

Sự trỗi dậy của ChatGPT: Từ GPT-1 đến GPT-3, kỷ nguyên AIGC đang đến gần
Tuyển chọn TechFlowTuyển chọn TechFlow
Sự trỗi dậy của ChatGPT: Từ GPT-1 đến GPT-3, kỷ nguyên AIGC đang đến gần
Lịch sử phát triển, nguyên lý công nghệ phía sau và những hạn chế của ChatGPT

ChatGPT là gì?
Gần đây, OpenAI đã ra mắt ChatGPT, một mô hình có thể tương tác theo hình thức trò chuyện và vì tính thông minh của nó nên đã được rất nhiều người dùng chào đón.
ChatGPT cũng là "người họ hàng" với InstructGPT mà OpenAI từng công bố trước đó. Việc huấn luyện mô hình ChatGPT sử dụng RLHF (học tăng cường với phản hồi từ con người). Có lẽ sự xuất hiện của ChatGPT chính là khúc dạo đầu cho việc OpenAI chuẩn bị ra mắt chính thức GPT-4.
GPT là gì? Từ GPT-1 đến GPT-3
Generative Pre-trained Transformer (GPT), là một mô hình học sâu tạo văn bản được huấn luyện dựa trên dữ liệu có sẵn trên Internet. Mô hình này được dùng trong hỏi đáp, tóm tắt văn bản, dịch máy, phân loại, tạo mã code và trí tuệ nhân tạo hội thoại.
Năm 2018, GPT-1 ra đời, cũng là năm khởi nguyên của các mô hình tiền huấn luyện trong xử lý ngôn ngữ tự nhiên (NLP).
Về hiệu năng, GPT-1 có khả năng khái quát nhất định, có thể áp dụng vào các nhiệm vụ NLP không liên quan đến giám sát.
Các nhiệm vụ phổ biến gồm:
-
Suy luận ngôn ngữ tự nhiên: Xác định mối quan hệ giữa hai câu (bao hàm, mâu thuẫn, trung lập);
-
Hỏi đáp và suy luận thường thức: Nhập đoạn văn và một số câu trả lời, đưa ra độ chính xác của câu trả lời;
-
Nhận diện độ tương đồng ngữ nghĩa: Xác định xem hai câu có liên quan về mặt ngữ nghĩa hay không;
-
Phân loại: Xác định xem văn bản đầu vào thuộc nhóm nào trong các nhóm đã định;
Mặc dù GPT-1 đạt được một số hiệu quả trên các nhiệm vụ chưa được điều chỉnh, nhưng khả năng khái quát của nó vẫn thấp hơn nhiều so với các nhiệm vụ được giám sát sau khi tinh chỉnh, do đó GPT-1 chỉ có thể coi là một công cụ hiểu ngôn ngữ khá chứ không phải là một AI đối thoại.
GPT-2 cũng xuất hiện đúng như kỳ vọng vào năm 2019. Tuy nhiên, GPT-2 không có nhiều đổi mới về cấu trúc mạng, mà chỉ sử dụng thêm tham số mạng và tập dữ liệu lớn hơn: mô hình lớn nhất gồm tổng cộng 48 tầng, với 1,5 tỷ tham số, mục tiêu học tập là dùng mô hình tiền huấn luyện không giám sát để thực hiện các nhiệm vụ có giám sát. Về hiệu năng, ngoài khả năng hiểu, GPT-2 lần đầu tiên thể hiện năng lực mạnh mẽ trong việc tạo nội dung: tóm tắt, trò chuyện, nối tiếp câu chuyện, viết truyện, thậm chí tạo tin giả, email lừa đảo hay đóng vai trực tuyến đều không thành vấn đề. Sau khi "trở nên lớn hơn", GPT-2 thực sự thể hiện khả năng phổ quát và mạnh mẽ, đạt hiệu suất tốt nhất thời điểm đó trên nhiều nhiệm vụ mô hình hóa ngôn ngữ cụ thể.
