

Cuộc trò chuyện chuyên sâu cùng Zhang Ye từ Scroll: zkEVM, Scroll và tương lai của nó
Tuyển chọn TechFlowTuyển chọn TechFlow
Cuộc trò chuyện chuyên sâu cùng Zhang Ye từ Scroll: zkEVM, Scroll và tương lai của nó
Bài viết này là tài liệu tuyệt vời để hiểu về Scroll, Trương Diệp đã trả lời 15 câu hỏi liên quan đến Scroll và zkEVM.
Phóng vấn viên: Nickqiao & Faust, Geeker Web3
Người được phỏng vấn: YeZhang, Đồng sáng lập Scroll
Biên tập: Faust, Jomosis
Vào ngày 17 tháng 6, Geeker Web3 và BTCEden, với sự hỗ trợ từ DevRel của Scroll – Vincent Jin, đã may mắn mời được đồng sáng lập Scroll là Zhang Ye đến để giải đáp rất nhiều câu hỏi về Scroll và zkEVM.
Trong buổi trao đổi, hai bên không chỉ thảo luận sâu về các chủ đề kỹ thuật mà còn chia sẻ những câu chuyện thú vị xung quanh Scroll cũng như tầm nhìn lớn lao về việc thúc đẩy kinh tế thực tại các khu vực châu Phi, châu Á và Mỹ Latinh. Bài viết này là bản ghi chép chi tiết cuộc phỏng vấn, dài hơn 10.000 từ, bao gồm ít nhất 15 chủ đề chính:
-
Không gian ứng dụng ZK trong lĩnh vực truyền thống
-
Sự khác biệt về độ khó kỹ thuật giữa zkEVM và zkVM
-
Những thách thức kỹ thuật mà Scroll gặp phải khi triển khai zkEVM
-
Những cải tiến mà Scroll đóng góp cho hệ thống chứng minh halo2 của Zcash
-
Cách Scroll hợp tác với nhóm PSE của Ethereum như thế nào
-
Scroll đảm bảo an toàn mạch (circuit) ở cấp độ kiểm toán mã nguồn ra sao
-
Kế hoạch đơn giản về phiên bản zkEVM mới và hệ thống chứng minh tương lai của Scroll
-
Thiết kế Multi Prover của Scroll và cách xây dựng mạng lưới Prover (mỏ khai thác zk), v.v.
Ngoài ra, ở phần cuối, ông Trương Diệp đã chia sẻ tầm nhìn lớn lao rằng Scroll sẽ bám rễ tại các khu vực có hệ thống tài chính lạc hậu như châu Phi, Thổ Nhĩ Kỳ, Đông Nam Á, nhằm tạo ra các kịch bản kinh tế thực tế giúp người dân "từ ảo chuyển sang thực". Bài viết này có thể là một tài liệu tuyệt vời giúp nhiều người hiểu rõ hơn về Scroll, khuyến khích mọi người đọc kỹ.

1. Faust: Thưa thầy Trương Diệp, thầy đánh giá thế nào về ứng dụng của ZK ngoài Rollup? Nhiều người thường mặc định rằng ZK chủ yếu dùng cho mixer, chuyển tiền riêng tư hoặc ZK Rollup và cầu nối ZK. Tuy nhiên, ngoài Web3, ví dụ như trong ngành công nghiệp truyền thống, ứng dụng ZK vẫn còn rất nhiều. Theo thầy, tương lai ZK có khả năng được áp dụng mạnh mẽ ở những lĩnh vực nào?
YeZhang: Đây là một câu hỏi hay. Những người làm ZK trong ngành công nghiệp truyền thống đã khám phá các trường hợp sử dụng ZK từ năm sáu năm trước. Thực tế, các ứng dụng ZK trong blockchain rất nhỏ bé, cũng vì vậy mà Vitalik từng nói rằng sau 10 năm nữa, quy mô ứng dụng ZK sẽ ngang bằng với blockchain.
Theo tôi, ZK sẽ có rất nhiều tiềm năng trong các tình huống cần thiết lập niềm tin. Giả sử bạn cần xử lý một tác vụ tính toán nặng nề. Nếu bạn thuê máy chủ trên AWS để chạy tác vụ và nhận kết quả, điều đó giống như bạn đang tự tính toán trên thiết bị do mình kiểm soát, nhưng bạn phải trả tiền thuê máy — khoản phí này thường không hề rẻ.
Tuy nhiên, nếu theo mô hình tính toán thuê ngoài, nhiều người có thể dùng thiết bị hoặc tài nguyên dư thừa để chia sẻ gánh nặng tính toán cho bạn, chi phí bạn bỏ ra có thể rẻ hơn so với việc thuê máy chủ. Nhưng vấn đề nằm ở chỗ niềm tin — bạn không biết liệu kết quả mà họ gửi lại có đúng hay không. Ví dụ, bạn giao cho tôi một phép tính phức tạp rồi trả tiền để tôi thực hiện. Nửa tiếng sau, tôi đưa ra một kết quả bất kỳ, bạn cũng không thể xác minh nó có hợp lệ hay không, vì tôi có thể bịa ra kết quả.
Nhưng nếu tôi có thể chứng minh rằng kết quả tính toán là đúng, bạn sẽ yên tâm hơn và dám giao thêm nhiều tác vụ tính toán hơn cho tôi. ZK có thể biến các nguồn dữ liệu không đáng tin thành đáng tin cậy — chức năng này rất mạnh mẽ. Nhờ ZK, bạn có thể tận dụng hiệu quả các tài nguyên tính toán thứ ba rẻ tiền nhưng không đáng tin.
