

Giải mã BitVM: Cách xác minh bằng chứng gian lận trên chuỗi BTC? (Thực thi các opcode của EVM hoặc VM khác)
Tuyển chọn TechFlowTuyển chọn TechFlow
Giải mã BitVM: Cách xác minh bằng chứng gian lận trên chuỗi BTC? (Thực thi các opcode của EVM hoặc VM khác)
BitVM không cần dữ liệu on-chain, trước tiên phát hành và lưu trữ ngoài chuỗi, trên chuỗi chỉ lưu Commitment (cam kết).
Tác giả: Vụ Nguyệt & Faust, Geeker web3
Chuyên gia tư vấn: Kevin He, Người sáng lập Cộng đồng BitVM tiếng Trung, cựu Web3 Tech Head@Huobi
Dẫn nhập: Hiện nay, lớp L2 của Bitcoin đang trở thành một xu hướng mạnh mẽ, trên thị trường đã có hàng chục dự án tự định vị là "Lớp 2 Bitcoin". Trong đó, nhiều dự án tự xưng là "Rollup" thuộc hệ sinh thái Bitcoin tuyên bố áp dụng phương án được đề xuất trong bản whitepaper BitVM, khiến BitVM trở thành chủ đề nổi bật trong hệ sinh thái Bitcoin.
Tuy nhiên đáng tiếc là, phần lớn tài liệu hiện có về BitVM đều chưa giải thích rõ ràng và dễ hiểu nguyên lý hoạt động của nó.
Bài viết này là kết quả tổng hợp đơn giản sau khi chúng tôi đọc bản whitepaper chỉ dài 8 trang của BitVM và tra cứu thêm các tài liệu liên quan đến Taproot, cây MAST, Bitcoin Script. Để giúp người đọc dễ tiếp cận hơn, một số cách diễn đạt ở đây khác với nội dung trình bày trong bản whitepaper BitVM. Chúng tôi giả định rằng bạn đọc đã có kiến thức cơ bản về Layer 2 và hiểu được khái niệm đơn giản về "bằng chứng gian lận (fraud proof)".

Tóm gọn trong vài câu: Suy nghĩ cốt lõi của BitVM: không cần dữ liệu on-chain, trước tiên công bố và lưu trữ bên ngoài chuỗi, chỉ lưu trữ Commitment (cam kết) trên chuỗi.
Khi xảy ra tranh chấp/chứng minh gian lận, chúng ta chỉ đưa lên chuỗi những dữ liệu cần thiết để chứng minh mối liên hệ giữa dữ liệu này với Commitment đã đăng trên chuỗi. Sau đó, mạng chính BTC sẽ kiểm tra xem các dữ liệu on-chain này có vấn đề gì hay không, cũng như xác minh xem nhà sản xuất dữ liệu (nút xử lý giao dịch) có hành vi gian lận hay không. Mọi thứ đều tuân theo nguyên tắc dao cạo Occam —— “Nếu không cần thiết, đừng tăng thêm thực thể” (gì ít đưa lên chuỗi được thì càng tốt).

Phần chính: Tóm tắt dễ hiểu về cơ chế xác minh bằng chứng gian lận dựa trên BitVM:
1.Tư duy cốt lõi của BitVM
Trước hết, máy tính/bộ xử lý là một hệ thống đầu vào - đầu ra được tạo thành từ hàng loạt mạch cổng logic. Một trong những ý tưởng cốt lõi của BitVM là sử dụng Bitcoin Script mô phỏng hiệu ứng đầu vào - đầu ra của các mạch cổng logic.
Miễn là có thể mô phỏng được các mạch cổng logic, về mặt lý thuyết ta có thể xây dựng được máy Turing và thực hiện mọi tác vụ có thể tính toán được. Nói cách khác, nếu bạn có đủ tiền và nhân lực, bạn có thể tập hợp một nhóm kỹ sư dùng ngôn ngữ Bitcoin Script thô sơ để lần lượt mô phỏng các cổng logic, rồi dùng lượng lớn các cổng logic này để tái hiện chức năng của EVM hoặc WASM.
