

TechFlow를 추적하다, 왜 TechFlow는 경력이 없는 젊은 인재들을 선호할까?
저자: Sam Gao, ElizaOS 저자
0. 서론
최근 DeepSeek V3와 R1의 연이은 등장으로 미국의 AI 연구원, 창업가, 투자자들이 점차 FOMO 상태에 빠지고 있다. 이 대열의 축제는 2022년 말 ChatGPT가 세상에 나왔을 때만큼이나 놀라운 일이다.

DeepSeek R1은 완전한 오픈소스(HuggingFace에서 무료로 모델 다운로드 및 로컬 추론 가능)이며 극도로 낮은 가격(OpenAI o1의 1/100 수준)이라는 특징 덕분에 단 5일 만에 미국 애플 AppStore 다운로드 1위를 차지했다.
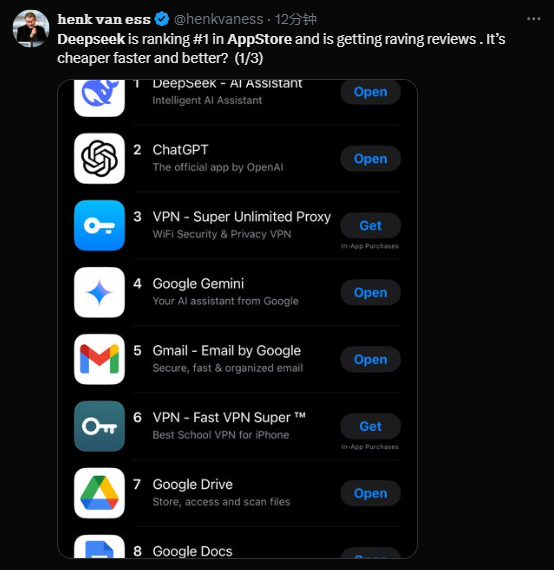
그렇다면 이 신비로운 기업, 중국계 양적 거래 회사에서 탄생한 새로운 AI 세력인 DeepSeek는 도대체 어디서 왔는가?
1. DeepSeek의 탄생 배경
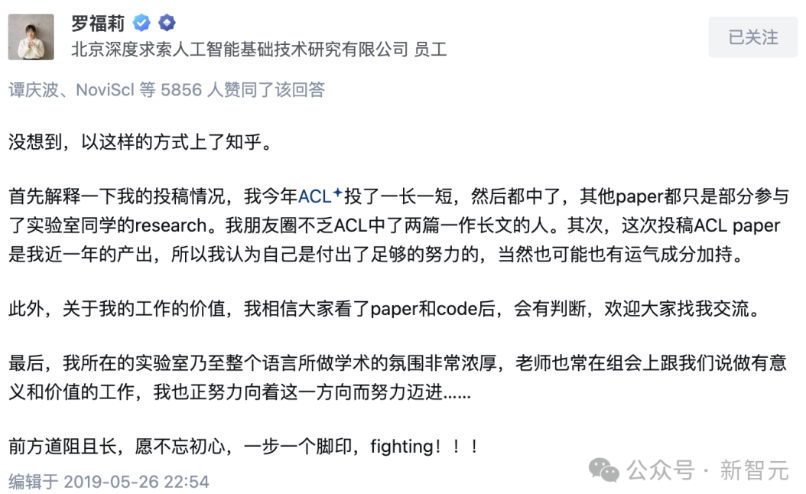
내가 처음 DeepSeek를 알게 된 것은 2021년이었다. 당시 다후안 연구소(DAMO Academy)에서 일할 때, 옆 팀의 천재 소녀였던 북대 석사 로푸리(Lo Fu-li)가 ACL(자연어 처리 최정상 학회)에 1년 만에 8편의 논문을 발표하며 화려하게 이름을 날렸는데, 그녀가 헹팡 양적거래(High-Flyer Quant)로 이직했다. 모두가 매우 궁금해했다. 돈을 많이 버는 양적거래 회사가 왜 굳이 AI 분야 인재를 영입하는가? 혹시 헹팡도 논문을 내야 하는가?
