

알리바바 Qwen3, 전 세계 오픈소스 정상에 등극… DeepSeek-R1 제치고 2시간 만에 별 17k 개 급습
작가: 신지원

【신지원 리드】 알리바바 Qwen3가 오늘 새벽 오픈소스로 공개되며 전 세계 오픈소스 대규모 모델의 정상에 등극했다! 성능은 DeepSeek-R1과 OpenAI o1을 모두 능가하며, MoE 아키텍처를 채택하고 총 파라미터 수는 235B로 주요 벤치마크에서 압도적인 성과를 거두었다. 이번에 공개된 Qwen3 제품군은 8종의 혼합 추론 모델 전체를 오픈소스로 제공하며 무료 상업적 이용이 가능하다.
오늘 새벽, 전 세계가 기다려온 알리바바의 차세대 통의천문 모델 Qwen3가 드디어 오픈소스로 공개됐다!
출시와 동시에 곧바로 전 세계 최강 오픈소스 모델의 왕좌에 올랐다.
DeepSeek-R1의 1/3 수준의 파라미터임에도 불구하고 비용은 크게 줄었으며, R1, OpenAI-o1 등 글로벌 최정상 모델들을 성능 면에서 전반적으로 능가한다.
Qwen3은 중국 최초의 '혼합 추론 모델'로서 '빠른 사고'와 '느린 사고'를 동일한 모델 내에 통합하여 간단한 요청에는 낮은 컴퓨팅 자원으로 즉시 답변하고, 복잡한 문제에는 다단계 깊이 있는 사고를 수행함으로써 컴퓨팅 자원 소비를 크게 절감한다.
MoE(Expert의 혼합) 아키텍처를 채택하였으며, 총 파라미터 수는 235B, 활성화되는 파라미터는 단 22B이다.
사전 학습 데이터량은 36조 토큰에 달하며, 후속 학습 단계에서 여러 라운드의 강화 학습을 통해 비사고 모드를 사고 모델에 원활하게 통합하였다.
탄생과 동시에 Qwen3은 주요 벤치마크를 휩쓸었다.
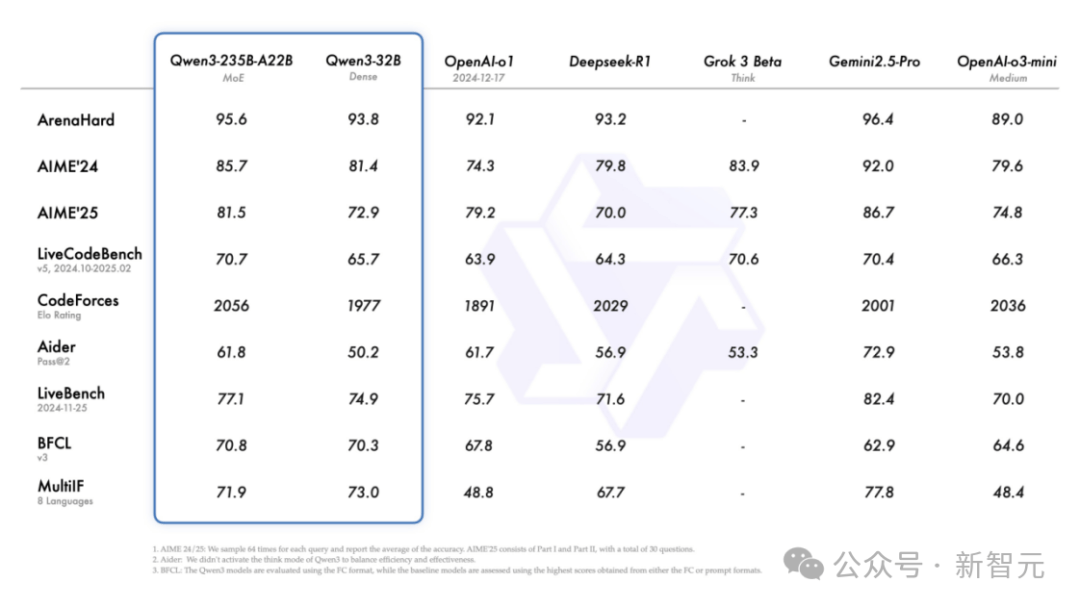
뿐만 아니라 성능이 크게 향상되었음에도 배포 비용은 크게 낮아져, Qwen3 풀버전을 단 4장의 H20 카드로 배포할 수 있으며, 메모리 사용량은 유사한 성능의 모델과 비교해 1/3 수준에 불과하다!
주요 특징 요약:
· 0.6B, 1.7B, 4B, 8B, 14B, 32B 및 30B-A3B, 235B-A22B 등 다양한 규모의 밀집형(Dense) 모델과 MoE 모델을 포함한다.
· 복잡한 논리 추론, 수학, 코딩 작업을 위한 '사고 모드'와 효율적인 일반 채팅을 위한 '비사고 모드' 사이를 원활하게 전환할 수 있어 다양한 시나리오에서 최적의 성능을 보장한다.
· 수학, 코드 생성, 상식 및 논리 추론 분야에서 이전의 QwQ(사고 모드) 및 Qwen2.5 instruct(비사고 모드) 모델보다 현저히 향상된 추론 능력을 갖췄다.
· 인간 선호도에 더 부합하며, 창의적 글쓰기, 역할극, 다중 대화 및 지시어 따르기 등에서 우수하여 더욱 자연스럽고 몰입감 있고 현실감 있는 대화 경험을 제공한다.
