

하드코어 대화 Scroll 장엽: zkEVM과 Scroll 그리고 그 미래
인터뷰어: Nickqiao & Faust, Geek Web3
인터뷰이: YeZhang, Scroll 공동 창립자
편집: Faust, Jomosis
6월 17일, Geek Web3와 BTCEden은 Scroll의 DevRel인 Vincent Jin의 도움을 받아 Scroll 공동 창립자 장예(張燁)를 초청해 Scroll과 zkEVM에 관한 다양한 질문에 답하는 자리를 가졌다.
이번 대담에서는 기술적 주제뿐만 아니라 Scroll의 흥미로운 일화들과 아프리카·아시아·남미 등지의 실물 경제를 활성화하려는 거대한 비전까지 폭넓게 다루었다. 본문은 이 인터뷰의 텍스트 기록으로, 1만 자 이상이며 최소 15개의 주제를 포함한다:
-
ZK 기술의 전통 산업 적용 가능성
-
zkEVM과 zkVM의 공학적 난이도 차이
-
Scroll이 zkEVM 구현 과정에서 겪은 어려움
-
Scroll이 Zcash의 halo2 증명 시스템에 가한 개선점
-
Scroll과 이더리움 PSE 팀의 협업 방식
-
코드 감사를 통해 Scroll이 회로의 안정성과 신뢰성을 확보하는 방법
-
Scroll의 차세대 zkEVM 및 증명 시스템에 대한 간략한 로드맵
-
Scroll의 멀티 프루버(Multi Prover) 설계 및 프루버 생성 네트워크(zk 마이닝 풀) 구축 방식 등.
그 외에도 장예 공동 창립자는 마지막에 Scroll이 아프리카, 터키, 동남아시아 등 금융 인프라가 낙후된 지역에 뿌리를 두고, 현지 주민들에게 실질적인 실물 경제 활용 사례를 제공함으로써 '가상'에서 '실물'로 전환하려는 거대한 비전을 언급했다. 본 인터뷰는 Scroll을 더 깊이 이해하는 데 탁월한 자료가 될 것이며, 많은 분들의 꼼꼼한 독서를 권장한다.

1.Faust: 장예 공동 창립자님께 여쭙습니다. 롤업(Rollup) 외 분야에서 ZK 기술의 응용 가능성에 대해 어떻게 생각하시나요? 많은 사람들이 ZK는 믹서(mixer), 프라이버시 트랜잭션, ZK 롤업, ZK 브릿지 등의 용도로 쓰이는 것으로 여기지만, 웹3 외부, 즉 전통 산업에서도 ZK는 다양한 응용 사례를 보이고 있습니다. 앞으로 ZK 기술이 가장 가능성이 큰 분야는 어디라고 보십니까?
YeZhang: 매우 좋은 질문입니다. 전통 산업에서 ZK를 연구하는 사람들은 5~6년 전부터 다양한 시나리오를 탐색해왔습니다. 블록체인에서 ZK를 사용하는 경우는 사실 전체 ZK 응용 중 극히 일부에 불과합니다. 그래서 비탈릭 부테린(Vitalik Buterin)이 10년 후면 ZK의 응용 범위가 블록체인만큼이나 커질 것이라고 말하는 것입니다.
저는 신뢰 가정(trust assumption)이 필요한 모든 상황에서 ZK가 강력하게 활용될 수 있다고 봅니다. 예를 들어, 무거운 계산 작업을 처리해야 한다고 합시다. AWS에서 서버를 임대해 자신의 작업을 실행하고 결과를 얻는 것은 자신이 소유한 장치에서 계산하는 것과 유사하지만, 서버 임대 비용은 일반적으로 저렴하지 않습니다.
하지만 컴퓨팅 아웃소싱 모델을 도입하면, 다른 사람들이 유휴 장비나 리소스를 활용해 당신의 계산 작업을 분담할 수 있으며, 이때 드는 비용은 직접 서버를 임대하는 것보다 저렴할 수 있습니다. 그러나 여기에는 신뢰 문제가 발생합니다. 당신은 다른 사람이 돌려준 계산 결과가 정확한지 알 수 없습니다. 복잡한 계산을 제게 맡기고 그 대가를 지불한다고 하겠습니다. 제가 30분 후 아무렇게나 결과를 제출하면, 당신은 그것이 진짜인지 확인할 방법이 없습니다. 제가 아무 결과나 조작할 수 있기 때문입니다.
