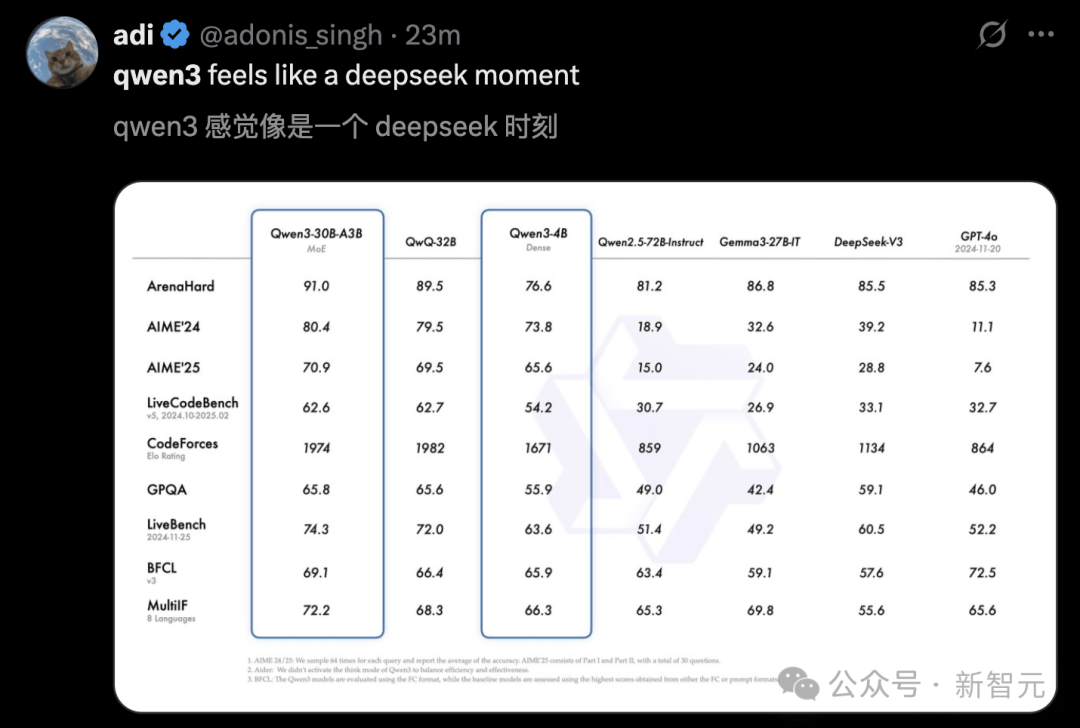
Trong đánh giá AIME25 ở trình độ toán Olympic, Qwen3 đạt 81.5 điểm, lập kỷ lục mới cho mô hình mã nguồn mở.
Trong đánh giá LiveCodeBench kiểm tra khả năng lập trình, Qwen3 vượt ngưỡng 70 điểm, biểu hiện thậm chí còn tốt hơn Grok3.
Trong đánh giá ArenaHard đo lường sự phù hợp với sở thích con người, Qwen3 đạt 95.6 điểm, vượt OpenAI-o1 và DeepSeek-R1.

Cụ thể, mô hình chủ lực Qwen3-235B-A22B so với các mô hình hàng đầu khác (như DeepSeek-R1, o1, o3-mini, Grok-3 và Gemini-2.5-Pro) trong các bài kiểm tra chuẩn về lập trình, toán học, năng lực chung, đều đạt điểm số rất ấn tượng.