Tiếp đó, GPT-3 xuất hiện, là một mô hình không giám sát (hiện nay thường được gọi là mô hình tự giám sát), gần như có thể hoàn thành phần lớn các nhiệm vụ xử lý ngôn ngữ tự nhiên, ví dụ như tìm kiếm theo câu hỏi, đọc hiểu, suy luận ngữ nghĩa, dịch máy, tạo bài viết và trả lời tự động v.v... Hơn nữa, mô hình này thể hiện xuất sắc trên nhiều nhiệm vụ, ví dụ như đạt mức độ tốt nhất hiện tại trong dịch thuật tiếng Pháp-sang-Anh và tiếng Đức-sang-Anh, các bài viết do nó tạo ra gần như không thể phân biệt được là do con người hay máy tạo ra (tỷ lệ nhận diện đúng chỉ 52%, ngang với đoán mò). Điều đáng kinh ngạc hơn là nó đạt độ chính xác gần 100% trong phép toán cộng trừ hai chữ số, thậm chí còn có thể tự động tạo mã code theo mô tả nhiệm vụ. Một mô hình không giám sát lại đa năng và hiệu quả như vậy dường như mang lại hy vọng về trí tuệ nhân tạo chung, có lẽ đây chính là lý do chủ yếu khiến GPT-3 ảnh hưởng mạnh mẽ đến vậy.
Mô hình GPT-3 thực chất là gì?
Thực tế, GPT-3 chỉ đơn giản là một mô hình ngôn ngữ thống kê. Về góc độ học máy, mô hình ngôn ngữ là việc mô hình hóa phân phối xác suất của chuỗi từ, tức là dùng các đoạn đã nói làm điều kiện để dự đoán phân phối xác suất của các từ khác xuất hiện ở thời điểm tiếp theo. Mô hình ngôn ngữ vừa có thể đánh giá mức độ phù hợp với ngữ pháp của một câu (ví dụ: đánh giá độ tự nhiên, trôi chảy của câu trả lời do hệ thống hội thoại người-máy tạo ra), đồng thời cũng có thể dùng để dự đoán và tạo ra câu mới. Ví dụ, với đoạn “Buổi trưa 12 giờ rồi, chúng ta cùng nhau đến nhà hàng”, mô hình ngôn ngữ có thể dự đoán những từ có thể xuất hiện sau “nhà hàng”. Một mô hình ngôn ngữ thông thường sẽ dự đoán từ tiếp theo là “ăn cơm”, còn một mô hình mạnh hơn có thể nắm bắt thông tin thời gian và dự đoán từ hợp cảnh “ăn trưa”.
Thông thường, sức mạnh của một mô hình ngôn ngữ phụ thuộc chủ yếu vào hai điểm:
-
Trước hết là xem mô hình có thể tận dụng toàn bộ thông tin ngữ cảnh lịch sử hay không, trong ví dụ trên nếu không thể nắm bắt thông tin ngữ nghĩa xa như “buổi trưa 12 giờ”, thì mô hình ngôn ngữ gần như không thể dự đoán từ tiếp theo là “ăn trưa”.
-
Thứ hai, cần xem xét liệu có đủ dữ liệu ngữ cảnh lịch sử phong phú để mô hình học hay không, tức là tập dữ liệu huấn luyện có đủ phong phú hay không. Vì mô hình ngôn ngữ thuộc học tự giám sát, mục tiêu tối ưu là cực đại hóa xác suất mô hình ngôn ngữ trên văn bản đã thấy, do đó bất kỳ văn bản nào cũng có thể làm dữ liệu huấn luyện mà không cần gắn nhãn.
Do GPT-3 có hiệu suất mạnh hơn và số lượng tham số rõ ràng lớn hơn, nó bao gồm nhiều văn bản chủ đề hơn, vượt trội rõ rệt so với thế hệ trước GPT-2.
Là mạng thần kinh dày đặc lớn nhất hiện nay, GPT-3 có thể chuyển đổi mô tả trang web thành mã tương ứng, bắt chước cách kể chuyện của con người, sáng tác thơ tùy chỉnh, tạo kịch bản trò chơi, thậm chí mô phỏng các triết gia quá cố để… dự đoán chân lý của cuộc sống. Thêm vào đó, GPT-3 không cần tinh chỉnh, khi xử lý các bài toán ngữ pháp, nó chỉ cần vài mẫu kiểu đầu ra (học ít-shot).
