

구글의 AI 논문, 900억 달러 규모의 스토리지 관련 주가 폭락 유발… 조작된 실험으로 비난받아
저자: TechFlow
구글이 ‘AI 메모리 사용량을 1/6로 압축한다’고 주장하는 논문 한 편이 지난주 미국 마이크론(Micron), 샌디스크(SanDisk) 등 전 세계 저장장치 반도체 주가를 900억 달러 이상 폭락시키는 계기가 되었다.
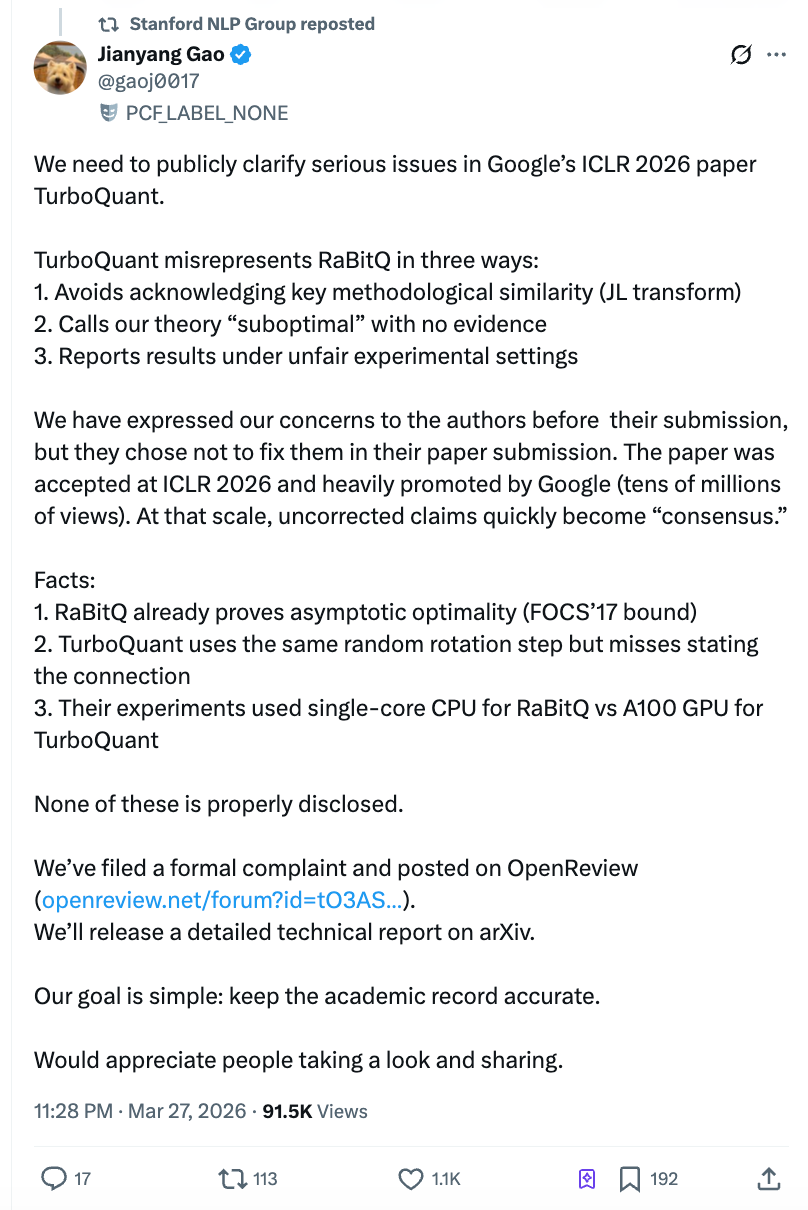
그러나 이 논문이 발표된 지 불과 이틀 만에, 논문에서 ‘압도적 우위’를 차지했다고 언급된 비교 대상인 취리히 연방공과대학(ETH Zurich) 박사후 연구원 가오젠양(Gao Jianyang)이 1만 자 분량의 공개 서한을 발표하며 구글 팀을 고발했다. 그는 실험 과정에서 경쟁 알고리즘은 단일 코어 CPU에서 실행되는 파이썬 스크립트로 테스트했으나, 구글 측 알고리즘은 A100 GPU로 테스트했으며, 투고 전 이미 이 문제점을 지적받았음에도 불구하고 수정을 거부했다고 주장했다. 이 공개 서한은 중국 지식 공유 플랫폼 지후(Zhihu)에서 조회 수가 급속히 400만 건을 넘었고, 스탠퍼드 자연어처리 그룹(Stanford NLP) 공식 계정이 이를 공유하며 학계와 시장 양쪽에서 충격이 확산되었다.