· AI 에이전트 기능에 능통하여 사고 모드와 비사고 모드 모두에서 외부 도구와의 정확한 통합을 지원하며, 복잡한 에이전트 기반 작업에서 오픈소스 모델 중 최고 수준의 성능을 달성한다.
· 처음으로 119개 언어 및 방언을 지원하며 강력한 다국어 지시어 수행 및 번역 능력을 갖추고 있다.
현재 Qwen3은 모더랩(MoodelScope) 커뮤니티, Hugging Face, GitHub에 동시에 출시되어 온라인 체험도 가능하다.
전 세계 개발자, 연구기관, 기업은 누구나 무료로 모델을 다운로드하여 상업적으로 이용할 수 있으며, 알리클라우드 백련(Bailian)을 통해 Qwen3 API 서비스를 호출할 수도 있다. 개인 사용자는 통의 앱(Tongyi App)을 통해 즉시 Qwen3을 체험할 수 있으며, 쿤즈(Kuaiz)는 곧 전면적으로 Qwen3를 탑재할 예정이다.
온라인 체험:
모더랩 커뮤니티:
https://modelscope.cn/collections/Qwen3-9743180bdc6b48
Hugging Face:
https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
GitHub:
https://github.com/QwenLM/Qwen3
이로써 알리바바 통의는 지금까지 200개 이상의 모델을 오픈소스로 공개했으며, 전 세계 다운로드 횟수는 3억 회를 넘었고, 천문 계열 파생 모델 수는 10만 개를 초과하여 미국의 Llama를 완전히 능가하며 전 세계 1위의 오픈소스 모델이 되었다!
Qwen3 제품군 등장
8종의 '혼합 추론' 모델 전면 오픈소스화
이번에 알리바바는 30B, 235B 크기의 MoE 모델 2종과 0.6B, 1.7B, 4B, 8B, 14B, 32B 등 6종의 밀집형 모델을 포함한 8종의 혼합 추론 모델을 한꺼번에 오픈소스로 공개하였으며, 모두 Apache 2.0 라이선스를 적용하였다.
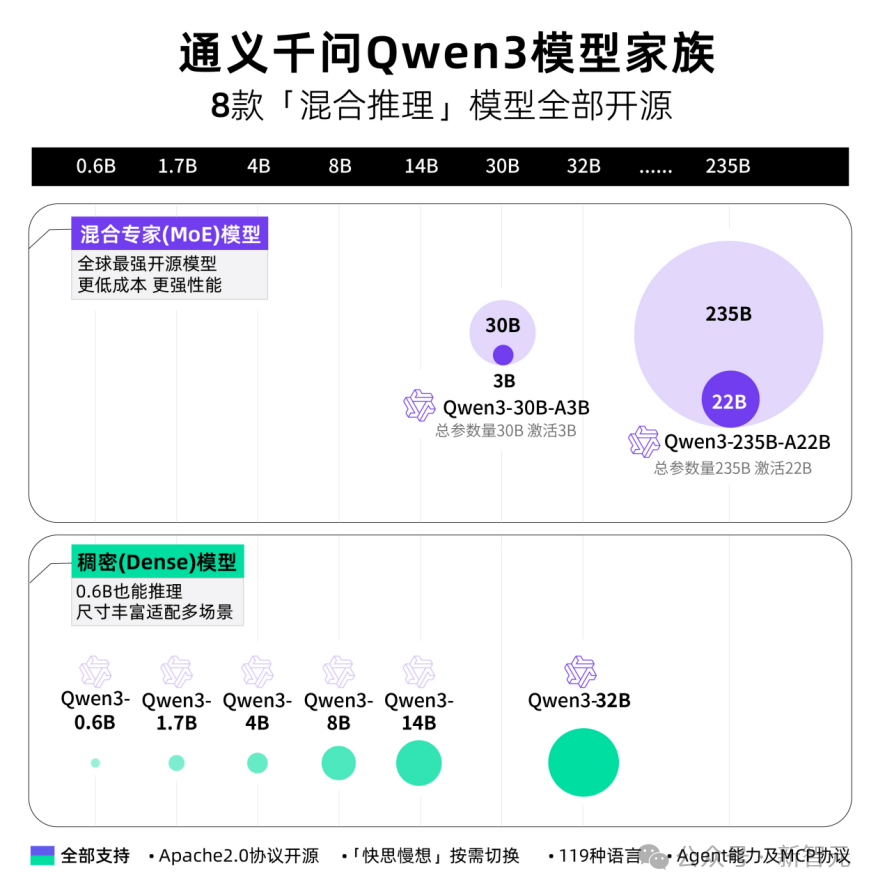
각 모델은 동일 규모의 오픈소스 모델 중 SOTA를 달성하였다.
Qwen3의 30B 파라미터 MoE 모델은 10배 이상의 모델 성능 레버리지를 실현하여 단 3B 파라미터만 활성화해도 이전 세대 Qwen2.5-32B 모델의 성능과 맞먹는다.
Qwen3의 밀집형 모델 성능도 계속 돌파하여, 절반의 파라미터 수로 동등한 고성능을 실현한다. 예를 들어 Qwen3의 32B 버전은 Qwen2.5-72B의 성능을 넘어선다.