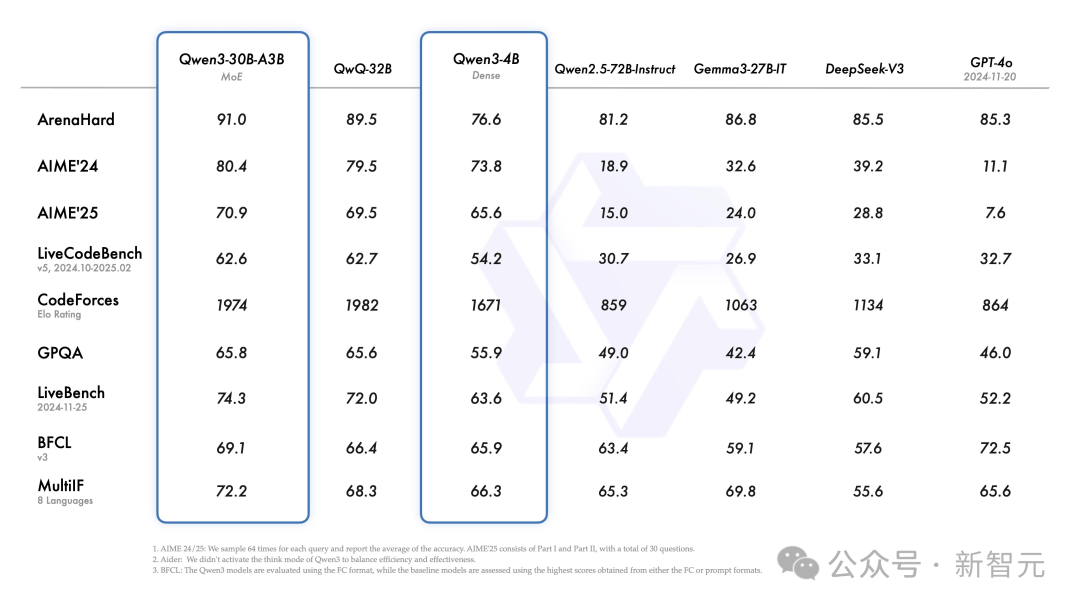
Ngoài ra, mô hình chuyên gia nhỏ hỗn hợp Qwen3-30B-A3B dù tham số kích hoạt chỉ bằng một phần mười QwQ-32B nhưng hiệu năng lại vượt trội hơn.
Ngay cả mô hình nhỏ như Qwen3-4B cũng có thể sánh ngang hiệu năng mô hình Qwen2.5-72B-Instruct.
Các mô hình đã tinh chỉnh như Qwen3-30B-A3B, cùng các phiên bản tiền huấn luyện (ví dụ Qwen3-30B-A3B-Base), hiện đã có thể tìm thấy trên các nền tảng như Hugging Face, ModelScope và Kaggle.
Về triển khai, Alibaba khuyến nghị sử dụng các framework như SGLang và vLLM. Đối với sử dụng cục bộ, mạnh mẽ khuyến nghị các công cụ như Ollama, LMStudio, MLX, llama.cpp và KTransformers.
Bất kể môi trường nghiên cứu, phát triển hay sản xuất, Qwen3 đều có thể dễ dàng tích hợp vào mọi quy trình làm việc.
Thúc đẩy bùng nổ Agent thông minh và ứng dụng mô hình lớn
Có thể nói, Qwen3 cung cấp hỗ trợ tốt hơn cho cuộc bùng nổ sắp tới của Agent thông minh và ứng dụng mô hình lớn.
Trong đánh giá BFCL kiểm tra khả năng Agent, Qwen3 lập kỷ lục mới 70.8, vượt Gemini2.5-Pro, OpenAI-o1 và các mô hình hàng đầu khác, điều này sẽ giảm đáng kể ngưỡng sử dụng công cụ của Agent.
Đồng thời, Qwen3 hỗ trợ bản địa giao thức MCP, có khả năng gọi công cụ mạnh mẽ, kết hợp với framework Qwen-Agent được gói sẵn mẫu gọi công cụ và bộ phân tích gọi công cụ.
Điều này sẽ giảm mạnh độ phức tạp lập trình, thực hiện hiệu quả các tác vụ như vận hành Agent trên điện thoại và máy tính.
Đặc điểm chính
Chế độ suy luận hỗn hợp
Mô hình Qwen3 giới thiệu một cách giải quyết vấn đề hỗn hợp. Chúng hỗ trợ hai chế độ:
1. Chế độ suy luận: Ở chế độ này, mô hình sẽ suy luận từng bước rồi đưa ra câu trả lời. Phù hợp với các vấn đề phức tạp cần suy nghĩ sâu.
2. Chế độ không suy luận: Ở chế độ này, mô hình sẽ nhanh chóng đưa ra câu trả lời, thích hợp cho các vấn đề đơn giản yêu cầu tốc độ cao.
Sự linh hoạt này cho phép người dùng kiểm soát quá trình suy luận của mô hình tùy theo mức độ phức tạp của nhiệm vụ.