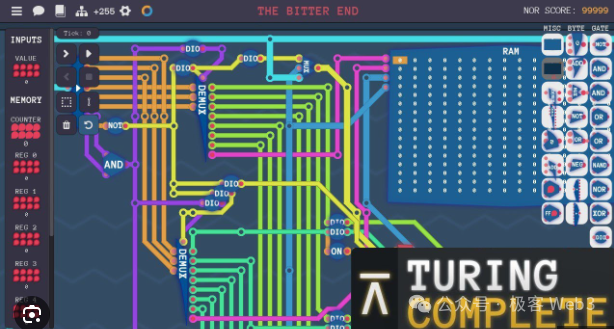
(Ảnh chụp màn hình từ một trò chơi giáo dục:《Turing Completeness》, nội dung chính là dùng các mạch cổng logic, đặc biệt là cổng NAND, để xây dựng một bộ xử lý CPU hoàn chỉnh)
Có người ví von suy nghĩ của BitVM giống như việc dùng mạch Redstone trong game《Minecraft》để xây một con chip M1. Hay nói cách khác, tương tự như dùng khối lego lắp nên tòa Empire State ở New York.

(Nghe đồn đây là chiếc "bộ xử lý" mà ai đó mất cả năm trời mới xây xong trong《Minecraft》)
2. Vì sao phải dùng Bitcoin Script để mô phỏng EVM hay WASM?
Việc này nghe có vẻ rất phiền phức. Nhưng lý do là vì phần lớn các dự án L2 Bitcoin thường chọn hỗ trợ các ngôn ngữ cao cấp như Solidity hoặc Move, trong khi ngôn ngữ duy nhất hiện tại có thể chạy trực tiếp trên chuỗi Bitcoin là Bitcoin Script – một ngôn ngữ lập trình thô sơ, gồm một loạt opcode đặc biệt, không đầy đủ Turing.

(Ví dụ mã Bitcoin Script)
Nếu L2 Bitcoin muốn giống như Arbitrum và các L2 Ethereum khác, thực hiện xác minh bằng chứng gian lận trên Layer 1 nhằm tận dụng tối đa độ an toàn của BTC, họ cần trực tiếp xác minh trên chuỗi BTC đối với "một giao dịch gây tranh cãi" hoặc "một opcode gây tranh cãi". Như vậy, cần phải chạy lại toàn bộ mã Solidity / opcode EVM mà L2 sử dụng ngay trên chuỗi Bitcoin. Vấn đề cuối cùng quy về:
Sử dụng ngôn ngữ lập trình đơn giản, gốc native của Bitcoin là Bitcoin Script để tái hiện chức năng của EVM hoặc máy ảo khác.
Do đó, nếu nhìn từ góc độ nguyên lý biên dịch, BitVM là chuyển đổi các opcode EVM/WASM/Javascript sang các opcode của Bitcoin Script, trong đó các mạch cổng logic đóng vai trò dạng trung gian (IR) giữa "opcode EVM → opcode Bitcoin Script".