당시 내가 알기로는 헹팡이 영입한 AI 연구원들은 대부분 개별적으로 활동하며 최첨단 기술 방향을 탐색하고 있었으며, 그중 가장 핵심적인 분야는 대규모 언어 모델(LLM)과 이미지 생성 모델(당시 OpenAI DALL-E 관련 기술)이었다.
시간은 흘러 2022년 말, ChatGPT의 충격으로 오랫동안 AI 분야에 축적된 경험을 쌓아온 헹팡의 CEO 량원펑(梁文锋)은 드디어 범용 인공지능(AGI) 분야 진출을 결심한다. "우리는 새 회사를 설립했고, 언어 모델부터 시작해서 시각 모델 등 다양한 분야로 확장할 것이다."
맞다. 바로 이 회사가 DeepSeek다. 2023년 초, 지푸(Zhipu), 문오다미엔(Moonshot), 바이촨(Baichuan) 등 '6小龙'이라 불리는 기업들이 점차 무대 중심에 서기 시작했고, 북경 중관춘과 우다커우의 번화한 중심지에서 DeepSeek는 이러한 자본의 주목을 받지 못하며 존재감이 묻혔다.
따라서 2023년, 스타 창업자가 없는 순수 연구기관이었던 DeepSeek는 시장에서 독립적으로 자금을 조달하기 어려웠다. 예를 들어 리카이푸의 01.ai, 양즈린의 문오다미엔, 왕샤오촨의 바이촨 등과 같은 유명 창업자들이 이끄는 기업들과 비교하면 더욱 그러했다. 결국 헹팡은 DeepSeek를 분사시키고 전액 출자를 결정했다. 2023년이라는 과열된 시장 상황 속에서 어느 VC도 DeepSeek에 투자하려 하지 않았다. 이유는 두 가지였다. 첫째, DeepSeek 팀은 대부분 막 박사학위를 받은 젊은 인재들로 구성되어 있어 유명한 최정상급 연구원이 없었고, 둘째, 자본 회수가 장기적으로 불투명했기 때문이다.
잡음과 부조리가 가득한 환경 속에서도 DeepSeek는 조용히 자신의 AI 탐험 이야기를 하나씩 써 내려갔다:
-
2023년 11월, 파라미터 670억 개를 가진 DeepSeek LLM을 출시, 성능이 GPT-4 수준에 근접함.
-
2024년 5월, DeepSeek-V2 정식 출시.
-
2024년 12월, DeepSeek-V3 발표. 벤치마크 결과, Llama 3.1 및 Qwen 2.5보다 우수하며 GPT-4o와 Claude 3.5 Sonnet과 비슷한 수준을 보여 업계의 큰 관심을 불러일으킴.
-
2025년 1월, 최초의 추론 능력을 갖춘 대규모 모델 DeepSeek-R1 출시. OpenAI o1의 1/100 미만 가격과 뛰어난 성능으로 전 세계 기술계를 경악하게 함. 비로소 세계는 진정한 중국의 힘이 도래했음을 깨달았다… 오픈소스는 항상 승리한다!
2. 인재 전략
나는 초기부터 일부 DeepSeek 연구원들을 알고 있었다. 주로 AIGC 분야 연구자들로서, 2024년 11월 Janus를 발표한 연구자, DreamCraft3D의 개발자, 그리고 최근 내 논문 최적화를 도와준 @xingchaoliu도 포함된다.

내가 관찰한 바로는, 내가 아는 연구원들은 대부분 매우 젊었으며, 대부분 재학생 박사과정 또는 졸업 후 3년 이내였다.


특히 이들은 베이징 지역 대학에서 석·박사 과정을 밟은 사람들이며, 학술적으로 매우 뛰어난 역량을 지녔다. 대부분 최정상 학회에 3~5편의 논문을 발표한 경험이 있는 연구자들이다.
나는 DeepSeek 친구에게 물어봤다. 왜 량원펑은 젊은 인재만 뽑는가?
그는 내게 헹팡 CEO 량원펑의 말을 전해주었다. 원문은 다음과 같다.