(참고 자료: 논문 한 편이 저장장치 관련 주가를 급락시켰다)
이 논란의 핵심은 복잡하지 않다. 즉, 구글이 대대적으로 홍보한 이 AI 정상급 학술대회 논문이, 이미 발표된 선도적 연구를 체계적으로 왜곡하고, 고의로 불공정한 실험 조건을 설정함으로써 허위의 성능 우위 내러티브를 조작했는가 하는 것이다. 이 논문은 전 세계 반도체 업계에 공포 심리를 유발해 매도 물량을 촉발시켰다.
TurboQuant가 한 일: AI의 ‘초안지’를 원래 두께의 1/6으로 압축하다
대규모 언어 모델(LLM)이 응답을 생성할 때는 이전에 계산한 내용을 계속 참조하면서 새 텍스트를 작성해야 한다. 이러한 중간 결과물은 임시로 GPU 메모리에 저장되며, 업계에서는 이를 ‘KV 캐시(KV Cache, 키-값 캐시)’라고 부른다. 대화가 길어질수록 이 ‘초안지’는 두꺼워지고, GPU 메모리 소비량도 증가하며, 비용 부담 역시 커진다.
구글 연구팀이 개발한 TurboQuant 알고리즘은 이 초안지를 원래 크기의 1/6으로 압축하는 것을 핵심 기능으로 내세운다. 동시에 정밀도 손실 없이 추론 속도를 최대 8배까지 향상시킬 수 있다고 주장한다. 이 논문은 2025년 4월에 학술 프리프린트 플랫폼 arXiv에서 처음 공개되었고, 2026년 1월에는 AI 분야 최고 권위의 학술대회 ICLR 2026에 채택되었으며, 3월 24일에는 구글 공식 블로그를 통해 재패키징되어 대대적으로 홍보되었다.
기술적으로 보면, TurboQuant의 아이디어는 간단히 설명할 수 있다. 먼저 수학적 변환을 통해 불규칙한 데이터를 통일된 형식으로 ‘정리’한 후, 사전에 계산된 최적 압축 테이블을 활용해 하나씩 압축한다. 마지막으로, 1비트 오류 정정 메커니즘을 적용해 압축 과정에서 생긴 계산 오차를 보정한다. 독립적인 커뮤니티 구현 결과에 따르면, 압축 효과 자체는 실재하며, 알고리즘 수준의 수학적 기여도 역시 실제 존재한다.
논란의 핵심은 TurboQuant가 ‘사용 가능하다’는 점이 아니라, 구글이 이를 ‘경쟁 알고리즘을 압도적으로 능가한다’고 입증하기 위해 어떤 방식으로 실험을 설계했는지에 있다.
가오젠양의 공개 서한: 세 가지 고발 사항, 모두 핵심을 찌른다
3월 27일 저녁 10시, 가오젠양은 지후(Zhihu)에 장문의 글을 게재했으며, 동시에 ICLR 공식 심사 플랫폼 OpenReview에도 공식적인 심사 의견을 제출했다. 그는 RaBitQ 알고리즘의 제1저자로, 이 알고리즘은 2024년 데이터베이스 분야 최고 권위의 학술대회 SIGMOD에 발표되었으며, 고차원 벡터의 효율적 압축이라는 동일한 문제를 해결한다.
그의 고발은 세 가지 항목으로 나뉘며, 각 항목마다 이메일 기록 및 시기별 시간선이 뒷받침된다.
고발 1: 타인의 핵심 기법을 무단으로 사용하고, 전문 전체에서 일절 언급하지 않음
TurboQuant와 RaBitQ는 기술적 핵심 단계에서 중요한 공통점을 갖는다. 바로 압축 수행 전에 데이터에 ‘무작위 회전(random rotation)’을 적용하는 것이다. 이 작업은 원래 불규칙하게 분포된 데이터를 예측 가능한 균일 분포로 바꿔 압축 난이도를 크게 낮추는 역할을 한다. 이는 두 알고리즘에서 가장 핵심적이며, 서로 가장 유사한 부분이다.