하지만 제가 제출한 계산 결과가 올바르다는 것을 증명할 수 있다면, 당신은 안심할 수 있고, 더 많은 계산 작업을 저에게 아웃소싱할 용기를 갖게 됩니다. ZK는 신뢰할 수 없는 데이터 소스를 신뢰 가능한 것으로 바꿀 수 있는 강력한 기능을 가지며, 이를 통해 값싸지만 신뢰할 수 없는 제3자 계산 리소스를 더욱 효율적으로 활용할 수 있습니다.
이러한 시나리오는 매우 의미 있으며, 컴퓨팅 아웃소싱 비즈니스 모델을 촉발할 수 있습니다. 일부 학술 논문에서는 이를 검증 가능한 컴퓨팅(verifiable computation)이라고 부릅니다. 다시 말해, 어떤 계산 자체를 신뢰할 만한 것으로 만드는 것입니다. 또한 ZK는 데이터베이스 분야에도 응용될 수 있습니다. 로컬에서 DB를 운영하는 것이 비용이 많이 들면, 아웃소싱을 선택할 수 있습니다. 누군가 여분의 DB 리소스를 가지고 있다면, 당신의 데이터를 그곳에 저장할 수 있습니다. 하지만 당신은 상대방이 자신의 데이터를 변경하거나, SQL 쿼리 결과가 올바른지 걱정할 수밖에 없습니다.
이에 대해 상대방이 증명(proof)을 생성하도록 할 수 있습니다. 이것이 가능하다면, 데이터 저장도 아웃소싱하면서 동시에 신뢰할 수 있는 결과를 얻을 수 있습니다. 이는 앞서 언급한 검증 가능한 컴퓨팅과 함께 중요한 응용 분야입니다.
또한 다양한 사례가 존재합니다. 저는 Verifiable ASIC(검증 가능한 반도체 칩)이라는 논문을 기억합니다. 칩을 생산할 때 ZK 알고리즘을 칩에 내장하면, 해당 칩으로 프로그램을 실행할 때 생성되는 결과에 자동으로 증명이 붙게 됩니다. 이렇게 되면 거의 모든 장치가 신뢰할 수 있는 결과를 생성하는 에이전트가 될 수 있습니다.
또 하나 다소 기이한 개념은 Photo Proof(사진 증명)입니다. 많은 사진들이 편집(포토샵)되었는지 아닌지 우리는 알 수 없습니다. 하지만 ZK를 이용해 사진이 조작되지 않았음을 증명할 수 있습니다. 예를 들어, 카메라 앱에 설정을 추가해 자동으로 디지털 서명을 생성하게 할 수 있습니다. 사진을 찍으면 이 서명이 사진에 도장을 찍듯이 남습니다. 누군가 당신의 사진을 가져가 포토샵으로 수정하거나 '2차 창작'을 하면, 서명을 검증함으로써 이미지가 조작되었음을 식별할 수 있습니다.
여기에 ZK를 도입하면, 원본 사진에 약간의 수정을 가했을 때, 단순히 회전이나 이동 같은 기본 조작만 했으며 원본 내용을 조작하지 않았음을 ZK 증명으로 입증할 수 있습니다. 이렇게 수정한 이미지가 원본과 본질적으로 동일함을 보여주고, 핵심 콘텐츠를 조작하여 '2차 창작'을 하지 않았음을 입증할 수 있습니다.
이러한 시나리오는 동영상 및 오디오로도 확장될 수 있으며, ZK를 통해 원본 영상에 무엇을 수정했는지 상대방에게 알려주지 않더라도 핵심 내용을 조작하지 않았음을 증명할 수 있습니다. 단순히 무해한 조정만 수행했음을 입증할 수 있습니다. 이 외에도 ZK가 활용될 수 있는 흥미로운 사례들이 많습니다.
현재로서는 ZK 기술의 응용이 널리 확산되지 못한 이유는 비용이 너무 높기 때문입니다. 기존의 ZK 증명 생성 방식은 임의의 계산에 대해 실시간으로 증명을 생성하기 어렵습니다. ZK의 오버헤드는 일반적으로 원래 계산의 100배에서 1000배에 달합니다. 물론 제가 말하는 숫자는 이미 낮춰진 수치입니다.
따라서 계산 작업이 원래 1시간 걸린다면, ZK 증명을 생성하는 데 오버헤드가 100배라면 100시간이 소요됩니다. GPU나 ASIC을 사용해 시간을 단축할 수 있지만, 여전히 엄청난 계산 리소스가 필요합니다. 아주 복잡한 계산을 해달라고 요구하면서 동시에 ZK 증명을 생성해달라고 하면, 저는 거절할 수밖에 없습니다. 왜냐하면 계산 리소스를 100배나 추가로 소모해야 하기 때문에 경제적으로 매우 비효율적이기 때문입니다. 따라서 일대일 상황에서는 일회성 ZK 증명 생성이 매우 비쌉니다.