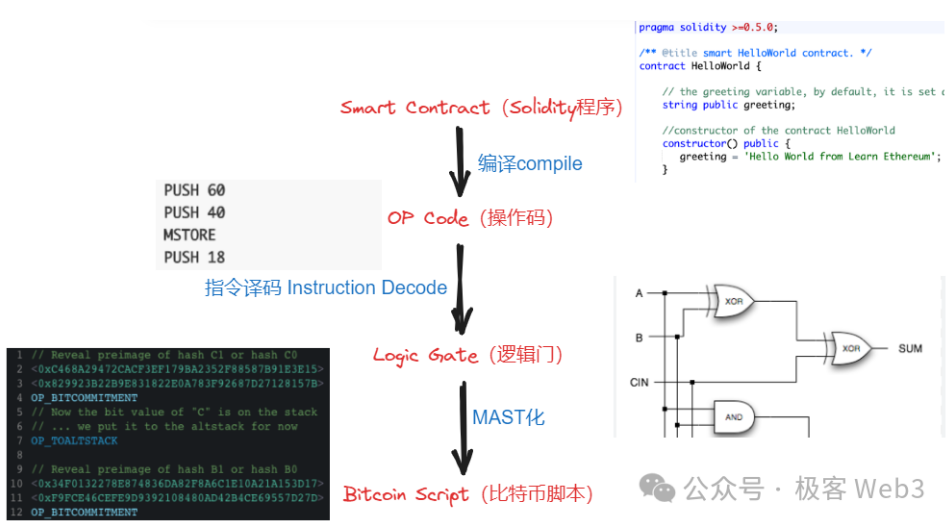
(Trong bản whitepaper BitVM, nói về ý tưởng tổng thể khi thực thi một số "lệnh gây tranh cãi" trên chuỗi Bitcoin)
Dù sao đi nữa, kết quả cuối cùng là mang các lệnh vốn chỉ xử lý được trên EVM/WASM sang trực tiếp xử lý trên chuỗi Bitcoin. Phương án này khả thi nhưng khó khăn nằm ở chỗ làm sao dùng lượng lớn mạch cổng logic làm dạng trung gian để biểu diễn tất cả các opcode EVM/WASM. Hơn nữa, việc dùng tổ hợp mạch cổng logic để trực tiếp biểu diễn một số quy trình xử lý giao dịch cực kỳ phức tạp có thể dẫn đến khối lượng công việc khổng lồ.
3. "Bằng chứng gian lận tương tác" giống hệt Arbitrum
Tiếp theo, ta nói đến một điểm cốt lõi khác được nhắc đến trong whitepaper BitVM, đó là "bằng chứng gian lận tương tác", gần như giống hệt với Arbitrum.
"Bằng chứng gian lận tương tác" liên quan đến một thuật ngữ gọi là assert (khẳng định). Thông thường, Proposer (người đề xuất) của L2 (thường do sequencer đảm nhiệm) sẽ đăng khẳng định assert trên Layer 1, tuyên bố rằng một số dữ liệu giao dịch, kết quả chuyển trạng thái là hợp lệ và chính xác.
Nếu có ai cho rằng khẳng định assert do Proposer gửi lên có vấn đề (dữ liệu liên quan sai lệch), sẽ phát sinh tranh cãi. Lúc này, Proposer và Challenger sẽ luân phiên trao đổi thông tin, dùng tìm kiếm nhị phân để nhanh chóng xác định một lệnh thao tác chi tiết cực nhỏ và đoạn dữ liệu liên quan.
Đối với lệnh thao tác gây tranh cãi này (OP Code), cần thực thi trực tiếp trên Layer 1 kèm theo tham số đầu vào, và xác minh kết quả đầu ra (các nút Layer 1 sẽ so sánh kết quả đầu ra do mình tính được với kết quả đầu ra mà Proposer đã công bố trước đó). Trong Arbitrum, điều này được gọi là "bằng chứng gian lận từng bước".

(Trong giao thức bằng chứng gian lận tương tác của Arbitrum, dùng tìm kiếm nhị phân duyệt qua dữ liệu do Proposer công bố để nhanh chóng xác định lệnh và kết quả thực thi gây tranh cãi, cuối cùng gửi bằng chứng gian lận từng bước lên Layer 1 để xác minh cuối cùng)
Tài liệu tham khảo: Cựu đại sứ kỹ thuật Arbitrum giải thích cấu trúc thành phần của Arbitrum (phần 1)

(Sơ đồ quy trình bằng chứng gian lận tương tác của Arbitrum, trình bày khá sơ lược)
Tới đây, tư tưởng bằng chứng gian lận từng bước đã rõ: Phần lớn các lệnh giao dịch xảy ra ở Layer 2 không cần xác minh lại trên chuỗi BTC. Chỉ riêng đoạn dữ liệu/mã vận hành gây tranh cãi nào đó, khi bị thách thức mới cần phát lại một lần trên Layer 1.