DeepSeek 팀의 신비로운 면모는 사람들의 호기심을 자극한다. 그들의 비밀 병기는 무엇인가? 외신은 이 비밀 병기가 바로 "젊은 천재들"이며, 이들은 재정적으로 월등한 미국 거대 기업들과도 경쟁할 수 있는 실력을 갖췄다고 평가한다.
AI 산업에서는 경험이 풍부한 베테랑을 고용하는 것이 일반적이며, 많은 중국 현지 AI 스타트업들도 해외 박사 학위 소지자나 숙련된 연구원을 선호한다. 그러나 DeepSeek는 정반대로, 경력이 없는 젊은 인재를 선호한다.
한때 DeepSeek와 협력했던 헤드헌터는 DeepSeek는 숙련된 기술자를 뽑지 않으며, "3~5년 이상의 경력이 있는 사람이 최대치이며, 8년 이상 경력자는 기본적으로 제외된다"고 밝혔다. 량원펑은 2023년 5월 36Kr 인터뷰에서 DeepSeek의 대부분 개발자는 신입 졸업자이거나 AI 분야에 막 입문한 사람들이라고 말했다. 그는 강조했다. "우리의 핵심 기술 포지션은 대부분 신입 졸업자 또는 1~2년 경력자들이 맡고 있다."
경력이 없는 인재들을 DeepSeek는 어떻게 선발하는가? 답은 '잠재력'에 있다.
량원펑은 "장기적인 일을 할 때에는 경험보다는 기초 능력, 창의성, 열정이 더 중요하다"고 말했다. 그는 현재 세계 최정상 50위권의 AI 인재들이 중국에 아직 없다고 인정하면서도, "하지만 우리는 스스로 그런 인재를 만들어낼 수 있다"고 강조했다.
이 전략은 마치 OpenAI의 초기 전략을 떠올리게 한다. OpenAI는 2015년 말 설립 당시, 샘 알트먼(Sam Altman)의 핵심 아이디어는 젊고 야심찬 연구원을 찾는 것이었다. 따라서 사령탑인 그렉 브록맨(Greg Brockman)과 수석 과학자 일랴 서츠크버(Ilya Sutskever)를 제외하면, 나머지 4명의 핵심 기술 창립 멤버(앤드류 카파시, 더크 킹마, 존 슐먼, 보이치에흐 자렘바)는 모두 신입 박사 졸업자였으며, 각각 스탠포드, 암스테르담 대학교, UC 버클리, 뉴욕 대학교 출신이었다.

왼쪽부터: 일랴 서츠크버(전 수석 과학자), 그렉 브록맨(전 사령탑), 안드레이 카파시(전 기술 책임자), 더크 킹마(전 연구원), 존 슐먼(전 강화학습 팀장), 보이치에흐 자렘바(현 기술 책임자)
이러한 '어린 늑대 전략(young wolf strategy)'은 OpenAI가 성과를 거두게 했다. GPT의 아버지인 알렉 라드퍼드(Alec Radford, 민간 3류 대학 출신), 이미지 생성 모델 DALL-E의 아버지 아디티아 라메시(NYU 학부 출신), GPT-4o의 멀티모달 책임자이자 3회 올림피아드 금메달리스트인 프라팔라 디하리왈(Prafulla Dhariwal) 등이 탄생했다. 초기에는 구체적인 목표도 불분명했던 '세상을 구하자'는 계획이었지만, 젊은 인재들의 돌파력 덕분에 OpenAI는 딥마인드 옆의 무명세력에서 거대 기업으로 성장할 수 있었다.
량원펑은 바로 샘 알트먼의 이 성공 사례를 보고 자신도 이 길을 선택했다. 다만 OpenAI가 ChatGPT 등장을 보기까지 7년이 걸린 것과 달리, 량원펑은 불과 2년여 만에 성과를 거두었으며, 이른바 '중국의 속도'라고 할 수 있다.
3. DeepSeek를 위한 변론
DeepSeek R1의 논문에서 공개된 각종 지표는 놀라울 정도로 뛰어났다. 그러나 동시에 두 가지 의문점도 제기되었다.