하지만 바로 이런 점 때문에 블록체인에 ZK가 적합한 이유이기도 합니다. 블록체인은 중복 계산(redundant computation)을 하며, 일대다(one-to-many) 상황이 많기 때문입니다. 블록체인 네트워크의 서로 다른 노드들은 동일한 계산 작업을 수행합니다. 만약 1만 개의 노드가 있다면, 동일한 작업이 1만 번 실행되어야 합니다. 하지만 체인 외부에서 작업을 완료하고 ZK 증명을 생성한 후, 1만 개의 노드가 그 증명만 검증하고 원래 계산을 다시 실행하지 않는다면, 원래 계산을 1만 번 반복할 필요가 없어집니다. 결국 한 사람의 계산 비용을 1만 개 노드의 중복 계산 비용과 교환하는 셈이므로, 전체적으로 보면 더 많은 사람들이 리소스를 절약할 수 있습니다.
따라서 사실 체인이 더 탈중앙화될수록 ZK와의 결합이 더 적합합니다. 누구나 거의 제로 비용으로 ZKP를 검증할 수 있기 때문입니다. 초기 증명 생성에 일정한 비용을 지불하는 것만으로도 대부분의 사람들을 해방시킬 수 있습니다. 이것이 바로 블록체인의 공개 검증 가능성(public verifiability)이 ZK와 잘 맞는 이유이며, 블록체인에는 많은 일대다 상황이 존재하기 때문입니다.
또한 위에서 언급하지 않은 한 가지가 있습니다. 현재 블록체인 분야에서 사용되는 오버헤드가 큰 ZK 증명은 모두 비대화형(non-interactive)입니다. 즉, 당신이 나에게 무언가를 주면, 나는 증명을 만들어 돌려주고 끝납니다. 블록체인에서는 체인과 계속해서 상호작용할 수 없기 때문입니다. 하지만 더 효율적이고 오버헤드가 낮은 증명 생성 방식이 있는데, 바로 대화형 증명(interactive proof)입니다. 예를 들어, 당신이 나에게 Challenge를 보내고, 내가 무언가를 보내고, 당신이 또 무언가를 보내고, 내가 다시 무언가를 보내는 식으로 여러 번의 상호작용을 통해 ZK의 계산량을 추가로 줄일 수 있습니다. 이러한 방식이 가능하다면, 큰 규모의 ZK 응용 시나리오에서의 증명 생성 문제를 해결할 수 있을 것입니다.
Nickqiao: zkML, 즉 ZK와 머신러닝의 융합 전망에 대해 어떻게 생각하십니까?
YeZhang: zkML 역시 매우 흥미로운 방향입니다. 머신러닝을 ZK화하는 것이 가능하지만, 저는 아직 이 분야에 결정타가 되는 응용 사례(killer application)가 부족하다고 봅니다. ZK 시스템의 성능이 향상되면 미래에 ML 수준의 응용을 지원할 수 있을 것이라며, 현재 zkML의 효율성은 gpt2 수준의 응용을 지원할 수 있으며 기술적으로는 가능하지만, ML의 추론(inference) 부분까지만 가능합니다. 궁극적으로 사람들이 여전히 탐색하고 있는 것은, 도대체 어떤 것이 자신의 추론 과정이 올바름을 증명해야 하는가 하는 점입니다. 이 문제는 상당히 난해합니다.