Tôi cho rằng đây là một kịch bản rất ý nghĩa, có thể thúc đẩy các mô hình kinh doanh như dịch vụ tính toán thuê ngoài. Một số tài liệu học thuật gọi đây là "tính toán xác minh được" (verifiable computation), tức là biến một quá trình tính toán trở nên đáng tin cậy. Ngoài ra, ZK có thể được ứng dụng trong lĩnh vực cơ sở dữ liệu. Giả sử việc vận hành CSDL tại chỗ quá tốn kém, bạn chọn phương án thuê ngoài, và một người có tài nguyên CSDL dư thừa sẵn sàng lưu trữ dữ liệu cho bạn. Bạn lo lắng họ có thể sửa đổi dữ liệu bạn ủy thác, hoặc kết quả truy vấn SQL bạn nhận được có chính xác không?
Trong trường hợp này, bạn có thể yêu cầu họ sinh ra một proof. Nếu điều này khả thi, bạn hoàn toàn có thể thuê ngoài việc lưu trữ dữ liệu và vẫn nhận được kết quả đáng tin cậy. Điều này cùng với tính toán xác minh được tạo thành một lớp ứng dụng lớn.
Còn nhiều ví dụ khác nữa. Tôi nhớ có một bài báo nói về "Verifiable ASIC" — khi sản xuất chip, bạn có thể tích hợp thuật toán ZK vào chip. Khi dùng chip để chạy chương trình, kết quả đầu ra sẽ tự động đi kèm một Proof. Như vậy, rất nhiều thiết bị có thể được ủy quyền để tạo ra kết quả đáng tin cậy.
Một ý tưởng hơi lạ đời là "Photo Proof" (chứng minh ảnh). Ví dụ, nhiều bức ảnh hiện nay bạn không biết có bị chỉnh sửa hay không, nhưng chúng ta có thể dùng ZK để chứng minh ảnh chưa bị thay đổi. Ví dụ, có thể tích hợp một cài đặt trong phần mềm máy ảnh để tự động tạo chữ ký số. Sau khi chụp ảnh, chữ ký này giống như một con dấu xác nhận. Nếu ai đó lấy ảnh của bạn đi chỉnh sửa (ví dụ "sáng tạo lại"), chúng ta có thể kiểm tra chữ ký để phát hiện ảnh đã bị thay đổi.
Ở đây, chúng ta có thể áp dụng ZK: khi bạn chỉnh sửa ảnh gốc một chút, bạn có thể dùng ZK Proof để chứng minh rằng bạn chỉ xoay, dịch chuyển ảnh — không thay đổi nội dung gốc — và chứng minh rằng ảnh đã chỉnh sửa gần như giống bản gốc, tức là bạn không thay đổi nội dung cốt lõi để "sáng tạo lại".
Ứng dụng này có thể mở rộng sang video và âm thanh: nhờ ZK, bạn không cần tiết lộ mình đã chỉnh sửa video gốc như thế nào, nhưng vẫn chứng minh được rằng bạn không thay đổi nội dung cốt lõi, chỉ thực hiện những điều chỉnh nhỏ không ảnh hưởng gì. Ngoài ra còn rất nhiều ứng dụng thú vị khác mà ZK có thể tham gia.
Hiện tại, tôi cho rằng lý do các ứng dụng ZK chưa được chấp nhận rộng rãi là vì chi phí quá cao. Các giải pháp sinh proof ZK hiện tại vẫn chưa thể sinh proof thời gian thực cho mọi phép tính, vì chi phí ZK thường gấp 100–1000 lần phép tính gốc — con số tôi đưa ra đã được giảm thiểu tối đa rồi.
Hãy tưởng tượng một tác vụ tính toán mất 1 giờ, bây giờ để sinh ZK Proof, chi phí phát sinh có thể lên tới 100 giờ — tức là gấp 100 lần. Dù bạn có thể dùng GPU hay ASIC để rút ngắn thời gian, thì vẫn phải chịu chi phí tính toán khổng lồ. Nếu bạn yêu cầu tôi thực hiện một phép tính phức tạp và sinh thêm ZK Proof, tôi có thể từ chối — vì nó đòi hỏi thêm 100 lần tài nguyên tính toán, xét về mặt kinh tế thì rất không hiệu quả. Vì vậy, đối với các tình huống một-một, việc sinh proof ZK một lần là rất đắt đỏ.
Tuy nhiên, đây cũng là lý do vì sao ZK đặc biệt phù hợp với Blockchain: vì blockchain thực hiện tính toán dư thừa, và có rất nhiều tình huống một-đa. Trong mạng blockchain, các nút khác nhau thực hiện cùng một tác vụ tính toán. Nếu có 10.000 nút, nhiệm vụ giống nhau được thực hiện 10.000 lần. Nhưng nếu bạn hoàn tất tác vụ ngoài chuỗi và sinh ZK Proof, 10.000 nút chỉ cần xác minh proof mà không cần chạy lại tác vụ — bạn không cần phát lại phép tính gốc 10.000 lần. Như vậy, bạn dùng chi phí tính toán của một người để thay thế cho chi phí tính toán dư thừa của 10.000 nút, xét tổng thể sẽ giúp tiết kiệm tài nguyên cho nhiều người.