-
① 사용한 Expert-Mixture(MoE) 기술은 학습 요구 사양과 데이터 요구 사양이 매우 높아, DeepSeek가 OpenAI의 데이터를 이용해 훈련했을 가능성에 대한 의심을 낳았다.
-
② 강화학습(RL) 기반 강화학습 기술을 사용했는데, 이는 하드웨어 요구 사양이 매우 높다. 그런데 메타, OpenAI의 수만 장 GPU 클러스터와 비교해 DeepSeek는 단 2048장의 H800만 사용했다.
이러한 컴퓨팅 파워의 제약과 MoE의 복잡성 때문에, 단 500만 달러로 한 번에 성공한 DeepSeek R1은 다소 의심스럽게 보일 수 있다. 그러나 당신이 R1을 '저비용 기적'이라 숭배하든 '화려하지만 실속 없음'이라 비판하든, 그 기능적 혁신의 눈부심은 무시할 수 없다.
비트맥스(BitMEX) 공동창업자 아서 헤이스(Arthur Hayes)는 다음과 같이 트윗했다. "DeepSeek의 부상으로 글로벌 투자자들이 미국 패권주의를 다시 의심하게 될까? 미국 자산 가치는 과대평가되고 있는가?"
스탠퍼드 대학교 교수인 우언다(吳恩達)는 올해 다보스 포럼에서 공개적으로 "DeepSeek의 발전에 깊은 인상을 받았다. 그들은 매우 경제적인 방식으로 모델을 학습시킬 수 있다는 것을 보여줬다. 최신 출시된 추론 모델도 매우 뛰어나다... 응원합니다!"라고 말했다.
A16z 창업자 마크 앤드리슨(Marc Andreessen)은 "Deepseek R1은 내가 본 것 중 가장 놀라우며 인상적인 돌파구 중 하나다. 게다가 오픈소스라는 점에서 세계에 주는 깊은 선물이다."라고 극찬했다.
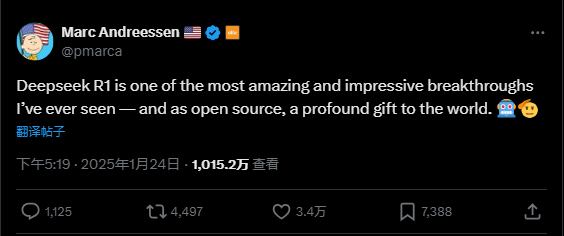
2023년 무대 구석에 서 있던 DeepSeek는 마침내 2025년, 음력 설날 직전, 세계 AI 정상에 올랐다.
4. Argo와 DeepSeek
Argo의 기술 개발자이자 AIGC 연구자로서, 나는 Argo의 핵심 기능들을 DeepSeek 기반으로 개선했다. Argo는 워크플로우(workflow) 시스템인데, 기존의 날것의 워크플로우 생성 작업은 DeepSeek R1을 통해 수행된다. 또한 Argo는 LLM을 표준 DeepSeek R1로 내장하였으며, 폐쇄형이고 고가인 OpenAI 모델을 버렸다. 이유는 워크플로우 시스템이 일반적으로 많은 토큰 소비와 맥락 정보(평균 >=10k 토큰)를 포함하기 때문에, OpenAI나 Claude 3.5 같은 고가 모델을 사용하면 실행 비용이 매우 커지기 때문이다. Web3 사용자들이 실제 가치를 확보하기 이전에 이러한 조기 과소비는 제품에 해가 된다.
DeepSeek의 성능이 점점 좋아짐에 따라, Argo는 DeepSeek를 중심으로 한 중국계 AI 세력과 더욱 긴밀한 협력을 이어갈 것이다. 예를 들어 Text2Image/Video 인터페이스의 중국화, LLM의 중국화 등이 포함된다.
협력 측면에서 Argo는 향후 DeepSeek 연구원들을 초청하여 기술 성과를 공유할 예정이며, 최정상급 AI 연구원들에게는 그랜트(grants)를 제공할 계획이다. 이를 통해 Web3 투자자와 사용자들이 AI 발전을 더 잘 이해할 수 있도록 돕고자 한다.
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News