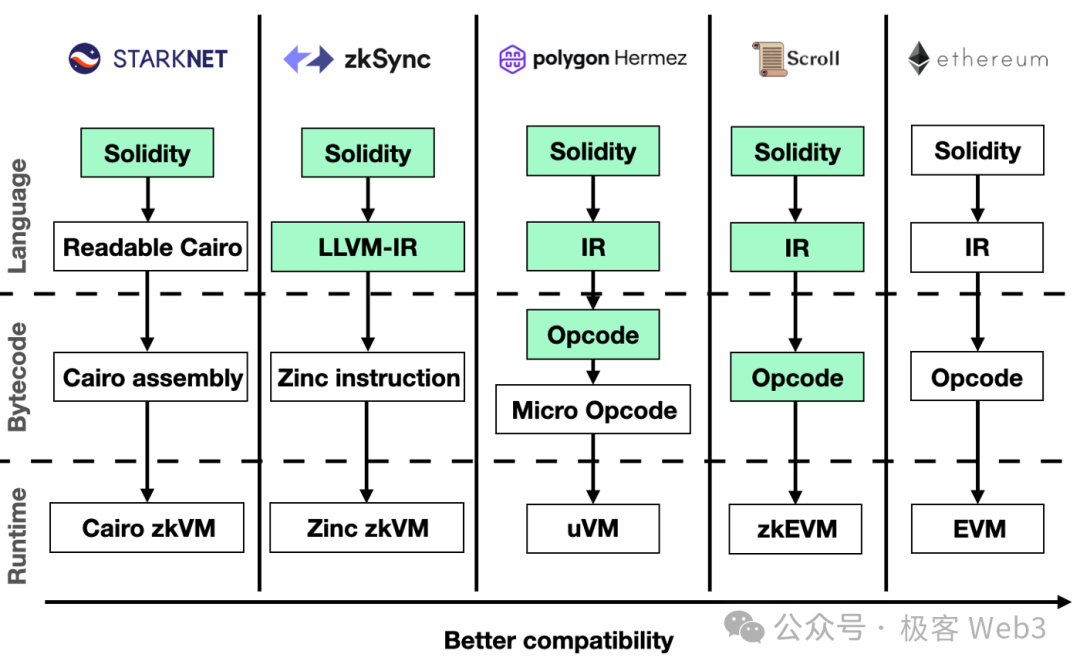
2.Nickqiao: 장예 공동 창립자님께 여쭙습니다. zkEVM과 zkVM의 공학적 구현 난이도 차이는 구체적으로 얼마나 큰가요?
YeZhang: 먼저, zkEVM이든 zkVM이든 본질적으로는 특정 가상머신의 오퍼레이션 코드(instruction set)에 맞춘 맞춤형 ZK 회로(circuit)를 생성하는 것입니다. zkEVM의 공학적 구현 난이도는 그 구현 방식에 따라 달라지며, 저희가 프로젝트를 시작할 당시 ZK의 효율성이 아직 충분히 높지 않았기 때문에, EVM의 각 오퍼레이션 코드마다 해당 회로를 작성한 후 이를 조합하여 맞춤형 zkEVM을 만드는 것이 가장 효율적인 방식이었습니다.
하지만 이러한 방식의 공학적 구현 난이도는 당연히 매우 크며, zkVM보다 훨씬 큽니다. EVM의 명령어 세트에는 100개가 넘는 오퍼레이션 코드가 있으며, 각각에 맞는 회로를 따로 만들어 조합해야 하기 때문입니다. EIP를 통해 EVM에 새로운 오퍼레이션 코드가 추가될 때마다, 예를 들어 EIP-4844처럼, zkEVM도 새로 추가해야 합니다. 결국 매우 긴 회로를 작성하고 오랜 시간 동안 감사를 진행해야 하므로, 개발 난이도와 작업량은 zkVM보다 훨씬 큽니다.
반면에 zkVM은 자체적으로 명령어 세트를 정의하며, 이 자체 명령어 세트는 매우 간단하게 만들 수 있고 ZK 친화적으로 설계할 수 있습니다. zkVM을 한번 만들면, 저수준 코드를 자주 변경하지 않아도 다양한 업그레이드와 프리컴파일(precompile)을 지원할 수 있습니다. 따라서 zkVM의 주요 작업량과 후속 업그레이드, 유지 관리의 어려움은 컴파일러에 집중되는데, 즉 스마트 계약을 zkVM 오퍼레이션 코드로 변환하는 단계에 있습니다. 이 점에서 zkEVM과 크게 다릅니다.
따라서 공학적 난이도 측면에서, 저는 zkVM이 맞춤형 zkEVM보다 구현이 더 쉬울 것이라 봅니다. 하지만 zkVM 위에서 EVM을 실행한다면, 전반적인 성능은 맞춤형 zkEVM보다 훨씬 낮습니다. 후자가 전용으로 설계되었기 때문입니다. 그러나 지난 2년간 프루버(prover)의 증명 생성 효율이 최소 3~5배, 혹은 5~10배까지 비약적으로 향상되었으며, 이에 따라 zkVM의 효율도 함께 상승하고 있습니다. 지금 zkVM으로 EVM을 실행하는 전반적인 효율이 서서히 개선되고 있으며, 미래에는 성능상의 열세가 개발 및 유지 관리의 용이성이라는 장점에 의해 상쇄될 수 있습니다. 결국 zkVM과 zkEVM 모두 성능 외에 가장 큰 병목은 개발 난이도에 있으며, 반드시 매우 강력한 엔지니어링 팀이 있어야만 이러한 복잡한 시스템을 제대로 유지 관리할 수 있습니다.