Nếu kết luận kiểm tra là:
-
Dữ liệu do Proposer công bố trước đó có vấn đề, tài sản ký quỹ của Proposer sẽ bị phạt (Slash);
-
Nếu Challenger có vấn đề, tài sản ký quỹ của Challenger sẽ bị phạt;
-
Nếu Prover không phản hồi thách thức trong thời gian dài, cũng có thể bị phạt.
Arbitrum dùng hợp đồng trên Ethereum để thực hiện các hiệu ứng trên, còn BitVM thì phải dùng Bitcoin Script để triển khai chức năng khóa thời gian, đa chữ ký, v.v.
4.Cây MAST và Bằng chứng Merkle
Sau khi nói sơ về "bằng chứng gian lận tương tác" và "bằng chứng gian lận từng bước", ta chuyển sang cây MAST và bằng chứng Merkle.
Như đã nói, trong phương án BitVM, sẽ không trực tiếp đưa lên chuỗi (on-chain) lượng lớn dữ liệu giao dịch xử lý bên ngoài chuỗi (off-chain) hay lượng lớn mạch cổng logic liên quan, mà chỉ đưa lên chuỗi một lượng dữ liệu/các mạch cổng logic cực nhỏ khi thật sự cần thiết.
Tuy nhiên, ta cần một phương pháp nào đó để chứng minh rằng các dữ liệu "ban đầu ở off-chain, giờ đưa lên on-chain" này không phải bịa đặt, đây chính là khái niệm Commitment (cam kết) thường thấy trong mật mã học. Bằng chứng Merkle là một dạng Commitment.
Trước hết, hãy nói về cây MAST. MAST là viết tắt của Merkelized Abstract Syntax Trees, là dạng cây Merkle được chuyển đổi từ cây AST trong lĩnh vực biên dịch.
Vậy cây AST là gì? Tên tiếng Việt là "cây cú pháp trừu tượng", đơn giản là chia nhỏ một lệnh phức tạp thành nhiều đơn vị thao tác cơ bản thông qua phân tích từ vựng, rồi tổ chức chúng thành một cấu trúc dữ liệu dạng cây.

(Một ví dụ đơn giản về cây AST, cây này chia nhỏ phép tính đơn giản x=2, y=x*3 thành các opcode底层 + dữ liệu)
Còn cây MAST chính là việc Merkle hóa cây AST để hỗ trợ bằng chứng Merkle. Cây Merkle có một ưu điểm là cho phép "nén dữ liệu" hiệu quả cao. Ví dụ, bạn muốn khi cần thiết thì công bố một đoạn dữ liệu trên cây Merkle lên chuỗi BTC, nhưng vẫn phải khiến người ngoài tin rằng đoạn dữ liệu này thực sự tồn tại trên cây Merkle chứ không phải bạn "bịa ra", thì phải làm thế nào?
Bạn chỉ cần ghi Root của cây Merkle lên chuỗi trước, sau này khi cần chỉ cần xuất trình bằng chứng Merkle để chứng minh đoạn dữ liệu cụ thể tồn tại trên cây Merkle tương ứng với Root là được.
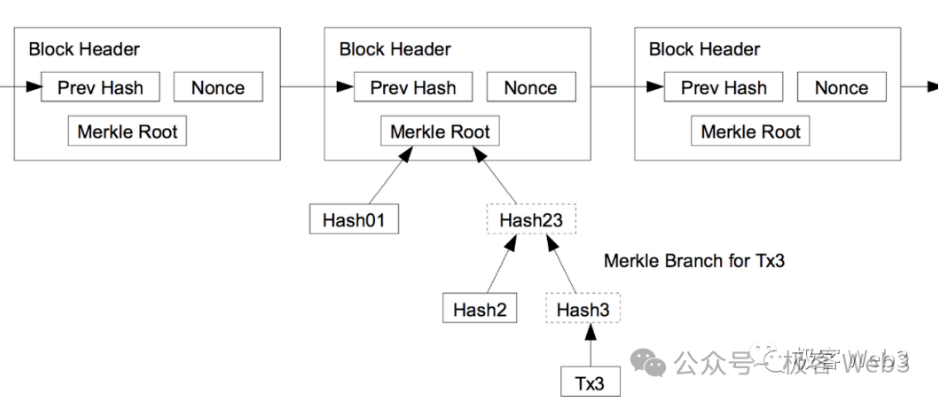
(Mối quan hệ giữa bằng chứng Merkle/Nhánh (Branch) và Root)
Do đó, không cần lưu trữ toàn bộ cây MAST trên chuỗi BTC, chỉ cần tiết lộ trước Root để làm Commitment, khi cần thì xuất trình đoạn dữ liệu + bằng chứng Merkle/Branch là đủ. Cách này giảm thiểu đáng kể lượng dữ liệu on-chain, đồng thời đảm bảo dữ liệu on-chain thực sự tồn tại trên cây MAST. Hơn nữa, chỉ công khai một phần nhỏ dữ liệu + bằng chứng Merkle trên chuỗi BTC thay vì toàn bộ dữ liệu, mang lại hiệu quả bảo vệ quyền riêng tư tốt.