동시에 모든 Qwen3 모델은 혼합 추론 모델이며, API를 통해 필요에 따라 '사고 예산(thinking budget)' (즉, 최대 심층 사고 토큰 수)을 설정하여 다양한 수준의 사고를 수행할 수 있어 AI 애플리케이션과 다양한 시나리오에서 성능과 비용의 다양한 요구를 유연하게 충족시킨다.
예를 들어 4B 모델은 모바일 기기용 최적의 크기이며, 8B는 PC 및 자동차 엣지에서 부드럽게 배포 활용 가능하다. 32B는 대규모 기업 배포에 가장 인기가 많으며, 여건이 있는 개발자라면 쉽게 시작할 수 있다.
새로운 오픈소스 모델의 왕, 기록 경신
Qwen3은 추론, 명령어 준수, 도구 호출, 다국어 능력 등에서 모두 크게 향상되어 국산 모델 및 전 세계 오픈소스 모델의 새로운 성능 기록을 수립했다—
AIME25 평가에서 오랜 수학 수준을 평가하는 테스트에서 Qwen3은 81.5점을 기록하여 오픈소스 모델의 신기록을 수립했다.
코드 능력을 평가하는 LiveCodeBench 평가에서 Qwen3은 70점 이상을 돌파하여 Grok3의 성과를 뛰어넘었다.
모델의 인간 선호 정렬 정도를 평가하는 ArenaHard 평가에서 Qwen3은 95.6점으로 OpenAI-o1 및 DeepSeek-R1을 능가했다.

구체적으로, 플래그십 모델인 Qwen3-235B-A22B는 DeepSeek-R1, o1, o3-mini, Grok-3, Gemini-2.5-Pro 등의 주요 모델과 비교하여 코딩, 수학, 일반 능력 등 각종 벤치마크에서 매우 뛰어난 성적을 거두었다.
또한 소형 MoE 모델인 Qwen3-30B-A3B는 QwQ-32B의 활성화 파라미터의 1/10 수준임에도 불구하고 성능이 오히려 더 우수하다.
심지어 Qwen3-4B와 같은 소형 모델도 Qwen2.5-72B-Instruct 모델의 성능과 견줄 수 있다.
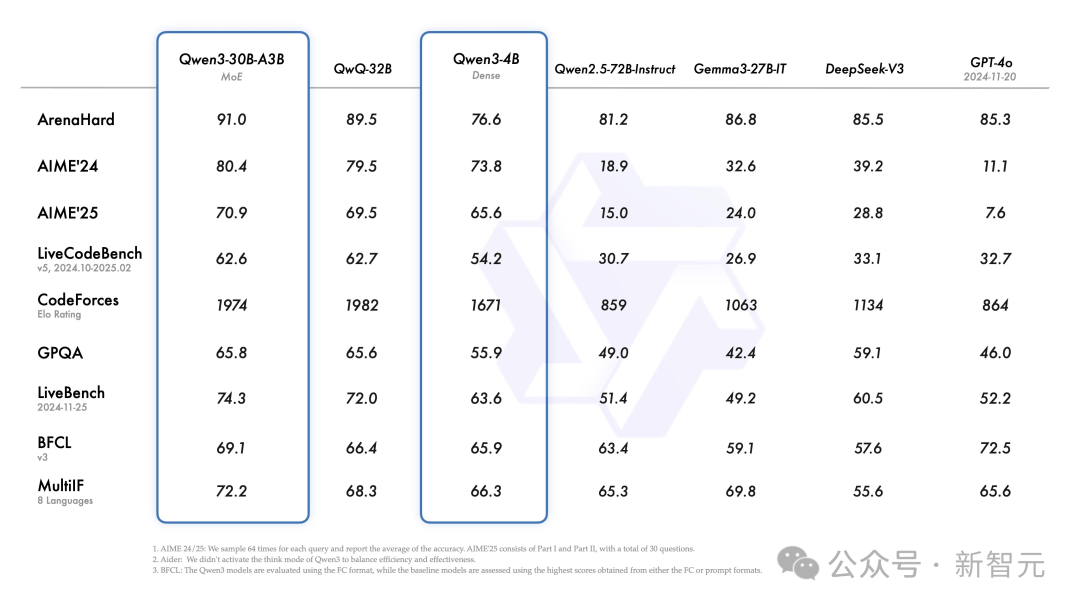
튜닝된 모델인 Qwen3-30B-A3B 및 사전 학습 버전(Qwen3-30B-A3B-Base)은 현재 Hugging Face, ModelScope 및 Kaggle 등의 플랫폼에서 확인할 수 있다.
배포의 경우, 알리바바는 SGLang 및 vLLM 프레임워크 사용을 권장한다. 로컬 사용의 경우 Ollama, LMStudio, MLX, llama.cpp 및 KTransformers 등의 도구를 적극 추천한다.
연구, 개발 또는 생산 환경을 막론하고 Qwen3은 다양한 워크플로우에 손쉽게 통합될 수 있다.
에이전트(Agent) 및 대규모 모델 애플리케이션 폭발에 긍정적 영향
말할 것도 없이, Qwen3은 다가올 에이전트 및 대규모 모델 애플리케이션의 폭발적인 성장에 더 나은 지원을 제공한다.
모델의 에이전트 능력을 평가하는 BFCL 평가에서 Qwen3은 70.8이라는 새로운 기록을 수립하여 Gemini2.5-Pro, OpenAI-o1 등 정상급 모델을 능가하였으며, 이는 에이전트의 도구 호출 장벽을 크게 낮출 것이다.