Ví dụ, các bài toán khó có thể giải bằng suy luận mở rộng, trong khi các câu hỏi đơn giản có thể trả lời trực tiếp mà không bị trì hoãn.
Quan trọng nhất, sự kết hợp hai chế độ này nâng cao đáng kể khả năng kiểm soát tài nguyên suy luận một cách ổn định và hiệu quả của mô hình.
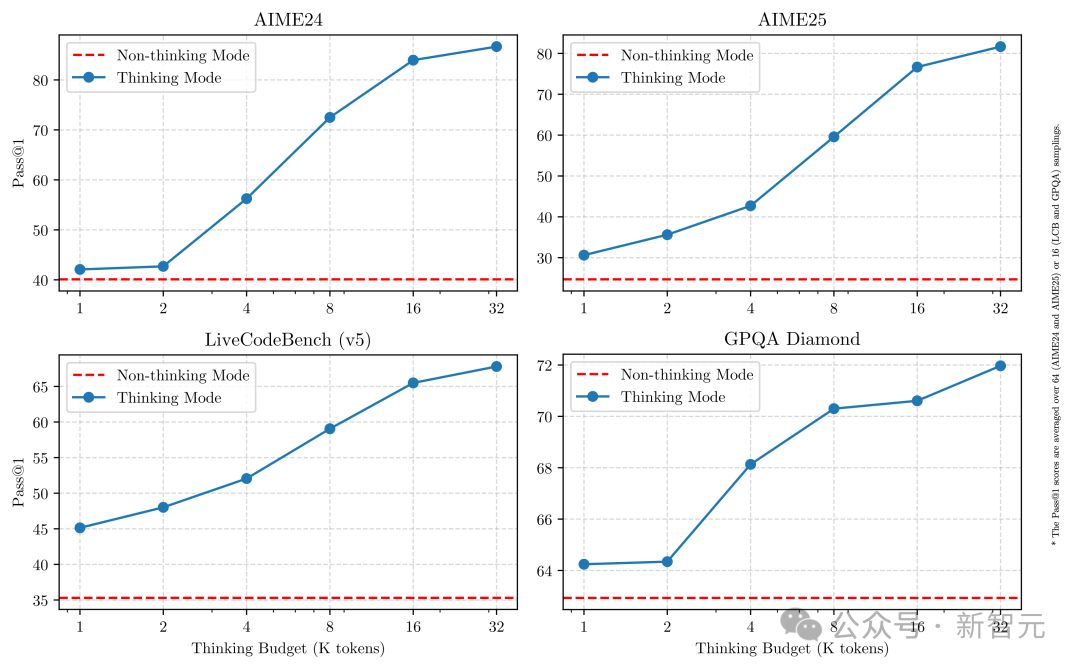
Như hình trên, Qwen3 thể hiện cải thiện hiệu suất có thể mở rộng và mượt mà, liên quan trực tiếp đến ngân sách tính toán suy luận được phân bổ.
Thiết kế này giúp người dùng dễ dàng cấu hình ngân sách riêng cho từng nhiệm vụ, từ đó tối ưu hóa cân bằng giữa hiệu quả chi phí và chất lượng suy luận.