Do đó, càng phi tập trung, blockchain càng phù hợp với ZK, vì bất kỳ ai cũng có thể xác minh ZKP với chi phí gần bằng 0. Chỉ cần bỏ ra chi phí ban đầu để sinh proof, chúng ta có thể giải phóng gánh nặng cho đại đa số người dùng — đây chính là lý do tính xác minh công khai của blockchain cực kỳ phù hợp với ZK, do blockchain có rất nhiều tình huống một-đa.
Một điểm nữa chưa được nhắc tới: hiện nay, các loại ZK proof có chi phí cao trong blockchain đều là dạng không tương tác — bạn đưa một thứ, tôi đưa proof, xong việc. Bởi trong blockchain, bạn không thể liên tục tương tác với chuỗi. Tuy nhiên, tồn tại một cách sinh proof hiệu quả hơn, chi phí thấp hơn: chứng minh tương tác. Ví dụ, bạn gửi cho tôi một Challenge, tôi gửi lại một thứ, bạn lại gửi tiếp, tôi lại gửi tiếp — qua nhiều lần trao đổi, có thể giảm đáng kể khối lượng tính toán ZK. Nếu phương pháp này khả thi, có thể giải quyết vấn đề sinh proof cho các ứng dụng ZK quy mô lớn.
Nickqiao: Nhìn nhận thế nào về zkML — sự kết hợp giữa ZK và học máy — về tiềm năng phát triển?
YeZhang: zkML cũng là một hướng thú vị — có thể "ZK hóa" Machine Learning. Tuy nhiên, tôi nghĩ lĩnh vực này vẫn thiếu các ứng dụng mang tính đột phá thực sự. Mọi người đều tin rằng khi hiệu suất hệ thống ZK được nâng cao, tương lai sẽ hỗ trợ được các ứng dụng ML ở cấp độ này. Hiện tại, hiệu suất zkML đủ để hỗ trợ các ứng dụng kiểu GPT-2 — về mặt kỹ thuật là khả thi, nhưng chỉ giới hạn ở phần suy luận (inference). Về cơ bản, tôi cho rằng cộng đồng vẫn đang mò mẫm tìm kiếm kịch bản ứng dụng — cụ thể là vấn đề hóc búa: điều gì thực sự cần bạn chứng minh rằng quá trình suy luận là đúng?
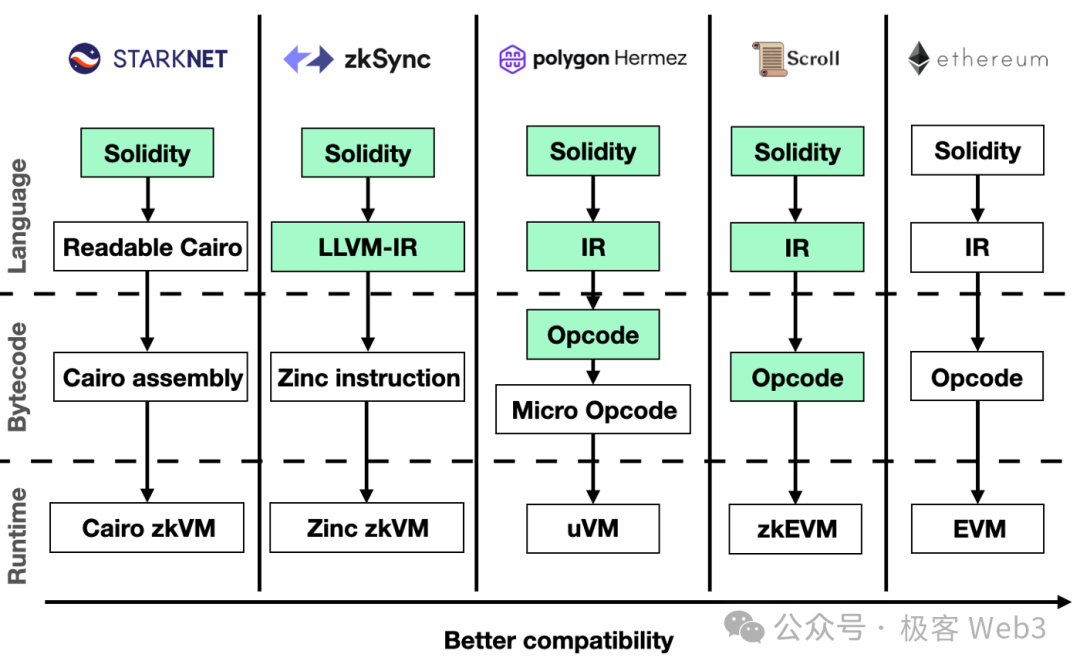
2. Nickqiao: Xin hỏi thầy Trương Diệp, sự khác biệt về độ khó kỹ thuật giữa zkEVM và zkVM cụ thể là bao nhiêu?
YeZhang: Trước hết, dù là zkEVM hay zkVM, bản chất đều là tạo ra mạch ZK tùy chỉnh cho tập lệnh/mã vận hành (opcode) của một máy ảo nhất định. Độ khó triển khai kỹ thuật của zkEVM phụ thuộc vào cách bạn thực hiện nó. Khi chúng tôi mới khởi động dự án, hiệu suất ZK chưa cao, nên cách hiệu quả nhất là viết mạch riêng cho từng opcode của EVM, sau đó ghép chúng lại để tạo ra một zkEVM tùy chỉnh.