또한 Qwen3은 기본적으로 MCP 프로토콜을 지원하며 강력한 도구 호출 기능을 갖추고 있으며, 도구 호출 템플릿과 도구 호출 파서를 패키징한 Qwen-Agent 프레임워크와 결합된다.
이는 코딩 복잡성을 크게 감소시키고, 효율적인 스마트폰 및 컴퓨터 에이전트 작업 등을 실현한다.
주요 특징
혼합 추론 모드
Qwen3 모델은 혼합 문제 해결 방식을 도입한다. 두 가지 모드를 지원한다:
1. 사고 모드: 이 모드에서는 모델이 단계별로 추론한 후 답변을 제시한다. 복잡한 문제에 깊이 있는 사고가 필요한 경우에 적합하다.
2. 비사고 모드: 이 모드에서는 모델이 신속하게 답변을 제공하며, 속도가 중요한 간단한 문제에 적합하다.
이러한 유연성 덕분에 사용자는 작업의 복잡성에 따라 모델의 추론 과정을 조절할 수 있다.
예를 들어 어려운 문제는 확장된 추론을 통해 해결하고, 간단한 문제는 지연 없이 직접 답변할 수 있다.
중요한 것은 이러한 두 모드의 결합이 모델이 추론 자원을 안정적이고 효율적으로 제어하는 능력을 크게 향상시켰다는 점이다.
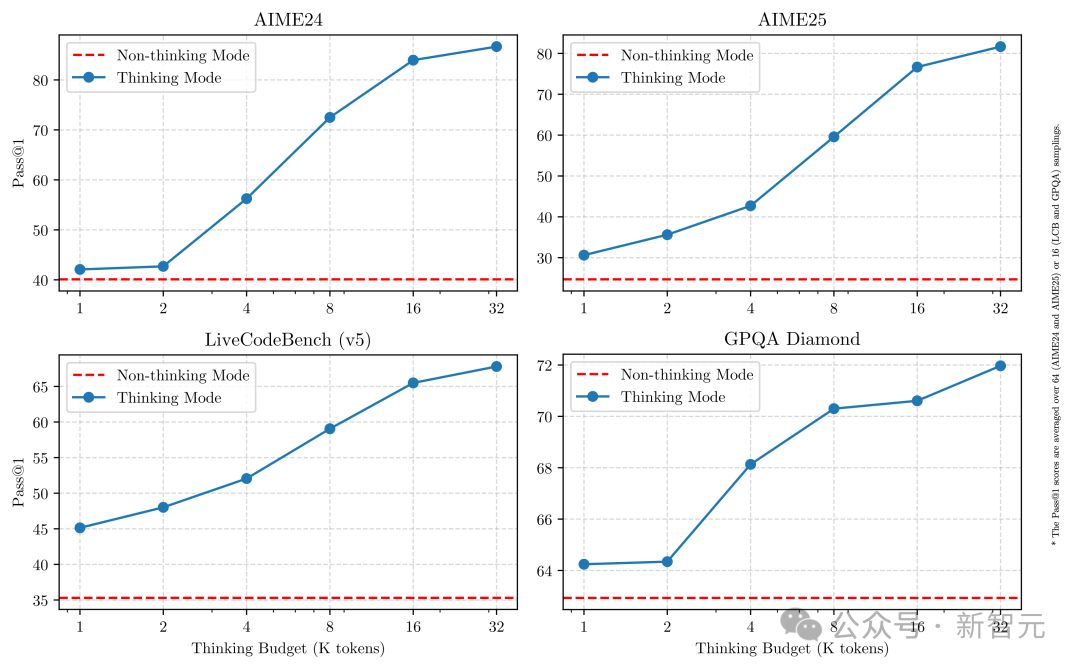
위 그림에서 보듯, Qwen3은 할당된 계산 추론 예산과 직접적으로 관련된 확장 가능하고 매끄러운 성능 향상을 보여준다.
이러한 설계는 사용자가 특정 작업에 맞춰 예산을 쉽게 구성할 수 있게 하여 비용 효율성과 추론 품질 사이의 최적 균형을 실현할 수 있도록 한다.