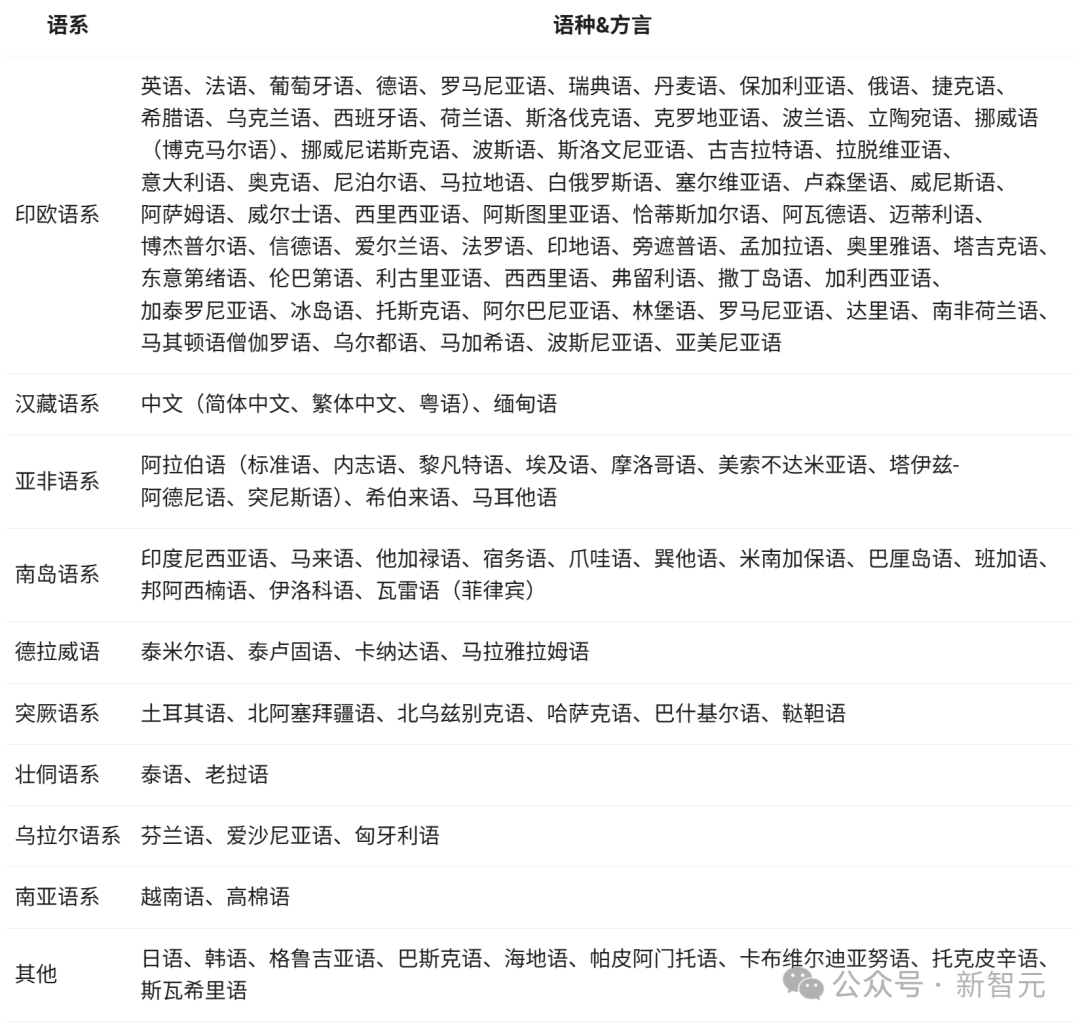
Hỗ trợ đa ngôn ngữ
Mô hình Qwen3 hỗ trợ 119 ngôn ngữ và phương ngữ.
Khả năng đa ngôn ngữ rộng rãi như vậy cũng có nghĩa là Qwen3 tiềm năng rất lớn để tạo ra các ứng dụng quốc tế lan tỏa toàn cầu.
Khả năng Agent mạnh mẽ hơn
Alibaba đã tối ưu hóa mô hình Qwen3 để nâng cao khả năng lập trình và Agent, đồng thời tăng cường hỗ trợ MCP.
Ví dụ dưới đây minh họa rõ ràng cách Qwen3 suy nghĩ và tương tác với môi trường.
36 nghìn tỷ token, huấn luyện đa giai đoạn
Là mô hình mạnh nhất trong dòng Thiên Vấn, Qwen3 đạt được biểu hiện ấn tượng như vậy nhờ đâu?
Cùng khám phá chi tiết kỹ thuật phía sau Qwen3.
Tiền huấn luyện
So với Qwen2.5, tập dữ liệu tiền huấn luyện của Qwen3 gần như gấp đôi thế hệ trước, từ 18 nghìn tỷ token mở rộng lên 36 nghìn tỷ token.
Dữ liệu bao phủ 119 ngôn ngữ và phương ngữ, không chỉ từ mạng mà còn bao gồm nội dung văn bản trích xuất từ các tài liệu PDF.
Để đảm bảo chất lượng dữ liệu, nhóm sử dụng Qwen2.5-VL để trích xuất văn bản tài liệu và thông qua Qwen2.5 để tối ưu độ chính xác nội dung trích xuất.
Ngoài ra, để nâng cao biểu hiện trong lĩnh vực toán học và lập trình, Qwen3 còn sử dụng Qwen2.5-Math và Qwen2.5-Coder để tạo ra lượng lớn dữ liệu tổng hợp, bao gồm sách giáo khoa, cặp hỏi-đáp và đoạn mã.