Tuy nhiên, cách này chắc chắn có độ khó kỹ thuật rất lớn — cao hơn nhiều so với zkVM, bởi EVM có hơn 100 opcode, mỗi opcode đều cần một mạch riêng, sau đó phải ghép lại. Mỗi khi có EIP bổ sung opcode mới cho EVM, ví dụ EIP-4844, zkEVM cũng phải thêm phần mới tương ứng. Cuối cùng, bạn phải viết mạch dài và trải qua quá trình kiểm toán kéo dài, nên độ khó và khối lượng công việc cao hơn rất nhiều so với zkVM.
Ngược lại, zkVM tự định nghĩa một bộ tập lệnh/opcode riêng, có thể thiết kế rất đơn giản và thân thiện với ZK. Sau khi tạo ra một zkVM, bạn không cần thay đổi mã底层 thường xuyên để hỗ trợ nâng cấp hay tiền biên dịch. Do đó, khối lượng công việc chính và độ khó bảo trì nâng cấp của zkVM tập trung vào trình biên dịch — bước chuyển đổi hợp đồng thông minh thành opcode của zkVM — điều này rất khác biệt so với zkEVM.
Vì vậy, xét về độ khó kỹ thuật, tôi cho rằng zkVM dễ triển khai hơn nhiều so với zkEVM tùy chỉnh. Tuy nhiên, nếu chạy EVM trên zkVM, hiệu suất tổng thể thấp hơn nhiều so với zkEVM tùy chỉnh, vì zkEVM được thiết kế chuyên biệt. Nhưng hiện nay, hiệu suất sinh proof của Prover đã tăng ít nhất 3–5 lần, thậm chí 5–10 lần trong hai năm qua, hiệu suất zkVM cũng được cải thiện theo. Dùng zkVM để chạy EVM, hiệu suất tổng thể đang dần được cải thiện. Trong tương lai, điểm yếu về hiệu suất của zkVM có thể bị che khuất bởi lợi thế về tính dễ dàng phát triển và bảo trì. Bởi lẽ, ngoài hiệu suất, điểm nghẽn lớn nhất của zkVM và zkEVM chính là độ khó phát triển — bạn cần một đội ngũ kỹ thuật cực kỳ mạnh để duy trì một hệ thống phức tạp như vậy.
3. Nickqiao: Có thể chia sẻ về những thách thức kỹ thuật mà Scroll gặp phải trong quá trình triển khai zkEVM, và cách khắc phục?
YeZhang: Nhìn lại chặng đường vừa qua, thử thách lớn nhất vẫn là mức độ bất định quá cao khi mới khởi động dự án. Khi bắt đầu, gần như không có ai khác làm zkEVM — chúng tôi là một trong những đội tiên phong khám phá cách biến zkEVM từ điều không thể thành có thể. Về mặt lý thuyết, trong 6 tháng đầu, chúng tôi đã xác định được một khung khả thi. Tuy nhiên, trong quá trình triển khai sau đó, khối lượng công việc kỹ thuật rất lớn, kèm theo nhiều thách thức kỹ thuật sâu sắc, ví dụ như cách hỗ trợ động các Pre-Compile khác nhau, hay cách gộp opcode hiệu quả hơn — tất cả đều liên quan đến những vấn đề kỹ thuật lớn.
Chúng tôi cũng là đội duy nhất và đầu tiên hỗ trợ Pre-Compile EC Pairing (ghép cặp đường cong elliptic). Việc triển khai mạch cho Pairing cực kỳ khó, liên quan đến nhiều vấn đề toán học phức tạp, đòi hỏi người viết mạch phải có nền tảng vững chắc về mật mã/học và kỹ năng kỹ thuật rất cao.
Sau này, còn phải cân nhắc tính khả năng bảo trì lâu dài của bộ công cụ kỹ thuật, và thời điểm nào nên nâng cấp lên zkEVM 2.0. Chúng tôi có một đội nghiên cứu chuyên biệt luôn nghiên cứu các giải pháp như dùng zkVM để hỗ trợ EVM, và đã có các bài báo thảo luận về hướng này.
Tóm lại, tôi cho rằng khó khăn trước đây nằm ở việc biến zkEVM từ không thể thành có thể, với các thách thức chủ yếu về triển khai kỹ thuật và tối ưu. Còn giai đoạn tiếp theo, thách thức lớn hơn là: thời điểm nào, bằng cách nào cụ thể, chuyển sang hệ thống chứng minh ZK hiệu quả hơn, làm sao chuyển codebase hiện tại sang zkEVM thế hệ mới, và zkEVM mới sẽ mang lại những tính năng mới gì — tất cả đều là không gian khám phá lớn.
4. Nickqiao: Nghe có vẻ Scroll đã cân nhắc chuyển sang hệ thống chứng minh ZK khác. Theo tôi biết, hiện tại Scroll dùng một bộ thuật toán dựa trên PLONK+Lookup. Liệu bộ này có phải là phù hợp nhất để triển khai zkEVM hiện nay, và tương lai Scroll dự định chuyển sang hệ thống chứng minh nào?
YeZhang: Trước tiên, tôi xin trả lời ngắn gọn về PLONK và Lookup. Hiện tại, bộ này vẫn là hệ thống phù hợp nhất để triển khai zkEVM hoặc zkVM. Hầu hết các triển khai gắn liền chặt chẽ với PLONK và Lookup cụ thể. Khi nói đến PLONK, thực tế thường ám chỉ việc dùng arithmetization của PLONK — tức là cách biểu diễn số học của mạch — để viết mạch zkVM.
Lookup là một cách viết mạch, một loại ràng buộc. Vì vậy, khi nói PLONK + Lookup, ý là dùng định dạng ràng buộc của PLONK khi viết mạch zkEVM hoặc zkVM — đây hiện là cách phổ biến nhất.