Có thể nói GPT-3 dường như đã thỏa mãn mọi tưởng tượng của chúng ta về một chuyên gia ngôn ngữ.
GPT-3 có những vấn đề gì?
Tuy nhiên GTP-3 không hoàn hảo, một trong những lo ngại lớn nhất hiện nay về trí tuệ nhân tạo là các chatbot và công cụ tạo văn bản có thể học tất cả văn bản trên mạng một cách vô tội vạ và không phân biệt chất lượng, từ đó sản sinh ra các đầu ra ngôn ngữ sai lệch, xúc phạm ác ý hoặc thậm chí mang tính tấn công, điều này sẽ ảnh hưởng nghiêm trọng đến ứng dụng tiếp theo của chúng.
OpenAI cũng từng đề cập rằng họ sẽ phát hành GPT-4 mạnh mẽ hơn trong tương lai gần:

So sánh GPT-3 với GPT-4 và bộ não con người (Nguồn ảnh: Lex Fridman @youtube)
Nghe nói GPT-4 sẽ được phát hành vào năm tới, có thể vượt qua bài kiểm tra Turing và tiên tiến đến mức không khác gì con người, ngoài ra chi phí doanh nghiệp áp dụng GPT-4 cũng sẽ giảm mạnh.
ChatGPT và InstructGPT
Khi nói đến ChatGPT, cần nhắc đến "tiền thân" của nó là InstructGPT.
Đầu năm 2022, OpenAI đã công bố InstructGPT, trong nghiên cứu này, so với GPT-3, OpenAI đã áp dụng nghiên cứu căn chỉnh (alignment research) để huấn luyện ra mô hình ngôn ngữ InstructGPT chân thực hơn, vô hại hơn và tuân thủ tốt hơn ý định của người dùng.
InstructGPT là phiên bản GPT-3 được tinh chỉnh lại, có thể giảm thiểu đầu ra độc hại, sai sự thật và thiên vị.
Nguyên lý hoạt động của InstructGPT là gì?
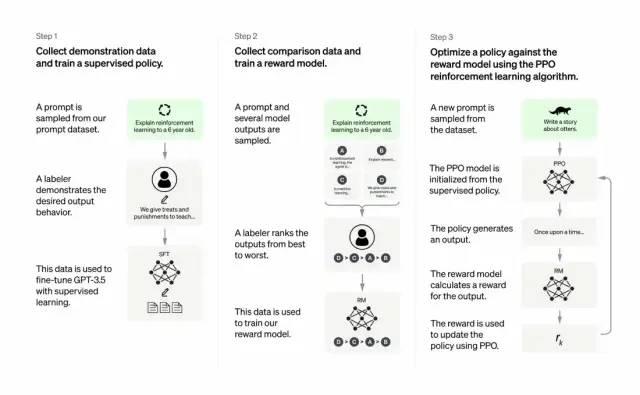
Các nhà phát triển kết hợp học có giám sát và học tăng cường dựa trên phản hồi từ con người để nâng cao chất lượng đầu ra của GPT-3. Trong phương pháp học này, con người xếp hạng các đầu ra tiềm năng của mô hình; thuật toán học tăng cường sẽ thưởng cho mô hình tạo ra các tài liệu tương tự như đầu ra chất lượng cao.
Tập dữ liệu huấn luyện bắt đầu bằng việc tạo prompt, trong đó một số prompt dựa trên đầu vào của người dùng GPT-3, ví dụ như "Kể cho tôi một câu chuyện về con ếch" hoặc "Giải thích về chuyến đổ bộ mặt trăng cho một đứa trẻ 6 tuổi bằng vài câu ngắn".
Nhà phát triển chia prompt thành ba phần và tạo phản hồi cho từng phần theo cách khác nhau:
-
Các tác giả do con người viết sẽ phản hồi nhóm prompt đầu tiên. Các nhà phát triển tinh chỉnh một GPT-3 đã được huấn luyện để biến nó thành InstructGPT, nhằm tạo ra các phản hồi hiện có cho từng prompt.