3.Nickqiao: Scroll이 zkEVM을 구현하는 과정에서 어떤 기술적 어려움을 겪었으며, 어떻게 해결하셨습니까?
YeZhang: 프로젝트를 진행하면서 가장 큰 도전은 처음 시작할 때의 불확실성이 너무 컸다는 점이었습니다. 저희가 프로젝트를 시작할 당시에는 기본적으로 다른 팀이 zkEVM을 하고 있지 않았으며, 저희는 zkEVM을 '불가능'에서 '가능'으로 만드는 최초의 팀 중 하나였습니다. 이론적으로는 프로젝트 시작 후 6개월 만에 실행 가능한 프레임워크를 기본적으로 확정했지만, 후속 구현 과정에서 zkEVM의 공학적 작업량이 매우 크고, 몇 가지 고도의 기술적 도전 과제도 있었습니다. 예를 들어, 어떻게 동적으로 다양한 프리컴파일(pre-compile)을 지원할 것인지, 오퍼코드(opcode)를 더 효율적으로 집약(aggregation)하는 방법 등은 많은 공학적 난관을 포함하고 있습니다.
또한 저희는 EC Pairing(타원곡선 페어링)이라는 프리컴파일을 지원하는 유일하고 최초의 팀이기도 합니다. 페어링(Pairing)과 같은 회로는 구현 난이도가 매우 높으며, 수학 등 복잡한 난제를 포함하고 있어 회로를 작성하는 사람의 암호학·수학 실력과 공학 능력에 매우 높은 수준을 요구합니다.
후기 발전 단계에서는 기술 스택의 장기적인 유지 보수 가능성과 언제쯤 차세대 zkEVM 2.0으로 업그레이드할지를 고려해야 했습니다. 저희는 전담 연구팀을 두고 있으며, zkVM 방식으로 EVM을 지원하는 등의 방안을 지속적으로 연구하고 있습니다. 관련 논문도 발표하며 논의를 진행하고 있습니다.
종합하면, 이전의 난관은 zkEVM을 '불가능'에서 '가능'으로 만드는 것이었으며, 주요 도전은 공학적 구현과 최적화에 있었습니다. 다음 단계에서는 어느 시점에, 어떤 구체적인 방식으로 더 효율적인 ZK 증명 시스템으로 전환할 것인지, 그리고 현재의 코드베이스를 차세대 zkEVM으로 어떻게 전이시킬 것인지, 차세대 zkEVM이 우리에게 어떤 새로운 기능을 제공할 수 있을지 등에 더 큰 도전이 있으며, 여기에는 광범위한 탐색 공간이 존재합니다.
4.Nickqiao: 듣기에 의하면 Scroll이 다른 ZK 증명 시스템으로 전환하는 것을 고려하고 있는 것 같습니다. 제가 아는 바에 따르면, 현재 Scroll은 PLONK+Lookup 기반의 알고리즘을 사용하고 있는데, 이 알고리즘이 현재 zkEVM 구현에 가장 적합한가요? 그리고 미래에 Scroll은 어떤 증명 시스템을 사용할 계획이신가요?
YeZhang: 먼저 PLONK와 Lookup에 관한 간단한 답변부터 드리겠습니다. 현재로서는 이 조합이 여전히 zkEVM 또는 zkVM을 구현하는 데 가장 적합한 시스템이며, 대부분의 구현은 특정한 PLONK와 Lookup에 종속되어 있습니다. 일반적으로 PLONK라고 하면, 주로 PLONK의 산술화(arithmetization) 방식, 즉 회로를 표현하는 수학적 형식을 사용해 zkVM 회로를 작성하는 것을 의미합니다.
Lookup은 회로 작성 시 사용되는 일종의 제약(constraint) 유형입니다. 따라서 PLONK + Lookup이라고 할 때, 이는 zkEVM 또는 zkVM 회로를 작성할 때 PLONK의 제약 형식을 사용한다는 의미이며, 현재로서는 가장 일반적인 방식입니다.
백엔드 측면에서는 PLONK와 STARK의 경계가 모호해졌으며, 이들은 단지 다른 다항식 커밋 방식(polynomial commitment)을 사용할 뿐이며, 사실상 매우 유사합니다. STARK + Lookup 조합을 사용하더라도 PLONK + Lookup과 유사하며, 사람들이 주목하는 것은 알고리즘뿐이며, 두 시스템의 차이는 주로 프루버의 효율성, 증명 크기 등에 나타납니다. 물론 프론트엔드 측면에서는 zkEVM 구현에 PLonk + Lookup이 여전히 가장 적합합니다.