Về phía backend, ranh giới giữa PLONK và STARK đã mờ nhạt, vì chúng chỉ dùng các phương pháp cam kết đa thức khác nhau nhưng khá tương tự. Ngay cả khi dùng tổ hợp STARK + Lookup, nó cũng tương tự PLONK + Lookup. Mọi người chỉ quan tâm đến thuật toán, còn sự khác biệt chủ yếu thể hiện ở hiệu suất Prover, kích thước proof, v.v. Dĩ nhiên, về phía frontend, Plonk + Lookup vẫn là lựa chọn phù hợp nhất để triển khai zkEVM.
Về câu hỏi thứ hai: tương lai Scroll dự định chuyển sang hệ thống chứng minh nào? Mục tiêu của Scroll là luôn giữ công nghệ và khung chuỗi ở vị trí tiên phong trong lĩnh vực zk. Vì vậy, chúng tôi chắc chắn sẽ dùng các công nghệ mới nhất. Chúng tôi luôn đặt an toàn và ổn định lên hàng đầu, nên sẽ không chuyển đổi hệ thống chứng minh ZK một cách quá táo bạo — có thể sẽ dùng Multi Prover làm bước chuyển tiếp, từng bước thăm dò và tiến hóa để hoàn thành nâng cấp thế hệ tiếp theo. Dù sao thì, quá trình chuyển đổi phải diễn ra êm xuôi.
Tuy nhiên, hiện tại nói chuyện chuyển đổi vẫn còn sớm — đây thực sự là định hướng phát triển cho 6–12 tháng tới.
5. Nickqiao: Trên hệ thống chứng minh hiện tại dựa trên PLONK và Lookup, Scroll có những đổi mới độc đáo nào không?
YeZhang: Hiện tại, hệ thống đang chạy trên mainnet của Scroll là halo2. Halo2 bắt nguồn từ nhóm dự án Zcash, ban đầu họ tạo ra một backend hỗ trợ Lookup và viết mạch linh hoạt. Sau đó, chúng tôi và nhóm PSE của Ethereum đã cùng cải tiến halo2, thay đổi sơ đồ cam kết đa thức từ IPA sang KZG, giúp giảm kích thước proof, từ đó xác minh ZK Proof trên Ethereum hiệu quả hơn.
Chúng tôi cũng đầu tư nhiều vào tăng tốc phần cứng GPU — so với việc dùng CPU để sinh ZKP, tốc độ sinh ZKP nhanh hơn 5–10 lần. Tổng thể, chúng tôi đã thay thế sơ đồ cam kết đa thức của halo2 gốc bằng phiên bản dễ xác minh hơn, đồng thời tối ưu hóa nhiều mặt ở Prover, và đầu tư nghiêm túc vào triển khai thực tế.

6. Nickqiao: Như vậy, hiện tại Scroll đang cùng nhóm PSE của Ethereum duy trì phiên bản halo2 dùng KZG. Thầy có thể chia sẻ cách hợp tác với nhóm PSE như thế nào?
YeZhang: Trước khi khởi động dự án, chúng tôi vốn đã quen một số kỹ sư trong nhóm PSE. Chúng tôi từng trao đổi, nói rằng muốn làm zkEVM, và ước lượng hiệu suất là ổn. Tình cờ cùng thời điểm đó, họ cũng muốn làm điều tương tự — thế là hai bên "gật đầu" ngay lập tức.
Vì vậy, chúng tôi quen những người muốn làm zkEVM thông qua cộng đồng Ethereum, từ Ethereum Research — tất cả đều muốn hiện thực hóa zkEVM và phục vụ Ethereum, nên rất tự nhiên bắt đầu mô hình hợp tác mã nguồn mở. Kiểu hợp tác này giống cộng đồng mã nguồn mở hơn là công ty thương mại — ví dụ, chúng tôi họp điện thoại hàng tuần để cập nhật tiến độ, thảo luận các vấn đề gặp phải.
Chúng tôi duy trì mã nguồn mở theo cách này, từ cải tiến halo2 đến triển khai zkEVM — trong quá trình khám phá, chúng tôi thường xuyên review mã lẫn nhau. Bạn có thể thấy từ lượng đóng góp mã trên Github: PSE viết khoảng một nửa, Scroll viết một nửa. Sau đó, chúng tôi hoàn tất kiểm toán mã và triển khai phiên bản thật sự được sản phẩm hóa, đang chạy trên mainnet. Tóm lại, mô hình hợp tác với PSE của Ethereum giống như một cộng đồng mã nguồn mở, mang tính tự phát.
7. Nickqiao: Thầy vừa nói rằng viết mạch zkEVM đòi hỏi kiến thức toán học và mật mã rất cao, do đó số người hiểu rõ zkEVM ắt hẳn rất ít. Vậy Scroll đảm bảo tính đúng đắn và ít lỗi của mạch như thế nào?
YeZhang: Vì mã nguồn mở, hầu như mỗi PR đều được thành viên của chúng tôi, một số người từ Ethereum và cộng đồng review, với quy trình kiểm toán nghiêm ngặt. Đồng thời, chúng tôi chi rất nhiều tiền cho kiểm toán mạch — trên 1 triệu USD — thuê các tổ chức kiểm toán mật mã và mạch uy tín nhất ngành như Trail of Bits, Zellic. Phần hợp đồng thông minh trên chuỗi cũng được OpenZeppelin kiểm toán. Về cơ bản, mọi thứ liên quan đến an toàn đều được đầu tư nguồn lực kiểm toán cao cấp nhất. Bên trong, chúng tôi còn có đội an toàn chuyên trách kiểm thử, liên tục nâng cao độ an toàn của Scroll.