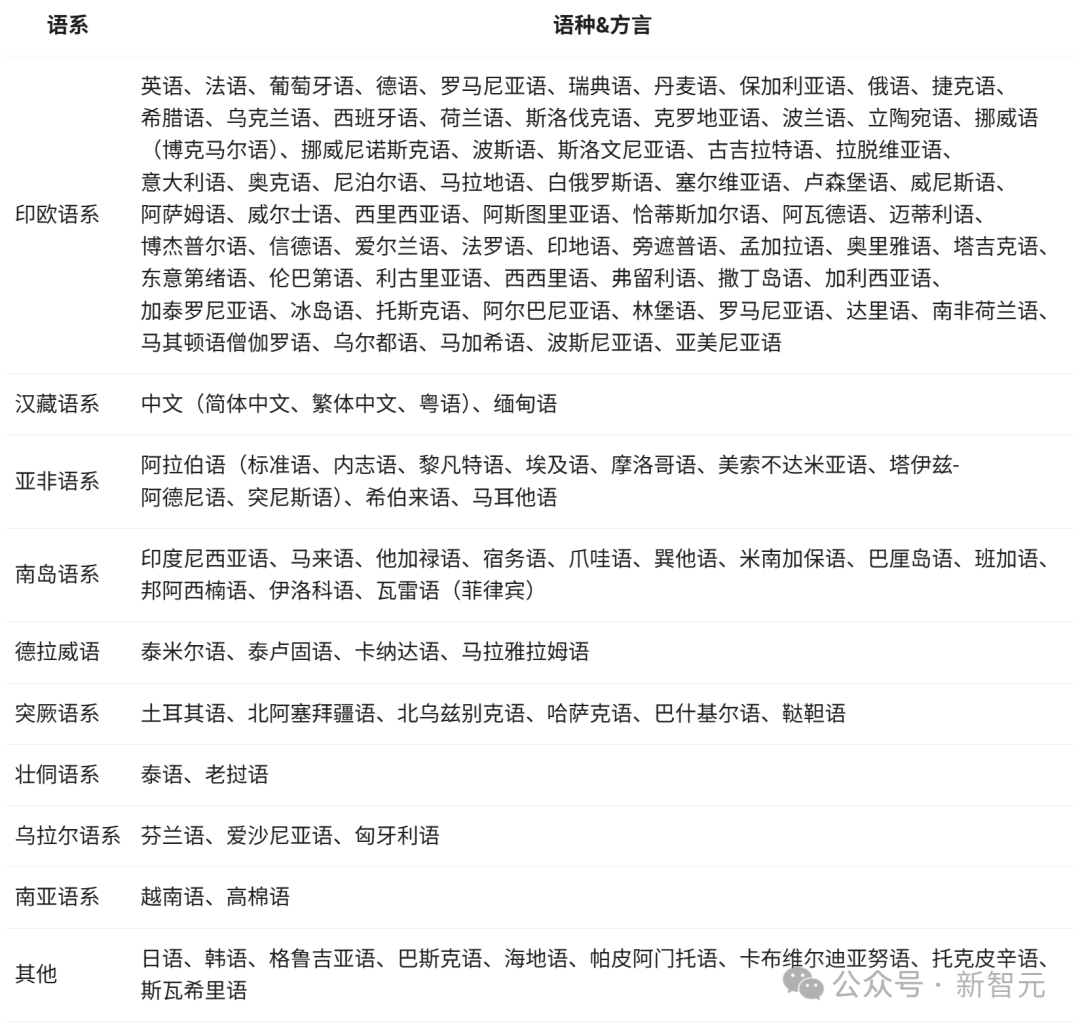
다국어 지원
Qwen3 모델은 119개 언어 및 방언을 지원한다.
이처럼 광범위한 다국어 능력은 Qwen3이 전 세계적으로 인기를 끌 수 있는 국제 애플리케이션을 만드는 잠재력이 매우 크다는 것을 의미한다.
강화된 에이전트 능력
알리바바는 Qwen3 모델을 최적화하여 코딩 및 에이전트 능력을 향상시키고, MCP 지원도 강화하였다.
다음 예제는 Qwen3가 어떻게 생각하고 환경과 상호작용하는지를 잘 보여준다.
36조 토큰, 다단계 학습
천문 시리즈 최강 모델인 Qwen3은 어떻게 이렇게 인상적인 성과를 달성했을까?
다음으로 Qwen3의 기술적 세부사항을 살펴보자.
사전 학습
Qwen2.5와 비교해 Qwen3의 사전 학습 데이터셋 규모는 거의 두 배로, 18조 토큰에서 36조 토큰으로 확장되었다.
119개 언어 및 방언을 포괄하며, 웹뿐만 아니라 PDF 등 문서에서 추출한 텍스트 내용도 포함된다.
데이터 품질을 보장하기 위해 팀은 Qwen2.5-VL을 활용해 문서 텍스트를 추출하고, Qwen2.5로 추출 내용의 정확성을 최적화하였다.
또한 수학 및 코딩 분야의 성능을 향상시키기 위해 Qwen2.5-Math 및 Qwen2.5-Coder를 활용하여 교과서, 질문-답변 쌍, 코드 조각 등大量的 합성 데이터를 생성하였다.
Qwen3의 사전 학습 과정은 총 세 단계로 나뉘며, 모델의 능력을 점진적으로 향상시킨다:
1단계(S1): 기초 언어 능력 구축
30조 토큰 이상을 사용하여 4k 컨텍스트 길이로 사전 학습한다. 이를 통해 모델은 튼튼한 언어 능력과 일반 지식 기반을 마련한다.
2단계(S2): 지식 집약형 최적화
STEM, 코딩, 추론 과제 등 지식 집약형 데이터의 비중을 늘려 추가 5조 토큰으로 추가 학습하여 전문 분야 성능을 더욱 향상시킨다.
3단계(S3): 컨텍스트 능력 확장
고품질 컨텍스트 데이터를 활용하여 모델의 컨텍스트 길이를 32k로 확장하여 복잡하고 매우 긴 입력을 처리할 수 있도록 한다.