Tài liệu tham khảo: Giữ lại dữ liệu và bằng chứng gian lận: Lý do Plasma không hỗ trợ hợp đồng thông minh
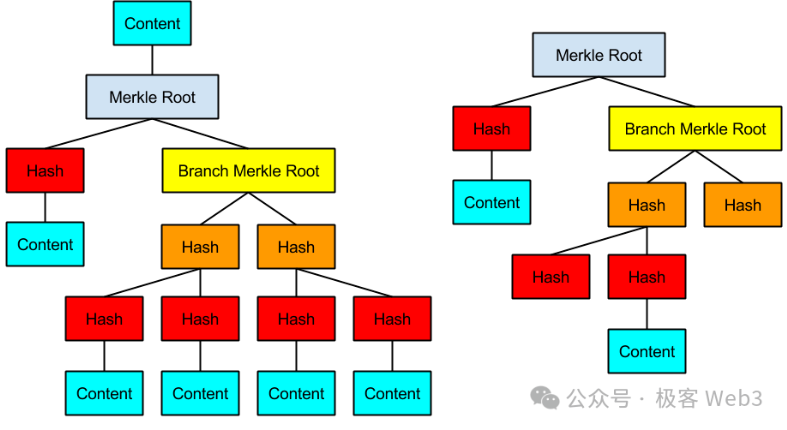
(Ví dụ cây MAST)
Phương án BitVM cố gắng dùng script Bitcoin biểu diễn toàn bộ các mạch cổng logic, sau đó tổ chức thành một cây MAST khổng lồ, các lá (leaf) ở đáy cây (Content trong hình) tương ứng với các mạch cổng logic được hiện thực bằng script Bitcoin.
Proposer của L2 sẽ thường xuyên đăng Root của cây MAST lên chuỗi BTC, mỗi cây MAST tương ứng với một giao dịch, liên quan đến tất cả tham số đầu vào / opcode / mạch cổng logic của giao dịch đó. Về mặt nào đó, điều này tương tự như việc Proposer của Arbitrum đăng Rollup Block lên chuỗi Ethereum.
Khi xảy ra tranh chấp, người thách thức sẽ tuyên bố trên chuỗi BTC rằng họ muốn thách thức Root nào mà Proposer đã công bố, sau đó yêu cầu Proposer tiết lộ một đoạn dữ liệu tương ứng với Root đó. Sau đó, Proposer sẽ xuất trình bằng chứng Merkle, lần lượt tiết lộ từng phần nhỏ dữ liệu của cây MAST trên chuỗi, cho đến khi cùng người thách thức xác định được mạch cổng logic gây tranh cãi. Sau đó có thể thực hiện việc phạt (Slash).