Quá trình tiền huấn luyện Qwen3 gồm ba giai đoạn, từng bước nâng cao năng lực mô hình:
Giai đoạn 1 (S1): Xây dựng năng lực ngôn ngữ cơ bản
Sử dụng hơn 30 nghìn tỷ token, tiền huấn luyện với độ dài ngữ cảnh 4k. Giai đoạn này đặt nền móng vững chắc về năng lực ngôn ngữ và kiến thức phổ thông cho mô hình.
Giai đoạn 2 (S2): Tối ưu hóa dữ liệu giàu kiến thức
Tăng tỷ lệ dữ liệu giàu kiến thức như STEM, lập trình và nhiệm vụ suy luận, tiếp tục huấn luyện thêm 5 nghìn tỷ token, nâng cao hơn nữa biểu hiện năng lực chuyên môn.
Giai đoạn 3 (S3): Mở rộng khả năng ngữ cảnh
Sử dụng dữ liệu ngữ cảnh chất lượng cao, mở rộng độ dài ngữ cảnh mô hình lên 32k, đảm bảo khả năng xử lý đầu vào phức tạp và cực dài.
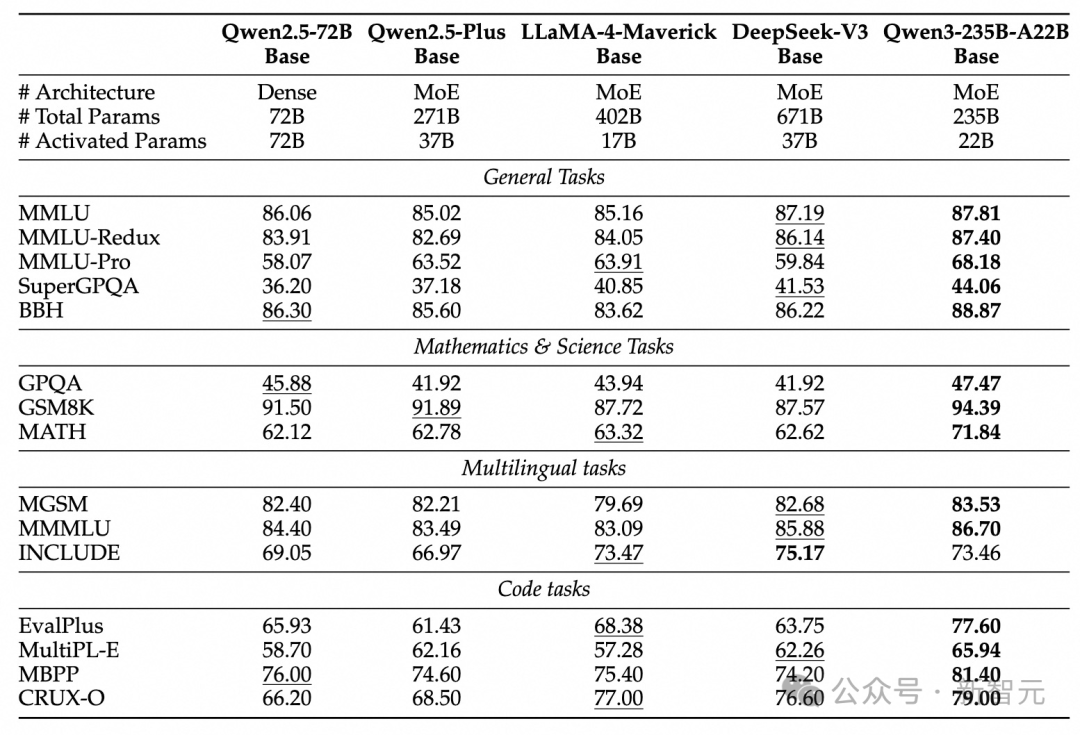
Nhờ tối ưu kiến trúc mô hình, mở rộng quy mô dữ liệu và phương pháp huấn luyện hiệu quả hơn, mô hình cơ sở Qwen3 Dense thể hiện hiệu suất nổi bật.
Như bảng dưới đây, Qwen3-1.7B/4B/8B/14B/32B-Base có thể sánh ngang Qwen2.5-3B/7B/14B/32B/72B-Base, đạt mức độ mô hình lớn hơn với tham số nhỏ hơn.