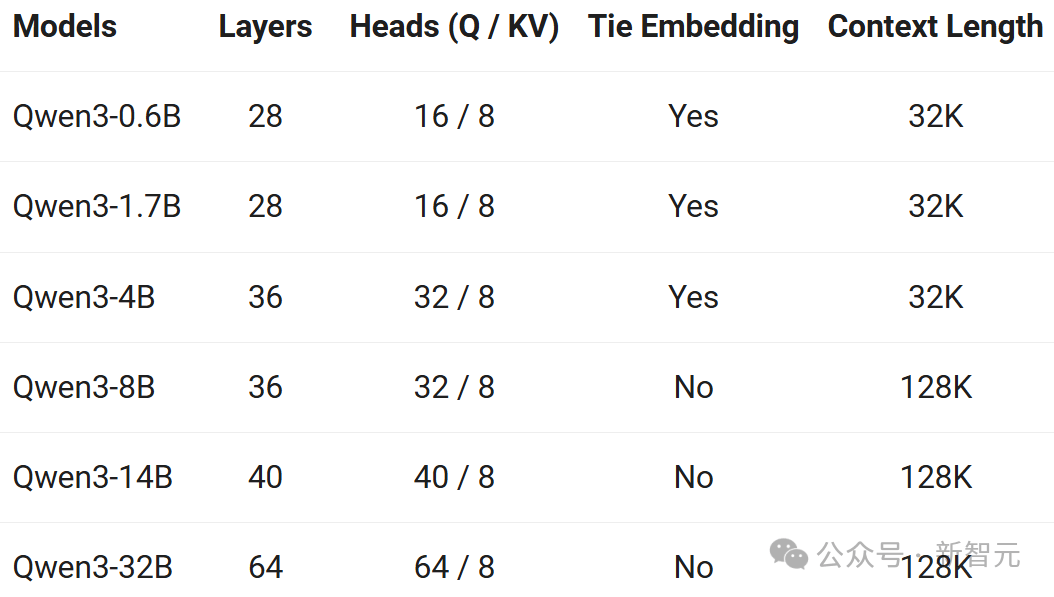
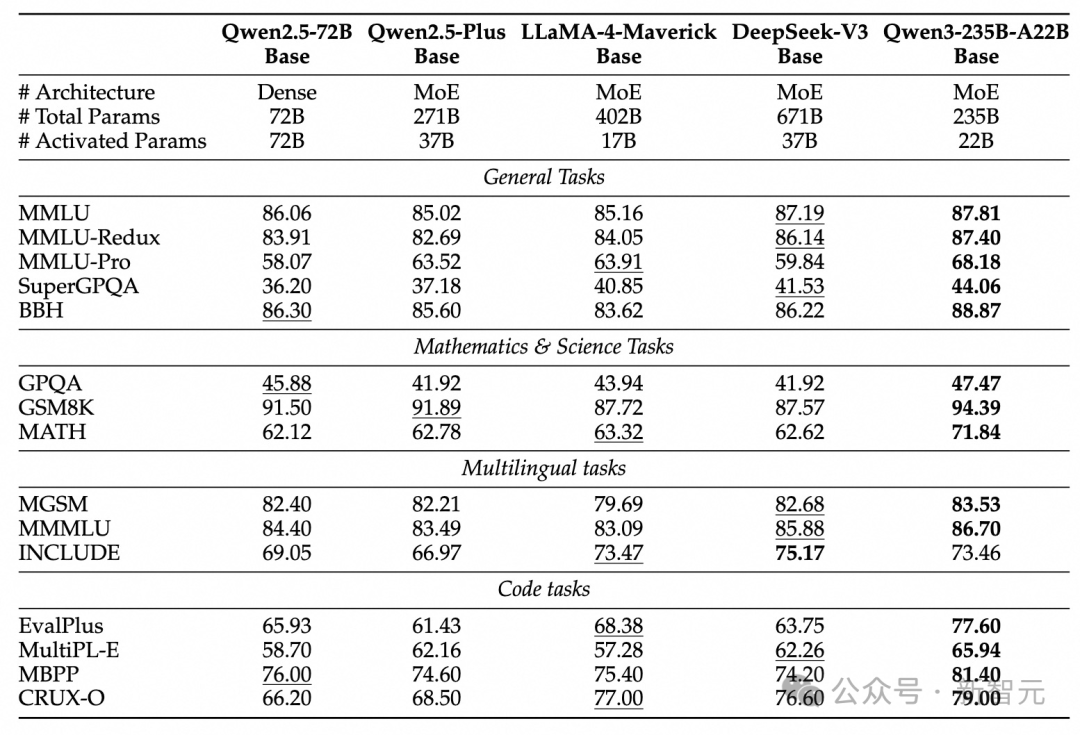
모델 아키텍처 최적화, 데이터 규모 확장 및 보다 효율적인 학습 방법 덕분에 Qwen3 Dense 기본 모델은 눈에 띄는 성능을 발휘한다.
아래 표에서 보듯, Qwen3-1.7B/4B/8B/14B/32B-Base는 Qwen2.5-3B/7B/14B/32B/72B-Base와 맞먹는 성능을 보이며, 더 작은 파라미터로 더 큰 모델의 수준에 도달한다.
특히 STEM, 코딩, 추론 분야에서 Qwen3 Dense 기본 모델은 더 큰 Qwen2.5 모델보다 우수한 성능을 보인다.
더욱 주목할 점은 Qwen3 MoE 모델이 단 10% 활성화 파라미터로 Qwen2.5 Dense 기본 모델과 유사한 성능을 실현한다는 것이다.
이는 학습 및 추론 비용을 크게 절감할 뿐만 아니라 모델의 실제 배포에 더 높은 유연성을 제공한다.