두 번째 질문인 Scroll의 미래 증명 시스템 전환 계획에 대해서 말씀드리겠습니다. Scroll의 목표는 항상 기술과 체인 프레임워크를 ZK 분야에서 최정상 수준으로 유지하는 것이기 때문에, 우리는 반드시 최신 기술을 채택할 것입니다. 우리는 항상 보안성과 안정성을 최우선 목표로 삼고 있으므로, ZK 증명 시스템을 지나치게 급진적으로 전환하지는 않을 것이며, 아마 먼저 멀티 프루버(Multi Prover)를 통해 전이 과정을 거치며 단계적으로 업그레이드와 반복 작업을 진행할 것입니다. 어쨌든 이것은 안정적인 전환 과정이어야 합니다.
하지만 현재로서는 새로운 증명 시스템으로의 전환은 아직 이릅니다. 이는 향후 6개월에서 1년 정도의 다음 단계 발전 방향입니다.
5.Nickqiao: Scroll은 현재 PLONK와 Lookup 기반의 증명 시스템에서 독특한 혁신을 이루었나요?
YeZhang: 현재 Scroll 메인넷에서 운영 중인 시스템은 halo2입니다. halo2는 원래 Zcash 팀이 개발한 것으로, Lookup을 지원하고 회로 형식을 유연하게 작성할 수 있도록 하는 백엔드 시스템입니다. 그 후 저희는 이더리움 PSE 팀과 함께 halo2를 개조하여, 기존의 IPA 다항식 커밋 방식을 KZG로 교체하였으며, 이를 통해 증명 크기를 줄이고, 이더리움에서 ZK 증명을 더 효율적으로 검증할 수 있게 되었습니다.
또한 GPU 하드웨어 가속 측면에서도 많은 작업을 진행하였으며, CPU를 사용해 ZKP를 생성하는 것과 비교하면 ZKP 생성 속도를 5~10배 빠르게 만들었습니다. 전반적으로 저희는 기존 halo2의 다항식 커밋 방식을 검증하기 더 쉬운 버전으로 교체하였으며, 프루버 최적화에 많은 노력을 기울였고, 공학적 구현에 상당한 노력을 기울였습니다.

6.Nickqiao: 그렇다면 현재 Scroll은 이더리움 PSE 팀과 함께 KZG 버전의 halo2를 공동으로 유지 관리하고 있는 셈이군요. 그러면 여러분이 PSE 팀과 어떻게 협업하고 있는지 설명해주실 수 있겠습니까?
YeZhang: Scroll이 프로젝트를 시작하기 전부터 저희는 이미 PSE 팀의 일부 엔지니어들과 알고 있었으며, zkEVM을 만들고 싶다고 이야기를 나누었고, 그 효율성도 대략적으로 예측해보았습니다. 마침 같은 시기에 그들도 동일한 일을 하려는 의도를 갖고 있었고, 자연스럽게 뜻이 맞아 협업이 성사되었습니다.
따라서 저희는 이더리움 커뮤니티, 특히 Ethereum Research를 통해 zkEVM을 만들고자 하는 사람들을 만나게 되었으며, 모두 zkEVM을 제품화하고 실현하려는 목표를 갖고 있었고, 이더리움에 봉사하려는 의지도 있었습니다. 그래서 자연스럽게 오픈소스 협업 모델을 시작하게 되었습니다. 이 협업 방식은 상업적 기업보다는 오픈소스 커뮤니티에 더 가깝습니다. 예를 들어 매주 전화 통화를 하며 진행 상황을 공유하고, 어떤 문제를 겪고 있는지 논의합니다.
이러한 방식으로 저희는 코드를 오픈소스로 유지 관리해왔으며, halo2 개선에서부터 zkEVM 구현까지 많은 탐색 과정을 거쳤고, 서로 코드 리뷰를 도와주었습니다. Github의 코드 기여량을 보면, PSE 팀이 절반을, Scroll 팀이 절반을 작성한 것을 확인할 수 있습니다. 이후 코드 감사를 완료하고 실제로 제품화되어 메인넷에서 운영되는 버전을 구현했습니다. 요약하면, 저희와 이더리움 PSE의 협업 모델은 오픈소스 커뮤니티의 방식과 같으며, 자발적인 형태입니다.
7.Nickqiao: 방금 말씀하신 바와 같이, zkEVM 회로를 작성하려면 수학과 암호학에 대한 요구 수준이 매우 높기 때문에, zkEVM을 제대로 이해하는 사람은 극소수일 것 같습니다. 그렇다면 Scroll은 어떻게 회로 작성의 정확성을 보장하고 버그를 최소화합니까?