Đặc biệt, trong các lĩnh vực như STEM, lập trình và suy luận, mô hình cơ sở Qwen3 Dense thậm chí còn vượt mô hình Qwen2.5 lớn hơn.
Ấn tượng hơn, mô hình Qwen3 MoE chỉ cần 10% tham số kích hoạt đã đạt hiệu suất tương đương mô hình cơ sở Qwen2.5 Dense.
Điều này không chỉ giảm mạnh chi phí huấn luyện và suy luận mà còn mang lại tính linh hoạt cao hơn cho triển khai thực tế mô hình.
Hậu huấn luyện
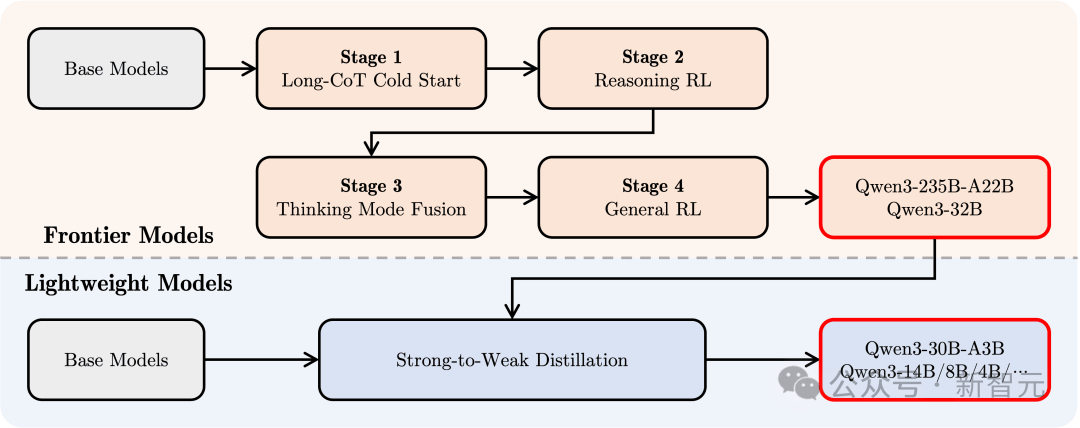
Để xây dựng một mô hình hỗn hợp vừa có thể suy luận phức tạp vừa phản hồi nhanh, Qwen3 thiết kế quy trình hậu huấn luyện bốn giai đoạn.
1. Khởi động lạnh chuỗi suy nghĩ dài
Sử dụng dữ liệu chuỗi suy nghĩ dài đa dạng, bao gồm toán học, lập trình, suy luận logic và vấn đề STEM, huấn luyện mô hình nắm bắt năng lực suy luận cơ bản.
2. Học tăng cường chuỗi suy nghĩ dài
Mở rộng tài nguyên tính toán RL, kết hợp cơ chế thưởng dựa trên quy tắc, nâng cao khả năng mô hình trong việc khám phá và tận dụng đường dẫn suy luận.
3. Hòa trộn chế độ suy nghĩ
Sử dụng dữ liệu chuỗi suy nghĩ dài và dữ liệu tinh chỉnh lệnh để tinh chỉnh, tích hợp khả năng phản hồi nhanh vào mô hình suy luận, đảm bảo mô hình vừa chính xác vừa hiệu quả trong nhiệm vụ phức tạp.
Dữ liệu này do mô hình suy nghĩ tăng cường giai đoạn 2 tạo ra, đảm bảo hòa trộn liền mạch giữa khả năng suy luận và phản hồi nhanh.
4. Học tăng cường phổ quát
Áp dụng RL trong hơn 20 nhiệm vụ lĩnh vực phổ quát như tuân thủ lệnh, tuân thủ định dạng và năng lực Agent, nâng cao thêm tính phổ quát và độ bền của mô hình, đồng thời sửa chữa hành vi xấu.
Phản hồi tích cực khắp mạng
Chưa đầy 3 giờ sau khi Qwen3 mở mã nguồn, đã thu hút 17k sao trên GitHub, hoàn toàn thổi bùng nhiệt huyết cộng đồng mã nguồn mở. Các nhà phát triển đua nhau tải về và bắt đầu thử nghiệm tốc độ cao.