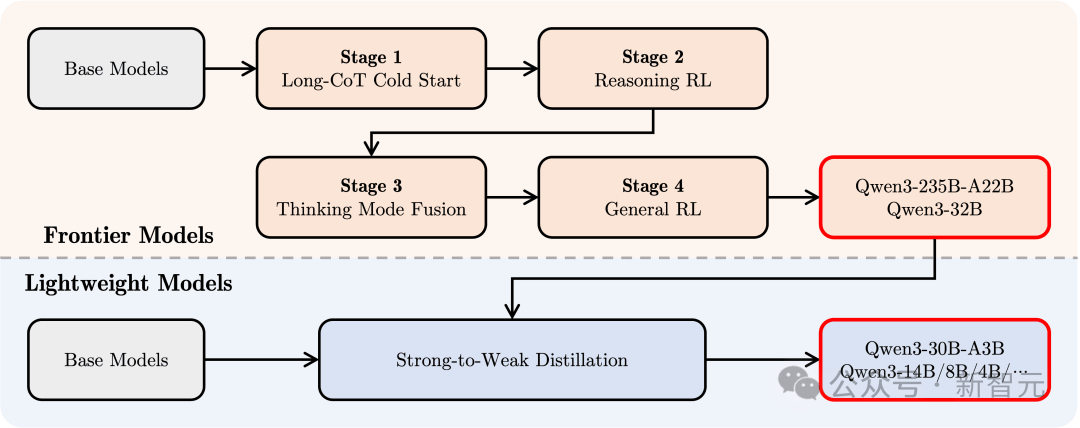
후속 학습(Post-training)
복잡한 추론과 신속한 응답이 가능한 혼합 모델을 만들기 위해 Qwen3은 4단계 후속 학습 프로세스를 설계하였다.
1. 장시간 사고 연쇄 콜드스타트
수학, 코딩, 논리 추론, STEM 문제를 포함한 다양한 장시간 사고 연쇄 데이터를 사용하여 모델이 기본적인 추론 능력을 습득하도록 한다.
2. 장시간 사고 연쇄 강화 학습
RL의 컴퓨팅 자원을 확장하고 규칙 기반 보상 메커니즘을 결합하여 모델이 추론 경로 탐색 및 활용 능력을 향상시킨다.
3. 사고 모드 융합
장시간 사고 연쇄 데이터와 지시어 미세 조정 데이터를 사용하여 빠른 반응 능력을 추론 모델에 통합하여 복잡한 작업에서도 정확하고 효율적인 성능을 보장한다.
이 데이터는 2단계의 향상된 사고 모델이 생성하여 추론 능력과 빠른 응답 능력의 원활한 융합을 보장한다.
4. 일반 강화 학습
명령어 따르기, 형식 따르기, 에이전트 능력 등 20여 개의 일반 분야 과제에 RL을 적용하여 모델의 일반성과 강건성을 더욱 향상시키고, 부적절한 행동을 수정한다.
인터넷 전반의 호평
Qwen3가 오픈소스 공개된 지 3시간도 안 되어 GitHub에서 17,000개의 스타를 받으며 오픈소스 커뮤니티의 열기를 완전히 붙였다. 개발자들은 너도나도 다운로드하여 초고속 테스트를 시작했다.
프로젝트 주소:
https://github.com/QwenLM/Qwen3
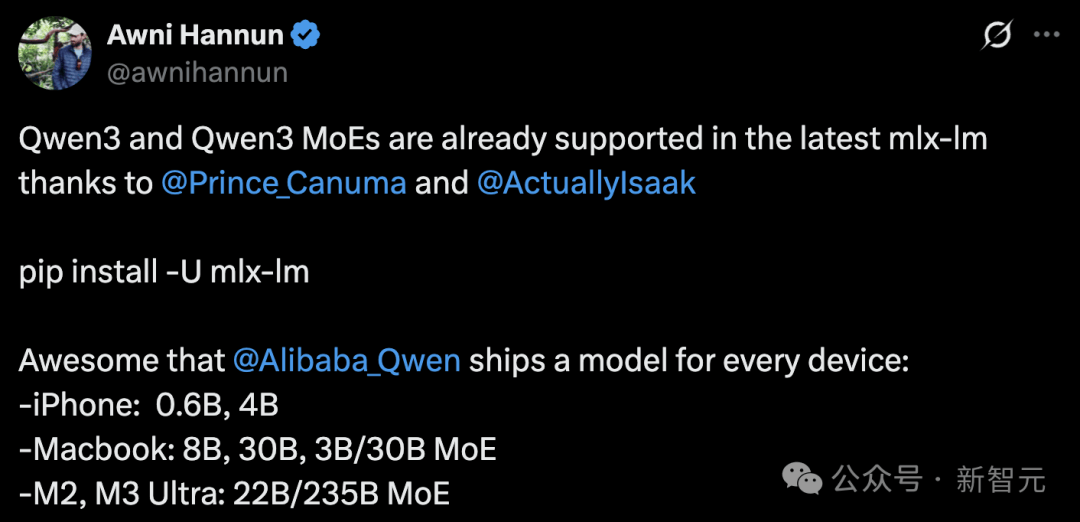
애플 엔지니어 Awni Hannun은 Qwen3가 MLX 프레임워크를 지원한다고 발표했다.
아이폰(0.6B, 4B), 맥북(8B, 30B, 3B/30B MoE), M2/M3 울트라(22B/235B MoE)와 같은 소비자용 기기에서도 로컬에서 실행 가능하다.
