

Vitalik: Độ phức tạp đóng gói và độ phức tạp hệ thống trong thiết kế giao thức
Tuyển chọn TechFlowTuyển chọn TechFlow
Vitalik: Độ phức tạp đóng gói và độ phức tạp hệ thống trong thiết kế giao thức
Hỗ trợ vừa phải độ phức tạp trong đóng gói, luyện tập phán đoán của chúng ta trong các trường hợp cụ thể.
Tác giả: Vitalik Buterin, đồng sáng lập Ethereum
Biên dịch: Nam Phong, Unitimes
Một trong những mục tiêu chính trong thiết kế giao thức Ethereum là tối thiểu hóa độ phức tạp: làm cho giao thức đơn giản nhất có thể, đồng thời vẫn đảm bảo blockchain có thể thực hiện đầy đủ các chức năng cần thiết của một mạng lưới blockchain hiệu quả. Giao thức Ethereum hiện tại còn xa mới hoàn hảo về mặt này, đặc biệt vì nhiều phần của nó được thiết kế vào các năm 2014–2016 khi mà hiểu biết của chúng ta còn rất hạn chế. Tuy nhiên, chúng tôi vẫn đang nỗ lực tích cực để giảm thiểu độ phức tạp.
Tuy nhiên, một trong những thách thức của mục tiêu này là độ phức tạp rất khó định nghĩa, và đôi khi bạn phải cân nhắc giữa hai lựa chọn, mỗi lựa chọn mang đến một dạng phức tạp khác nhau với những chi phí khác nhau. Vậy làm thế nào để so sánh?
Có một công cụ trí tuệ mạnh mẽ giúp chúng ta suy nghĩ tinh tế hơn về độ phức tạp, đó là phân biệt giữa độ phức tạp được đóng gói (encapsulated complexity) và độ phức tạp hệ thống (systemic complexity).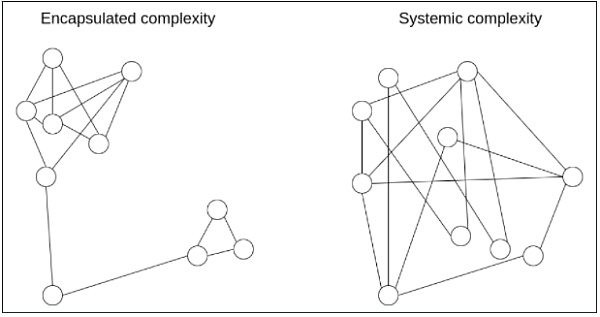
"Độ phức tạp được đóng gói" xuất hiện khi một bộ phận con bên trong của hệ thống là phức tạp, nhưng lại cung cấp một "giao diện" (interface) đơn giản ra bên ngoài. Trong khi đó, "độ phức tạp hệ thống" xuất hiện khi các thành phần khác nhau của hệ thống thậm chí không thể tách biệt rõ ràng và có những tương tác phức tạp lẫn nhau.
Dưới đây là một vài ví dụ.
Chữ ký BLS vs. Chữ ký Schnorr
Chữ ký BLS và chữ ký Schnorr là hai phương án chữ ký mật mã phổ biến, đều có thể xây dựng dựa trên đường cong elliptic.
Về mặt toán học, chữ ký BLS trông rất đơn giản:
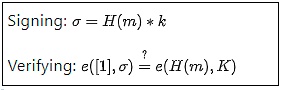
H là một hàm băm, m là thông điệp, k và K lần lượt là khóa riêng và khóa công khai. Cho đến giờ thì rất đơn giản. Tuy nhiên, độ phức tạp thực sự nằm ẩn trong định nghĩa của hàm e: phép ghép cặp đường cong elliptic (elliptic curve pairings), một trong những phần toán học khó hiểu nhất trong toàn bộ mật mã học.
Bây giờ hãy xem xét chữ ký Schnorr. Chữ ký Schnorr chỉ phụ thuộc vào các đường cong elliptic cơ bản. Tuy nhiên, logic tạo và xác minh chữ ký lại hơi phức tạp một chút:

Vậy… loại chữ ký nào “đơn giản” hơn? Điều này phụ thuộc vào việc bạn quan tâm điều gì! Chữ ký BLS có độ phức tạp kỹ thuật khổng lồ, nhưng tất cả đều được giấu kín trong định nghĩa của hàm e. Nếu bạn coi hàm e như một hộp đen, thì thực tế chữ ký BLS rất đơn giản. Ngược lại, chữ ký Schnorr có tổng độ phức tạp thấp hơn, nhưng lại có nhiều thành phần hơn, và có thể tương tác theo những cách tinh vi với thế giới bên ngoài.
Ví dụ:
-
Tạo chữ ký đa khóa (multi-sig) BLS (kết hợp hai khóa k1 và k2) rất đơn giản: chỉ cần σ1+σ2. Nhưng chữ ký đa khóa Schnorr yêu cầu hai vòng tương tác và phải xử lý các cuộc tấn công Key Cancellation tinh vi.
-
Chữ ký Schnorr yêu cầu sinh số ngẫu nhiên, còn chữ ký BLS thì không.