YeZhang: 저희는 오픈소스 코드이기 때문에, 기본적으로 모든 PR(Pull Request)에 대해 저희 팀원들과 이더리움 팀원들, 그리고 일부 커뮤니티 구성원들이 리뷰를 진행하며, 엄격한 감사 절차를 거칩니다. 또한 회로 감사에 상당한 비용을 투입하였으며, 100만 달러 이상을 들여 Trail of Bits, Zellic 등 이 분야에서 가장 전문적인 암호학 및 회로 감사 기관에 의뢰하였습니다. 체인 상의 스마트 계약 부분도 openzeppelin에 감사를 맡겼으며, 보안과 관련된 모든 항목에 최고 수준의 감사 리소스를 동원하였습니다. 내부에는 전담 보안 팀이 테스트를 지속적으로 수행하며 Scroll의 보안성을 지속적으로 강화하고 있습니다.
Nickqiao: 이러한 감사 방식 외에 형식적 검증(formal verification) 등 수학적으로 더 엄밀한 방법은 없었나요?
YeZhang: 저희는 형식적 검증(formal verification) 방향을 이미 오래전부터 살펴봤으며, 최근 이더리움도 zkEVM에 형식적 검증을 어떻게 적용할지 고민하고 있습니다. 이는 매우 좋은 방향입니다. 하지만 현재로서는 zkEVM에 완전한 형식적 검증을 적용하기에는 이르며, 작은 모듈부터 탐색을 시작해야 합니다. 형식적 검증을 실행하는 데는 비용이 들기 때문입니다. 예를 들어, 코드에 형식적 검증을 적용하려면 먼저 사양(specification)을 작성해야 하는데, 이 사양을 작성하는 것도 쉽지 않으며, 이를 완벽하게 갖추는 데는 오랜 시간이 필요합니다.
따라서 현재로서는 zkEVM에 완전한 형식적 검증을 적용할 시기가 아니라고 생각하지만, 저희는 이더리움을 포함한 외부 협력자들과 함께 지속적으로 zkEVM의 형식적 증명 방법을 어떻게 구현할지 적극적으로 탐색할 계획입니다.
현재로서는 가장 좋은 방법은 여전히 인공 감사입니다. 왜냐하면 사양(spec)과 형식적 검증이 있다고 하더라도, 사양을 잘못 작성하면 여전히 문제가 발생하기 때문입니다. 따라서 현재로서는 우선 인공 감사를 통해, 오픈소스와 취약점 보상(bug bounty) 방식을 활용해 Scroll 코드의 안정성을 확보하는 것이 가장 좋다고 생각합니다.
하지만 차세대 zkEVM에서는 어떻게 형식적 검증을 수행할지, 그리고 어떻게 더 나은 zkEVM을 설계하여 사양을 쉽게 작성할 수 있도록 하고, 형식적 검증을 통해 그 안전성을 입증할지가 이더리움의 궁극적인 목표입니다. 즉, zkEVM이 형식적으로 검증된 후에는 이더리움 메인넷에 안심하고 배포할 수 있게 되는 것입니다.

8.Nickqiao: Scroll이 채택한 halo2가 STARK 등 새로운 증명 시스템을 지원하려면 개발 비용이 매우 클까요? 여러 증명 시스템을 동시에 지원하는 플러그인식 구조를 구현할 수 있을까요?
YeZhang: halo2는 매우 모듈화된 ZK 증명 시스템으로, 도메인(field), 다항식 커밋 등을 교체할 수 있습니다. halo2에서 사용하는 다항식 커밋을 KZG에서 FRI로 바꾸기만 하면, 기본적으로 halo2 기반의 STARK 버전을 구현할 수 있습니다. 실제로 이를 시도한 사례도 있습니다. 따라서 halo2가 STARK를 지원하는 것은 완전히 가능합니다.
하지만 실제 적용 과정에서 극한의 효율을 추구한다면, 지나치게 모듈화된 프레임워크는 오히려 일부 효율성 문제를 야기할 수 있습니다. 모듈화를 위해 맞춤화 정도를 희생하게 되며, 이에 따른 대가를 치러야 하기 때문입니다. 저희는 지속적으로 고민하고 있는 문제가 있습니다. 즉, 미래의 발전 방향이 모듈화된 프레임워크인지, 아니면 매우 특화된 프레임워크인지 말입니다. 특히 저희처럼 충분히 강력한 ZK 개발 팀을 보유한 경우, 독립적인 증명 시스템을 유지 관리하면서 zkEVM을 더욱 효율적으로 만들 수 있습니다. 물론 위의 문제는 어느 정도 타협이 필요하지만, halo2는 FRI를 지원할 수 있다는 점은 분명합니다.