Nickqiao: Ngoài cách kiểm toán này, có dùng các phương pháp nghiêm ngặt về mặt toán học như xác minh hình thức (formal verification) không?
YeZhang: Chúng tôi thực ra đã nghiên cứu hướng Xác minh Hình thức (Formal Verification) từ rất sớm, và Ethereum gần đây cũng đang cân nhắc cách làm formal verification cho zkEVM — đây thực sự là một hướng đi tốt. Tuy nhiên, hiện tại, việc thực hiện formal verification đầy đủ cho zkEVM vẫn còn sớm — chỉ có thể bắt đầu từ những module nhỏ. Vì Formal Verification có chi phí, ví dụ bạn cần viết một spec trước khi chạy nó trên mã nguồn, mà viết spec không dễ, và hệ thống này cần thời gian dài để hoàn thiện.
Vì vậy, tôi cho rằng hiện chưa phải lúc để thực hiện formal verification toàn diện cho zkEVM, nhưng chúng tôi sẽ tiếp tục tích cực nghiên cứu cùng các đối tác bên ngoài như Ethereum về cách làm formal verification cho zkEVM.
Hiện tại, cách tốt nhất vẫn là kiểm toán thủ công, vì ngay cả khi có spec và Formal Verification, nếu spec sai thì vẫn gặp vấn đề. Vì vậy, tôi nghĩ hiện tại tốt nhất vẫn là kiểm toán thủ công, kết hợp mã nguồn mở và chương trình thưởng phát hiện lỗi (bug bounty) để đảm bảo tính ổn định mã nguồn của Scroll.
Tuy nhiên, ở zkEVM thế hệ tiếp theo, cách làm formal verification, cách thiết kế zkEVM tốt hơn để dễ viết spec hơn, và dùng formal verification để chứng minh an toàn — là mục tiêu cuối cùng của Ethereum. Nghĩa là, khi một zkEVM đã được xác minh hình thức, họ có thể yên tâm triển khai nó lên mainnet Ethereum.

8. Nickqiao: Về halo2 mà Scroll dùng, nếu muốn hỗ trợ các hệ thống chứng minh mới như STARK, chi phí phát triển có lớn không? Có thể xây dựng hệ thống plugin hỗ trợ nhiều hệ thống chứng minh đồng thời không?
YeZhang: halo2 là một hệ thống chứng minh ZK cực kỳ mô-đun — bạn có thể thay thế miền (field), cam kết đa thức, v.v. Chỉ cần thay cam kết đa thức từ KZG sang FRI là về cơ bản có thể tạo ra một phiên bản halo2-STARK. Thực tế đã có người làm điều này, nên việc halo2 hỗ trợ STARK là hoàn toàn khả thi.
Tuy nhiên, trong triển khai thực tế, nếu theo đuổi hiệu suất cực cao, khung càng mô-đun càng dễ dẫn đến vấn đề hiệu suất — vì bạn hy sinh mức độ tùy chỉnh để đạt tính mô-đun, phải trả một cái giá. Chúng tôi đang liên tục theo dõi vấn đề: hướng phát triển tương lai nên là khung mô-đun hay khung cực kỳ tùy chỉnh? Đặc biệt khi chúng tôi có đội phát triển ZK đủ mạnh để duy trì một hệ thống chứng minh độc lập, giúp zkEVM hiệu quả hơn. Tất nhiên, cần cân nhắc, nhưng với halo2, nó có thể hỗ trợ FRI.
9. Nickqiao: Hướng cải tiến chính về ZK của Scroll hiện nay là gì? Là tối ưu thuật toán hiện tại, thêm các tính năng mới, v.v.?
YeZhang: Đội kỹ thuật của chúng tôi đang tập trung vào việc tiếp tục nâng cao hiệu suất Prover lên gấp đôi, đồng thời đạt mức tương thích EVM tốt nhất. Trong bản nâng cấp tiếp theo, chúng tôi sẽ duy trì vị trí là zkEVM tương thích nhất trong các ZK Rollup. Hiện tại, mọi zkEVM khác đều không tương thích tốt bằng chúng tôi.
Đây là một mặt mà đội kỹ thuật Scroll đang làm: tiếp tục tối ưu Prover và Compatibility, đồng thời giảm phí. Chúng tôi đã đầu tư rất nhiều nhân lực nghiên cứu zkEVM thế hệ tiếp theo — khoảng một nửa lực lượng kỹ thuật, nhằm đạt được việc sinh proof ZK trong vài phút hoặc vài giây, giúp hiệu suất Prover cao hơn.
Đồng thời, chúng tôi đang khám phá lớp thực thi zkEVM mới. Trước đây node của chúng tôi dùng go-ethereum, nhưng hiện có client Ethereum bằng Rust hiệu suất cao hơn là Reth. Vì vậy, chúng tôi đang nghiên cứu cách tích hợp zkEVM thế hệ tiếp theo với client Reth tốt hơn để nâng cao hiệu suất toàn chuỗi. Chúng tôi sẽ đánh giá xem, nếu zkEVM xây dựng quanh lớp thực thi mới, nên dùng cách triển khai và chuyển đổi nào là tốt nhất.