Phép ghép cặp đường cong elliptic thường là một “miếng bọt biển hấp thụ độ phức tạp” mạnh mẽ, vì chúng chứa đựng nhiều độ phức tạp được đóng gói, nhưng lại giúp giải pháp có ít độ phức tạp hệ thống hơn. Điều này cũng đúng trong lĩnh vực các cam kết đa thức (polynomial commitments): so sánh sự đơn giản của cam kết KZG (cần dùng phép ghép cặp) với logic nội bộ phức tạp hơn của các lập luận tích trong (inner product arguments, không cần phép ghép cặp).
Mật mã học vs. Kinh tế học mật mã
Một lựa chọn thiết kế quan trọng thường xuất hiện trong nhiều thiết kế blockchain là so sánh giữa mật mã học (cryptography) và kinh tế học mật mã (cryptoeconomics). Ví dụ điển hình (như trong Rollups) là lựa chọn giữa bằng chứng tính đúng đắn (tức là ZK-SNARKs) và bằng chứng gian lận (fraud proofs).
ZK-SNARKs là công nghệ phức tạp. Mặc dù ý tưởng cơ bản đằng sau ZK-SNARKs có thể được giải thích rõ ràng trong một bài viết, nhưng việc triển khai thực tế một ZK-SNARK để xác minh một phép tính lại liên quan đến độ phức tạp gấp nhiều lần phép tính gốc (vì vậy, lý do tại sao bằng chứng ZK-SNARK cho EVM vẫn đang trong quá trình phát triển, trong khi bằng chứng gian lận cho EVM đã ở giai đoạn thử nghiệm). Việc triển khai hiệu quả một bằng chứng ZK-SNARK đòi hỏi thiết kế mạch tối ưu cho mục đích cụ thể, sử dụng các ngôn ngữ lập trình lạ, và nhiều thách thức khác. Mặt khác, bằng chứng gian lận về bản chất rất đơn giản: nếu có ai thách thức, bạn chỉ cần chạy trực tiếp phép tính đó trên chuỗi. Để nâng cao hiệu suất, đôi khi thêm vào một sơ đồ tìm kiếm nhị phân, nhưng ngay cả như vậy cũng không làm tăng đáng kể độ phức tạp.
Mặc dù ZK-SNARKs phức tạp, nhưng độ phức tạp của chúng là độ phức tạp được đóng gói. Ngược lại, độ phức tạp thấp hơn của bằng chứng gian lận lại là độ phức tạp hệ thống. Dưới đây là một số ví dụ về độ phức tạp hệ thống mà bằng chứng gian lận gây ra:
-
Chúng yêu cầu kỹ thuật khuyến khích cẩn thận để tránh tình trạng bế tắc của người xác minh (verifier's dilemma).
-
Nếu được thực hiện trong quá trình đạt đồng thuận, chúng cần bổ sung loại giao dịch đặc biệt cho bằng chứng gian lận, đồng thời phải tính đến trường hợp nhiều bên cùng cạnh tranh gửi bằng chứng gian lận.
-
Chúng phụ thuộc vào một mạng đồng bộ.
-
Chúng cho phép các cuộc tấn công kiểm duyệt (censorship attacks) cũng có thể bị lợi dụng để trộm cắp.
-
Rollup dựa trên bằng chứng gian lận yêu cầu các nhà cung cấp thanh khoản hỗ trợ rút tiền tức thì.
Do những lý do này, ngay cả khi xét về độ phức tạp, các giải pháp mật mã thuần túy dựa trên ZK-SNARKs có thể an toàn hơn về lâu dài: ZK-SNARKs có các phần phức tạp hơn — điều này là thứ một số người phải chấp nhận khi chọn ZK-SNARKs; nhưng ZK-SNARKs lại có ít cảnh báo tiềm ẩn hơn — điều này là thứ mọi người đều phải lo lắng.
Các ví dụ khác
-
PoW (đồng thuận Nakamoto): độ phức tạp được đóng gói thấp vì cơ chế rất đơn giản và dễ hiểu, nhưng lại có độ phức tạp hệ thống cao hơn (ví dụ như các cuộc tấn công đào mỏ ích kỷ).
-
Hàm băm: độ phức tạp được đóng gói cao, nhưng lại có các thuộc tính rất dễ hiểu, do đó độ phức tạp hệ thống thấp.
-
Thuật toán xáo trộn ngẫu nhiên: thuật toán xáo trộn có thể nội bộ phức tạp (ví dụ như Whisk), nhưng đảm bảo tính ngẫu nhiên mạnh và dễ hiểu; hoặc nội bộ đơn giản, nhưng lại tạo ra tính ngẫu nhiên yếu và khó phân tích (tức là độ phức tạp hệ thống).
-
Giá trị do thợ đào khai thác (MEV): một giao thức mạnh đủ để hỗ trợ các giao dịch phức tạp có thể khá đơn giản bên trong, nhưng những giao dịch phức tạp đó có thể gây ra các tác động hệ thống phức tạp lên cơ chế khuyến khích của giao thức, vì chúng đề xuất khối theo những cách rất bất thường.