-
Bước tiếp theo là huấn luyện một mô hình để thưởng cao hơn cho các phản hồi tốt hơn. Với nhóm prompt thứ hai, mô hình đã được tối ưu hóa sẽ tạo ra nhiều phản hồi. Người đánh giá do con người thực hiện sẽ xếp hạng từng phản hồi. Khi đưa ra một prompt và hai phản hồi, một mô hình thưởng (một GPT-3 khác đã được tiền huấn luyện) học cách tính thưởng cao hơn cho phản hồi được xếp hạng cao và thưởng thấp hơn cho phản hồi kém.
-
Các nhà phát triển sử dụng nhóm prompt thứ ba và phương pháp học tăng cường Proximal Policy Optimization (PPO) để tinh chỉnh thêm mô hình ngôn ngữ. Sau khi đưa ra prompt, mô hình ngôn ngữ sẽ tạo phản hồi, còn mô hình thưởng sẽ cấp phần thưởng tương ứng. PPO sử dụng phần thưởng để cập nhật mô hình ngôn ngữ.
Điều quan trọng nằm ở đâu?
Cốt lõi nằm ở —— trí tuệ nhân tạo cần phải là trí tuệ nhân tạo có trách nhiệm.
Các mô hình ngôn ngữ của OpenAI có thể hỗ trợ trong lĩnh vực giáo dục, trị liệu ảo, công cụ hỗ trợ viết, trò chơi nhập vai v.v... Trong những lĩnh vực này, thiên kiến xã hội, thông tin sai lệch và nội dung độc hại đều là những vấn đề khá nan giải; chỉ những hệ thống có thể tránh được những thiếu sót này mới thực sự hữu ích.
Quá trình huấn luyện của ChatGPT và InstructGPT khác nhau ở điểm nào?
Tổng thể, ChatGPT giống như InstructGPT được nêu ở trên, đều được huấn luyện bằng RLHF (học tăng cường với phản hồi từ con người).
Điểm khác biệt nằm ở cách thiết lập dữ liệu phục vụ huấn luyện (và thu thập). (Ở đây giải thích thêm: mô hình InstructGPT trước đây, với mỗi đầu vào sẽ cho một đầu ra, sau đó so sánh với dữ liệu huấn luyện, nếu đúng thì thưởng, sai thì phạt; còn ChatGPT hiện nay với một đầu vào, mô hình đưa ra nhiều đầu ra, sau đó con người xếp hạng các kết quả này từ “giống lời người” đến “vớ vẩn”, mô hình học theo cách xếp hạng của con người, chiến lược này gọi là học có giám sát, cảm ơn Tiến sĩ Trương Tử Kiêm đã góp ý đoạn này.)
ChatGPT có những hạn chế gì?
Cụ thể như sau:
a) Trong giai đoạn học tăng cường (RL) khi huấn luyện, không có nguồn cụ thể nào về chân lý hoặc câu trả lời chuẩn để trả lời câu hỏi của bạn.
b) Mô hình huấn luyện trở nên thận trọng hơn, có thể từ chối trả lời (để tránh báo động sai).
c) Việc huấn luyện có giám sát có thể gây hiểu lầm/thiên vị cho mô hình, khiến nó nghiêng về việc biết câu trả lời lý tưởng, thay vì mô hình tạo ra một loạt phản hồi ngẫu nhiên và chỉ có người đánh giá chọn ra các phản hồi tốt/xếp hạng cao
Lưu ý: ChatGPT nhạy cảm với cách diễn đạt. Đôi khi mô hình không phản hồi một cụm từ nào đó, nhưng chỉ cần điều chỉnh nhẹ câu hỏi/cụm từ, nó cuối cùng lại trả lời đúng. Người huấn luyện có xu hướng thích các câu trả lời dài hơn vì trông có vẻ toàn diện hơn, dẫn đến xu hướng trả lời dài dòng, đồng thời mô hình có thể lạm dụng một số cụm từ nhất định. Nếu gợi ý ban đầu hoặc câu hỏi mơ hồ, mô hình sẽ không yêu cầu làm rõ một cách thích hợp.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News