10. Nickqiao: Như vậy, với việc Scroll xem xét hỗ trợ nhiều hệ thống chứng minh, có cần thiết phải triển khai nhiều hợp đồng Verifier trên chuỗi không? Ví dụ như xác minh chéo (cross-validation)
YeZhang: Tôi nghĩ đây là hai vấn đề khác nhau. Thứ nhất, có cần thiết làm hệ thống chứng minh mô-đun và đa dạng Prover không? Tôi cho rằng điều này có ý nghĩa, vì từ đầu đến cuối, chúng tôi là một dự án mã nguồn mở. Càng làm khung mã nguồn mở này trở nên phổ quát, càng thu hút nhiều người cùng xây dựng, cộng đồng bạn càng lớn mạnh, sau này trong phát triển dự án hay dùng công cụ, có thể tự nhiên tận dụng sức mạnh bên ngoài. Vì vậy, việc tạo ra một khung chứng minh ZK không chỉ dùng cho riêng Scroll mà còn cho người khác là rất có ý nghĩa.
Thứ hai, về việc xác minh chéo trên mainnet — đây thực ra là chủ đề độc lập với việc hệ thống chứng minh có đa dạng hay hỗ trợ STARK/PLONK hay không. Rất hiếm dự án nào dùng cùng một zkEVM, xác minh bằng PLONK rồi lại xác minh bằng STARK — điều này rất hiếm vì nó không tăng an toàn đáng kể, ngược lại làm Prover tốn chi phí hơn. Vì vậy, thường không xảy ra xác minh chéo như vậy.
Chúng tôi thực ra đang làm một thứ gọi là Multi Prover — có thể có hai Prover cùng chứng minh một Block giống nhau, nhưng sẽ gộp hai Proof lại ở ngoài chuỗi rồi mới đưa lên chuỗi để xác minh. Vì vậy, sẽ không có xác minh chéo giữa STARK và SNARK trên chuỗi. Giải pháp Multi Prover của chúng tôi nhằm đảm bảo khi một bộ Prover có lỗi mã, bộ còn lại có thể thay thế — một hệ thống bị bug, hệ thống kia vẫn hoạt động bình thường. Vì vậy, đây là chủ đề khác với xác minh chéo.
11. Nickqiao: Với Multi Prover của Scroll, chương trình chứng minh của mỗi Prover có gì khác biệt?
YeZhang: Trước hết, giả sử tôi có một zkEVM chuẩn viết bằng halo2, một Prover chuẩn sinh ZKP rồi xác minh trên chuỗi, nhưng có một vấn đề: zkEVM rất phức tạp, có thể có lỗi. Nếu có lỗi, ví dụ hacker hoặc chính dự án lợi dụng lỗi này để sinh proof, cuối cùng rút sạch tiền của mọi người — điều này rất tệ.
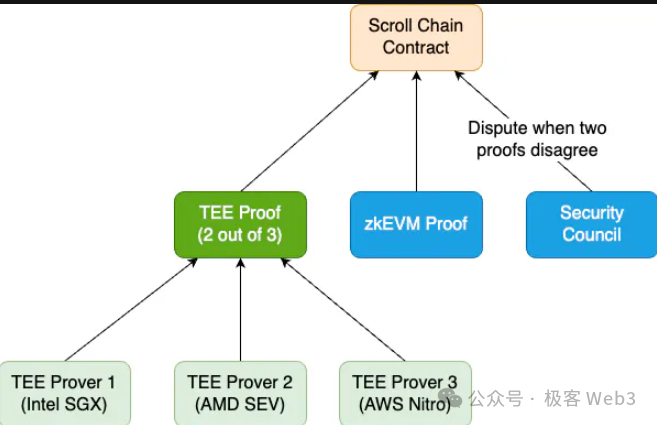
Tư tưởng cốt lõi của Multi Prover thực ra lần đầu tiên được Vitalik đề xuất tại sự kiện Bogota. Ý tưởng là: nếu một zkEVM có thể có lỗi, bạn có thể đồng thời chạy các loại Prover khác nhau — ví dụ dùng Prover dựa trên SGX/TEE (Scroll hiện dùng这套), hoặc dựa trên OP, hoặc dùng zkVM để chạy EVM. Dù bằng cách nào, các Prover này phải cùng chứng minh tính hợp lệ của một L2 Block.
Giả sử có 3 Prover khác loại, chỉ khi cả 3 proof do chúng sinh ra đều vượt qua xác minh, hoặc ít nhất 2 trong 3 vượt qua, bạn mới có thể xác định trạng thái cuối cùng của Layer2 trên Ethereum. Multi Prover đảm bảo khi một Prover gặp sự cố, hai Prover còn lại có thể thay thế, từ đó độ ổn định toàn hệ thống Prover rất tốt, nâng cao an toàn ZK Rollup. Tất nhiên, điều này cũng gây ra nhược điểm khác như chi phí vận hành Prover tổng thể tăng lên. Chúng tôi có một bài blog chuyên biệt giới thiệu các khái niệm này.
12. Nickqiao: Về phần sinh proof ZK của Scroll, mạng lưới sinh proof (mỏ zk) được xây dựng như thế nào — tự xây hay thuê ngoài một phần tính toán cho bên thứ ba như Cysic?
YeZhang: Hiện tại, thiết kế của chúng tôi thực ra rất đơn giản — chúng tôi muốn càng nhiều người sở hữu GPU hoặc thợ đào tham gia vào mạng lưới proof (mỏ zk) của chúng tôi. Tuy nhiên, hiện tại thị trường Prover của Scroll do chúng tôi tự vận hành. Chúng tôi hợp tác với một số bên thứ ba có cụm GPU để họ chạy Prover — nhưng đây là vì ổn định mainnet, vì một khi Prover phi tập trung sẽ nảy sinh nhiều vấn đề.