-
Cây Verkle: cây Verkle thực sự có một chút độ phức tạp được đóng gói, thực tế còn phức tạp hơn nhiều so với cây Merkle thông thường. Tuy nhiên, về mặt hệ thống, cây Verkle cung cấp một giao diện sạch sẽ và đơn giản tương tự như ánh xạ khóa-giá trị (key-value). Sự "rò rỉ" (leak) chính về độ phức tạp hệ thống là khả năng kẻ tấn công thao túng cây Verkle để khiến một giá trị cụ thể có một nhánh (branch) rất dài; nhưng rủi ro này giống hệt nhau đối với cả cây Verkle và cây Merkle.
Chúng ta nên cân nhắc như thế nào?
Thông thường, lựa chọn có độ phức tạp được đóng gói thấp hơn cũng chính là lựa chọn có độ phức tạp hệ thống thấp hơn, do đó có một lựa chọn rõ ràng đơn giản hơn. Nhưng trong những trường hợp khác, bạn phải đưa ra quyết định khó khăn giữa hai loại độ phức tạp. Đến đây thì rõ ràng rằng, nếu phải chọn, độ phức tạp được đóng gói sẽ ít nguy hiểm hơn. Rủi ro từ độ phức tạp hệ thống không đơn thuần là hàm số của độ dài đặc tả; một đoạn mã 10 dòng trong đặc tả tương tác với các phần khác có thể phức tạp hơn một hàm 100 dòng khác, vốn được xem như một hộp đen.
Tuy nhiên, phương pháp ưu tiên độ phức tạp được đóng gói cũng có giới hạn. Lỗi phần mềm có thể xảy ra ở bất kỳ đoạn mã nào, và khi mã càng lớn, xác suất xuất hiện lỗi tiến gần đến 1. Đôi khi, khi bạn cần tương tác với một bộ phận con theo những cách mới không ngờ tới, độ phức tạp ban đầu được đóng gói có thể trở thành độ phức tạp hệ thống.
Một ví dụ về điều này là cấu trúc cây trạng thái hai lớp (two-level state tree) hiện tại của Ethereum, đặc trưng bởi cây các đối tượng tài khoản, trong đó mỗi đối tượng tài khoản lại có một cây lưu trữ riêng.
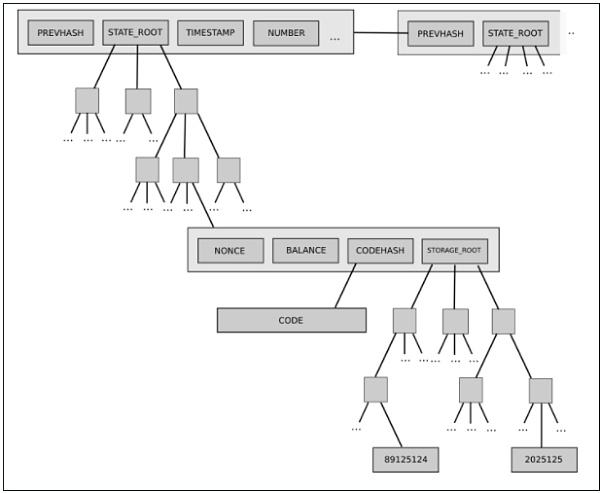
Cấu trúc cây này khá phức tạp, nhưng ban đầu, độ phức tạp này dường như được đóng gói tốt: phần còn lại của giao thức tương tác với cây như một kho lưu trữ khóa/giá trị có thể đọc/ghi, vì vậy chúng ta không cần lo lắng về cách cây được xây dựng.
Tuy nhiên, về sau, độ phức tạp này đã cho thấy ảnh hưởng hệ thống: khả năng của một tài khoản sở hữu một cây lưu trữ tùy ý lớn có nghĩa là không thể tin cậy dự đoán kích thước của một phần trạng thái cụ thể nào đó (ví dụ: "tất cả các tài khoản bắt đầu bằng 0x1234"). Điều này khiến việc chia nhỏ trạng thái thành nhiều phần trở nên khó khăn hơn, đồng thời làm phức tạp việc thiết kế giao thức đồng bộ và nỗ lực phân phối quá trình lưu trữ. Tại sao độ phức tạp được đóng gói lại trở thành hệ thống? Vì giao diện đã thay đổi. Giải pháp là gì? Đề xuất hiện tại chuyển sang cây Verkle cũng bao gồm việc chuyển sang thiết kế cây đơn lớp cân bằng.
Cuối cùng, trong bất kỳ trường hợp cụ thể nào, việc loại độ phức tạp nào được ưa chuộng hơn là một câu hỏi không có câu trả lời đơn giản. Điều tốt nhất chúng ta có thể làm là ủng hộ vừa phải độ phức tạp được đóng gói, nhưng không quá mức, và vận dụng phán đoán của mình trong từng trường hợp cụ thể. Đôi khi, hy sinh một chút độ phức tạp hệ thống để giảm mạnh độ phức tạp được đóng gói thực sự là cách tốt nhất. Đôi khi khác, bạn thậm chí có thể đánh giá sai cái nào là được đóng gói và cái nào không. Mỗi tình huống là khác biệt.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News