TurboQuant 저자들은 심사 답변서에서 이 점을 스스로 인정했으나, 논문 본문 어디에서도 RaBitQ와의 관계를 명시하지 않았다. 더욱 중요한 배경은 다음과 같다. TurboQuant의 제2저자 마지드 달리리(Majid Daliri)는 2025년 1월 가오젠양 팀에 직접 연락하여, RaBitQ 소스코드 기반으로 작성한 파이썬 버전 디버깅을 요청했다. 해당 이메일에는 재현 절차와 오류 메시지가 상세히 기재되어 있었는데, 이는 TurboQuant 팀이 RaBitQ의 기술적 세부 사항을 매우 잘 알고 있었다는 의미이다.
ICLR의 익명 심사위원 한 명도 독자적으로 두 알고리즘이 동일한 기법을 사용한다는 점을 지적하고, 충분한 논의를 요구했다. 그러나 최종 판본 논문에서는 TurboQuant 팀이 관련 논의를 보완하지 않았을 뿐 아니라, 본문 내 RaBitQ에 대한 (이미 부족했던) 설명조차 부록으로 이동시켰다.
고발 2: 근거 없이 상대 기법을 ‘이론적으로 비최적’이라고 단정함
TurboQuant 논문은 RaBitQ를 단순히 ‘이론적으로 비최적(suboptimal)’이라고 규정하고, 그 이유를 RaBitQ의 수학적 분석이 ‘상당히 대략적’이라고 주장한다. 그러나 가오젠양은 RaBitQ 확장판 논문이 이미 이론 컴퓨터과학 분야 최고 권위의 학술대회에서 압축 오차가 수학적으로 도달 가능한 최적 경계(optimal bound)에 이른다는 점을 엄격히 증명했다고 지적한다.
2025년 5월, 가오젠양 팀은 여러 차례 이메일을 통해 RaBitQ 이론의 최적성을 상세히 설명했다. TurboQuant 제2저자 달리리는 이 사실을 전 팀원에게 전달했다고 확인하였다. 그러나 논문 최종판에서는 여전히 ‘비최적’이라는 표현을 유지했으며, 어떠한 반박 근거도 제시하지 않았다.
고발 3: 실험 비교 과정에서 ‘왼손으로 상대를 묶고, 오른손으로 칼을 든 상태’에서 경쟁시킴
이 항목이 전체 고발 가운데 가장 강력한 타격력을 지닌다. 가오젠양은 TurboQuant 논문의 속도 비교 실험에서 두 가지 불공정 조건이 중첩되었다고 지적한다.
첫째, RaBitQ 공식 버전은 최적화된 C++ 코드로 제공되었으며, 기본적으로 멀티스레딩을 지원한다. 그러나 TurboQuant 팀은 이를 사용하지 않고, 스스로 번역한 파이썬 버전을 이용해 RaBitQ를 테스트했다. 둘째, RaBitQ 테스트 시 단일 코어 CPU를 사용하고 멀티스레딩을 비활성화했지만, TurboQuant는 NVIDIA A100 GPU를 사용했다.
이 두 조건이 중첩되면 독자들이 접하게 되는 결론은 “RaBitQ가 TurboQuant보다 수 개의 수량급(order of magnitude) 느리다”는 것이다. 그러나 이 결론의 전제는 구글 팀이 상대를 손발을 묶은 후 경주를 시킨 것임을 독자는 알 수 없다. 논문 내에서는 이러한 실험 조건 차이를 충분히 공개하지 않았다.
구글의 반응: “무작위 회전은 일반 기술이므로 모든 논문을 인용할 수 없다”
가오젠양이 공개한 자료에 따르면, TurboQuant 팀은 2026년 3월 이메일 답변에서 “무작위 회전과 존슨-린덴스트라우스 변환(Johnson-Lindenstrauss transformation)은 이미 해당 분야의 표준 기술이며, 이를 사용한 모든 논문을 인용할 수는 없다”고 밝혔다.