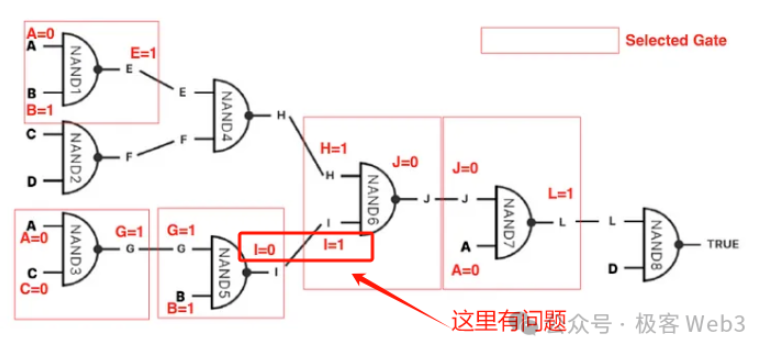
(Nguồn ảnh: Link)
5. Cuối cùng
Tới đây, phần quan trọng nhất của toàn bộ phương án BitVM cơ bản đã trình bày xong. Dù một vài chi tiết vẫn còn hơi mơ hồ, nhưng hy vọng bạn đọc đã nắm bắt được tinh hoa và trọng tâm của BitVM.
Còn về cam kết giá trị bit (bit value commitment) được nhắc đến trong whitepaper, mục đích là để ngăn chặn việc Proposer khi bị thách thức và buộc phải xác minh mạch cổng logic trên chuỗi, lại gán giá trị đầu vào cho cổng logic "vừa là 0 vừa là 1", gây ra sự nhập nhằng lẫn lộn.
Tổng kết
Phương án BitVM: trước tiên dùng script Bitcoin biểu diễn mạch cổng logic, sau đó dùng mạch cổng logic biểu diễn opcode của EVM/máy ảo khác, rồi dùng opcode biểu diễn quy trình xử lý bất kỳ lệnh giao dịch nào, cuối cùng tổ chức thành cây Merkle/cây MAST.
Một cây như vậy, nếu biểu diễn quy trình xử lý giao dịch quá phức tạp, dễ dàng vượt quá 100 triệu lá, do đó cần cố gắng giảm thiểu dung lượng block mà Commitment chiếm giữ cũng như phạm vi bị ảnh hưởng bởi bằng chứng gian lận.
Mặc dù bằng chứng gian lận từng bước chỉ cần đưa lên chuỗi một đoạn dữ liệu và script mạch cổng rất nhỏ, nhưng cây Merkle hoàn chỉnh phải được lưu trữ lâu dài bên ngoài chuỗi, để khi có người thách thức thì có thể đưa dữ liệu trên cây lên chuỗi bất cứ lúc nào.
Mỗi giao dịch xảy ra trên L2 sẽ tạo ra một cây Merkle lớn, áp lực tính toán và lưu trữ đối với các nút là điều dễ hình dung, đa số người dùng có lẽ không muốn vận hành nút (tuy nhiên dữ liệu lịch sử này có thể được loại bỏ theo thời gian, và mạng B^2专门引入类似 Filecoin 的 zk 存储证明,激励存储节点长期保存历史数据)
Tuy nhiên, các optimistic rollup dựa trên bằng chứng gian lận về bản chất không cần quá nhiều nút, vì mô hình tin cậy của chúng là 1/N – chỉ cần trong số N nút có 1 nút trung thực, có thể khởi động bằng chứng gian lận đúng lúc, thì mạng L2 vẫn an toàn.
Tuy nhiên, thiết kế giải pháp L2 dựa trên BitVM vẫn đối mặt với nhiều thách thức, ví dụ như:
1) Về lý thuyết, để nén dữ liệu hơn nữa, không nhất thiết phải xác minh opcode trực tiếp trên Layer 1, mà có thể nén quy trình xử lý opcode thành một bằng chứng zk, để người thách thức thách thức từng bước xác minh bằng chứng zk. Cách này có thể giảm mạnh lượng dữ liệu on-chain. Nhưng chi tiết phát triển cụ thể sẽ rất phức tạp.
2) Proposer và Challenger phải tương tác nhiều lần bên ngoài chuỗi, cần thiết kế giao thức ra sao, Commitment và quá trình thách thức nên được tối ưu hóa thêm như thế nào trong quy trình xử lý, đòi hỏi rất nhiều suy nghĩ.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News