9.Nickqiao: 현재 Scroll의 ZK 분야 주요 반복 개발 방향은 무엇입니까? 현재 알고리즘의 최적화, 새로운 기능 추가 등이 중심인가요?
YeZhang: 저희 엔지니어링 팀의 핵심은 현재 프루버의 성능을 한 번 더 향상시키는 것이며, EVM 호환성도 최고 수준으로 유지하는 것입니다. 다음 버전 업그레이드에서는 저희가 ZK 롤업 중에서 가장 높은 EVM 호환성을 유지하는 위치를 계속 유지할 것입니다. 현재 다른 모든 zkEVM은 우리의 호환성보다 떨어진다고 생각합니다.
이것이 바로 Scroll 엔지니어링 팀이 현재 추진 중인 방향으로, 프루버와 호환성의 지속적인 최적화와 수수료 감소입니다. 저희는 이미 차세대 zkEVM 연구에 많은 인력을 투입하고 있으며, 전체 엔지니어링 인력의 절반 정도를 투입해 분 단위, 심지어 초 단위의 ZK 증명 생성을 실현하고, 프루버의 효율성을 높이려고 노력하고 있습니다.
또한, 새로운 zkEVM 실행 계층(execution layer)을 탐색하고 있습니다. 저희 노드는 기존에 go-ethereum을 사용했지만, 현재는 성능이 더 우수한 Rust 기반의 이더리움 클라이언트 Reth가 있습니다. 따라서 저희는 차세대 zkEVM을 Reth 클라이언트와 어떻게 더 잘 통합할지 연구하고 있으며, 체인 전반의 성능을 향상시키려고 합니다. zkEVM이 새로운 실행 계층을 중심으로 할 경우, 어떤 구현 방식과 전이 형태가 가장 적합할지 면밀히 검토할 것입니다.
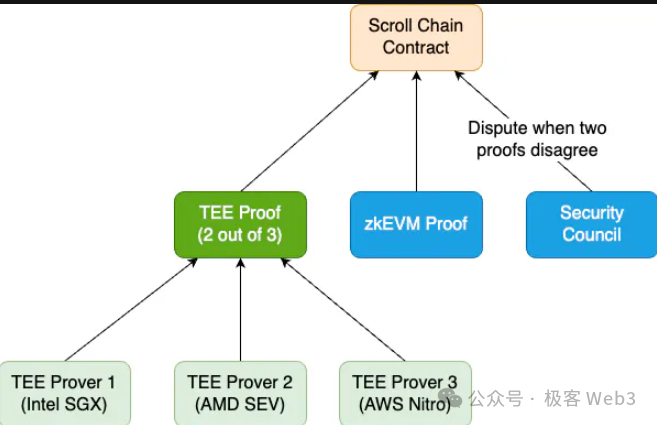
10.Nickqiao: 그렇다면 Scroll이 다양화된 증명 시스템을 지원하려는 계획이 있다면, 체인 상에 여러 Verifier 계약을 구현할 필요가 있겠습니까? 예를 들어, 상호 검증(cross-validation)을 하는 방식 말입니다.
YeZhang: 저는 이것이 두 가지 문제라고 생각합니다. 첫째, 모듈화된 증명 시스템과 다양한 프루버를 만드는 것이 필요한가 하는 점입니다. 저는 이것이 의미 있다고 봅니다. 왜냐하면 저희는 처음부터 오픈소스 프로젝트이기 때문입니다. 공개하는 프레임워크가 더 범용적일수록 더 많은 사람들이 도구를 만들어주는 데 동참하게 되고, 커뮤니티도 자연스럽게 커지며, 이후 프로젝트 개발이나 도구 사용 시 외부의 역량을 자연스럽게 활용할 수 있게 됩니다. 따라서 Scroll만을 위한 것이 아니라 다른 사람들도 사용할 수 있는 ZK 증명 프레임워크를 만드는 것은 매우 의미 있는 일입니다.
두 번째는 메인넷에서 상호 검증을 하는 문제입니다. 이는 증명 시스템 자체가 다양화되어 있거나, STARK 또는 PLONK를 지원하는지와는 무관한 주제입니다. 일반적으로 동일한 zkEVM을 PLONK로 한 번 검증하고, STARK로 또 한 번 검증하는 경우는 거의 없습니다. 왜냐하면 보안성이 크게 향상되지 않지만, 프루버의 비용은 훨씬 더 커지기 때문입니다. 따라서 일반적으로 이러한 상호 검증 상황은
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News