가오젠양 팀은 이는 개념을 교묘히 혼동하는 것이라고 반박한다. 문제는 무작위 회전을 사용한 모든 논문을 인용하라는 것이 아니라, RaBitQ가 동일한 문제 설정 하에서 이 기법을 벡터 압축과 결합한 최초의 연구이며, 또한 이에 대한 이론적 최적성을 입증한 최초의 연구라는 점이다. 따라서 TurboQuant 논문은 두 연구 간의 관계를 정확히 서술해야 마땅하다.
스탠퍼드 자연어처리 그룹(Stanford NLP Group) 공식 X 계정이 가오젠양의 성명을 공유했다. 가오젠양 팀은 이미 ICLR OpenReview 플랫폼에 공개 심사 의견을 게재했으며, ICLR 대회 의장 및 윤리위원회에 공식 민원을 제출했다. 향후 arXiv에도 상세한 기술 보고서를 게재할 예정이다.
독립 기술 블로거 다리오 살바티(Dario Salvati)는 비교적 중립적인 평가를 내렸다. 즉, TurboQuant는 수학적 방법론 측면에서 진정한 기여를 했으나, RaBitQ와의 연관성은 논문에서 서술된 것보다 훨씬 밀접하다는 것이다.
900억 달러 시장 가치 증발: 논문 논란과 시장 공포의 겹쳐짐
이 학술 논란이 발생한 시점은 극도로 민감하다. 구글은 3월 24일 공식 블로그를 통해 TurboQuant를 발표한 직후, 전 세계 저장장치 반도체 업종이 급격한 매도 압력을 받았다. CNBC 등 다수의 언론 보도에 따르면, 마이크론 테크놀로지는 연속 6거래일 하락하며 누적 하락률이 20%를 넘었고, 샌디스크는 하루 만에 11% 하락했다. 한국의 SK하이닉스는 약 6%, 삼성전자는 약 5%, 일본의 카이오(Kioxia)는 약 6% 각각 하락했다. 시장의 공포 논리는 단순명료하다. 소프트웨어 압축 기술이 AI 추론 과정의 메모리 수요를 6배 감소시킬 수 있다면, 저장장치 칩에 대한 수요 전망은 구조적으로 하향 조정될 수밖에 없다는 것이다.
모건스탠리 애널리스트 조셉 무어(Joseph Moore)는 3월 26일 보고서에서 이 논리를 반박하며 마이크론과 샌디스크에 대해 ‘매수’ 등급을 유지했다. 무어는 TurboQuant가 압축하는 것은 KV 캐시라는 특정 유형의 캐시일 뿐, 전체 메모리 사용량은 아니라고 지적하고, 이를 ‘정상적인 생산성 개선’으로 분류했다. 웰스파고 애널리스트 앤드류 로차(Andrew Rocha) 역시 제븐스 역설(Jevons paradox)을 인용하며, 효율성 향상으로 인한 비용 절감이 오히려 더 대규모의 AI 배포를 촉진시켜 궁극적으로는 메모리 수요를 증가시킬 수 있다고 주장했다.
오래된 논문, 새로운 포장: AI 연구에서 시장 내러티브로 이어지는 전달 체인의 위험
기술 블로거 벤 폴라디안(Ben Pouladian)의 분석에 따르면, TurboQuant 논문은 2025년 4월부터 이미 공개되었으며, 새로 나온 연구가 아니다. 그러나 구글은 3월 24일 공식 블로그를 통해 이를 재포장·홍보했고, 시장은 이를 완전히 새로운 돌파구로 받아들여 가격을 책정했다. 이런 ‘오래된 논문, 새롭게 발표’ 전략과, 논문 내에 존재할 수 있는 실험 편향이 결합되면서, AI 연구가 학술 논문에서 시장 내러티브로 전달되는 과정에 내재된 체계적 위험이 드러난 것이다.
AI 인프라 투자자들에게 있어, 어떤 논문이 ‘수 개의 수량급’ 성능 향상을 달성했다고 주장할 때, 가장 먼저 질문해야 할 것은 비교 기준이 공정한가 하는 것이다.
가오젠양 팀은 문제의 공식적 해결을 계속 추진할 것임을 분명히 밝혔다. 구글 측은 현재까지 공개 서한의 구체적 고발 사항에 대해 공식적인 입장 표명을 하지 않았다.
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News