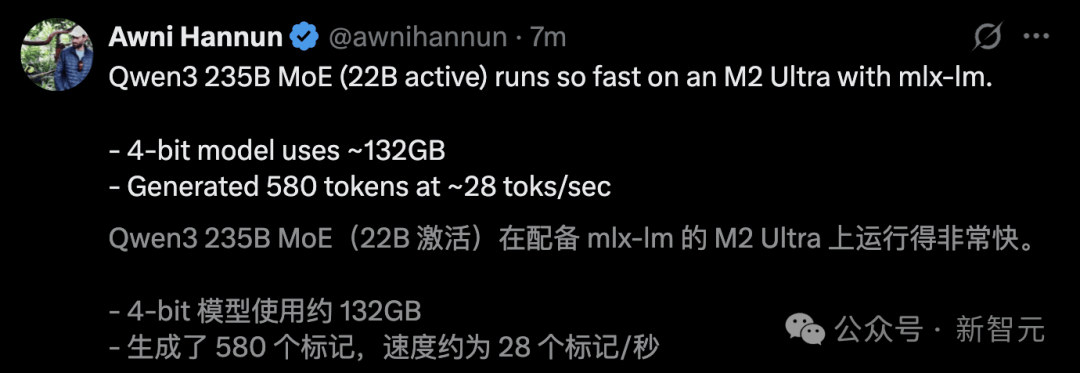
그는 M2 울트라에서 Qwen3 235B MoE를 실행하여 생성 속도가 초당 28 토큰에 달한다고 밝혔다.
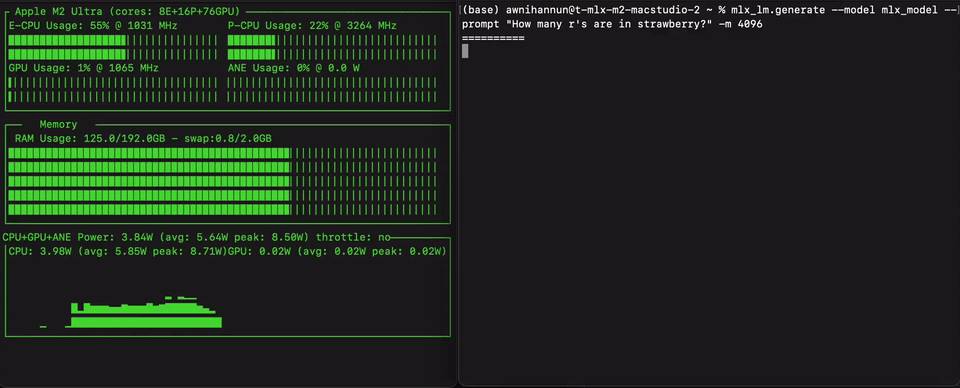
일부 네티즌의 실측 결과, Qwen3과 유사한 크기의 Llama 모델은 전혀 다른 수준이라며, 전자는 더 깊은 추론, 더 긴 컨텍스트 유지, 더 어려운 문제 해결이 가능하다고 평가했다.

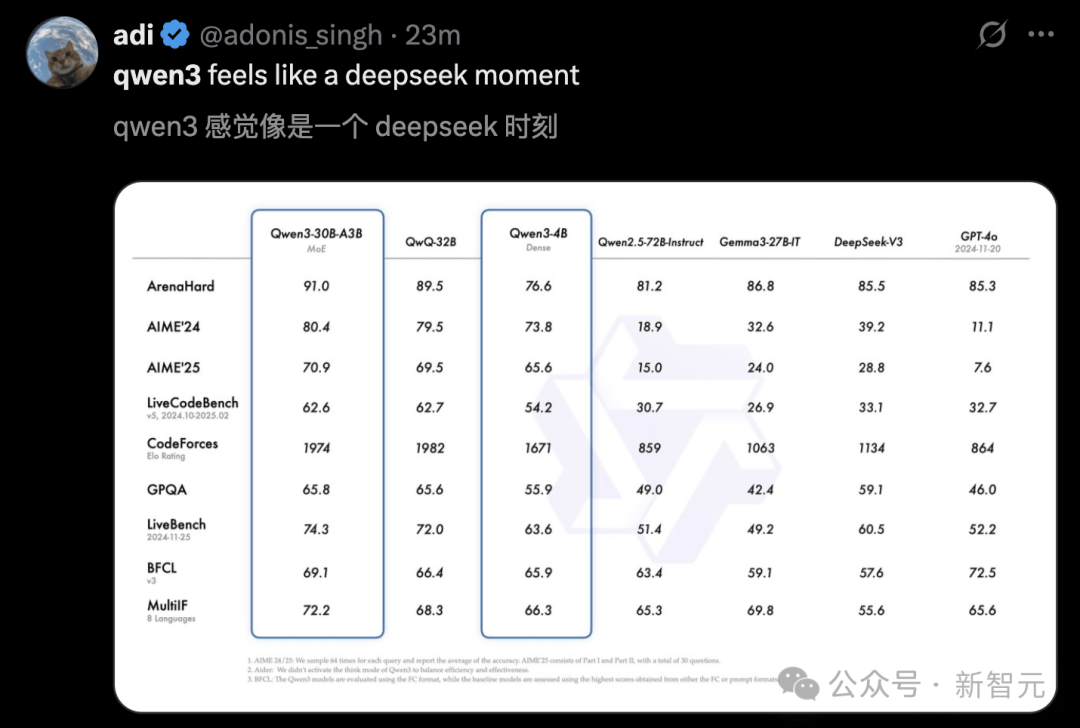
또 어떤 이는 Qwen3이 마치 딥시크(Depseek)의 순간 같다고 표현하기도 했다.
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News