Địa chỉ dự án:
https://github.com/QwenLM/Qwen3
Kỹ sư Apple Awni Hannun thông báo, Qwen3 đã được hỗ trợ bởi framework MLX.
Hơn nữa, bất kể thiết bị tiêu dùng iPhone (0.6B, 4B), MacBook (8B, 30B, 3B/30B MoE), hay M2/M3 Ultra (22B/235B MoE), đều có thể chạy cục bộ.
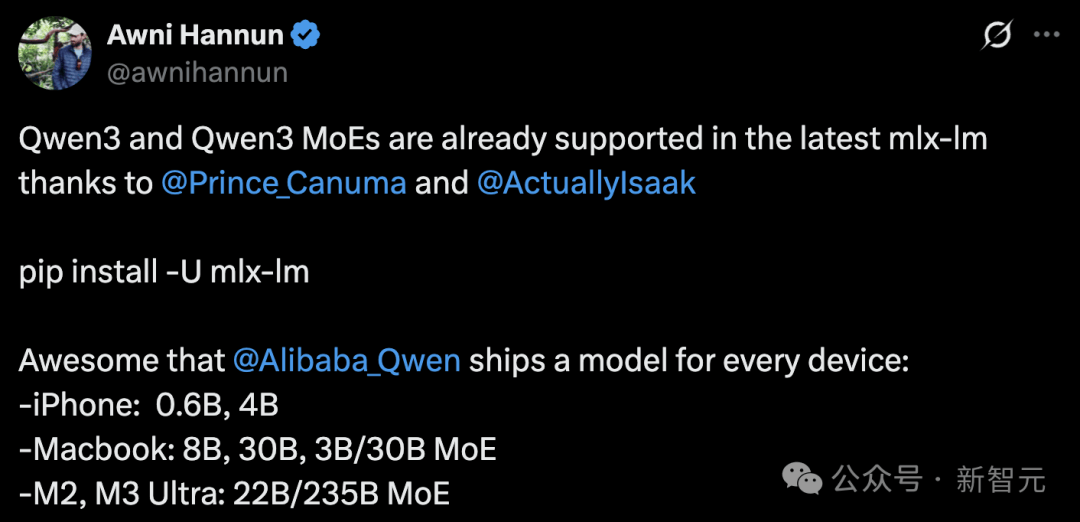
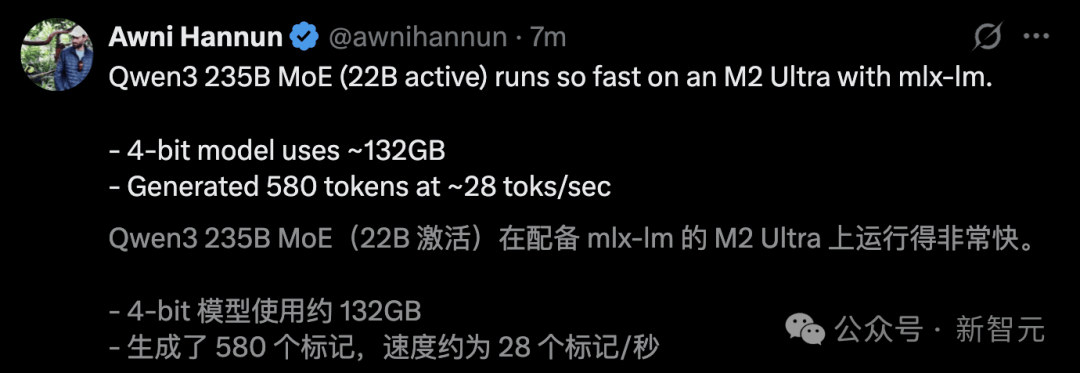
Anh ấy đã chạy Qwen3 235B MoE trên M2 Ultra với tốc độ tạo ra lên tới 28 token/giây.
Một số người dùng thử nghiệm thực tế cho biết, so với mô hình Llama cùng kích thước, Qwen3 hoàn toàn không cùng một đẳng cấp. Mô hình trước suy luận sâu hơn, duy trì ngữ cảnh dài hơn, và giải quyết được các vấn đề khó hơn.

Cũng có người nhận xét, Qwen3 giống như một "thời khắc DeepSeek".
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News