Ví dụ, nếu cơ chế khuyến khích thiết kế không tốt, không ai sinh proof cho bạn, hiệu suất mạng sẽ bị ảnh hưởng. Giai đoạn đầu, chúng tôi chọn cách tương đối tập trung, nhưng thiết kế giao diện và khung rất dễ chuyển sang mô hình phi tập trung. Người ta hoàn toàn có thể dùng khung kỹ thuật của chúng tôi để tạo mạng Prover phi tập trung, chỉ cần thêm cơ chế khuyến khích.
Tuy nhiên, hiện tại vì ổn định Scroll, mạng lưới sinh Prover của chúng tôi vẫn tập trung. Tương lai, chúng tôi sẽ mở rộng hơn việc phi tập trung hóa mạng Prover — mỗi người đều có thể chạy nút Prover riêng. Chúng tôi cũng đang hợp tác với các nền tảng bên thứ ba như Cysic, Snarkify network, để xem nếu ai đó muốn dùng stack kỹ thuật của chúng tôi khởi động Layer2 riêng, có thể kết nối trực tiếp vào thị trường Prover bên thứ ba để dùng dịch vụ Prover của họ.
13. Nickqiao: Scroll có đầu tư hay thành quả gì trong lĩnh vực tăng tốc phần cứng ZK không?
YeZhang: Thực ra đây chính là hai hướng lớn đầu tiên tôi từng đề cập — thứ nhất là biến zkEVM từ không thể thành có thể, thứ hai là lý do vì sao chúng tôi có thể làm được điều đó: vì hiệu suất tăng tốc phần cứng ZK đã được nâng cao.
Thực tế, 3 năm trước khi làm Scroll, tôi đã bắt đầu làm việc về tăng tốc phần cứng ZK, và cũng có các bài báo về ASIC hoặc tăng tốc GPU. Chúng tôi hiểu rất sâu về phần cứng zk, dù là chip hay GPU, dù là học thuật hay thực tiễn, đều có độ tin cậy rất cao.
Tuy nhiên, Scroll sẽ tập trung vào tăng tốc phần cứng GPU, vì chúng tôi không có nguồn lực chuyên về FPGA hay phần cứng, cũng không có kinh nghiệm sản xuất chip. Vì vậy, chúng tôi sẽ hợp tác với các công ty phần cứng như Cysic — họ chuyên về phần cứng, còn chúng tôi tập trung vào lĩnh vực phần mềm như tăng tốc GPU. Đội của chúng tôi sẽ tối ưu tăng tốc GPU và công bố mã nguồn, các đối tác bên ngoài có thể phát triển chuyên sâu như ASIC, và chúng tôi thường xuyên trao đổi, thảo luận các vấn đề gặp phải.
14. Nickqiao: Thầy vừa nói Scroll tương lai sẽ chuyển sang các hệ thống chứng minh khác. Với một số hệ thống chứng minh mới như Nova hay các thuật toán khác, thầy có thể giải thích sơ qua không? Chúng có ưu điểm gì?
YeZhang: Đúng vậy. Hiện tại, một trong những hướng chúng tôi đang khám phá nội bộ là dùng miền nhỏ hơn, có thể kết hợp với các hệ thống chứng minh hiện tại — ví dụ như các thư viện kiểu PLONKy3, có thể thực hiện nhanh các phép toán trên miền nhỏ. Đây là một lựa chọn: chuyển từ miền lớn trước đây sang miền nhỏ.
Chúng tôi cũng đang xem xét một số hướng khác, ví dụ hệ thống chứng minh GKR — thời gian sinh proof của nó ở mức tuyến tính, độ phức tạp thấp hơn nhiều so với các Prover khác, nhưng hiện chưa có cách triển khai kỹ thuật trưởng thành. Để làm được điều này, cần đầu tư thêm nhiều nhân lực và vật lực.
Tuy nhiên, ưu điểm của GKR là hiệu suất rất cao khi xử lý tính toán lặp lại — ví dụ tính toán chữ ký thực hiện 1000 lần, GKR có thể sinh proof rất hiệu quả. Cầu nối ZK Polyhedra dùng GKR để chứng minh chữ ký, hiệu suất rất cao. Hơn nữa, EVM có nhiều bước tính toán lặp lại, có thể dùng GKR để giảm đáng kể chi phí sinh proof ZK.
Một ưu điểm khác là hệ thống chứng minh GKR thực sự yêu cầu ít tài nguyên tính toán hơn nhiều so với các hệ thống khác. Ví dụ, dùng PLONK hay STARK để chứng minh quy trình tính hàm keccak, bạn cần commit và tính toàn bộ các biến trung gian, tất cả những gì sinh ra trong suốt quá trình tính keccak.
Nhưng với GKR, bạn chỉ cần commit lớp đầu vào rất ngắn — nó có thể biểu diễn tất cả tham số trung gian thông qua mối quan hệ truyền dẫn, không cần commit các biến trung gian, giúp giảm đáng kể chi phí tính toán. Giao thức sum check đằng sau GKR cũng được các framework mới nổi bật như Jolt, Lookup argument hoặc một số khung mới hấp dẫn sử dụng, nên hướng này rất tiềm năng — chúng tôi đang nghiên cứu nghiêm túc.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News














